CFL-Net:Image Forgery Localization Using Contrastive Learning
CFL-Net: Image Forgery Localization Using Contrastive Learning
论文(arxiv)
![]()

摘要
传统的伪造定位方法的缺点是过度拟合和只关注少数特定的伪造痕迹。我们需要一种更通用的图像伪造定位方法,能够很好地适应各种伪造条件。底层伪造区域定位的一个关键假设是,无论伪造类型如何,每个伪造图像样本中未被篡改和被篡改区域的特征分布都存在差异。在本文中,我们的目标是利用这种差异特征分布来帮助图像伪造定位。
具体来说,我们使用对比损耗来学习映射到一个特征空间,在该空间中,每个图像的未篡改区域和被篡改区域之间的特征被很好地分离。此外,该方法不需要对伪造类型进行任何先验知识或假设,就可以对伪造区域进行局部定位。我们证明,我们的工作优于几个现有的方法在三个基准的图像处理数据集。
引言
交叉熵损失鼓励模型对同一类别提取相似特征。这可能有助于对Imagenet或cityscape等数据集进行分类或分割,在这些数据集中,相同类别的对象应该具有类似的特征。然而,在图像伪造定位中,由于不同的操作会在被篡改区域留下不同的伪造足迹,因此对数据集中所有被篡改区域提取相似的特征并不是最优的。因此,在没有附加约束的情况下,一个常见的基于交叉熵损失的框架容易对特定的伪造模式进行过拟合,这不利于泛化。
考虑到这些局限性,我们在最近提出的对比损失的基础上,提出了一种新的伪造定位方法,称为对比伪造定位网络CFL-Net。我们的方法依赖于底层伪造区域定位的一般假设,即无论伪造类型如何,未被篡改区域和被篡改区域之间的特征统计量仍存在差异,即颜色、强度、噪声等。在本文中,我们着重于利用特征空间中的这种差异,通过对比损失来帮助图像伪造定位。具体来说,我们的模型学习映射到一个特征空间,在这个空间中,每个图像中未被篡改和被篡改区域之间的特征被很好地分离和分散。因此,我们的方法并不专注于特定的伪造线索。此外,我们还计算了每个样品的对比损失。因此,我们的方法对每个样本的伪造线索进行了不同的处理,这有助于归纳。
