A New Benchmark and Model for Challenging Image Manipulation Detection
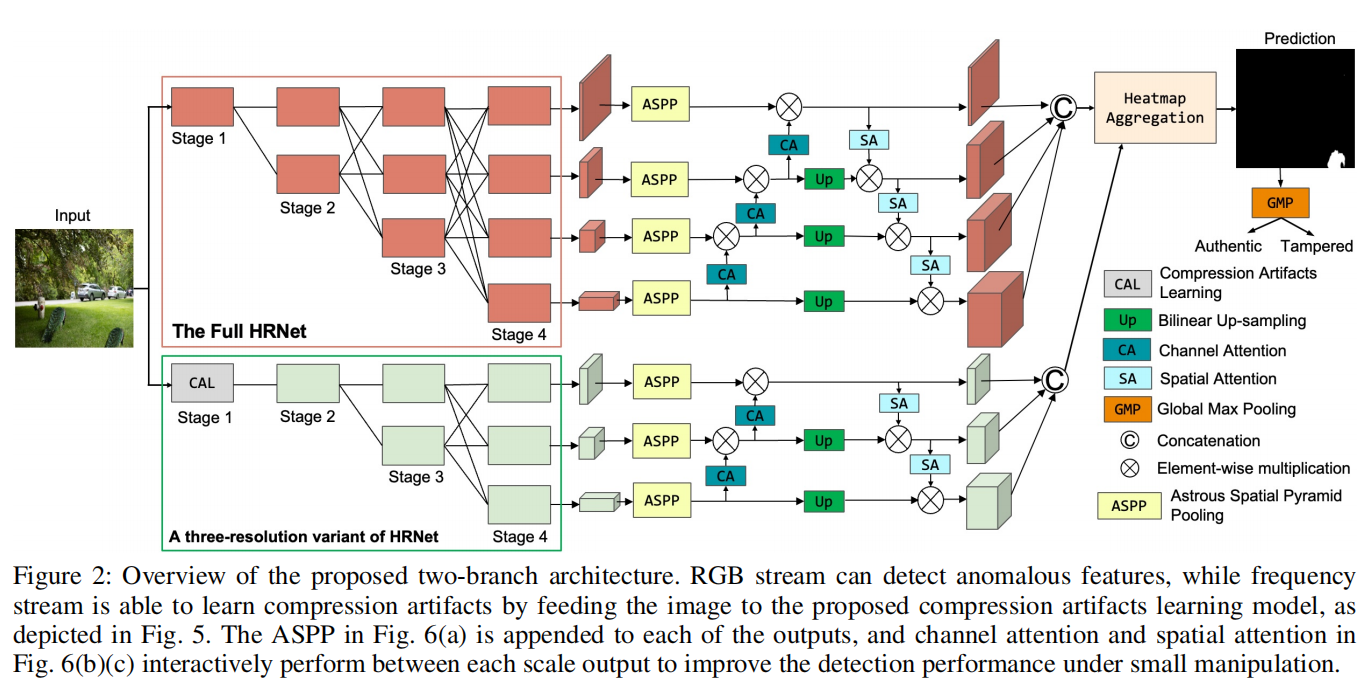
发表于AAAI2024,包含RGB和频率特征的hrnet双分支架构,能够检测双压缩伪影的压缩伪影学习模型。
CatmullRom Splines-Based Regression for Image Forgery Localization
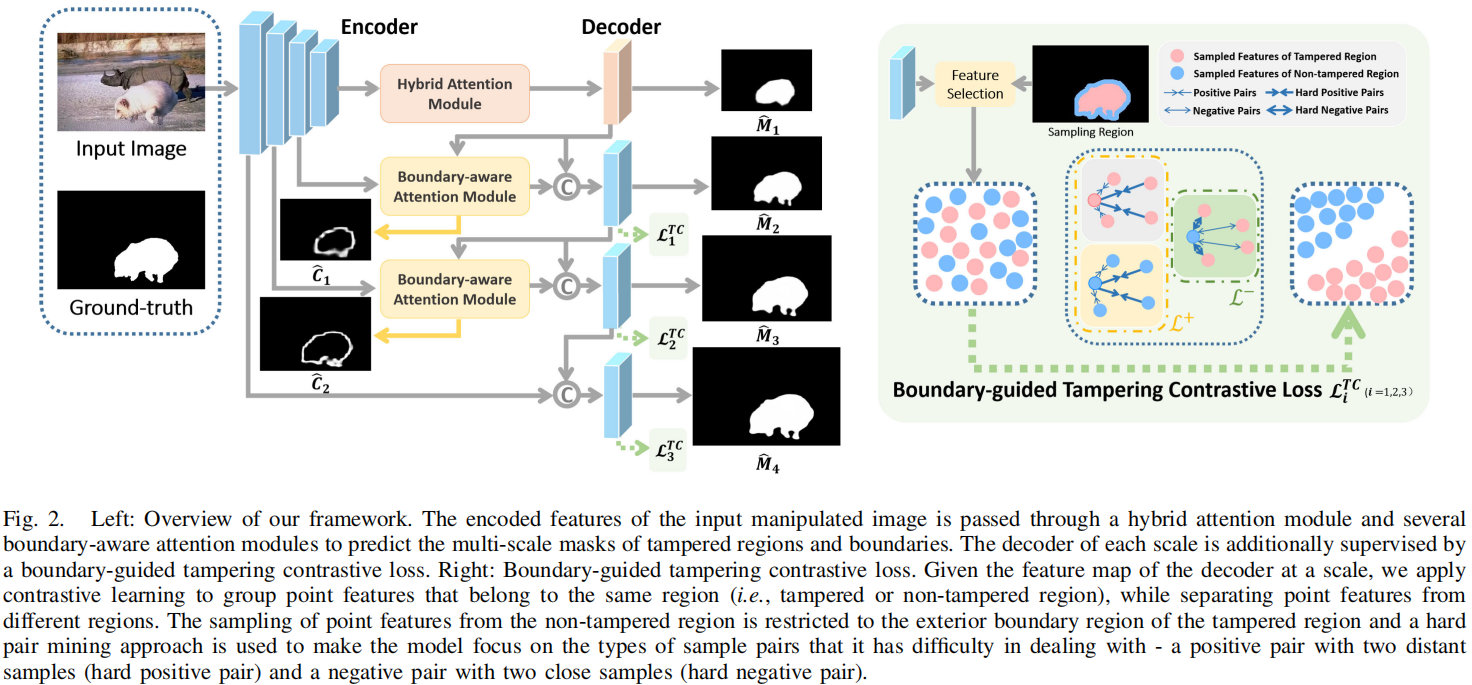
