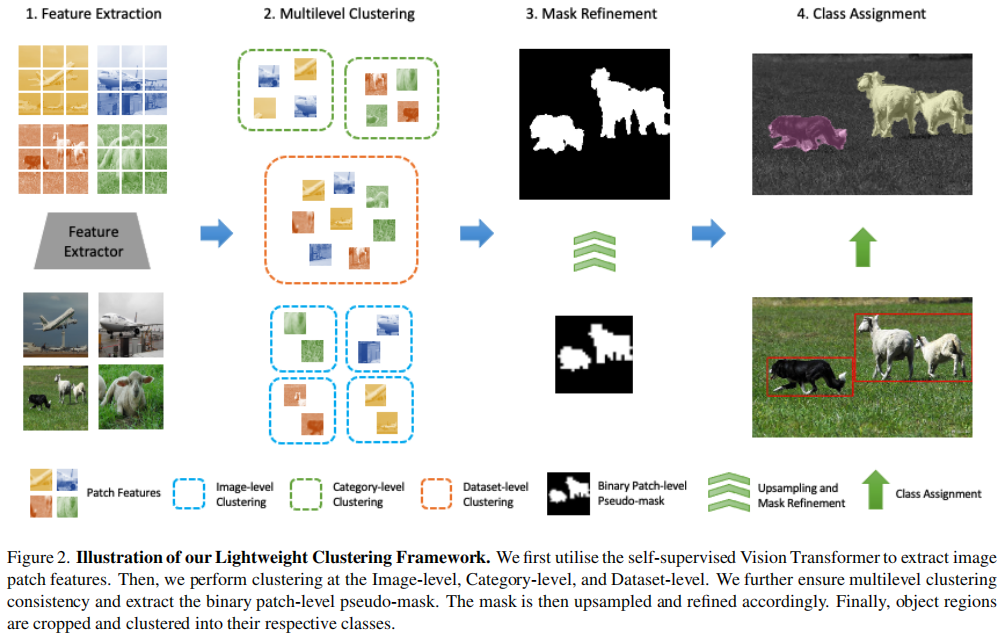
Image Manipulation Detection With Implicit Neural Representation and Limited Supervision
Image Manipulation Detection With Implicit Neural Representation and Limited Supervision
Zhenfei Zhang1 , Mingyang Li2 , Xin Li1 , Ming-Ching Chang1 , and Jun-Wei Hsieh3 1 University at Albany, State University of New York 2 Stanford University 3 National Yang Ming Chiao Tung University {zzhang45, xli48, mchang2}@albany.edu mingyang.li@stanford.edu jwhsieh@nycu.edu.tw摘要
随着篡改技术的发展,图像处理检测(IMD,Image Manipulation Detection)变得越来越重要。然而,大多数最先进的(SoTA,state of-the-art)方法都需要高质量的训练数据集,其中具有图像级和像素级注释。当应用于不同于训练数据的操纵或噪声样本时,这些方法的有效性受到影响。为了解决这些挑战,我们提出了一个统一的框架,结合了无监督和弱监督的方法的IMD。我们的方法引入了一种新的预处理阶段,基于来自隐式神经表示的可控拟合函数(INR,Implicit Neural Representation)。此外,我们引入了一种新的选择性像素级对比学习方法,它只专注于高置信度区域,从而减少了与像素级标签缺失相关的不确定性。在弱监督模式下,我们利用ground-truth图像级标签来指导自适应池化方法的预测,促进了对图像级检测的操作区域的全面探索。无监督模型采用自蒸馏训练方法进行训练,通过不同的来源从最深层获得选择高置信度的伪标签。大量的实验表明,我们提出的方法优于现有的无监督和弱监督的方法。此外,它在新的操作检测任务上有效地与完全监督的方法竞争。
1引言
多种媒体篡改工具的出现,如[10,49,61,64,70,73]psp和人工智能编辑和生成方法,使得操纵媒体内容变得越来越方便。然而,这种可访问性也带来了广泛存在的错误信息的相关问题,这可能导致严重的安全影响。因此,开发和实现鲁棒篡改检测技术,即图像操作检测(IMD)方法,是有效降低这些风险的关键。以前的方法通常处理的基本操作操作如下:
(1)拼接,包括从一个图像中获取内容并粘贴到另一个图像上,(2)复制移动,其中一个图像的部分被复制和重新定位到同一图像中的另一个位置,(3)消除,这需要擦除图像的部分,并用合成内容替换它们。
尽管在完全监督的IMD方法方面取得了重大进展,但他们还是遇到了几个显著的挑战。
首先,这些方法在面对看不见的操作类型时通常表现不佳。
其次,由于它们依赖于具有图像级和像素级注释的高质量训练数据集,因此将它们扩展到看不见的操作类型面临着挑战。获取这样的数据集是昂贵的,而且在许多情况下,是不切实际的,特别是考虑到现实生活中无数种类的篡改方法。
第三,虽然一些语言引导的数据集可能缺乏像素级的标签,但它们在处理现实世界的场景时具有优势。这些数据集可以潜在地增强IMD模型的泛化能力。
为了解决完全监督的IMD方法的局限性,并提高对现实世界使用的泛化能力,我们建议将无监督和弱监督的方法集成到一个统一的IMD框架中。我们的框架允许训练使用单独的图像级标签,甚至没有任何标签,与许多无监督和弱监督的任务[14,30,48,52,56,72,74]对齐。与完全监督的方法相比,我们的方法具有优越的泛化能力,并且可以使用没有注释的数据集进行训练。我们的方法首先观察到,在大多数情况下,被篡改的区域表现出与真实区域的差异,比如颜色和照明的变化,这对需要精确建模区域的拟合函数提出了挑战。[63]的结果表明,隐式神经表示(INR)的可控拟合函数倾向于学习训练图像的平均表示。基于这一见解,我们提出了以下问题作为我们的假设:如果我们只在真实的图像上训练一个INR,拟合函数能有效地表示被篡改区域的特征吗?
