WMGTI
Which Model Generated This Image? A Model-Agnostic Approach for Origin Attribution
Fengyuan Liu1, Haochen Luo1, Yiming Li2, Philip Torr1, and Jindong Gu1⋆
1 牛津大学,牛津大学OX1 3PJ,英国
2
新加坡南阳科技大学,新加坡639798
摘要
视觉生成模型的最新进展使高质量图像的生成成为可能。为了防止误用生成的图像,识别生成这些图像的原始模型是很重要的。在这项工作中,我们研究了在一个实际的环境中,只有少数由源模型生成的图像可用,而源模型不能被访问。目标是检查一个给定的图像是否由源模型生成。我们首先将这个问题表述为一个少量的单类分类任务。为了解决这一任务,我们提出了OCC-CLIP,基于CLIP的框架,用于少镜头单类分类,即使在多个候选者中也能识别图像的源模型。与各种生成模型相对应的大量实验验证了我们的OCC-CLIP框架的有效性。此外,一个基于最近发布的DALL·E-3API的实验验证了我们的解决方案的实际适用性。我们的源代码可以在https://github.com/uwFengyuan/OCC-CLIP上找到。
关键词:模型属性·生成的图像·CLIP分类
1介绍
最近的视觉生成模型能够产生异常质量的图像,这已经引起了公众对知识产权(IP)保护和滥用[15,31,33,34]的问责制的关注。为了应对人工智能生成内容(AIGC)带来的挑战和机遇,美国最近的一项行政命令[3]规定,所有人工智能生成的内容必须清楚地标记其来源,如稳定扩散[46]。这使得生成图像的起源归因在现实世界的应用中至关重要,指的是识别给定图像是否由特定模型生成的过程。
为了解决上述的起源归因问题,我们在社区中探索了三种主要的方法。第一种方法涉及到[35,37,43,57,59]的水印,这需要对生成的结果进行额外的修改,从而影响生成的质量。第二种方法是在训练过程中向模型中注入指纹[10,68-70],并使用一个有监督的分类器来识别这些指纹。这一过程需要改变训练工作。也提出了无修改的方法,它不需要修改生成或训练过程。具体来说,现有的方法利用了逆工程[29,64],基于一个合成样本可以由创建它的生成器最准确地重建的想法。然而,逆工程方法需要访问目标模型,并需要采样许多图像作为参考。
在这项工作中,我们的目标是在一个实际的开放世界环境中进行起源归因(图1),在这个环境中,模型参数不能被访问,并且只有由模型生成的少数样本可用。这种设置在现实世界的应用中是有意义的,因为当前的生成模型,例如DALL·E-3[2],并不是开源的,并且从它们中取样许多图像需要大量的成本。
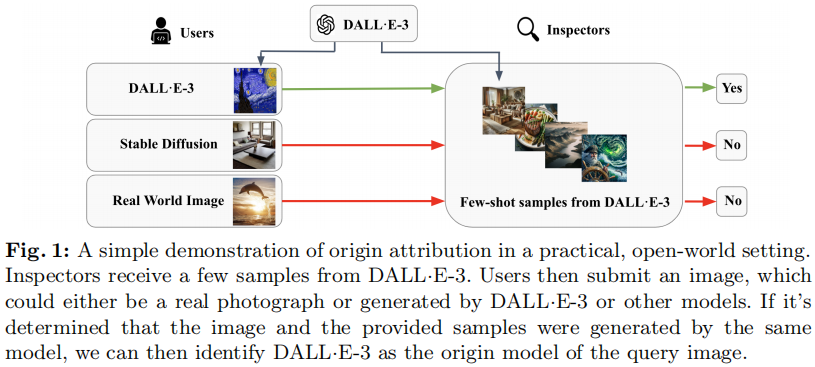
图1:在一个实用的、开放的世界环境中,起源归因的简单演示。检查员们收到了一些来自DALL·E-3的样本。然后用户提交一张图像,它可以是真实的照片,也可以是由DALL·E-3或其他模型生成的图像。如果确定该图像和所提供的样本是由同一模型生成的,那么我们就可以识别出DALL·E-3为查询图像的原始模型。
为了克服这种情况下的挑战,我们首先将问题表述为一个
few-shot的单类分类任务。然后,我们提出了一个基于clip的框架作为一个有效的解决方案,称为OCC-CLIP。使用我们的框架,我们可以确定给定的图像和少数可用的图像是否从同一模型生成。如果是这样,我们可以自信地识别生成少数图像的模型作为给定图像的原始模型。此外,我们还证明了我们的方法可以扩展到对多个源模型进行起源归因。