发表于AAAI2024,提出基于CatmullRom样条的回归网络,为了明确抑制假阳性样本和避免不确定性边界,综合再评分算法(CRA,Comprehensive Re-scoring Algorithm),综合评估每个区域的信任分数作为篡改区域,而垂直纹理交互感知(VTP, Vertical Texture-interactive Perception)控制生成更准确的区域边缘。
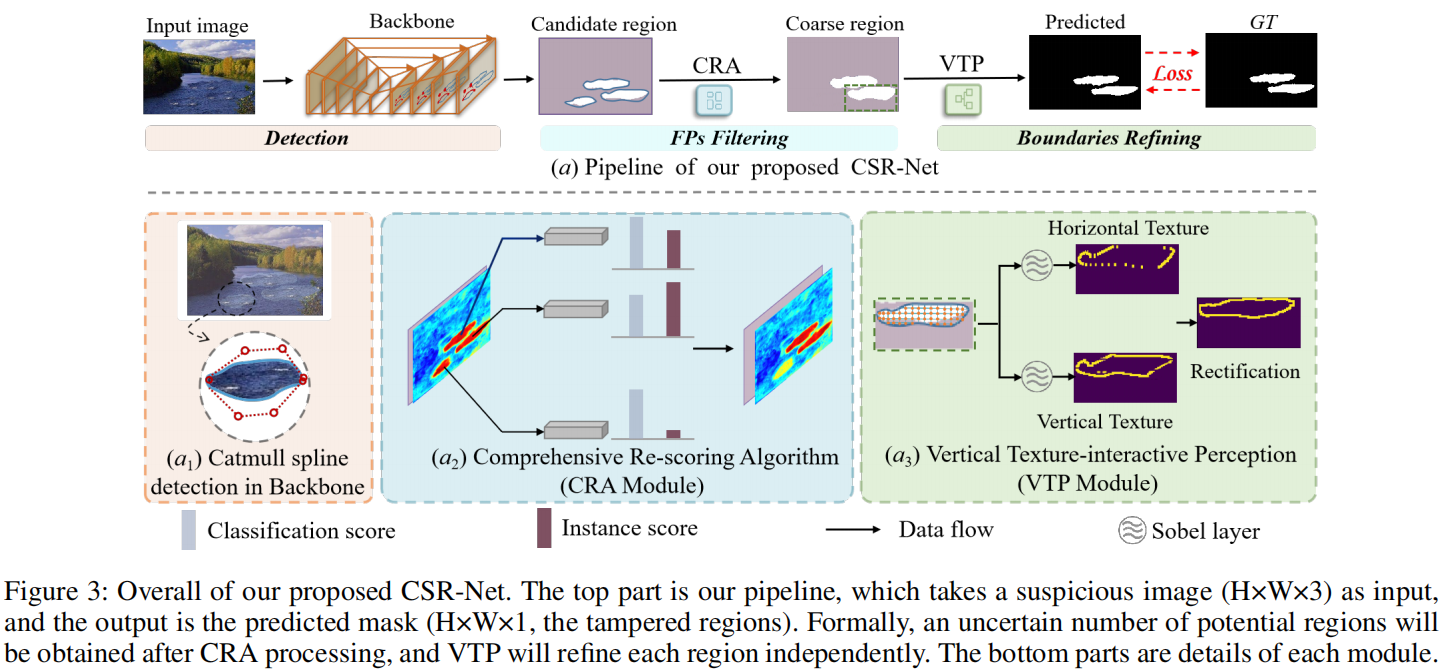
Learning Discriminative Noise Guidance for Image Forgery Detection and Localization
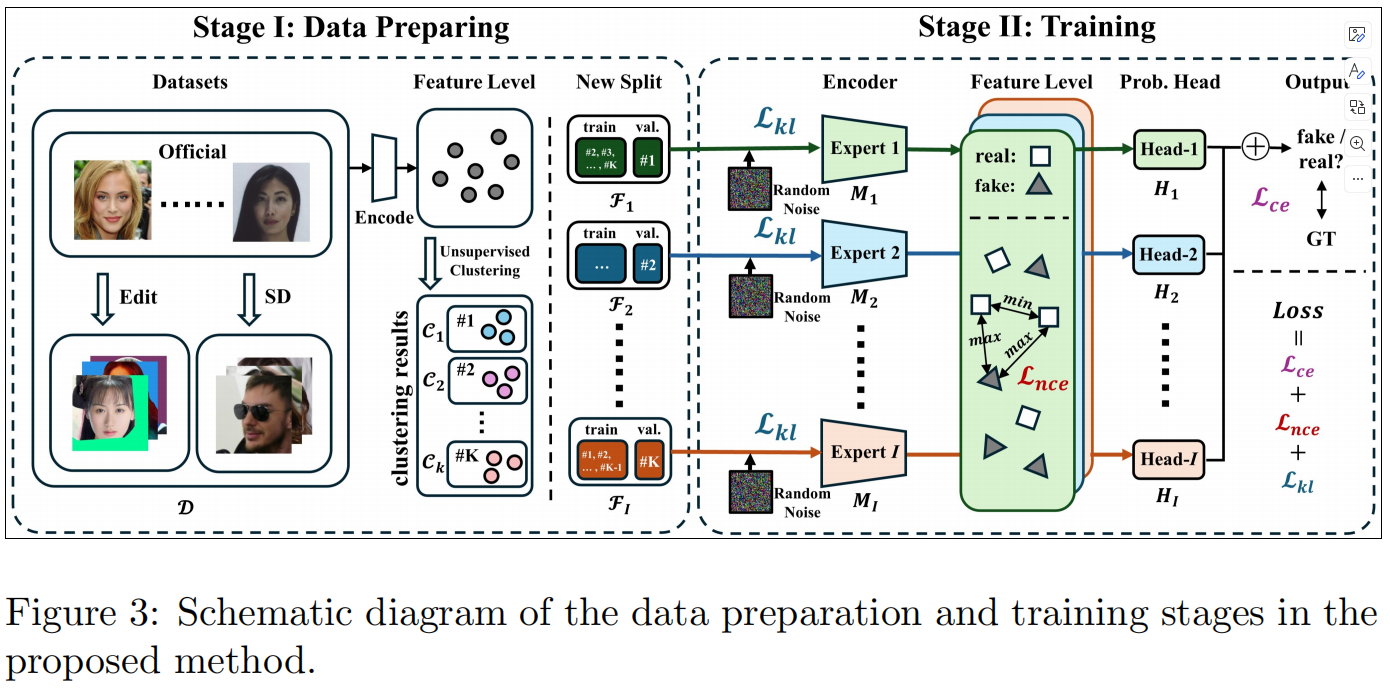
