
A comprehensive survey on image authentication for tamper detection with localization
A comprehensive survey on image authentication for tamper detection with localization
H R Chennamma1 & B Madhushree 1
摘要
以数字形式存储或传输的数据容易遭受攻击。数字图像尤其容易遭到未经授权的访问和非法篡改。正因如此,图像可信度验证方法因其在政府、军事、法医鉴定、电子商务等众多社会领域的重要性,正日益受到重视。即便是轻微的攻击也可能造成灾难性后果。因此,保护图像免遭篡改变得愈发关键。现有文献中已开发出多种方法来确保数字图像的真实性和完整性,这些方法可归纳为主动式与被动式图像认证及篡改检测技术。主动式图像认证通常采用水印、数字签名及混合技术等通用方案,而被动式认证则依赖图像固有的自然特征实现隐式验证。数字图像取证工具已被用于识别数字篡改痕迹。通过梳理过去三十年的文献发现,图像可信度验证方法已取得显著成效。然而,若要精准定位图像篡改痕迹,即便操作得当且具备专业技能,仍是一个尚未解决的难题,且难度相当高。这促使我们对图像认证技术进行全面综述,该综述不仅能够实现图像篡改检测,还能定位被篡改区域。我们还讨论了未来的研究方向。
关键词 数字签名 数字水印 明确认证 图像认证 隐式认证 破坏定位
1.引言
图像认证是使图像能够验证其真实性和完整性的一种过程,由于其在提供安全性和完整性方面的重要性而受到广泛关注。在当今数字时代,图像更容易被篡改,完整保存图像变得异常困难。因此,保护医疗影像、军事影像等敏感图像的安全性显得尤为重要。完整性是指图像自生成以来保持完整无损、未经人为篡改的状态,这正是图像真实性的核心概念。真实性[126]指图像来源或权威性可被验证且未经复制。由于其独特的完整性标准,图像认证与其他类型的数据认证存在本质区别。同一图像可能以多种文件格式存在,这些格式虽然能呈现几乎相同的视觉细节,但数据表征却大相径庭。图像压缩虽能减少冗余,但不会改变其语义内涵。在实际应用中,图像认证既要具备抗篡改能力,又要适配图像增强操作(如对比度校正、直方图均衡化和有损压缩)——这些操作不会改变图像语义,同时需对恶意攻击(如插入或修改图像细节)保持敏感。
