AdaIFL:Adaptive Image Forgery Localization via a Dynamic and Importance-aware Transformer Network
AdaIFL: Adaptive Image Forgery Localization via a Dynamic and Importance-aware Transformer Network
摘要
图像处理和操作技术的快速发展给多媒体取证,特别是图像伪造定位(IFL)带来了前所未有的挑战。
本文解决了IFL中的两个关键挑战:
(1)各种伪造技术留下了明显的法医痕迹。然而,现有的模型忽略了伪造模式之间的差异。伪造技术的多样性使得单一的静态检测方法和网络结构具有普遍适用的挑战性。为了解决这个问题,我们提出了AdaIFL,这是一个动态的IFL框架,它为不同的网络组件定制不同的专家组,构建多个不同的特征子空间。通过利用自适应激活的专家网络,AdaIFL可以捕获与伪造模式相关的判别特征,增强了模型的泛化能力。
(2)许多法医鉴定的痕迹和手工艺品都位于伪造区域的边界上。现有的模型要么忽略了区分信息的差异,要么利用边缘监督损失来迫使模型关注区域边界。这种硬约束的方法容易产生注意力偏差,导致模型对图像边缘过于敏感,或无法精细地捕捉到所有的法医痕迹。在本文中,我们提出了一种特征重要性感知注意力,一种灵活的方法,自适应地感知不同区域的重要性,并将区域特征聚集成可变长度的标记,将模型的注意力导向更有区别和信息的区域。
在基准数据集上的大量实验表明,AdaIFL优于最先进的图像伪造定位方法。我们的代码可以在https://github.com/LMIAPC/AdaIFL上找到。
关键词:图像伪造定位·动态网络架构·特征重要性意识注意
1介绍
随着图像编辑和处理技术的快速发展,人们更容易创建真实的伪造图像,这可能会被滥用来传播恶意信息,对媒体内容[31]的安全性构成重大挑战。因此,开发一种有效的对伪造图像的识别和定位方法具有重要意义。
近年来,研究人员提出了许多基于深度学习的方法[14,25,37,39,43]来检测和定位伪造域,取得了重大进展。然而,这些方法在现实生活中仍然不能取得令人满意的结果,主要面临两个挑战:
(1)制造商拥有各种操作图像的技术和工具,包括对象插入、删除、克隆和失真,每一种都留下不同的伪影和法医痕迹。如图1
(a)所示,现有的方法在处理具有不同伪造线索和模式的伪造图像时缺乏适应性。
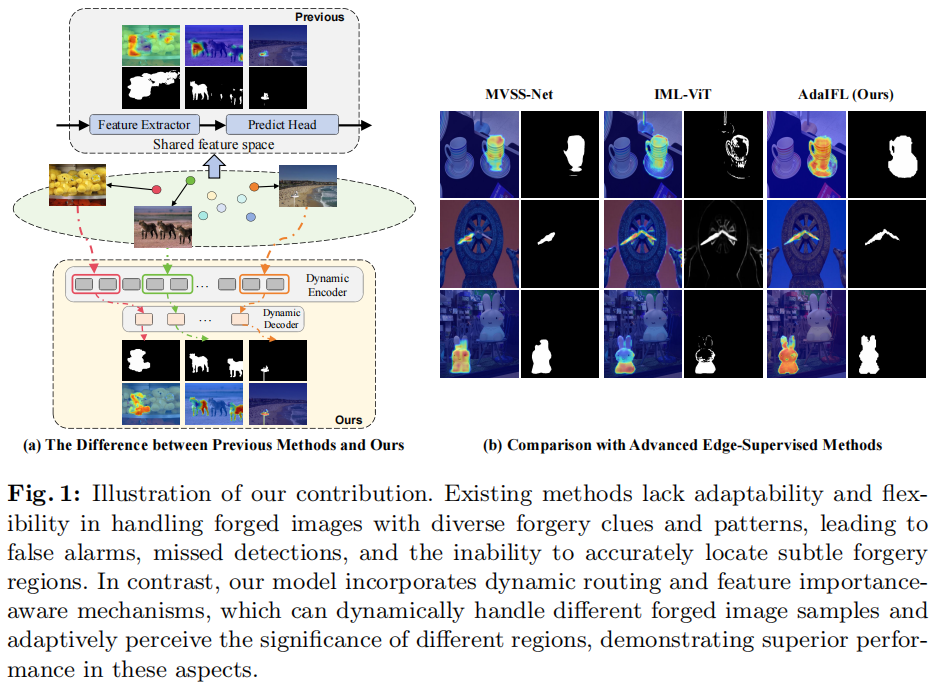
图1:我们的贡献的说明。现有的方法在处理具有不同伪造线索和模式的伪造图像时缺乏适应性和灵活性,导致错误警报、漏检,无法准确定位细微的伪造区域。相比之下,我们的模型结合了动态路由和特征输入感知机制,可以动态地处理不同的伪造图像样本,并自适应地感知不同区域的重要性,在这些方面表现出优越的性能。
(2)通过图像操作产生的人工制品和法医痕迹主要位于伪造区域的边界上。这些痕迹是微妙而微妙的,涉及到光线、纹理或去除小物体的微小变化。由于稀疏的特性、有限的上下文信息和易受损坏的漏洞,这给伪造定位带来了重大挑战。为了捕获微妙的伪影和法医痕迹,一些方法,如IML-ViT
[21]和MVSS-Net
[5],使用边缘监督损失来迫使模型集中于区域边界。然而,如图1
(b)所示,这种硬约束的方法很容易导致注意力偏差,导致模型对图像边缘过于敏感,或无法精细地捕捉到所有的法医痕迹。这就导致了诸如错误警报、检测遗漏以及无法准确定位具有尖锐边界的伪造区域等问题。因此,为了防止模型过度依赖边界区域,忽视其他关键特征,必须实现更加灵活和适当的平衡。
