
A memory-augmented multi-task collaborative framework for unsupervised traffic anomaly detection in driving videos
A memory-augmented multi-task collaborative framework for unsupervised traffic anomaly detection in driving videos
Rongqin Liang a, Yuanman Li a, Yingxin Yi a, Jiantao Zhou b, Xia Lia,∗
摘要
在自动驾驶和驾驶辅助系统中,识别行车视频中的交通异常对保障行车安全至关重要。针对驾驶事件长尾分布带来的潜在风险,现有交通异常检测方法主要依赖无监督学习。然而,多数传统无监督方法仅采用单一预任务,无论是基于外观特征还是未来目标定位的检测方法,都难以同时建模驾驶场景中的全局与局部运动,导致检测效果欠佳。本文提出一种创新的增强记忆多任务协同框架,通过光流重建与未来目标定位任务的协同工作,全面建模驾驶过程中的全局与局部运动,从而更精准地检测涉及本车与非本车的异常。此外,我们引入记忆增强型运动表征机制,充分挖掘不同类型运动表征间的关联性,并利用记忆中存储的常规交通模式高级特征来增强运动表征,从而显著扩大异常特征的识别差异。在公开数据集上的实验结果表明,本方法较现有最先进方法实现了性能提升。
1.引言
然而,由于驾驶场景的动态特性源于车辆的快速移动,基于外观特征的方法通常难以检测涉及非本车车辆的交通异常——这类异常通常仅引发局部场景变化。此外,基于未来目标定位的方法通过预测场景中物体的位置来检测交通异常。这类方法侧重于物体的运动状态(即局部运动),这有助于识别涉及非本车车辆的交通异常(例如与远处车辆的碰撞),但这类方法忽略了驾驶场景的整体运动建模,导致其在检测涉及全局场景变化的交通异常时效果欠佳。因此,如何准确检测涉及本车(即本车车辆相关交通异常)和非本车(即观测到的物体相关交通异常)的异常,对驾驶视频中的交通异常检测(TAD)至关重要。此外,交通异常检测本质上是识别与常规交通模式不同的异常值。因此,建立常规交通模式模型并提升对异常模式的敏感度,对于实现精准的交通异常检测具有重要意义。
本研究提出通过融合光流重建与未来目标定位任务,实现全局与局部运动的综合建模。一方面,驾驶场景中的光流数据反映了车辆行驶时的全局运动特征,利用光流重建误差可有效检测涉及全局场景变化的交通异常。另一方面,未来目标定位聚焦于场景中物体的运动状态(即局部运动),有助于识别涉及局部场景变化的交通异常。此外,全局与局部运动之间存在相互关联性,主要基于以下原因:首先,全局运动本质上反映了驾驶车辆的自我运动特征,这有助于更精准地建模由场景中物体引发的局部运动;其次,局部运动提供了与驾驶场景局部动态相关的线索,可能提升全局运动特征描述的准确性。
