Towards Modern Image Manipulation Localization A Large-Scale Dataset and Novel Methods

论文(arxiv)
# 摘要
近年来,图像篡改定位因其在保障社交媒体安全方面的关键作用而越来越受到人们的关注。然而,如何准确地识别伪造的区域仍然是一个开放的挑战。其中一个主要的瓶颈是,由于其昂贵的创建过程,严重缺乏高质量的数据。为了解决这一限制,我们提出了一种新的范式,称为CAAA,可以在像素级自动和精确地注释大量的人工伪造的图像。我们进一步提出了一种新的度量QES,以方便不可靠注释的自动过滤。利用CAAA和QES,我们构建了一个大规模、多样化、高质量的数据集,其中包括123,150张带有掩码注释的人工伪造图像。此外,我们开发了一种新的模型APSCNet,用于精确的图像篡改定位。根据大量的实验,我们的数据集显著地提高了在广泛使用的基准测试上的各种模型的性能,这些改进归因于我们提出的有效方法。这些数据集和代码可以在https://github.com/qcf-568/MIML上公开获得。
1. 引言
我们提出了一种新的思想,利用训练有素的约束图像处理定位模型,自动获取这些未标记的伪造图像的掩模标注,从而大大缓解了图像处理定位的数据稀缺问题,如图1所示。
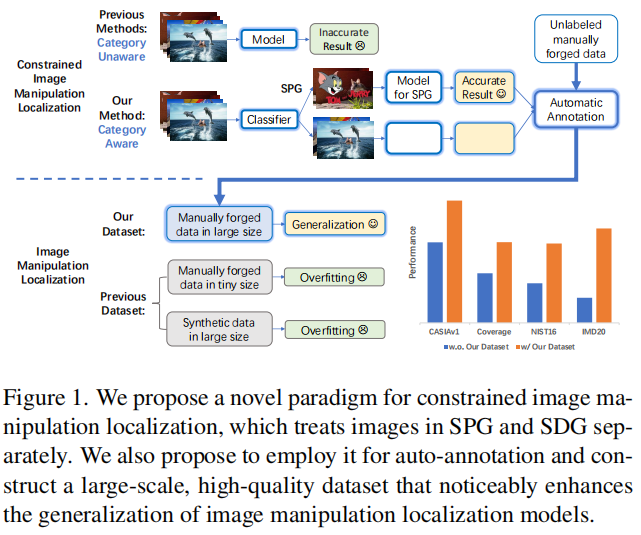
图1.我们提出了一种新的约束图像处理定位范例,它分别处理SPG和SDG中的图像。我们还建议将它用于自动注释,并构建一个大规模、高质量的数据集,显著提高了图像篡改定位模型的泛化性。
由于约束图像篡改定位方法利用相应的真实图像对伪造区域进行定位,可以大大降低任务的复杂性。
然而,尽管在挑战性较小的数据方面取得了进展,但由于三个严重的障碍,以前的约束图像篡改定位方法不足以作为复杂的现代图像的合格自动注释器。首先,他们大多使用一个单一的基于相关性的模型来处理所有的输入数据[19,28],我们认为这是一个次优的范式。一般情况下,根据操纵图像之间的共同部分是伪造区域还是真实区域,将伪造图像对及其原始图像可分为共享供体组(SDG,Shared
Donor Group)和共享探针组(SPG, Shared Probe
Group)两组,如图2所示。

虽然以往的基于相关的方法对于可持续发展目标是合理的,但它们还不够适合SPG,因为SPG中数据的实际公共部分大多是背景,而可持续发展目标中的实际公共部分大多是前景。与可持续发展目标中的共享前景相比,SPG中的共享背景具有更大的面积和更少的显著特征。同时对可持续发展目标和SPG数据上训练基于相关的模型会导致混淆,削弱其泛化能力。其次,从真实图像中减去伪造图像得到的差异图总是可以突出伪造区域,但这一重要线索被以往的约束图像篡改定位方法完全忽略了。最后,以往的工作对操作过程中大量重新缩放操作导致的语义错位关注不够重视,这混淆了模型并对其产生负面影响。
为了解决这些问题,我们提出了一种新的范例,称为类别感知自动注释(CAAA,Category-Aware