在本文中,我们提出了一种新的动态和重要性感知的变压器网络AdaIFL。为了解决在处理伪造样本时适应性不足的挑战,我们提出了一个新的动态框架,将动态路由机制的概念合并到IFL中。我们的框架包括一个基于transformer的动态编码器和一个轻量级的动态解码器。我们在不同的网络组件中定制不同的专家组,构建多个不同的特征子空间。通过门控网络的路由,伪造的图像样本可以选择性地激活网络的不同部分,从而在各自的特征子空间中挖掘出与伪造模式相关的鉴别特征。这大大提高了模型的泛化能力。
为了避免模型对伪造区域周围的边界伪影的过度敏感或忽视,我们提出了特征重要性感知注意(FIA,feature
importance-aware
attention),这是一种灵活的方法,可以自适应地感知不同区域的重要性。其中一个关键组件是自适应token聚合器(ATA,adaptive
token
aggregator),它由三个部分组成:重要性感知区域分区、聚合规模分配和自适应token聚合。ATA的目标是基于区域特征的鉴别信息,将区域特征动态聚合为可变长度tokens,为不同尺度和形状的伪造区域建模。具体来说,我们设计了一个评分网络来量化每个图像特征的重要性。根据重要性评分,将整个图像区域划分为多个子区域。然后利用一种简单而有效的自适应机制对判别信息进行评估,从而确定每个子区域的聚集规模。特别是,较小的聚合尺度被分配为具有更多区别区域的区域生成更多的特征标记,如图像处理边界。最后,利用聚类算法在聚合尺度的引导下对token进行合并,得到了紧凑而又具有高度判别性的token表示。FIA将模型的注意力导向更有鉴别力的区域,显著提高了模型准确定位各种伪造区域的能力。
我们的主要贡献总结如下:
- 我们提出了AdaIFL,一个新的动态和重要性感知的IFL框架。据我们所知,这是第一次将动态路由机制引入IFL,使其在该领域的开创性贡献。
- 我们提出了一种特征重要性感知注意,即自适应地感知不同区域的重要性,提高了模型准确定位不同伪造区域的能力。
- 我们在几个基准上进行了广泛的实验,并证明了AdaIFL在定性和定量上优于现有的最先进的方法。
2相关工作
3方法
3.1框架概述
在本文中,我们提出了AdaIFL,一个动态的和重要性感知的图像伪造定位框架。如图2所示,AdaIFL将动态路由机制引入到IFL中。
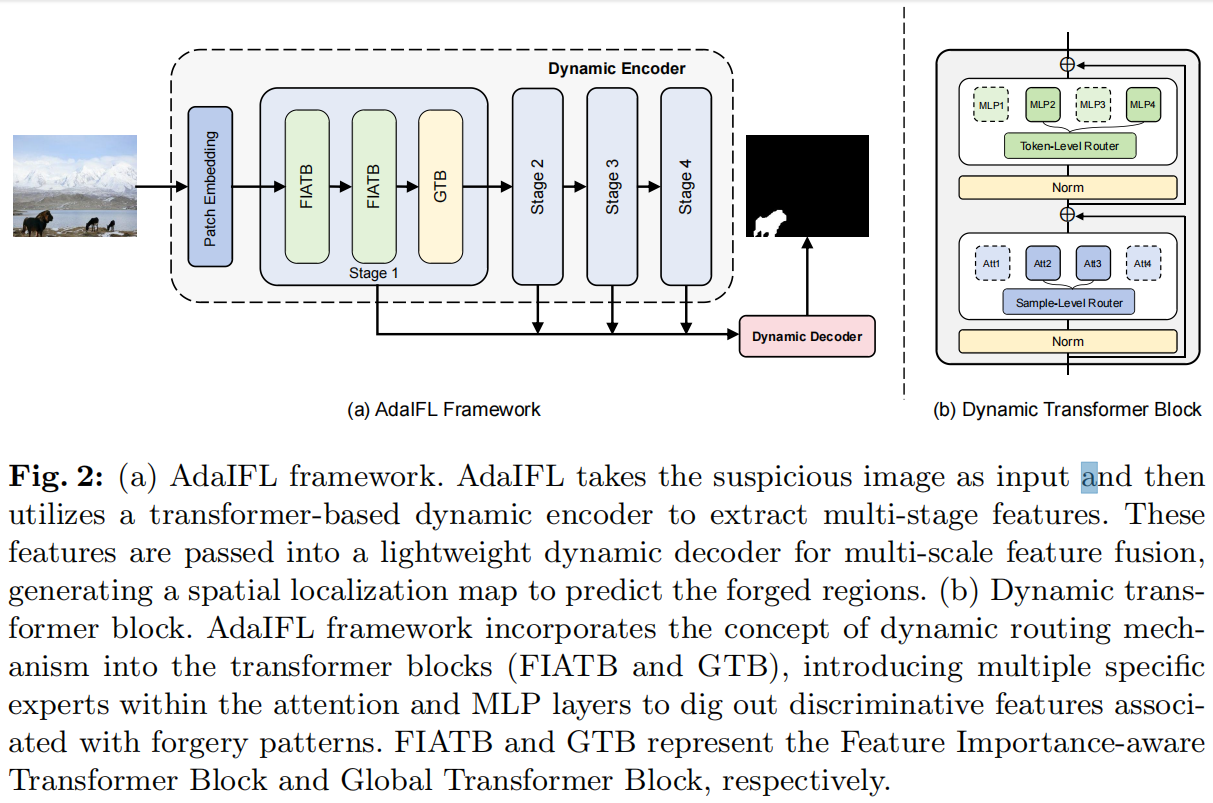
图2: (a) AdaIFL框架。AdaIFL以可疑的图像作为输入,然后利用一个基于transformer的动态编码器来提取多级特征。这些特征被传递到一个轻量级的动态解码器中,进行多尺度的特征融合,生成一个空间定位图来预测伪造的区域。(b)动态transformer块。AdaIFL框架将动态路由机制的概念整合到transformer块(FIATB和GTB)中,在注意力层和MLP层中引入多个特定的专家网络,以挖掘出与伪造模式相关的区别特征。FIATB和GTB分别表示特征重要性感知的transformer块和全局transformer块。
它为不同的网络组件定制了不同的专家网络,构建了多个特征子空间来专门学习不同的伪造模式。具体来说,该框架由一个基于transformer的动态编码器和一个轻量级的动态解码器组成。该编码器包括四个阶段,每个阶段包括两个堆叠的特征重要性感知transformer块(FIATB)和一个全局transformer块(GTB)。此外,我们提出了一个动态解码器来融合多阶段特征,并预测伪造区域的空间定位图。其详细结构如图4 (a)所示,包括多尺度特征融合(MSFF)和动态解码两个过程。在下面的章节中,我们将详细介绍AdaIFL的几个关键组件。
3.2动态transformer组件
准备工作:专家网络的混合。
专家网络的混合层(MoE,Mixture