鉴于上述光流重建和未来对象定位的独特优势,我们提出了一种新的记忆增强多任务协作框架(MAMTCF),用于驾驶视频中的无监督交通异常检测。首先,我们提出了一种无监督多任务协作框架,以全面建模驾驶场景中的全局和局部运动。与基于单一预文本任务的现有交通异常检测方法相比,我们的框架通过协作完成光流重建和未来对象定位任务,从而建模驾驶场景的全局和局部运动,有助于检测涉及自车和非自车的异常,实现显著的性能提升。此外,我们提出了一种记忆增强运动表示(MAMR)机制,以充分探索不同类型运动表示之间的相互关系,并利用存储在记忆中的正常交通模式的高级特征来重建运动表示。这扩大了与异常交通模式表示的区分度,使得交通异常更容易被检测。具体而言,在训练阶段, MAMTCF 被应用于训练光流重建和未来对象定位任务。在推理阶段,我们根据光流重建的误差和观察到的对象预测位置的方差,为驾驶视频帧获得一个异常分数。我们工作的主要贡献可以总结如下:
- 我们提出了一种新型多任务协作框架,用于无监督交通异常检测(TAD)。与以往基于单一预文本任务的TAD方法相比,我们的框架通过协同完成光流重建和未来目标定位任务,同时建模驾驶场景中的全局运动和局部运动。这种协作机制促进了对涉及自车和非自车异常的检测,显著提升了交通异常的检测效果。
- 我们进一步提出一种记忆增强的运动表征机制,通过利用记忆中存储的正常交通模式的高级特征,全面探索不同类型运动表征之间的相互关系并重构运动表征。这种重构的运动表征有助于增强与异常情况的差异性,从而有利于交通异常的检测。
- 该框架在两项已发表的大规模基准测试中实现了最先进的性能,为驾驶视频中的无监督交通异常检测提供了有前景的发展方向。
2.相关工作
2.1. 监视视频中的视频异常检测(VAD)
2.2. 行车记录仪视频中的交通异常检测(TAD)
2.3. 记忆网络
记忆模块在神经网络中[48,49]作为读写全局记忆的一种类型,最近受到了广泛关注。例如,Memformer[49]利用外部动态记忆来编码和检索过去的信息,以实现高效的序列建模。最近,一些研究[6,12,50]将记忆网络应用于监控视频中的 VAD 任务。例如,Park等人[50]提出使用具有更新方案的记忆模块,其中记忆中的条目记录了训练数据的正常模式。 𝐻𝐹2 - VAD [6]引入了记忆模块,用于存储光流重建的正常模式,以便通过重建误差敏感地识别异常事件。在本工作中,我们首次尝试探索一种记忆机制,以增强运动表示,用于驾驶视频中的交通异常检测。
3.提出的方法:MAMTCF
MAMTCF 模型的整体框架如图1所示。它主要由三个部分组成:(1) 特征提取模块,用于提取不同类型的运动表示;(2) 记忆增强运动表示(MAMR)机制,用于协作处理不同类型的运动表示并输出记忆增强的运动表示;(3) 多任务解码器,用于重建光流并预测物体未来的边界框。在推理阶段,重建误差和预测误差均用于交通异常检测。
在接下来的部分中,我们将首先介绍特征提取模块,然后是 MAMR 机制,接着是多任务解码器,最后展示如何使用我们的模型进行驾驶视频中的交通异常检测。

图1. 我们的 MAMTCF 算法框架。 MAMTCF 主要由特征提取模块、记忆增强运动表示(MAMR)机制和多任务解码器组成。
(1)首先,通过特征提取模块将驾驶视频帧的光流和场景中观察到的物体边界框编码为不同类型的运动表示;
(2)然后, MAMR 机制协同处理不同类型的运动表示,并输出记忆增强的运动表示;
(3)记忆增强的运动表示分别通过多任务解码器来重建光流和预测物体未来的边界框;