因此,我们的方法对每个样本的伪造线索处理不同,有助于泛化。我们的主要贡献总结如下:
1. 提出了一种新的图像伪造定位方法,称为CFL-Net。利用了每个图像样本中未被篡改和被篡改区域之间特征分布的差异,而不关注特定的伪造足迹。因此,我们的方法更适合于检测真实生活中的伪造。
2. 解决了在无任何约束的情况下使用交叉熵损失进行通用图像伪造定位的问题。我们将对比损失纳入其中,并针对这个问题进行调整。
3. 我们在基准操作数据集上进行了大量的实验,表明我们的方法优于现有的几种图像伪造定位方法。
网络框架
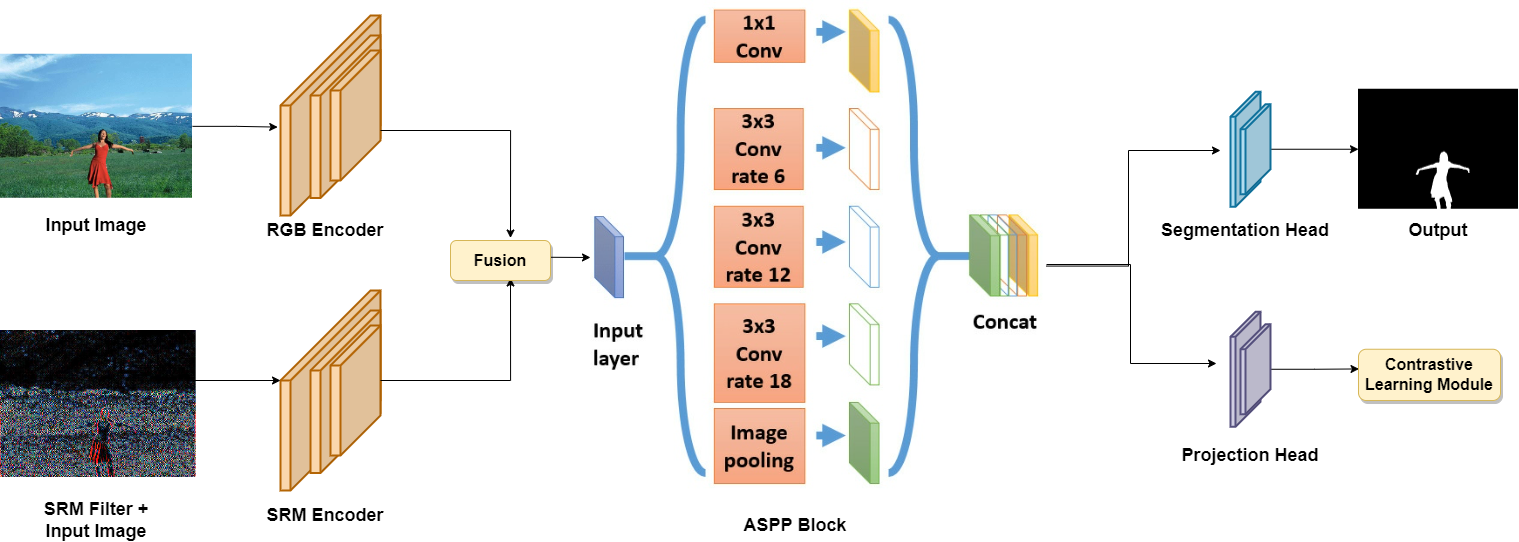
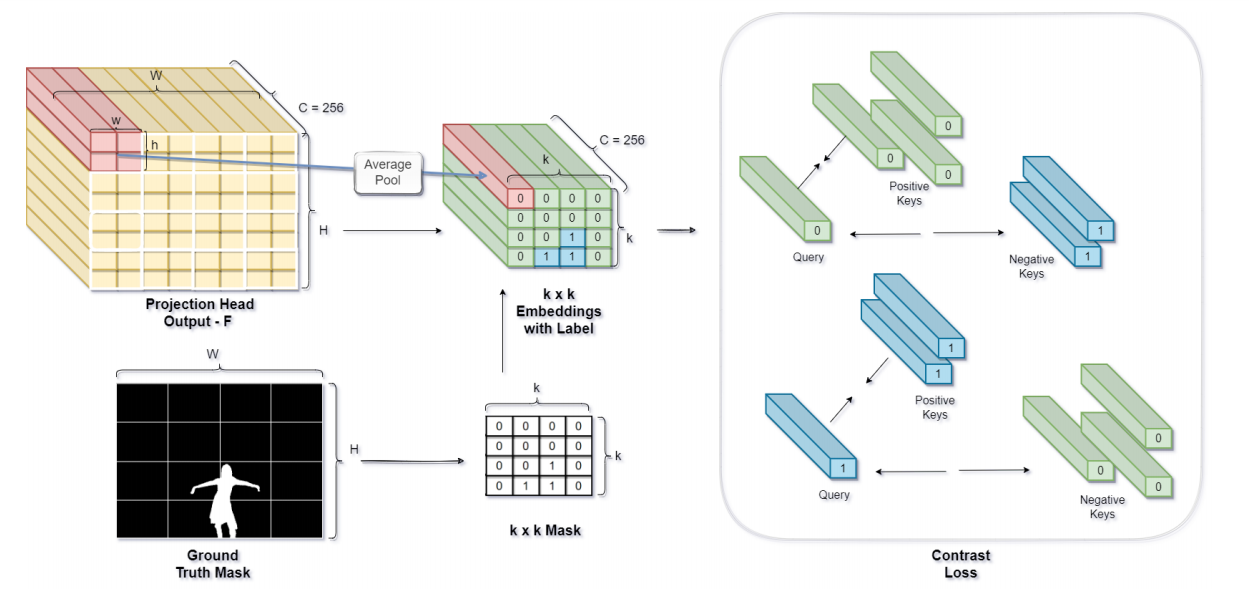
图3:对比学习模块:为了便于可视化,图中的投影头输出了一个形状为256×8×8的特征图F。然后将特征图分成4个×4个补丁。然后,对每个补丁中的4个空间向量进行平均,得到大小为4×4的嵌入(图中表示为‘k×k带标签的嵌入’)。ground truth掩码也被划分为4×4个补丁,每个补丁中计数出出现的最大像素标签,得到输出的4×4掩码(图中表示为“k×k掩码”)。
我们使用了两个流编码器,一个用于RGB输入图像,另一个用于SRM滤波图像。由编码器产生的特性被融合并传递到ASPP模块中。来自ASPP块的输出特征然后通过分割头和Projection头,其中第一个产生最终的预测掩模,后者产生进入对比学习模块的特征。