为了得到这个问题的答案,我们首先只使用来自CASIAv2
[12]的原始图像来训练一个INR,并使用它来重建三个主流数据集。然后,我们应用完全监督的SoTA方法对重建的数据集进行评估,如图1所示。
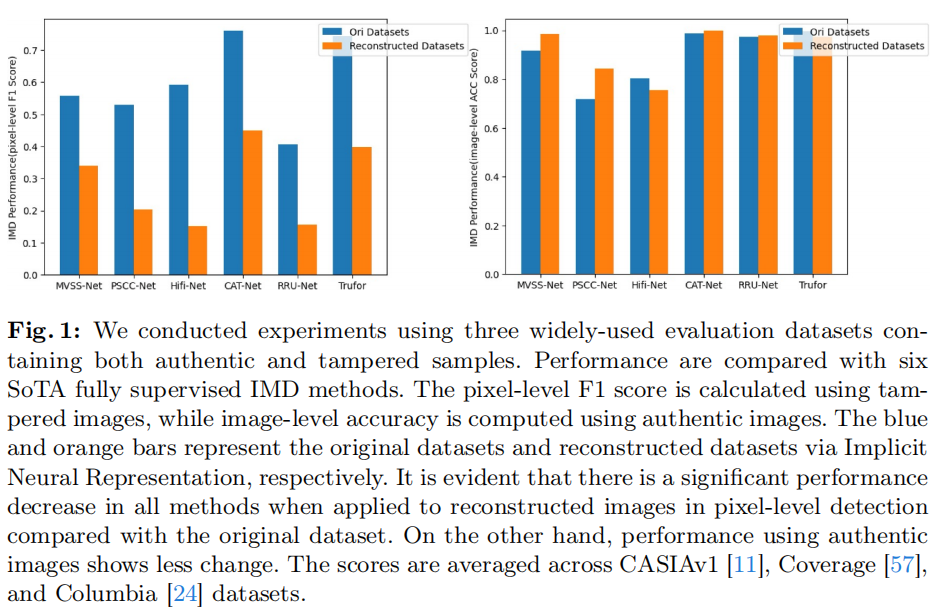
图1:我们使用三个广泛使用的评估数据集,包含真实和篡改样本进行实验。并与六种SoTA全监督IMD方法进行了性能比较。像素级F1得分计算使用篡改图像,而图像级精度计算使用真实图像计算。蓝色和橙色条分别表示通过隐式神经表示的原始数据集和重构数据集。结果表明,与原始数据集相比,所有针对重建图像的像素级检测方法的性能都有显著的下降。另一方面,使用真实图像的性能变化较小。这些分数取了CASIAv1 [11]、Coverage[57]和Columbia[24]数据集上的平均值。
令人惊讶的是,当使用INR重建样本时,这些方法的评价结果显著下降,而在真实图像样本中的性能变化较小。这一结果导致了我们初步假设,即INR可能不能有效地捕获篡改区域的特征。为了验证这一假设,我们计算了图2中重建图像和原始图像之间的重建误差图。

图2:给出了在原始图像和重建图像之间计算的重建误差图的示例。前两行分别描述了数据样本及其对应的ground-truth掩码。前三列显示了被篡改的图像示例,而最后三列显示了真实的图像,其中ground-truth的掩码都是黑色的。显然,重建过程不能正确地重建被篡改的像素,导致错误映射中的激活。相反,在真实的样本中观察到的变化较小。
值得注意的是,我们在被篡改样本的被篡改区域观察到激活,而在真实样本中没有明显的差异。这一观察结果启发我们将INR作为一种预处理方法,并将重建错误图与输入的RGB图像连接起来,然后将其输入给主干。我们将这种预处理方法命名为神经表示重建(NRR,Neural
Representation
Reconstruction)。
在使用INR进行预处理的成功之后,我们进一步探索了我们的发现,并在我们的框架中充分利用了它。从对比学习[22]中获得灵感,我们利用NRR作为对比样本生成器,并引入选择性像素级对比学习,只关注高度自信的区域。该方法有效地减轻了与缺乏像素级标签相关的不确定性,并进一步提高了弱监督性能。我们进一步将我们的方法扩展到一个完全无监督的方法,使用选定的高置信伪标签,使用自蒸馏[69]训练策略。最后,以往的SoTA方法广泛应用于全局最大池(GMP,Global-Max
Pooling)或全局平均池(GAP,Global-Average
Pooling)用于图像级检测。然而,GMP可能会阻碍训练,并导致不准确的预测,因为只有最具区别性的反应是反向传播的,而忽略了整个被篡改的内容。相反,由于GAP的弱激活像素,容易产生不准确性。为了克服这一限制,我们提出了一个自适应的全局平均池,它关注于高置信的篡改区域。因此,我们的方法可以产生更全面和鲁棒的图像级预测。