Auto-Annotation),它分别处理SDG和SPG中的图像对。所提出的CAAA范式由三个组成部分组成。首先,使用分类器来确定输入图像对是属于SDG还是SPG。该分类器可以通过使用无标记图像的自监督学习来有效地进行训练。其次,利用差异感知语义分割模型,利用图像对及其差异映射在SPG中进行精确的约束操作定位。此外,一个语义对齐相关匹配模型,通过更好的语义对齐提高了SDG的性能。实验表明,我们的方法在复杂场景下显著优于以往的约束图像篡改定位方法,并且足以进行自动标注。
随后,我们从互联网上收集了大量手工伪造的图像,然后用提出的CAAA对其伪造的区域进行注释。该方法可以显著缓解图像处理定位中非合成数据的稀缺性,如图1所示。为了确保所有的注释都足够可靠,我们进一步提出了一个新的度量标准,称为质量评估评分(QES)。QES可以自动评估注释的质量并排除坏的注释,而不需要ground-truths来计算。实验表明,我们的数据集可以在广泛使用的基准测试上显著改进各种图像篡改定位模型。
此外,为了更好地利用我们的MIML数据集,我们提出了一个新的模型,称为APSC-Net,它在各种基准测试上都优于以前的方法。
综上所述,我们的主要贡献如下:
- 我们提出了一个新想法:从网络规模的图像中促进图像篡改定位的任务,以及从较少挑战性的任务,约束图像篡改定位中提取的自动注释。
- 我们提出了一种新的约束图像篡改定位范式,称为CAAA,它分别处理SPG和SDG。对于SPG,我们建议使用用语义信息去噪的图像差分。对于可持续发展目标,我们建议将语义与一个跨级别的特征相关框架对齐。
- 我们提出了一种新的有效度量QES,在数据集构建时自动过滤出不可靠的掩码注释。
- 基于上述技术,我们构建了一个大规模的、多样化的、高质量的数据集,称为MIML。它显著地解决了图像篡改定位的手工伪造数据的问题,从而大大提高了模型的泛化能力。
与图像处理定位相比,约束图像处理定位(CIML, constrained image manipulation localization)[32]在给定的真实图像的额外帮助下对伪造的图像区域进行定位。以往的工作大多是基于相关匹配,并对SDG和SPG中的图像对进行统一处理。Wu等人[32]提出了第一个深度相关模型DMVN,该模型计算相关映射来定位图像中的相似对象。Liu等人提出去除池化层,采用无卷积获得更丰富的空间信息。Liu等人的[18]采用了注意感知机制来获得更好的表现。Tan等人[28]提出在编码器和解码器中都执行相关性,以提取更好的特征。这些方法在挑战性较小的数据集上取得了重大进展(例如,合成COCO [32])。然而,它们的性能在具有高分辨率、大变化度和大复杂度的现代图像中受到限制。
2. 分类感知自动注释模块
对于受限的图像篡改定位,以往的工作没有考虑SPG和SDG图像对之间的差异,而是使用单一的相关性模型对其进行统一处理。我们认为这种范式是次优的,原因如下:
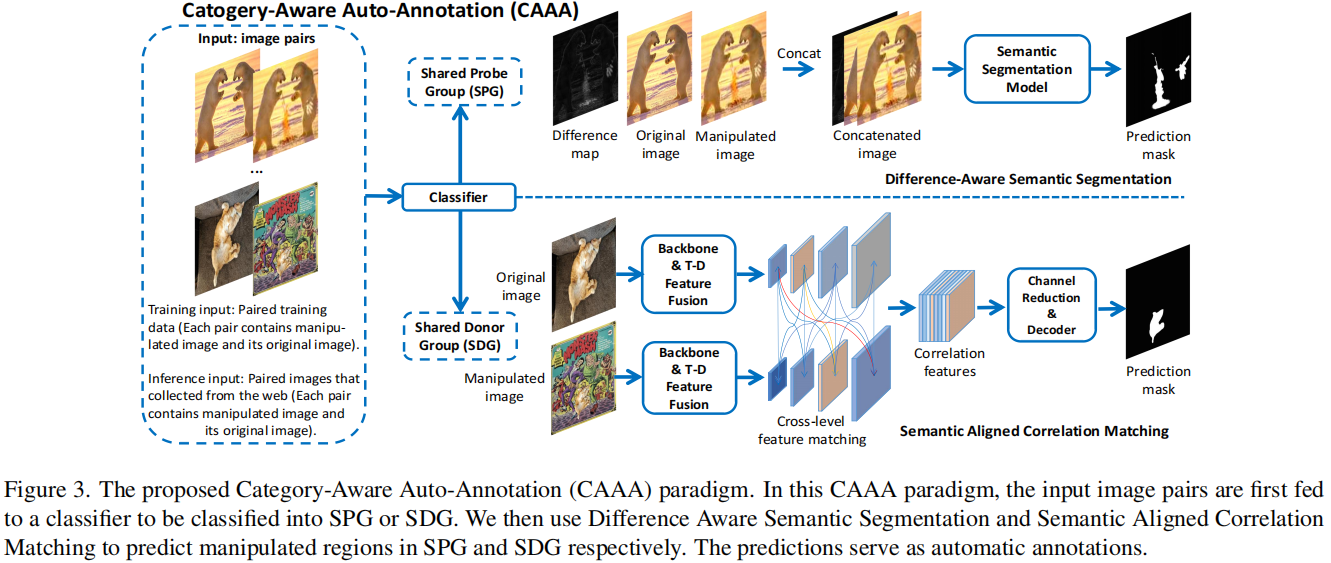
首先,SDG 图像的相似区域是前景区域(例如,图3中SDG