我们使用SRM过滤器,并使用它作为其他流的输入。SRM滤波器是一种高通滤波器,它增强了输入图像的高频信息,从而更突出边缘信息,有利于篡改的定位。我们使用ResNet作为这两个流的Backbone。然后,我们通过将特性通道连接起来,融合两个流中的特性。融合特征图采用ASPP模块,提取多尺度信息。全局上下文有助于收集更多的线索,如对比度差异等,用于操作检测。ASPP模块通过在不同尺度上提取信息来帮助实现这一点,比如全局上下文以及更细粒度的像素级上下文信息变得可用。
然后我们使用分割头和Projection头,将ASPP模块提取的上采样多尺度特征作为输入。我们选择一个DeepLab风格的分割头,输出大小为H ×W的最终分割图。投影图由Conv-BatchNorm-Conv层构成,该层将特征图投影到\(F∈R^{256×H×W}\), 256为嵌入维数。将嵌入的特征图F传递给对比学习模块。评估时不使用投影头。
ASPP模块
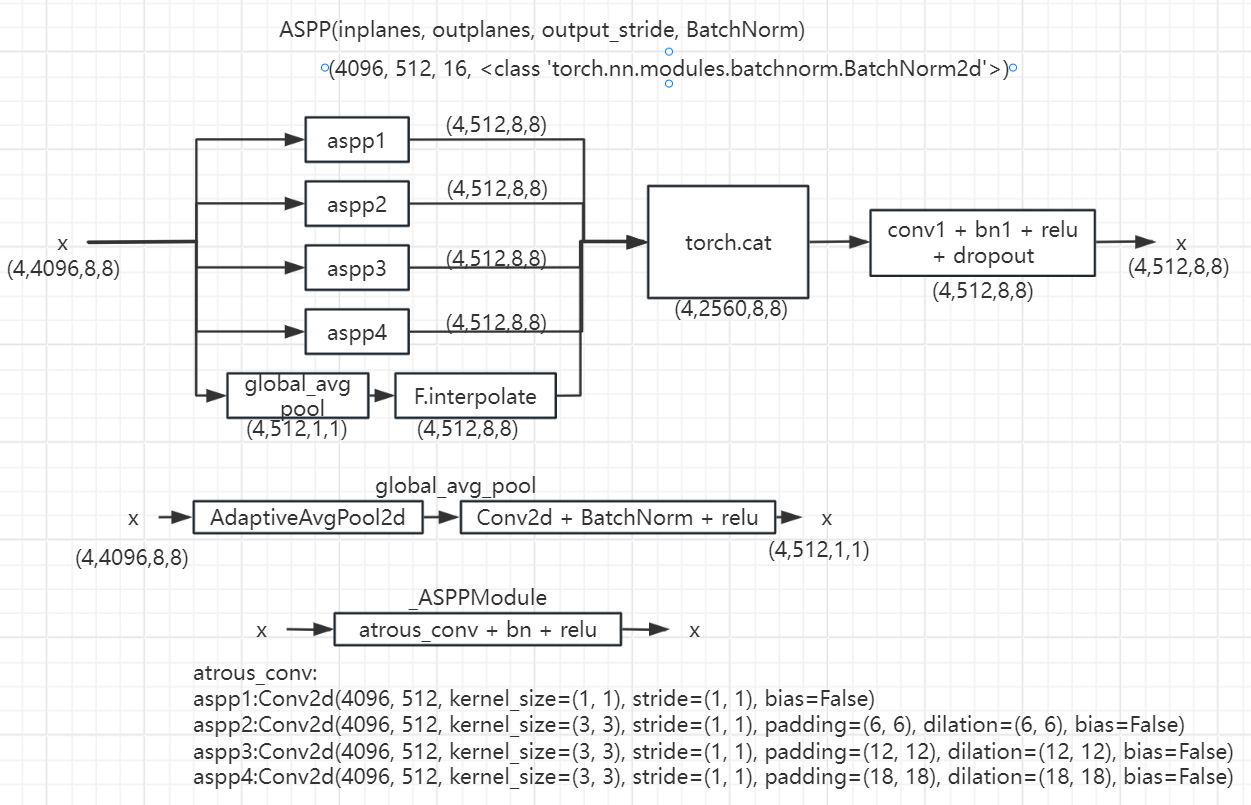
在融合的特征图上使用了ASPP模块[7],从而可以提取出多尺度的信息。据[41]报道,全局上下文有助于收集更多的线索,如对比度差异等,用于操作检测。ASPP模块通过提取不同尺度的信息来帮助实现这方面,这样全局上下文以及更细粒度的像素级上下文信息就可用了。
对比学习模块
由于我们的嵌入式特征图在空间上的大小是H×W,并且我们有相应的、大小相似的真实掩模M,所以我们知道每个像素嵌入的标签。因此,我们可以使用有监督的对比学习。对于每个查询像素嵌入\(z_i\),该嵌入的对比损失变为: \[L_i=\frac{1}{|A_i|}\sum_{k\in A_i}-log(\frac{exp(z_i\cdot k^+/ \tau)}{exp(z_i\cdot k^+/ \tau)+\sum_{k^-}exp(z_i\cdot k^-/ \tau)})\] 其中,\(k^+\)是一个嵌入与查询\(z_i\)具有相同标签的像素。\(A_i\)表示投影头输出特征图\(F\)中所有\(k_+\)的集合。同样,\(k_-\)是\(F\)中与\(z_i\)不同标签的像素嵌入。