of Experts)包括一组专家网络,记为\(E_{1},E_{2},\cdot\cdot,E_{N}\),以及记为\({\mathcal{G}}\)的路由网络。在网络的不同组件中,每个专家网络可以实现为注意层、MLP层或卷积层。路由网络\({\mathcal{G}}\)负责确定利用每个专家网络\(E_i\)的概率,并选择前k个专家作为最终输出的贡献者。\({\mathcal{G}}\)可以根据各种形式选择专家,如单个token、输入样本或任务嵌入:
\[\displaystyle{\cal
G}=\left\{\begin{array}{l l}G_{t o k e
n}\left(x_{i}\right),&\mathrm{Token}\mathrm{-}\mathrm{level}\\ G_{s
a m p l e}\left(X\right),&\mathrm{Sample}\mathrm{-}\mathrm{level}\\
G_{t a s k}\left(e m b e d(i d_{t a s
k})\right),&\mathrm{Task}\mathrm{-}\mathrm{level}\end{array}\right.\]
其中,\(G\)定义了门决策的特定路由策略,\(\textstyle
X=\{x_{i}\}_{i=1}^{L}\)是当前样本中所有token的序列。专家网络混合层的最终输出是来自选定的专家网络\(E\subset\{E_{1},E_{2}\cdot\cdot\cdot
E_{N}\}\): \[y=\sum_{i\in E}{\cal
G}\left(x\right)\cdot E_{i}\left(x\right)\]
专家网络混合层的动态transformer组件。
我们进一步将专家网络混合层的动态路由概念纳入到transformer架构中。具体来说,我们向多个特定的专家网络引入注意力机制和MLP层。我们鼓励这些专家网路探索与伪造模式相关的独特的工件和法医痕迹,以增强网络的泛化能力。
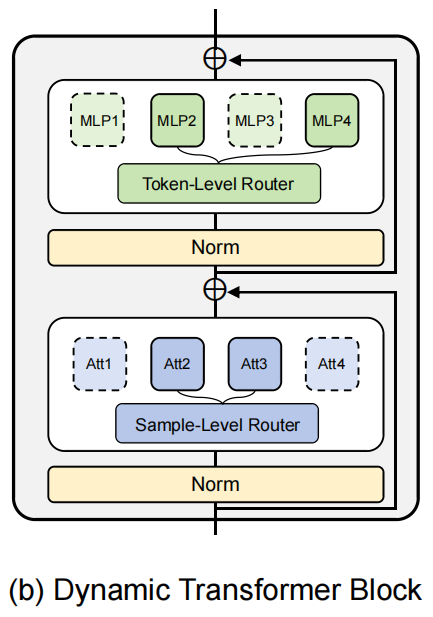
如图2 (b)所示,我们用一组并行注意的专家网路和一组 sample-level的路由器替换原来的注意层,用一组并行MLP专家和一组token级路由器替换原来的MLP层。在形式上,AdaIFL编码器的transformer块可以表述为: \[\begin{array}{c}{X_{l}^{\prime}=\mathrm{MoE}\mathrm{-Att}\left(\mathrm{LN}\left(X_{l-1}\right)\right)+X_{l-1}}\\ X_{l}=\mathrm{MoE}\mathrm{-FFN}\left(\mathrm{LN}\left(X_{l}^{\prime}\right)\right)+X_{l}^{\prime}\end{array}\] 其中,\(\mathrm{MoE}-\mathrm{Att}(X)=\sum_{i\in E_{\mathrm{Att}}}G_{s a m p l e}^{i}\left(X\right)\cdot E_{\mathrm{Att}}^{i}\left(X\right)\),\(\mathrm{MoE}-{\mathsf {FFN}}(x)=\sum_{i\in E_{MLP}}G_{t o k e n}^{i}\left(x\right)\cdot E_{\mathrm{MLP}}^{i}\left(x\right)\),LN表示图层的归一化。值得注意的是,我们在FIATB中对MoE采用了特征重要性感知的注意力,详见Sec3.3。在GTB中,使用了标准的全局自注意机制。
3.3特征重要性感知的注意力
为了避免模型对操纵边界区域的过度敏感或忽视,我们提出了一种特征重要性感知的注意力,即自适应地感知不同区域的重要性,并将区域特征聚合成可变token,对不同尺度、形状和内容的伪造区域进行建模。整体结构如图3所示。
