Forgery-aware Adaptive Learning with Vision Transformer for Generalized Face Forgery Detection
Forgery-aware Adaptive Learning with Vision Transformer for Generalized Face Forgery Detection
(发表于TCSVT,IEEE Transactions on Circuits and Systems for Video Technology, 1区B刊)
摘要
随着生成模型的快速发展,目前人脸伪造检测面临的挑战是如何有效地检测来自不同未知领域的真实操纵人脸。虽然以往的研究表明,经过预训练的基于视觉变换器(ViT)的模型在对深度伪数据集进行完全微调后,可以获得一些有希望的结果,但其泛化性能仍不令人满意。为此,我们提出了一种在自适应学习范式下的伪造感知自适应视觉Transformer网络(FAViT),其中预先训练的ViT网络中的参数保持不变,而设计的自适应模块进行优化以捕获伪造特征。
具体来说,设计了一个全局自适应模块来模拟输入令牌之间的长期交互,利用自注意机制来挖掘全局伪造线索。为了进一步探索必要的局部伪造线索,提出了一种局部自适应模块,通过增强局部上下文关联来暴露局部不一致性。此外,我们还引入了一个细粒度的自适应学习模块,该模块强调通过细粒度对的关系学习对真实面孔的共同紧凑表示,驱动这些提出的自适应模块感知细粒度的伪造感知信息。
大量的实验表明,我们的FA-ViT在交叉数据集评估中取得了最先进的结果,并增强了对看不见扰动的鲁棒性。特别是在FA-ViT的跨数据集评估中,Celeb-DF和DFDC数据集的AUC得分分别达到93.83%和78.32%。该代码和训练过的模型已经在:
https://github.com/LoveSiameseCat/FAViT 上发布了。
索引术语-人脸伪造检测,视觉转换器,自适应学习,泛化性能。
I.介绍
随着深度学习技术的快速发展,人工智能生成内容(AIGC)技术在多种多媒体任务中取得了重大进展。然而,这一进步对人眼辨别这些数字内容提出了巨大的挑战。特别是,攻击者可以很容易地为各种恶意目的生成伪造的面部内容(又名Deepfakes),对社会构成金融欺诈、政治冲突和冒充的紧迫威胁。
以往的大多数工作都使用卷积神经网络(CNN)来构建检测器,其中初始[1]或效率网络[2]由于其出色的深度伪检测性能而被广泛应用作基本主干。为了提高其普遍性,一些作品探索了隐藏在被操纵面孔中的常见的伪造线索,如噪声信息[3]-[5]、混合伪影[6]-[8]、频率特征[9]-[11]等。然而,cnn中有限的接受域限制了它们全面学习更广义的特征[12]的能力。作为回应,一些方法寻求使用视觉变压器(ViT)进行人脸伪造检测[13]-[16]。由于自注意机制,这些基于vit的方法可以模拟不同输入标记之间的长程关系。然而,ViT难以捕获局部特征细节,这在深度伪造检测[17]中尤为重要。为了解决这一限制,之前的工作将CNN本地先验纳入到ViT架构[18],[19]中。
与从头开始训练的模型[20]相比,预先训练的模型在下游任务中表现出更好的收敛性和泛化性,并且预先训练的ViT
1在取证任务[21]中已被证明是有效的。因此,在以前的工作[13],[17]-[19]中,通常使用公共可访问的预先训练的权重来初始化基于vit的检测器,然后在深度假数据集上更新这些参数。然而,最近的工作[22],[23]指出,基于vit的模型对特定的下游任务进行完全微调会破坏预先训练的特征,并可能过度拟合特定的数据模式[21],可能会阻碍它们在开放集环境中的泛化能力。另一方面,如图1所示,被篡改人脸上的伪造伪影会导致全局或局部的不一致,这表明需要从多个角度对关键表示进行建模。