然而,用这种方式计算\(L_i\)有一些主要的局限性。首先,基于单像素嵌入的对比损失没有考虑相邻嵌入的上下文信息。此外,为了计算损失,需要存储大小为HW×HW的点积矩阵,这很消耗内存。因此,为了在上下文和细粒度轨迹之间找到平衡,我们选择将F划分为局部区域。
我们首先将\(F∈R^{256×H×W}\)在空间上划分为k×k个块,从而得到\(f_i\in R^{256\times h\times w}\),其中\(i\in\{1,2,3…k^2\}\)、\(h=\frac{H}{k}\)和\(w=\frac{W}{k}\)。然后,我们取每个局部区域中像素嵌入的平均值。从而使每个\(f_i\)都变成了\(R^{256}\)的形状。以类似的方式,我们将地面真实掩模M划分为k×k个块。Mask在未被篡改区域的值为0,在伪造区域的值为1。我们得到\(m_i\in R^{h\times w}\),其中\(i\in\{1,2,3…k^2\}\)、\(h=\frac{H}{k}\)和\(w=\frac{W}{k}\)。为了得到每个\(m_i\)的标签值,我们计算了h×w个块中的0和1的数量。然后,我们指定块中的最大值为\(m_i\)的值。
然后,我们有了像素嵌入\(f_i\)和每个嵌入\(m_i\)的相应标签。我们现在得到监督对比损失: \[L_i=\frac{1}{|A_i|}\sum_{k\in A_i}-log(\frac{exp(f_i\cdot k^+/ \tau)}{exp(f_i\cdot k^+/ \tau)+\sum_{k^-}exp(f_i\cdot k^-/ \tau)})\] 其中,\(A_i\)表示与\(f_i\)具有相同标签的所有其他像素嵌入\(k^+\)的集合。