Robust Image Forgery Detection over Online Social Network Shared Images

摘要
Photoshop和美图等图像编辑软件的滥用,导致数字图像的真实性受到质疑。与此同时,网络社交网络(OSNs)的广泛使用使其成为传输伪造图像、报道假新闻、传播谣言等的主要渠道。不幸的是,osn所采用的各种有损操作,如压缩和调整大小,给实现鲁棒的图像伪造检测带来了巨大的挑战。为了对抗OSN共享的伪造行为,本文提出了一种新的鲁棒训练方案。我们首先对osn引入的噪声进行了彻底的分析,并将其解耦为两部分,即可预测的噪声和看不见的噪声,它们分别建模。前者模拟了所公开的(已知)osn操作所引入的噪声,而后者的设计不仅完成前一个,而且还考虑了探测器本身的缺陷。然后,我们将建模的噪声合并到一个鲁棒的训练框架中,显著提高了图像伪造检测器的鲁棒性。大量的实验结果验证了该方案与几种最先进的竞争对手相比的优越性。最后,为了促进图像伪造检测的未来发展,我们基于四个现有数据集和三个最流行的osn建立了一个公共伪造数据集。所设计的探测器最近在一次证书伪造检测竞赛中排名第一1。源代码和数据集可以在https://github.com/HighwayWu/ImageForensicsOSN上找到
I. 引言
很少有研究明确地解决在普遍存在的OSN平台上针对损耗操作的鲁棒伪造检测的设计。这样的主题非常重要,因为这些有损耗的操作会严重降低检测性能。如图1所示,最先进的算法[42]可以准确地检测到原始伪造文件中的伪造区域;但在处理通过脸书传输的伪造文件时,检测性能会严重下降。
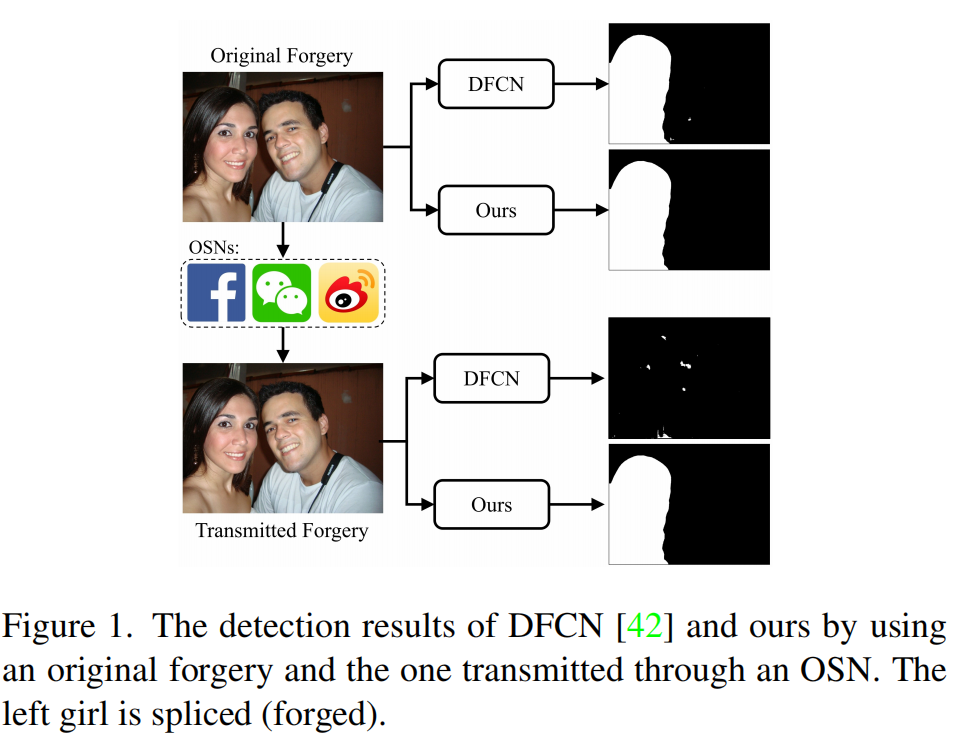
为了减轻OSN的负面影响,第一个关键问题是分析和建模由OSN有损信道引入的噪声。然而,这是一个相当不同的问题,主要是因为当前的平台没有披露操纵传输图像的过程。虽然[33,34]透露了osn采用的部分操作,但仍有许多未知的操作,例如Facebook中的增强过滤。更重要的是,osn经常调整它们的图像处理管道,这使得建模更具挑战性。
针对上述挑战,本文设计了一种鲁棒的图像伪造检测方法,以击败osn中的有损操作。具体来说,为了处理OSN的退化,我们提出了一种噪声建模方案,并将模拟噪声集成到一个鲁棒的训练框架中。我们将OSN噪声解耦为两个组成部分:
1)可预测的噪声和2)看不见的噪声。前者被设计用于模拟已知操作(如JPEG压缩)所带来的可预测损失,其建模依赖于带有残差学习的深度神经网络(DNN)和嵌入的可微JPEG层。而后者主要是针对osn所采取的不可知的行动和/或各种osn的训练和测试之间的差异。显然,从信号本身的角度来看,为看不见的噪声建立一个合适的模型是不现实的。为了解决这个困难,我们将我们的观察结果从噪声的角度转移到伪造检测器上,只关注可能导致检测性能下降的噪声。这种策略自然地孵化了一种新的算法,利用对抗噪声[35]的核心思想来建模看不见噪声,它本质上是难以察觉的扰动,会严重降低模型性能。结果表明,我们的鲁棒图像伪造检测方法具有优越的鲁棒性,性能优于几种先进的算法。我们的方案的检测结果的一个例子如图1所示。最后,我们基于四个现有的数据集[1,6,14,17]和三个OSN平台(脸书、微博和微信),构建了一个包含5000多个项目的公共伪造数据集。我们的主要贡献可以总结如下:
- 我们提出了一种新的训练方案来对抗osn上传输的鲁棒图像伪造检测。该训练方案不仅对osn引入的可预测噪声进行建模,还结合了看不见噪声进一步提高鲁棒性。
- 与几种最先进的方法[12,27,37,42]相比,我们的模型取得了更好的检测性能,特别是在对抗osn传输的场景中。
- 我们基于四个现有的数据集[1,6,14,17]和三个平台(脸书、微博和微信)建立了一个公共伪造数据集。
本文的其余部分组织如下。第2部分回顾一下相关的工作。第3部分通过提出的鲁棒训练策略,详细介绍了鲁棒图像伪造检测。实验结果见第4部分和第5部分。
