Unlocking the Capabilities of Large Vision-Language Models for Generalizable and Explainable Deepfake Detection

Unlocking the Capabilities of Large Vision-Language Models for Generalizable and Explainable Deepfake Detection
Peipeng Yu 1 Jianwei Fei 2 Hui Gao 1 Xuan Feng 1 Zhihua Xia 1 Chip-Hong Chang 3
1 济南大学网络安全学院
2 澳门大学
3
南洋理工大学电气与电子工程学院
摘要
目前的大型视觉语言模型(LVLMs)在理解多模态数据方面表现出显著的能力,但由于其知识和取证模式的错位,它们在深度造假检测方面的潜力仍未得到充分探索。为此,我们提出了一种新框架,旨在挖掘语言模型在深度伪造检测中的潜力。该框架包含知识引导的伪造检测器(KFD, Knowledge-guided Forgery Detector)、伪造提示学习器(FPL, Forgery Prompt Learner)和大型语言模型(LLM, Large Language Model)。KFD用于计算图像特征与原始或深度伪造图像描述嵌入之间的相关性,从而实现伪造的分类和定位。
1.引言
生成式人工智能的快速发展显著加速了深度造假技术的发展,促进了逼真的面部操作和重演。尽管这些技术在娱乐和艺术领域有着显著的应用,例如稳定扩散(Esser等,2024)和DALL·E(Ramesh等,2021),但它们的滥用对社会构成了严重的安全威胁(Wang等,2024b)。这些工具允许用户通过输入精心设计的提示,合成出逼真但不存在的内容,使得深度伪造生成比以往任何时候都更加容易获取且潜在危险。
大型视觉-语言模型(LVLMs)为解决这一问题提供了有希望的解决方案。这些模型在广泛多样的数据集上进行了预训练,能够捕捉大量关于自然物体的知识,从而显著提高识别被篡改内容的泛化能力。通常,LVLM会使用图像编码器提取图像特征,然后将这些特征与文本提示结合,输入到大型语言模型(LLM)中生成响应。例如,输入一张面部图像,并附带这样的提示:“这是一张用于深度伪造检测的面部图像,不应出现局部颜色差异或明显的拼接痕迹。这是一张深度伪造图像吗?”LVLM可以评估图像是否可能被篡改。然而,现有的LVLM主要针对通用图像理解任务进行了优化,可能无法有效捕捉深度伪造检测所需的细节特征。直接进行微调存在挑战,因为LVLM在处理“颜色差异”或“视觉伪影”等专业术语时,可能难以准确地解释这些术语在伪造检测中的含义。因此,设计一个能够更好地理解这些术语的模型至关重要。
本文旨在利用大型视觉-语言模型的能力,解决深度伪造检测任务。人们通常通过特定的描述符,如细微的视觉瑕疵、局部光照不一致和过度平滑的纹理,来识别被篡改的内容。然而,这些特征难以仅通过数据模拟或特征增强准确复制,这限制了现有方法对被篡改内容的全面解读(Zhang et al., 2024)。为了解决这一局限性,我们提出探索图像与文本描述之间的校正,以辅助深度伪造检测。