目前已有大量关于伪造检测的综述论文发表,每篇论文都采用了不同的研究方法。Kaur Gill等人提出了仅包含被动技术的伪造检测分类体系[55]。Vinolin等人阐述的伪造检测分类体系具有重要价值,该体系不仅包含主动与被动技术的层级结构,更侧重于被动技术的研究[153]。近年来,研究者们采用深度学习算法进行篡改检测与定位以提升检测效果,因此基于深度学习技术的综述研究显得尤为重要。巴拉德等人撰写的深度学习图像篡改检测综述,系统阐述了被动技术的应用现状、未来发展方向及数据集选择[17]。
判断图像是否被篡改其实很简单,但要高效定位篡改区域却是个难题。我们发现,当篡改者使用专业图像编辑工具进行操作时,要精确定位篡改区域几乎不可能。因此,通过定位技术进行图像篡改检测的认证方式,能为图像提供全方位保护。无论如何,图像认证主要承担两大功能:验证图像的真实性与完整性。本文基于主动式和被动式图像认证方法,对篡改定位问题进行了系统性综述。
本文其余部分结构安排如下:第二部分阐述基于主动图像认证的篡改检测与定位技术,涵盖水印、特征签名及混合方法等前沿技术;第三部分介绍基于被动图像认证的篡改检测与定位技术,包含基于像素、格式、相机、物理环境及几何特征的多种方法;第四部分列举文献中使用的公开数据集;第五部分总结全文并展望未来研究方向。
2.主动方法
主动式图像认证是一种通过在图像中嵌入或传输已知认证码来验证信息及发送方可信度的认证方式。该方法需在记录或发送时生成独特的数字签名或水印。数字水印、数字签名及混合方法是主动式认证的三种主要形式。
2.1.数字水印
2.1.1.脆弱水印
2.1.2.半脆弱水印
2.1.3.鲁棒水印
2.2.数字签名
2.2.1.密码签名
2.2.2.鲁棒签名
2.2.3.感知图像哈希
2.2.4.[FASHION]用于信息保障的取证图像哈希
2.3.混合方法
混合方法是两种或多种不同技术的结合。如图3所示,首先从原始图像生成哈希值,然后将该哈希值或从原始图像获取的特征作为水印嵌入并发送给接收方。若接收端的哈希值存在任何差异,则视为图像被篡改。Chen等人[32]采用数字水印与数字签名技术相结合的方法来验证图像的真实性和完整性。数字水印将水印嵌入图像中,而数字签名则生成独立的签名文件并随图像一同传输。为避免额外流程并提高准确性,作者将数字水印与签名技术相结合。推荐方案是根据图像生成签名并将其作为水印嵌入原始图像,从而省去了将签名文件与图像一同发送的额外步骤。该方法不仅能验证完整性,还能精准定位篡改痕迹。
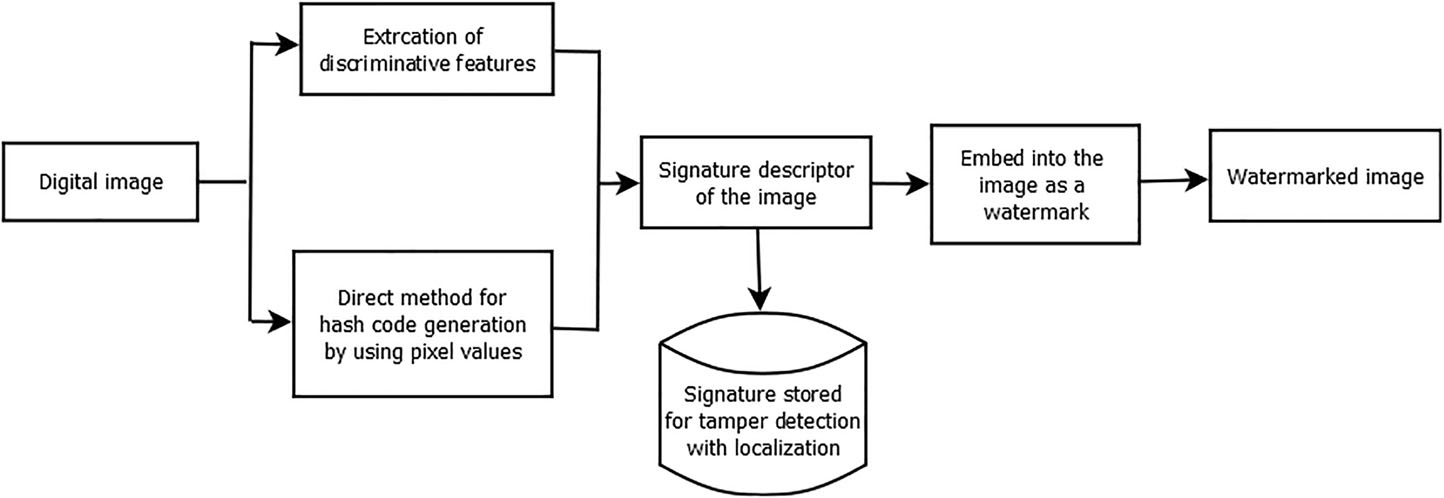
图3 混合技术的框图
3.被动方法
图像认证的被动方法依赖于图像固有的自然特征,而非发送者特定信息(如签名或水印)。在缺乏明确认证的情况下,被动式方法成为图像验证的替代解决方案。大多数数字图像取证技术采用被动检测手段,在缺乏水印或特征标记时识别内容篡改痕迹。研究显示,虽然数字伪造图像不会留下任何被篡改的视觉线索,但其仍会破坏自然图像内容的底层统计特性[41]。