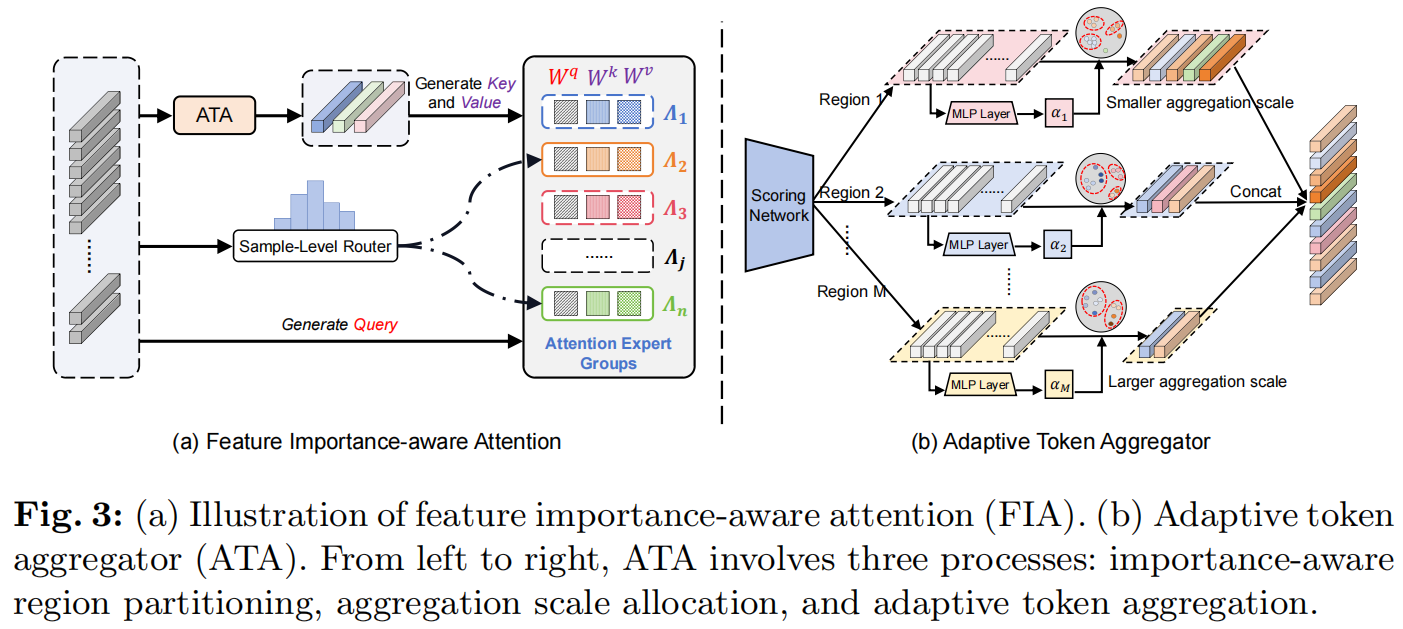
图3: (a)特征重要性感知的注意力(FIA,feature importance-aware attention)例证。(b)自适应token聚合器(ATA,Adaptive token aggregator)。从左到右,ATA涉及三个过程:重要性感知区域分区、聚合规模分配和自适应token聚合。
重要性感知的区域分区。
我们设计了一个评分网络来评估区域特征对IFL任务的重要性,记为\(f_s\),它是一个由两个MLP层组成的轻量级模块。具体来说,给定一个输入特征\(X\in\mathbb{R}^{N\times d}\),其中d表示每个特征标记的维数,N表示特征标记的数量。\(f_s\)用于量化每个特征标记\(x_i\)的重要性。 \[s_{i}=f_{s}(x_{i}),\,i=1,\cdot\cdot\cdot,\,N\] 此外,根据重要性分数对特征token进行排序,得到一组特征token及其各自的分数,表示为\(\left\{x_{i}^{\prime}\right\}_{i=1}^{N}\)和\(\left\{s_{i}^{\prime}\right\}_{i=1}^{N}\)。此外,根据token的排序列表,将整个图像区域划分为m个不规则子区域\(\left\{R_{i}\right\}_{i=1}^{m}\),每个子区域包含\(N_{R_i}\)标记。
聚合规模分配
基于每个区域对伪造定位的重要性,动态调整聚合尺度,对不同尺度和形状的伪造区域进行建模。为了实现这一点,我们使用了一个简单的MLP层来将区域重要性的分布转换为信息密度因子。这些因素被用来评估每个图像区域的鉴别信息,表示为\(\rho=\left\{\rho_{1},\ \rho_{2},\ \ldots,\rho_{m}\right\}\)。然后应用Softmax函数对密度因子进行归一化,并利用它们生成不同区域的聚集尺度。这可以表述为: \[\hat{\rho}_{i}=\frac{e^{\rho_{i}}}{\sum_{i=1}^{m}e^{\rho_{i}}},i=1,\cdot\cdot,m\] , \[c_{i}=N_{\lambda}\hat{\rho}_{i},\alpha_{i}=\frac{N_{R_{i}}}{c_{i}}\]
式中,\(N_{\lambda}\)为预定义的token总数\((N_{\lambda}\ll N)\),\(c_i\)表示分配给子区域\(R_i\)的token数,\(\alpha_{i}\)表示\(R_i\)的聚集规模。这种自适应方法将更小的聚集规模分配到更有区别的区域,产生更多的特征token。相反,其他区域使用更大的规模来进行更粗的token聚合。
自适应token聚合ATA
在分配了相应的聚合规模之后,我们需要进一步考虑如何聚合token。直观地说,聚合具有相似语义信息的token可以避免对冗余特征的过度关注和对微妙特征的关注不足。受[7,41]的启发,我们使用聚类算法进行token聚类和合并,从而得到更准确和紧凑的token表示。具体来说,我们使用DPC-KNN算法[7]来进行token聚类,这是一种基于密度峰值的k-最近邻聚类算法。在此算法的基础上,根据每个区域的特征token的相似性划分为\(c_i\)不同的聚类。在聚合过程中,将重要性分数作为权重分配给同一集群内的token,强调不同token的重要性。因此,可以获得每个集群的token表示: \[\hat{x}_{i}=\frac{\sum_{j\in c_{i}}e^{s_{j}}x_{j}}{\sum_{j\in c_{i}}e^{s_{j}}}\] 最后,将来自所有区域的聚合token连接起来,得到最终的token表示\(\hat{X}\in\mathbb{R}^{N_{\lambda}\times d}\)。
