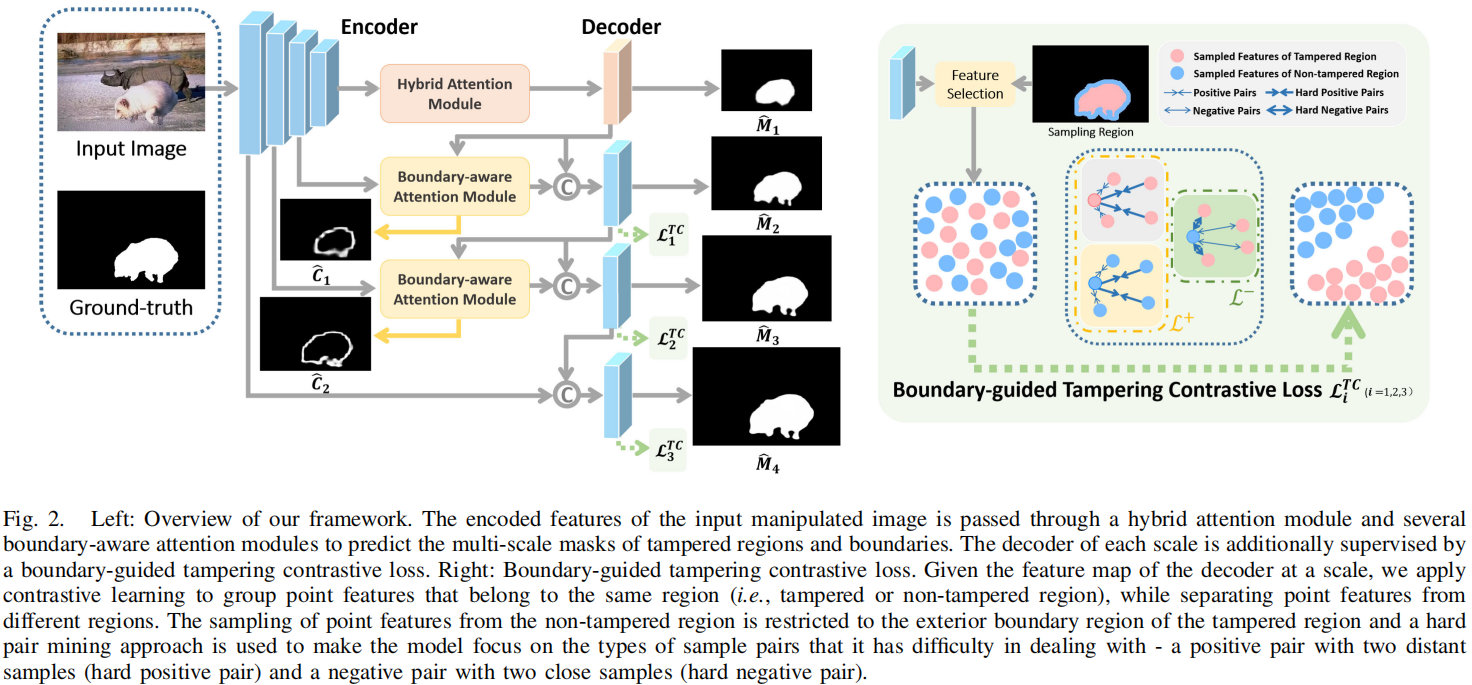
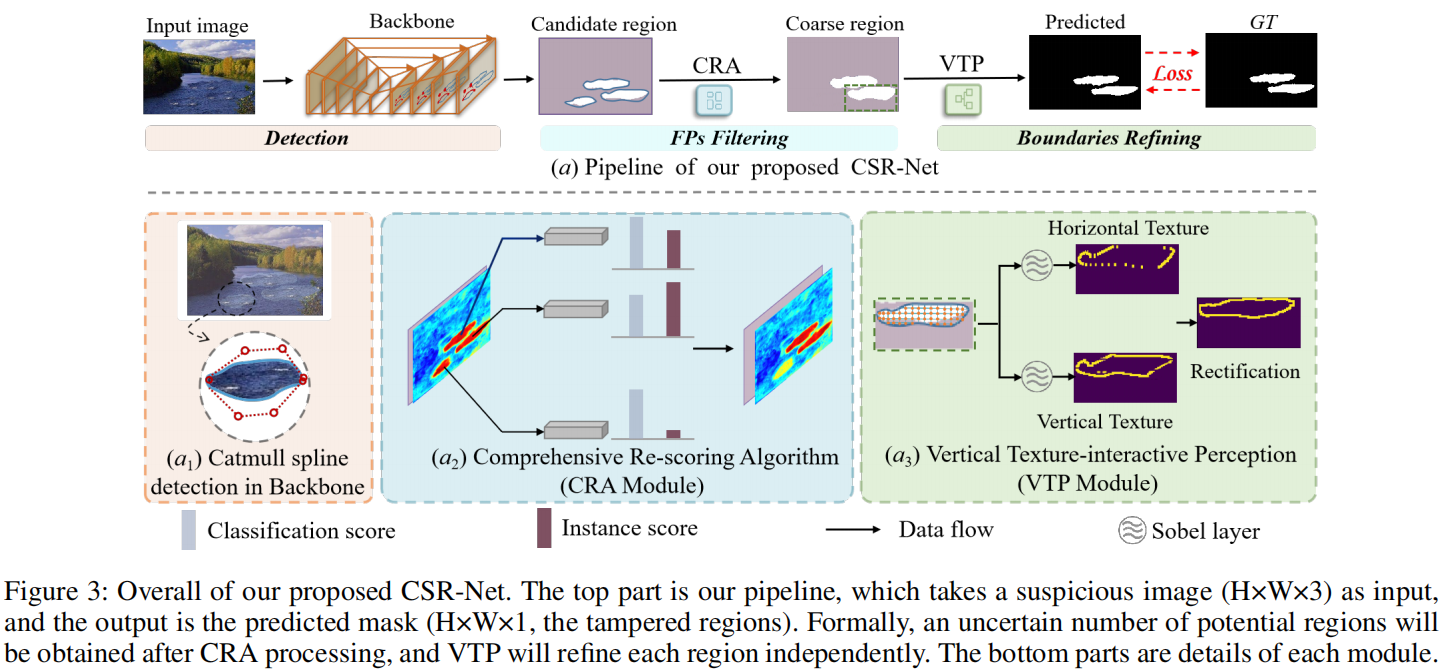
CatmullRom Splines-Based Regression for Image Forgery Localization
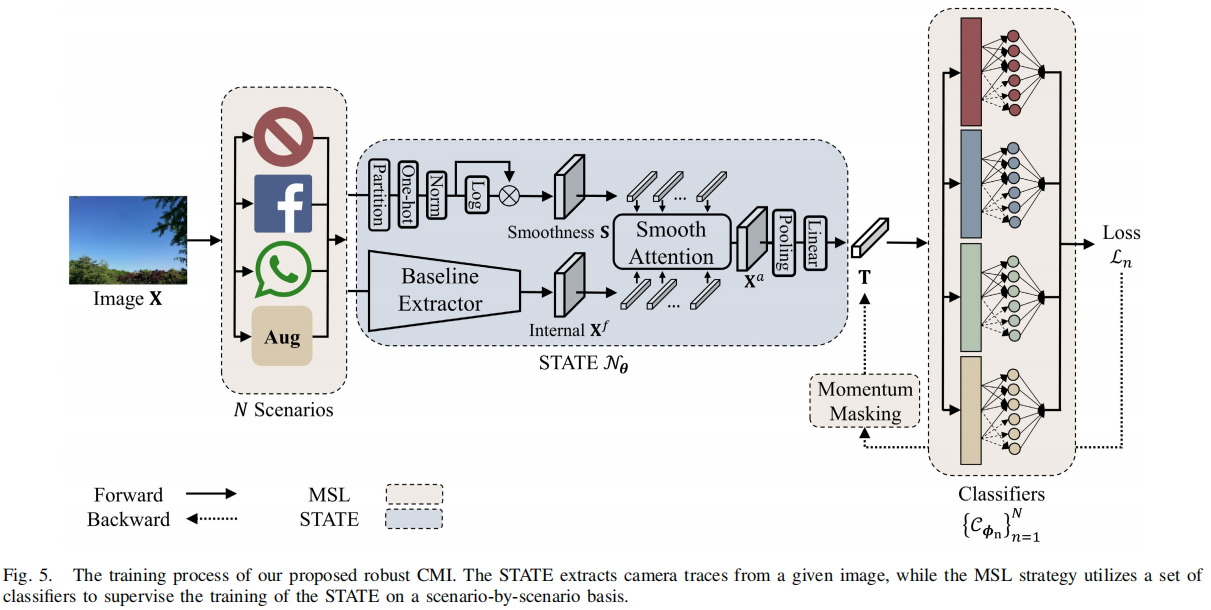
发表于AAAI2024,提出基于CatmullRom样条的回归网络,为了明确抑制假阳性样本和避免不确定性边界,综合再评分算法(CRA,Comprehensive Re-scoring Algorithm),综合评估每个区域的信任分数作为篡改区域,而垂直纹理交互感知(VTP, Vertical Texture-interactive Perception)控制生成更准确的区域边缘。