(4)最后,通过融合光流的重建误差和预测边界框的方差来获得异常分数。
3.1.特征提取
在驾驶场景中同时建模全局和局部运动,有助于检测涉及自我和非自我交通异常。在本研究中,我们首先应用特征提取模块来提取不同类型运动表征。如图1所示,我们主要提取两类输入的表征,即视频帧的光流和观测场景中物体的边界框。
实际上,视频帧的光流反映了驱动场景的整体运动。为了建模这种整体运动,我们将从帧 𝑡 到 𝑡 +1的光流表示定义为时间步 𝑡 的整体运动,可以表示为:
其中是光流编码器的参数,表示从帧 𝑡 到 𝑡 + 1 的光流,该光流由预训练的 FlowNet 2.0 [51] 获取。在我们的实验中,我们采用了与 𝐻𝐹2 - VAD [6] 中光流编码器相同的网络架构。
此外,场景中观测物体的边界框反映了物体的运动状态。因此,我们将观测场景中物体的运动状态定义为局部运动,其可表述为:
其中 表示位置编码器的参数。 表示在观察到的 𝑡 场景中 𝑁 个物体的边界框,这是通过预训练的 Mask- RCNN [52] 获得,然后使用 Deep-SORT [53] 算法进行跟踪。在我们的实验中,位置编码器由一个全连接层(FC)和一个门控循环神经网络(GRU)组成。此外,为了更好地感知物体的运动状态,我们进一步利用物体的光流来编码其当前的运动特征。具体来说,类似于 [10,16],我们使用感兴趣区域池化(RoIPool)操作和双线性插值从预计算的光流场中提取物体的运动特征。局部运动 可以如下更新:
其中 是多层感知机(MLP)的参数。在获得全局运动 和局部运动 后,我们的模型能够感知驾驶场景中的全局和局部运动,从而使我们的方法能够检测涉及自身和非自身交通异常。
3.2. 用于协作多任务的增强记忆的运动表征机制
通过结合不同类型的运动表征有助于检测各类交通异常。具体而言,关注驾驶场景全局变化的全局运动表征,能有效识别涉及驾驶者的异常;而侧重场景局部变化的局部运动表征,则更擅长检测非驾驶者相关的异常。直观来看,最简单的融合方式是将两种表征拼接后分别用于不同任务。但全局与局部运动表征之间存在内在关联:一方面,全局运动本质上反映了驾驶车辆的自身运动,有助于更精准地模拟场景中物体引发的局部运动;另一方面,局部运动提供了与场景动态相关的线索,可能提升全局运动表征的识别精度。此外,自编码器的泛化能力可能导致其学习到正常与异常交通的共性模式[12],从而模糊正常与异常运动表征的界限,导致异常检测漏检。因此,简单拼接不同运动表征并非明智策略,表5的实验结果也印证了这一点。
在我们的工作中,我们特别设计了一种记忆增强的运动表示(MAMR)机制用于交通异常检测。我们的机制利用注意力机制探索不同运动表示之间的相互关系,并进一步利用存储在记忆中的正常交通模式的高级特征来重建运动表示,从而提高对异常交通模式的敏感度。具体来说,如图2所示,我们的 MAMR 机制主要由一个运动间层和一个记忆增强的运动层组成。前者建模不同类型运动表示之间的相互关系,而后者则利用存储在记忆中的正常交通模式来重建运动表示,从而增加与异常情况的差异。
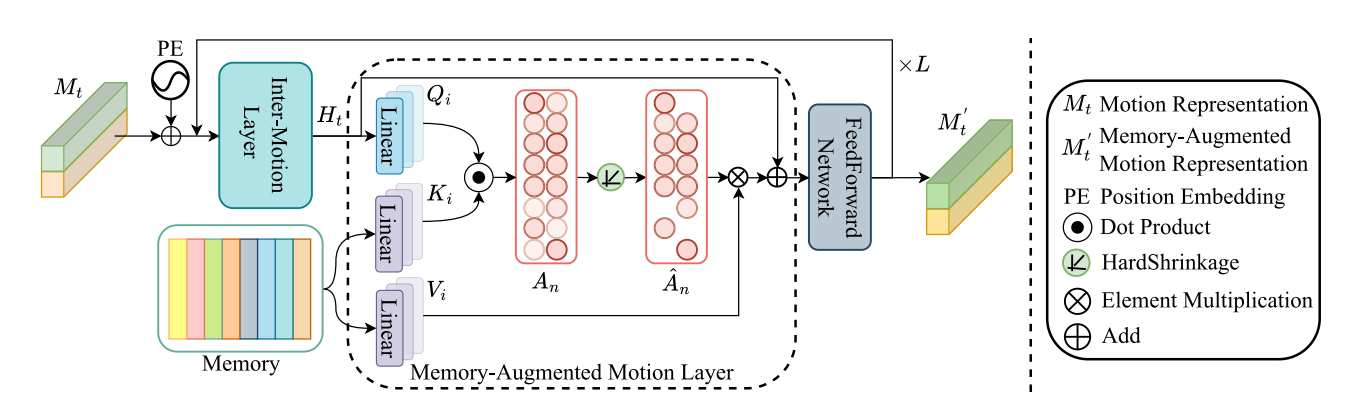
