A Survey on Deep Clustering:From the Prior Perspective
A Survey on Deep Clustering: From the Prior Perspective
四川大学计算机科学学院,成都,中国四川
摘要
由于神经网络具有强大的特征提取能力,深度聚类在分析高维和复杂的真实世界数据方面取得了巨大的成功。深度聚类方法的性能受到网络结构和学习目标等各种因素的影响。然而,正如本调查中所指出的,深度聚类的本质是对先验知识的整合和利用,这在很大程度上被现有的工作忽略了。从开创性基于数据结构假设的深度聚类方法到最近基于数据增强不变性的对比聚类方法,深度聚类的发展本质上对应于先验知识的演化。在本调查中,我们通过将深度聚类方法分为六种先验知识类型,提供了一个全面的回顾。我们发现,总的来说,先前的创新遵循两个趋势,即,i)从采矿到建设,以及ii)从内部到外部。此外,我们在五个广泛使用的数据集上提供了一个基准,并分析了具有不同先验的方法的性能。通过提供一个新的先验知识视角,我们希望这次调查能够提供一些新的见解,并启发未来在深度聚类社区的研究。
1 介绍
2 问题定义
在本节中,我们将介绍深度聚类的管道,包括符号和问题定义。除非特别通知,否则在本文中,我们使用粗体大写和小写分别表示矩阵和向量。表1总结了常用的符号。

深度聚类问题的正式定义如下:给定一组属于C类的实例\(\mathcal{D}=\{\bf x_{i}\}_{i=1}^{N}\in\mathcal{X}\),深度聚类的目的是学习鉴别特征,并根据实例的语义将其分为C聚类。具体来说,深度聚类方法首先学习一个深度神经网络\(f:{\mathcal{X}}\rightarrow{\mathcal{Z}}\)用于特征提取\(\mathbf{z}_{i}=f(\mathbf{x}_{i})\)。给定潜在空间的实例特征,可以得到聚类结果。最直接的方法是应用经典算法,如K-means(MacQueen等,1967)和DBSCAN(Ester等,1996a)。另一种解决方案是训练一个额外的集群头\(h\ :\mathcal{Z}\to\mathbb{R}^{C}\)生成满足\(\textstyle{\sum_{i=0}^{K}\mathbf{p}_{i j}}\;=\;1\)的生成软集群分配\(\mathbf{p}_i=\operatorname{sotrmax}(h(\mathbf{z}_{i}))\)。第\(i\)个实例的硬簇分配可以通过arg max操作来计算,即: \[\tilde{y}_{i}=\arg\operatorname*{max}_{j}\ {\bf p}_{i j},1\leq j\leq C\] 聚类分配提供了数据底层的固有语义结构,可以用于各种下游分析。
3 深度聚类的先验条件
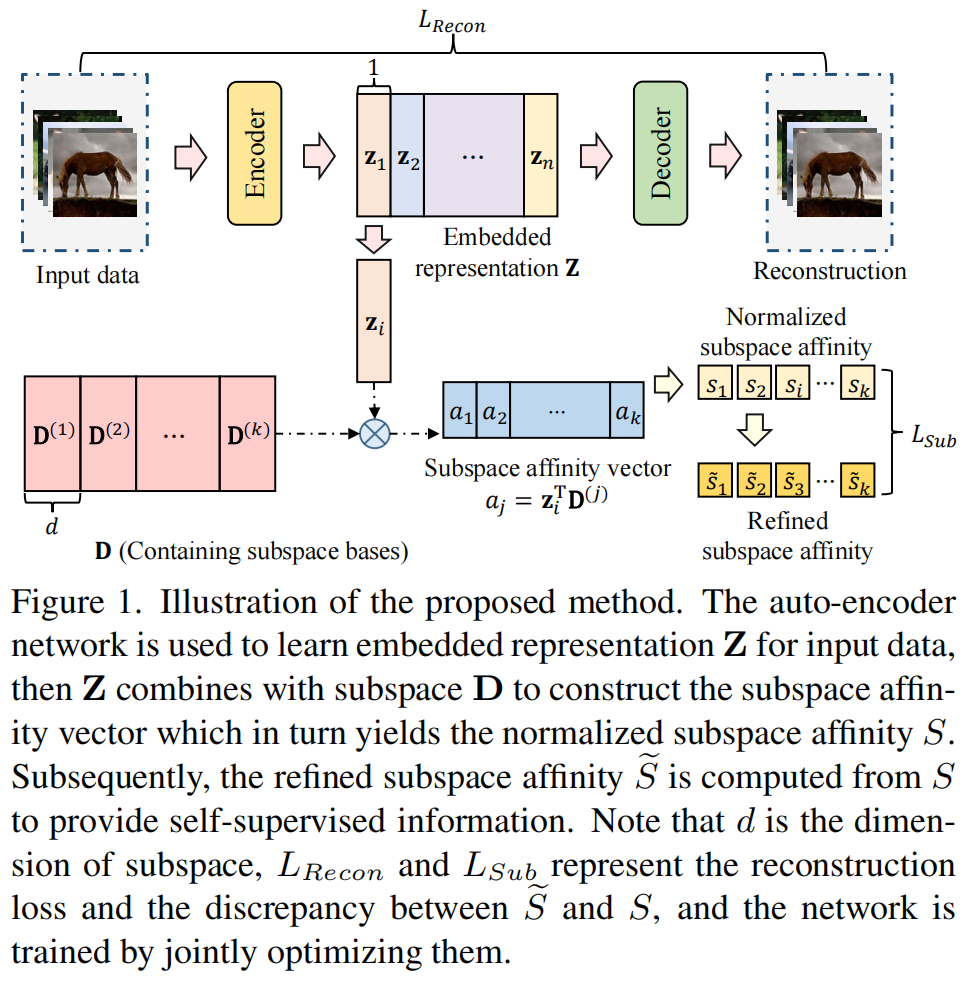
在本节中,我们将从先验知识的角度来回顾现有的深度聚类方法。先验情况如图1所示,方法分类总结在表2中。