2.相关工作
2.1.图像伪造检测
许多取证方法(例如,[2、3、5、7、8、18-23、26、36、39、40])已经被提出来验证数字图像的真实性。这些方法通过特定的伪影来检测锻造区域,如拼接[18,26]、复制移动[23,39]、中值滤波[8,20]、插入绘画[21,22,36]等。为了更好地适应实际需求,越来越多的方法被开发来解决检测一般(复合)类型的伪造[4,5,11,12,27,37,41,42]的问题,其中基于深度学习的方法是最成功的。沿着这条线,Wu等人[37]提出了一种一般的伪造检测网络MT-Net,该网络首先提取图像处理特征,然后识别异常区域。Mayer和Stamm最近,[27]引入了法医相似性,以确定两个图像补丁是否包含相同的法医痕迹。从相机指纹的角度来看,科佐利诺和维多里瓦·[12]设计了一种提取相机模型指纹的方法,称为噪声指纹,以揭示伪造的区域。为了学习通用伪造的痕迹,Zhuang等人[42]使用了使用ps脚本的训练数据生成策略。
2.2.在线社交网络(OSN,Online Social Network)
Facebook、Wechat、Weibo等各种OSN平台的普及,大大简化了图片的传播和共享。然而,正如许多现有的作品[33,34]所表明的那样,几乎所有的osn都以一种有损的方式操作上传的图像。这些有损操作所带来的噪声会严重影响法医方法的有效性。以在[32–34]中发现的Facebook为例,这些操作主要包括三个阶段:调整大小、增强过滤和JPEG压缩。具体来说,如果图像的分辨率高于2048像素,则将应用调整大小。然后,对图像中一些选定的块进行高度自适应和复杂的增强滤波。正如在[33,34]中提到的,由于这些增强过滤操作的适应性,要精确地了解它们是非常具有挑战性的。最后,对图像进行一轮JPEG压缩,并根据图像内容自适应地确定一个质量因子(QF)。通过对[33]中提供的数据集的分析,Facebook使用的QF值范围从71到95。尽管在不同的OSN平台上的图像操作是不同的,主流osn进行的操作仍然有许多相似之处(例如,无处不在的JPEG压缩)[33]。
一些现有的取证[9,24,38]被设计用来识别所涉及的传输操作。Liao等人[9,24]首先提出了一种基于盲信号分离的两种操作识别的特征解耦方法。为了进一步揭示一个长链,You等人的[38]提出了一个解决方案,通过创新性地将操作链检测表示为一个机器翻译问题。
([38]
J. You, Y. Li, J. Zhou, Z. Hua, W. Sun, and X. Li. A transformer based
approach for image manipulation chain detection. In ACM Int. Conf.
Multimedia, pages 3510–3517. ACM, 2021. 3)
3.针对通过osn进行传输的鲁棒图像伪造检测
在本节中,我们将详细介绍针对osn上传输的鲁棒图像伪造检测方案。导致成功的关键技术是适当地建模osn导致的退化,并将这些知识集成到一个鲁棒的训练框架中。从第2部分第二小节得知,OSN中的图像处理操作相当复杂;其中一些可以精确地知道,而另一些只能部分已知,甚至完全未知。因此,我们建议将OSN噪声分为两种类型:
1)可预测噪声和2)不可见噪声。前一种类型对应于退化源被明确识别的情况。而后一种类型是各种噪声不确定性的组合,包括未知的建模/参数,训练和测试osn之间的差异,甚至是一些完全看不见的退化源。通过在训练阶段添加建模的OSN噪声,检测器有望学习到更广义的特征,能够在OSN传输中存活下来,从而显著提高整体伪造检测性能。
在图2中,我们说明了我们的伪造检测鲁棒训练方案的框架,它包括四个阶段。
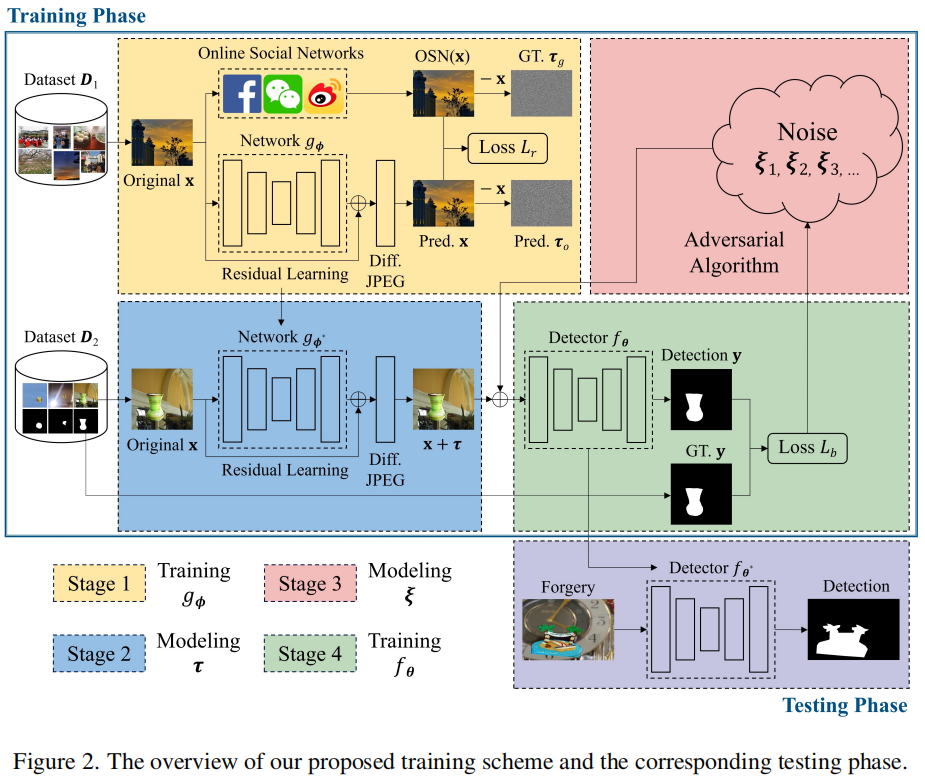