特征重要性感知的注意力FIA
我们提出了基于自适应token聚合器的特征重要性感知注意力(FIA),以避免过度关注冗余特征或忽略局部细节。具体来说,我们将原始特征token\(X\in\mathbb{R}^{N\times
d}\)投影为查询Q,将聚合token\(\hat{X}\in\mathbb{R}^{N_{\lambda}\times
d}\)投影为键K和值V。该流程的定义为: \[\begin{array}{l}{Q=X
W^{q},K=\hat{X}W^{k},V=\hat{X}W^{v}}\\
\mathrm{FIA}(Q,K,V)=\mathrm{Softmax}\left({\cfrac{Q
K^{\top}}{\sqrt{d}}}\right)V\end{array}\] 其中,\(W^{q},W^{k},W^{v}\in\mathbb{R}^{d\times
d}\)为可学习矩阵。
如图6所示,FIA将模型的注意力转向更区分的区域,提高了伪造定位的性能。
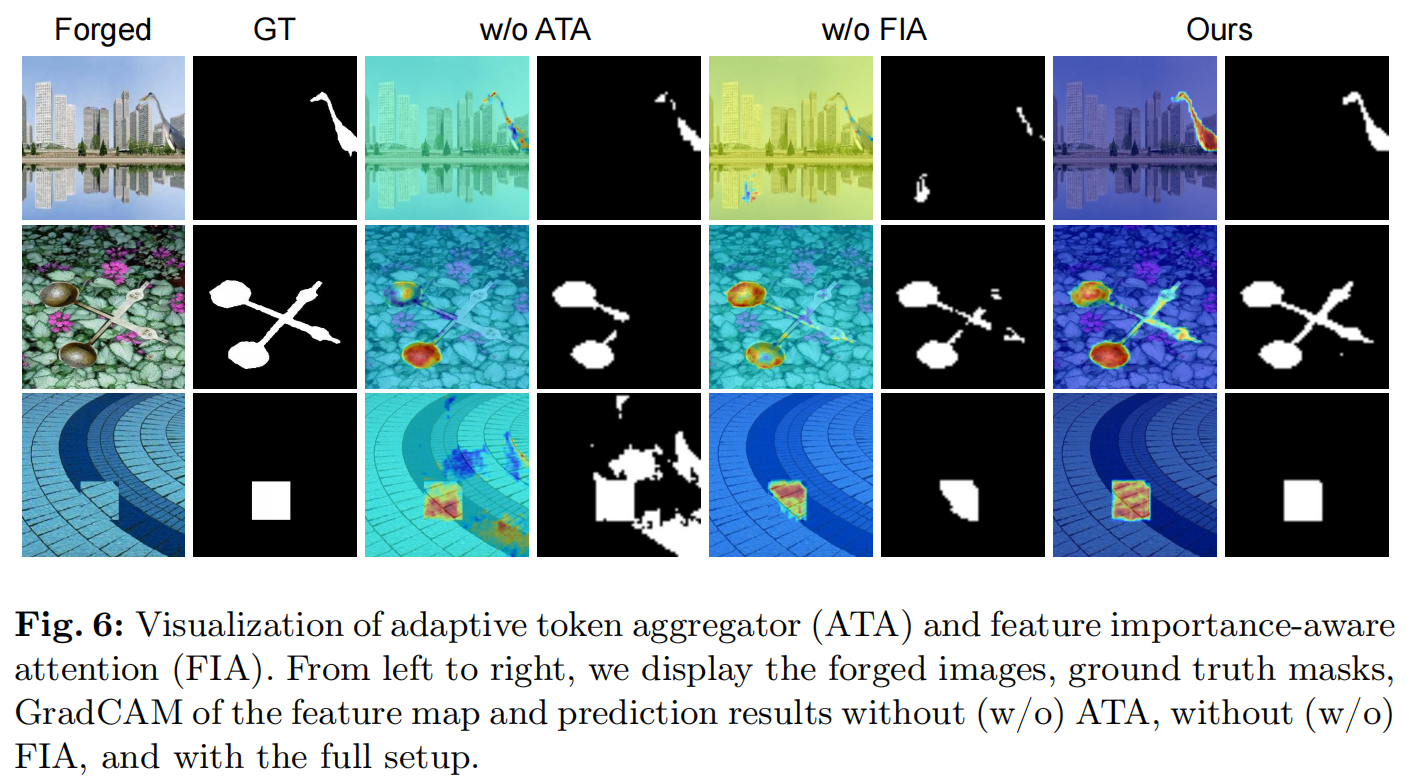
图6:自适应token聚合器(ATA)和特征重要性感知注意力(FIA)的可视化。从左到右,我们显示伪造的图像、ground-truth掩模、特征图的GradCAM和没有(w/o)ATA,没有(w/o)FIA和完整设置的预测结果。
这是由于有几个优点。
(1)区域划分机制限制了真实区域和伪造区域之间的相互作用,缓解了特征耦合问题。许多伪造技术旨在创建语义上一致的和感知上令人信服的篡改图像的视觉欺骗。因此,直接聚类[7,41]无意中导致了特征耦合。如图6所示,ATA的区域划分机制缓解了这个问题,减少了误报。
(2)自适应聚合机制可以根据不同区域的重要性动态调整聚合规模,使模型能够灵活地适应伪造区域的各种尺度和形状。
3.4动态解码器
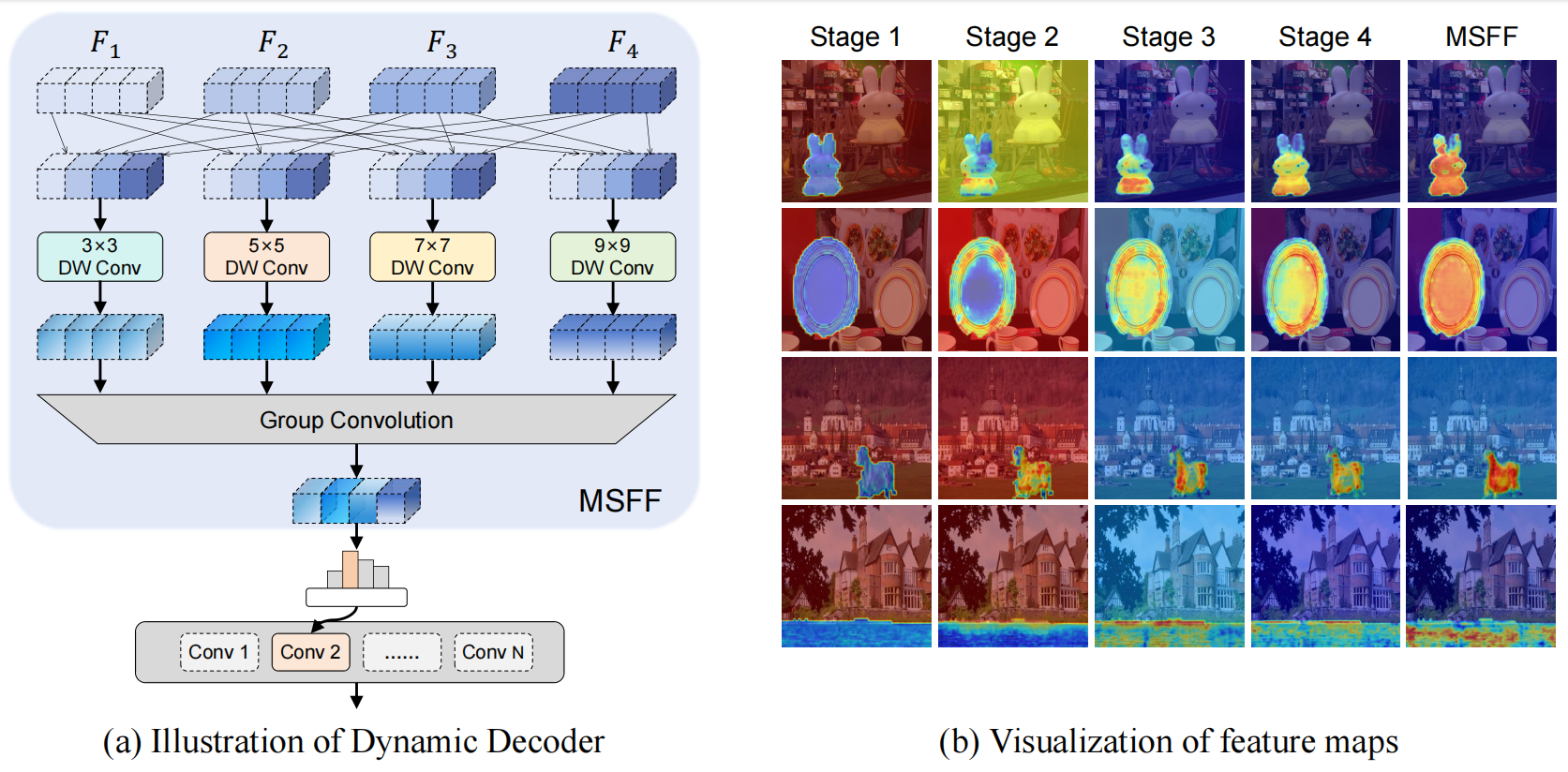

图4: (a)动态解码器示意图。它由多阶段特征融合(MSFF)和动态解码器组成。(b)从左到右是阶段1、阶段2、阶段3、阶段4和MSFF的输出特性映射的GradCAM。MSFF模块集成了多阶段的特性,提高了伪造定位的性能。
如图4
(a)所示,动态解码器由多阶段特征融合(MSFF)和动态解码两个过程组成,旨在融合多阶段特征,实现更好的定位性能。如图4
(b)所示,每个阶段都侧重于捕获不同级别的特征。因此,MSFF被提出充分利用特征在不同阶段的表达能力,并捕获更多的鉴别信息。
具体来说,MSFF利用从transformer的四个阶段中提取的特征图\(F_1\)、\(F_2\)、\(F_3\)和\(F_4\)作为输入,并沿着通道维度将每个特征图分成四个部分。然后,我们从每个特征图中选择一部分特征,并将它们连接起来,得到四个融合的特征。然后,利用不同核大小的深度可分离卷积来处理这四个融合特征,捕获多尺度特征。此外,利用群卷积[18]提取有价值的信息,并从融合的特征中过滤出冗余的特征表示。此外,利用群卷积[18]提取有价值的信息,并从融合的特征中过滤出冗余的特征表示。这一点可以表述如下:
\[\begin{array}{l}Z_{i}=\mathrm{Concat}\left(F_{1}\left[i\right],F_{2}\left[i\right],F_{3}\left[i\right],F_{4}\left[i\right]\right),Z_{i}^{'}=\mathrm{D
W}_{k_{i}\times k_{i}}{\left(Z_{i}\right)}\\