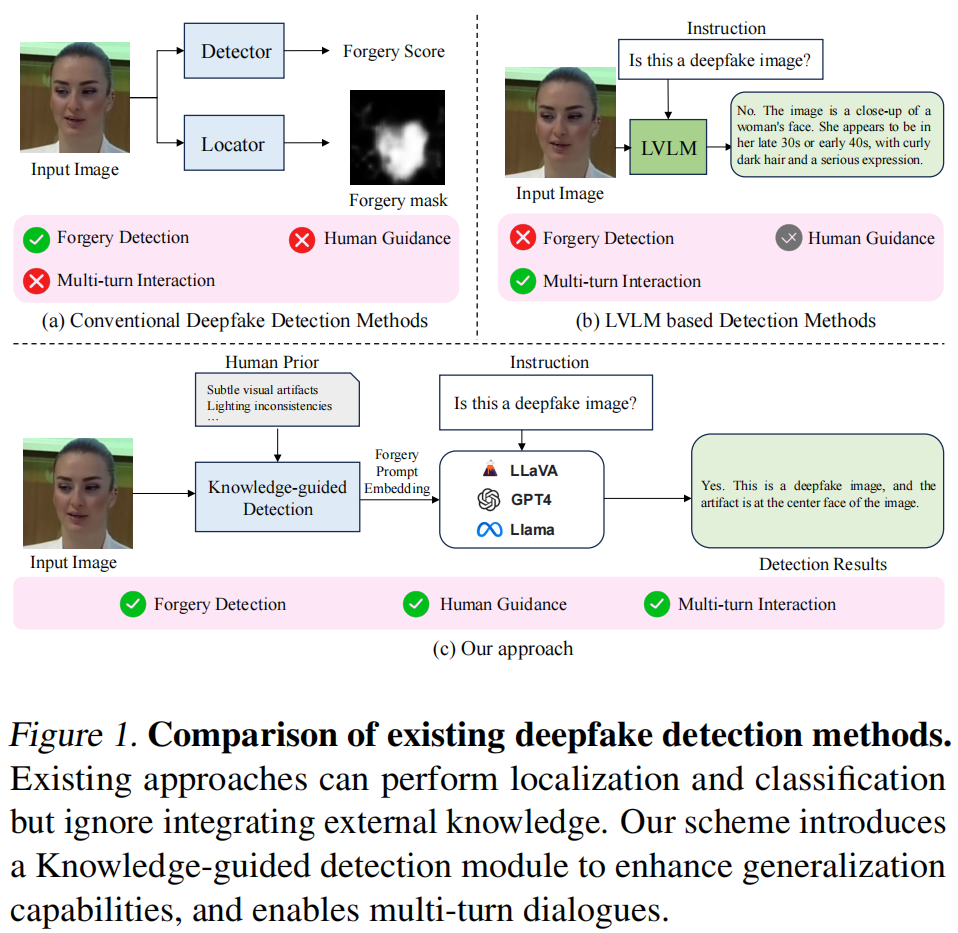
如图1所示,我们提出了一种基于预训练知识的新型LVLM深度伪造检测框架,该框架能够实现通用且可解释的检测(Lester
et al., 2021; Liu et al.,
2022)。我们首先整合外部知识来训练一个伪造检测器,然后将该检测器的特征融入语言模型(LLM)中以生成响应。
具体来说,该框架包含两个关键阶段:知识引导的伪造检测器训练和语言模型提示调优。
在知识引导的伪造检测器训练阶段,我们的目标是训练出一个高精度的深度伪造检测器。利用预训练的多模态编码器,我们从图像中提取图像特征,并从原始图像和伪造图像的描述中提取文本特征。通过计算这些图像特征与描述文本嵌入之间的相关性,我们生成了一致性图,这些图展示了视觉内容与文本描述之间的对齐情况。这些地图随后由伪造定位器和分类器处理,生成伪造分割图和伪造评分。
在语言模型提示调优阶段,我们将深度伪造检测的知识融入语言模型中,生成伪造检测描述。为了确保深度伪造检测的准确性,我们使用专门为本任务定制的模拟伪造图像-文本对来训练语言模型。我们的贡献总结如下:
- 我们提出了一种基于LVLM的深度伪造检测新框架,通过提示调优集成细粒度伪造提示嵌入,显著增强了模型的泛化能力和可解释性。
- 我们引入了一种知识引导的伪造检测器,生成伪造一致性图,将原始图像和深度伪造图像的描述文本嵌入与图像特征对齐,以增强泛化能力。
- 在FF++、CDF1、CDF2、DFD、DFDCP、DFDC和DF40等多个基准上的大量实验表明,我们的方案在泛化性能上优于现有方法,并且具有支持多轮对话的能力。
2.相关工作
2.1深度造假检测方法
传统的分类架构在早期深度伪造内容的伪造线索检测方面取得了显著成效。近年来,为了提高深度伪造检测模型的泛化能力,研究者们探索了多种策略,包括数据增强(Li et al., 2020a; Shiohara & Yamasaki, 2022; Nguyen et al., 2024)、特征一致性分析 (Zhao et al., 2021b; Yan et al., 2023)以及频域异常检测(Jeong et al., 2022; Liu et al.,2021; Wang et al., 2023a),。尽管这些方法提高了检测精度,但它们主要依赖于数据增强或增强特征提取(Yan等,2024),并且往往忽略了外部人类知识的整合。然而,许多深度伪造的特征嵌入在人类知识中,仅靠数据或特征增强难以捕捉这些特征。这一局限性显著限制了现有算法的泛化能力。本文提出了一种基于LVLM的深度伪造检测框架,该框架通过将图像特征与真实/伪造描述对齐,增强了模型检测未知深度伪造的能力。
2.2大型视觉语言模型
近期,大型视觉-语言模型(LVLMs)在多模态任务中的应用潜力得到了显著展示(Gunjal等,2024;Leng等,2024;Gu等,2024)。典型的LVLM架构包括图像编码器、投影器和语言模型(LLM)。图像编码器从输入图像中提取视觉特征,这些特征随后通过投影器转换为视觉提示嵌入。这些视觉嵌入与文本提示嵌入结合,输入到语言模型中生成响应。