基于这些观察结果,我们提出了用于广义人脸伪造检测的伪造感知自适应视觉Transformer网络(FA-ViT),其中预先训练的权值是固定的,只有设计的自适应模块被优化,以从全局和局部的角度捕获丰富的伪造感知信息。
FA-ViT的概述如图2所示。
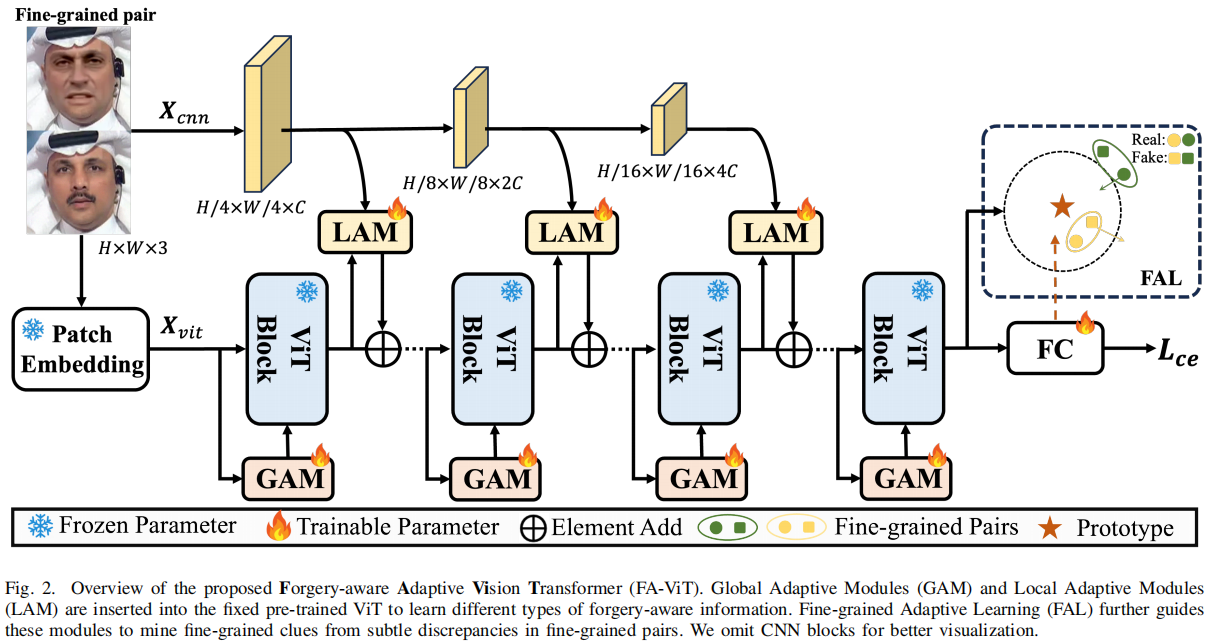
它主要由两个模块组成:全局自适应模块(GAM,Global Adaptive
Module)和局部自适应模块(LAM, Local Adaptive
Module),以用于捕获全局和局部伪造感知信息。具体来说,GAM设计来为接收ViT令牌,并与自注意层的原始查询、键和值输出进行交互。
具体来说,GAM被设计为接收ViT令牌,并与自注意层的原始查询、键和值输出进行交互。考虑到全局伪影跨越了操纵面部的大区域,GAM利用自我注意机制来增强其从这些伪影中学习全局取证线索的能力。
另一方面,LAM采用二次编码[24]来增强每个ViT标记与其相邻空间信息之间的局部关联,指导模型强调局部不一致性之间的异常情况。因此,全局和局部伪造感知信息共同适应固定的预训练特征,形成用于在各种场景中检测深度伪造的广义法医表示。
此外,常用的交叉熵损失强调类别水平的差异,但难以捕获细粒度信息,揭示操纵和真实面孔之间的细微差别[10],[25],[26]的差异。为了解决这一问题,我们设计了细粒度自适应学习(FAL)。如图2所示,将具有相似视觉语义内容但属于不同类别的细粒度对作为输入对进行分组。FAL利用来自最后一个完全连接(FC)层的权重作为真实面孔的代理原型,并通过圆损失[27]来规范原型和每个细粒度对之间的关系。在FAL的指导下,将所提出的自适应模块挖掘更细粒度的伪造感知信息,在特征空间中压缩真实面,从而进一步提高模型的通用性。
我们的主要贡献总结如下:
- 我们观察到,当对深度假检测的任务进行完全微调时,基于vit的模型难以推广到看不见的数据集。为了解决这一问题,我们提出了一种新型的伪造感知自适应视觉Transformer网络(FAViT),用于自适应学习范式下的广义人脸伪造检测。
- 我们提出了全局自适应模块(GAM)和局部自适应模块(LAM),它们有效地使全局和局部伪造感知信息适应于预先训练的ViT特征。此外,我们设计了一种新的线粒度自适应学习(FAL)来指导这些自适应模型在自适应学习过程中捕获细粒度信息。
- 我们在多个数据集和传感器上进行了广泛的实验,结果表明,我们提出的FA-ViT在各种评估中优于最先进的方法。
II. 相关工作
A.面部伪造检测
B.模型适应
C. 细粒度的信息学习
III. 提出的方法
在本节中,我们首先在第III-A节中概述了所提出的FA-ViT。三。然后,我们在章节III-B和III-C中描述了全局自适应模块(GAM)和局部自适应模块(LAM)。最后,在第III-D节中提出了细粒度自适应学习(FAL)。
A. 概述
我们提出的FA-ViT的框架如图2所示。
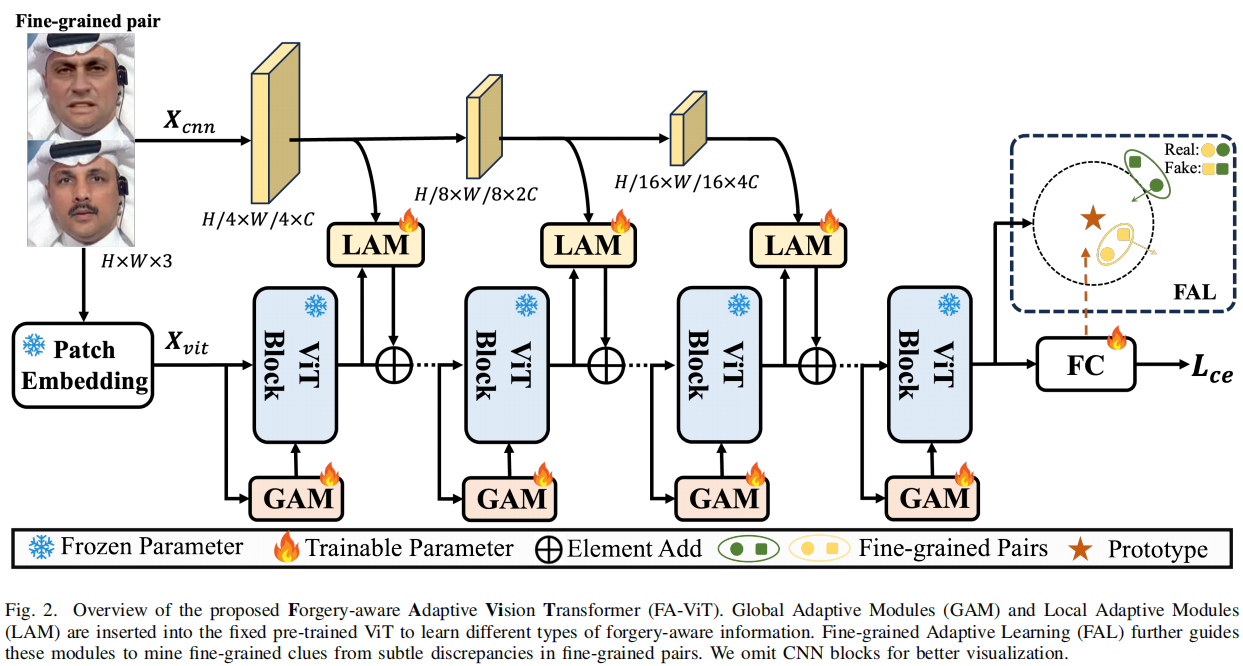
它采用预先训练好的ViT为基本骨干,由12个ViT块组成。每个块由一个自我注意(SA)层和一个多层感知器(MLP)层组成。在训练过程中,这些块内的参数保持冻结。
在FA-ViT中,输入的\(\mathbf{X}\in\mathbb{R}^{H\times
W\times3}\)被划分为L个图像补丁,并进一步处理成D维标记,记为\({\bf X}_{v i t}\ \in\ \mathbb{R}^{L\times