分支中的猫)。它们有特定的、相似的形状和独特的特征。相比之下,SPG图像的相似区域是背景。它们通常没有足够独特的特征来进行精确的相关匹配(例如,在图3的SPG分支图像中,一块背景中的雪与所有其他块背景中雪有很高的相似性)。因此,这些区域很可能会在基于相关性的模型中造成混淆,特别是在复杂的场景中。因此,这些区域很可能会在基于相关性的模型中造成混淆,特别是在复杂的场景中。
第二,配对的SPG图像之间的差异是一个重要的提示。SPG图像对中的大部分区域几乎相同,并在空间上对齐(例如,图3中SPG分支的图像对)。简单地在它们之间减去最终的差异图就可以突出被操纵的区域。然而,这些信息在以前的基于相关匹配的模型中难以利用,因此在以前的CIML工作中没有考虑到。
基于这些观察结果,我们提出了一个新的CIML任务范式,类别感知自动注释CAAA。其关键思想是独立处理SPG和SDG图像,如图3所示。首先,利用第3.1节中提出的分类器,将输入的图像对分为SPG或SDG。对于SPG,图像对采用第3.2节中提出的差分感知语义分割进行处理。对于SDG,图像对通过第3.3节中提出的语义对齐相关匹配进行处理。更重要的是,用我们提出的范式训练的模型被进一步用于执行在大量手工伪造的图像上的自动注释。作为回报,收集的数据解决了用于图像篡改定位的非合成数据的严重短缺。
2.1 自监督分类器
为了实现SPG和SDG的分类,我们提出了通过对无标记图像的自监督学习来训练分类器。给定一个图像,我们对其进行随机的增强和操作,然后将伪造的图像和原始图像形成一个SPG图像对。为了构建一个 SDG图像对,我们从原始图像中复制随机对象,调整它们的大小,并将它们粘贴到另一个图像中。利用所得到的图像对,我们可以有效地训练我们的分类器。每个输入对中的两个图像在被输入到分类器之前被连接在通道维数中。分类器只需要识别一个图像对中的两个图像是几乎相同(SPG)还是明显不同(SDG),而不考虑哪一个或哪里是假的。因此,这个分类任务非常简单,我们可以准确地将图像对分成两组。
2.2 具有差异感知能力的语义分割
理想情况下,对于SPG中的图像对,真实图像和伪造图像之间的绝对差异实际上是伪造区域。然而,被操纵的图像在传输[31]过程中通常会发生退化,这使得无法利用绝对差异作为精确的注释。如图4所示。

图4.由于篡改后的图像在传输过程中通常会经历一系列的退化,因此它们与真实图像之间的绝对差异不能准确地表示伪造区域。我们的方法通过使用语义信息来实现了充分的去噪,从而解决了这一问题。
由于传输退化,图像差分图中几乎所有的区域都是非零的。即使是OTSU [24]算法二值化的差异图也在真实区域上突出,特别是在高频区域,如边缘。为了解决这个问题,我们建议利用图像中的语义信息来去噪差异映射。为了实现这一点,我们提出将真实图像、伪造图像及其差异映射图的信道维数连接输入到一个语义分割模型中。
2.3 语义对齐的关联匹配