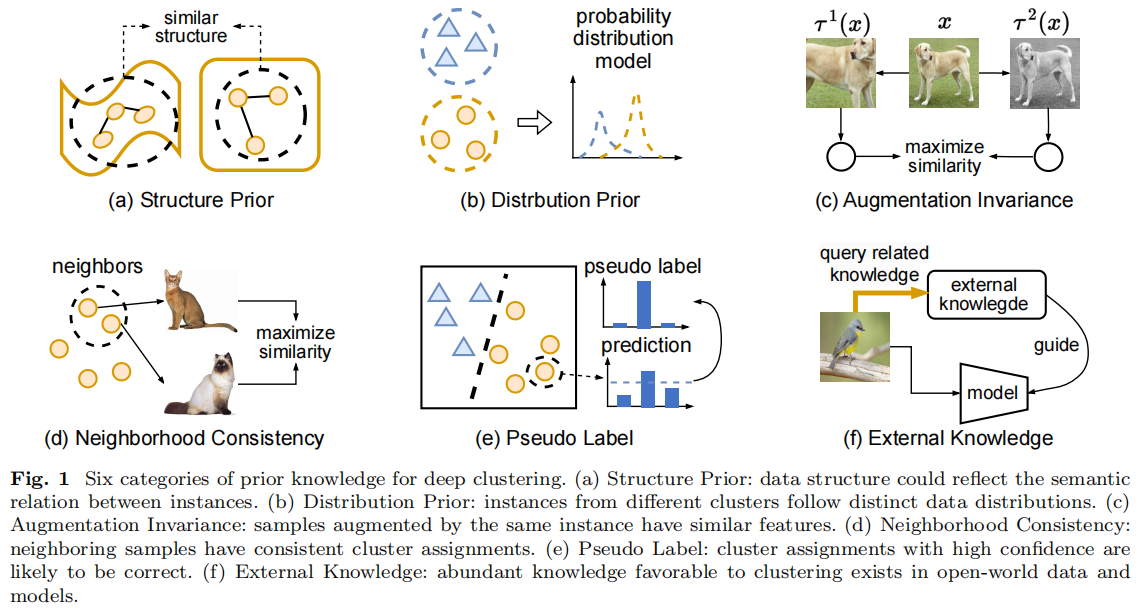
图1.深度聚类的6类先验知识。(a)结构先验:数据结构可以反映实例之间的语义关系。(b)分布先验:来自不同集群的实例遵循不同的数据分布。(c)增强不变性:由相同实例增强的样本具有相似的特征。(d)邻域一致性:相邻的样本具有一致的聚类分配。(e)伪标签:具有高可信度的聚类分配很可能是正确的。(f)外部知识:在开放世界的数据和模型中存在大量有利于聚类的知识。
表2 从先验知识的角度总结了深度聚类方法。
| 先验知识 | 方法 | 主要贡献 | |
|---|---|---|---|
| 结构先验 | 固有的数据结构反映了语义关系 | ABDC (2013) | 以EM的方式优化特征和聚类分配 |
| DEN (2014),SpectralNet (2018) | 将光谱聚类从浅层扩展到深层 | ||
| PARTY (2016) | 引入了从子空间学习到深度聚类的稀疏性先验 | ||
| JULE (2016) | 将聚集层从浅层扩展到深层 | ||
| DCC (2018) | 提出了关系匹配来实现非参数深度聚类 | ||
| 分布先验 | 不同语义的实例遵循不同的数据分布 | VaDE (2016) | 利用高斯混合模型学习不同的簇分布 |
| ClusterGAN (2019),DCGAN (2015) | 使用GAN隐式地学习集群分布 | ||
| 增强不变性 | 实例特征对数据增强不变 | IMSAT (2017) | 提出了成对增广样本之间的不变性 |
| IIC (2019),Completer (2021) | 提出了关于增强不变性的互信息框架 | ||
| 集群分配对数据增强是不变的 | PICA (2020) | 探索增强样本的聚类分配之间的不变性 | |
| CC (2021),DRC (2020) | 同时探索在实例级别和集群级别上的增强不变性 | ||
| TCC (2021) | 利用集群语义和实例组合的统一表示 | ||
| 邻域一致性 | 相邻的实例具有相似的语义 | SCAN (2020) | 在相邻实例之间强加一致的集群分配 |
| NNM (2021) | 在邻居之间执行集群级的对比学习 | ||
| GCC (2021) | 在邻居之间执行实例级和集群级的对比学习 | ||
| 伪标签 | 具有高置信度的聚类分配是可靠的 | DEC (2016) | 通过锐化构造目标集群分布 |
| DeepCluster (2018) | 使用K-means生成伪标签 | ||
| SCAN (2020) | 选择高置信度的预测,用强增强样本来微调模型 | ||
| SPICE (2022) | 利用原型选择伪标签,采用半监督学习的方法对模型进行微调 | ||
| TCL (2022) | 在对比学习中使用伪标签来减少假负对 | ||
| ProPos (2022) | 使用K-means中的伪标签来增加集群的紧凑性 | ||