被动式图像篡改检测方法可大致分为五类:基于像素、基于格式、基于相机、基于物理环境及基于几何检测[47]。下文将探讨各类篡改检测技术的最新进展,这些技术不仅能有效识别篡改痕迹,还能精确定位篡改区域。
3.1 基于像素的方法
基于像素的检测通常依赖于图像的像素值。这些技术用于识别像素层面因操作产生的统计异常,主要涉及三种类型:复制-粘贴、重采样和拼接技术。复制-粘贴法是图像伪造中最常用的方法,即把图像的一部分复制并粘贴到同一图像的其他位置。重采样则是通过调整图像部分的尺寸、拉伸或旋转,将其转移到不同的测试网格上。拼接技术则是将至少两张图像合成一张的伪造方式。当两张图像被拼接成一张时,仅凭肉眼观察可能很难发现拼接区域。
众多研究提出了多种基于像素的伪造检测方法[11,18,27,33,37,40,45,51,52,54,57,61,62,64,65,71,73,80,83,85,87,89,90,93–95,104,107,112,114–118,123,127,133,136,143–145,149,155,167,176–178,182,184]。该方法首先将原始图像分割为互不重叠的区块,随后通过主成分分析(PCA)、离散余弦变换(DCT)、离散小波变换(DWT)、特征矩阵变换(FMT)、奇异值分解(SVD)、小波特征提取(SIFT)或表面特征提取(SURF)等算法从每个区块中提取特征。为检测篡改区域,需进行特征选择与字典序排序。弗里德里希等人提出基于DCT的复制-移动区域检测方法,但该方法对含噪图像效果欠佳[127]。文献[104]采用PCA方法自动确定精确复制-移动区域,但时间复杂度较高。通过相似度匹配方法可降低时间复杂度,且该方法在含噪条件下同样有效[104]。张等人提出了一种创新策略,该策略既能处理含噪图像也能处理压缩图像,并利用DWT方法准确检测复制-移动区域[176]。相较于其他算法,文献[83]将DWT与SVD相结合以降低时间复杂度。后续研究采用SIFT特征不仅可识别复制-移动区域,还能检测虚假区域[64]。尽管SVD能可靠检测复制-移动区域,但在高含噪或压缩图像中表现欠佳[73]。主成分分析(PCA)技术经过改进,现已能处理含大量噪声和压缩的图像,从而精准定位复制-移动区域[89]。拼接方法同样关注拼接区域的检测,为此z.qu等人提出了 DWVAM [133]算法来识别拼接区域。DCT-SURF技术可同时检测拼接和复制-移动现象,有助于精确识别篡改区域[87]。