A New Benchmark and Model for Challenging Image Manipulation Detection
发表于AAAI2024,包含RGB和频率特征的hrnet双分支架构,能够检测双压缩伪影的压缩伪影学习模型。
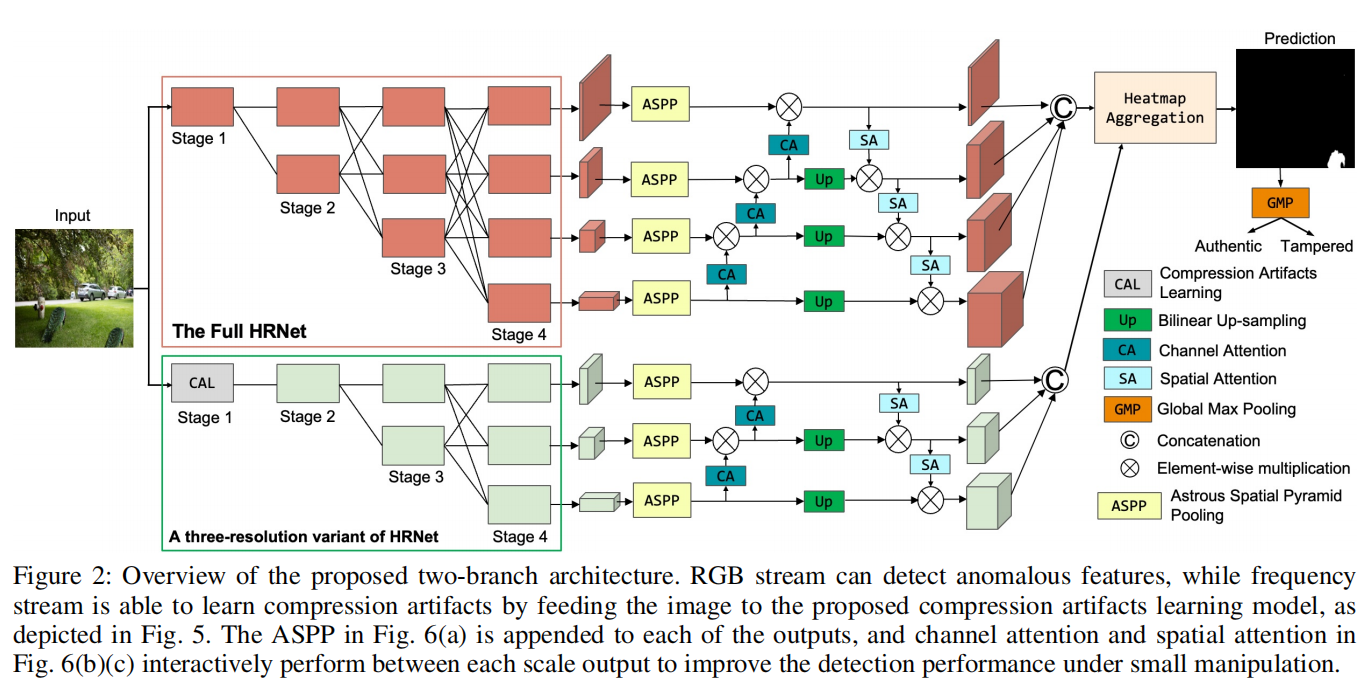
MGQFormer: Mask-Guided Query-Based Transformer for Image Manipulation Localization
发表于AAAI2024,为应对交叉熵损失优先考虑逐像素精度,但忽略了篡改区域的空间位置和形状细节,设计了基于掩码引导查询的转换器框架(MGQFormer),该框架使用GroundTruth掩码来引导可学习查询令牌(LQT)识别伪造区域。
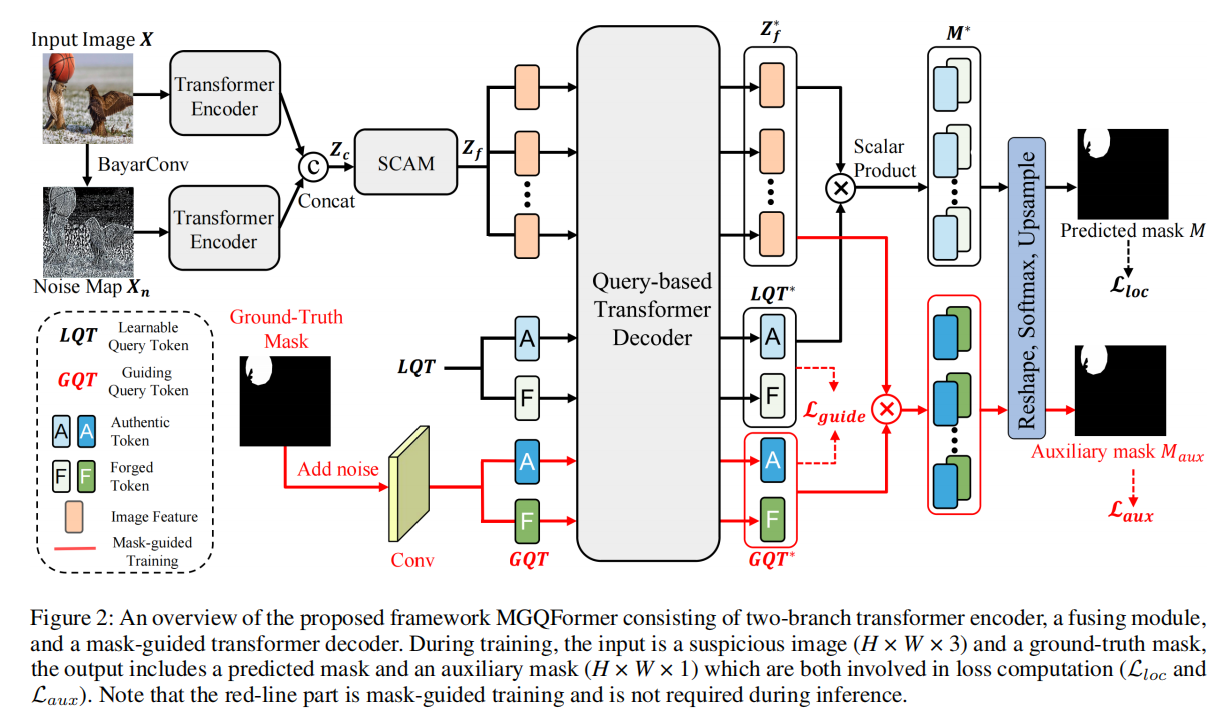
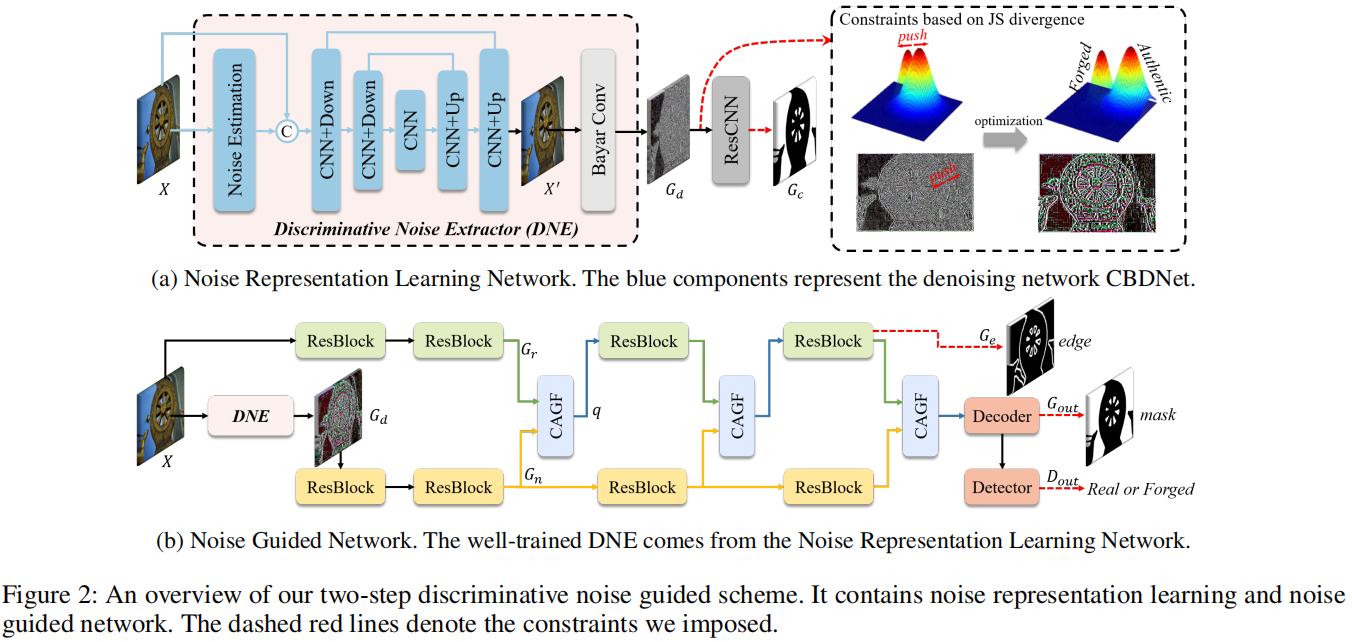
