这里将列举一些关于图像篡改检测的比赛
2025全球AI攻防挑战赛-赛道一:图片全要素交互认证-检测赛
2025全球AI攻防挑战赛-赛道一:图片全要素交互认证-检测赛_算法大赛_天池大赛-阿里云天池的赛制
图像取证相关的四大任务:图像篡改检测与定位、deepfake、AIGC检测、文档篡改检测与定位
该比赛将上述四大任务整合为图片全要素交互认证任务,选手的模型将在四个任务上进行比较,考研模型的泛化性能力
1.阿里云天池相关
1.1真实场景篡改图像检测挑战赛
1.1.1介绍
真实场景篡改图像检测挑战赛是阿里官方在2022年举办的基于真实场景下的图像篡改检测,更多真实业务场景的篡改图像(资质、文书、截图、门脸图等),更多真实攻击手段(缩放、重压缩、裁剪、截图、社交传输等),更大的篡改数据集(1万张以上图像)。区别于以往的图像取证比赛专注于自然内容图像,我们比赛采用的数据为大量伪造的证书文档类图像。任务是通过提供的训练集学习出有效的检测算法,对测试集的伪造图像进行篡改定位。
官方比赛地址https://tianchi.aliyun.com/competition/entrance/531945
1.1.2评价指标
在测试集的4000张图像中选手需要进行篡改定位,生成对应的二值化mask图像。我们会对选手所提交的mask与我们的基准mask计算F1值与IOU值。
最终成绩计算公式:Score
= IOU + F1
1.1.3优秀结果展示
rank 1(1/1149)
真实场景篡改图像检测挑战赛方案展示(复赛第一)_天池技术圈-阿里云天池
https://github.com/Junjue-Wang/Rank1-Ali-Tianchi-Real-World-Image-Forgery-Localization-Challenge
基于篡改任务中存在的三个挑战,我们设计以下思路:
针对数据集正负样本不均衡问题,采用 lovasz-loss[1],自动平衡训练过程中样本权重,保证对每张图片的正样本都有足够的学习能力。并且采用像素级 Online HardExample Mining(OHEM)[2],自动过滤高置信度样本,针对困难且复杂的样本学习,进一步削弱正负样本不均衡问题。
针对正负样本视觉差异小,判别特征微弱问题,采用大尺度输入与大尺度放缩数据增强策略,从微观和宏观层面分别增强特征差异。在微观层面上,对原始图像随机放大 1.0-3.0 倍,增强局部细节信息,使模型更加关注篡改区域中的异常样本(如擦除存在的残留,粘贴边缘的模糊效应等);在宏观层面上,对放大后的图像随机裁剪768×768 与 1024×1024 的图像块,保证理论感受野足够大,使模型捕获大范围上下文信息,从而对比正负样本区域,提升其判别特征提取能力。
针对训练集数据量小,泛化性弱问题,引入三种来源不同的数据集:
- 数据集 Sea3为安全 AI
挑战者计划第五期:伪造图像的篡改检测-长期赛训练集,2005 张;
2. Ext 为自建数据集,通过爬取网图,自行标注,808 张;
3. 伪标签数据集,通过多轮迭代,高置信度 A 榜测试集样本,4000 张。基于上述手段,将训练集扩充为原来 2.7 倍,极大提升了训练样本多样性。
此外,考虑到计算资源受限与任务难易程度,采用渐进式学习方式。首先利用768×768 输入训练模型,然后利用 1024×1024 输入进行模型微调。同样在数据方面,先仅利用 40k 训练集进行模型训练,然后加入扩充样本进行模型微调。伪标签交叉监督CNN 和 Transformer 结构的网络,提升模型效果。
- 数据集 Sea3为安全 AI
挑战者计划第五期:伪造图像的篡改检测-长期赛训练集,2005 张;
采用多种类型模型(CNN+Transformer)相融合的方式,提升不同表征形式对于不同特征的互补性。CNN 部分编码器采用目前 SOTA 的 ConvNeXt[3]模型,解码器采用金字塔结构UPerNet[4];Transformer部分编码器采用目前SOTA的Swin-Transformer[5]模型,解码器采用 UPerNet。同时为了增加解码器差异性,还额外增加了 SegFormer[6]模型。三模型结果融合,获取高置信度伪标签,多轮迭代优化,提升模型的识别性能。