将离散余弦变换(DCT)与离散小波变换(DWT)相结合,可有效检测高度压缩图像的伪造痕迹,能准确识别伪造区域[54]。DCT技术能识别模糊、含噪且压缩图像中的伪造区域,并帮助确定其确切位置[27,65]。Tian-Tsang等人[116]开发了一种新型拼接检测技术,通过双相干特性实现拼接识别。Chennamma等人[35]利用晶状体径向畸变开发了一种检测剪接的新方法。若图像中存在镜头径向失真程度的不一致性,可通过基于线性的校准方法检测图像篡改痕迹。该方法对真实图像同样适用。何中伟等人[62]提出了一种基于马尔可夫方法的拼接检测方案:首先从原始图像的DCT域和DWT域提取马尔可夫特征,其中DCT域提取的特征更为全面,不仅包含块内相关性,还涵盖块间相关性。生成所有相关特征后,采用 SVM -RFE算法筛选特征以降低维度并生成最终向量,最后通过 SVM 作为分类器区分真实图像与拼接图像。穆罕默德·曼祖鲁尔·伊斯拉姆等人[66]提出 LBP 纹理算子用于彩色图像拼接检测,该方法将图像分割为非重叠区块,利用DCT识别伪造引起的图像变化,同时采用 LBP 增强篡改检测效果。最终生成的 LBP 图像再次分割为非重叠区块,并最终整合为特征向量。
通常,图像伪造是通过将图像的某部分复制粘贴到另一图像上(图像合成)来实现的。在此过程中,需要调整图像尺寸以匹配原始图像的网格。这一过程被称为重采样。重采样过程会在图像中引入新的相关性,这有助于检测被修改的部分。文献[129]提出了一种基于EM算法的概率图估计方法,并将每个像素与其邻近像素之间的相关性纳入考量,从而辅助检测篡改区域。该方法的主要缺点是仅适用于未压缩或轻微压缩的JPEG、GIF和TIFF图像。为克服这一缺陷,Prasad等人[130]提出了一种基于DCT和DWT的方法,其中DCT应用于整个图像以保留高频系数,这有助于检测篡改区域。小波分析可用于检测篡改区域,该方法将图像分解为水平、对角线和垂直三个细节层级,而非保留高频系数。提取这三个细节后,其余系数会被消除。这种方法对图像缩放和压缩具有更强的抗性。
Babak Mahdian等人[108]提出了一种基于拉东变换与导数运算的创新方法,该技术能高效、盲态且自动化地追踪插值与重采样过程。当两幅或多幅图像拼接成高质量伪造品时,该方法可有效检测伪造行为,此类伪造通常包含缩放、偏斜、旋转及尺寸调整等几何变换。检测此类几何变换需通过插值与采样步骤。借助重采样/插值检测器,可轻松识别被篡改区域。该方法对JPEG压缩与重采样具有更强鲁棒性,但时间复杂度较高。为缩短处理时间,Matthias Kirchner等人[78]提出采用固定线性预测残差的快速可靠重采样方案。该方案通过变换参数影响残差值,从而精准定位图像中的重采样区域。实验结果表明,相较于其他技术,该方法具有较高的可靠性。