在7个数据集上进行了实验评估,其中包括5个具有一般操作类型的主流数据集和2个包含不可见的篡改样本的新数据集。结果表明,我们的方法优于SoTA弱监督和无监督方法。此外,在新的操作检测任务中,我们的方法与完全监督的方法相比,取得了具有竞争力的结果。最后,我们的方法可以很容易地扩展到没有像素级标签的数据集,这显示出了增强的通用性。
本文的贡献包括:
(1)我们提出了一种新的方法来实现可信的弱和无监督的IMD结果。我们的方法可以很容易地适应于没有标签或只有图像级标签的图像。
(2)据我们所知,我们是第一个研究内隐神经表征(INR)在IMD任务中的潜力的人。利用INR的预处理步骤证明了处理被篡改案例的有效性。
(3)我们引入了选择性监督,它减少了与没有标签相关的不确定性,并进一步提高了检测性能。
(4)大量的实验验证了我们所提出的方法的有效性,与SoTA方法相比,它在标准和新型操作类型上都具有优越的性能。
2相关工作
3提出的方法
3.1整体架构
图3显示了我们的IMD框架的整体体系结构。
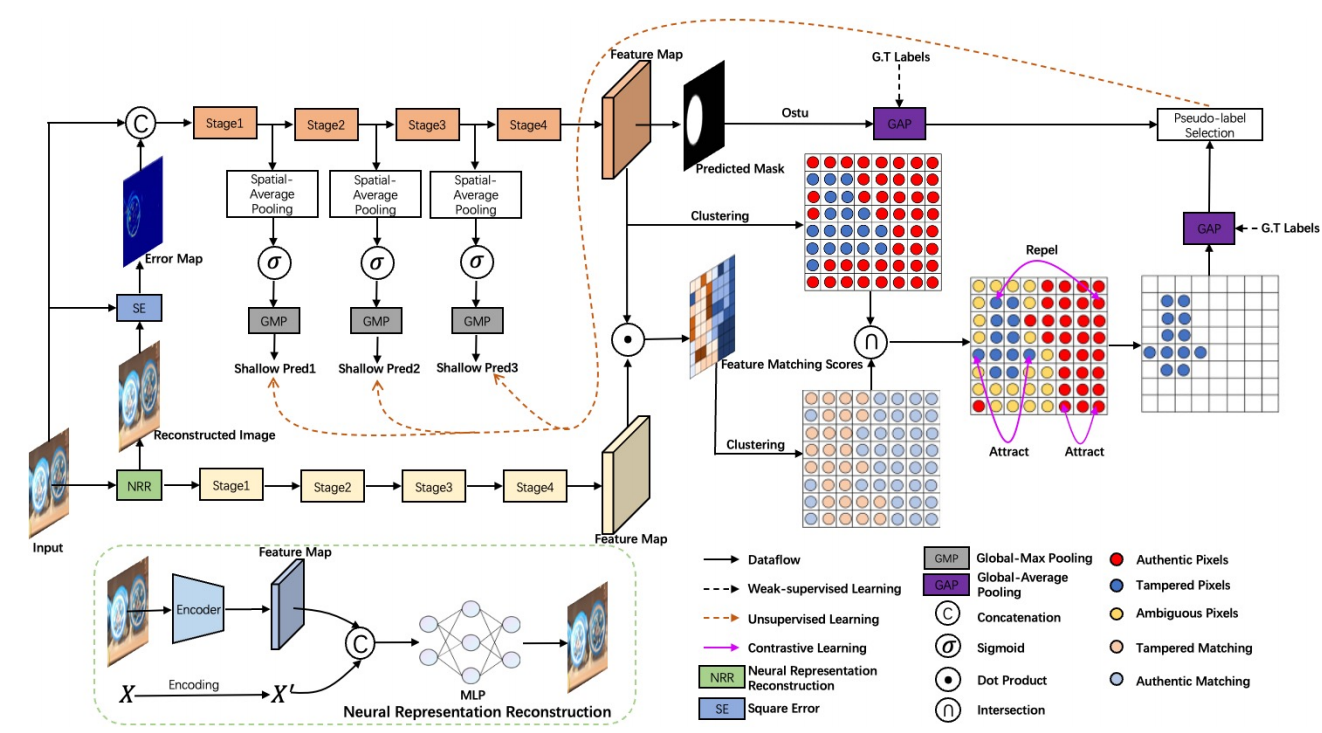

基本架构由两个具有共享权重的分支组成。给定一个RGB图像\[I\in\mathbb{R}^{H\times W\times3}\],其中H和W分别为其高度和宽度,我们首先应用神经表示重建(NRR)将其重建为\[I_R\in\mathbb{R}^{H\times W\times3}\],并在\(I_R\)和\(I\)之间生成重构误差图\[I_E\in\mathbb{R}^{H\times W\times1}\]。然后我们将\(I\)和\(I_E\)连接起来,将它们输入第一个分支,作为主分支。与大多数IMD方法类似,主分支在最终的特征图上使用一个简单的上采样和Sigmoid激活函数生成一个掩模。然后,我们应用Otsu的方法自适应地选择激活的区域进行图像级预测,就像在[65]中所做的那样。将重建的图像\(I_R\)输入第二分支,作为特征匹配的互补分支。经过主干处理后,我们得到了两个特征图\(F\)和\(F_R\)。接下来,我们通过点积计算两个特征映射之间的特征匹配分数\(M\),其中真实像素往往具有更高的匹配分数,反之亦然。对于操作检测的两类分类,对\(F\)和\(M\)应用无监督聚类,然后将两个聚类结果相交,并将像素级对比学习专门应用于更可信的交叉特征。利用所提出的自适应分类结果进行自适应全局平均池,该池集中于高置信篡改区域进行理解图像级预测。在一种弱监督的方式下,应用ground-truth图像级标签来监督预测。在无监督的情况下,从最深层中选择一组高置信的伪标签,通过自蒸馏[69]训练策略来监督浅层预测。通过比较来自Otsu的方法和聚类技术的预测来选择高置信度的伪标签,只选择那些被两个来源一致确定的来源。
3.2神经表征重建NRR
