
AA-CLIP:Enhancing Zero-Shot Anomaly Detection via Anomaly-Aware CLIP
AA-CLIP: Enhancing Zero-Shot Anomaly Detection via Anomaly-Aware CLIP
Wenxin Ma1*,2 ,Xu Zhang1,2 ,Qingsong Yao5 ,Fenghe Tang1,2 ,Chenxu Wu1,2,Yingtai Li1,2 ,Rui Yan1,2 ,Zihang Jiang1,2 ,S.Kevin Zhou1*,2,3,4
1 中科院生物医学工程学院 生命科学与医学分院
2 中科院苏州先进研究所奇迹中心
3 中国科学院信息科学与技术部智能信息处理重点实验室
4 中科院精密与智能化学国家重点实验室
5 斯坦福大学
摘要
异常检测(AD)技术主要用于缺陷检测和病变识别等应用场景中的异常值识别。尽管CLIP模型凭借强大的泛化能力在零样本异常检测任务中展现出潜力,但其固有的异常感知不足特性导致对正常与异常特征的区分能力有限。为解决这一问题,我们提出异常感知型CLIP(AA-CLIP)模型,在保持泛化能力的同时,显著提升了文本和视觉空间中的异常区分能力。AA-CLIP通过简单高效的两阶段方法实现:首先生成具有异常感知能力的文本锚点以清晰区分正常与异常语义,随后将图像块级视觉特征与这些锚点进行对齐,从而实现精准的异常定位。该两阶段策略借助残差适配器,以可控方式逐步优化CLIP模型,既实现了有效的反向传播(AD),又保持了CLIP的类别知识。大量实验验证表明,AA-CLIP作为零样本反向传播任务的资源高效解决方案,在工业和医疗应用领域均取得了业界领先水平的成果。
该代码可在以下网址获取:https://github.com/Mwxinnn/AA-CLIP
1.引言
异常检测(AD)通过建立数据集分布模型来识别异常值,例如工业产品中的缺陷[2]或医学影像中的病灶[13]。尽管先前的异常检测框架[10,11,15,23,31,58]在特定类别具备充足标注数据时能有效检测异常,但其高资源消耗特性常限制其对新类别及罕见类别的泛化能力。这一局限性在现实场景中尤为突出,因为收集全面标注的AD数据集通常难以实现,因此需要探索小样本学习和迁移学习方法。