基于这一架构,诸如BLIP-2(李等,2023)、LLaVA(刘等,2024a)和MiniGPT-4(朱等,2024)等模型,在自然场景的语言教学(苏等,2023;杨等,2024)和视觉推理(陈等,2024)方面取得了显著进展。一些研究还探讨了低维语言模型(LVLMs)在伪造检测中的应用。FakeShield(徐等,2024)构建了一个大规模的图像-文本数据集,并引入了一种专门用于伪造检测的基于LVLM的框架。FKA-Owl(刘等,2024b)提出了一种新的假新闻检测框架,该框架利用特定于伪造的知识来增强LVLMs,使其能够对操纵行为进行推理。同样,FFAA(黄等,2024)提出了一种多模态LVLM方法,用于可解释的、开放世界的面部伪造分析,突显了LVLMs在伪造检测任务中的潜力。
尽管取得了这些进展,当前的基于语言模型的深度伪造检测方法(LVLMs)主要集中在通用语言处理和视觉理解上,往往忽略了对深度伪造检测任务至关重要的细节。这一局限性限制了它们在伪造定位和分类上的效果。为了解决这一问题,我们开发了一种新的深度伪造检测框架,该框架基于语言模型,通过构建细粒度的伪造提示嵌入来指导语言模型检测细微的篡改行为。通过在预训练的语言模型中整合丰富的外部知识,我们的方案不仅增强了模型对各种伪造类型的泛化能力,还保留了其原有的对话功能。
3.拟提出的方法
我们的目标是使低维线性模型(LVLMs)能够准确地区分真实与伪造的面孔。尽管LVLMs是在大规模数据集上训练的,但它们主要针对通用图像理解任务,往往缺乏对伪造细节的敏感度。为了解决这一问题,我们提出了一种基于LVLM的新深度伪造检测框架,通过构建精细的伪造提示,提高了对深度伪造伪影的敏感度。如图2所示,我们的方案基于传统的语言模型框架,该框架包括图像编码器、投影器和语言模型。
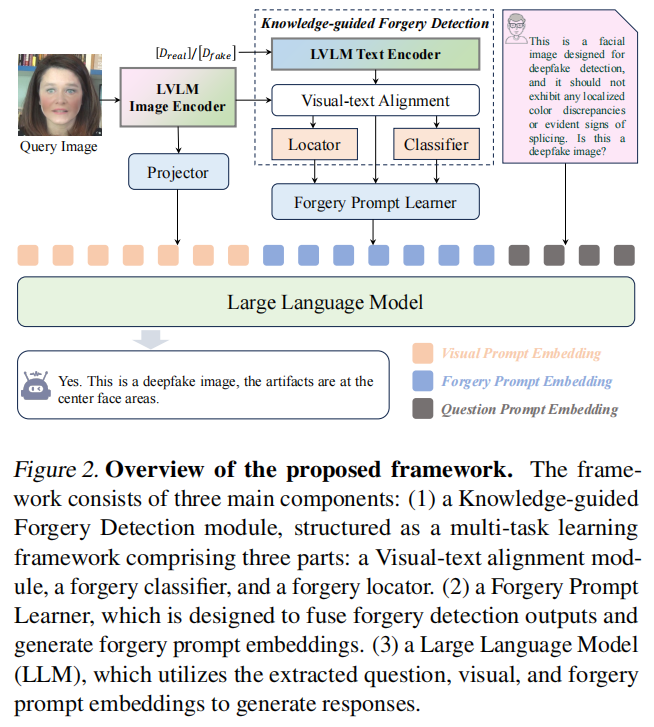
图像编码器从输入图像中提取内容特征,这些特征随后由投影器转换为视觉提示嵌入\(E_{visual}\)。此外,用户查询被编码为问题提示嵌入\(E_{question}\)。为了训练用于伪造检测的模型,我们采用了两阶段流程。
在第一阶段,我们训练了一个知识引导型伪造检测器(Knowledge-Guided
forgery
Detector,简称KFD),通过计算图像内容特征与原图/深度伪造图像描述之间的相关性来进行伪造检测和定位。这一阶段确保KFD能够通过学习精细的视觉-文本关联,有效分类和定位伪造物。
在第二阶段,我们通过LLM提示调优,将KFD的知识整合到LVLM框架中。具体来说,我们设计了一个伪造提示学习器,用于将与伪造相关的特征转换为伪造提示嵌入。这些嵌入,连同问题和视觉提示的嵌入,随后被输入到LLM中,以生成文本检测结果。
为了进一步提高模型的可解释性,我们采用了交替训练策略,同时使用深度伪造数据集和通用视觉问答(VQA,
Visual Question
Answering)数据集。这使得模型不仅能够准确检测深度伪造,还能保持多轮对话的能力。
3.1.知识引导型伪造检测器
伪造的视觉文本对齐
为了获取伪造检测的相关知识,我们受到(Jeong等,2023)的启发,将图像内容特征与预定义的文本描述特征进行对齐,以获得细粒度的伪造特征。这一过程如图3所示。
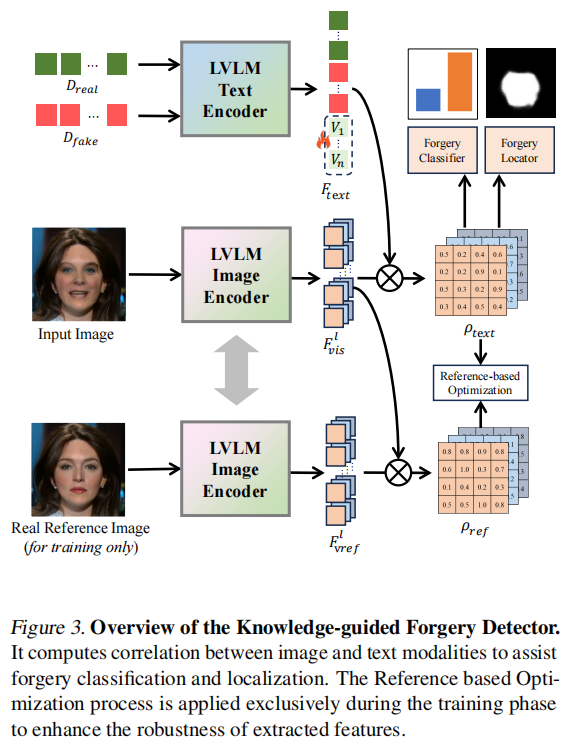