粗略地说,阶段1和阶段2是专门通过一个可微的网络来模拟可预测的噪声。第三阶段处理通过对抗性噪声产生策略对看不见噪声的建模。最后,阶段4处理了图像伪造检测器\(f_{\theta}\)的实际鲁棒训练。请注意,我们的鲁棒训练方案可以与任何基于深度学习的图像伪造检测器相结合。由于这项工作的重点更多的是在鲁棒的训练上,我们在下面将我们的注意力限制在1-3阶段,而留下\(f_{\theta}\)的细节在第4部分第1小结陈述。
形式上,设\(\tau\)和\(\xi\)分别表示可预测噪声和不可见噪声,因此在鲁棒训练阶段考虑的复合噪声变为
\[\delta=\tau+\xi.\]
对于每次训练迭代,我们首先采样两个原始的3通道(RGB)彩色图像\(\{\mathbf{p}_1,\mathbf{p}_2\} \in
\mathbb{R}^{H\times W\times3}\)和一个二进制掩码\(\mathbf{y}\in\{0,1\}^{H\times\dot{W}\times1}\)其中,1代表伪造的区域,0代表其他地方。然后一个伪造的图像x可以被合成为
\[\mathbf{x}=\mathbf{p}_1\odot(1-\mathbf{y})+\mathbf{p}_2\odot\mathbf{y},\]
其中,\(\odot\)表示元素级别的乘法。在拥有一对伪造的图像和相应的ground-truth掩膜后,我们可以创建一个数据集\(\mathcal{D}=\{(\mathbf{x}_i,\mathbf{y}_i)\}_{i=1}^N\)用于训练,其中,\(i\)是训练样本的索引。在复合噪声\(\delta\)下,图像伪造检测器\(f_{\theta}\)的鲁棒训练可以表述为: \[\arg\min_{\boldsymbol{\theta}}\frac{1}{N}\sum_{i=1}^{N}\mathbb{E}_{P(\boldsymbol{\delta})}\Big\{\mathcal{L}_{b}(f_{\boldsymbol{\theta}}(\mathbf{x}_{i}+\boldsymbol{\delta}),\mathbf{y}_{i})\Big\},\]
式中,\(P(\boldsymbol{\delta})\)表示复合噪声\(\delta\)的分布,N为训练样本数,\(\mathcal{L}_{b}\)为二值交叉熵(BCE)损失。
在我们的噪声模型中,我们考虑了一个相当一般的设置,即两个噪声分量\(\tau\)和\(\xi\)是相关的。然后,采用鲁棒训练方案的等式(3)可以进一步写成:
\[\arg\min_{\boldsymbol{\theta}}\frac{1}{N}\sum_{i=1}^{N}\mathbb{E}_{P(\boldsymbol{\tau})}\Big\{\mathbb{E}_{P(\boldsymbol{\xi}|\boldsymbol{\tau})}\{\mathcal{L}_{b}(f_{\boldsymbol{\theta}}(\mathbf{x}_{i}+\boldsymbol{\tau}+\boldsymbol{\xi}),\mathbf{y}_{i})\}\Big\},\]
其中,\(P(\boldsymbol{\tau})\)为\(\tau\)的边缘分布,\(P(\boldsymbol{\xi}|\boldsymbol{\tau})\)为给定\(\tau\)的\(\xi\)的条件分布。从实现的角度来看,在有足够数量的噪声样本时,可以有效和准确地计算出这些期望值。为了进行等式(4)的稳健训练,一个关键的任务是建模边缘分布\(P(\boldsymbol{\tau})\)和条件分布\(P(\boldsymbol{\xi}|\boldsymbol{\tau})\)。
3.1.建模分布\(P(\boldsymbol{\tau})\)
我们现在对分布\(P(\boldsymbol{\tau})\)进行建模,其中的退化是由OSN平台的有损操作引起的。从第2部分第2小节,我们知道\(\tau\)的主要衰退源头是应用的JPEG压缩,而后处理(如增强滤波)也部分地影响了\(\tau\)。对于一个图像\(\mathbf{x}_i\)和一个固定的OSN平台,所产生的噪声可以很容易地计算出来:
\[\tau_i=\mathrm{OSN}(\mathbf{x}_i)-\mathbf{x}_i,\]
其中函数\(OSN(\cdot)\)反映了给定OSN平台进行的所有操作。请注意,\(\tau_i\)依赖于\(\mathbf{x}_i\),即噪声是依赖于信号的。通过这种方式,我们似乎可以生成大量的噪声样本,这可以用来模拟\(P(\boldsymbol{\tau})\)的分布。然而,在实践中,这种简单的建模方案是相当有问题的。处理后的图像\(\mathrm{OSN}(\mathbf{x}_i)\)必须通过将\(\mathbf{x}_i\)上传到特定的OSN平台,然后下载来获得。一方面,这种程序很耗时间;另一方面,许多osn平台不允许过多地上传/下载操作。例如,如果在短时间内观察到太多的上传操作,Weibo甚至会禁止该账户。这严重限制了所获得的噪声样本的数量,使得这种幼稚的方案在实践中非常无效。
为了解决这一挑战,我们采用了另一种策略,以一种不明确的方式建模\(P(\boldsymbol{\tau})\)。我们提出使用一个替代的深度网络来模拟OSN的操作,以便方便地产生大量的噪声样本\(\tau_i\)。具体来说,为了与OSN平台上的图像处理管道保持一致,我们训练了一个DNN模型,该模型显式地嵌入了一个可微层来描述JPEG压缩。对于输入图像\(\mathbf{x}_i\),我们的目标是学习一个映射\(g_{\boldsymbol{\phi}} : \mathbb{R}^{d} \to
\mathbb{R}^{d}\),其中,\(g_{\boldsymbol{\phi}}\)是一个具有可训练参数\(\phi\)的网络,用于预测了OSN的输出。我们为了\(g_{\boldsymbol{\phi}}\)使用了U-Net架构[28],因为它本质上是一个图像到图像的映射。训练过程如图2的第一阶段所示,然后在第二阶段使用训练良好的\(g_{\boldsymbol{\phi^*}}\)来建模\(P(\boldsymbol{\tau})\)。在训练阶段,我们以离线方式收集输入图像\(\mathbf{x}_{i}\in\mathbb{R}^{d}\)和OSN传输版本\(\mathrm{OSN}(\mathbf{x}_i)\in\mathbb{R}^d\)。训练\(g_{\boldsymbol{\phi}}\)的目标函数可以表示为:
\[\min_{\boldsymbol{\phi}}\Big\{\mathcal{L}_r(g_{\boldsymbol{\phi}}(\mathbf{x}_i),\mathrm{OSN}(\mathbf{x}_i))\Big\},\]
其中,\(\mathcal{L}_{r}(\mathbf{x},\mathbf{y})=\|\mathbf{x}-\mathbf{y}\|_{2}\)。
由于我们更感兴趣的是学习由OSN传输产生的噪声,而不是图像内容本身,我们在设计\(g_{\boldsymbol{\phi}}\)时采用了一个残差学习结构[16]。考虑到这一点,我们将目标函数更改为:
\[\min_\phi\Big\{\mathcal{L}_r(\mathbf{x}_i+g_\phi(\mathbf{x}_i),\mathrm{OSN}(\mathbf{x}_i))\Big\}.\]
残差学习有利于模型的优化,显著提高了建模性能。
此外,我们明确地将一个特殊的JPEG层集成到模型中,以便更好地生成结构性的、类似于JPEG的工件,这反映了各种OSN平台中的真实情况。实现了等式(7)中目标函数的端到端优化,我们需要确保JPEG压缩的每一步都是可微的。很容易发现量化是唯一不可微的步骤,主要是因为所采用的舍入函数\(\left\lfloor\cdot\right\rceil\)到处都有0的导数。为了处理它,我们用可微版本[31]来近似舍入函数:
\[\lfloor x\rceil_a=\lfloor
x\rceil+(x-\lfloor x\rceil)^3.\]
一旦有了一个可微的JPEG层,训练\(g_{\boldsymbol{\phi}}\)的目标函数就变成了:
\[\min_\phi\mathcal{L}_r(\mathcal{J}_q(\mathbf{x}_i+g_\phi(\mathbf{x}_i)),\mathrm{OSN}(\mathbf{x}_i)),\]
其中,\(\mathcal{J}_q\)表示具有给定QF
q的可微JPEG层。在我们的训练中,q在Facebook采用的[71,95]范围内均匀采样。然后就可以直接推导出噪声\({\tau}_i\)为 \[\tau_i(q)=\mathcal{J}_q(\mathbf{x}_i+g_{\boldsymbol{\phi}^*}(\mathbf{x}_i))-\mathbf{x}_i,\]
其中,通过求解优化问题等式(9)得到\(\phi^{*}\),q是与JPEG压缩相关联的QF。然后实现蒙特卡罗(MC,Monte
Carlo)采样方案,生成大量的噪声样本,用于对分布\(P(\boldsymbol{\tau})\)进行建模。
3.2.建模条件分布\(P(\boldsymbol{\xi}|\boldsymbol{\tau})\)
然后,我们解决条件分布\(P(\boldsymbol{\xi}|\boldsymbol{\tau})\)的建模问题,从而可以解决等式
(4)中的优化问题。我们加入噪声术语\(\xi\)的原因是,可预测的噪声\(\tau\)不能完全捕获在实践中遇到的噪声行为。例如,不同的osn可能采用不同的过程,如,动态调整QF,自适应地调整大小,甚至引入完全未知的操作。
现在的一个关键问题是如何为看不见的噪声\(\xi\)建立一个适当的模型。显然,就像我们在第3部分第1小节中所做的那样,从信号本身的特征来建模\(\xi\)是不现实的。为了解决这一挑战,我们通过研究噪声对检测性能的影响,将我们的位置从噪声方面转移到检测器\(f_{\theta}\)方面。在各种潜在的不可见噪声\(\xi\)中,我们实际上只需要注意那些降低检测性能的噪声,而忽略了那些对检测影响很小的噪声。这促使我们在建模\(P(\boldsymbol{\xi}|\boldsymbol{\tau})\)时使用一种对抗性噪声[35]。从本质上讲,对抗性噪声通常是人类感官难以感知,但同时能够引起严重的模型输出错误。与此同时,我们所关注的看不见的噪声\(\xi\)是一个能够欺骗探测器的噪声,而且通常也很小(一个高度失真的图像会偏离伪造的目的)。这种与检测器\(f_{\theta}\)效果的相似性使得对抗性噪声成为建模\(\xi\)的合适候选噪声。
从对抗性的角度来看,有各种方法来定义噪声\(\xi\),只要通过添加噪声\(\xi\)来创建的对抗性例子,就会跨越决策边界。注意到噪声\(\xi\)通常振幅较小,我们提出沿着相对于输入代价函数的梯度设置\(\xi\)的方向,以使噪声能量最小化。因此,对于给定的输入\(\mathbf{x}_i\)、可预测噪声\({\tau}_i\)和目标输出\(\mathbf{y}_i\),将不可见噪声\(\xi_i\)表示为 \[\boldsymbol{\xi}_{i}=\mathcal{S}(\nabla_{\mathbf{x}_{i}}\mathcal{L}_{b}(f_{\boldsymbol{\theta}}(\mathbf{x}_{i}+\boldsymbol{\tau}_{i}),\mathbf{y}_{i})),\]
其中,\(\mathcal{S}\)返回梯度的符号。通过在训练过程中加入这些对抗性噪声,期望使学习到的模型不仅对特定的对抗性噪声,而且对更一般的不可见噪声具有鲁棒性。