对比语言-图像预训练模型(CLIP)已成为极具前景的解决方案,在各类零样本任务中展现出卓越的泛化能力[24-26,42]。基于CLIP的成功经验,近期多项研究通过利用异常相关描述来指导异常区域检测,将其应用于少样本/零样本异常检测任务。具体而言,视觉编码器经过训练可将异常图像映射为视觉特征,这些特征与异常描述的文本特征比与正常描述的特征具有更高的匹配度[29,30,49,60]。后续研究[6,7,17,41]着重优化CLIP的补丁级特征表示,以实现与文本特征的更好对齐,从而显著提升异常定位性能。
这些方法依赖于需要具备异常感知能力的文本特征,才能有效区分异常情况。然而最新研究指出,CLIP在细粒度语义感知与推理方面存在局限性[21,22,36,38,45,46]。通过分析CLIP在异常检测中的纹理特征发现,虽然其文本编码器能有效捕捉物体级信息,但在区分正常与异常语义时存在可靠性不足的问题。
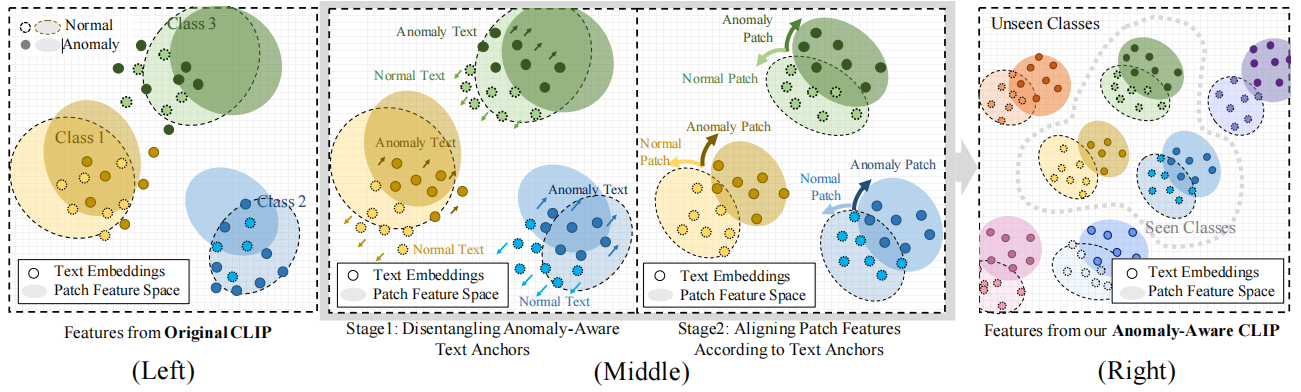
图1。
(左)CLIP的异常感知缺陷:预训练阶段的类别级图像-文本对齐导致CLIP在异常/正常语义区分上存在模糊性,且补丁-文本对齐精度不足。
(中)我们的两阶段自适应策略:第一阶段将异常与正常文本特征解耦为文本空间中的锚点;第二阶段通过训练补丁级视觉特征与这些锚点对齐,最终形成具备异常感知能力的CLIP。
(右)泛化型异常感知能力:本方法使CLIP能够对已知及未知类别均具备泛化型异常感知能力。
如图1(左)可视化的概念及图2示例所示,CLIP存在固有的异常感知缺陷:正常与异常纹理特征的重叠会降低文本引导式异常检测的精确度。我们认为,通过在文本空间中建立更清晰的正常与异常语义区分标准,使CLIP具备异常感知能力,对于引导视觉编码器精准检测和定位异常至关重要。
这一发现促使我们通过增强文本空间中的异常判别能力来改进基于CLIP的零样本异常检测方法,最终实现了基于异常感知CLIP(AA-CLIP)的突破——该模型通过编码异常感知信息进行优化。AA-CLIP采用创新的两阶段自适应策略:第一阶段在冻结视觉编码器的同时对文本编码器进行自适应训练,为每个训练类别在文本空间中构建异常感知语义的“锚点”。如图1(中)所示,各类别的文本特征被解耦为独立的锚点,异常判别效果显著。值得注意的是,这种解耦机制同样适用于新类别和未见类别,有效支持异常检测任务中的零样本推理(参见图1(右))。第二阶段中,AA-CLIP将图像块级视觉特征与这些特化纹理锚点进行对齐,引导CLIP视觉编码器聚焦异常相关区域。这种双阶段策略构建了精准高效的异常检测框架。
值得注意的是,由于CLIP经过海量数据的深度训练,为保持其预训练知识,我们在两个阶段均采用简单结构的残差适配器。该设计既实现了对CLIP的可控适配,又增强了其处理细粒度自适应任务的能力,同时不牺牲泛化能力。