类似地,\(k^−\)是所有与\(f_i\)有不同标签的负像素嵌入。损失函数中的所有嵌入都是\(L_2\)归一化的。对于单个图像样本,我们通过对所有嵌入的平均得到最终的对比损失: \[L_{CON}=\frac{1}{k^2}\sum_{i\in k^2}L_i\] 最后要优化的损失是: \[L=L_{CE}+L_{CON}\] 其中\(L_{CE}\)是交叉熵损失。
实验
在本节中,我们将描述在三个不同的操作数据集上进行的实验,以探索CFL-Net的有效性。这些数据集是包含几种操作类型的通用操作数据集,并不只特定于一种操作类型。我们使用的评估度量是像素级的曲线下面积(AUC)评分。
我们使用ResNet-50作为这两个流的编码器。我们用Adam优化器训练CFL-Net,学习率为1e-4。每过了20个epochs,我们就会将学习率降低20%。我们将输入图像的大小调整为256×256。我们将F划分为总共64个×64个块。温度系数\(\tau\)设置为0.1。对交叉熵损失进行加权,使被篡改类的权重增加十倍。我们将批处理大小设置为4,并在NVIDIA RTX Titan GPU上训练模型超过100个epochs。
与各种baseline模型的比较:
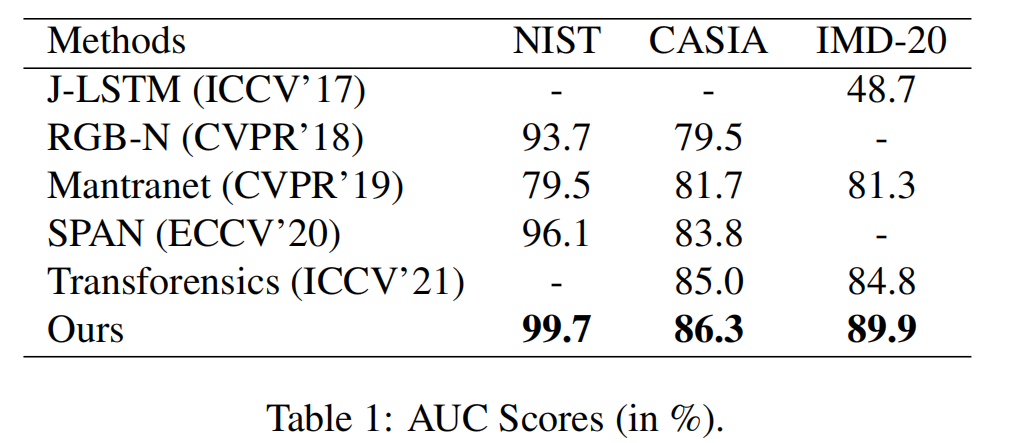
我们在表1中报告了我们的方法和基线模型的AUC评分(%)。需要注意的是,这里陈述的RGB-N和SPAN的结果是它们在各自的论文中报道的精细结果。JLSTM和Transforensics不进行任何预训练。虽然ManTraNet在合成操作数据集上对它们的模型进行了预训练,但它们并没有对特定的数据集进行微调。从表格中可以看出,CFLNet在基线模型中的所有数据集上都取得了最好的定位性能。特别是,CFLNet在IMD-20数据集上的性能大大优于所有的基线模型,而IMD-20数据集是一个具有各种伪造类型的真实操作数据集。具体来说,CFL-Net在IMD-20数据集上获得了89.9%的AUC分数,比性能第二良好的模型Transforensics提高了5.1%。