D}\)。在每个ViT块中,我们在SA层中插入一个GAM。当\({\bf X}_{v i
t}\)通过SA层时,GAM借助自我注意机制捕获全局伪造感知信息。另一方面,我们从\({\bf
X}\)中提取多尺度空间特征,其中每个尺度特征\({\bf X}_{c n
n}\)都是从一个由三个卷积层组成的CNN块中获得的。LAM为每个ViT标记聚合了来自\({\bf X}_{c n
n}\)的空间伪造感知信息,这有助于以自适应学习的方式捕获丰富的局部细节。除了常用的交叉熵(CE)损失外,我们还引入了FAL来指导GAMs和LAMs来捕获更细粒度的伪造感知信息。
B. 全局自适应模块GAM
自注意层是ViT中的一个关键组件,它使每个输入令牌能够聚合来自所有其他令牌的信息。我们首先简要介绍了自注意层的计算过程。
表示\(\mathbf{X}_{v i t}^{i n}\in\mathbb{R}^{L\times
D}\)是ViT块的输入,首先通过三个可学习矩阵\(W_{Q}\in\mathbb{R}^{D\times D}\),\(W_{K}\in\mathbb{R}^{D\times D}\)和\(W_{V}\in\mathbb{R}^{D\times
D}\),预测查询令牌\({\bf
Q}\in\mathbb{R}^{L\times D}\),关键令牌\({\bf K}\in\mathbb{R}^{L\times
D}\)和值令牌\({\bf
V}\in\mathbb{R}^{L\times D}\): \[{\bf
Q}={\bf X}_{v i t}^{i n}W_{Q},\ \ {\bf K}={\bf X}_{v i t}^{i n}W_{K},\ \
{\bf V}={\bf X}_{v i t}^{i n}W_{V}.\]
然后将自注意层的计算表示为: \[{\bf X}_{v i
t}^{o u t}=\mathrm{Attention}({\bf Q},{\bf K},{\bf
V})=\mathrm{softmax}(\mathbf{QK}^{\mathsf{T}}/{\sqrt{D}})\mathbf{V},..\]
其中,\({\bf X}_{v i t}^{o u
t}\)是输出。
所提出的GAM建立在自注意层之上,利用自注意机制挖掘全局信息。先前的工作[18],[61],[62]已经证明了标记嵌入(即块表示)表现出比与遥远标记的邻近标记更强的相关性。因此,采用具有瓶颈结构的卷积层在GAM中建模这种局部空间关系,在全局自适应学习过程中引入与标记相关的局部先验。我们提出的GAM的细节如图3所示。
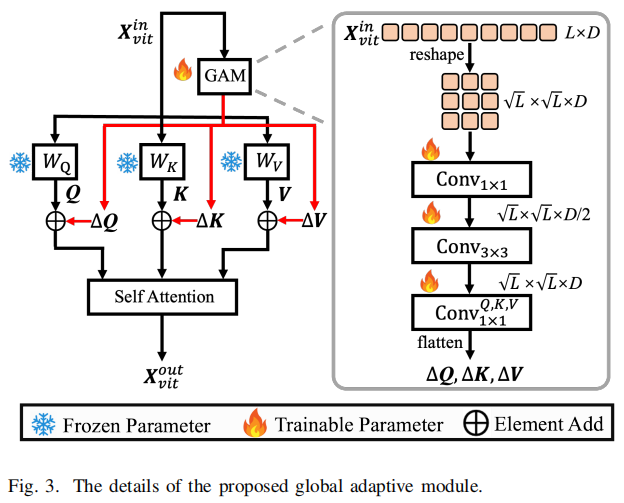
具体来说,首先将\(\mathbf{X}_{v i t}^{i n}\)根据其原始的空间位置重塑为\(\sqrt{L}\times\sqrt{L}\times D\)的形状。然后应用1×1卷积层来降维,然后使用3×3卷积层来捕获令牌级依赖。最后,GAM通过三种不同的1×1卷积生成Q、K和V的全局自适应信息。此过程的表述如下: \[\triangle{\bf Q},\triangle{\bf K},\triangle{\bf V}=\mathrm{Conv}_{1\times1}^{Q,K,V}(\mathrm{Conv}_{3\times3}(\mathrm{Conv}_{1\times1}({\bf X}_{w i t}^{i n}))),\]
