
DETECTIVE SAM:ADAPTIVE AI-IMAGE FORGERY LOCALIZATION
DETECTIVE SAM: ADAPTIVE AI-IMAGE FORGERY LOCALIZATION
Anonymous authors
Paper under double-blind review
ICLR 2026 rate: 6-6-6-4
摘要
在生成式AI时代,图像伪造检测面临全新挑战:现代编辑流程生成的逼真图像经过语义连贯的处理后,能规避传统检测手段,而模型能力也在飞速进化。为此,我们开发了基于SAM2框架的Detective SAM系统。SAM2作为图像分割基础模型,通过结合扰动驱动的取证线索、轻量级特征适配器和掩码适配器,实现自动提示将取证线索转化为伪造掩码。为应对扩散模型的快速迭代,我们推出AutoEditForge自动化编辑生成流程,涵盖四种编辑类型。该流程不仅提供高质量数据以维持新编辑器下的检测精度,还能持续优化Detective SAM。在七个基准数据集和七种基线模型的测试中,Detective SAM展现出稳定的离分布性能,平均交并比达到36.99/44.19 F1,较最优基线提升33.67%的交并比。此外,我们证明最先进的编辑会导致定位系统崩溃。当使用500个AutoEditForge样本时,Detective SAM能快速适应并恢复性能,使得随着编辑模型改进,检测系统可实现低摩擦度的实用更新。AutoEditForge、Detective SAM的预训练权重和训练脚本可在匿名存储库中获取: https://anonymous.4open.science/r/Detective-SAM-9057/.
1 引言
深度学习技术让逼真图像生成变得触手可及。现代模型生成的合成图像对人眼而言往往难以辨识(拉梅什等人,2021)。即便图像主体真实,针对性的编辑操作仍能篡改身份、伪造证据,甚至误导观众(卡达等人,2025)。随着虚拟环境中此类内容泛滥,识别图像篡改痕迹已成为当务之急。在现代局部编辑技术背景下,图像伪造定位(IFL)面临巨大挑战——那些细微逼真的增删操作常常能逃过人类感知。图1展示了来自纳米香蕉(Gemini 2.5 Flash Comanici等人,2025)的典型篡改案例及其预测结果。

传统图像流形框架(Legacy IFL)主要针对剪接和复制-移动操作(Kwon等,2021)。通过利用编辑检测和定位的特征信号——即法医线索,该框架能够识别跨图像合并和图像内重复。然而,包括DALL-E等扩散模型在内的现代生成器技术,使得传统线索和方法逐渐过时(Ramesh等,2022;Zhang等,2024)。传统IFL的设计原理依赖于相机或压缩产生的伪影,而现代生成模型由于其伪影源自生成过程,因此缺乏这些特征(Kwon等,2021;Guillaro等,2023)。最新扩散数据集揭示了显著的定位精度下降(Nguyen等,2024;Zhang等,2024);生成模型的快速发展形成了动态目标,需要持续更新的数据和训练。
由扩散模型引发的范式转变,推动了对更强有力的取证线索研究热潮。其中部分研究在无需训练(Ricker等,2024;Tsai等,2024a;He等,2024)和零样本(Cozzolino等,2024)方法上取得了实证成功,这些方法通过在基础模型的嵌入空间中引入显式扰动伪影来实现。图像基础模型通过大规模自监督学习(Dosovitskiy等,2021;Oquab等,2024)获取嵌入向量。此类嵌入向量揭示了扩散模型在遭遇高斯噪声或模糊等扰动时输出的分布偏移,为识别扩散编辑提供了强有力的取证线索。