具体来说,该过程涉及一个预训练的图像编码器和一个预训练的文本编码器。图像和文本编码器均来自ImageBind(Girdhar等,2023),这是一个大规模的多模态预训练模型,拥有广泛的跨模态知识。我们首先定义了真实图像描述(\(D_{real}\))和虚假图像描述(\(D_{fake}\)),并使用文本编码器提取它们的语义特征。这些特征与一个可学习的嵌入层连接,生成特定任务的文本嵌入\(F_{t e x t}\in\mathbb{R}^{2\times C_{t e x
t}}\),其中\(C_{text}\)表示文本嵌入的维度。对于视觉特征,我们从图像编码器中选取l层,获取每层提取的中间特征。这些中间特征通过线性层处理后,生成视觉特征\(F_{v i s}^{i}\in\mathbb{R}^{H_{i}\times
W_{i}\times C_{t e x
t}}\),其中i表示第i层。计算视觉特征与文本特征之间的相似度图,并将这些相似度图连接起来形成一致性图。计算一致性图的公式如下:
\[\rho_{t e x t}=\{F_{v i s}^{i}F_{t e x
t}^{\mp}\}.\]
此外,为了优化提取的图像特征,我们计算了参考图像(原始图像)\(F_{v r e f}^{i}\)与输入图像特征\(F_{v i
s}^{i}\)之间的余弦相似度。这种相似度优化提高了图像编码器提取特征的鲁棒性。需要注意的是,参考图像仅在训练阶段使用,在推理阶段则不使用。相似度计算如下:
\[\rho_{r e f}=\{C o s(F_{v r e f}^{i},F_{v i
s}^{i})\}.\]
伪造定位器和分类器
为了提高模型对深度伪造内容的敏感度,我们引入了伪造定位器和伪造分类器,用于识别伪造区域并区分原始图像和深度伪造图像。伪造定位器由三个分支组成,每个分支分别对相应的连贯图进行下采样和上采样处理,随后通过插值、连接和卷积层生成分割图。伪造分类器同样包含三个分支。首先,三个特征图通过卷积和池化操作进行处理,然后将这些特征图连接起来,形成统一的特征表示。接下来,我们使用两个全连接层来计算图像的真实或伪造概率。为了提高伪造分割的准确性,我们采用了Dice损失函数。此外,我们还通过优化文本一致性图(\(\rho_{t e x t}\))与参考一致性图(\(\rho_{r e
f}\))之间的匹配度,进一步增强了提取的伪造特征的鲁棒性。这两个图都旨在准确地定位伪造区域。定位损失的公式如下:
\[\mathcal{L}_{l o c}=D i c
e\big(\phi(\rho_{t e x t}),g t\big)+\lambda D i c e\big(\phi(\rho_{r e
f}),g t\big),\] 其中,\(\phi\)代表伪造定位器,gt代表真实掩码。Dice损失用于优化预测分割与真实掩码之间的重叠度。λ是用于平衡这两种损失的权重参数。
此外,我们采用二元交叉熵损失来优化伪造分类任务的性能,其公式如下:
\[\mathcal{L}_{c l
s}=-\left(c\log({\hat{c}})+(1-c)\log(1-{\hat{c}})\right),\]
其中\(\hat{c}\)是预测的伪造分数,表示该图像是否为假;c是真实标签(0代表真实,1代表伪造)。