由于广泛的重缩放操作,语义失调成为对基于相关性的方法的有效性产生不利影响的关键因素。例如,在图3的SDG分支中,原始图像中的猫占据了一个很大的区域,而在伪造的图像中,同一只猫被限制在一个小得多的区域内。原始图像的猫特征大多在最高水平,而伪造图像的猫特征大多在最低水平。因此,两幅图像之间在同一编码水平上的视觉特征存在语义错位。然而,以往的工作只是迫使模型在相同的特征层次之间进行特征匹配,这混淆了模型,并对其泛化产生了负面影响。为此,我们提出通过实现更好的语义对齐来提高相关模型的性能。
具体来说,给定从主干模型中提取的一组不同分辨率的特征映射,我们首先用平均池化的最高特征计算全局表示,然后用卷积层将它们与最高特征融合。随后,我们以一种类似于在FPN
[15,34]中的自上而下的方式融合了这些特性映射。这样,低级特性就具有更多的语义,并准备与高级特性相匹配。然后,我们以跨层次的方式计算输入图像对特征之间的相关特征
$ F_{corr} $
,如式(1),这不同于以前的方法[18,19,32],它只计算与方程(2)相同水平的特征图之间的相关特征。
\[[Corr(F_{o,i},F_{m,j}) for i in (0{-}3) and
for j in (0{-}3)]\]
\[[Corr(F_{o,i},F_{m,i}) for i in (0-3) ]\]
在这些方程中,Corr表示之前工作中广泛使用的相关函数,[18,19,32], $ F_{o,i} $ 表示原始图像的第i层特征图, $ F_{m,j} $ 表示伪造图像的第j层特征图。我们的模型能够自适应地选择最优匹配路由,从而增强语义对齐。 $ F_{corr} $ 随后被连接,信道减少并输入卷积解码器进行最终预测。
3. MIML数据集
在本节中,我们提出了一个大规模的、多样化的、高质量的数据集,称为MIML。其关键思想是利用在现有数据集上训练的约束图像篡改定位模型,自动从网络中人工伪造的图像获得准确的掩码注释。为了确保数据集的高质量,我们还提出了一个新的度量标准来过滤掉不充分的注释。
3.1 数据集构成
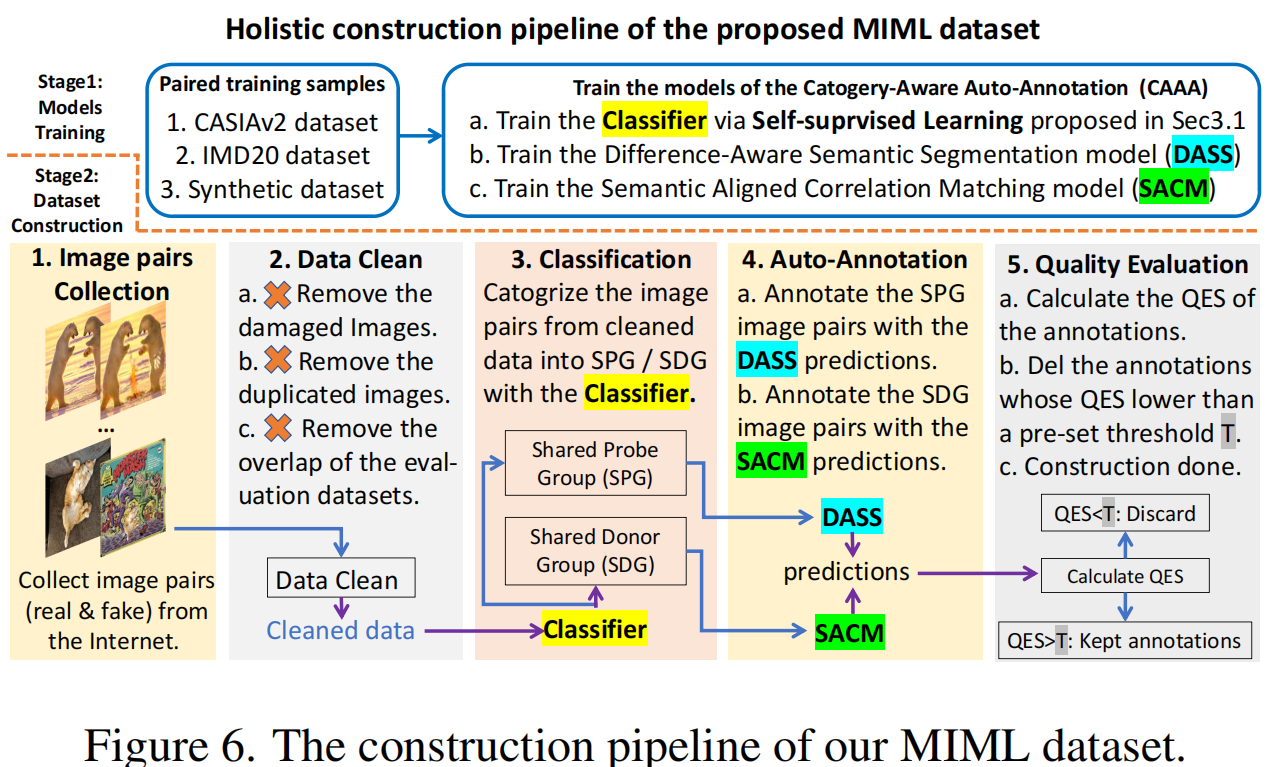
如图6所示,我们构建MIML的步骤如下:
图像收集。我们从imgur.com中收集图像对。在这个网站上,这些图片是由数百万人手工伪造的,因此有高质量、多样化的伪造区域。
数据清理。我们清理收集到的数据,并排除与第6块中的评估数据集重叠的图像。
分类。我们使用第3.1节中提出的分类器将清理后的图像对分类为SPG或SDG。实际的分类器是三个模型[8,20,21]的集合。
自动注释。我们利用第3.2节和第3.3节中提出的DASS和SACM,分别自动获取SPG和SDG中图像的掩码注释。
质量评价。经过自动注释,SPG的注释已经有了高质量,而SDG的注释仍然不令人满意。为了保证整体质量,我们提出了一种新的度量标准,质量评估评分(QES),以进一步过滤掉不可靠的注释。QES的关键思想是,大多数高质量的预测都有非常高的置信度和尖锐的边缘,因此我们可以评估预测的质量,并通过检查预测的置信度和清晰度来排除不好的预测。具体来说,给定一个具有形状(H,W)和归一化概率的预测掩模,我们计算QES如下:
\[\textbf{QES=}\frac{\sum_{i,j}^{H,W}p_{i,j}>(1-T_{h})}{\sum_{i,j}^{H,W}p_{i,j}>T_{l}}\]
其中, $~ \sum_{i,j}^{H,W}p_{i,j} > (1 - T_{h}) $ 表示高置信度大于
$ (1 - T_{h}) $ 的预测区域, $~ \sum_{i,j}^{H,W}p_{i,j}>T_l $
表示预测的总潜在操纵面积。我们将 $ T_{h} $ 和 $ T_{l} $ 设置为 $~
\frac{1}{16} $
,只保留QES>0.5的样品。实验表明,我们的QES与IoU度量有很强的相关性,可以有效地帮助过滤出不可靠的掩码注释。
3.2 数据集亮点
我们在图5中给出了所建议的数据集的几个例子。

我们的数据集的主要亮点如下:
- 高质量。该数据集中的图像操作是由人类精心制作的。这些数据可以教模型在现实世界中发现伪造,而不仅仅是在合成数据中过度拟合几个简单的模式。
- 大规模。如表1所示,所提出的数据集共有123,150张人工伪造的图像,比之前的手工IML数据集多几十倍(例如,≈比IMD20的60倍)。
- 多样性。我们的数据集包括各种大小、各种样式和各种类型的操作(例如,复制-移动、拼接、删除)的图像。它们是由成千上万的人利用各种软件创建的。这些不同的数据可以大大提高深度IML模型的泛化能力。
- 现代风格。我们的数据集有大量的现代图像,最近被捕获和伪造,跟上了现代数码摄影技术的步伐。相比之下,CASIA数据集[3]是在十多年前提出的,其中大多数图像的尺寸都很小,而且都很模糊。因此,我们的数据集可以更好地满足现代图像操作定位的要求。
- 强大的可扩展性。网络上有许多越来越受欢迎的图像处理比赛,不断吸引数百万人来参加(例如1900万pas-Battles[9,25]的900万人),产生了大量新的手工伪造图像。我们的数据集构建方法已经准备好利用这些不断增长的廉价web数据。因此,我们的数据集可以很容易地进行扩展,显示出强大的可扩展性。
4. APSC-Net
在本节中,我们提出了一个新的模型,称为APSCNet,以实现精确的图像操作定位。如图7所示,它由特征提取器、自适应感知模块和自校准模块组成。
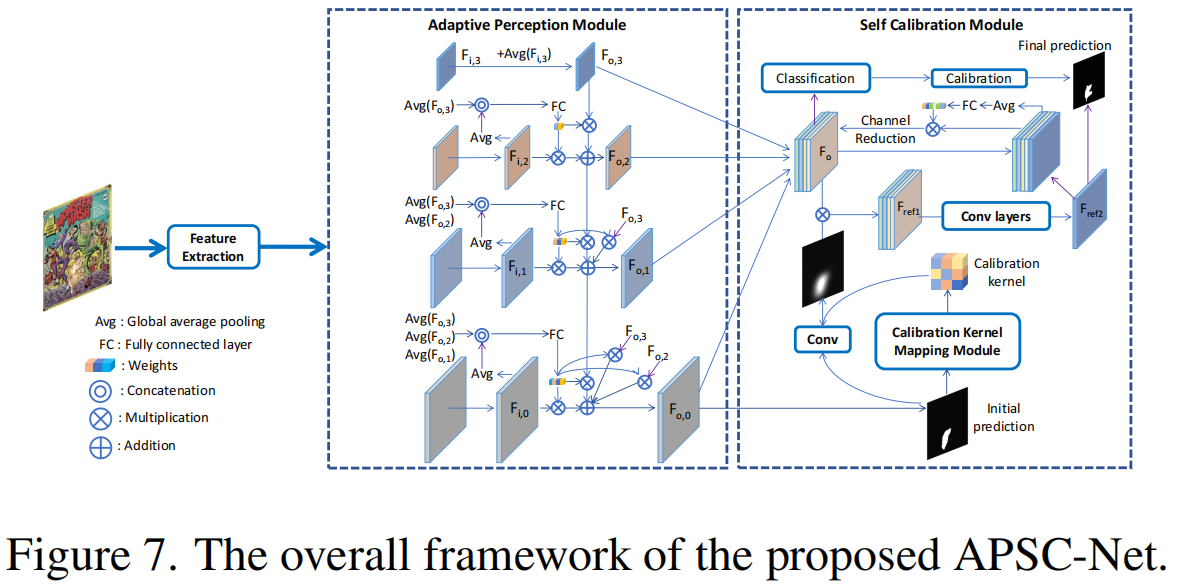
4.1 自适应感知模块
在细致的图像取证分析过程中,人类经常会反复放大和缩小图像,选择一组最佳的观察结果来帮助他们的最终预测。为了模拟人类的感知方式,我们设计了一个自适应感知模块,以帮助模型比较不同的视图,并自适应地选择每个输入图像的最优组合。其关键思想是使用从全局表示计算出的自适应权重对当前和所有高级特征图进行加权。
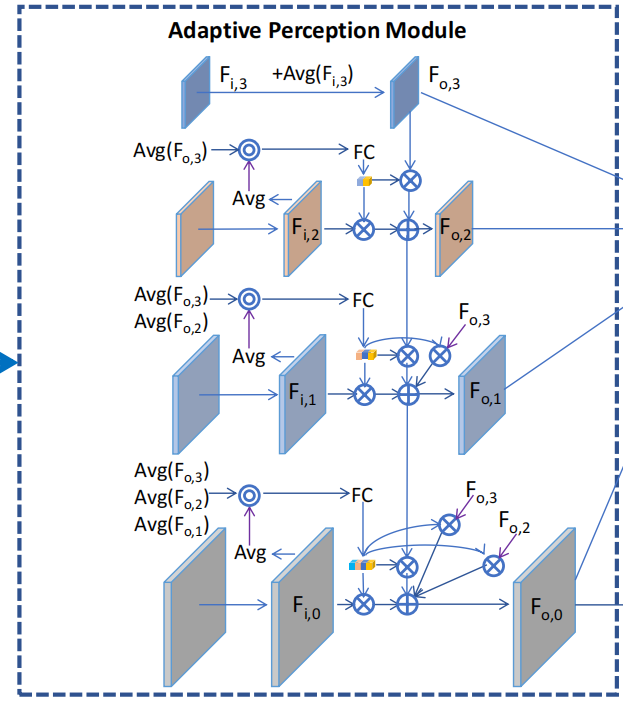