Learning Discriminative Noise Guidance for Image Forgery Detection and Localization
发表于AAAI2024,一种两阶段判别噪声引导的方法,第一阶段训练一个噪声提取器,以明确地扩大真实区域和伪造区域之间的噪声分布差异,第二阶段将噪声不一致和RGB数据集成,以进行伪造检测和定位。
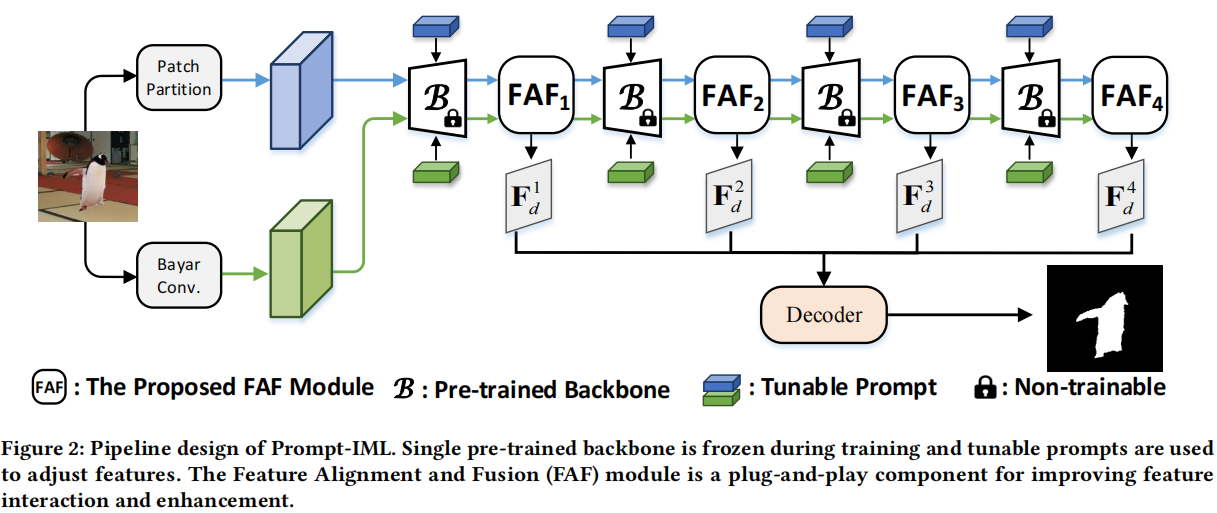
Multi-view Feature Extraction via Tunable Prompts is Enough for Image Manipulation Localization
发表于ACMMM2024,针对IML任务中公共训练数据集的稀缺,通过采用可调提示来利用预训练模型的丰富先验知识,即Prompt-IML框架,即插即用的特征对齐和融合模块。