图2. 提出的 MAMR 机制示意图。 MAMR 机制主要由一个运动间层、一个记忆增强运动层和一个前馈网络组成。运动间层探索全局运动与局部运动之间的相互关系,而记忆增强运动层则检索存储在记忆中的正常交通模式的高级特征,并用正常交通模式重建运动表征。
3.3.1 交互运动层
为建立全局运动与局部运动的关联模型,我们首先设计了一个基于自注意力机制的运动交互层。具体而言,如图2所示,我们首先为全局运动和局部运动添加位置编码,以表征二者间的相对关系,其数学表达式可表述为:
其中 是全局运动和局部运动的拼接表示,表示广泛使用的硬编码位置嵌入策略 [54]。然后,我们应用自注意力机制来建模全局运动与局部运动之间的相互关系,其公式可以表示为:
其中, ,和 是的查询 ,键和值 对应的参数,表示多头自注意力, 𝐿𝑁(⋅)是层归一化, 𝐻𝑡 模型描述了全局运动与局部运动之间的相互关系。
3.2.2 增强记忆的运动层
为了提高对异常交通模式的敏感度,我们进一步设计了一个基于交叉注意力的记忆增强运动层。该层利用存储在记忆中的正常交通模式的高级特征来重建运动表征,从而提高对异常交通模式的敏感度。
具体来说,如图2所示,记忆被设计为一个矩阵,包含固定维度 𝐶 的正常交通模式高级特征的 𝑀 个槽位。需要注意的是,记忆在训练开始时是随机初始化的。对于每个输入,记忆增强运动层需要读取记忆以检索正常交通模式的相关高级特征。我们利用交叉注意力机制来实现这一功能:
其中记忆存储槽向量以参数和参数投影到键和值中,而 则以参数投影到查询中。 表示重构的运动表示。需要注意的是,为了使存储的正常交通模式的高级特征更具代表性,我们采用了文献 [12] 中的硬收缩操作,以促进记忆的稀疏性。
其中 是一个非常小的正标量, 𝑎𝑖 ∈ 𝐴𝑛 , 𝑖 ∈(1,𝑀), 𝜆 表示收缩阈值, 𝑅𝑒𝐿𝑈 是 ReLU 激活函数。硬收缩操作促使模型用更少但更相关的记忆项来重建 𝐻𝑡 ,从而促进学习更能代表正常交通模式的记忆中的高层次特征。此外,参考文献 [12],我们在训练过程中还对 进行稀疏正则化最小化,以促进记忆的稀疏性。
其中 𝑎𝑖 ∈ 𝐴𝑛 且 𝑖 ∈(1,𝑀)。
最后,我们在记忆增强运动层之后应用了一个前馈网络,其可以表述为:
其中 𝐹 𝐹 𝑁(⋅)是一个由两个全连接层组成的模块, 表示 𝐹 𝐹 𝑁(⋅)的参数, 𝑀𝑡 ′ 是增强记忆的运动表示。我们可以观察到,我们的 MAMR 机制不仅建模了不同类型运动表示之间的相互关系,还利用了正常交通模式的高级特征来重建运动表示,从而提高了我们框架对交通异常的敏感度。与文献 [6,12] 中提出的记忆网络不同,我们特别设计了一个运动间层来建模不同类型运动表示之间的相互关系,并提出了一种增强记忆的运动层,以自适应地从记忆中检索与输入运动表示相关的正常交通模式的高级特征。
3.3.用于交通异常检测的多任务解码器
在获得增强记忆的运动表征后,我们可轻松将其解码用于多项任务,如光流重建和未来目标定位。在推理阶段,基于多任务的重建误差和预测偏差,实施无监督TAD。
3.3.1.光流重建
如图1所示,我们利用多任务解码器来重建视频帧的光流,并预测场景中观察到的物体未来的边界框。具体来说,运动表示 𝑀𝑡 ′通过光流解码器来重建光流,这可以表述为:
其中 𝑆𝑝𝑙𝑖𝑡(⋅)表示 𝑀𝑡 ′ 的通道划分, 𝐹𝑡 ′ ,𝑋𝑡 ′ 分别表示增强记忆的全局运动和局部运动。 𝛩𝑓 是光流解码器 𝜙𝑑𝑒𝑐(⋅)的参数, 𝐼𝑡 ′ 表示重建的光流。在我们的实验中,我们使用了与 𝐻𝐹2 -VAD [6]. 中光流解码器相同的网络架构。需要注意的是,为了更好地重建光流,我们将解码器倒数第二层的卷积层替换为 SSPCAB 模块 [43]。该模块将基于重建的功能整合到自监督预测架构的构建块中,具体细节参见 [43]。
事实上,在驾驶场景中,移动速度是导致交通异常的重要因素之一。因此,在本研究中,我们不仅监督光流的一致性,还强调重构外观变化的一致性。重构光流的损失函数如下:
其中(𝐼𝑥 ,𝐼𝑦)= 𝐼𝑡 表示图像在 𝑥 和 𝑦 方向上的偏移量。公式(11)中的第一项 𝐿𝑚𝑜𝑡𝑖𝑜𝑛 强调了外观变化的一致性,而最后一项 𝐿𝑟𝑒𝑐𝑜𝑛 则监督重建的光流。
3.3.2.未来对象定位
对于未来的对象定位任务,如图3所示,我们利用位置解码器对运动表示 𝑀𝑡 ′进行循环解码,以得到对象的未来边界框,可以写成:
其中投影头 𝑔(⋅)由一个线性层和一个 ReLU 激活层组成,而 MLP 也由一个线性层和一个 ReLU 激活层组成。此外, 𝜉 ∗ 是可学习的参数, 𝑒0 初始值为零。 𝑌 1∶ 𝑁 𝑡 +1 表示在时间步 𝑡 + 1 时预测的对象边界框,其中 𝑡 的范围是从 𝑡 到 T-1。
此外,预测边界框的损失函数可定义为:
其中 𝑑(⋅)计算欧几里得距离。结合重构光流的损失函数 𝐿𝑓 和公式 (8) 中的稀疏性损失 𝐿𝑠 ,我们的最终损失函数表述为:
其中 𝜆1 、 𝜆2 和 𝜆3 是不同损失的系数。
3.3.3 交通异常检测
本节将阐述我们的多任务协作框架如何在推理阶段检测驾驶视频中的交通异常。
我们融合了基于不同类型运动一致性得出的交通异常评分。具体而言,我们分别计算了光流重建误差和预测边界框的方差,具体方法如下:
其中 𝑆𝑒 表示光流的重建误差, 𝑆𝑙 表示从时间 𝑡 −1 到 𝑡 −2 ,...,𝑡 − 𝛿 预测的时间 𝑡 的 𝛿 边框方差。 𝑆𝑒 关注驾驶场景的整体变化,有助于检测涉及自我的交通异常。𝑆𝑙 强调场景中的局部变化,这有助于检测非自我异常。请注意,我们通过 𝑆𝑇 𝐷(⋅)计算边界框左上角和右下角坐标(即 𝑏𝑏𝑜𝑥 = 𝑥𝑚𝑖𝑛 ,𝑦𝑚𝑖𝑛 ,𝑥𝑚𝑖𝑛 ,𝑦𝑚𝑖𝑛)的方差,并取其平均值作为该对象在时间 𝑡 的预测误差。由于场景中存在异常的物体具有相对较大的相应预测误差,因此我们取场景中最大预测误差作为该驾驶视频在时间 的异常分数。
此外,我们将重构误差 𝑆𝑒 与边界框方差 𝑆𝑙 融合,以获得最终的交通异常分数 𝑆𝑓 ,其公式可以表示为:
其中 𝑁𝑜𝑟𝑚(⋅)表示最大最小归一化, 𝛼 ∈ [0,1]表示融合系数。
5.结论
本文提出了一种新颖的记忆增强多任务协作框架,用于驾驶视频中无监督的交通异常检测。与以往基于单一预文本任务的TAD方法不同,我们的方法通过在光流重建和未来物体定位任务上协作,同时建模驾驶场景中的全局和局部运动,从而更好地检测涉及自我和非自我异常。此外,提出的 MAMR 机制充分探索了不同类型运动表征之间的相互关系,并利用存储在记忆中的正常交通模式的高级特征增强运动表征,从而扩大了与异常的区分度。两个大规模数据集上的定量和定性实验结果均表明,我们的方法在各种情况下具有优越性。