受[63]和图1 2中实验观察结果的启发,我们应用NRR对输入图像进行重构。重构误差可以突出操作跟踪,从而在后续的IMD模型之前提供一个不可或缺的信息。在INR中,首先使用图像编码器将输入图像转换为特征映射\[F_N\in\mathbb{R}^{H\times W\times C}\],其中H和W为高度和宽度,C为特征通道的数量。输入的坐标集可以用\[X\in\mathbb{R}^{H\times W\times 2}\]来表示。我们通过将连接\(F_N\)和\(X\)进行连接,随后将它们输入多层感知器(MLP)进行解码。NRR的表述为: \[I_{R}[x,y]=M L P(F_{N}[x,y],X[x,y]),\] 其中,\(I_{R}\)是从\(I\)重建的RGB像素值,\([x,y]\)是每个像素位置。NRR的主要目标是重构\(I\)的RGB值,用损失函数表述为: \[\mathcal{L}_{N R R}=||I-I_{R}||_{1}\,.\] 请注意,这种重建并不能正确地描述高频像素。因此,我们应用来自[39]的位置编码来将\(X\)映射到一个高维空间。这种位置编码可表示为: \[X^{'}=(\sin(2^{0}\pi X),\cos(2^{0}\pi X),\cdot\cdot\cdot\cdot,\sin(2^{L-1}\pi X),\cos(2^{L-1}\pi X))\] 其中,\(L\)是控制NRR拟合能力的预设定常数。通常情况下,\(L\)越大,拟合就越准确。在我们的任务中,我们的目标是避免来自反映输入的NRR的输出;相反,我们希望NRR忠实地保存正常(真实)内容中的信息,同时在极端(篡改)像素中引入不忠实。我们根据经验选择\(L = 8\)作为最优权衡。
3.3选择性对比学习
从NRR中获得\(I_R\)后,我们使用\(I_E =(I_R−I)^2\)计算\(I\)和\(I_R\)之间的重构误差图。然后,我们连接\(I_E\)和\(I\),增强到主干的第一个(主)分支的输入。对于第二个(互补)分支的输入,我们发送\(I_R\)来进行特征匹配。我们使用ResNet50
[23]作为主干,它由四个阶段组成,匹配以前的弱监督方法。两个分支的权重共享。经过主干网处理后,我们从不同的输入源获得了2个特征输出\(F\)和\(F_R\)。然后,我们使用点积计算特征匹配分数\(M\)为: \[{M}_{x,y}=\sigma\left(\frac{P(F_{R}^{x,y})\cdot
P(F^{x,y})}{\sqrt{C}}\right),\] 其中,\({M}_{x,y}\)是在空间位置\((x,y)\)上的相似度得分。项目头\(P(\cdot)\)包含2个卷积层和ReLU激活层。\(\sigma(\cdot)\)表示sigmoid激活函数,\(\sqrt{C}\)提供归一化。
由于NRR能够正确地再现真实的像素(而不是被篡改的像素),\(M\)中的高匹配分数往往对应于图像的真实部分。相比之下,低分数往往对应于图像的篡改的区域。由于缺乏ground-truth来监督最终特征,我们采用无监督聚类进行类似于[3,37,41,44,47,58]的伪造/原始聚类,并假设元素较少的聚类是被篡改的聚类。这一假设与当前操作数据集的真实情况相一致。原因是,在大多数情况下,被篡改的区域通常比真实的区域要小得多。
理想情况下,我们可以通过InfoNCE