3.2.伪造提示学习和LLM
伪造提示学习
为了有效将伪造特征转化为语言模型的输入,我们提出了一种伪造提示学习器,该学习器能够将伪造分割图、伪造分数和一致性图转换为伪造提示嵌入。同时,我们还为伪造提示学习器添加了可学习的提示嵌入,以在深度伪造检测任务中融入额外信息。伪造提示学习器由两个卷积神经网络、一个全连接层以及可学习的提示嵌入\(E_{b a s e}\in\mathbb{R}^{n_1\times C_{e m
b}}\)组成,其中\(C_{e m
b}\)表示嵌入向量的维度。具体来说,两个卷积网络将伪造分割图和一致性图转换为向量表示,分别为\(E_{l o c}\in\mathbb{R}^{n_2\times C_{e m
b}}\)和\(E_{c o n
s}\in\mathbb{R}^{n_3\times C_{e m b}}\)。伪造得分扩展为\(E_{c l s}\in\mathbb{R}^{1\times C_{e m
b}}\)。这些嵌入被连接并输入到卷积层,生成伪造提示嵌入\(E_{forgery}\in\mathbb{R}^{n_f\times C_{e m
b}}\)。最后,伪造提示嵌入、视觉提示嵌入和问题提示嵌入被输入到语言模型中。
LLM
LLM通过处理提示嵌入来解读上下文,并准确识别伪造区域。通过结合视觉细节(来自\(E_{forgery}\)和\(E_{visual}\))与用户查询(来自\(E_{question}\)),LLM生成的响应不仅提供了伪造检测的判断,还能精确定位被篡改的区域(如眼睛、嘴巴)。在此过程中,我们利用提示调优和LoRA技术,使用专门为深度伪造检测任务定制的模拟图像-文本对来微调LLM。为了确保LLM生成的响应准确无误,我们采用交叉熵损失来衡量预测响应与目标标签之间的差异。公式如下:
\[\mathcal{L}_{l l
m}=-\sum_{j}y_{j}\log(\hat{y_{j}}),\] 其中,\(\hat{y_{j}}\)表示第j个标记的预测概率,而\(y_{j}\)则是对应的真值标签。
3.3.LLM提示调优的数据
伪造数据模拟
我们计划让LLM能够识别原始图像和深度伪造图像,并且还能定位伪造区域。这需要对专门描绘被篡改区域的图像-文本对进行训练,但目前这类数据尚不可用。为了解决这一问题,我们借鉴了SBI(Shiohara
&
Yamasaki,2022)的技术,利用现有的真实图像构建图像-文本对。首先,我们从真实图像\(I_{real}\)中生成面部特征点,然后随机选择1到n个区域(如鼻子、嘴巴或眼睛)作为目标伪造区域。接着,我们对真实图像应用轻微的仿射变换,生成仿射变换后的图像\(I_{affine}\)。原始的真实图像作为背景(目标面部),而仿射变换后的图像则作为前景(源面部)。根据Nguyen等人(2024)的方法,我们使用泊松混合技术将前景和背景图像结合在一起。混合过程如下:
\[{\bf I}_{M}={\bf M}\odot{\bf I}_{a f f i n
e}+{\bf(1-M)\odot I_{r e a l}}\]
其中M是基于选定伪造区域构建的凸包掩膜,其取值范围为0到1。符号\(\odot\)表示元素级乘法。