| 外部知识 | 在开放的世界中存在着丰富的集群有利知识 | SIC (2023) | 从预先训练过的视觉语言模型的文本空间中生成图像伪标签 |
| TAC (2023b) | 构建更有区别的文本,并进行跨模态蒸馏来改进聚类 |
3.1 结构先验
3.2 分配先验
3.3 增强不变性
3.4 邻域一致性
3.5 伪标签
3.6 外部知识
4 实验
在本节中,我们将介绍对深度聚类的评估。简单地说,我们首先介绍评估指标和通用基准。然后对现有的深度聚类方法的结果进行了分析。
4.1 评价指标
对于聚类评估,通常使用三个度量标准来度量预测的聚类分配\(\tilde{y}\)如何与 ground-truth标签\(y\)相匹配,包括准确性(ACC)、标准化互信息(NMI)和调整兰德系数(ARI)。指标值越高,对应的聚类性能越好。这三个指标的定义如下:
- ACC(Amig´o et al, 2009)表示聚类预测的正确率:
\[\mathrm{ACC}={\frac{1}{N}}\sum_{i=1}^{N}\mathrm{1}\{y_{i}=\tilde{y}_{i}\},\]
- NMI(McDaid et al,2011)量化了预测标签\(\tilde{Y}\)和 ground-truth标签\(Y\)之间的互信息:
\[\mathrm{NMI}={\frac{I(\bar{\bf Y};{\bf Y})}{\frac{1}{2}[H(\bar{\bf Y})+H({\bf Y})]}},\]
其中H (Y)表示Y的熵,\(I(\bar{\bf Y};{\bf Y})\)表示\(\tilde{Y}\)和\(Y\)之间的互信息。
- ARI(Hubert and Arabie,1985)是兰德系数(RI,rand index)的归一化,它计算同一集群和不同集群中的实例对的数量:
\[\mathrm{RI}={\frac{\mathrm{TP}+\mathrm{TN}}{\mathrm{C}_{N}^{2}}},\]
其中,TP和TN为真正对和真负对的个数,\(C^2_N\)为可能的实例对的个数。ARI是通过添加以下规范化来计算出来的: \[\mathrm{ARI}={\frac{\mathrm{RI}-\mathbb{E}(\mathrm{RI})}{\operatorname*{max}(\mathrm{RI})-\mathbb{R}(\mathrm{RI})}},\]
4.2 数据集
在早期阶段,深度聚类方法在相对较小的低维数据集上进行评估(例如COIL-20(Nene等,1996),YaleB(Georghiades等,2001))。近年来,随着深度聚类方法的快速发展,在更复杂和更具有挑战性的数据集上评估聚类性能变得越来越流行。有五个被广泛使用的基准数据集:
- CIFAR-10 (Krizhevsky et al, 2009) 由来自10个不同类别的6万张彩色图像组成,包括飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船和卡车。