因此,它验证了我们的主张,即cfll-net非常适合于本地化真实生活中的伪造品。我们的模型在其他数据集上也优于基线模型——Casia和Nist。此外,值得指出的是,CFLNet在没有对合成操作数据进行预训练的情况下就实现了这些结果。
实验(有无对比损失)
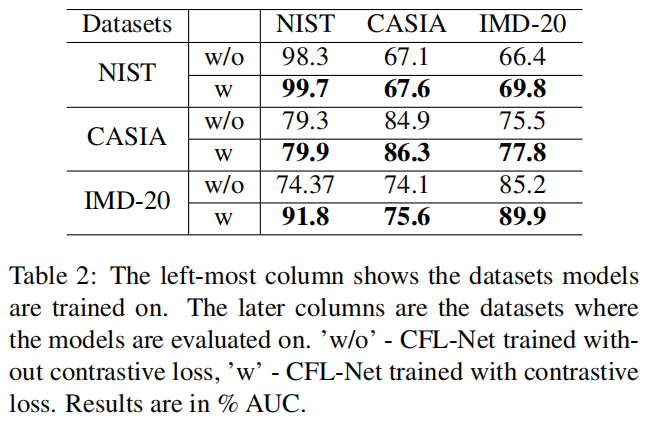
表2:最左边的一列显示了所训练的数据集模型。后面的列是评估模型的数据集。“w/o”训练没有对比损失,“w”训练有对比损失。结果以%
AUC表示。
表2显示了结果。很明显,用对比损失训练的CFL-Net在跨数据集的推广方面表现得非常好。在所有情况下,该模型比没有对比损失的模型表现得更好。当在IMD-20上进行训练并在NIST的测试集上进行评估时,我们提出的模型甚至优于ManTraNet的AUC分数。当在IMD-20数据集上进行训练时,可以看到的性能提高最高。IMD-20是真实的图像操作数据集,因此在这个数据集上进行训练有助于模型学习最一般化的特征。因此,我们提出的在IMD-20上训练并在其他数据集上进行评估的模型,与在没有对比损失的情况下训练的模型相比,产生了最大的性能改进。
还需要注意的是,在NIST上训练和在其他数据集上评估的两种模型的表现都很差,因为NIST拥有的图像很少,即数据集中有584张图像。因此,很难使用NIST来推广到其他数据集。尽管如此,我们提出的模型还是比训练后的没有对比损失的模型表现得更好。
定性分析
为了证明我们的对比损失通过避免同一类特征的聚类来保持特征的变化,我们通过t-SNE将从图5中分割头获得的类特征可视化。
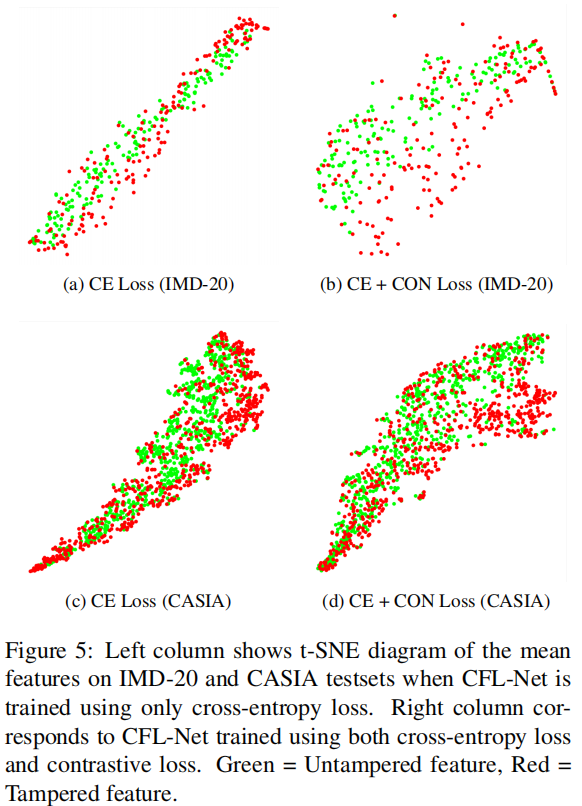