问答内容
训练LVLM需要大量的视觉问题与答案对。因此,我们为每张图像构建了相应的文本查询。为了确保与深度伪造检测任务的兼容性,我们在每个查询中加入背景描述,例如:“这是一张专为深度伪造检测设计的面部图像,不应出现局部颜色差异或明显的拼接痕迹。”这可以视为一种人类先验知识。此外,我们将知识引导伪造检测器(KFD)的预测结果融入提示中,例如:“根据KFD预测,伪造分数为0.93。”然后,我们会提出一个与图像内容相关的问题,例如:“这是一张深度伪造图像吗?”LVLM的响应会指出图像中是否存在伪造,并指出伪造的具体位置。例如,“是的,这是一张深度伪造的图片,伪造区域位于图像的中心面部。”在这里,伪造区域是根据在伪造数据模拟过程中选定的区域来定义的。通过定义查询和响应,我们可以训练LVLM来区分原始图像和深度伪造图像。输入到LVLM的提示格式如下:
\(\#\#\#Human: <Img>E_{visual}</Img>E_{f o r g e r y}[Task description][KFD result] Is this a deepfake image?<br/>\#\#\#Assistant:,\)
其中,\(E_{visual}\)表示视觉提示嵌入,\(E_{forgery}\)表示伪造提示学习器学习到的伪造提示嵌入,KFD结果表示伪造分类结果,Task description提供了深度伪造检测任务的文本描述。
4.实验
4.1.实验设置
数据集。FaceForensics++(FF++)数据集(Rossler等人,2019)包含1000段真实视频和5000段伪造视频,涵盖五类深度伪造类别,是深度伪造检测领域应用最广泛的基准数据集之一。DFD(Dufour与Gully,2019)、CDF1、CDF2(Li等人,2020b)、DFDCP(Dolhansky,2019)、DFDC(Dolhansky等人,2020)以及DF40 (Yan等人)等常用数据集,常用于评估深度伪造检测的泛化性能。所有图像均通过Dlib和RetinaFace进行裁剪处理。本研究仅使用FF++数据集的真实数据进行训练。
评估指标。根据现有方法(Shiohara & Yamasaki,2022;Nguyen等,2024),我们采用视频级别的接收者操作特征曲线下的面积(AUC)和平均精度(AP)作为评估指标。此外,我们通过评估语言模型(LLM)文本输出的真实性(是或否)的二分类结果,来评估其性能,从而计算出LLM响应的视频级别AUC。
比较方法。我们根据几种最先进的深度伪造检测算法评估我们的方法(Rossler et al., 2019; Li et al., 2020a; Qian et al., 2020; Zhao et al.,2021a; Liu et al., 2021; Zhao et al., 2021b; Cao et al., 2022;Shiohara & Yamasaki, 2022; Wang et al., 2023a;b; Dong et al., 2023; Yan et al., 2023; Xu et al., 2023; Yan et al.,2024; Nguyen et al., 2024; Cheng et al., 2024; Lin et al.,2025; Luo et al., 2024; Ba et al., 2024; Fu et al., 2025)和基于LVLM的方法 (Khan & Dang-Nguyen, 2024; Su et al., 2023; Liu et al., 2024b; Wang et al., 2024a)
