分类 - K-means聚类

How to Use K-means for Big Data Clustering?
发表于Pattern Recognition 2023, 设计了一个优化kmeans的算法BigMeans。
1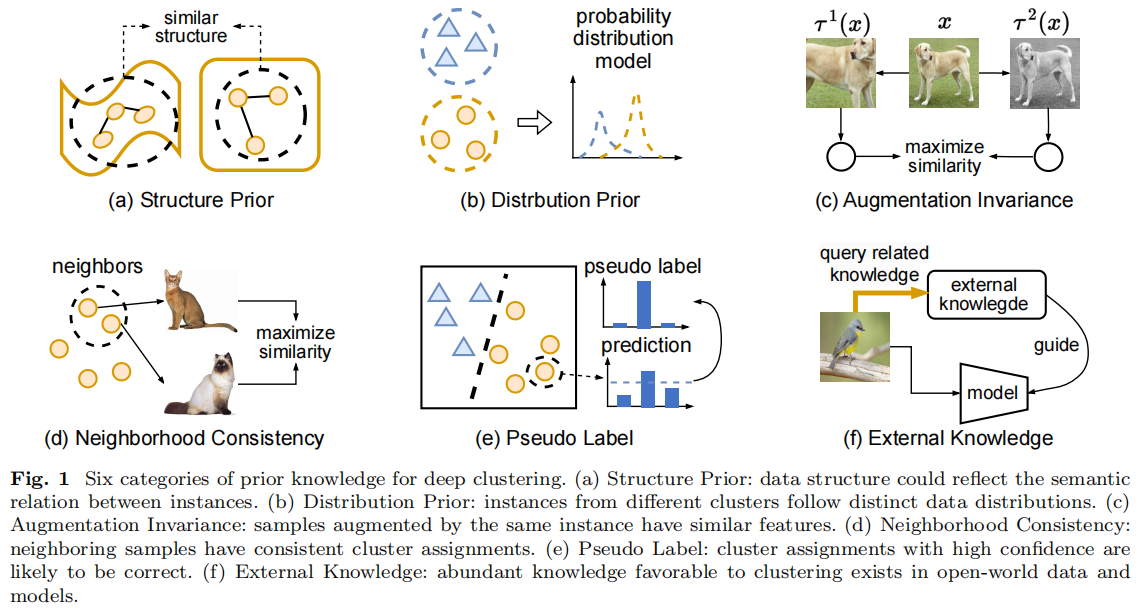
A Survey on Deep Clustering:From the Prior Perspective
发表于Vicinagearth 2024,从先验的角度看深度聚类方法,(a)结构先验:数据结构可以反映实例之间的语义关系。(b)分布先验:来自不同集群的实例遵循不同的数据分布。(c)增强不变性:由相同实例增强的样本具有相似的特征。(d)邻域一致性:相邻的样本具有一致的聚类分配。(e)伪标签:具有高可信度的聚类分配很可能是正确的。(f)外部知识:在开放世界的数据和模型中存在大量有利于聚类的知识。
2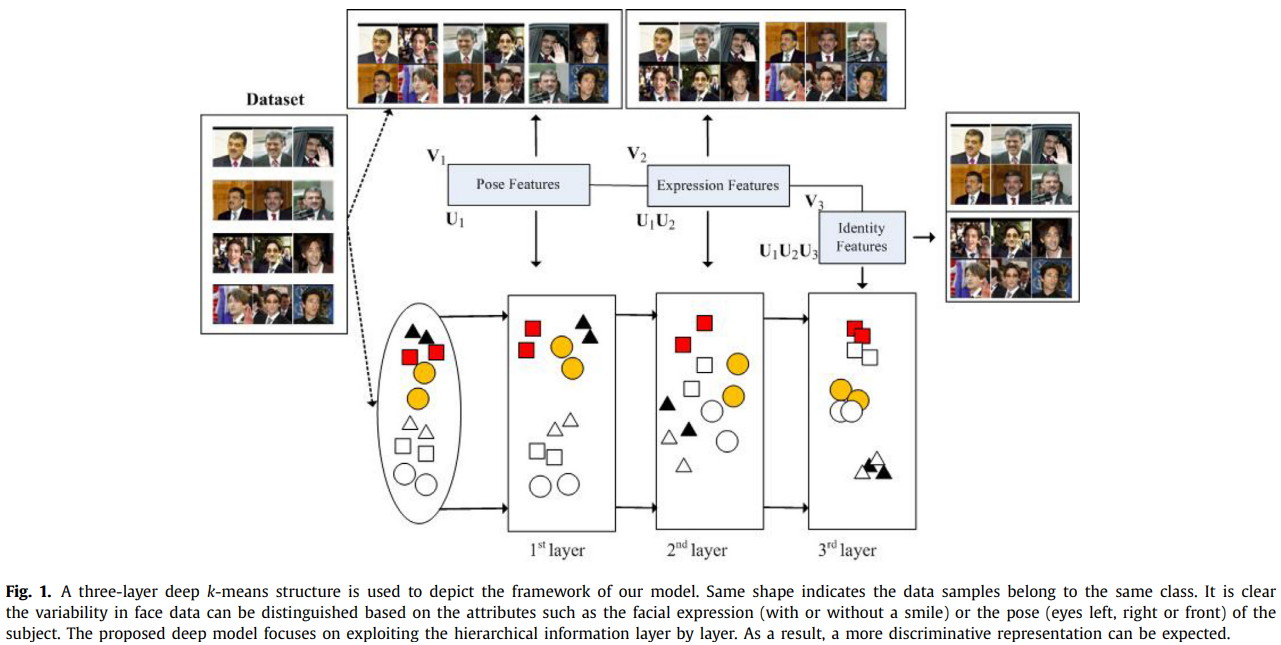