[22]对\(M\)和\(F\)应用像素级对比学习像[58]一样。然而,我们发现这种方法在我们的实验中效果并不好,因为由于缺乏ground-truth掩膜,聚类置信度可能较低。为了解决这个问题,我们对\(M\)和\(F\)的聚类结果相交,并将相交的聚类表示为\(C_1\)。在交集之后,我们将有2个集群,无论其是真实的还是被篡改的,因为它们来自于两个不同来源的相同的预测。因此,我们只将InfoNCE应用于交叉像素进行对比学习,而保持模糊像素不变。这种选择性对比学习损失的表述为:
\[\mathcal{L}_{S C
L}=-\log\frac{\frac{1}{J}\sum_{j\in[1,J]}\exp(q\cdot
k_{j}^{+}/\tau)}{\sum_{i\in[1,K]}\exp(q\cdot k_{i}^{-}/\tau)},\]
其中\(q\)是一个编码查询;\(J\)和\(K\)分别是被选择的正键和负键的数量;\(\tau\)是一个温度超参数。我们将正键\(k_{j}^{+}\)设置为与原始区域相关的像素,而负键\(k_{i}^{-}\)对应于与被篡改区域相关的像素。
3.4自适应全局平均池化AGAP
许多现有的方法使用全局最大池(GMP)和全局平均池(GAP)来进行图像级预测,以确定输入是真实的还是被篡改的。然而,GMP可能会阻碍训练,并导致不准确的预测,因为只有最具区别性的反应是反向传播的,而忽略了整个被篡改的内容。全局平均池(GAP)容易出现由于弱激活像素造成的不准确性。
为了解决这些挑战,我们引入了自适应全局平均池(AGAP),它侧重于高置信度的篡改区域,用于全面的图像级预测。利用两个聚类结果的交集(在第3.3节中讨论),我们首先从聚类的角度将全局平均池(GAP)专门应用于相交的被篡改区域。然而,仅依赖于无监督聚类可能不能保证在没有地面真实标签的所有输入类型上的最佳性能和鲁棒性。正如在[32]中所讨论的,当图像直方图表现为双峰分布时,Otsu的方法表现良好,而聚类提供了灵活性和处理更复杂的直方图的能力。因此,我们结合Otsu和聚类来增强图像级预测和训练的鲁棒性。具体来说,GAP应用于Otsu和交叉聚类结果的篡改响应,用图像级标签进行损失计算。关于Otsu的方法和聚类的进一步细节可以在他们各自的论文[15,43]中找到。
3.5弱监督和无监督的IMD
在弱监督的IMD设置中,我们利用ground-truth图像级标签来监督使用二值交叉熵(BCE)损失的预测训练,即:
\[\mathcal{L}_{B C
E}(g,\hat{g})=-(1-g)\log(1-\hat{g})-g\log(\hat{g}),\]
其中,\(g\)和\(\hat{g}\)分别为ground-truth值和预测得分。以弱监督的方式进行的最终分类损失是两个BCE损失的总和,并将两个池化结果与g进行比较。
在没有使用标签的无监督IMD设置中,我们采用了自蒸馏训练策略[69],使用来自最深层的伪标签作为教师来监督浅层输出。