rank 5
rank17
【2022阿里安全】真实场景篡改图像检测挑战赛 决赛rank17方案分享_阿里 篡改监测-CSDN博客
1.1.4其他优秀结果展示
- 【PaddleSeg】【天池大赛】真实场景篡改图像检测挑战赛线上2391-CSDN博客
- 天池比赛-真实场景篡改图像检测挑战赛_天池篡改检测-CSDN博客
- lyx3911/tianchi-image-tamper: 天池-真实场景篡改图像检测挑战赛
1.2 ICDAR 2023 DTT in Images 1: 文本篡改图像检测分割比赛
1.2.1赛道1:分类
ICDAR 2023 DTT in Images 1: Text Manipulation Classification
1.2.2赛道2:分割
ICDAR 2023 DTT in Images 2: Text Manipulation Detection
1.2.3 相关开源代码
- lyx3911/tianchi-ICDAR2023-ImageTamper: 天池&ICDAR2023篡改图像检测比赛方案
- Jayc-Z/tianchi_ICDAR2023: 阿里云天池ICDAR 2023: 篡改文本检测 15名方案介绍
- 阿里天池ICDAR 2023 DTT in Images 1: Text Manipulation Classification(10/1267)_tampered text in images (tti) tianchi competition-CSDN博客
- 自研算法提升文本图像篡改检测精度,抖音技术团队获 ICDAR2023 分类赛道冠军..._算法_ 字节跳动技术团队-2048 AI社区
- 击败全球上千参赛队伍,合合信息获ICDAR“文本篡改检测”赛道冠军-腾讯云开发者社区-腾讯云
1.3 天池的安全AI挑战赛第五期
https://tianchi.aliyun.com/competition/entrance/531812/introduction(已不可访问),相关代码分享如下
1.4 AFAC2023-金融数据验真-赛题1 金融文档防篡改
近年来,人工智能技术在金融领域的运用正在不断加深,为金融行业的风控、营销、投顾、管理等业务注入了数字化的血液,为银行、保险、基金、券商等金融机构实现数智化转型提供引擎动能。在CCF指导下,蚂蚁财富、蚂蚁保和网商银行联合浙江大学、上海交通大学、西安交通大学、中央财经大学、蚂蚁技术研究院和天池平台,共同发布国内首套金融AI挑战赛赛题,涵盖理财服务、保险风控、信贷风控、基金预测等多个业务场景,覆盖通用机器学习、计算机视觉、自然语言处理等多个算法领域,直击金融市场科技破局痛点难点,在此邀请业界和学界各位同好,共同探讨解决方案,发挥行业技术优势,共建一个追求卓越的技术氛围与互动生态。
这个比赛是金融数据验真方向的赛题,金融文档防篡改,其项目链接为https://tianchi.aliyun.com/competition/entrance/532096
比赛所提供的数据按类别可以分为拍摄文档、小票,扫描文档/pdf以及街景照片等,数据量如下所示。我们基于以上数据源构建了篡改数据集,篡改的方法为常见的copy move,splicing,removal等常见的方式以及目前比较流行的基于深度学习的图像生成方式。
未找到相关选手的代码分享
1.5 CV学习赛:文档篡改智能识别
CV学习赛:文档篡改智能识别_学习赛_赛题与数据_天池大赛-阿里云天池的赛题与数据
欢迎加入“金融CV创新赛:文档篡改智能识别”,本赛题由本赛题由“AFAC2023-金融数据验真-赛题1 金融文档防篡改”大赛延伸而来,现开放长期练习赛季,供大家学习。