- CIFAR-100 (Krizhevsky et al, 2009) 包含100个类,分为20个超类。每个图像都带有一个“细”类标签和一个“粗”超类标签。
- STL-10 (Coates et al, 2011) 包含来自10个对象类的13000张标记图像。此外,它还提供了10万张未标记图像用于自监督学习,以提高聚类性能。
- ImageNet-10 (Chang et al, 2017) 是ImageNet数据集的一个子集(Deng等人,2009)。它包含10个类,每个类都有1300张高分辨率图像。
- ImageNet-Dog (Chang et al, 2017) 是ImageNet的另一个子集。它由属于15个犬种的图像组成,适用于细粒度的聚类任务。
除此之外,最近的一些工作采用了两个更具挑战性的大规模数据集,Tiny-ImageNet (Le and Yang, 2015)和ImageNet-1K (Deng et al, 2009),来评估其有效性和效率。表3总结了对这些数据集的简要描述。
4.3 性能比较
在5个广泛使用的数据集上的聚类性能如表4所示。
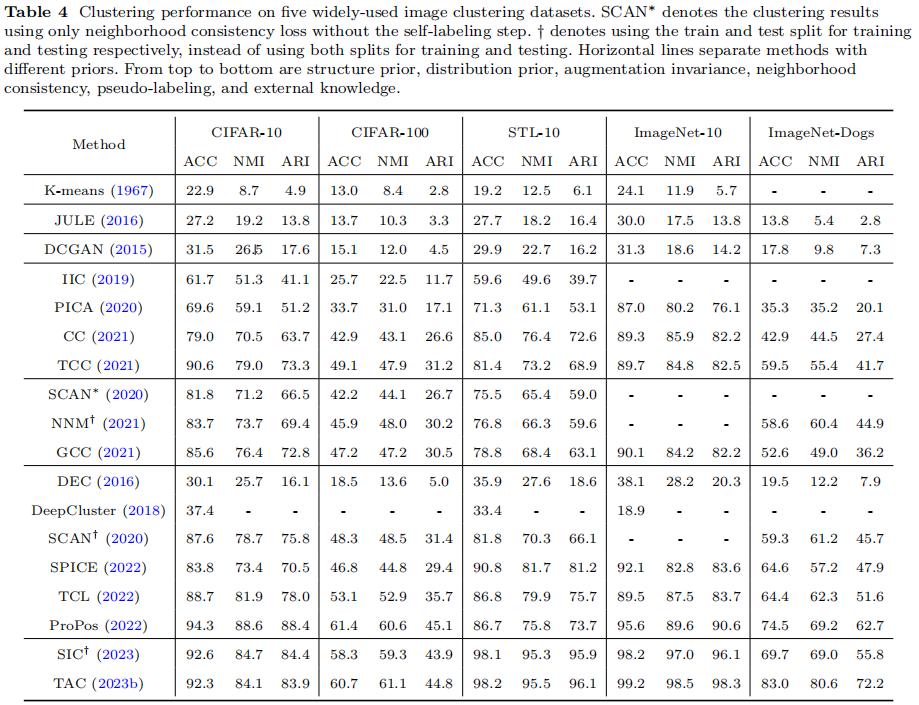
由于深度神经网络的特征提取能力,早期基于结构和分布先验的深度聚类方法获得了比经典的K-means方法更好的性能。然后,一系列的对比聚类方法通过数据增强引入额外的先验,显著提高了性能。在此之后,更先进的方法通过进一步考虑邻域一致性(GCC与CC相比),并使用伪标签(SCAN与SCAN∗相比)来提高性能。值得注意的是,不同先验的性能收益是独立的。例如,ProPos通过分别利用增强不变性和伪标记先验,显著优于DEC和CC。最近,基于外部知识的方法取得了最先进的性能,证明了这是一种新的深度聚类范式的广阔前景。此外,当类别数量不断增长(从CIFAR-10到CIFAR-100)或语义变得更加复杂(从CIFAR-10到ImageNet-Dogs)时,聚类就变得更具挑战性。这些结果表明,更具挑战性的数据集,如完整的ImageNet-1K,有望在未来的工作中进行基准测试。
5 在Vicinagearth中的应用
在本节中,我们将探讨在Vicinagearth领域内深度聚类的一些典型应用,这是一个由“Vicinage”和“Earth”融合而成的术语。Vicinagearth代表了从海平面以下1000米(阳光停止穿透的深度)到海拔10000米(商用飞机的典型巡航高度)的关键空间高度。这个区域非常重要,因为它包括人类活动的核心区域,包括居住和生产地区。近年来,深度聚类已成为邻近地球内不可或缺的分析工具,有助于揭示邻近空间内数据的复杂模式和结构。深度聚类在该区域的多种应用包括异常检测、环境监测、社区检测、人员再识别等。
异常检测,也被称为异常值检测(Comaniciu和Meer,2002)或新奇检测(Esteretal.,1996b),试图识别异常实例或模式。在Vicinagearth的背景下,深度聚类被证明是为了分析从不同来源获得的传感器数据,如水下监测系统、空中传感器或地面传感器(
