
Dinomaly:The Less Is More Philosophy in Multi-Class Unsupervised Anomaly Detection
Dinomaly: The Less Is More Philosophy in Multi-Class Unsupervised Anomaly Detection
Jia Guo1 Shuai Lu2 Weihang Zhang2 † Fang Chen3 Huiqi Li2 † Hongen Liao1,3 ✉
1中国北京清华大学 生物医学工程学院
2中国北京北京理工大学
3中国上海上海交通大学生物医学工程学院
摘要
最新研究揭示了无监督异常检测(UAD)在多类别图像场景中的实际应用场景,该场景需要构建统一模型。尽管针对这一挑战性任务已取得多项进展,但在多类别场景下的检测性能仍远逊于最先进的类别分离模型。本研究旨在弥合这一显著性能差距。本文提出Dinomaly框架——一种基于极简重构的异常检测方案,完全采用纯Transformer架构设计,无需依赖复杂结构、附加模块或特殊技巧。基于仅包含注意力机制和MLP的强效框架,我们发现四个对多类别异常检测至关重要的核心组件:
(1)可扩展基础Transformer模块,用于提取通用且具有区分度的特征;
(2)噪声瓶颈模块,通过预置Dropout机制实现噪声注入;
(3)天然无聚焦能力的线性注意力机制;
(4)非强制性重构机制,避免层间及点对点重建。
我们在MVTec-AD、VisA、Real-IAD等主流异常检测基准集上开展大量实验,所提出的Dinomaly框架在三个数据集上分别取得99.6%、98.7%和89.3%的图像级 AUROC ,不仅超越现有最先进的多类别 UAD 方法,更创下最先进的类别分离 UAD 记录。
代码可在以下网址获取:https://github.com/guojiajeremy/Dinomaly
1.引言
无监督异常检测(UAD)旨在从正常图像中识别异常模式并精确定位异常区域。由于潜在异常的多样性及其稀疏性,该任务被提出采用仅包含正常样本的可访问训练集作为无监督范式进行建模。 UAD 具有广泛的应用场景,例如工业缺陷检测[3]、医学疾病筛查[13]及视频监控[37],有效解决了这些场景中收集和标注所有可能异常数据的难题。
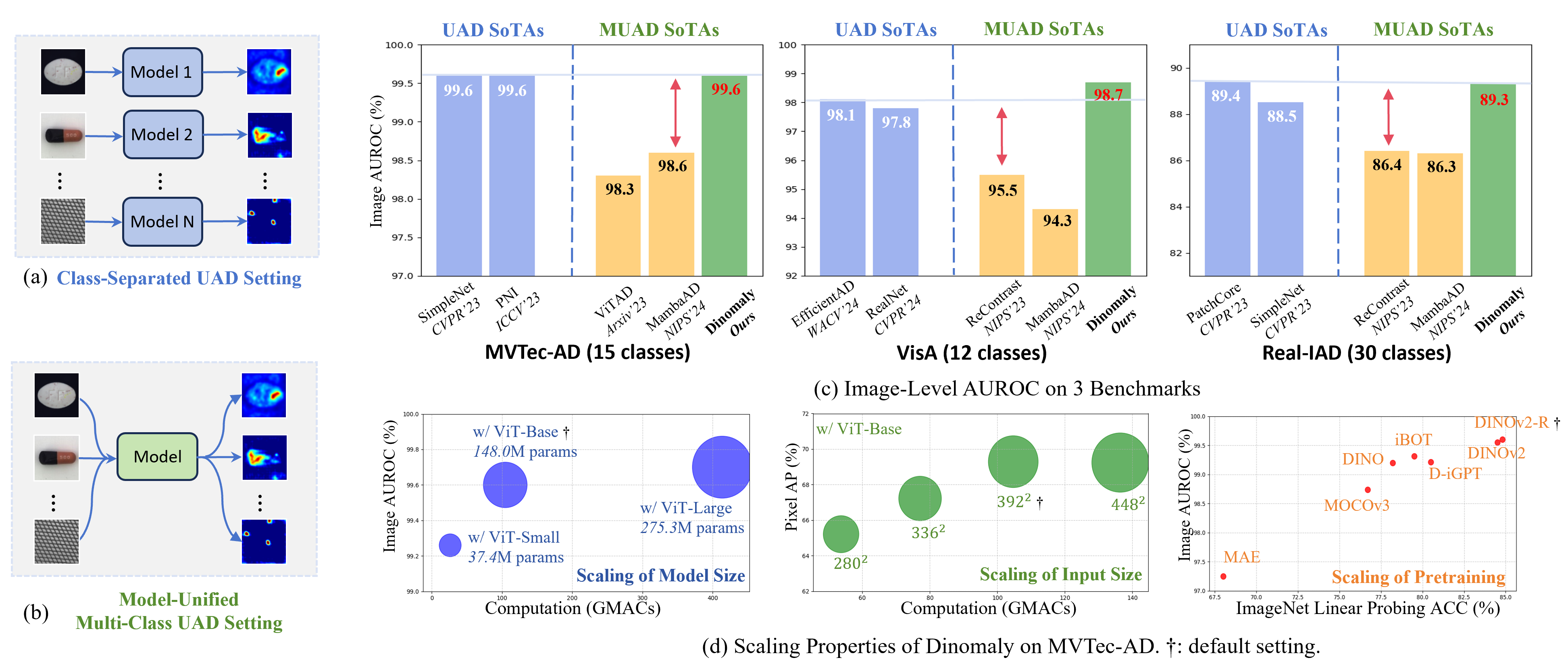
图1.Dinomaly的设置、基准测试与扩展性分析。
(a)类别分离 UAD 的任务设置。(b) 统一模型的多类UAD的任务设置。
(c)在MVTec-AD[3]、VisA[70]和Real-IAD[54]数据集上与现有最佳方法的对比。(d)Dinomaly的扩展特性。