近年来,人工智能技术在金融领域的运用正在不断加深,为金融行业的风控、营销、投顾、管理等业务注入了数字化的血液,为银行、保险、基金、券商等金融机构实现数智化转型提供引擎动能。在CCF指导下,蚂蚁财富、蚂蚁保和网商银行联合浙江大学、上海交通大学、西安交通大学、中央财经大学、蚂蚁技术研究院和天池平台,共同发布国内首套金融AI挑战赛赛题,涵盖理财服务、保险风控、信贷风控、基金预测等多个业务场景,覆盖通用机器学习、计算机视觉、自然语言处理等多个算法领域,直击金融市场科技破局痛点难点,在此邀请业界和学界各位同好,共同探讨解决方案,发挥行业技术优势,共建一个追求卓越的技术氛围与互动生态。
1.6 全球AI攻防挑战赛—赛道二:AI核身之金融场景凭证篡改检测
全球AI攻防挑战赛—赛道二:AI核身之金融场景凭证篡改检测
在全球人工智能发展和治理广受关注的大趋势下,由中国图象图形学学会、蚂蚁集团、云安全联盟CSA大中华区主办,广泛联合学界、机构共同组织发起全球AI攻防挑战赛。本次比赛包含攻防两大赛道,分别聚焦大模型自身安全和大模型生成内容的防伪检测,涉及信用成长、凭证审核、商家入驻、智能助理等多个业务场景,覆盖机器学习、图像处理与计算机视觉、数据处理等多个算法领域,旨在聚合行业及学界力量共同守护AI及大模型的安全,共同推动AI安全可信技术的发展。
金融领域交互式自证业务中涵盖信用成长、用户开户、商家入驻、职业认证、商户解限等多种应用场景,通常都需要用户提交一定的材料(即凭证)用于证明资产收入信息、身份信息、所有权信息、交易信息、资质信息等,而凭证的真实性一直是困扰金融场景自动化审核的一大难题。随着数字媒体编辑技术的发展,越来越多的AI手段和工具能够轻易对凭证材料进行篡改,大量的黑产团伙也逐渐掌握PS、AIGC等工具制作逼真的凭证样本,并对金融审核带来巨大挑战。
为此,开设AI核身-金融凭证篡改检测赛道。将会发布大规模的凭证篡改数据集,参赛队伍在给定的大规模篡改数据集上进行模型研发,同时给出对应的测试集用于评估算法模型的有效性。
训练集有100w左右的数据,测试集A、B有10w。
首先根据对训练集和测试集的观察,该团队发现训练集和测试集数据分布有很大差别,其中困难场景大多为店面图片,如何优化店面的篡改对提升性能有较大帮助。其直接的总结难点和初步解决方法如下:
- 提升模型对店面图片窜改的敏感性(可使用AIGC生成更多店面窜改图)
2. 数据集分布不一致(用离线伪标签策略逐渐使模型向测试集偏移)
3. 窜改类型丰富(设计一套窜改pipeline进一步提升模型泛化性)
4. 数据集规模较大,算力要求高(采用640尺度训练,或者选取一个类似分布的小训练集,不从头训练而是微调)
5. 采用Micro-F1 指标需要调整阈值
该团队将热被窝定义为传统的水平目标检测任务,模型采用Co-DINO-Swin-L,使用Object365预训练模型在640x640的尺度进行训练,轮次大约为3轮。
篡改预准备
用PaddleOCRv4多卡推理得到每张图片都文字行标注,融合原来的篡改类别与正常文字行类别作为新的训练标注文件(在数据输入到模型之前,算法会自动丢弃Text类别,防止造成不利影响)。这样一来我们后续可以同时利用两种标注进行自定义的窜改,极大地丰富了窜改形式。
篡改构造(模仿攻击方)
我们自定义了四个数据增强方法,并构建了一个全自动的,即插即用的篡改pipeline,用于增加模型的鲁棒性。
1.InnerCopyPaste
图片内文字替换
图片中包括原本存在的篡改bbox和text区域,将这框做大小匹配,将大小相似的内容进行互换,同时将类别替换为篡改,这将丰富原图中的篡改类型,尤其是针对于发票和税,截图有很好的效果。
2.InnerFlipPaste
原地镜像
选择随机的框进行上下或者左右翻转
3.InpantingRemoval
基于OpenCV的移除
选取随机文字内容进行抹除
4.CopyPaste_Possion
基于泊松融合的copypaste增强 +
Cache+随机旋转,缩放