实现细节。我们的方法采用了PandaGPT架构,该架构中集成了ImageBindHuge模型作为图像和文本编码器。我们从编码器的第16层、第24层和第32层提取特征,与文本特征计算一致性图,然后将这些图传递给Vicuna-7B模型进行推理。为了实现多轮对话功能,我们在深度伪造数据集和PandaGPT数据集之间交替训练。伪造区域的数量n设定为3。所有图像均裁剪至224×224。训练在两块Nvidia RTX 4090 GPU上进行,共50个周期,使用Adam优化器,学习率为1e-4,权重衰减为1e-5。损失参数λ设为1。
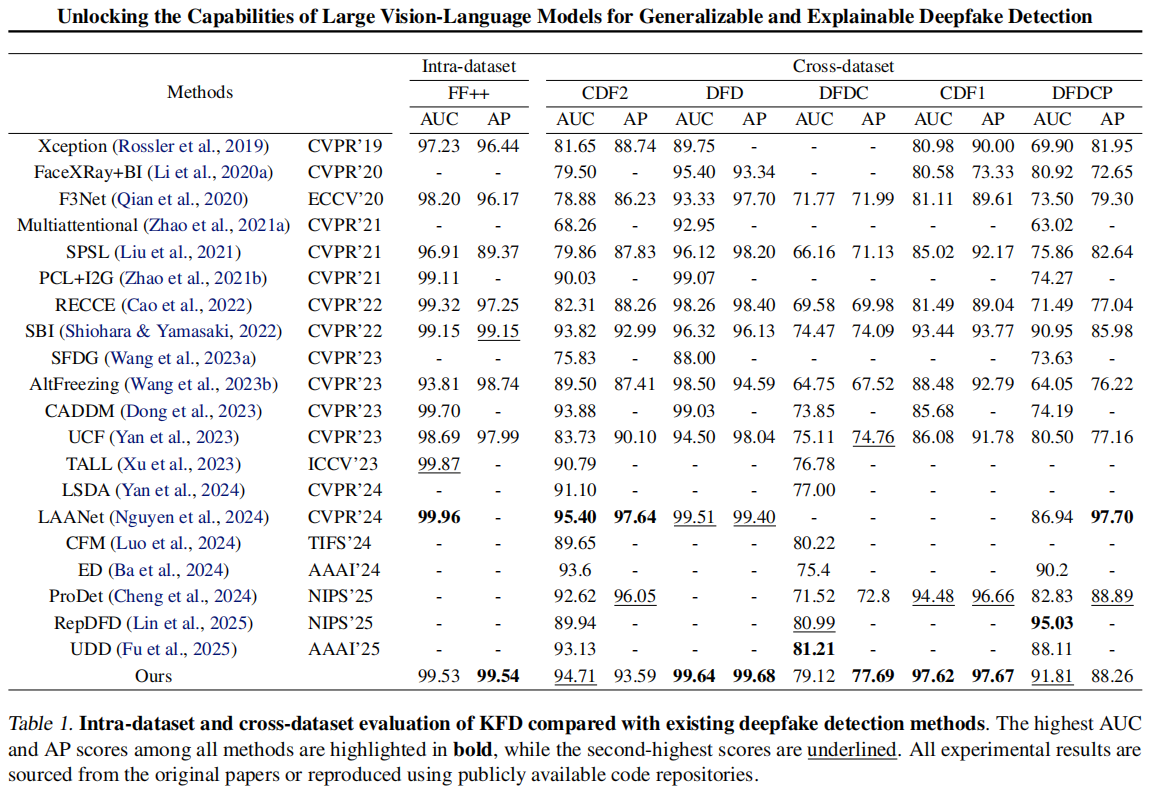
4.2.与SOTA检测方法的比较
我们首先将我们的方法与几种最先进的深度伪造检测方法进行比较。(Li et al., 2020a; Shiohara &Yamasaki, 2022; Cao et al., 2022; Huang et al., 2023; Yan et al., 2024; Tan et al., 2024)
4.3.与基于LVLM的方法的比较
LVLM检测性能
我们对我们的框架进行了基准测试,与最先进的基于LVLM的分类方法(Khan
& Dang-Nguyen,2024;Lin et al.,2025;Fu et
al.,2025)和VQA方法(Su et al.,2023;Wang et al.,2024a;Liu et
al.,2024b)进行了对比。在这些评估中,图像和相应的查询都被作为输入提供给LVLM,模型需要判断图像的真实性(真实或伪造)。对于分类任务,我们的知识引导的伪造检测器(KFD)在检测性能上显著优于现有的基于LVLM的分类方法。对于VQA模型如PandaGPT、Qwen2-VL和FAKOwl,我们利用LLM的输出(“是”或“否”)来判断真实性,并计算AUC值进行评估。如表3所示,我们的方法在FF++、CDF2、DFD、CDF1和DFDCP数据集上始终优于现有的基于LVLM的VQA方法,表现更佳。
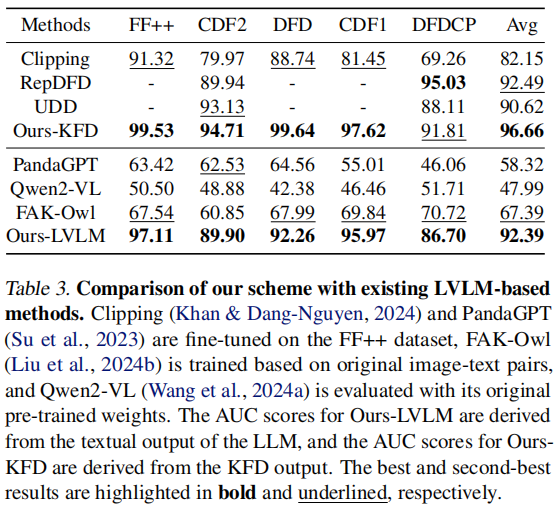
对话式可视化。与传统检测方法不同,我们的方案不仅支持深度伪造检测,还能实现多轮对话功能,让用户能更深入地了解图像内容。图5展示了数据集内和跨数据集评估中的部分对话示例。实验结果表明,我们提出的方案能精准识别图像中的伪造区域,而大语言模型则提供了精准且符合上下文的判断。更多多轮对话示例详见补充材料。

4.4.分析
训练图像数量。
在真实场景中获取大规模人脸图像往往难以实现,因此我们通过调整训练图像数量来评估模型性能。具体而言,我们从FF++数据集中随机抽取50、100、200和500张真实图像,生成对应的假图像-文本对用于训练。训练步骤固定为500次。基于LLM的响应结果计算视频级AUC指标。