传统 UAD 方法会为每个对象类别构建独立模型(如图1(a)所示),但这种单类别单模型架构会导致模型存储开销显著增加[60],尤其当应用场景涉及大量对象类别时更为明显。对于 UAD 方法而言,构建紧凑的正常模式边界对异常识别至关重要。当各类别导致正常模式内部结构变得过于复杂时,对应分布特征将难以准确测量,从而影响检测性能。近期研究提出统一异常检测框架(UniAD)[60]及后续改进方案,采用统一模型进行多类别异常检测(MUAD)(如图1(b)所示)。在此框架下,直接将输入数据原样输出(无论正常或异常)的“恒等映射”策略会损害传统方法的性能表现[60]。该现象是由多类正常模式的多样性所导致,这些模式促使网络对未见过的模式进行泛化。
两年内,针对 MUAD 问题已提出多种方法,例如邻域掩码注意力机制[60]、合成异常检测[68]、向量量化[36]、扩散模型[16,59]以及状态空间模型(Mamba)[17]。然而,最先进的 MUAD 方法与类别分离 UAD 方法之间仍存在不可忽视的性能差距,如图1(c)所示,这限制了统一模型的实用性。此外,先前方法采用精心设计的模块和架构,可能不够直观,因而普遍存在通用性不足和易用性差的问题[18,36]。
本研究旨在通过多类别统一模型追赶基于类别分离的异常检测模型性能。我们提出Dinomaly框架,一个完全基于Transformer模块[51](特别是自注意力机制和多层感知机MLPs)构建的极简重构 UAD 框架。
首先,我们通过实证研究了自监督预训练视觉Transformer(ViT)[12]作为特征编码器时的扩展规律,用于提取重构目标。
随后提出三个简洁关键要素来解决 MUAD 场景中的关键身份映射问题,且无需增加复杂度或计算负担:
- 第一,作为精心设计的伪异常和特征噪声的替代方案,我们建议 MLP 激活内置Dropout机制,防止网络同时恢复正常与异常模式;
- 第二,利用线性注意力机制(Softmax注意力机制的计算效率优化版本)的“副作用”——该机制会阻碍局部区域聚焦,从而避免信息重复传递;
- 第三,现有方法采用层间及区域级重构方案,通过蒸馏解码器使其即使在异常区域也能精准模拟编码器行为。
因此,我们建议通过将多层结构整体归类并在优化过程中舍弃重建效果良好的区域来放宽重建约束条件。
