MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection
MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image
Manipulation Detection![]()

摘要:
由于通过复制移动、拼接和/或绘制来操纵图像可能导致对视觉内容的误解,因此检测这些类型的操作对于媒体取证至关重要。考虑到对内容的各种可能的攻击,设计一种通用的方法是非常重要的。当前基于深度学习的方法在训练数据和测试数据一致时很有前景,但在独立测试时表现不佳。此外,由于缺乏真实的测试图像,其图像级检测特异性值得怀疑。关键问题是如何设计和训练一个深度神经网络,使其能够学习对新数据操作敏感的可泛化特征,同时防止真实数据的误报。我们提出了多视图特征学习来共同利用篡改边界伪影和输入图像的噪声视图。由于这两个线索都是语义不可知论的,因此学习到的特征是可概括的。为了有效地从真实图像中学习,我们使用多尺度(像素/边缘/图像)监督进行训练。我们将新网络命名为MVSS-Net及其增强版本MVSS-Net++。在数据集内和跨数据集场景下进行的实验表明,MVSS-Net++表现最佳,并且对JPEG压缩、高斯模糊和基于截图的图像重捕获具有更好的鲁棒性。
贡献:
综上所述,我们的主要贡献如下:
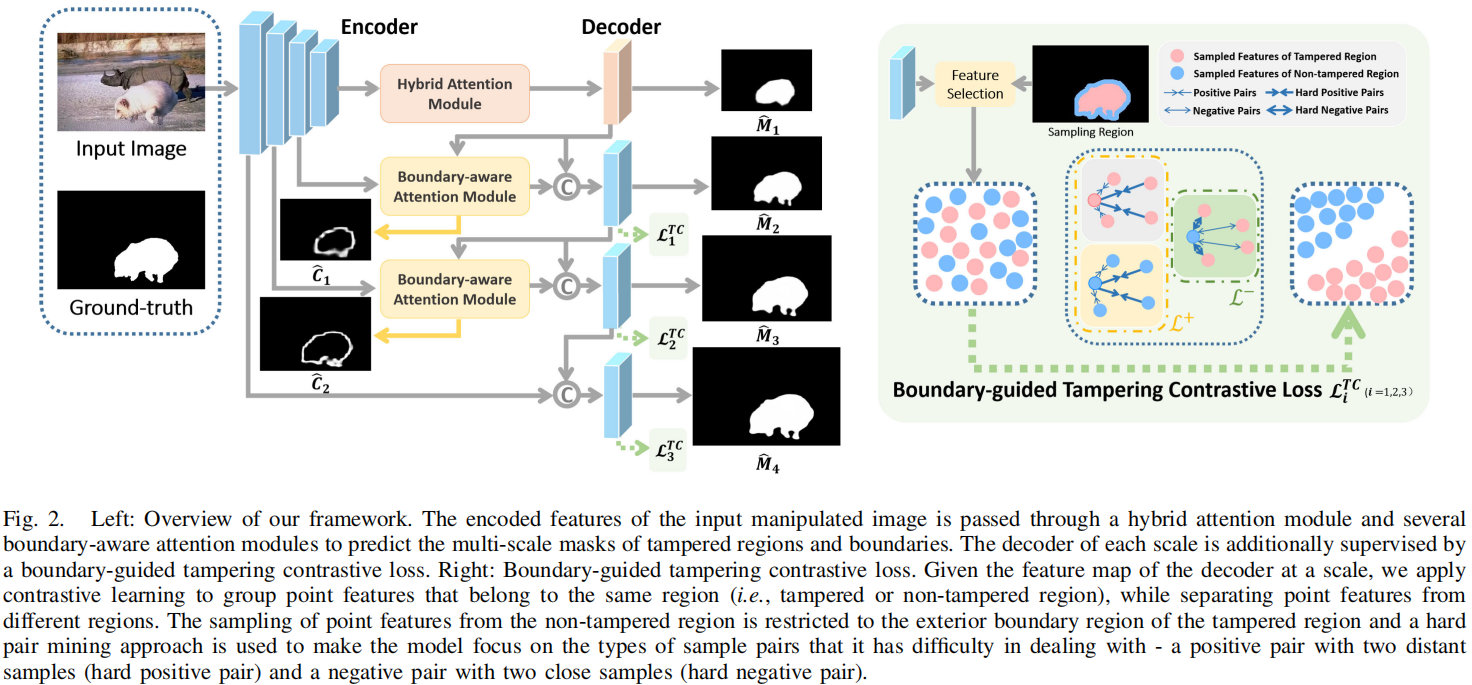
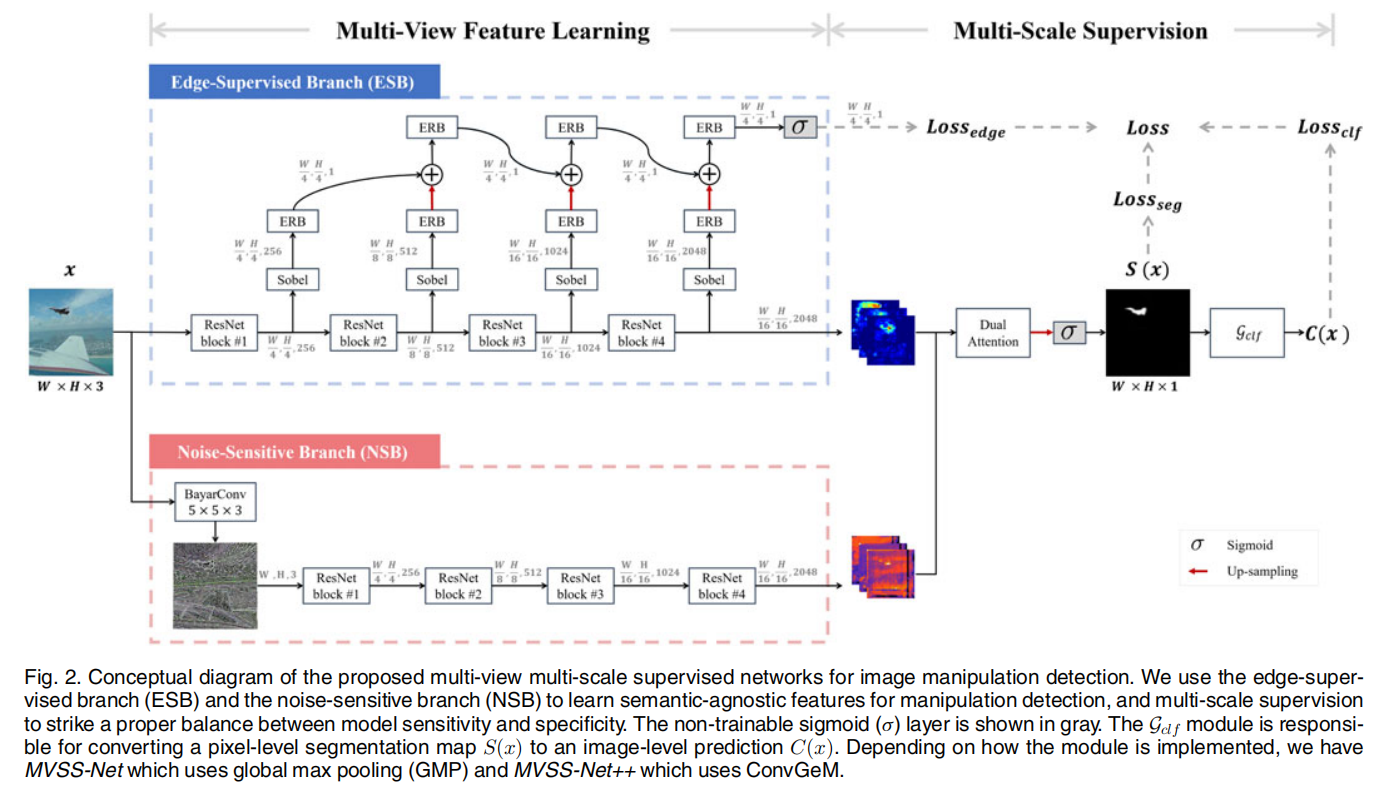
- 提出了一种新的图像处理检测网络MVSS-Net。如图2所示,MVSS-Net的技术优势在于它能够以端到端的方式共同利用多视图输入、显式提取的边界构件和整体信息。多视图特征学习的目的是提取语义不可知的特征,从而获得更一般化的特征。