然而,由等式(11)计算出的噪声依赖于特定的输入\(\mathbf{x}_i\),而不是适用于训练集中所有示例和未知示例的一般输入。为了全面提高检测器的泛化能力,我们提出将对抗性噪声的方向调整为一个全局梯度方向。为此,我们采用了一种类似于随机梯度下降(SGD,Stochastic
Gradient
Descend)[30]的策略,通过从训练数据集的随机子集中随机选择的随机近似方法。更具体地说,对于第\((t+1)\)个输入\(\mathbf{x}_{t+1}\),\({\xi}_{t+1}\)(\(\tau\)条件)可以设置为从第一个t输入计算出的平均梯度,即:
\[\xi_{t+1}=\frac{1}{t}\sum_{i=0}^{t}\mathcal{S}(\nabla_{\mathbf{x}_{i}}\mathcal{L}_{b}(f_{\boldsymbol{\theta}}(\mathbf{x}_{i}+\boldsymbol{\tau}_{i}+\boldsymbol{\xi}_{i}),\mathbf{y}_{i})),\]
其中,\({\xi}_{0}\)被初始化为0。虽然等式(12)可以用来估计平均梯度,但是它只反映了特定的已知数据(训练数据)的梯度。为了缓解上述问题,进一步提高鲁棒性,我们提出在小范围内扰动\({\xi}_{t+1}\)。在这里,使用参数模型来描述平均梯度会更理想。为了找到一个合适的平均梯度模型,我们首先采用数据驱动的方法,分析从训练过程中随机选择的1000个\(\xi\)的样本的统计数据。在图3中,我们使用t-SNE
[13]在一个二维空间中可视化了这些1000个随机样本。
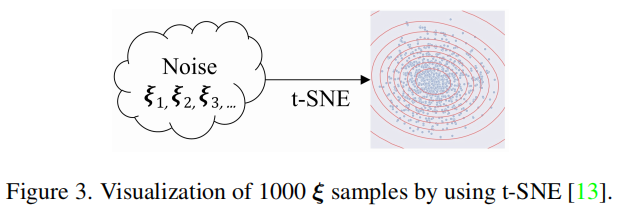
可以看出,样本点集中在某一中心周围,当它们离开该中心时逐渐消失。这一现象建议我们使用高斯分布来建模平均梯度,即:
\[\xi_{t+1}|\tau\sim\mathcal{N}(\boldsymbol{u}_{t+1},\sigma^2\mathbf{I}),\]
其中,\(\sigma\)是一个控制方差的经验集参数, \[\boldsymbol{u}_{t+1}=\epsilon\cdot\frac1t\sum_{i=0}^t\mathcal{S}(\nabla_{\mathbf{x}_i}\mathcal{L}_b(f_{\boldsymbol{\theta}}(\mathbf{x}_i+\boldsymbol{\tau}_i+\boldsymbol{\xi}_i),\mathbf{y}_i)),\]
而\(\epsilon\)是一个用于约束扰动大小的参数,以避免不必要的模型退化。
在等式(13)中使用参数化模型后,我们可以很容易地生成噪声样本来建模条件分布\(P(\boldsymbol{\xi}|\boldsymbol{\tau})\)。因此等式(4)可以扩展为
\[\min_{\boldsymbol{\theta}}\sum_{i=1}^N\sum_{j=1}^m\sum_{k=1}^h\mathcal{L}_b(f_{\boldsymbol{\theta}}(\mathbf{x}_i+\boldsymbol{\tau}_j+\boldsymbol{\xi}_k),\mathbf{y}_i),\]
其中,关于的期望分别近似于m和h
MC样本。有了这个可计算的损失函数,我们就能够执行鲁棒训练,如算法1所示。

4.实验结果
在本节中,我们给出了实验结果,以证明我们所提出的方法的优越的性能。由于空间的限制,在补充文件中给出了更多的结果。
4.1.实验设置
基线检测器
该检测器的目标是在像素级的精度上检测伪造区域。具体来说,检测器\(f_{\boldsymbol{\theta}}: \mathbb{R}^{H\times W\times3}\to\mathbb{R}^{H\times W\times1}\)以分辨率为H×W的彩色图像作为输入,最终输出检测结果的二进制图。在我们的设置中,我们在基线检测器中采用了U-Net [28]架构。为了提高提取伪造相关特征的能力,我们通过合并空间信道“Squeeze-and-Excitation(SE)”机制[29]进一步增强了架构,产生了一个称为SE-U-Net的变体,而不是简单地使用传统的普通U-Net。