为验证所提出的Dinomaly模型在 MUAD 环境下的有效性,我们在多个常用基准数据集上进行了大量实验,包括MVTec AD[3](15个类别)、VisA[70](12个类别)和RealIAD(30个类别)。如图1所示,我们的基础规模Dinomaly模型在MVTec AD、VisA和RealIAD数据集上分别实现了99.6%、98.7%和89.3%的图像级 AUROC 率,远超现有最先进方法。此外,可扩展性是Dinomaly的核心优势:进一步扩大模型规模可将性能提升至99.8%、98.9%和90.1%的峰值水平;而在计算资源受限场景中,通过缩减参数规模和输入数据量可获得高效解决方案。
2.相关工作
多类别 UAD
UniAD[60]首次提出多类别异常检测方法,旨在通过统一模型检测不同类别异常。在此场景下,传统 UAD 方法常面临‘相同捷径’挑战,即在推理过程中既能有效恢复无异常样本,也能恢复异常样本[60]。学界认为,这种现象源于多类别正常模式的多样性,导致网络对未见过的模式产生泛化能力。当前许多研究致力于应对这一挑战[14,31,36,59,60]。UniAD[60]采用邻域掩码注意力模块和特征抖动策略来缓解这些捷径效应。 HVQ -Trans[36]提出了一种向量量化(VQ,vector quantization)Transformer模型,该模型能对异常数据产生显著的特征差异。LafitE[59]采用潜在扩散模型并引入特征编辑策略来缓解该问题。DiAD[16]同样运用扩散模型解决多类别 UAD 场景。OmniAL[68]专注于统一场景下的异常定位,通过合成伪异常来防止重建结果的重复性。ReContrast[14]尝试通过两个编码器间的交叉重建来缓解身份映射问题。ViTAD[5]构建了统一的特征重建 UAD 框架,并采用Transformer基础模块。MambaAD[17]在多类别 UAD 背景下探索了最新提出的状态空间模型(SSM,State Space Model)Mamba。更多相关 UAD 研究详见附录A。
3.方法
3.1. Dinomaly框架
“我不理解的,我无法创造”——Richer Feynman
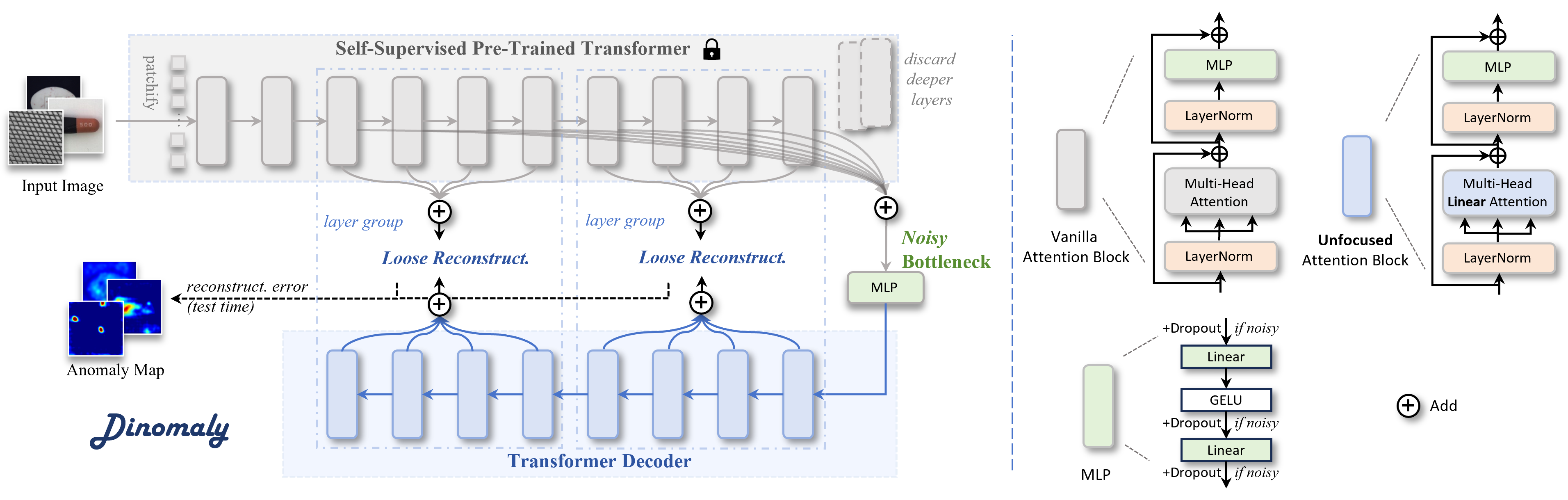
图2. 由简单纯正的Transformer构建模块构建的Dinomaly框架。
人类天生具备从已知信息中识别异常的能力,这为探索世界提供了重要途径。类似地,我们构建了一个基于重构的框架,该框架依托人工神经网络的认知特性。如图2所示,Dinomaly系统由编码器、瓶颈层和重构解码器组成。在通用性方面,我们采用预训练的ViT网络[12]作为编码器,该网络包含12个Transformer层,可提取具有不同语义尺度的信息特征图。瓶颈层采用简单 MLP(即前馈网络, FFN),用于整合编码器中间8层的特征表示。解码器结构与编码器相似,同样由8个Transformer层构成。在训练过程中,解码器通过最大化特征图间的余弦相似度,逐步学习重构编码器中间层的特征。在推理过程中,解码器预期能够重建特征图的正常区域,但对于异常区域则无法完成重建,因其从未见过此类样本。