发表于AAAI2024,一种两阶段判别噪声引导的方法,第一阶段训练一个噪声提取器,以明确地扩大真实区域和伪造区域之间的噪声分布差异,第二阶段将噪声不一致和RGB数据集成,以进行伪造检测和定位。
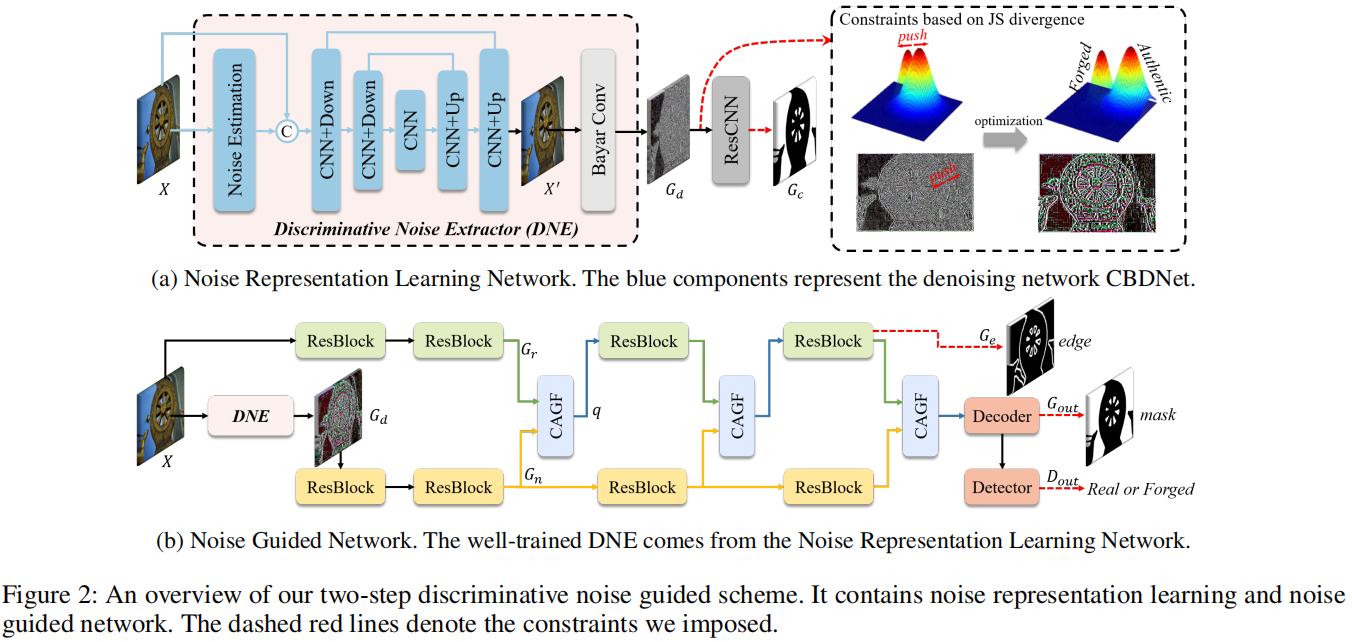
MGQFormer: Mask-Guided Query-Based Transformer for Image Manipulation Localization
发表于AAAI2024,为应对交叉熵损失优先考虑逐像素精度,但忽略了篡改区域的空间位置和形状细节,设计了基于掩码引导查询的转换器框架(MGQFormer),该框架使用GroundTruth掩码来引导可学习查询令牌(LQT)识别伪造区域。