训练/验证数据集
对于OSN网络\(g_{\boldsymbol{\phi}}\)的训练,我们采用了数据集\(\mathbf{WEI}\)(记为\(\mathcal{D}_{1}\))[33],该数据集包含了1300多张原始图像及其处理后的版本。需要注意的是,我们只使用来自Facebook的数据来培训\(g_{\boldsymbol{\phi}}\)。而对于\(f_{\boldsymbol{\theta}}\)的训练,我们使用\(\mathbf{Dresden}\)[15]数据集作为原始图像的来源。然后,我们通过将原始图像与来自\(\mathbf{MS-COCO}\) [25]数据集中的对象拼接来生成伪造的图像。这些伪造图像的数据集记为\(\mathcal{D}_{2}\)。\(\mathcal{D}_{1}\)和\(\mathcal{D}_{2}\)随机分为训练集和验证集,比例为9: 1。
测试数据集
我们通过采用四种广泛使用的数据集(\(\mathbf{DSO}\)[6],\(\mathbf{Columbia}\)[17],\(\mathbf{NIST}\)[1]和\(\mathbf{CASIA}\)[14])创建测试数据集,并生成它们的OSN传输版本。更具体地说,我们通过三个最流行的OSNs(Facebook、Wechat和Weibo)手动上传和下载上述数据集,得到了5232个伪造的数据集和相应的掩码。这些收集到的数据集可以在https://github.com/HighwayWu/ImageForensicsOSN上获得我们希望这些数据集可以作为我们的研究社区的有用的基准,以对抗在osn上共享的伪造品。
对比网络
我们将我们提出的方案与四种最先进的方法进行了比较:\(\mathbf{MT-Net}\) [37]、\(\mathbf{NoiPri}\) [12]、\(\mathbf{ForSim}\) [27]和\(\mathbf{DFCN}\) [42]。
4.2.定量比较
在像素域上的AUC、F1和IoU(越高越好)的定量比较见表1。
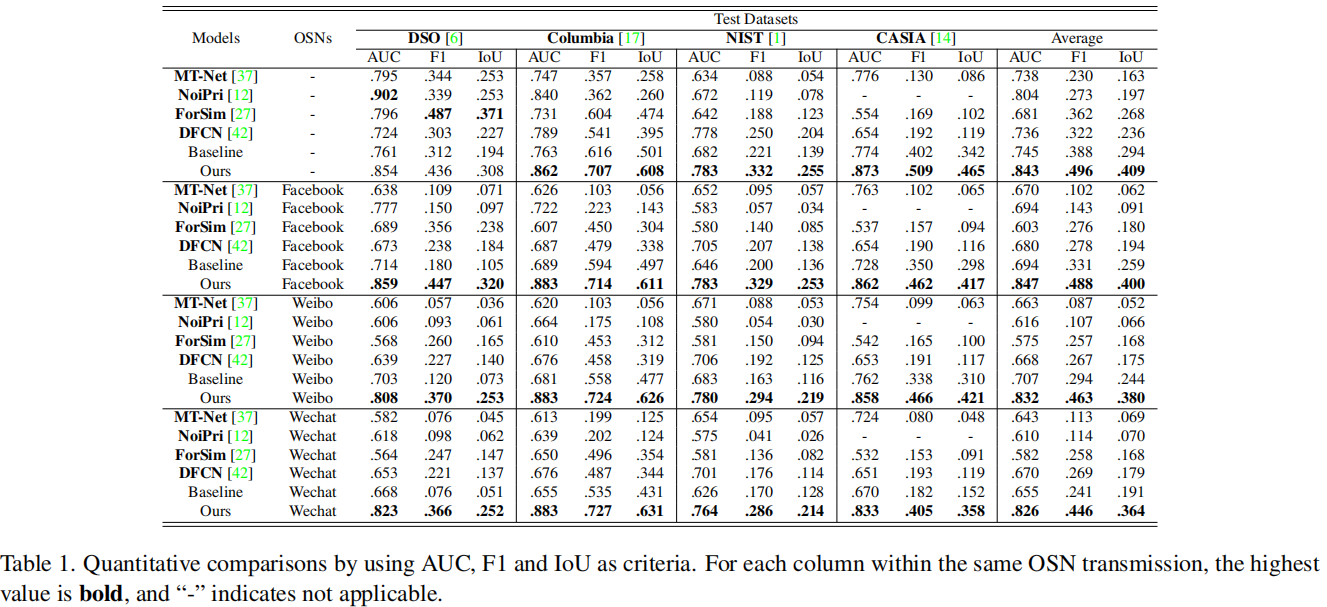
表1.以AUC、F1、IoU为标准的定量比较。对于同一OSN传输中的每一列,最高值为粗体,“-”表示不应用。
在这里,我们还报告了基线检测器的结果,以一种比较的方式证明了我们的鲁棒训练方案的改进。可以观察到,当伪造图片不通过OSN传输时,ForSim
[27]、DFCN [42]和我们的检测方法获得了类似的结果,而MT-Net [37]和NoiPri
[12]的表现略差。需要注意的是,由于NoiPri的分辨率小,不能用于检测CASIA中的伪造,而我们的方法没有这样的限制,在CASIA上比其他竞争对手表现更好。
在伪造图片通过osn的情况下,所有现有方法的检测性能都显著下降。例如,在通过Facebook、Weibo和Wechat传播后,与没有OSN传输的情况相比,与MT-Net相关的IoU得分分别下降了10.1%、11.1%和9.4%,相比之下,由于\(\tau\)和\(\xi\)的适当的噪声建模,我们提出的方法对OSN传输表现出相当理想的鲁棒性,并且仍然能导致准确的伪造检测。以Facebook为例,IoU的降幅仅为0.9%。我们也可以注意到,Weibo和Wechat的伪造检测性能下降略大,分别下降了2.0%和4.5%。这主要是因为,与Facebook相比,Weibo和Wechat对上传的图片采用了更严格的压缩,导致了更多的证据丢失。另外,为了训练我们的方法,我们只使用Facebook数据,根本没有任何Weibo和Wechat数据。从表1,我们可以看到使用Facebook数据训练的方案可以很好地推广到Weibo和Wechat传输的伪造上。
4.3.定性比较