2. 通过多尺度监督进行网络训练。这使我们能够有效地从真实的图像中学习,而这些图像被现有技术所忽略。因此,大大提高了操作检测的特异性。
3. 在多个基准测试中优于SOTA。在两个训练集和六个测试集上进行的大量实验表明,MVSS-Net优于SOTA。真实测试图像的包含揭示了模型在图像级别的检测特异性。
MVSS++模型:
实验:
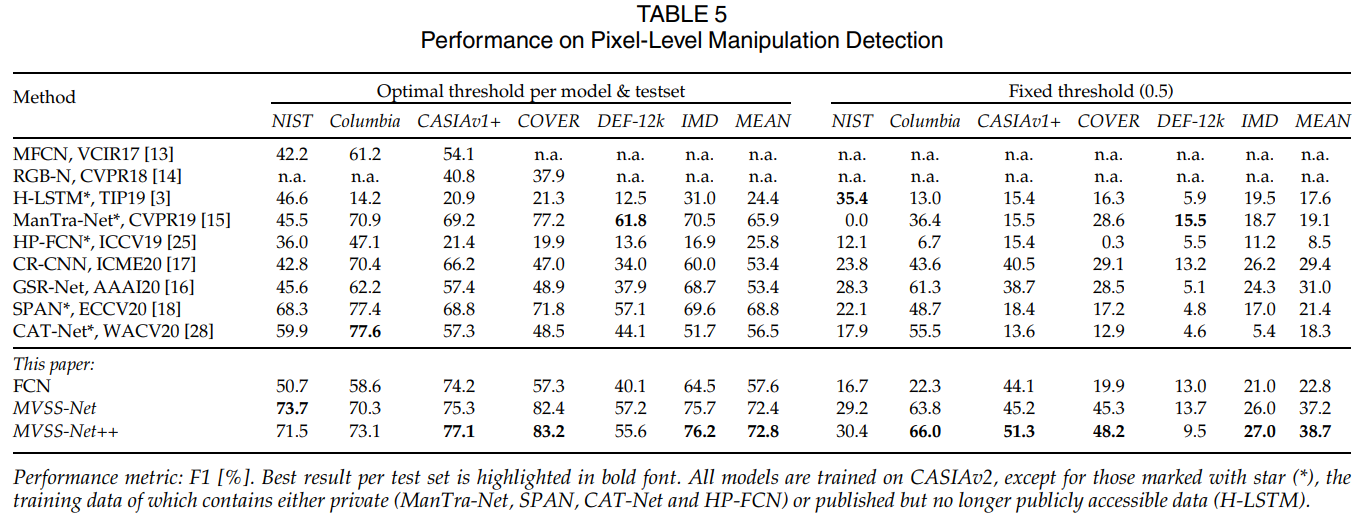
像素级篡改检测:
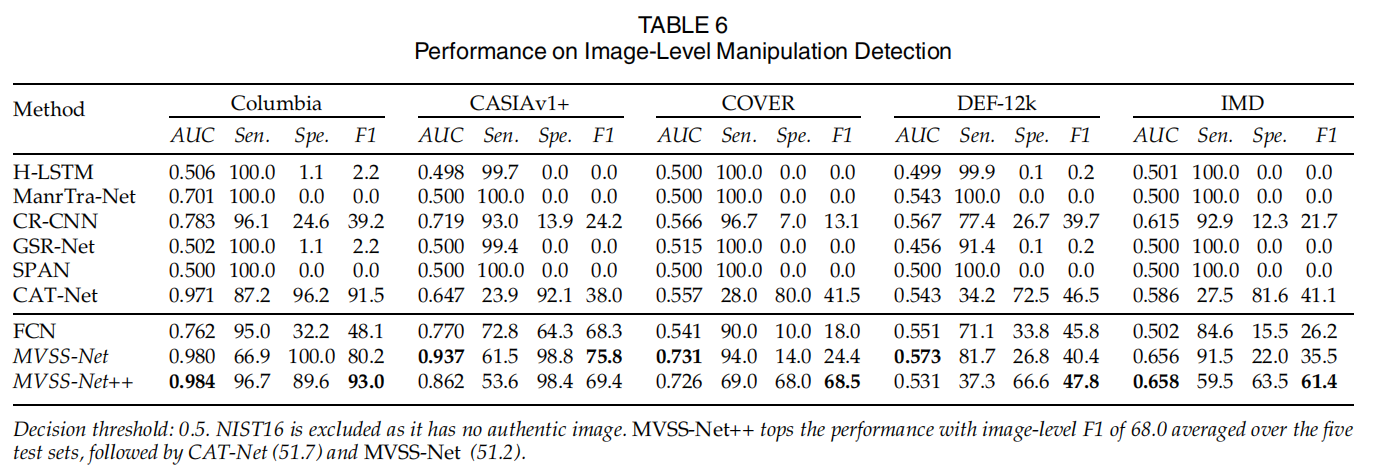
图像级篡改检测:
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 zhaozw后院!
评论
匿名评论