基础Transformer模型
基于大规模数据集预训练的基础模型,尤其是视觉 Transformer(ViTs)[12,33],为各类计算机视觉任务提供了基础框架与起点。这类网络采用自监督学习方案,包括对比学习(如MoCov3[6]、DINO[4])、掩码图像建模(MAE[19]、SimMIM[57]、BEiT[40])及其组合方法(iBOT[69]、DINOv2[39]),能够生成适用于图像级视觉任务与像素级视觉任务的通用特征。
由于 UAD 缺乏监督机制,大多数先进方法采用预训练网络来提取判别特征。近期研究[28,43,65]初步发现,在异常检测任务中,自监督模型所具备的鲁棒性和通用性特征优势明显优于领域特定的ImageNet特征。本文通过系统分析基础视觉Transformer(ViT)(如图1(d)所示),率先探究了 UAD 模型的扩展行为。我们的综合评估涵盖预训练策略(图5)、模型规模(表4)和输入分辨率(表5),具体细节详见第4.4节。在兼顾检测性能与计算效率的前提下,我们默认采用由DINOv2-Register[7]预训练的ViT-Base/14作为Dinomaly模型的编码器。
3.2. 噪声瓶颈
“Dropout is all you need.”
先前研究[14,60,68]将基于多样化多类样本训练的 UAD 方法性能下降归因于“身份映射”现象;本研究将该问题重新定义为“过度泛化”问题。泛化能力是神经网络的优势,使其能在未见过的测试集上表现同样出色。然而,在利用神经网络认知本质的无监督异常检测场景中,泛化能力并非必要条件。随着多类别 UAD 设置导致图像及其模式的多样性增加,解码器能够将其重建能力推广至未见过的异常样本,从而导致基于重建误差的异常检测失效。
针对身份映射问题的直接解决方案是将“重构”替换为“恢复”。具体而言,现有研究不再直接根据正常输入重建正常图像或特征,而是提出在输入图像[62,67]或编码器特征[59,60]上添加伪异常扰动,同时仍让解码器恢复无异常的图像或特征,构建类似去噪框架。然而这类方法采用的经验性异常生成策略可能无法跨领域、跨数据集、跨方法通用。本研究转向利用简单优雅的Dropout技术。自2014年Hinton等人[21]将其作为过拟合解决方案提出后,Dropout已成为包括Transformer在内的神经架构基石。在Dinomaly中,我们采用Dropout技术随机丢弃 MLP 瓶颈中的神经激活值。不同于缓解过拟合的作用,Dropout在Dinomaly中的功能可解释为对正常表征施加伪特征异常扰动,类似于去噪自编码器[52,53]。无需引入特定模块,这一简单组件能强制解码器无论测试图像是否含异常均恢复正常特征,从而有效缓解相同映射问题。