在各种生成模型上的大量实验证明,我们提出的框架可以有效地确定给定图像的起源归属。此外,在few-shot可用的情况下,以及对给定的图像应用图像预处理时,我们的框架显示了优越性。它在多源起源归因场景中也被证明是有效的。此外,我们的实验,基于最近发布的DALL·E-3[2]API,证实了我们的解决方案在实际商业系统中的有效性。
我们的主要贡献可以总结如下。
- 我们提出了一个新的任务,在一个实际的设置中,生成的图像被归因于原始模型,只有很少的镜头可用的图像由模型生成。
- 我们将这个问题表述为一个简单的一类分类任务,然后提出了一个基于CLIP的框架,称为OOC-CLIP,来解决这个问题。
- 在8个生成模型上进行了广泛的实验,包括扩散模型和GANs。我们的解决方案在一个真实世界的图像生成系统上进行了进一步的验证,即DALL·E-3[2]。
2相关工作
3方法
在本节中,我们首先介绍标准的基于CLIP的分类框架,然后介绍我们用于少量单类分类的OCC-CLIP框架。最后,我们将展示如何将我们的框架扩展到多个类。
3.1基于clip的分类背景
CLIP是一个预先训练过的多模态模型,用于预测图像是否匹配文本提示符。它包括一个图像编码器\(E_v(\cdot)\)和文本编码器\(E_t(\cdot)\)。预先训练好的CLIP可以通过将图像与提示列表[16]进行比较来执行few-shot多类分类,每个提示列表代表一个类。在形式上,假设我们有K个类。设\(X^v\in X\)表示一个图像,\(X^t_i\)表示表示第\(i\)文本类的提示符。图像\(X^v\)的预测类概率计算如下: \[p(\mathrm{class}=i|v)=\frac{\exp(\mathrm{sim}(E_{i}(X_{i}^{t}),E_{v}(X^{v})))}{\sum_{j=1}^{K}\exp(\mathrm{sim}(E_{t}(X_{j}^{t}),E_{v}(X^{v})))}\]
其中,sim(·)测量两个嵌入之间的距离,例如,点积。
在上面的分类中,使用手工制作的文本提示来表示类[16]。快速的设计需要专门的知识,而且创建起来很耗时。为了缓解这一问题,Zhou等人[71]引入了上下文优化(CoOp)的概念,它使用可学习的向量来细化与提示相关的单词。CoOp使模型能够根据合适的提示进行自动优化,而不是手动设计提示。形式上,第i类的提示符可以表示为\(X_{i}^{p}=[t]\otimes[C L A S
S_{i}]\),其中t是可学习的上下文向量,\(\otimes\)是一个连接操作,\(CLASS_i\)对应于第i类的名称。优化的目的是尽量减少每个\(X_i^v\)的 ground-truth \(Y_i\)的误差。这是通过对可学习的提示使用交叉熵损失函数\(\mathcal L\)来实现的。 \[\operatorname*{min}_{X^{p}}\sum_{j=1}^{N}\sum_{i=1}^{K}\mathcal{L}(f(E_{v}(X_{j}^{v}),E_{t}(X_{i}^{p})),Y_{i})\]
3.2基于clip的少镜头单类分类
基于clip的分类器,CoOp,可以在少数人的学习设置中实现优异的性能,其中每个类都有一些图像可用。然而,在我们的设置中,只有少数由生成模型生成的一类图像是可用的。因此,一个标准的基于clip的分类器不能直接应用于解决少量的单类分类任务。
我们现在提出了基于clip的单类分类框架,称为OCC-CLIP。在我们的框架中(图2),从生成模型中收集到的少数图像被视为目标类,而从一个干净的数据集中随机采样的图像被标记为非目标类。
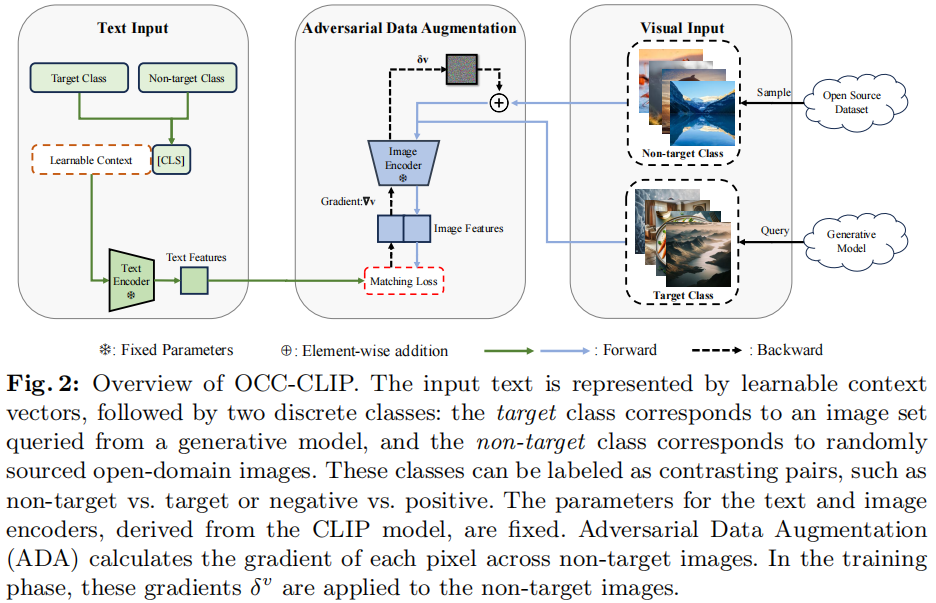