近期发布的Segment Anything模型(SAM Kirillov等人,2023;SAM2 Ravi等人,2024)作为图像分割领域的专用基础模型,采用强大的大规模预训练编码器。该模型在下游任务中的表现尤为突出(Chen等人,2024),已成功应用于阴影与伪装检测(Jie和Zhang,2023;Meeran等人,2024)以及IFL。在IFL领域,SAM模型被重新定向用于伪造区域分割。目前SAM在IFL中的应用仍在不断拓展:现有方法(Kwon等人,2024;Zhang等人,2025)仍侧重传统伪造方法,而忽视了更具扩散特异性特征的线索。
当前IFL面临三个持久性问题:
1)现有方案普遍忽视现代编辑特征的法证线索,未能充分挖掘基础模型中蕴含的先验信息;
2)模型架构需支持实时整合新编辑数据,既能快速适应又可避免灾难性遗忘;
3)系统需在近期主流编辑器上保持高效,但实验数据表明新版本模型表现持续下滑,这表明需要持续更新训练和评估数据。
为此,我们提出Detective SAM框架——一个针对现代图像伪造检测(IFL)挑战的综合性解决方案。该框架基于两大核心突破:首先,通过大规模预训练的SAM2编码器可检测嵌入分布的偏移特征,将这种由扰动驱动的取证线索转化为SAM2的自动热图提示,有效解决问题1;其次,借助轻量级特征适配器(Chen等人,2024),将SAM2解码器从目标分割任务重新定向至伪造检测任务。在保持SAM2主干网络冻结不变的前提下,仅对自研模块进行训练,从而实现高效轻量级微调,支持新编辑器的持续迭代,完美解决问题2。图2直观展示了该架构与SAM2各模块间的交互关系。
最后,我们通过AutoEditForge直接实现挑战3,确保训练和评估数据始终保持最新。AutoEditForge是一个自动化流程,能够对真实图像进行类人本地生成式编辑,并通过替换、移除、添加和局部修改四种方法生成像素级精准的蒙版。该工具与Detective SAM形成协同效应:AutoEditForge持续提供新鲜的编辑后真实图像对,既支持评估又便于快速调整。
我们在生成式编辑领域对IFL的贡献如下:
SAM检测架构
我们在SAM2框架基础上扩展了图像伪造检测任务,具体包含:(i) 以扰动驱动的特征嵌入作为取证信号,(ii)专为伪造区域分割优化的轻量级适配器,以及(iii)可学习的提示模块——该模块通过将特征嵌入映射为热图提示,引导SAM2自动定位伪造区域。用于微调和评估的SAM检测器
AutoEditForge作为基于指令的本地编辑自动化流程(支持替换/删除/添加/局部修改),可随编辑器迭代保持数据同步,实现持续微调与性能评估。配合Detective SAM的轻量级适配器,该系统能在保留原有性能的同时,快速恢复新编辑器的IoU/F1等关键指标。综合评价方法
Detective SAM在七个基准数据集上进行了基准测试,提供了强大且稳定的分布外(OOD)结果,与最佳基线相比,平均 OOD IoU提高了33.67%。我们证明了定位器在最近的扩散编辑中会崩溃,需要持续的微调。
2 相关工作
图像伪造定位
图像伪造检测(IFL)不仅致力于检测图像是否被篡改,还能够逐像素精确定位篡改区域。要识别图像伪造,需要有效的信号或“取证线索”。这些线索/伪影可能包括重建误差(Vesnin 等,2024)、JPEG压缩伪影(Kwon 等,2021)、显性噪声伪影(Zhu 等,2024a)或隐性噪声伪影(Zhang 等,2025)。隐性噪声伪影是经过训练的网络,能从图像中提取特定伪影,例如Noiseprint(Cozzolino & Verdoliva ,2018; Guillaro 等,2023)。相比之下,显性噪声伪影无需重新训练即可处理扰动特征。