除了定量比较外,图4还给出了两个具有代表性的例子(更多结果见补充文件)。
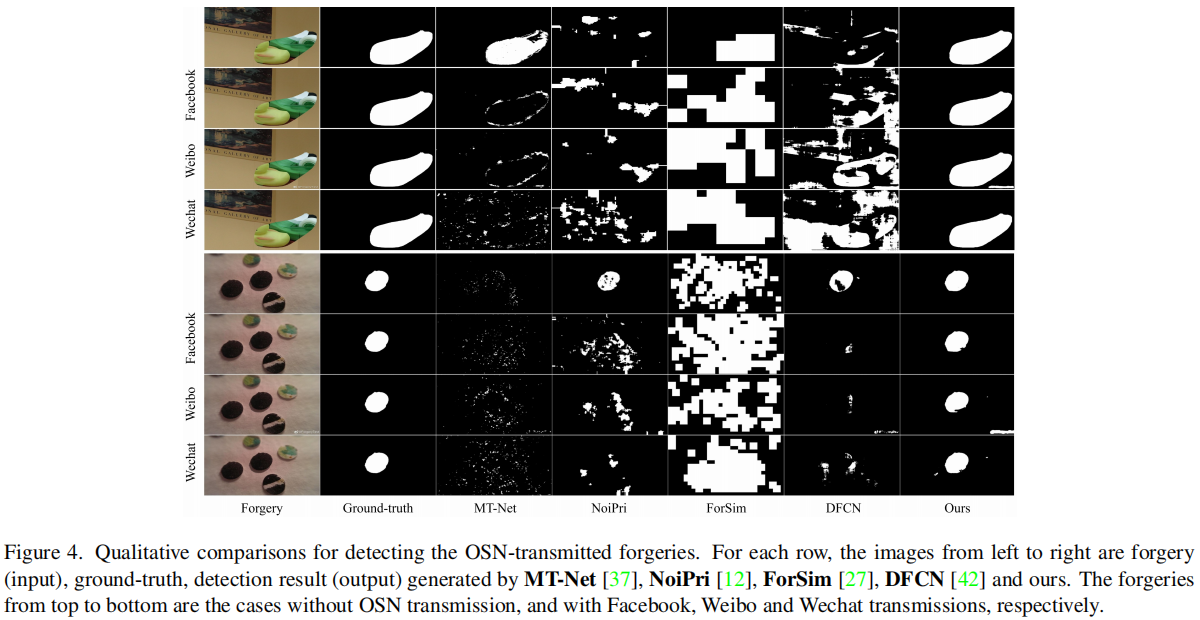
图4.检测OSN传输伪造品的定性比较。对于每一行,从左到右的图像都是伪造(输入)、 ground-truth、由MT-Net[37]、NoiPri [12]、ForSim [27]、DFCN [42]和我们生成的检测结果(输出)。从上到下的伪造品分别是没有OSN传输,以及有Facebook、Weibo和Wechat传输的案例。
可以看出,在正常情况下(没有OSN传输),现有的检测方法表现得相对较好,例如,第一种情况下的MT-Net和ForSim,以及第二种情况下的NoiPri和DFCN。然而,这些方法在OSN传输版本的情况下并不能达到令人满意的检测性能。以第二种情况下的NoiPri为例。对于Facebook、Weibo和Wechat传输的图像,识别出的伪造区域分布在多个物体上,使得伪造检测效果降低。相比之下,我们提出的方法可以学习更鲁棒的伪造特征,从而在这些具有挑战性的情况下产生更精确的检测结果,这主要归功于复合噪声建模的鲁棒训练方案。
4.4.消融研究
我们现在通过分析每个建模噪声(即可预测噪声\(\tau\)和不可见噪声\(\xi\))如何对最终检测性能的贡献,对我们提出的训练方案进行消融研究。为此,我们首先禁止在方案中使用每个噪声,然后在适当的设置下评估不同的再训练检测器的性能。所得结果见表2。
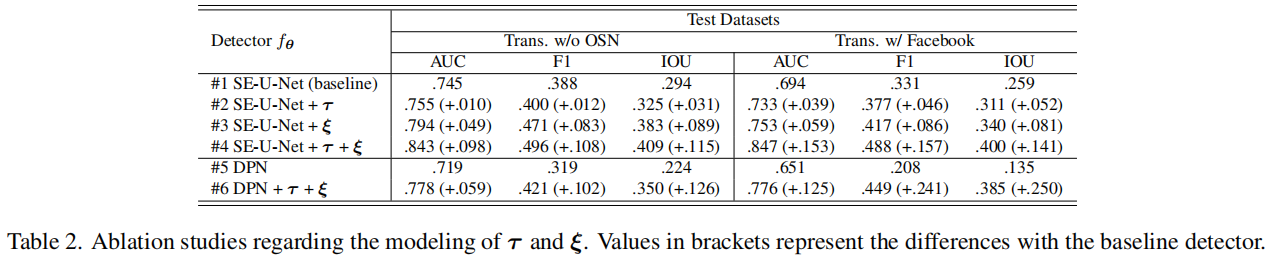
可以看出,在检测器(#2行)训练中引入可预测的噪声\(\tau\)可以略微提高检测性能(F1增益1.2%),这在Facebook传输中更明显(F1增益4.6%)。然而,由于只采用\(\tau\)是不完整的,如在第3部分第2小节中提到的,我们进一步加入设计的不可见噪声\(\xi\)。第3行的结果表明,\(\xi\)可以有效地提高检测器的鲁棒性,带来更显著的改进(例如,F1增加8.6%)。最后,第4行证明,当同时应用复合噪声\(\tau\)和\(\xi\)时,检测器对目标环境的稳定性更强,这对于OSN传输上的伪造检测任务至关重要(例如,F1的增益为15.7%)。此外,我们没有只使用SE-U-Net作为检测器,而是采用了另一个著名的架构,DPN [10],以展示我们提出的训练方案的多功能性。如第5行和第6行所示,我们的鲁棒性训练方法也可以很好地增强DPN的鲁棒性。
4.5.一些进一步的鲁棒性评估
虽然该方案主要是为了对抗osn进行的有损操作,但我们也希望评估其在一些更常用的退化场景下的鲁棒性,如噪声添加、裁剪、调整大小、模糊和独立的JPEG压缩。这种评估在现实情况中是非常重要的,因为这些类型的后处理操作经常被用来清除或隐藏伪造的伪影。为此,我们将这些后处理操作应用于原始测试集Columbia,并在图5中报告了定量比较。
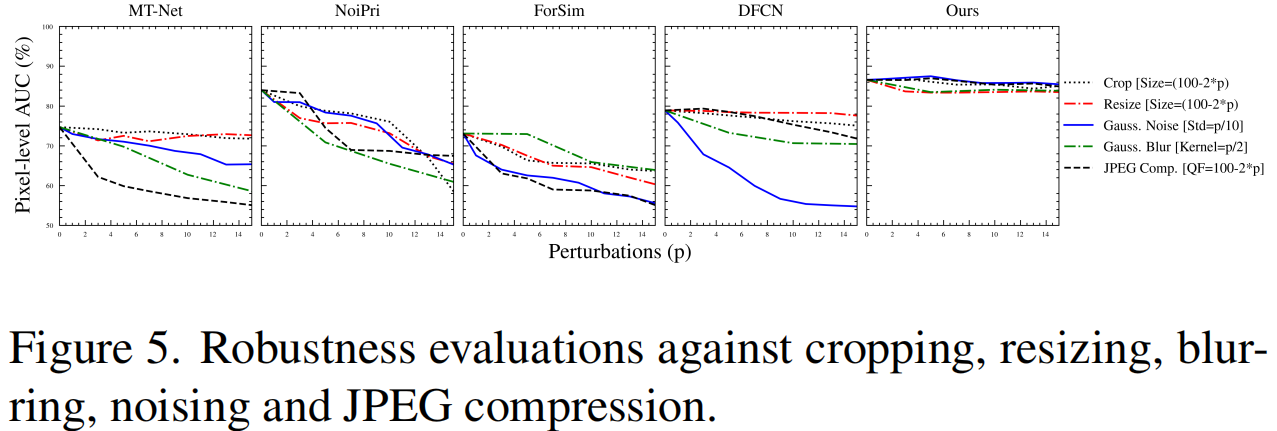
为了便于演示,我们使用一个统一的参数p来控制不同操作的大小。横轴的原点(p = 0)对应于没有任何后处理的情况。可以观察到,对比网络[12,27,37,42]不能随着扰动强度的增加而表现一致,而我们的方法可以很好地推广到击败这些后处理操作。
5.结论
在本文中,我们提出了一种新的训练方案来提高图像伪造检测对各种基于OSN的传输的鲁棒性。该方案的设计借助于建模一个可预测的噪声\(\tau\)以及一个有意引入的看不见的噪声\(\xi\)。实验结果表明,我们的方案与几种最先进的方法相比具有优越性。此外,我们为未来的法医研究社区建立了一个osn传输的伪造数据集。
致谢
澳门科技发展基金2021-2021-2023-0072/2020/20200/015/2019/AMJ,060/2019/A1和077/2012,澳门大学研究委员会2018-00029-FST和MYRG2019-00023-FST,中国自然科学基金61971476,阿里巴巴集团通过阿里巴巴创新研究计划。