为了解图像伪造检测的前沿方法,文献中可查阅若干综述论文,这些论文重点阐述了基于被动检测方法的不同伪造技术的优缺点[4,14,139,154]。近年来,深度学习技术被广泛应用于伪造区域的检测与定位。Rao等人采用专为拼接与复制移动检测设计的卷积神经网络(CNN)技术[135]。该CNN模型通过预训练标注样本,可作为局部图像块描述符。利用预训练的CNN从测试图像中提取密集特征,并将特征融合方法应用于 SVM 分类。为准确检测篡改区域,Mohammed等人引入了离散余弦变换[10]。该方法首先将RGB图像转换为灰度图像,随后将图像分割为非重叠区块。针对每个区块计算二维离散余弦变换系数,并采用之字形扫描方式将特征向量应用于二维系数。接着通过字典序对区块进行排序,随后利用欧氏距离对每个区块进行匹配以检测重复区块。区块匹配不仅足以检测伪造区域,作者还通过偏移向量辅助伪造决策,从而精确定位伪造区域。
重采样特征与深度学习技术被用于检测图像篡改。首先通过随机游走分割法定位篡改区域,随后利用 LSTM 计算重采样特征以实现精准定位。这两种方法均能高效检测复制-移动、重采样及拼接篡改[25]。为提升整体伪造检测效能,Mohammed等人提出重采样检测框架,将复制-移动算法作为预过滤步骤以增强伪造检测[110]。除复制-移动外,数字拼接在图像篡改中同样至关重要。文献[92]中,研究者提出深度融合网络定位拼接伪造,通过组合多层卷积层构建融合网络,该网络在多种场景下均取得显著成效。Vega等人[13]提出了一种新型篡改检测方法,结合DCT、DWT和 LBP 检测伪造区域:首先将图像转换为YCbCr格式并应用DWT,随后将转换后的图像分割为若干区块,对每个区块进行直方图分析并提取 LBP 特征;接着从每个 LBP 区块提取DCT系数,将向量拼接后应用 SVM 。该方法在 CASIA v1.0和 CASIA v2.0数据集上均取得良好效果。穆扎法尔[113]提出了一种基于深度学习的卷积神经网络,该网络通过输入图像提取特征,再利用特征匹配技术识别伪造痕迹。为消除误匹配,系统采用后处理机制,从而精确定位伪造区域。该框架采用跳跃连接结构[109],通过复制-移动、拼接和移除等操作进行检测。其架构包含 LSTM 、编码器-解码器和跳跃连接三个层级:第一层 LSTM 学习篡改与未篡改区块间的转换规律;编码器-解码器通过卷积运算提取空间信息;最后一层则综合 LSTM 输出值与空间特征进行篡改检测。