\hat{Z}=\mathrm{GC}\left(\mathrm{Concat}\left(Z_{1}^{'},\;Z_{2}^{'},\;Z_{3}^{'},\;Z_{4}^{'}\right)\right)\end{array}\]
其中,\(k_{i}\in\{3,5,7,9\}\),DW表示深度上可分离的卷积,GC表示群卷积。
最后,我们引入了一个动态解码模块来预测输入图像的伪造区域。它涉及一组并行预测头\(\{P_{i}\}_{i=1}^{n}\)和一个样本路由器。每个预测头\(P_i\)被实现为一个1x1的卷积,即\(P_{i}(\hat{Z})=W_{i}\hat{Z}\)。在样本路由器中,我们首先执行全局平均池化来生成全局嵌入\(\tau\)。然后,通过一个全连接层和sigmoid函数,即\(A
P\left(\hat{Z}\right)=\sigma\left(W_{a}\tau\right)\),计算每个头部的激活概率。动态解码器的最终输出是概率最高的前k个预测头的加权和:
\[Y=\sum_{A P_{i}\in\mathrm{top.k}}A
P_{i}({\hat{Z}})\cdot P_{i}({\hat{Z}})\]
3.5优化
为了提高模型在像素级检测伪造区域的准确性,我们利用了二进制交叉熵损失和dice损失[22]。 \[{\mathcal{L}}_{\mathrm{BCE}}\left(p,y\right)=\sum\left(-y_{i}\log p_{i}-\left(1-y_{i}\right)\log\left(1-p_{i}\right)\right)\] , \[\mathcal{L}_{\mathrm{Dice}}\left(p,y\right)=1-\frac{2\sum p_{i}\cdot y_{i}}{\sum p_{i}{}^{2}+\sum y_{i}{}^{2}}\] 其中,\(p_i\)和\(y_i\)分别为伪造图像中每个像素的预测标签和ground-truth。此外,我们采用度量学习损失[13]来增加[23]后伪造图像样本中真实区域和伪造区域之间的特征分布的差异。 \[{\mathcal{L}}_{q}={\frac{1}{|A_{i}|}}\sum_{k^{+}\in A_{i}}-\log{\frac{\exp\left(q\cdot k^{+}/\tau\right)}{\sum_{k_{-}}\exp\left(q\cdot k^{-}/\tau\right)}}\] 其中,\(k^+\)和\(q\)表示真实区域的特征嵌入,\(k^−\)表示伪造区域的特征嵌入。\(A_i\)表示所有\(k^+\)的集合。结合以上所有情况,我们的最终损失函数可以表述为: \[\mathcal{L}=\lambda_{1}\cdot\mathcal{L}_{q}+\lambda_{2}\cdot\mathcal{L}_{\mathrm{BCE}}\ +\lambda_{3}\cdot\mathcal{L}_{\mathrm{Dice}}\] 其中,\(\lambda_{1}\)、\(\lambda_{2}\)、\(\lambda_{3}\)是平衡损失函数中这三项的参数\((\lambda_{1}+\lambda_{2}+\lambda_{3}=1)\)。在实验中,它们分别被设为0.5、0.15和0.35。
4实验
4.1实验设置
数据集。
我们使用与[11,19]相同的数据集来训练AdaIFL。这些训练数据集包括CASIA v2 [6]、IMD2020 [24],以及由[19]创建的经过伪造的图像数据集,涵盖了各种类型的伪造。为了全面评估AdaIFL的泛化能力,我们对5个与训练集不重叠的数据集进行了基准测试,即CASIA v1 [6]、Coverage[35]、DSO-1 [4]、NIST16 [10]和MISD [16]。这些数据集覆盖了大量的伪造图像,具有不同的伪造类型和广泛分布的数据源。