A_Survey_on_Deep_Clustering:_From_the_Prior_Perspective
一个关于深度聚类的总结:从先验的角度来看
四川大学计算机科学学院,成都,中国四川
摘要
由于神经网络具有强大的特征提取能力,深度聚类在分析高维和复杂的真实世界数据方面取得了巨大的成功。深度聚类方法的性能受到网络结构和学习目标等各种因素的影响。然而,正如本调查中所指出的,深度聚类的本质是对先验知识的整合和利用,这在很大程度上被现有的工作忽略了。从开创性基于数据结构假设的深度聚类方法到最近基于数据增强不变性的对比聚类方法,深度聚类的发展本质上对应于先验知识的演化。在本调查中,我们通过将深度聚类方法分为六种先验知识类型,提供了一个全面的回顾。我们发现,总的来说,先前的创新遵循两个趋势,即,i)从采矿到建设,以及ii)从内部到外部。此外,我们在五个广泛使用的数据集上提供了一个基准,并分析了具有不同先验的方法的性能。通过提供一个新的先验知识视角,我们希望这次调查能够提供一些新的见解,并启发未来在深度聚类社区的研究。

DeepClustering
深度聚类
A Survey on Deep
Clustering: From the Prior Perspective
Image Clustering with
External Guidance
Scaling Up Deep
Clustering Methods Beyond ImageNet-1K
Unsupervised Learning of
Visual Features by Contrasting Cluster Assignments
DeepClusteringSurvey
Deep Clustering: A Comprehensive Survey
Yazhou Ren, Member, IEEE, Jingyu Pu, Zhimeng Yang, Jie Xu,
Guofeng Li, Xiaorong Pu, Philip S. Yu, Fellow, IEEE, Lifang He,
Member, IEEE
摘要
聚类分析在机器学习和数据挖掘中起着不可或缺的作用。学习一个好的数据表示对聚类算法至关重要。近年来,深度聚类可以利用深度神经网络学习聚类友好表示,已广泛应用于聚类任务。现有的深度聚类调查主要集中在单视图领域和网络架构上,忽略了聚类的复杂应用场景。为了解决这个问题,在本文中,我们提供了一个全面的调查,以深度聚类的视图的数据源。在不同的数据源和初始条件下,我们从方法学、先验知识和体系结构等方面系统地区分了聚类方法。具体地说,根据传统的单视角深度聚类、半监督深度聚类、深度多视图聚类和深度转移聚类四种深度聚类方法。最后,我们讨论了深度聚类在不同领域中所面临的开放挑战和潜在的未来机遇。
引言
深度单视图聚类
通过深度神 ...