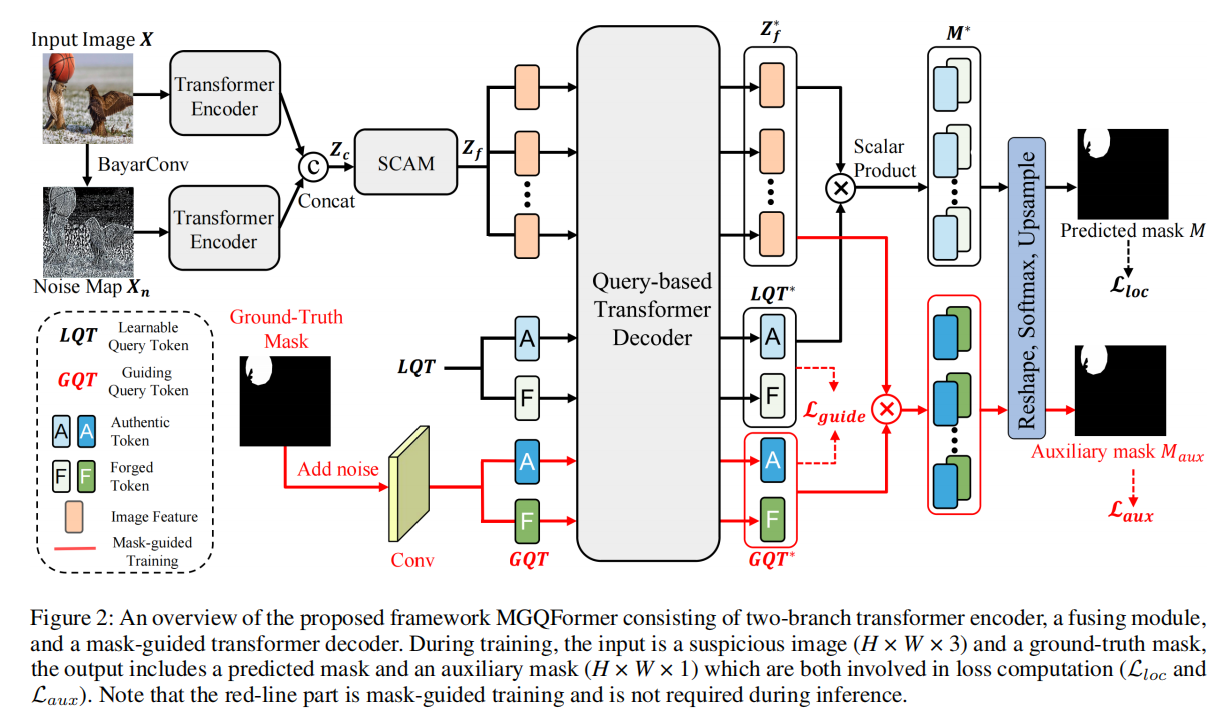
Multi-view Feature Extraction via Tunable Prompts is Enough for Image Manipulation Localization
发表于ACMMM2024,针对IML任务中公共训练数据集的稀缺,通过采用可调提示来利用预训练模型的丰富先验知识,即Prompt-IML框架,即插即用的特征对齐和融合模块。
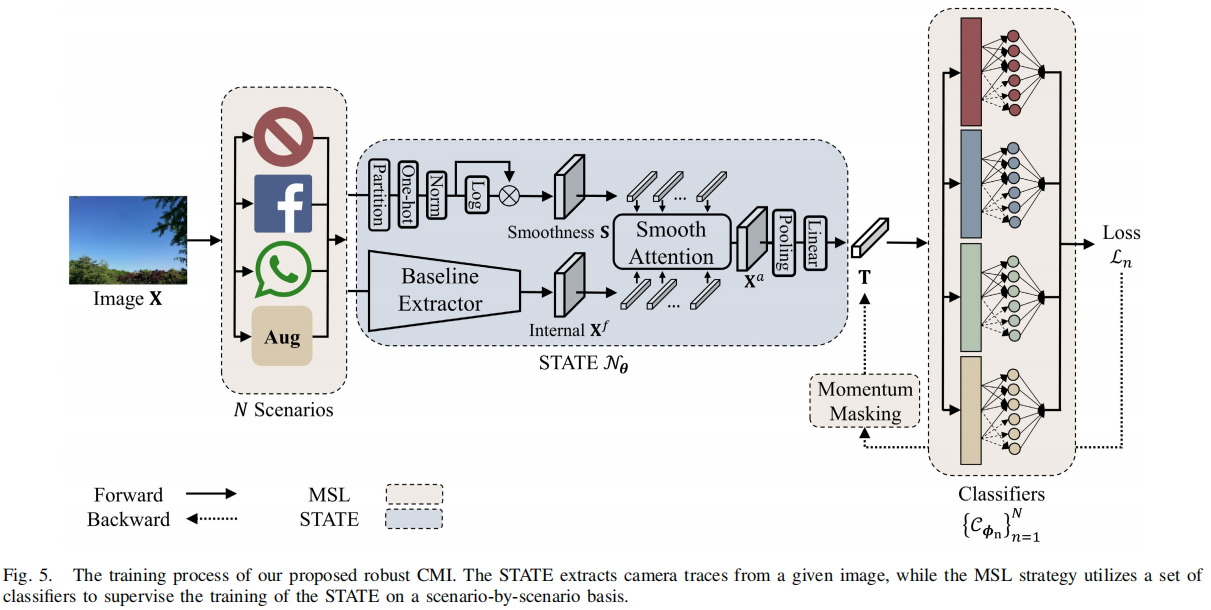