具体来说,给定从主干模型中提取的4个特征图,我们首先将它们映射到1×1转换层的通道上,得到4个特征图 $ F_{i,0},F_{i,1},F_{i,2},F_{i,3} $ 。然后,我们通过全局平均池化从 $ F_{i,3} $ 中得到全局图像表示,并使用1×1卷积层将它们与 $ F_{i,3} $ 融合,得到 $ F_{o,3} $ 。最后,对于(2,1,0)中的a和范围(a+1,3)中的b,我们遵循下面的公式(3)和(4)依次计算 $ F_{o,a} $ : \[[w_{a,a},w_{a,b}]=\sigma(f_{a}(Cat([Avg(F_{i,a}),Avg(F_{o,b})])))\]
\[F_{o,a}=Conv(w_{a,a}*F_{i,a}+\sum_{b=a+1}^3w_{a,b}*F_{o,b})\]
其中Avg表示全局平均池,Cat表示通道维连接, $ f_a $ 表示具有ReLU层的两个线性层, $ $ 表示Sigmoid激活函数,Conv表示3×3卷积层。
4.2 自校准模块
当对操纵图像进行细致的定位时,人类倾向于通过比较预测的伪造区域周围的特征来确认他们的初始预测。此外,他们可能会根据他们对图像真实性的全局评估来修改他们的局部预测。为了模拟人类的感知方式,我们设计了一个自校准模块,以获得更好的性能。
如图7所示,提出的自校准模块包括基于分割的自校准(SSC,Segmentation-based
Self Calibration)和基于分类的自校准(CSC,Classification-based Self
Calibration)。
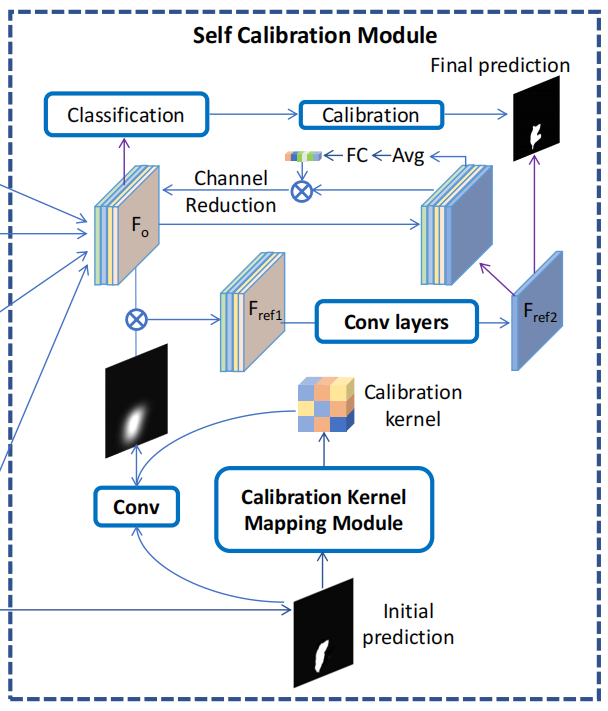
对于SSC,从自适应感知模块的末端获得初始预测,并将其输入一个由几个卷积层组成的小校准核映射模块。随后,我们得到一个校准核,并对其初始预测进行卷积运算。然后使用Min-Max方法对结果值进行归一化。我们将标准化结果乘以
$ F_o $ ,即 $ F_{o,0},F_{o,1},F_{o,2},F_{o,3} $ 的串联,得到 $ F_{ref1}
$ 。接下来,我们使用多个卷积层来细化 $ F_{ref1} $ ,并得到细化的特征 $
F_{ref2} $ 。在此之后,我们将 $ F_{ref2} $ 与 $ F_o $
连接起来,执行信道注意和信道减少的方法,用结果替换 $ F_o $ ,并重复利用
$ F_o $ 和校准预测的过程,再次获得 $ F_{ref2} $ 两次,以获得 $ F_{ref2}
$
的改进版本。利用SSC,我们的模型可以根据其初始掩模预测大致自适应地关注最优区域,从而通过深入分析获得更高的性能。
对于CSC,我们首先将改进后的特征
$ F_{ref2} $
输入到一个小分类头中,用于预测输入图像是否被篡改。如果图像被预测为真实,掩模预测很可能会有很多的假阳性(FP),所以我们增加二值化阈值来减少FP。另一方面,如果图像被预测为篡改,我们会降低二值化阈值以减少假阴性。给定输入图像被预测为篡改的概率P,CSC将预测掩模的二值化阈值从0.5调整到
$~ min(max(1-P,\lambda),1-\lambda) $ , $~ \lambda $ 设置为0.3。
5. 实验
5.1 受约束图像篡改定位CIML任务的实验