3.3. 非聚焦线性注意
“One man’s poison is another man’s meat”
Softmax注意力机制是Transformer模型的核心架构,使模型能够针对输入标记序列的不同部分进行注意力分配。具体而言,给定长度为N的输入序列时,注意力机制首先将其转换为三个矩阵:查询矩阵、键矩阵以及值矩阵。
其中、、为可学习参数。通过基于查询-键相似度计算注意力图,Softmax注意力机制的输出可表示为:
回到 MUAD ,先前的方法[36,60]建议采用注意力机制而非卷积层,因为卷积层容易学习到相同的映射关系。然而,这两种操作都存在过度聚焦于对应输入位置以生成输出结果的风险,从而可能导致恒等映射。
是否存在某种简单解决方案可防止注意力机制对相同信息产生关注?在Dinomaly研究中,我们转而利用一种无需Softmax注意力机制(即线性注意力机制)的“去聚焦能力。线性注意力机制被提出作为一种有前景的替代方案,旨在降低基于标记数量的传统Softmax注意力机制的计算复杂度[26]。通过用简单的激活函数 (通常 )替代Softmax操作,我们可以将计算顺序从改为。形式上,线性注意力机制(LA)可表示为:
计算复杂度从O(N²d)降低至O(Nd²)。复杂度与表达能力之间的权衡关系构成了一个难题。先前研究[15,48]将线性注意力机制在监督任务中的性能下降归因于其聚焦能力不足。由于缺乏通过Softmax操作实现的非线性注意力权重调整机制,线性注意力机制无法有效聚焦与查询相关的关键区域(如前景和邻域)。然而,这一特性恰恰符合我们研究场景中重构解码器的优化需求。
为探究注意力机制的信息传播特性,我们采用原始Softmax注意力机制或线性注意力机制作为解码器中的空间混合器,训练了两种Dinomaly变体模型,并对其注意力图进行可视化分析。
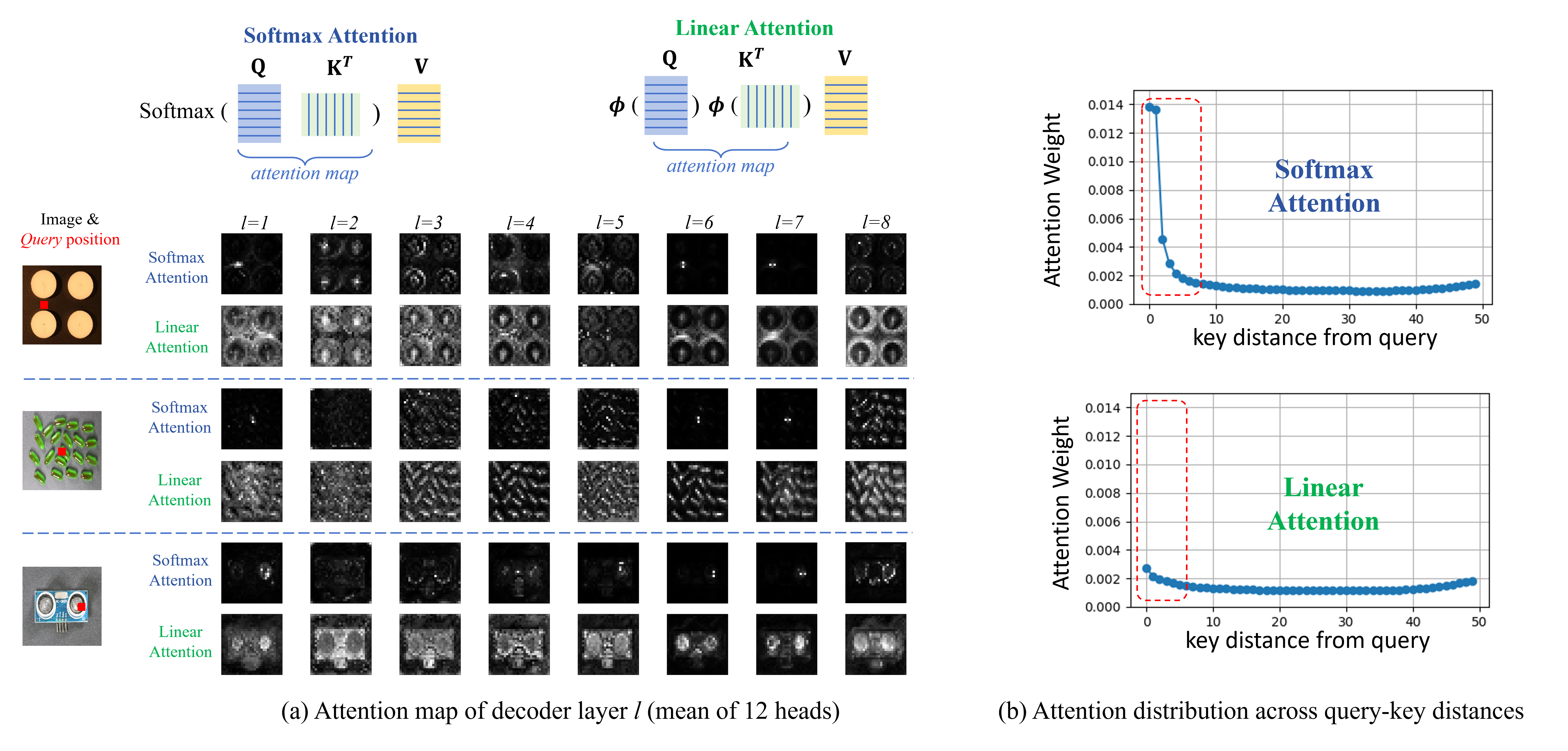
图3. Softmax注意力机制与线性注意力机制对比。(a) 注意力图可视化。(b) 注意力分布。
如图3所示,Softmax注意力机制倾向于聚焦于查询区域的精确位置,而线性注意力机制则将注意力分布扩展至整个图像范围。这表明线性注意力机制因缺乏聚焦能力,会利用更多长距离信息来重建各位置特征,从而降低在重构过程中将未见过模式的相同信息传递至下一层的风险。当然,采用线性注意力机制还能有效降低计算成本,避免性能下降问题。