为了简化浅层的预测结果并减少计算开销,主干每个中间阶段的分类头在信道维度中使用空间平均池,将其重塑为单通道特征图。接下来是一个s型函数和全局最大池化。在传统的自蒸馏方法中,将地面真实损失和自蒸馏相结合可以提高整体性能,但这种方法不适用于无监督的环境。我们的实验表明,仅仅依靠自蒸馏并不能产生令人满意的结果,因为从最深层的输出可能缺乏准确性,阻碍了训练过程和整体性能。
从选择性监督方法[31]中汲取灵感,这被证明在处理噪声标签数据集方面是有效的,我们利用它的概念,基于特征表示和给定标签之间的对齐来选择训练例子。然而,在我们的无监督设置中,标签的缺失带来了一个挑战。为了克服这一障碍,我们比较了Otsu和聚类方法获得的预测,只选择两种来源一致预测的预测作为自蒸馏训练的伪标签。
在伪标签选择中,超过0.5的预测被认为是篡改样本。与弱监督设置类似,我们在选择的伪标签和浅层预测之间使用BCE损失来进行监督。在推理过程中,排除了浅层中的所有分类头,以避免不必要的参数。
训练目标。我们首先将通过\(\mathcal{L}_{NRR}\)训练的NRR作为预训练模型,在IMD训练过程中所有权重冻结。为了简单起见,我们使用符号\(\mathcal{L}_{cls}\)来表示在无监督方法和弱监督方法中进行分类的损失函数,尽管如上所述略有不同。
我们提出的IMD的总损失,记为\(\mathcal{L}_{total}\),是使用BCE损失和选择性像素级对比学习损失的分类损失的加权和:
\[\mathcal{L}_{t o t a
l}=\alpha\mathcal{L}_{c l s}+\beta\mathcal{L}_{S C L}\]
其中,\(\alpha\)和\(\beta\)是加权超参数。
4实验
数据集:我们的模型只使用CASIAv2
[12]进行训练,其中包括7491个真实样本和5063个篡改图像。对于标准IMD任务的评估,我们使用了广泛使用的基准测试,包括CASIAv1
[11]、Coverage[57]、Columbia[24]、IMD2020 [42]和NIST16 [19]。CASIAv1
[11]由拼接和复制移动图像组成。Coverage[57]只包含使用一些后处理方法的复制移动样本。Columbia[24]由363张未压缩图像组成,平均分辨率为938×720。NIST16
[19]和IMD2020
[42]只包含被篡改的图像,适用于像素级评估。这些数据集涵盖了传统的操作类型,包括拼接、复制-移动和删除。对于涉及新的或更复杂的操作类型的评估,我们使用IEdit
[51]和MagicBrush
[68],这是两个语言驱动的数据集,包含各种新的操作类型,如动作变化和光线变化。
评估指标:我们使用IOU和F1分数,包括像素级的F1分数P-F1,图像级的F1分数I-F1,以及组合的F1分数C-F1。C-F1分数通过调和平均值同时统计了像素级和图像级的性能,提供了一个整体的性能比较。所有F1分数和IOU分数均使用0.5作为固定阈值进行计算。由于在IEdit
[51]中缺乏像素级掩模,我们包括图像级ACC以进行额外的评估。
实现细节:我们采用ResNet50