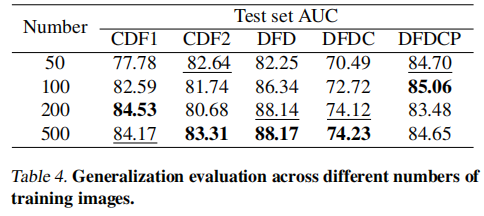
如表4所示,仅使用500张训练图像,我们的方法就达到了业界领先水平。尽管减少训练集的规模会导致精度略有下降,但我们的方法即使在仅有100张训练图像的情况下仍能保持竞争力。这突显了我们框架的稳健性,尤其是在数据稀缺的情况下。
即时调优机制的效能验证。
该机制通过将伪造检测知识转化为大模型输入,显著提升识别准确率。其核心架构包含伪造提示学习器(FPL)、大模型及LoRA策略。为评估该模块效能,我们在FF++、CDF2和DFDC数据集上开展消融实验。
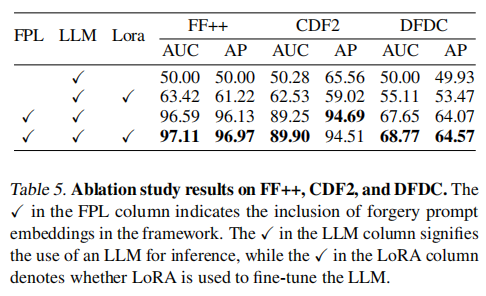
通过计算大模型在鉴别真伪图像时的输出结果曲线下面积(AUC),如表5所示:配备伪造提示学习器的模型展现出更优的AUC值,表明其在深度伪造检测任务中具有更强的识别能力。值得注意的是,集成LoRA策略后性能进一步提升,在多个数据集上均取得优于未采用该策略的配置结果。
对训练数据集的通用性
深度造假检测的通用性与所使用的训练数据的多样性密切相关。为验证该方法在不同数据集上的有效性,我们在多个训练集上训练模型,并在FF++、CDF2、DFDCP和DFDC数据集上进行了跨数据集评估。
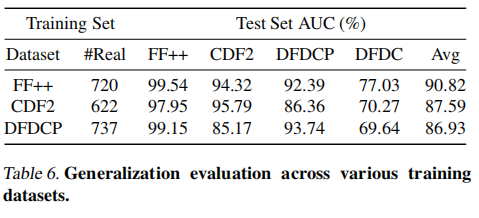
如表6所示,我们根据语言模型的响应计算了检测AUC值。结果表明,本方法在多样化数据集上展现出强大的鲁棒性,并能通过不同类型的伪造样本进行泛化训练,有效应对各类伪造类型。
不同LLM架构的影响
深度伪造检测性能与所采用的特定大模型架构密切相关,因为不同大模型具有独特的特性。为评估各类大模型架构的检测表现,我们选取了Llama-3.2-
1B、Llama-3.2-3B和Vicuna-7B三个模型进行测试。实验在FF++、CDF1、DFD和DFDC数据集上展开。如表7所示,我们发现大规模架构始终展现出更优的检测效果。这一趋势表明,参数容量更大的模型更能精准捕捉细微的伪造痕迹。
基于参考优化的消融研究
为了验证基于参考的优化过程的有效性,我们在两种配置下训练了模型:一种是使用基于参考的优化过程(ROP),另一种是没有使用该过程。随后,我们评估了该方法在不同数据集上的泛化能力。表8总结了在CDF1、CDF2、DFDC和DFDCP数据集上的泛化性能。结果显示,即使不进行相似性优化,所提出的框架也优于现有方法。此外,引入相似性优化过程后,性能进一步提升,这进一步证明了其在增强深度伪造检测模型泛化能力方面的有效性。
5.结论
在这项研究中,我们提出了一种新的深度伪造检测框架,该框架利用语言模型(LLM)来提升泛化能力和解释性。通过整合知识引导的伪造检测器,我们能够有效地将图像特征与原始图像和深度伪造图像的文本描述进行匹配,从而促进伪造分类和定位。此外,我们还引入了一个伪造提示学习器,能够将细粒度的伪造特征转化为语言模型的输入,确保了准确的伪造检测结果。在包括FF++、CDF1、CDF2、DFD、DFDCP和DFDC在内的多个基准测试中,我们的方案在泛化性能上超越了现有方法。值得注意的是,我们的框架还支持多轮对话,提供了交互式且可解释的检测结果。这些发现强调了基于语言模型的方法在提升深度伪造检测技术方面所具有的潜力。