指标。
在之前的大多数工作之后,我们使用像素级的曲线下面积(AUC)、F1和Union上的交集(IoU)分数作为评估指标,其中阈值默认设置为0.5。
实施细节。
AdaIFL使用PyTorch实现,并以端到端方式进行培训。在训练过程中,输入的图像被裁剪到1024×1024。为了防止训练数据集大小不平衡造成的偏差,我们采用[11,19]的方法,在每个训练时期对每个数据集进行相等的采样。此外,还采用了常用的数据增强技术,如翻转、缩放、模糊和JPEG压缩来增强数据的多样性。我们使用了一个Adam
[17]优化器,其学习速率从2×10−4衰减到1×10−7。
4.2与最新方法的比较
我们仔细选择带有开放源代码和预训练模型的方法进行测试,以确保公平的比较。此外,确保这些模型的训练数据集不与测试数据集重叠是至关重要的。最后,我们选择了8种最先进的方法,以公平的方式进行全面的比较,即TruFor[11],HiFi-IFDL[12],CAT-Net v2[19],ManTraNet[37],MVSS-Net[2],PSCC-Net[20],IF-OSN[36]和IML-ViT [21]。
定量比较
表1为不同模型对IOU、f1、AUC评分的定量比较结果。
表1:不同图像伪造定位方法的性能比较。报告了IOU、F1和AUC评分。第一个和第二个排名分别以粗体和下划线显示。
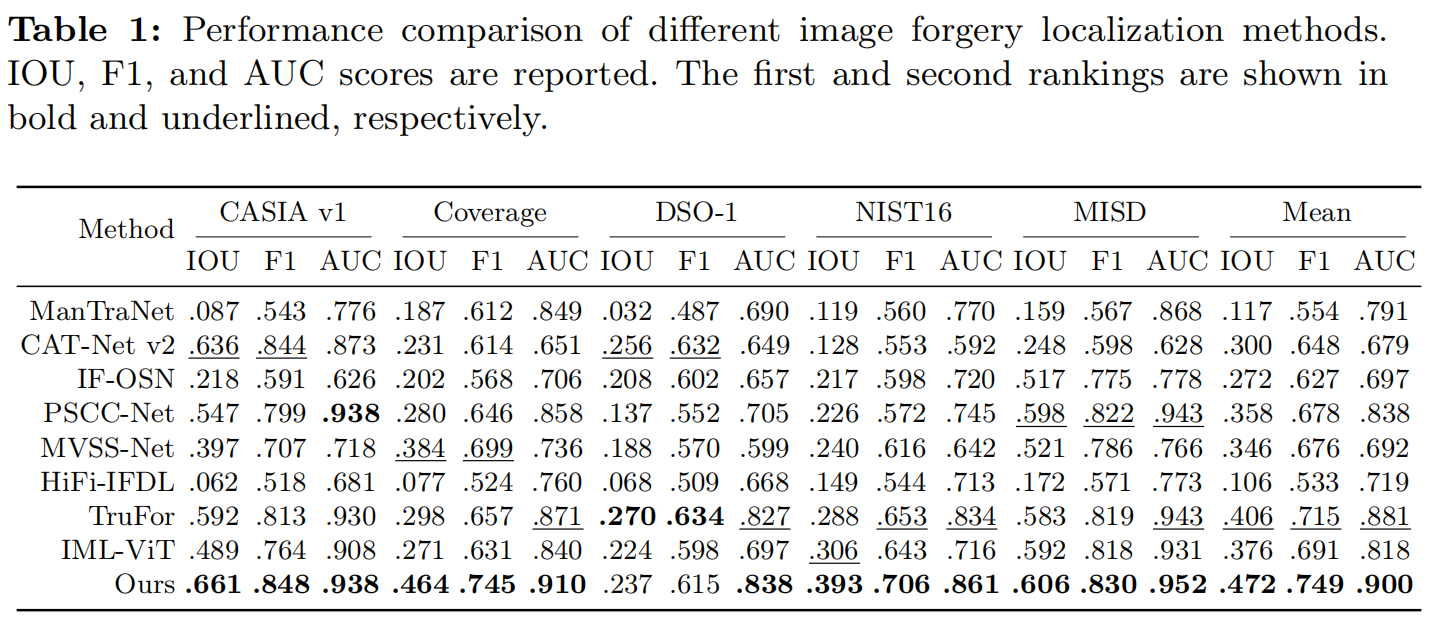
在所有比较模型中,AdaIFL达到了最先进的性能,平均IOU、F1和AUC得分分别比第二优模型高出6.6%、3.4%和1.9%。具体来说,对于F1和IOU评分,AdaIFL在CASIA、Coverage、NIST16和MISD上的定位性能最好,在DSO-1中排名第二。特别是在Coverage(复制-移动伪造数据集)上,AdaIFL的IOU和F1得分比第二优模型高出8.0%和4.6%,证明了我们的模型在抑制伪造区域和真实区域之间的特征耦合方面的突出能力。在更具挑战性的NIST16数据集上,我们的模型在IOU和F1分数上比第二优的模型高出8.7%和5.3%,在处理各种操作技术和伪造模式方面显示出非凡的泛化能力。值得注意的是,使用AUC作为度量可能会导致高估模型的性能,因为数据集的伪造像素和真实像素之间的比例高度不平衡。然而,我们的模型在所有数据集上都获得了最好的AUC分数。
定性比较
图5显示了不同测试图像的伪造定位结果。

我们的方法在几个方面都优于目前的SOTA方法。首先,我们的方法有效地减少了误报和漏检。与其他方法将非伪造区域错误识别为伪造或遗漏许多伪造区域不同,我们的方法可以准确地定位具有尖锐边界的伪造区域。其次,该方法可以准确地定位各种复杂形状的锻造区域。这在测试图像的第五行和第六行可以明显看出,其中其他方法只能预测粗略的结果,而不能捕获详细的边界。相比之下,我们的方法可以准确地定位具有复杂形状的伪造区域。第三,我们的方法在精确定位微小和微妙的伪造区域方面表现出了特殊的能力。如第三行和第六行的测试图像所示,许多方法很难识别这些小区域,而我们的方法可以准确地定位它们。
鲁棒性分析
在现实世界的场景中,伪造的图像可能会经历各种后处理操作。为了评估AdaIFL对伪造定位的鲁棒性,我们使用了常用的图像退化技术,即高斯模糊、高斯噪声、伽马校正和JPEG压缩。如表2所示,在NIST16上的测试结果表明,与其他最先进的方法相比,AdaIFL对各种降解技术表现出优越的鲁棒性。
表2:在不同失真条件下对NIST16数据集的定位性能。报告了IOU和F1的分数。
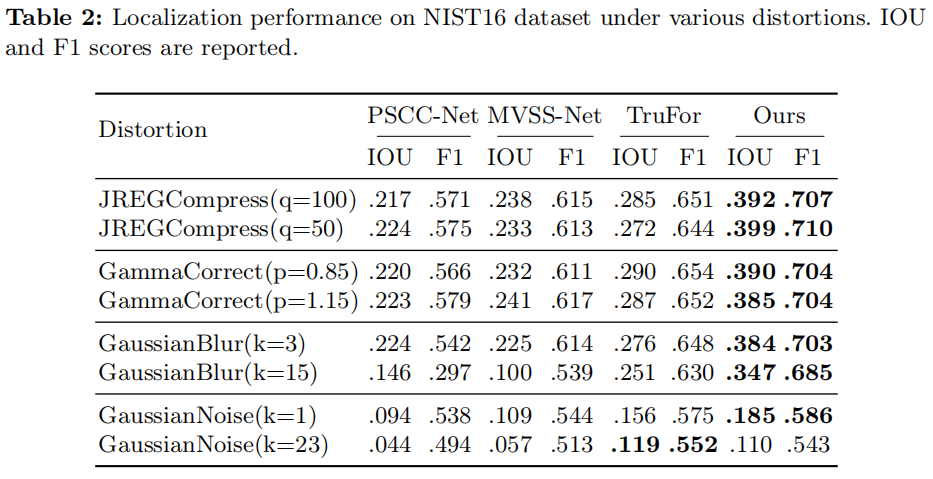