Chatterjee和Ahmed,2022)。通过对传感器数据的模式和典型行为的分析,系统能够检测异常,这些异常可能是安全威胁或不规则活动的信号。
环境监测包括分析从环境传感器收集的数据(Xia和Vlajic,2007),如监测空气质量、水条件和地质因素。其主要目标是确保生态系统的健康(Wu
et
al,2016),并发现潜在的环境威胁,如污染事件或自然灾害。深度聚类技术在对相似的环境模式进行分组方面起着至关重要的作用,有助于对异常情况的识别。这一应用程序有助于实时环境监测(Kumar
et
al,2012),提高了及时应对环境挑战的能力。
社区检测(Fortunato,2010;Jin等人,2021年)涉及到评估节点组是如何聚集或分割的,以及它们在网络中加强或分裂的趋势。在Vicinagearth的背景下,这项技术被用于识别密切相互作用或共享相似生态位的物种群(默多克和耶格尔,2011)。深度聚类在复杂生态网络的分析中起着关键作用(Montoya
et
al,2006),有助于更深入地了解生态群落及其动态。
人的再识别(Wu等人,2019;Ye等人,2021)是一项关键的任务,涉及到识别和匹配不同摄像机视图中的个体(Yang
et
al,2022a)。这项技术在公共安全和执法行动中发挥着重要作用,因为它有助于监测人口密集的地区,以将潜在的威胁或主题列入观察名单。深度聚类算法的集成显著提高了人的再识别系统的可伸缩性和效率(Yan
et
al,2023)。深度聚类有效地管理大量和动态变化的人群带来的复杂性。此外,深度聚类技术的适应性扩大了其应用范围,包括监测自然栖息地和跟踪在不同的和不受控制的环境中的野生动物。
6 未来的挑战
虽然现有的工作取得了显著的性能,但一些实际的挑战和新出现的要求尚未得到充分解决。在本节中,我们将深入探讨现代深度集群的一些未来方向。
6.1 细粒度聚类
细粒度聚类的目的是识别数据中细微和复杂的变化,这在像识别生物亚种这样的研究中特别有利(Li et al,2023c,d)。主要的挑战是,细粒度的类表现出高度的相似性,其区别通常在于颜色、标记、形状或其他微妙的特征。在这种情况下,传统的粗粒度集群先验经常被证明是不够的。例如,在增强不变性之前的颜色和形状增强会变得无效。最近,C3-GAN(Kim和Ha,2021)在对抗性训练中使用对比学习来生成逼真的图像,能够细致入微地捕获细粒度的细节,并确保集群之间的可分离性。
6.2 非参数聚类
许多集群方法通常需要预定义的和固定数量的集群。然而,真实世界的数据集经常对未知的集群数量的挑战,反映了更接近现实的情况。只有少数作品 (Chen,2015; Shah and Koltun, 2018; Zhao et al, 2019;Wang et al, 2021) 一直致力于解决这个问题。这些方法通常依赖于计算全局相似度,并引入巨大的计算成本,特别是在大规模数据集中。因此,有效地确定簇数C的最优值仍然是一个开放的挑战,通常涉及到人类先验的合并。在现有的工作中,DeepDPM引入了狄利克雷过程高斯混合模型(DPGMM,Dirichlet Process Gaussian Mixture Models)(Antoniak,1974),利用狄利克雷过程作为混合组件的先验分布。DeepDPM通过Metropolis Hastings框架(Hastings, 1970)指导下的拆分和合并操作动态调整集群C的数量。