图2:OCC-CLIP的概述。输入文本由可学习的上下文向量表示,然后是两个离散的类:目标类对应于从生成模型中查询到的图像集,而非目标类对应于随机来源的开放域图像。这些类可以被标记为对比对,如非目标与目标或阴性与阳性。从CLIP模型中得到的文本和图像编码器的参数是固定的。对抗性数据增强(ADA)计算非目标图像上的每个像素的梯度。在训练阶段,这些梯度$ ^v$被应用于非目标图像。
这两个类可以被标记为任何对比性的对,如非目标与目标或阴性与阳性。对这些图像分别对对应于目标类和非目标类的两个可学习提示进行了优化。
为非目标类选择的少数图像不能很好地代表非目标类的整个分布,因为它们是从一个开源数据集(例如,ImageNet
[9])中随机采样的。为了克服这一挑战,我们提出了一种对抗性数据增强(ADA)技术,该技术在训练过程中扩展了非目标类空间的覆盖范围,更接近于目标空间的边界,从而提高了模型学习目标模型归因的能力。ADA的目标是通过在非目标图像中添加小扰动\(\delta
^v\)来最大化损失,而可学习提示的目标是通过学习目标和非目标类之间的边界来最小化损失。综上所述,OCC-CLIP中的优化可以表述为:
\[\operatorname*{min}_{X^{p}}\operatorname*{max}_{\delta^{\phantom{A}}}\sum_{j=1}^{N}\sum_{i=1}^{K}\mathcal{L}(f(E_{v}(X_{j}^{v}+\delta_{j}^{v}),E_{t}(X_{i}^{p})),Y_{i})\]
其中,\(\delta
^v\)是由我们的ADA技术计算出的对抗性图像扰动。
我们的OCC-CLIP的实现见算法1。

如算法所示,对非目标类的图像进行了前后传递的梯度信息。梯度信息用于计算对抗性扰动。可学习的提示将在另一个向前和后向的图像上更新。在实验部分讨论了训练超参数的敏感性。
在优化过程中,CLIP的视觉和文本编码器都被冻结。在验证过程中,如果将其分类为目标类,则将确定一个图像是由与目标图像的源模型相同的生成模型生成的图像。
3.3基于CLIP的少镜头多类分类
我们还探讨了多源起源归因场景。例如,为了确定图像的起源是否可以归因于ProGAN [25]、 Stable Diffusion[46]或Vector Quantized Diffusion[19],我们可以使用三个与这些模型相对应的单类分类器进行分类。给定一组训练过的K个单类分类器\(\{O C C_{1},O C C_{2},\cdot\cdot\cdot,O C C_{K}\}\)对于K个类和一个阈值\(\theta\)(例如0.5),对于一个输入样本\(X^v\),让\(s_{i}(X^{v})\)表示第\(i\)个分类器\(OCC_i\)给出的\(X^v\)分数。样本\(X^v\)的预测类\(C(X^{v})\)确定如下: \[C(X^{v})=\left\{\begin{array}{l l}{\mathrm{arg~max}_{i}\epsilon(y,...,K)~s_{i}(X^{v})}&{\mathrm{if~max}_{i\in\{1,...,N\}}\;s_{i}(X^{v})\gt \theta,}\\ \mathrm{others}&{mathrm{otherwise.}}\end{array}\right.\] 给定一个图像,如果第i类分类器提供的\(X^v\)的最大分数超过阈值,则将\(X^v\)归类为第\(i\)类。否则,它被认为属于K个分类器定义的类别之外的类别。
4实验
在本节中,我们首先描述实验设置,并介绍我们与基线方法的比较。我们还研究了我们的方法对各种因素的敏感性,如源模型对应的目标类、非目标类数据集、可用图像的数量和图像预处理。此外,我们还展示了我们的框架在多源起源归属场景和真实世界的商业生成API中的有效性。
4.1实验设置
数据集。