图像操作自动标注的任务可以作为一个CIML任务的评估。考虑到IMD20数据集[23]中的图像与我们要标注的目标图像非常相似,我们使用其中一部分使用IoU和F1-score来评估模型的性能。
5.1.2 实施细节
我们将IMD20中伪造的伪造图像分为SPG或SDG,并将它们以大约3:1的比例随机分成训练集和测试集。CASIAv2 [3]和大约100万张通过使用COCO数据集合成的图像[14]也被用于训练。输入图像的大小调整为512x512,并在所有方法中应用一致的训练配置以进行公平比较。
5.1.3 消融实验
对于SPG,伪造图像与其真实图像之间的图像差异可以粗略地表示伪造区域,图像本身可以提供语义信息,帮助模型去噪差异映射。我们在IMD20 SPG的测试集上对所提出的差异感知语义分割进行了消融实验,如表4的右侧所示,这两种方法都可以提高模型的性能。
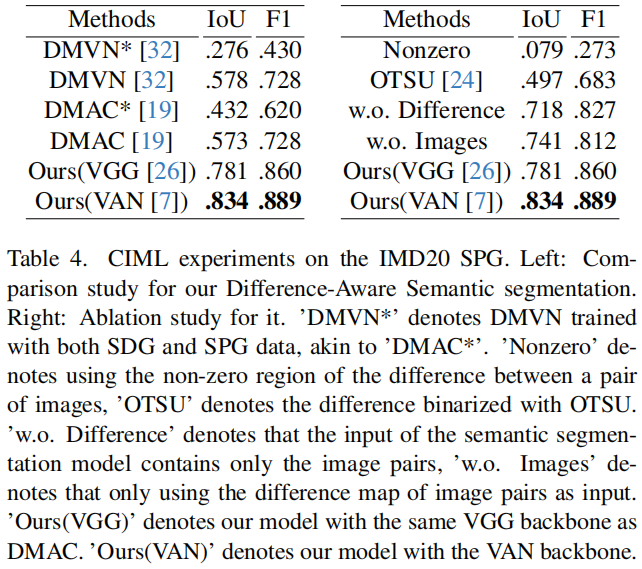
表4。在IMD20 SPG上进行的CIML实验。左:我们的差异感知语义分割的比较研究。右:对应的消融实验。“DMVN*”表示同时使用SDG和SPG数据进行训练的DMVN,类似于“DMAC*”。“Nonzero”表示使用一对图像之间的差值的非零区域,“OTSU”表示用OTSU二值化的差值。'w.o. Difference‘表示语义分割模型的输入只包含图像对,’w.o. Images‘表示只使用图像对的差异映射作为输入。“Ours(VGG)”表示我们的模型与DMAC具有相同的VGG主干。“Ours(VAN)”表示我们的模型使用VAN主干。
对于SDG,语义对齐可以减少训练过程中的混淆,帮助我们的模型实现更好的泛化。我们在IMD20 SDG的测试集上对所提出的语义对齐相关匹配进行了消融实验,结果如表5的右侧所示。
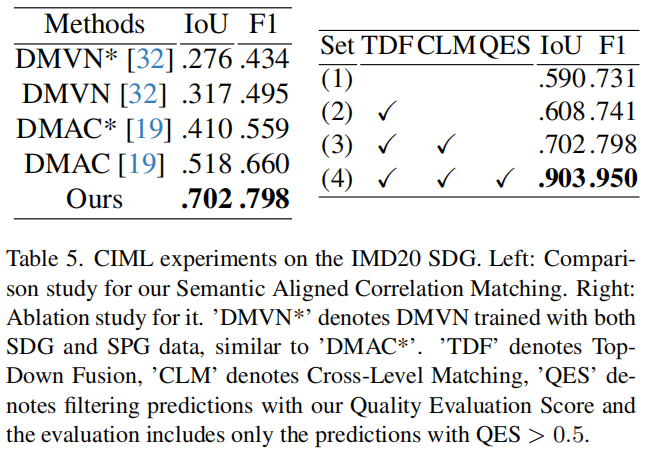
显然,这两个提议的组件都有助于提高模型的更高性能。此外,所提出的质量评价评分(QES)允许自动过滤最令人满意的预测。由于IMD20的ground truth中存在一些错误,我们的方法足以获得准确的自动注释。
5.1.4 对QES的消融实验
所提出的QES度量的目标是在数据集创建期间自动过滤掉糟糕的预测,其中ground truth是不可用的。如表3所示,越高的QES阈值,精度就会越高。

这是因为具有更大的高置信度和更清晰的边缘比率的预测大多更接近实际的ground truth,而清晰度和置信度可以通过我们的QES很好地评估。因此,我们的QES显示了与IoU度量有很强的相关性。
5.1.5 比较实验
我们在与我们相同的数据上,使用它们的公共代码对DMVN [32]和DMAC [19]进行了重新训练,结果如表4和表5的左侧所示。显然,我们的方法明显优于这些以前的方法。值得注意的是,同时使用SPG和SDG数据训练的DMVN和DMAC在这两个任务上的表现都比只使用SPG或SDG数据训练的任务更差。
5.2 图像篡改定位IML任务的实验
5.2.1 实施细节