Robust deep k-means:An effective and simple method for data clustering
发表于PR 2021。
3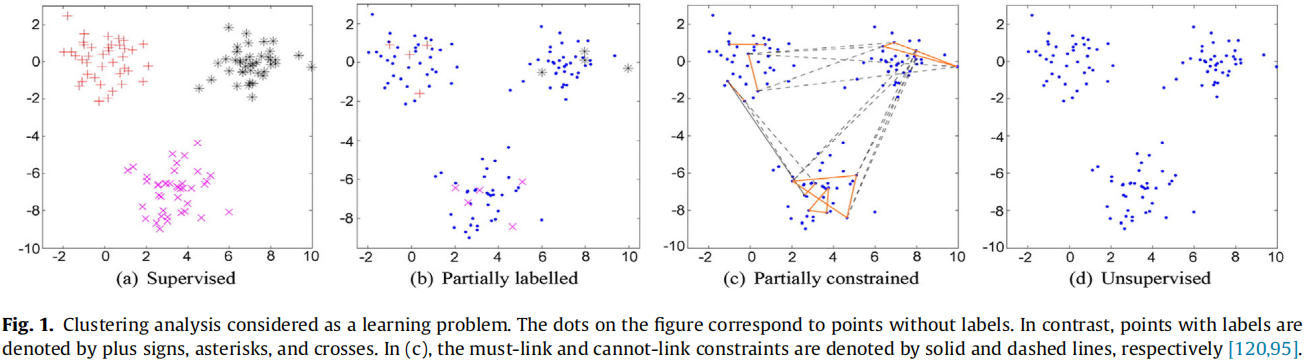
K-means clustering algorithms:A comprehensive review, variants analysis, and advances in the era of big data
发表于Information Sciences 2023。
4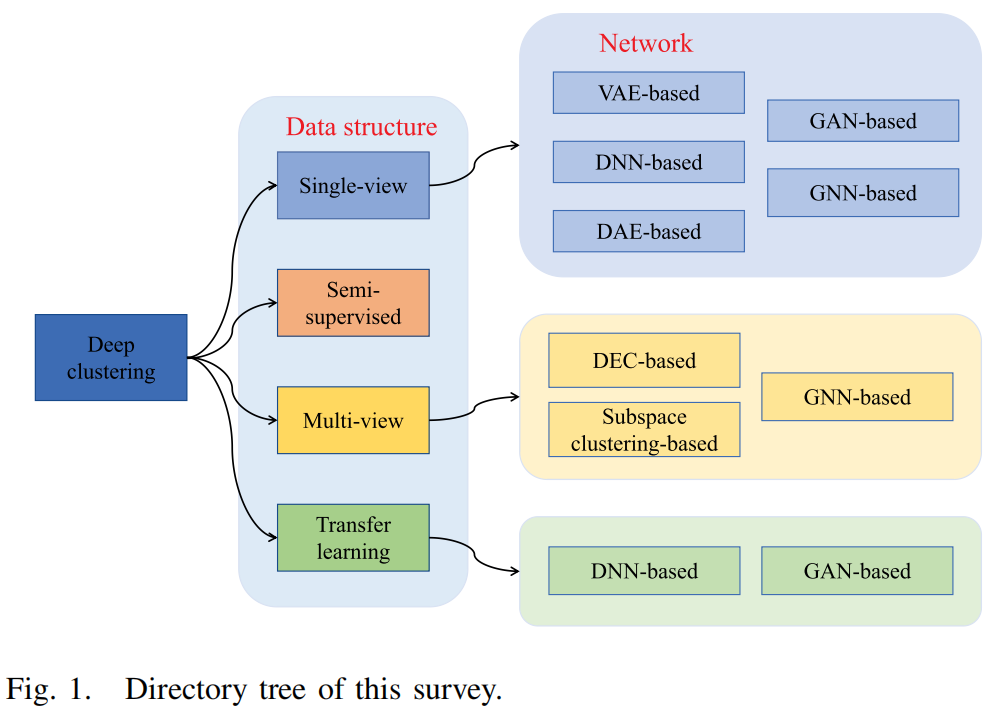
Deep Clustering:A Comprehensive Survey
发表于IEEE Transactions on Neural Networks and Learning Systems 2024,深度聚类的综合综述。
5