卷积神经网络在检测篡改区域方面发挥着关键作用,与其他技术相比展现出显著优势。该神经网络通过特定训练方式实现篡改区域识别:首先将图像输入CNN进行特征提取,再通过特征比对检测伪造区域。生成对抗网络(GAN)被用于检测伪造区域[2]。文献[82]中,研究者提出一种用于数字图像深度修复的CNN模型,该模型通过像素级特征提取实现图像修复定位,不仅在海量数据中表现优异,还能精准定位篡改区域[59,96]。为提升效率,研究者提出了改进版CNN——掩码R-CNN,该模型包含三个阶段:第一阶段提取图像显著特征,第二阶段进行区域提议,最终通过预测实现篡改区域检测[8,160]。针对多重复制-移动篡改,Bilal等人提出了一种检测与定位篡改区域的技术:首先将图像转换为灰度图并应用离散小波变换,随后使用SURF和Bristk算法提取特征,进行特征匹配后通过 DBSCAN 和 RANSAC 进行聚类以识别误匹配,最后通过后处理确定伪造区域[23]。在篡改与未篡改图像的区分方面,Azrak等人提出了一种三角变换以定位伪造区域,并应用深度学习技术来区分伪造与未伪造图像[9]。
机器学习算法同样能取得与深度学习技术相当的优异效果。为检测复制粘贴和拼接伪造,作者Lourembam等人提出了一种基于机器学习的方法:将RGB图像转换为灰度图像并分割成若干区块,通过SIFT和SURF算法从每个区块提取特征,计算各关键点的特征向量值,再与区块特征向量进行比对,基于特定阈值检测伪造区域[43]。Doegar等人进一步提出了一种增强定位的组合技术,将深度学习与机器学习算法相结合。该方法采用GoogleNet进行图像特征提取,并运用随机森林算法检测伪造区域[99]。而伪造区域的恢复则更具挑战性。Ying等人提出的Imuge技术将U-Net编码器与伪造定位网络相结合,该技术不仅能精确定位伪造区域,还能近似还原原始数据[175]。
深度伪造技术通过在图像或视频中用其他人脸替换原始人脸。在检测深度伪造时,区分篡改图像与未篡改图像的能力至关重要,这有助于在遇到严重问题时做出正确判断。基于生成对抗网络(GAN)的深度学习技术能有效识别篡改图像[56]。已有深度伪造专项调研揭示了利用深度学习技术创建和检测深度伪造的各类方法[120]。由于多媒体数字图像更易被篡改,开发防深度伪造工具显得尤为重要。路易莎·维尔多利瓦在研究中系统阐述了深度伪造检测的不同方法、现有工具的局限性及未来发展方向[152]。
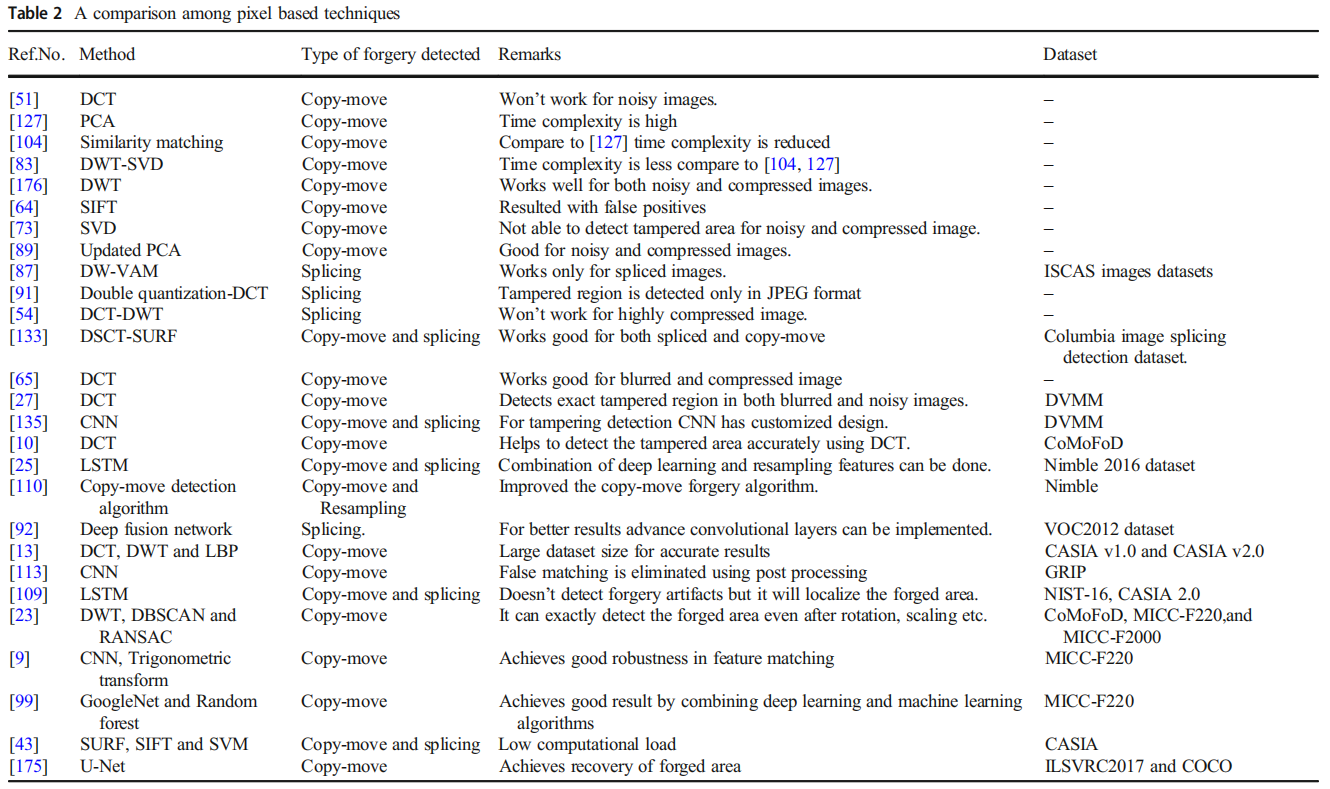
表2以鸟瞰图形式展示了基于像素的技术在以下方面的比较:所采用的方法/途径、检测到的伪造类型、各方法的局限性或优势,以及用于伪造检测的数据集。