我们采用ConvNeXt-Base [21]作为特征提取器,对模型进行160k次迭代的训练,批量大小为20,在按照之前的工作[6,12]进行训练时,输入大小设置为512x512。我们使用交叉熵损失和AdamW优化器[22],学习速率从1e-4到1e-6。CASIAv2 [3]和CAT-Net [12]中的合成数据集用于按照之前的工作[6,12]进行训练。
5.2.2对MIML数据集的消融实验
除了我们的APSCNet外,我们分别用PSCC-Net [17]和CAT-Net [12]的公共代码重新训练了提出的MIML数据集。当使用MIML数据集进行训练时,我们对原始合成数据和MIML采用近似1:1的采样比,所有实验中的总训练量都是固定的,以便进行公平比较。
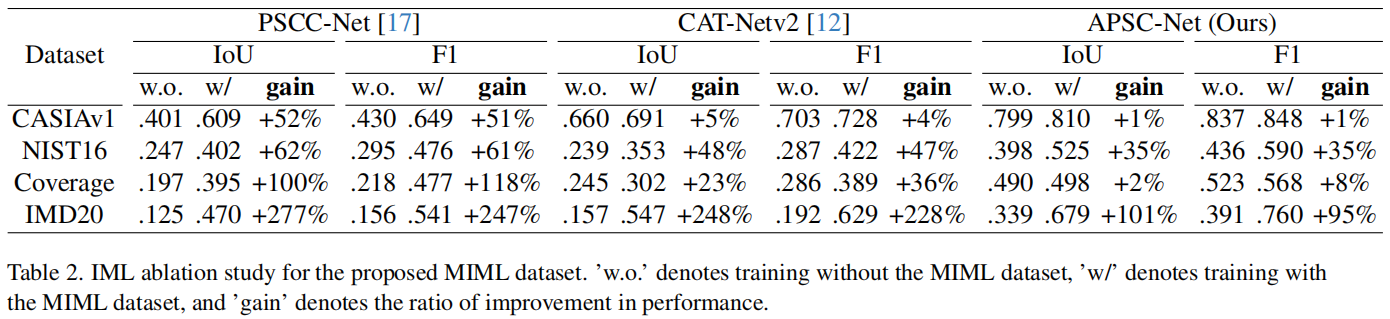
如表2所示,MIML可以显著提高所有这些模型的性能,而在训练或测试过程中没有任何额外的负担。这是因为MIML可以大大缓解深度IML模型中人工伪造数据的严重短缺。为了进一步确认我们的MIML数据集的有效性,我们将IMD20数据集随机划分为10个12个样本的IMDP1和988个样本的IMDP2,用相同大小规模的IMDP1替换MIML数据集,用它们训练APSC-Net。
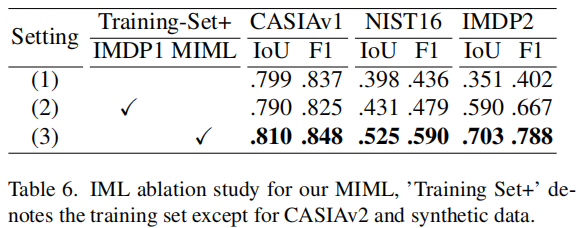
如表6所示,尽管在训练中加入IMDP1减轻了领域差距,提高了模型在NIST16和IMDP2上的性能,但仍明显低于使用MIML训练的模型。显然,MIML可以通过其大量不同的手工伪造数据,显著提高深度模型的泛化能力。
5.3.3 APSC-Net的比较实验
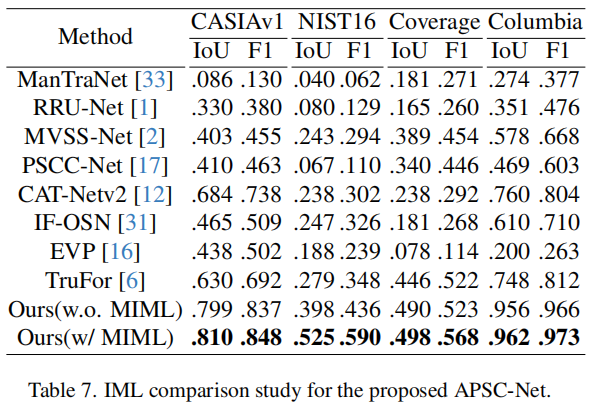
我们在广泛使用的基准测试上比较了我们的APSC-Net与最先进的(SOTA)方法的性能。考虑到以前的方法执行不同的后处理,导致不公平(例如EVP [16]使用最佳阈值计算GT执行二值化),我们忽略了与他们所提出的方法无关的后处理和用一个固定的阈值0.5均匀地二值化预测,然后评估性能与普通IoU和F1-score指标。定量结果如表7所示,我们的APSC-Net在所有这些基准测试上都优于以前的最先进的方法。
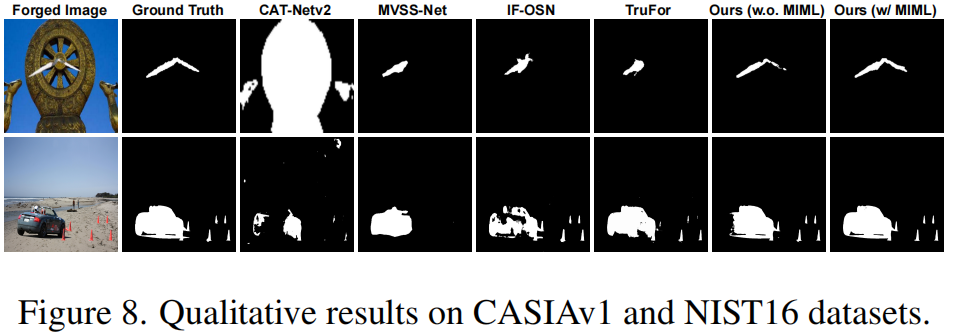
视觉比较的定性结果如图8所示。
6. 结论
在本文中,我们提出了一种新的约束图像处理定位(CIML)范例,称为CAAA,它分别处理共享探针组SPG和共享供体组SDG图像对。实验表明,该范式明显优于以往的CIML方法。在此范例下,训练后的模型被用于自动标注未标记的伪造图像,以进行图像操作定位。我们还提出了一种新的度量QES来自动排除错误的预测。因此,我们提出了一个大规模、多样化、高质量的数据集MIML,包括123,150张人工伪造的图像和像素级注释,这可以通过解决它们的数据稀缺问题来激发深度取证模型的潜力。此外,我们提出了一种新的有效模型APSC-Net用于图像操作定位。我们希望我们提出的CAAA范式、QES度量、MIML数据集和APSCNet能够为社区带来见解,并促进图像操作定位的现实应用。