最新研究表明,基础模型的嵌入空间中存在明显的噪声伪影。Rigid(He 等人,2024)和BLUR(Tsai 等人,2024a)的研究表明,通过检测细微的嵌入分布偏移,无需训练即可利用DINOv2(Oquab 等人,2024)图像基础模型检测合成扩散模型图像。实证结果表明,显性伪影在扩散模型伪造的定位/检测中展现出应用前景。传统定位模型通常采用隐性噪声伪影来检测复制-移动和拼接伪造(Kwon 等人,2021; Liu 等人,2022; Guillaro 等人,2023),这些方法在传统伪造场景中效果良好,因为隐性噪声伪影能有效捕捉伪造源图像的压缩/相机伪影。随着SIDA(Huang 等人,2025)和FakeShield(Xu 等人,2025)等模型的出现,基于多模态大语言模型(MLLMs)的图像伪造检测新分支应运而生。这些方法利用扩散模型编辑的文本到图像特性进行伪造定位,并提供解释说明。
SAM在IFL中的应用
SAM在IFL中的改进方案已引发广泛关注(Kwon 等人,2024; Lai 等人,2023; Zhang 等人,2025)。这些方法通过训练SAM分割伪造区域,与传统目标分割任务形成对比,从而区分篡改区域与真实内容。例如,SAM被用于深度伪造定位(Lai 等人,2023)时采用重建误差信号,或在多源伪造分割中(Kwon 等人,2024)通过大规模对比预训练和固定16×16点网格实现。然而,基于扩散的篡改常表现为细微伪影和高度不规则区域。因此,我们需要可学习的提示词来动态适应基于扩散伪造的不可预测模式。IMDPrompter(Zhang 等人,2025)通过可学习的热图和框提示词实现这一目标,采用多种滤波器/视图作为信号。该技术既未使用显式扰动驱动信号,也未基于 Chen 等人(2024)的强SAM改进成果,而是重新训练SAM2的掩码解码器。 Chen 等人(2024)通过轻量级特征适配器微调,在伪装、阴影和医学图像分割中展现出稳健的下游性能。其他方法则直接利用SAM的分割能力,无需可学习提示词(Su 等人,2024)。
扩散数据集生成
IFL数据集的生成方式已从手动标注和编辑提示(Jia 等,2023)发展到使用众包工作者(Zhang 等,2024),目前则实现了全自动数据集生成(Huang 等,2025; Xu 等,2025)。这些全自动流程在替换、删除、添加和局部修改等多样化编辑操作上存在局限,且通常未采用最新的扩散模型。附录C对比了代表性流程。
3 Detective SAM
我们研究图像伪造检测任务,给定一个包含三个通道的RGB图像(高度H、宽度W),目标是预测一个二值掩码,其中Bij=1表示像素(i,j)被编辑/篡改,否则为0。本研究严格聚焦于基于扩散的图像编辑流程生成的篡改。扩散模型通过处理指令来生成源图像的局部篡改,如图1所示。保持篡改区域周围不变的方法包括覆盖掩码内的潜在变量,或仅在被掩码区域注入噪声(Wu等,2025;Lugmayr等,2022)。
3.1 总览
Detective SAM通过引入扰动驱动的特征流和轻量级适配器,对SAM2(Ravi等,2024)进行增强,同时保持其主干结构不变。特征适配器用于微调SAM2的解码器,而掩码适配器则对解码器进行提示。这种设计使解码器及其输入与伪造检测任务保持一致。该架构包含三个步骤:1. 生成扰动嵌入特征;2. 通过特征适配器将原始特征与扰动特征进行校正;3. 最后利用所有特征通过掩码适配器生成取证热图提示,具体步骤如图2所示。
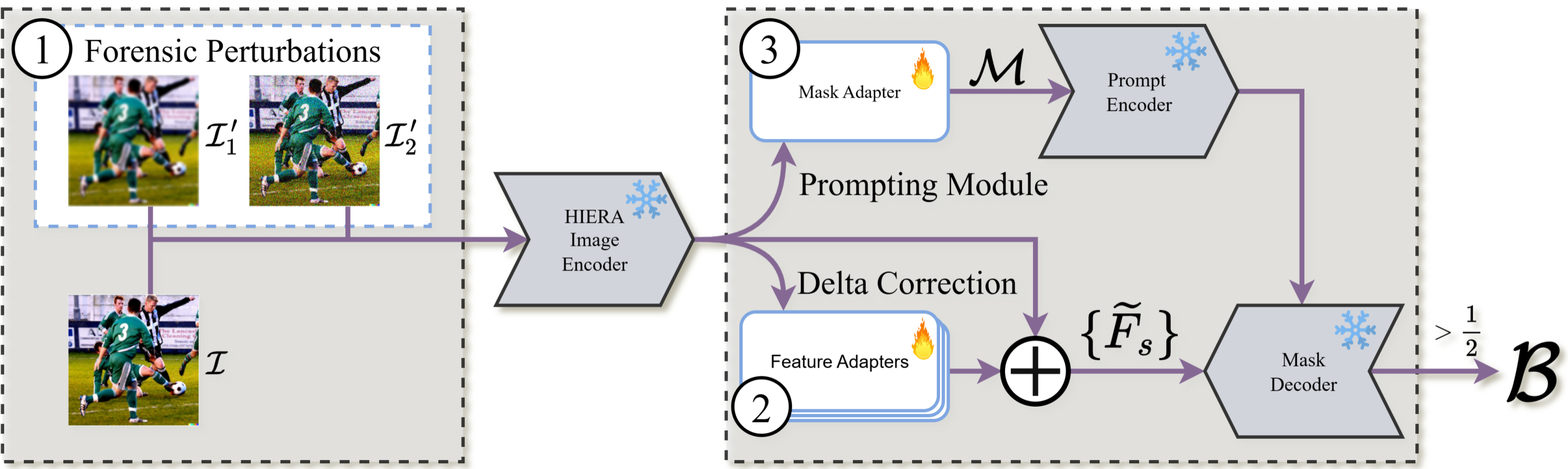
图2:Detective SAM的流程图,其中白色部分表示我们可学习的模块和流程,灰色部分表示SAM2的冻结模块。输入图像I、扰动图像、热图提示、自适应特征及二值伪造掩码B。原始SAM2组件的流程图详见附录B.2。