\[{\bf X}_{v i t}^{o u t}=\mathrm{Atention}(\bf Q+\triangle Q,{\bf K}+\triangle\bf K,{\bf V}+\triangle{\bf V}),\]
其中\(\triangle{\bf Q},\triangle{\bf K},\triangle{\bf V}\)是原始Q、K和V的自适应信息。由于原始信息和自适应信息融合在一起,并随后通过自我注意操作进行处理,这确保了GAM与所有令牌交互,从而从全局的角度捕获伪造感知特征。值得注意的是,\(\mathrm{Conv}_{1\times1}^{Q,K,V}\)中的参数被初始化为零,这有助于全局伪造感知知识的稳定学习。
C. 局部自适应模块LAM
纯ViT处理通过堆叠的线性层的输入,这很难捕获对检测被操纵的面孔至关重要的局部细节。如图1所示,被操纵面中的伪影往往会引入局部不一致,说明每个查询令牌必须强调其与周围位置的关系,以检测局部伪造线索。以前的方法使用交叉注意模块[14]、[15]、[63]或加法操作[17]、[64]将局部空间信息注入到类似vit的架构中,但经常忽略了每个查询令牌的上下文重要性。为了缓解这一问题,我们提出的LAM旨在强调自适应学习过程中的上下文信息,从而有效地从局部不一致中捕获关键的局部伪造线索。
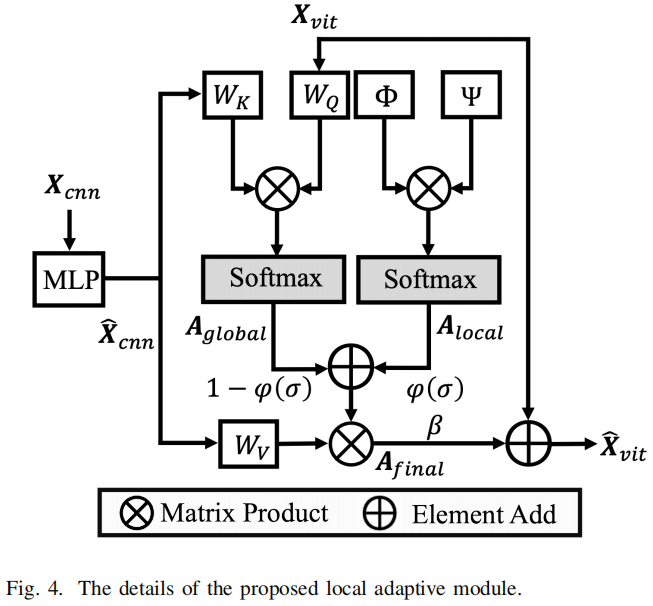
图4提供了我们提出的LAM的细节。空间特征\({\bf X}_{c n n}\)首先通过MLP层投射到\(\hat{\mathbf{X}}_{c n n}\)上,其中\(\hat{\mathbf{X}}_{c n n}\)和\({\bf X}_{v i t}\)具有相同的形状。对于\({\bf X}_{v i t}\)中的第a个令牌\(\mathbf{X}_{t o k e n}^{a}\),LAM通过同时考虑其全局注意\(\mathrm{A}_{g l o b a l}^{a}\)和局部注意\(\mathrm{A}_{l o c a l}^{a}\),计算其在\(\hat{\mathbf{X}}_{c n n}\)不同部分的注意得分: \[\mathbf{A}_{f i n a l}^{a}=(1-\varphi(\sigma))\mathbf{A}_{g l o b a l}^{a}+\varphi(\sigma)\mathbf{A}_{l o c a l}^{a},\] 其中\(\mathbf{A}_{f i n a l}^{a}\)是\(\mathbf{X}_{t o k e n}^{a}\)的最终注意图。\(\varphi(\cdot)\)表示s型函数,\(\sigma\)是一个初始化值为零的可学习参数。\(\mathrm{A}_{g l o b a l}^{a}\)的计算类似于交叉注意,其表示如下: \[{\bf A}_{g l o b a l}^{a}=s o f t m a x(({\bf X}_{t o k e n}^{a}W_{Q})({\bf\hat{X}_{c n n}}W_{K})^{T}).\] 利用二次编码[24],引入\(\mathrm{A}_{l o c a l}^{a}\)算法来强调\(\mathbf{X}_{t o k e n}^{a}\)周围空间信息的局部性: \[{\bf A}_{l o c a l}^{a}=s o f t m a x(\Phi\Psi^{T}),\] 其中,\(\Phi \in \mathbb{R}^{\sqrt{L}\times{\sqrt{L}}\times3}\)表示局部强度,\(\Psi\in \mathbb{R}^{1\times3}\)是决定\(\mathbf{X}_{t o k e n}^{a}\)注意方向的方向向量。