图5:左栏显示了当仅使用交叉熵损失训练CFL-Net时,IMD-20和CASIA测试集上的平均特征的t-SNE图。右列对应于使用交叉熵损失和对比损失训练的CFL-Net。绿色=未篡改特征,红色=篡改特征。
左列显示了当仅使用CFL-Net训练交叉熵损失时,IMD-
20和CASIA测试集上每个图像样本的平均特征向量。很明显,未被篡改(图中绿色)和被篡改(图中红色)区域对应的特征在这里是堵塞的。与此同时,右栏显示了同时使用交叉熵和对比损失进行CFL-Net训练时的平均特征。这两个区域对应的特征更加分散。
因此,不同的操作足迹更容易可分离。实验表明,传统的交叉熵损失由于类别内不变性而减少了图像伪造定位的泛化,而我们提出的方法可以通过分散特征分布来提高泛化效果。
消融实验(损失函数变化)
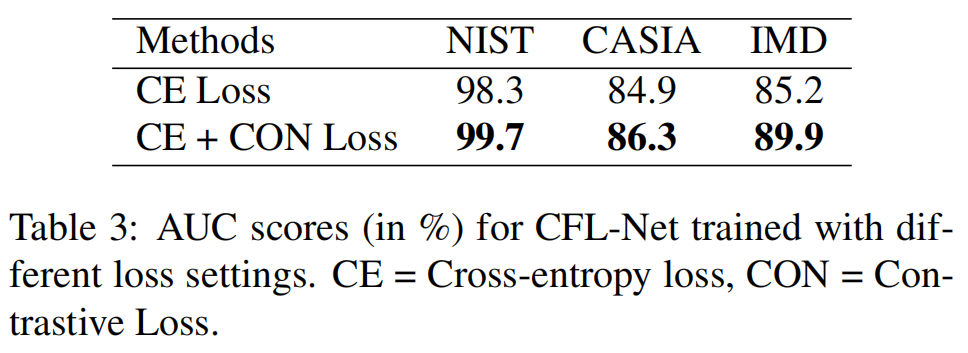
在表3中,我们报告了结果。从表中可以清楚地看出,添加对比损失确实有助于定位。这种改进在真实的图像处理数据集IMD-20上更为突出。对比损失有助于提高AUC评分4.7%。需要注意的是,在没有对比损失的情况下,我们的方法已经取得了很好的结果。
结论
在本文中,我们从一个新的角度来研究通用的图像伪造定位问题。我们发现了现有方法的一个主要缺点,该方法关注特定的伪造足迹,并使用没有任何约束的交叉熵损失来定位伪造。为了解决这一缺点,我们补充了交叉熵损失和对比损失,并提出了一种新的图像伪造定位方法,即对比伪造定位网络CFL-Net。我们在三个基准图像处理数据集上进行了实验,并将实验结果与近年来的主要伪造定位方法进行了比较。CFL-Net在AUC度量方面优于所有方法。此外,在现实生活中的图像处理数据集IMD-2020上的改进更为突出。在未来的工作中,可以考虑一个更复杂的融合机制来融合来自RGB和SRM流的特征映射。例如,注意模块或最近提出的视觉变压器可以被用作一种融合机制。