3.2 基于格式的方法
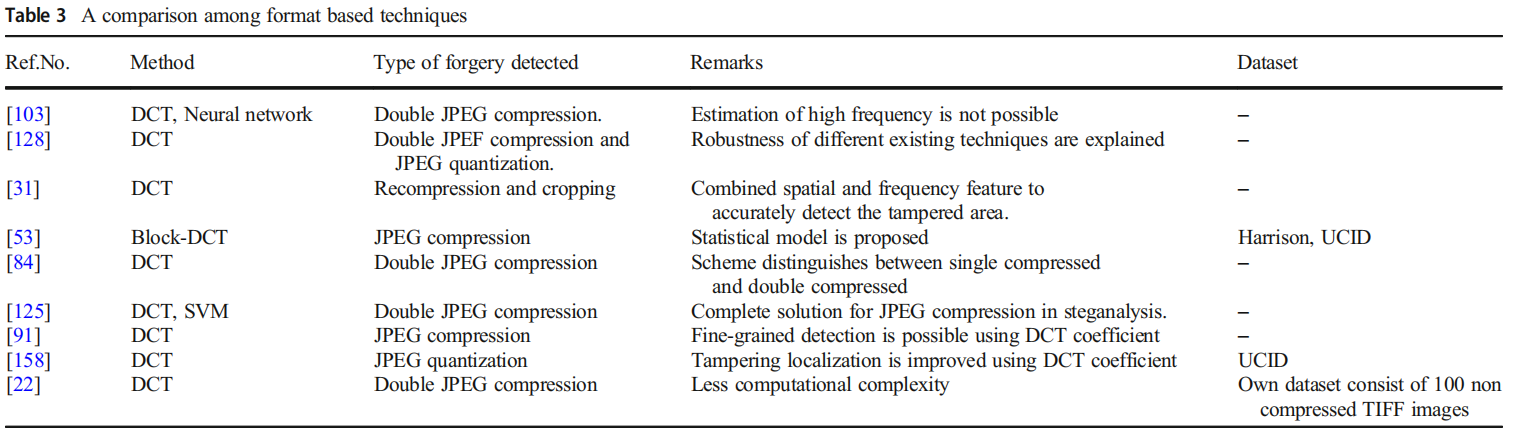
最具代表性的图像可信度验证方法当属基于格式的检测技术。这类技术主要应用于JPEG格式图像,具体可分为JPEG量化、双JPEG压缩和JPEG块效应检测三种类型。JPEG量化技术通过将数据压缩位数缩减至单一量化值来实现压缩。多数图像会经历多次JPEG压缩,这意味着当图像再次被压缩时,由于数据重叠导致DCT系数间产生相关性,从而形成双JPEG压缩现象。而JPEG块效应检测则针对因块间变化导致的JPEG压缩图像裁剪问题,通过分析DCT系数间的相关性来识别块效应伪影[22,31,53,84,91,103,125,128,158]。表3系统梳理了各类基于格式技术的特征,包括所采用的方法、可检测的伪造类型、各技术的局限性与优势,以及用于伪造检测的典型数据集。
3.3 基于相机的方法
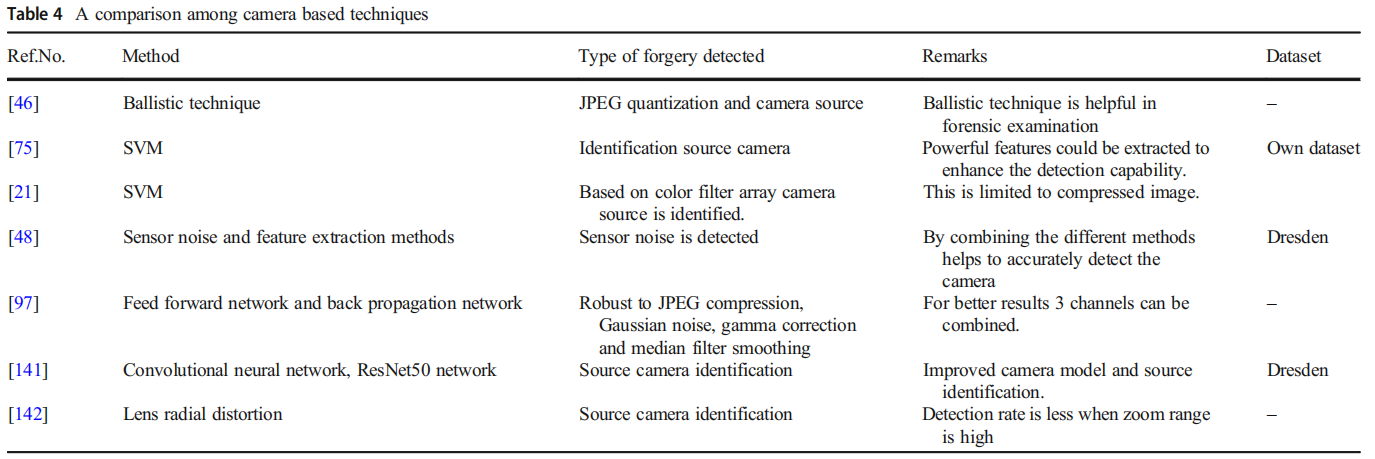
当数码相机拍摄图像时,画面会从感光元件传输到存储器。在相机内部处理图像的过程中,会经历色彩滤光片阵列、JPEG压缩、量化、白平衡和伽马校正等处理阶段。从拍摄到存储的整个过程中,图像会固有地包含各种相机伪影,例如色差、滤光片插值、相机响应和传感器噪声。这些伪影的差异可能被用作篡改证据[5,21,42,46,48,75,76,97,140–142]。表4展示了基于相机技术的对比分析,包括所采用的方法/技术、检测到的伪造类型、各方法的局限性或优势,以及用于伪造检测的数据集。
3.4 基于物理环境的技术
若用于合成的图像在不同光照条件下拍摄,则难以在合成照片中匹配其光照条件。若图像中存在不真实的光照现象,则可能存在篡改痕迹。约翰逊等人首次尝试通过获取不同物体的光源方向来检测篡改区域[67]。后续研究改进了该方法,引入多光源检测技术,使其适用于复杂光照环境[68]。作者约翰逊团队进一步将该技术拓展至三维空间[69],伪造品识别准确率达83.7%[34]。基等人提出检测三维光照环境的技术[74],通过分析光源方向的不一致性可识别图像伪造,检测率达87.33%[106]。范等人基于物体形状与光线明暗差异,提出检测二维光照下篡改区域的技术[44]。德卡瓦尔等人利用统计数据分析色彩光照差异,提出图像伪造检测技术,采用 SVM 与融合分类器实现伪造品识别,检测率达86%[40]。表5概述了基于物理环境的技术在以下方面的比较:所采用的方法/途径、检测到的伪造类型、每种方法的局限性或优势,以及用于伪造检测的数据集。

3.5 基于几何的技术