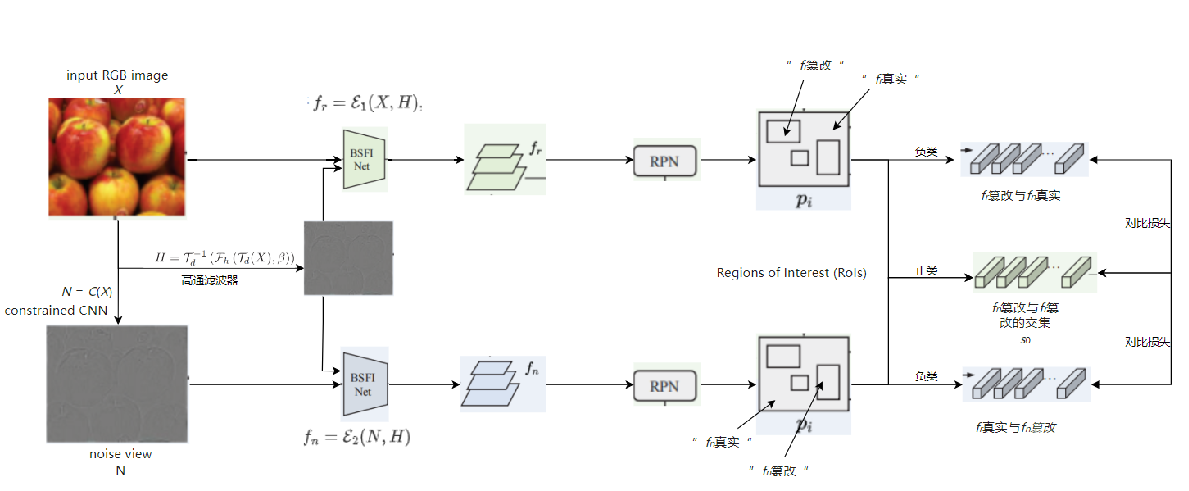

MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image Manipulation Detection
MVSS-Net: Multi-View Multi-Scale Supervised Networks for Image
Manipulation Detection
摘要:
由于通过复制移动、拼接和/或绘制来操纵图像可能导致对视觉内容的误解,因此检测这些类型的操作对于媒体取证至关重要。考虑到对内容的各种可能的攻击,设计一种通用的方法是非常重要的。当前基于深度学习的方法在训练数据和测试数据一致时很有前景,但在独立测试时表现不佳。此外,由于缺乏真实的测试图像,其图像级检测特异性值得怀疑。关键问题是如何设计和训练一个深度神经网络,使其能够学习对新数据操作敏感的可泛化特征,同时防止真实数据的误报。我们提出了多视图特征学习来共同利用篡改边界伪影和输入图像的噪声视图。由于这两个线索都是语义不可知论的,因此学习到的特征是可概括的。为了有效地从真实图像中学习,我们使用多尺度(像素/边缘/图像)监督进行训练。我们将新网络命名为MVSS-Net及其增强版本MVSS-Net++。在数据集内和跨数据集场景下进行的实验表明,MVSS-Net++表现最佳,并且对JPEG压缩、高斯模糊和基于截 ...