基于微软公共对象(COCO,Microsoft
Common Objects in
Context)2014数据集[32]的验证集,五种不同的生成模型,即 Stable Diffusion
Model[46]、Latent Diffusion Model[46]、GLIDE[40]、Vector Quantized
Diffusion[19]和GALIP
[60],共生成202,520张图像。这些模型在四个不同的数据集上进行了预训练,即LAION-5B
[52]、COCO [32]、LAION-400M [53]和过滤后的CC12M
[5]。共生成了5个来自不同源模型的图像数据集,即SD、VQ-D、LDM、Glide、GALIP。为了平衡扩散模型生成的图像数据集的数量和GANs生成的图像数据集的数量,我们使用了[63]提供的已有数据集(即GauGAN
[42]、ProGAN [25]和StyleGAN2
[26])。这些数据集共同作为一个鲁棒的基准,涵盖了两种主要的生成技术:
GANs和扩散模型。
模型。
OCC-CLIP利用了16个上下文向量。这个模型是建立在开源的CLIP框架之上的。该图像编码器使用ViT-B/16体系结构。除了提示学习者外,所有预先训练的参数都是固定的。初始上下文向量从一个正态分布中随机抽样,其特征是均值为0,标准差为0.02。
训练设置。
所有生成的图像都被调整为\(224\times224\),然后根据每个模型的预先训练的数据集进行归一化。采用随机梯度下降作为优化策略,学习速率为0.0001,通过余弦退火进行调制。利用交叉熵损失作为损失函数。默认情况下,对于50次场景,训练过程最多限制在200个周期。测试数据集由从测试集中随机选择的1000张图像组成,以确保可靠的评估。为了抵消在训练的新生阶段爆发的爆炸性梯度,在第一个阶段,学习速率稳定地保持在\(1\times
10^{-5}\)。8个生成模型(即SD、VQ-D、LDM、Glide、GALIP、ProGAN、StyleGAN2、GauGAN)迭代视为目标类,而4个开源数据集(即COCO
[32]、ImageNet [9]、Flickr [66]和CC12M
[5])迭代视为非目标类。但在默认设置下,只有一半的非目标图像被ADA增强,SD被指定为目标图像集,COCO被选择为非目标图像集。
评价。
每个模型都通过接收者操作特征曲线下的面积(AUC)进行评估。接收者操作特征曲线(ROC)是一个图形表示方法,它在不同的阈值水平上绘制了真阳性率(TPR)和假阳性率(FPR)。
AUC表示分类器对随机选择的正实例的排序高于随机选择的负实例的概率。为了减少随机性,每个模型每次都用不同的训练集进行10次训练。然后,在测试集上报告平均AUC和相应的标准偏差。AUC得分越高,表现越好。对于每个表,相应的标准差见补充表。更多的实验细节,如不同的测试任务和准确性分数,可以在补充中找到。
4.2与baseline的比较
基线
由于目前还没有完全适合我们的设置的方法,我们通过评估来自不同使用领域的12种基准方法,对OCC-CLIP进行了综合评估(见表1)。补充部分可以找到与其他基线[13,64]的比较。
5结论
在这项工作中,我们在一个实际的环境中研究起源归属,其中只有少数由源模型生成的图像可用,而源模型不能被访问。所引入的问题首先被表述为一个几镜头的单分类任务。提出了一种简单而有效的基于clip的解决方案框架来解决该问题。我们在开源流行的生成模型和商业生成API上进行的实验表明了我们的框架的有效性。我们的OCC-CLIP框架也可以应用于解决其他领域的少量单一分类任务,我们将其留在未来的工作中。另一项未来的工作是评估我们的框架[7,8,17,18]的自然性和对抗性鲁棒性,并构建对抗性鲁棒性变体[23,65]。