注意,为了简化,我们在softmax操作之前省略了平坦操作。假设\(\mathbf{X}_{t o k e n}^{a}\)的空间位置为\((i_a,j_a)\),同样,在\(\hat{\mathbf{X}}_{c n n}\)中第b个标记的空间位置为\((i_b,j_b)\)。\(\Phi\)在位置\((a,b)\)上的相对局域性强度\(\phi_{a,b}\in\mathbb{R}^{1\times3}\)表示为: \[\phi_{a,b}=(\|(i_{b}-i_{a},j_{b}-j_{a})\|_{2},i_{b}-i_{a},j_{b}-j_{a})\,.\] 另一方面,方向向量\(\Psi\)表示为: \[\Psi=(-1,2\psi_{1},2\psi_{2}),(\psi_{1},\psi_{2})\in\{-1,0,1\}\,.\] 在实践中,我们在不同的头部为\(\psi_{1}\)和\(\psi_{2}\)分配不同的值,以探索不同方向的局部信息,如图5所示。

我们为每个查询标记收集最终的注意映射,以形成\(\mathbf{X}_{v i t}\)的\(\mathbf{A}_{f\,i n a l}\),并使用它将局部空间信息注入到ViT特征中。此过程的表述如下: \[\hat{\bf X}_{v i t}={\bf X}_{v i t}+\beta{\bf A}_{f i n a l}\hat{\bf X}_{c n n}W_{V},\] 其中β是一个初始化的可学习缩放因子,\(\hat{\bf X}_{v i t}\)被传递到下一个vit块。根据经验,将多尺度空间信息分别注入第一、第四和第七个ViT块。
D. 细粒度的自适应学习FAL
细粒度信息对于提高泛化性能[17]、[47]、[48]非常重要。因此,我们引入了FAL来促进细粒度伪造感知信息的自适应学习。我们首先将最后一个FC层中与真实人脸对应的权重向量设置为真实人脸的代理原型,因为之前的工作[65]已经证明,分类器中的权重收敛到每个类的中心方向。在每个细粒度对中,FAL拉近了原型和真实人脸之间的相似性,同时通过修改后的circle损失将篡改过的人脸从原型中推开[27]: \[L_{F A L}=\log\big[1+\sum\exp(\eta(\gamma_{n}(s_{n}-m_{n})-\gamma_{p}(s_{p}-m_{p})))\big],\]
\[s_{p}=\mathrm{CosSim}(\mathrm{F}_{r e a l},\mathrm{F}_{p r o}),\ s_{n}=\mathrm{CosSim}(\mathrm{F}_{f a k e},\mathrm{F}_{p r o})\]
\[\gamma_{p}=m a x(1+m-s_{p},0),\;\;\gamma_{n}=m a x(m+s_{n},0),\]
\[m_{p}=1-m,\ m_{n}=m,\]
其中CosSim表示余弦相似度,而\(F_{pro}\)是真实面孔的原型。η是比例因子。M是控制细粒度对中的裕度和加权因子的超参数。\(F_{real}\)和\(F_{fake}\)是来自最后一个ViT块的细粒度对的编码特性。
在优化过程中,通过\(\gamma_{n}(s_{n}-m_{n})-\gamma_{p}(s_{p}-m_{p})=0.\),实现了决策边界。通过使用方程式13和14,将决策边界转换为:
\[s_{n}^{2}+(1-s_{p})^{2}=2m^{2}\]
方程15表明FAL鼓励细粒度对向以sp = 1和sn = 0为中心、半径为\({\sqrt{2}}m\)的圆收敛,如图6所示。