6.3 公平聚类
用不同的获取方法从不同的来源收集真实世界的数据集,可以增强机器学习模型的泛化性。然而,这些数据集经常表现出固有的偏见,特别是在敏感的属性上,如性别、种族和民族。这些偏差将导致个人和少数群体之间的差异,导致聚类划分偏离数据的潜在目标特征。在公正和公平的分析至关重要的应用程序中,如就业、医疗保健和教育,追求公平尤其相关。为了解决这一挑战,公平聚类试图减轻这些偏见的影响,因为每个样本的偏见属性。
为了解决这一艰巨的任务,Chierichetti
et
al首先引入了一种称为球流分解的数据预处理方法。最近的研究进展通过对抗性训练(Li等人,2020年)和互信息最大化(Zeng等人,2023年)在大规模数据上解决了这一问题。值得注意的是,Zeng等人设计了一种新的度量方法,从信息论的角度来评估聚类质量和公平性。尽管有这些发展,但仍有改进的空间,建立更好的评价指标是本研究的一个持续领域。
6.4 多视图聚类
多视图数据(Xu et
al,2013;Liu等人,2019b)在现实世界中很常见,即信息从各种传感器捕获或从多个角度观察。这些数据本身就很丰富,提供了多样化而又一致的信息。例如,RGB视图将提供颜色细节,而深度视图将显示空间信息,这表示视图的互补方面。同时,存在一种视图一致性级别,因为同一对象在不同的视图之间具有共同的属性。为了处理多视图数据,提出了多视图聚类(Deng
et al,2015;Liu et
al,2019a)来利用互补和一致的特征。其目标是整合来自所有视图的信息,以产生一个统一的和深刻的聚类结果。
近年来,几种深度学习方法(Andrew等,2013;Wang等,2016;赵等,2016;Peng等人,2019)旨在应对这一挑战。二进制多视图聚类Zhang等人(2018)同时细化了二进制聚类结构和离散数据表示,确保了内聚聚类。为了追求视图的一致性,Lin等人(2021,2022)最大化了跨视图的互信息,从而对齐了共同的属性。SURE(Yang
et
al,2022b)旨在通过利用鲁棒对比损失来加强视图之间共享特征的一致性。最近,Li等人(2023a)执行了约束对比损失,以在集群水平上保持视图互补。这些创新的方法表明了在多视图分析领域取得的重大进展,在那里,聚类在加强对多视图数据的协同利用方面继续发挥关键作用。
7 结论
深度聚类或无监督学习的关键是寻求有效的监督来指导表示学习。与传统的网络结构或数据类型的分类法不同,本调查从先验知识的角度提供了一个全面的回顾。随着聚类技术的发展,出现了一种明显的趋势,从探索数据本身内部的先验转向诸如自然语言指导等外部知识。探索ChatGPT或GPT-4V(ision)等外部预训练模型可能成为一个很有前途的途径。这项调查可能提供了一些有价值的见解,并激发了对深度聚类的进一步探索和进步。