[23]作为骨干,模型使用PyTorch [45]实现,参数随机初始化。我们应用AdamW
[35]作为优化器。NRR中的多层感知器(MLP)遵循三隐藏层架构。NRR训练了120个轮次,初始学习速率为2×10−4,并应用权重衰减。对弱监督模式下的IMD模型进行了50次训练,初始学习率为0.0005,权值衰减。对于无监督模型,我们训练了20个轮次代,初始学习率为0.0001,应用权重衰减。图像增强仅限于随机翻转和裁剪。我们使用固定的阈值0.5从特征映射中提取二进制掩模,与之前的方法一致。弱监督训练的超参数α和β分别设置为1.0和0.1,无监督训练分别设置为1.0和0.3。对于聚类算法,我们使用了K-means
[34]。
4.1与SoTA方法的比较
为了与SoTA方法进行公平的比较,我们选择了源代码是公开可用的方法。应用于比较的无监督方法有NOI
[38]、CFAl [17]、MCA [1]、NoisePrint [9]和IVC [8],而弱监督方法包括FCN
[46]和WSCL
[65]。
此外,我们使用两个新的操作数据集进行了实验,并将我们的方法与完全监督的方法进行了比较,包括RRUNet
[2], Mantra-Net [60], SPAN [25], PSCC-Net [33], Trufor [20], CAT-Net
[29],Hifi-Net [21], CR-CNN [62], ObjectFormer [54], and MVSS-Net
[5]。
与SoTA无监督方法的比较:由于无监督方法假设所有图像都包含篡改部分,他们将所有测试图像分类为篡改。因此,它们不适合进行图像级评估。我们进行了像素级实验,比较了它们定位篡改区域的能力,如表1所示。
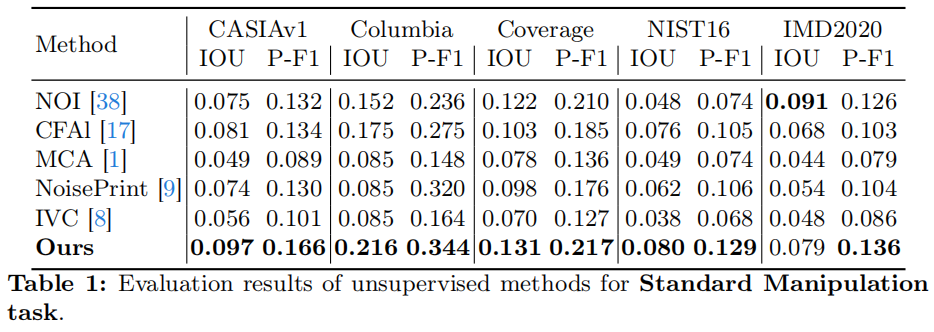
我们可以观察到,在五个广泛使用的标准操作基准中,我们提出的方法在无监督设置中比其他无监督方法获得了最好的检测性能。
与SoTA弱监督方法的比较:表2为弱监督SoTA方法的实验结果。
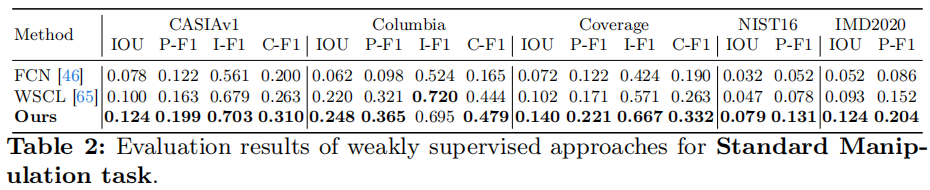
除了在Columbia[24]数据集中的图像级别上的F1(I-F1)得分外,我们的方法在所有其他指标上都优于SoTA方法。与WSCL相比,Columbia的I-F1得分相对较低,我们认为原因是Columbia没有后处理,所以我们的方法可能对篡改不是很敏感。然而,尽管存在这个问题,我们的方法在Columbia数据集中实现了最好的定位性能。
比较使用新的操作数据集:为了显示我们的方法的泛化能力。我们在表3中的两个新的操作检测数据集上使用完全监督和弱监督的方法进行评估。
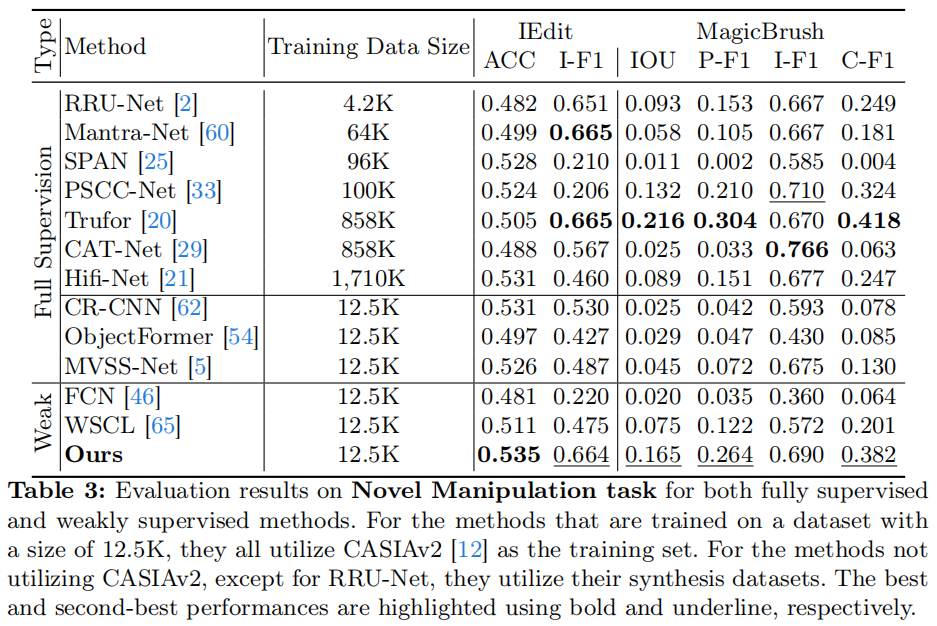
我们可以看到,完全监督的方法不能适应新的操作类型,导致低检测性能,即使它们使用了一个非常大的具有图像级和像素级标签的合成训练数据集。相比之下,我们的方法在使用极少的训练数据而只使用图像级标签的情况下,取得了具有竞争力的性能。