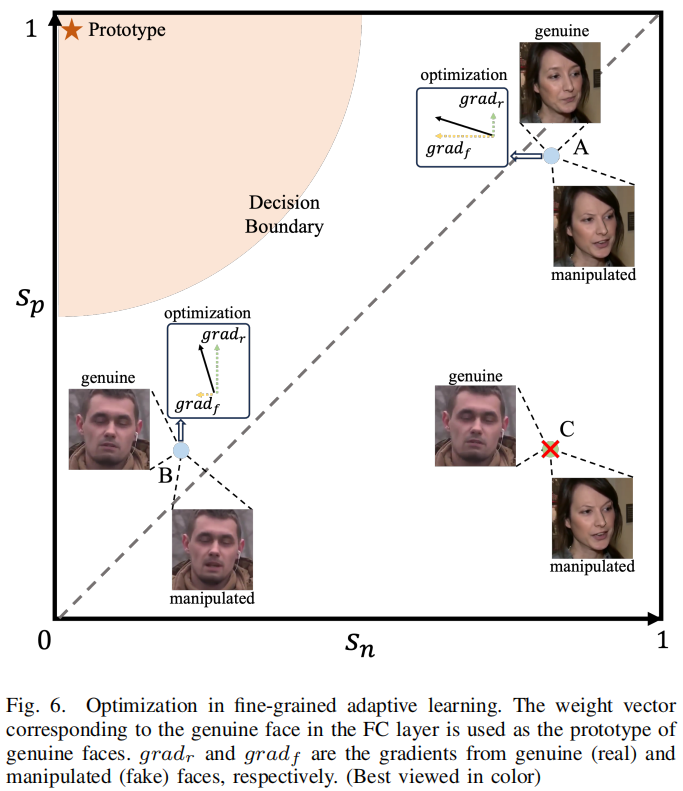
这种优化使每个细粒度对能够提供更灵活的梯度来指导细粒度信息的学习。例如,在A点,当远远大于\(grad_r\)时,该模型强调捕获细粒度的鉴别信息,以推开被篡改的人脸。相比之下,在B点,当\(grad_f\)比\(grad_r\)小得多时,该模型侧重于学习细粒度的一致性,以拉近真实的人脸。另一方面,FAL忽略了非细粒度对的梯度,如图图6中C点的例子。在这种情况下,差异涉及到背景或非必要的操作区域,这可能会导致模型过拟合到平凡的特征。
显然,FAL通过探索细微差异区域的细粒度信息,在特征空间中紧凑真实的人脸特征。它没有明确地惩罚被操纵面孔的距离,因为我们希望在不同的伪造技术中保留操纵痕迹的多样性。与单中心损失(SCL,Single
Center
Loss)[10]使用不同类别之间的平均距离来压缩类内方差不同,FAL专注于学习每个细粒度对中的细粒度鉴别信息和一致信息,使挖掘关键信息的过程更加精确。
E. 总损失
我们提出的FA-ViT是端到端训练的,并由预测结果\(\hat y\)和地面真实标签y之间的交叉熵损失进行监督: \[L_{c e}=-y\log\hat{y}-(1-y)\log\left(1-\hat{y}\right),\] 其中,标签y为0是为真实的面孔,否则y为1。总体目标函数由两个组成部分组成: \[L_{t o t a l}=L_{c e}+\lambda L_{F A L},\] 其中,λ是一个加权参数。在第一个训练阶段,我们将λ设置为0,允许模型专注于学习分类信息。随后,我们将λ调整为1,从而促进了细粒度信息的学习。
IV. 实验
A.实验设置
1)数据集:
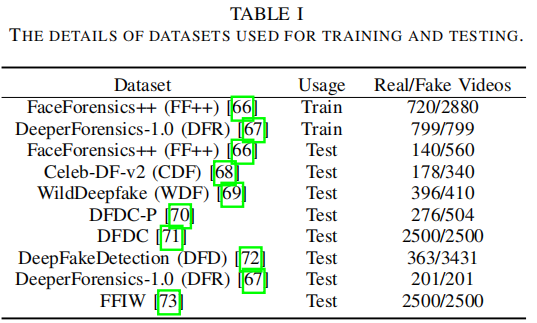
我们采用了8个广泛使用的公共数据集来评估我们的模型。
1)FaceForensics++(FF++)[66]是一个广泛使用的数据集,由四种类型的人脸操作技术组成:DeepFakes
(DF) [75], Face2Face (F2F)[76], FaceSwap (FS) [77], and NeuralTextures
(NT)
[78]。
2)Celeb-DF-v2(CDF)[68]是一个高质量的深度假数据集,专门针对名人的人脸。
3)WildDeepfake(WDF)[69]从互联网上收集深度伪造视频,其中包括各种场景和伪造方法。在WDF上的评价结果反映了检测器在现实世界场景中的性能。
4)Deepfake
Detection
Challenge(DFDC)[71]提供了一个具有挑战性的数据集,包含来自不同场景的各种深度假视频,使用了不同的深度伪造、基于GAN和传统的人脸交换方法。
5)Deepfake
Detection Challenge
Preview(DFDC-P)[70]提供了一个DFDC数据集的预览版本,并合并了两种面部修改算法。
6)DeepFakeDetection(DFD)[72]是另一个全面的深度假数据集。这个数据集包括超过3000个被操纵的视频,包括28个演员和不同的场景。
7)DeeperForenics-1.0(DFR)[67]是通过使用FF++的真实视频和创新的端到端面部交换框架。它也可以作为一个流行的数据集来衡量morel的鲁棒性。
8)FFIW-10K (FFIW) [73]
是一个最近的大规模数据集,它专注于多人的场景。对于DFD数据集,我们使用所有的视频来进行评估。对于其他的数据集,我们按照官方的策略来分割相应的数据集。关于一个全面的概述,请参见表一。