Learning Discriminative Noise Guidance for Image Forgery Detection and Localization
发表于AAAI2024,一种两阶段判别噪声引导的方法,第一阶段训练一个噪声提取器,以明确地扩大真实区域和伪造区域之间的噪声分布差异,第二阶段将噪声不一致和RGB数据集成,以进行伪造检测和定位。
MGQFormer: Mask-Guided Query-Based Transformer for Image Manipulation Localization
发表于AAAI2024,为应对交叉熵损失优先考虑逐像素精度,但忽略了篡改区域的空间位置和形状细节,设计了基于掩码引导查询的转换器框架(MGQFormer),该框架使用GroundTruth掩码来引导可学习查询令牌(LQT)识别伪造区域。

Exploring Multi-Modal Fusion for Image Manipulation Detection and Localization2
Exploring Multi-Modal Fusion for Image Manipulation Detection and
Localization
论文(arxiv)
post1post2
数据集
下载 train 数据集:
Casiav2
tampCOCO
IMD2020
FantasticReality
下载 test 数据:
Casiav1
corel
CocoGlide
Columbia
COVER
DSO-1
创建Casiav1+数据集需要corel数据集。
测试集的数据列表分为操纵图像和真实图像,并存在于名为的文件中:
./data/IDT-<DATASET_NAME>-manip.txt./data/IDT-<DATASET_NAME>-auth.txt
这是为了在评估本地化时易于使用,因为您只使用操纵的图像(真实图像的本地化F1始终为0!)。
为了便于使用和再现,训练的数据列表分为训练文件和val文件。我们使用Kwon等人在CA ...
Learning Transferable Visual Models From Natural Language Supervision2
在 CUDA GPU 上, 运行如下指令:
$ conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0$ pip install ftfy regex tqdm$ pip install git+https://github.com/openai/CLIP.git
Zero-Shot Prediction:
import osimport clipimport torchfrom torchvision.datasets import CIFAR100# Load the modeldevice = "cuda" if torch.cuda.is_available() else "cpu"model, preprocess = clip.load('ViT-B/32', device)# Download the datasetcifar100 = CIFAR100(root=os.path.expanduser("~ ...

Learning Transferable Visual Models From Natural Language Supervision
Learning Transferable Visual Models From Natural Language
Supervision
官方解读博客:
CLIP: Connecting text and
images (openai.com)
1 CLIP 论文解读:
1.1 背景和动机
[借助文本的监督方法属于有监督和无监督的一个中间地带]
借助文本的监督方法属于:”借助有限的标注数据进行有监督训练” 和
“借助几乎无限量的原始文本进行无监督训练”
二者之间的中间地带。相同的是,这两种方式都使用静态的 Softmax
分类器来执行预测,缺乏动态输出的机制。这严重限制了它们的灵活性和
“Zero-Shot” 能力。
[CLIP 方法及其结果]
在本文中作者研究了借助大规模自然语言监督训练图像分类器。互联网上存在大量公开可用的无标注文本数据集,作者创建了一个包含4亿对
(图像,文本) 的新数据集,并通过对比语言-图像预训练的方式训练了 CLIP
模型,是一种从自然语言监督中学习视觉模型的有效新方法。作者发现 CLIP
类似于 GPT
家族,在预 ...
A New Benchmark and Model for Challenging Image Manipulation Detection
发表于AAAI2024,包含RGB和频率特征的hrnet双分支架构,能够检测双压缩伪影的压缩伪影学习模型。
Exploring Multi-Modal Fusion for Image Manipulation Detection and Localization
Exploring Multi-Modal Fusion for Image Manipulation Detection and
Localization
希腊信息技术研究所,研究和技术研究中心,希腊塞萨洛尼基
论文(arxiv)
post1post2
摘要
最近的图像操作定位和检测技术通常利用由噪声敏感滤波器产生的法医伪影和痕迹,如SRM和Bayar卷积。
在本文中,我们展示了在这种方法中常用的不同过滤器擅长于揭示不同类型的操作,并提供互补的法医痕迹。因此,我们探索了合并这些滤波器输出的方法,其目的是利用所产生的伪影的互补性来执行图像操作定位和检测(IMLD)。
我们提出了两种不同的方法:一种是从每个法医过滤器产生独立的特征,然后将它们融合(称为晚期融合),另一种是执行不同模态输出的早期混合并产生早期组合特征(这称为早期融合)。
我们证明了这两种方法在图像操作定位和检测方面都取得了具有竞争力的性能,在多个数据集上优于最先进的模型1。
方法
编码器解码器框架
Architecture
图片分 ...