可视化结果:我们在图4中展示了一些与SoTA方法相比的可视化结果。

我们的方法可以更好地定位被篡改的区域,即使没有使用像素级的标签。然而,由于缺乏像素级的标签,我们的模型不能准确地检测到被篡改的边缘。我们的方法的这些结果是由弱监督模型产生的。
4.2消融研究
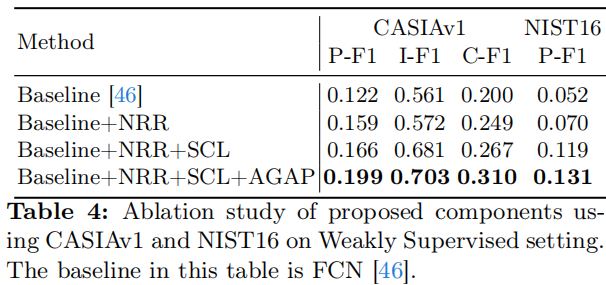
我们进行了几项消融研究来评估每个建议成分的有效性。对于这些研究,我们使用了CASIAv1 [12]和NIST16 [19]数据集。
提出的组件的有效性:我们引入了三个新的组件:使用神经表示重建(NRR)的预处理阶段,选择性像素对比学习(SCL)和自适应全局平均池(AGAP)的非/弱监督IMD。在弱模式下进行的消融研究见表4。很明显,随着我们所提出的模块的逐步集成,模型检测篡改的整体能力不断提高。
伪标签选择(PLS):在我们的无监督方法中,我们引入了PLS,它专门利用来自两个来源的高可信度伪标签来监督自蒸馏训练过程中的浅层预测。表5检查了PLS的影响。
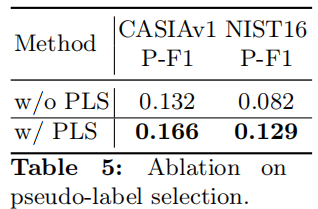
在没有PLS的实验中,我们使用主分支的图像级预测作为伪标签来指导浅层预测。所提出的PLS在提高无监督性能方面是有效的。
自适应全局平均池:为了证明所提出的AGAP的优越性,我们使用不同的池方法在弱监督设置下进行了消融研究,包括全局最大池(GMP)、全局平均池(GAP)、广义平均池(GeM)[50]和全局光滑池(GsM)[55]。结果如表6所示。
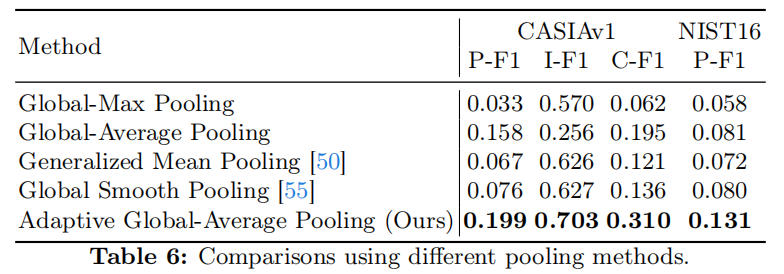
同样,所提出的AGAP也取得了最好的性能,突出了其优越性。
5结论
我们提出了一个新的框架,集成了无监督和弱监督方法的图像操作检测(IMD)。我们的方法具有一个开创性的预处理步骤,利用了一个来自隐式神经表示的可控拟合函数,为其提供了一个操作区域的先验。此外,我们提出了一种选择性像素级对比学习技术,该技术对高可信度的区域进行优先排序,减少了由于缺乏像素级标签而产生的不确定性。对于图像级预测,我们引入自适应全局平均池来彻底探索用于检测和鲁棒训练的操作区域。在无监督模式下,我们实现了伪标签选择,从较深的层中选择高可信度的预测作为伪标签,通过自蒸馏训练方法来监督较浅的层中的预测。大量的实验验证了我们的方法的有效性,证明了比现有的无监督和弱监督的方法更好的性能。值得注意的是,我们的方法在检测新的操作方面与完全监督的方法有效地竞争,展示了其在现实场景中的鲁棒性。
这项工作的局限性包括被篡改区域边缘的不准确定位,导致比ground
truth更大的预测掩模。
未来的工作包括开发更强大的模型和有效的预滤波器,以提高像素级的检测性能。
Acknowledgements:
This work is supported by the DARPA Semantic Forensics (SemaFor) Program
under contract HR001120C0123 and NSF CCSS-2348046.