2)实施细节:
我们使用MTCNN [79]裁剪面区域,并将其调整为224×224。我们从每个视频中只采样20帧来构建训练数据。在测试过程中,我们从每个视频中抽取50帧的样本进行评估。我们的方法是在一个NVIDIA GTX 3090上使用PyTorch库[80]实现的。我们采用在ImageNet-21K [81]上预训练的ViT-Base模型作为FA-ViT的主要骨干。为了进行优化,我们使用了Adam [82]优化器,其初始学习速率为3×10−5,权重衰减为1×10−5,批量大小为32。学习速率每5个时代衰减0.5个。FAL中m和η的超参数将在第2节中进行讨论。IV-F.CNN的详细结构如表二所示,参数使用随机初始化方法进行初始化。
3)评价指标:
我们遵循[17]中的评价策略,以准确性(ACC)和受试者工作特征曲线下面积(AUC)作为我们的评价指标。为了进行公平的比较,我们对同一视频中的预测进行平均,得到视频级的预测,并给出了其他工作的结果。
B. 数据集内评估
我们在广泛使用的FF++数据集上进行了数据集内实验,包括高质量(C23)和低质量(C40)数据集。所有的模型都在同一个数据集上进行训练和测试,其中的性能显示了模型在伪造的人脸中捕获操作痕迹的能力。表3说明了数据集内的结果,其中我们分别加粗和下划线显示了最佳和第二优的分数。
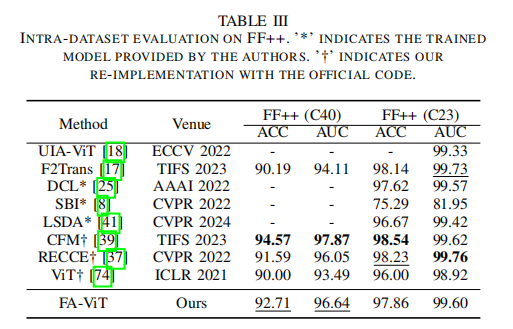
一般来说,在C40压缩数据中删除了许多操作痕迹,这使得它们很难被检测到。在这种具有挑战性的环境下,可以观察到,我们提出的FAViT比大多数以前的艺术有相当大的优势。例如,我们的方法在AUC方面比最近基于vit的模型F2Trans多出了2.53%。当对C23数据进行评估时,所有的SOTA方法都能够实现非常高的检测acc。FA-ViT仍然取得了97.86%的ACC评分和99.60%的AUC评分,证明了其对C23数据的有效性。此外,与ViT基线相比,FAViT在C40设置下将ACC从90.00%提高到92.17%,在C23设置下将96.00%提高到97.86%。
虽然FA-ViT在数据集内评估中获得了令人满意的检测精度,但其性能仍低于CFM
[39]和RECCE
[37]。这一结果可能是由于CFM需要像素级标签来进行监督,而侦察采用了像素级重建任务,使得这些方法对数据集内模式更加敏感。我们将研究其他设计的可能性,以进一步提高数据集内设置的性能。
C. 跨数据集评估
跨数据集评估是一个非常具有挑战性的设置,因为这些数据集中的场景和字符是复杂的,并且与训练数据不同。为了全面评估在不同的不可见数据集上的泛化性能,我们在7个基准数据集上进行了广泛的实验。具体来说,所有的模型都在FF++(C23)上进行训练,并在不可预见的数据集上进行评估: CDF、WDF、DFDC-P、DFDC、DFD、DFR和FFIW。
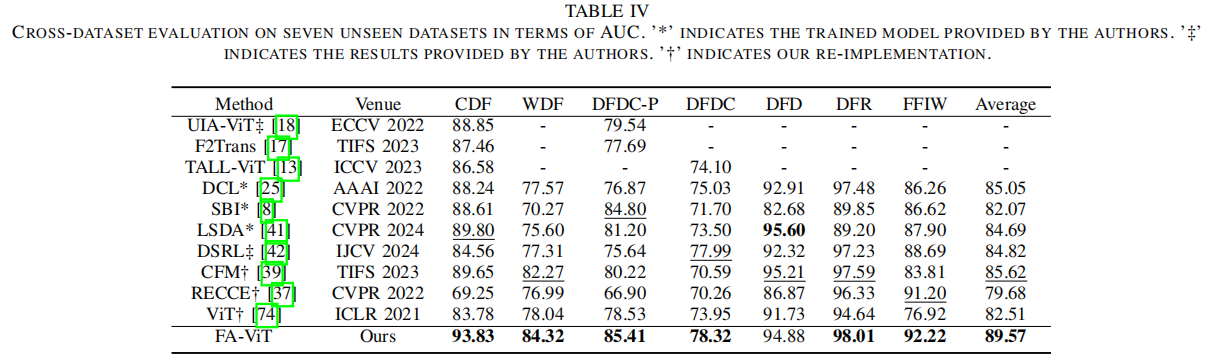
表四说明了在AUC方面的交叉数据集比较结果。与其他基于ViT的CDF方法相比,包括UIA-ViT、F2Trans、TALL-ViT和ViT,我们提出的FA-ViT方法分别优于4.98%、6.37%、7.25%和10.05%。值得注意的是,CFM获得了最好的数据集内性能,但其泛化性能不如我们提出的FA-ViT。此外,与最近的方法LSDA和DSRL相比,我们的FA-ViT在AUC方面分别提高了4.88%和4.75%,突出了其检测看不见的深度假面孔的最先进的泛化能力。总的来说,FA-ViT在所有7个数据集上都表现出了出色的性能,这些发现验证了自适应学习范式对预训练的ViT的有效性。
D. 交叉篡改评估