3.4. 松散重建
“The tighter you squeeze, the less you have.”

图4. 重构约束示意图。
(a) 层间重建(稀疏型)。(b) 层间与猫层重建。(c) 层间重建(密集型)。
(d) 松散组间重建,单组(本研究方法)。(e) 松散组间重建,双组(本研究方法)。
松散约束
特征重构/蒸馏 UAD 方法的先驱[10,46]受到知识蒸馏[20]的启发。大多数基于重构的方法通过相应解码器层[10,46,65](图4(a))或最后解码器层[58,60](图4(b))来蒸馏特定编码器层(例如3个ResNet阶段的最后3层)。直观来看,随着编码器-解码器特征对数量的增加(图4(c)), UAD 模型能够利用更多不同层级的信息来识别异常。然而,根据知识蒸馏的理论直觉,当采用更多层间监督机制时,学生模型(解码器)能够更精准地模仿教师模型(编码器)的行为[30],但这会对通过编码器-解码器差异检测异常的 UAD 模型造成负面影响。这种现象也体现为特征映射问题。得益于Transformer模型中柱状层的自上而下一致性特征,我们提出通过将目标层的所有特征图整体叠加来放宽层间约束条件,如图4(d)所示。该方案可视为弱化层间对应关系,为解码器提供更多自由度,使得在输入模式未见过时解码器能与编码器产生显著差异。由于浅层特征包含有助于精准定位的低级视觉特征,我们可进一步将特征划分为低语义层级组与高语义层级组,如图4(e)所示。
松弛损失
基于上述分析,我们通过剔除特征图中的部分点来实现逐点重构损失函数的松弛化处理。具体而言,我们直接采用硬挖掘全局余弦损失[14],该方法在训练过程中会分离余弦距离较小的高精度重构特征点的梯度。其中,和分别表示编码器与解码器的(组合式)特征图:
其中表示余弦距离,表示数据展平操作,表示位于坐标(h,w)处的特征点,表示将梯度收缩至原始值的十分之一。通过的筛选机制,从批量数据中选取余弦距离较小的k%特征点进行梯度收缩。总损失函数为所有编码器-解码器特征对的Lglobal−hm值的平均值。
5.结论
本文提出Dinomaly这一极简 UAD 框架,旨在解决现有 MUAD 模型性能不足的问题。我们通过Dinomaly框架中的四大核心组件——基础Transformer、噪声 MLP 瓶颈、线性注意力机制及宽松重构机制,在无需复杂模块和技巧的情况下,显著提升了 MUAD 场景下的模型性能。基于MVTec AD、VisA和Real-IAD数据集的大量实验表明,该框架不仅优于传统模型统一式多分类模型,甚至超越了近期提出的类别分离模型,充分证明了在复杂场景中实现统一模型且避免严重性能下降的可行性。