Deep High-Resolution Representation Learning for Human Pose
Estimation
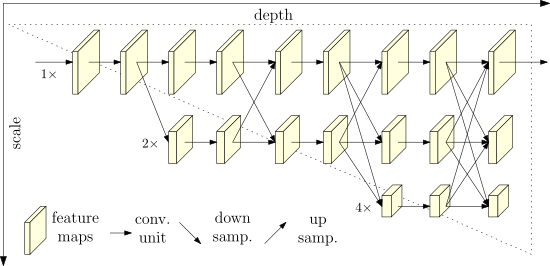
Illustrating the architecture of the
proposed HRNet
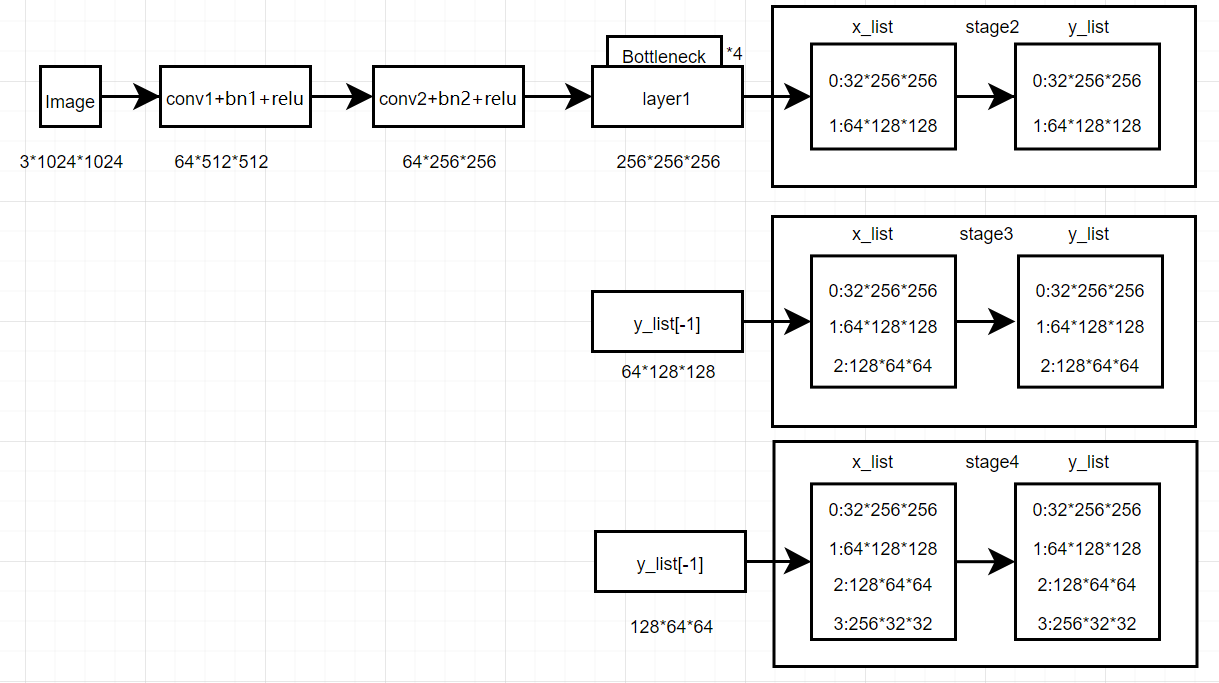
算法流程如下:
architecture
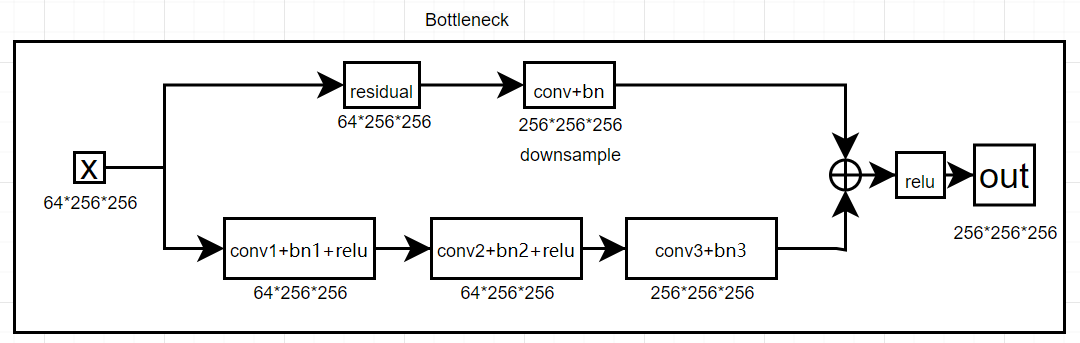
其中Bottleneck的网络如下:
Bottleneck
stage:
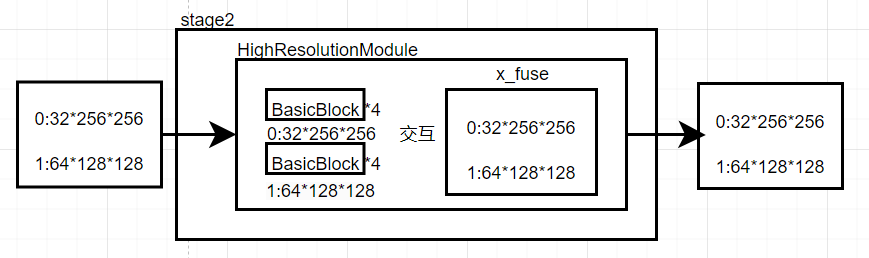
stage2
stage3
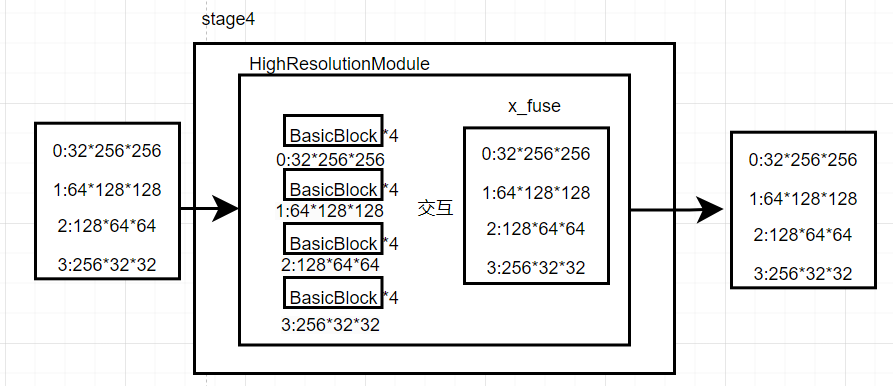
stage4
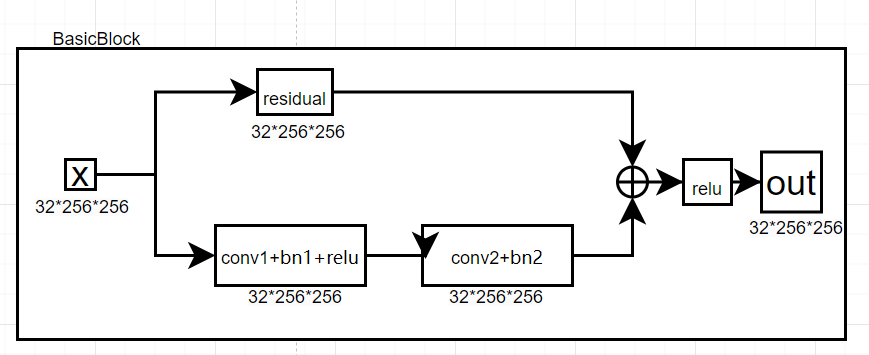
其中BasicBlock的网络如下:
BasicBlock
以下是Hrnet特征间信息交互过程,为x_fuse过程,本身并不改变各个分辨率特征的大小
fuse_layers是hrnet多个不同分辨率特征信息交互的网络,本身并不改变各个分辨率特征的大小
以下为fuse_layers的构造代码:
hrnet:code
num_branches = self .num_branches num_inchannels = self .num_inchannels fuse_layers = [] for i in range (num_branches if self .multi_scale_output else 1 ): fuse_layer = [] for j in range (num_branches): if j > i: fuse_layer.append( nn.Sequential( nn.Conv2d( num_inchannels[j], num_inchannels[i], 1 , 1 , 0 , bias=False ), nn.BatchNorm2d(num_inchannels[i]), nn.Upsample(scale_factor=2 **(j-i), mode='nearest' ) ) ) elif j == i: fuse_layer.append(None ) else : conv3x3s = [] for k in range (i-j): if k == i - j - 1 : num_outchannels_conv3x3 = num_inchannels[i] conv3x3s.append( nn.Sequential( nn.Conv2d( num_inchannels[j], num_outchannels_conv3x3, 3 , 2 , 1 , bias=False ), nn.BatchNorm2d(num_outchannels_conv3x3) ) ) else : num_outchannels_conv3x3 = num_inchannels[j] conv3x3s.append( nn.Sequential( nn.Conv2d( num_inchannels[j], num_outchannels_conv3x3, 3 , 2 , 1 , bias=False ), nn.BatchNorm2d(num_outchannels_conv3x3), nn.ReLU(True ) ) ) fuse_layer.append(nn.Sequential(*conv3x3s)) fuse_layers.append(nn.ModuleList(fuse_layer))
以下为fuse_layers的前向传播代码:
for i in range (len (self .fuse_layers)): y = x[0 ] if i == 0 else self .fuse_layers[i][0 ](x[0 ]) for j in range (1 , self .num_branches): if i == j: y = y + x[j] else : y = y + self .fuse_layers[i][j](x[j]) x_fuse.append(self .relu(y))