人脸伪造检测器在新操作方法上的泛化性能在现实应用中非常重要。我们遵循[17],[25]中提出的协议来评估交叉操作性能,其中模型在不同的篡改类型的样本上进行训练,并在未知的篡改方法上进行测试。结果见表五。
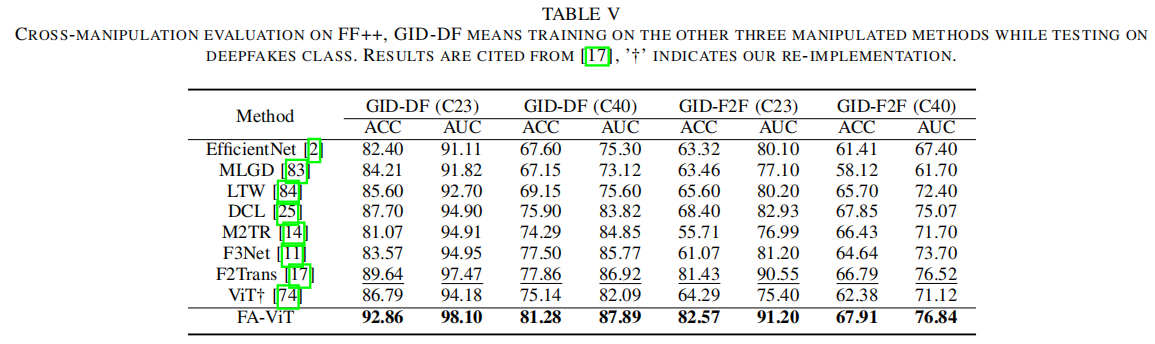
我们提出的方法在交叉操作评估方面取得了优越的性能,分别比GID-DF(C23)的3.22%和GID-DF(C40)的3.42%。值得注意的是,我们观察到完全精细的ViT并不能很好地推广到F2F,而我们提出的FA-ViT在GIDF2F(C23)和GID-F2F(C40)上都取得了实质性的改进,这表明自适应学习策略极大地提高了模型的泛化性能。
E. 对真实世界扰动的鲁棒性
通过在线社交网络传输深度假视频不可避免地会引入各种失真[85],如视频压缩、噪声等。为了研究对不可见扰动的鲁棒性性能,我们遵循了DFR [67]中提出的协议。具体来说,具体来说,不同的扰动应用于DFR的测试集,包括单水平随机类型畸变(std/sing)、随机水平随机类型畸变(std/rand)、三种随机水平随机类型畸变的混合(std/mix混合3)和四种随机水平随机类型畸变的混合(std/mix4)。我们在DFR的原始训练集上训练FA-ViT和ViT。
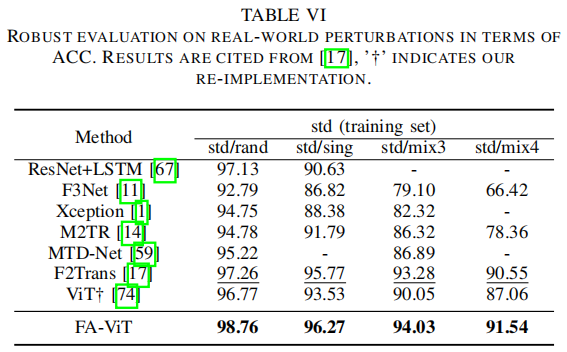
表六说明了在ACC方面的比较结果。我们可以观察到,当对std/mix3和std/mix4设置中的原始输入应用多种类型的扰动时,其他方法会显著降低。例如,ViT在std/rand设置中达到了96.77%,但在std/mix4设置中其性能下降到了87.06%。相比之下,我们提出的FA-ViT在所有失真设置中都获得了最好的性能,在复杂的场景中其性能逐渐下降。主要原因可能是我们在自适应学习过程中保留了预先训练过的ViT特征,因为这些特征在各种扰动[86]下表现出了鲁棒性能。
F. 消融研究
为了分析我们提出的FA-ViT中不同成分的影响,我们通过在FF++(C23)上训练所有变体来进行消融实验。我们给出了FF++的数据集内结果和CDF和WDF数据集的跨数据集结果。为了确保公平的比较,所有的实验都使用相同的随机种子进行。
1)对不同模型自适应的影响
2)GAM的消融:
3)LAM的影响
4)对提出的FAL进行的实验
5)不同参数对FAL的影响
6)零初始化的影响
7)不同的预训练初始化的影响
8)不同的预训练初始化的影响
G. 显著性地图可视化
为了更好地阐明我们的FA-ViT的有效性,我们使用GradCAM++ [92]将模型对深度假脸的注意力可视化,如图10所示。可以观察到,FA-ViT为不同的深度假脸生成了可区分的显著性图,并捕获了方法特有的伪影,如FS的前额区域和F2F的口腔区域。在跨数据集场景中,ViT难以在复杂环境中检测深度造假,如CDF中的大姿态人脸或DFDC中具有挑战性的照明条件。相比之下,FA-ViT在不同的未知数据集上持续地跟踪被操纵的区域,从而从决策的角度验证其有效性。
V. 结论
在本文中,我们从模型自适应的角度提出了一种新的伪造感知自适应自适应视觉变压器(FA-ViT),这在以往的研究中被忽略了。具体来说,在训练过程中设计了全局自适应模块(GAM)和局部自适应模块(LAM),将全局和局部伪造感知信息用于广义表示学习时,保留了预训练后的ViT的表达性。此外,我们还引入了细粒度自适应学习(FAL),以促进细粒度伪造感知信息的自适应学习。总之,我们提出的框架为人脸伪造检测的挑战提供了一个广义和稳健的解决方案。我们相信,我们提出的方法可以为研究界提供有价值的见解,并进一步推进人脸伪造检测系统的发展。