之前的三个方法为同图间窜改,我们还做了跨图窜改,具体来说设计了一个基于缓存队列和柏松融合的CopyPaste方法,我们首先设置一个缓存队列,大小设置为300,每次遍历到图片中的所有篡改目标或者OCR识别的目标将会存储在其中,队列维护一个最大长度,使得其中的目标具有全局随机性。在数据增强环节,算法会随机选择CopyPaste的目标数量,并加上随机缩放(0.9-1.1),随机旋转翻转操作后,粘贴到该张图片的任意位置,本方法设置了copy,mixup_copy,
possion_copy三种粘贴策略,出于效果考虑,最终选取泊松融合作为粘贴手段,该方法能较好的处理复制图片的边缘信息,使得融合更为自然。
店面图片的篡改构造
策略一:Stable
Diffusion
由于SD的字符生成能力较弱,中文能力更差,我们采用简单的prompt保证AIGC的效果
prompt = ["background", "change the text font", "change the text's color"] |
策略二:AnyText
AnyText模型具有更好的中文字体生成能力,比较适合店面图片的场景,我们生成随机常用中文来改变店面图片的文字。
其他策略
- 模型集成和测试数据增强
策略:水平翻转,采用(640,768)多尺度TTA(Test Time
Augmentation)进行soft
nms集成。
不同训练数据的模型采用WBF(Weighted Boxes
Fusion)进行集成。
- 缩放边框,容纳更多计算。
官方标注采用Polygons格式, 标注非水平框导致IOU降低,最终影响Micro-F1精度。为了使旋转目标更适应于水平检测任务,我们缩放来边框从而提高TP(True Positive)。
- 半监督学习
尝试MixPL半监督训练,因训练集数据淹没测试集分布且无法偏移,最终未采用。我们使用离线半监督策略,教师模型生成伪标签,学生模型微调学习,性能大幅提升。
实际可视化效果发现数据标注质量不佳,不排除纯模型伪标签给到选手的可能,难以进行人工清洗。比赛中途尝试过去除部分超过白边的框,模型掉点,榜上有轻微的提点。
数据去重
在初赛阶段,我们发现划分的验证集精度明显高于线上A榜测试集精度(验证集95+,线上70+),怀疑是线上线下数据分布差异大,并且验证集中可能出现和训练集高度相似的样本,通过简单的真值可视化筛查,发现训练集中确实存在大量的相似样本,可能是官方对训练集做了一定的离线增强处理。
所以使用ResNet50快速的构建图片的特征库,然后基于构建的特征库,计算了测试集中所有样本和训练集所有样本的相似度,筛选出相似度top2的样本,并通过可视化发现有一定数量的测试集在训练集中也存在高度相似的样本,对此我们也基于找出的共3.5w数据,训练了一个专家模型,用于后续的模型融合。
数据拆分
考虑到数据集样本数量较多(100w,相当于COCO的数倍),一方面对过于宽泛的数据分布,模型的学习难度较大,可能会发生欠拟合;另一方面,使用多个模型学习不同的数据分布,再通过wbf等方式进行模型融合,可以提高最终的检测精度;此外,百万量级数据全量训练,即使在训练资源充足的前提下,每个样本也仅能被训练到几次,难以对在线数据增强方案进行优化。
因此,采用类似五折交叉验证的方式,将数据分成5份,训练了5个模型并分别提交测试性能。
数据伪标签
在初赛A榜期间,尝试用当时最好的模型,对全量数据打了伪标签,补充了阈值0.8以上的框的标注,伪标签的增加同样是线下掉点,线上轻微提升,但是B榜掉点,这也体现了数据分布的随机性。
模型选型
从官方给定的baseline出发,考虑现在比较新的transformer模型,前期全量数据实验选定后续都是用CO-DETR-ViT模型,时间不够的情况下,后期新加入一些CO-DETR-SWIN-L的模型,所有的模型TTA后使用WBF进行融合。
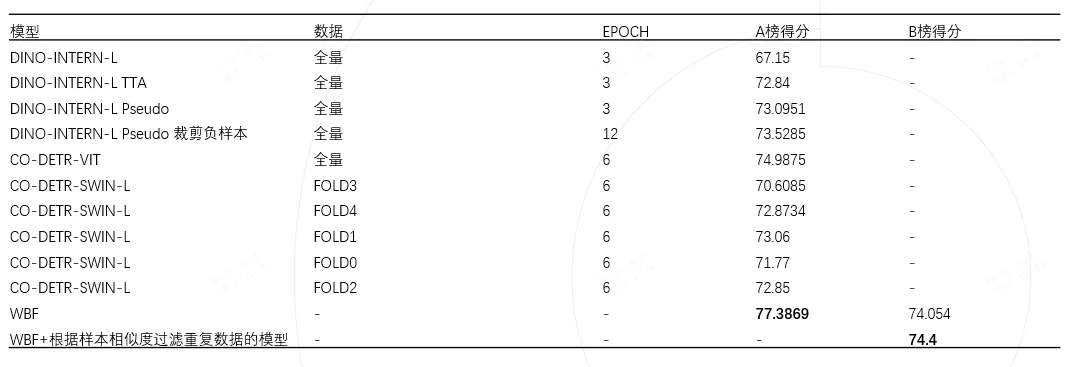
模型指标
从比赛开始到结束我们的模型指标迭代见下表。