基于几何的技术用于测量图像中物体相对于相机位置的坐标、形状和尺寸。通常,主点位于图像中心附近。若人物或物体在图像中发生比例性位移,主点也会随之移动。因此,通过计算图像中主点间的差异来实现篡改检测。Johnson等人提出了如何从图像及其他几何形状中估算主点的方法。他们证明了平移平面等于主点偏移量,并展示了如何利用这些数值进行篡改检测[70,119]。
4.数据集
数据集是检验各类图像伪造检测算法效能的主要依据。目前研究者已创建少量公开数据集,这些资源为研究者提供了在不同场景下验证检测篡改区域方法的有效平台。其中 ISCAS 数据集和哥伦比亚数据集被广泛应用于拼接方法测试: ISCAS 数据集包含约20幅1024×1024至2600×2000像素的图像[87],哥伦比亚数据集则包含约1845幅128×128像素的图像。这些图像均提取自Calphotos图像库,其余部分则采集自数码相机[133]。在复制-移动技术检测中, DVMM 采用的数据库包含多个不同来源:第一个数据集来自哥伦比亚大学,图像尺寸为128×128像素;第二个数据集来自柯达公司,包含压缩的PNG格式图像[27,135]。根据图像处理类型的不同,数据集的选取也有所差异。例如,CoMoFoD数据库专门用于检测复制-移动伪造,其数据集按处理类型进行分类,包含250张512×512像素的伪造图像[10]。针对基于像素的克隆、删除、重采样等处理方式,主要采用Nimble或NIST-16数据库进行检测,这些数据库包含不同后处理程度和压缩版本的图像。其中Nimble数据库收录了2520张经过处理的图像[25,109,110]。
为区分篡改与未篡改图像,本研究采用VOC2012数据集。该数据集包含未经篡改的图像,有助于检测拼接痕迹[92]。为在低特征向量 CASIA 下获得良好效果,引入了两个版本的数据集: CASIA v1.0和 CASIA v2.0。 CASIA v1.0包含1721张图像,尺寸为384256像素,全部为 JPG 格式,其中800张为真实图像,921张为拼接图像。 CASIA v2.0包含12614张图像,尺寸为240160像素,格式包括 JPG 、TIFF和bmp,其中7491张为真实图像,5123张为拼接图像[13,43,109]。为检测精确篡改区域,使用 MICC -F220和 MICC -F2000数据集。 MICC -F220包含220张图像,分为110张篡改图像和110张原始图像,整体图像篡改面积占1.2%。 MICC -F2000包含2000张图像,分为700张篡改图像和1300张原始图像,整体图像篡改面积占1.12%[9,23,99]。该数据集相比其他数据集能提供更准确的结果。