实验结果表明,我们的直截了当的方法显著提升了CLIP模型在零样本对抗训练中的表现,即便在数据有限的场景下依然有效。通过采用最小样本量训练(例如每个类别仅需一个正常样本和一个异常样本,即2-shot训练),并在未见过的数据集上进行测试,我们的方法实现了与其他基于CLIP的对抗训练技术相当的零样本性能。训练集仅包含每个类别64个样本的情况下,该方法在跨数据集零样本测试中已达到 SOTA 水平,充分验证了其在最小数据需求下最大化CLIP对抗训练潜力的能力。
我们的主要贡献总结如下:
1.异常感知CLIP模型:通过增强并提升模型的异常判别能力,我们提出AA-CLIP框架,该模型在文本和视觉空间中对异常现象具有更强的序列感知能力,并将异常感知信息直接编码至原始CLIP模型中。
2.基于残差适配器的高效迁移学习:通过实现简单的残差适配器架构,在提升零样本异常检测性能的同时,有效避免了模型泛化能力的损失。
3.高 SOTA 与高效训练:本方法在多种数据集上均取得 SOTA 效果,即使在训练样本有限的情况下仍展现出强大的异常检测能力。
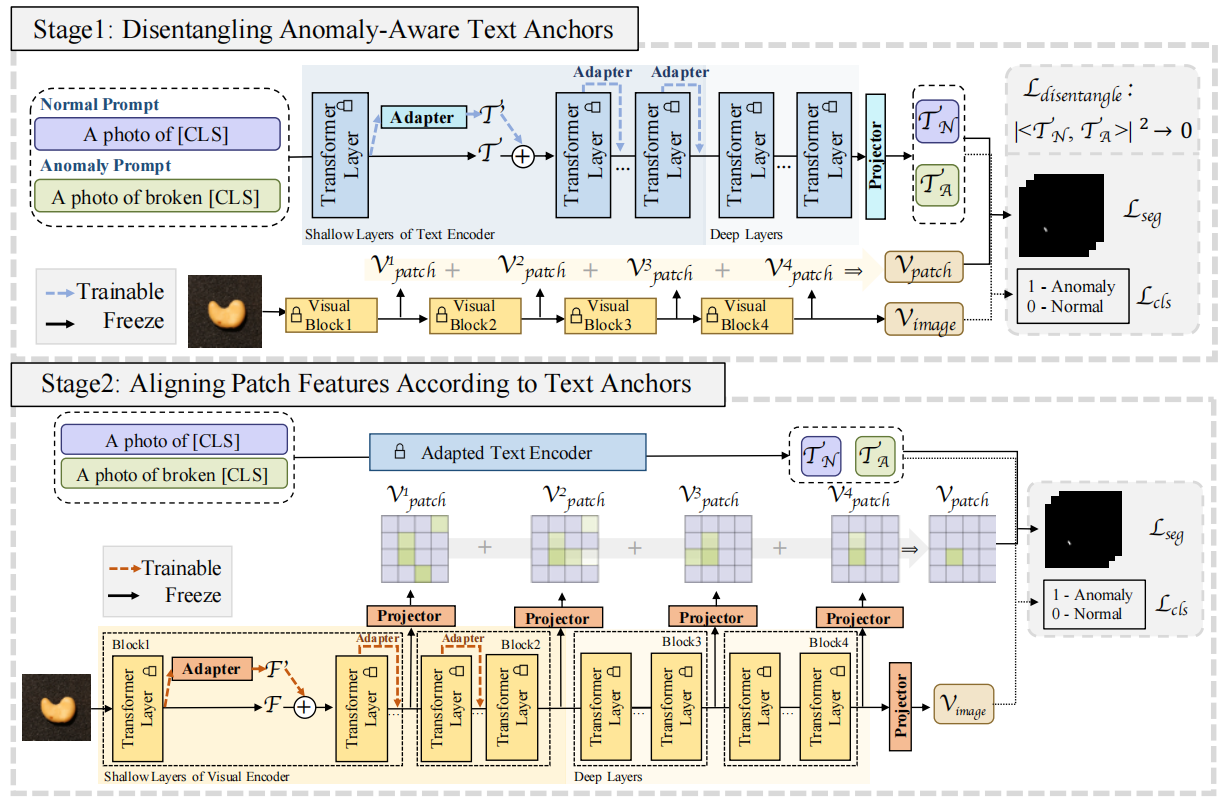
图4. 异常感知CLIP的两阶段训练流程。
第一阶段通过解耦损失函数辅助训练AA-CLIP的文本编码器,使其具备识别异常相关语义的能力。
第二阶段则将图像块特征与这些文本锚点进行对齐。
两个阶段的实现均通过将残差适配器集成到CLIP主干网络的浅层结构中达成。这种可控的自适应机制使CLIP能够有效区分异常数据,从而构建出我们提出的异常感知CLIP模型。
结论与讨论
据我们所知,这是首个明确分析CLIP模型内在异常感知缺失问题的研究。为解决该问题,我们提出了一种简单而有效的两阶段训练策略,将异常感知信息嵌入CLIP模型,从而实现已见类与新异类之间异常表征的清晰区分。通过利用残差适配器,我们的方法保留了CLIP强大的泛化能力,在多个数据集上实现了卓越的零样本性能。
基于该两阶段适配策略开发的改进型AA-CLIP模型,揭示了优化CLIP特征空间对提升下游应用性能的潜力。除解决异常感知缺失问题外,本研究还为攻克CLIP模型中其他“感知缺失”问题奠定了基础,例如情境感知能力不足或领域相关细微差异的捕捉局限性,这为拓展CLIP跨任务适应性提供了方法学依据。此外,我们在全样本训练中观察到过拟合现象,提示CLIP适配过程中可能存在性能饱和风险,值得进一步研究。