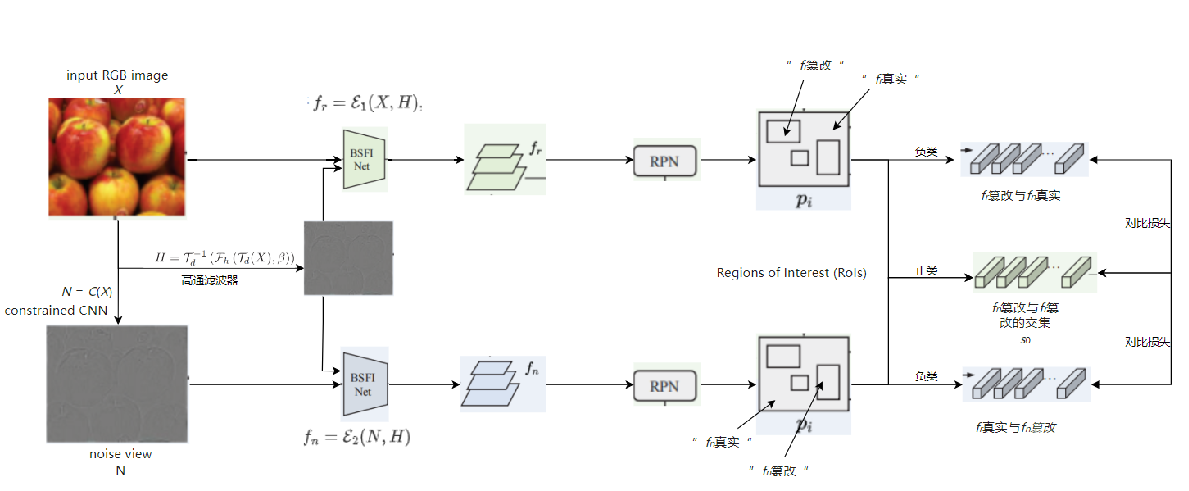
UnionFormer Unified-Learning Transformer with Multi-View Representation for Image Manipulation Detection and Localization
发表于CVPR2024,集成三个视图的UnionFormer框架,一个调节不同尺度上空间一致性的篡改特征提取网络BSFI-Net。

SAM1
Segment Anything Model for Medical Images?
发表于MICCAI 2024
Testing pipeline of SAM
image-20240528220811746
train with box接下来是的代码来自https://github.com/yuhoo0302/Segment-Anything-Model-for-Medical-Images任务是医学图片的分割------------------------------------------------------------------------------------------------------------优化器和损失函数设计:------------------------------------------------------------------------------------------------------------# Set up the optimizer, hyperparameter tuning will imp ...

SAM
Segment Anything
论文(arxiv)
摘要
我们介绍了分段任意事物(SA, Segment
Anything)项目:一个新的图像分割任务、模型和数据集。在数据收集循环中使用我们的高效模型,我们建立了迄今为止(迄今为止)最大的分割数据集,在11M许可和尊重隐私的图像上有超过10亿个面具。该模型的设计和训练是及时的,因此它可以转移零镜头到新的图像分布和任务。我们评估了它在许多任务上的能力,发现它的零样本性能令人印象深刻——通常与之前的完全监督结果竞争,甚至更好。
Segment Anything Model
接下来,我们将描述用于快速分割的分段任何东西模型(SAM, Segment
Anything Model)。
image-20240519201116761
图4:分段任何东西模型(SAM)概述。重量级图像编码器输出图像嵌入,然后可以通过各种输入提示有效地查询,以平摊的实时速度产生对象掩模。对于对应于多个对象的模糊提示,SAM可以输出多个有效的掩码和相关的置信度分数。
...
CMX:_Cross-Modal_Fusion_for_RGB-X_Semantic_Segmentation_With_Transformers
CMX: Cross-Modal Fusion for RGB-X Semantic Segmentation With
Transformers(TruFor使用了这个方法)
image-20240516170446816
1、原任务是分割任务,论文提出了一种将RGB图与其他图特征充分融合的方法RGB-X,可以从RGB图与X图提取特征。
2、RGB-X主要由两个部分组成:CM-FRM、FFM。
CM-FRM用于提取图片特征,其可以纠正关于另一个特性的一个特性,反之亦然,将属于同一层次的特征融合成一个单一的特征图。
FFM参考自注意力机制,设计了一种将特征融合的方法最后通过融合特征,完成分割任务。
TruFor使用了cmx来提取融合特征
image-20240516170520387
image-20240516170527564
image-20240516170535748
两阶段的特征融合模块(FFM)来增强信息的交互和组合。
在信息交换阶段(阶段1),两个分支仍然保持不变,并设计了一种交叉注意机制,在两个分 ...