此外,表2表明,过量的噪声(k = 23)导致了我们的模型中的次优结果。这可能是由于路由过程受到噪声的影响,导致了专家的次优选择。我们认为,设计适当的补救机制,以确保在各种退化场景中路由的准确性,可能是有益的。
4.3消融分析
在本节中,我们将从特征重要性感知和动态网络结构这两个角度来分析AdaIFL中关键组件的影响。具体来说,AdaIFL通过分别在编码器(DyE)和解码器(DyD)中定制各种专家组,将动态路由的想法整合到IFL中。特征重要性感知注意注意力(FIA)自适应地感知不同区域的重要性,其中一个关键组件是自适应标记聚合器(ATA),它将区域特征聚合成可变长度的标记,将模型的注意力导向更具鉴别性和信息丰富的区域。为了评估FIA、ATA、DyE和DyD的有效性,我们分别从AdaIFL中移除每个组件,并将测试结果与CASIA和MISD数据集上的完整设置进行比较。
特征重要性感知的影响
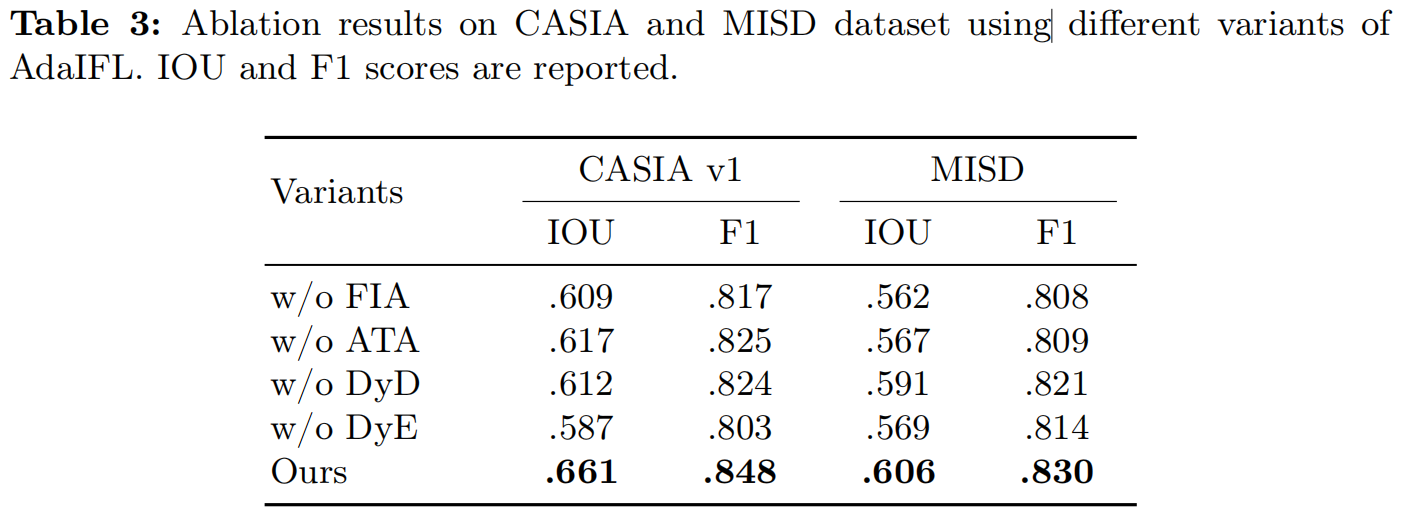
如表3中所示,用原注意力代替FIA后,IOU得分下降5.2%,CASIA F1得分下降3.1%,MISD IOU下降4.4%,MISD F1下降2.2%。去除ATA后,CASIA的IOU得分分别下降了4.4%和MISD的下降了3.9%。

此外,图6显示,去除FIA或ATA会导致检测失误、误报和无法准确定位伪造区域等问题。AdaIFL受益于区域划分和自适应聚合机制,缓解了特征耦合的问题,提高了图像伪造定位的性能。
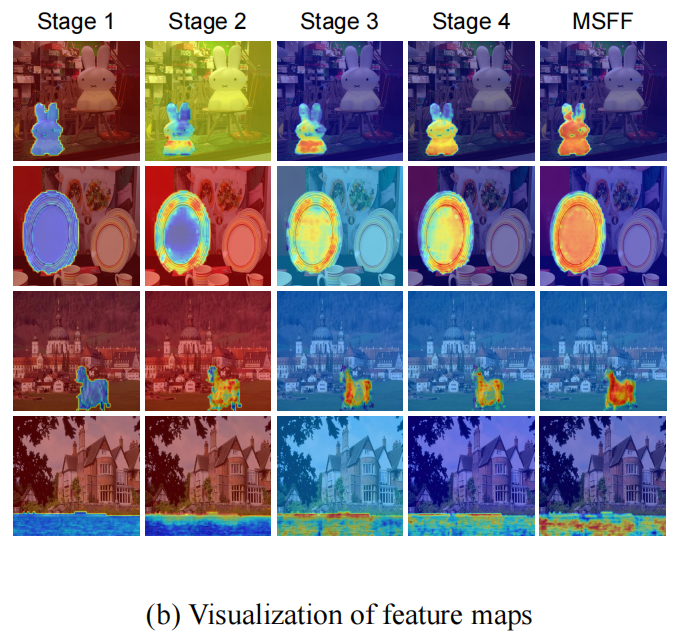
此外,图4 (b)显示了变压器编码器不同阶段的特征图的GradCAM。在 FIA的指导下,AdaIFL专注于在不同的阶段捕捉不同的特征。在初始阶段,该模型对伪造区域边界的局部细节进行了优先排序,强调了对边界伪造痕迹的精细感知。在随后的阶段中,它专注于在伪造区域内捕获不同级别的特征。MSFF模块通过融合这些特性,增强了模型的表达性,从而能够更好地捕获伪造的工件和法医痕迹。
动态网络结构的影响
在AdaIFL中,我们将动态路由的概念应用于基于transformer的编码器和轻量级路由器中。
如表3所示,去除动态专家组会显著降低定位性能。具体来说,从编码器中删除所有动态专家组,CASIA的IOO和F1得分下降了7.4%和4.5%,MISD的IOU和F1得分下降了3.7%和1.6%。从解码器中去除动态成分后,CASIA和MISD的IOU得分分别下降了4.9%和1.5%。这清楚地说明了动态路由概念在增强模型泛化方面的关键作用。
5结论
本文解决了图像伪造定位的两个关键挑战:
(1)处理不同伪造图像的适应性不足,
(2)捕获边界伪影的方法不灵活。
为了解决这些问题,我们提出了一种新的动态和重要性感知的图像伪造定位框架(AdaIFL),该框架可以动态地处理不同的伪造图像样本,并自适应地感知不同区域的重要性,提高了模型的泛化能力。大量的实验表明,我们所提出的方法优于最先进的方法。
Acknowledgements
This work is supported by Shenzhen Science and Technology Program (No.JCYJ20230807120800001), and 2023 Shenzhen sustainable supporting funds for colleges and universities (No.20231121165240001). The authors sincerely appreciate the computing environment supported by the China Unicom Shenzhen Intelligent Computing Center.