Uncertainty-Uncertainty_Learning_for_Improving_Image_Manipulation_Detection
Uncertainty-guided Learning for Improving Image Manipulation
Detection
摘要
图像操纵检测(IMD)至关重要,因为伪造图像和传播错误信息可能是恶意的,会危害我们的日常生活。IMD是解决这些问题的核心技术,并在两个主要方面提出了挑战:(1)数据不确定性,即被操纵的工件通常很难被人类辨别,并导致噪声标签,这可能会干扰模型训练;(2)
模型不确定性,即由于操纵操作,同一对象可能包含不同的类别(篡改或未篡改),这可能会混淆模型训练并导致不可靠的结果。以往的工作主要集中在通过设计细致的特征和网络来解决模型的不确定性问题,但很少考虑数据的不确定性。在本文中,我们通过引入一个不确定性引导的学习框架来解决这两个问题,该框架通过一个新的不确定性估计网络(UEN)来测量数据和模型的不确定性。UEN在动态监督下进行训练,并输出估计的不确定性图来细化操纵检测结果,这显著缓解了学习困难。据我们所知,这是第一项将不确定性建模嵌入IMD的工作。在各种数据集上进行的大量实验证明了最先进的性能,验证了我们方法的有效性和可推广性。
将不 ...
Pre-training-free_Image_Manipulation_Localization_through_Non-Mutually_Exclusive_Contrastive_Learning
Pre-training-free Image Manipulation Localization through
Non-Mutually Exclusive Contrastive Learning
四川大学计算机科学学院
厦门科技大学计算机与信息工程学院
摘要
深度图像操作定位(IML)模型存在训练数据不足,严重依赖于预训练。我们认为对比学习更适合于解决IML的数据不足问题。形成相互排斥的正性与负性是对比学习的先决条件。然而,当在IML中采用对比学习时,我们遇到了三类图像补丁:篡改、真实和轮廓补丁。篡改和真实的补丁自然是相互排斥的,但是包含篡改和真实像素的轮廓补丁对它们不是相互排斥的。
简单地取消这些轮廓补丁会导致巨大的性能损失,因为轮廓补丁对学习结果是决定性的。因此,我们提出了非互斥对比学习(NCL)框架来从上述困境中拯救传统的对比学习。在NCL中,为了应对非互斥性,我们首先建立一个具有双分支的枢轴结构,在训练时不断地在正和负之间切换轮廓补丁的作用。然后,我们设计了一个枢轴一致的损失,以避免由角色转换过程造成的空间损坏。
通过这种方式,NCL既继承了自监督的优点来 ...
ANOMALYCLIP
ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARNING FOR ZERO-SHOT ANOMALY
DETECTION
Qihang Zhou1∗ , Guansong
Pang2∗ , Yu Tian3 , Shibo
He1† , Jiming Chen1†
1浙江大学2新加坡管理大学3哈佛大学
论文(arxiv)
# 摘要
零样本异常检测(ZSAD, Zero-shot anomaly detection
)需要使用辅助数据进行训练的检测模型,以便在目标数据集中没有任何训练样本的情况下检测异常。这是一个至关重要的任务时,当训练数据无法访问由于各种问题,例如,数据隐私,但它是具有挑战性的,因为模型需要推广异常在不同领域前景对象的外观,异常区域和背景特性,如缺陷/肿瘤在不同的产品/器官,可以显著不同。最近,大型的预先训练的视觉语言模型(VLMs),如CLIP,在包括异常检测在内的各种视觉任务中显示出了很强的零样本识别能力。然而,它们的ZSAD性能较弱,因为vlm更关注于前 ...