接下来我们将更详细地描述该过程,有关符号说明的概述请参见附录A。
3.2 模型体系结构
我们基于SAM2(Ravi等人,2024)构建模型,这是一个可提示的图像/视频分割器,其特征包括:hiera图像编码器(Ryali等人,2023)在三个空间尺度上生成嵌入向量,提示编码器用于处理点、框或热图,以及一个输入提示和多尺度特征的掩码解码器。SAM2的骨干网络(hiera编码器、提示编码器、掩码解码器)保持冻结。我们的轻量级适配器联合训练,结果包括:
(i)三个特征适配器(针对所有三个hiera尺度),它们将扰动后的图像嵌入向量作为法医线索,并执行∆Fs校正以输出适应后的特征;
(ii)一个掩码适配器,由自动提示网络组成,为解码器生成热图M。
特征适配器为单卷积层,而掩码适配器包含一个在降尺度嵌入空间中操作的变压器,以保持模型参数数量适中:层宽为64时,特征适配器使用81k参数,掩码适配器使用887k参数。这意味着该模型可以在 NVIDIA H100 GPU上用两小时完成训练。
输入和编码
作为第一步,我们为适配器模块构建了法医特征嵌入。给定输入图像,我们使用简单的图像空间操作符(例如高斯模糊、高斯噪声和JPEG压缩)生成N个扰动图像,其中扰动参数为 θ 。扩散模型在这种扰动下显示出嵌入偏移(He等,2024;Tsai等,2024b)。Detective SAM利用这些作为法医线索,以定位先验的形式。
和均由冻结的SAM2层级编码器(Ryali等人,2023)编码,生成嵌入向量,在层级尺度(S=32,64,128)上以分辨率输出。为匹配SAM2解码器预期的图像格式,我们采用SAM2的冻结无记忆(图像)嵌入进行填充(s=32),并使用SAM2的冻结卷积处理层处理s∈{64,128}。为简洁起见且不损失一般性,我们仅采用单一扰动,从而在不同层级生成六个特征嵌入向量。
特征适配器(delta校正)
接下来,我们使用经过取证扰动的特征嵌入对基础特征嵌入进行校正,使解码器专注于伪造物定位而非通用对象分割。我们通过轻量级特征适配器{As}实现这一目标,该适配器将基础特征与扰动特征拼接输入,生成残差增量校正。这些∆Fs校正通过残差连接用于调整未扰动特征,从而生成特征;
其中注入SAM2解码器的特征遵循Chen等人(2024)提出的架构。特征适配器采用单层1×1卷积网络,将冻结的SAM2解码器专门化为下游IFL任务,同时保持最小的开销。
Mask适配器(自动提示)。
通过专门针对IFL任务设计的解码器,我们用一个基于法医线索生成自动热图提示M的掩码适配器替换了SAM2的手动用户提示。这种提示可以是点、边界框或热图。我们选择热图是因为它能反映法医信号的空间结构。相比之下,基于点或框的提示大多忽略了这些信息。掩码适配器将所有特征映射到适合SAM解码器的热图提示M中。它接收所有特征,首先通过双线性上采样将它们转换到一个共同的精细网格 sˆ = max S。然后我们进行跨尺度、跨流的卷积融合,以获得统一的特征张量。这种融合在空间上与HRNet(Wang等,2020)一致,并且由于浅层跨尺度混合而轻量级。
为了确保全局一致性,我们在粗分辨率下使用了一个轻量级的transformer;其自注意力机制聚合了补丁标记之间的上下文,并抑制空间不一致的伪造估计,具体示例见附录B.3。以输入为例,transformer在降采样、补丁化的表示上操作,生成低分辨率的粗略逻辑值和不确定性逻辑值图 。其中,降采样因子被视为超参数。两者均被重新上采样回通用网格 sˆ ,得到 和。
恢复精细边界需要将高层次上下文与局部细节结合;我们通过线性空间门控混合上下文来实现这一点,如(Chen等,2016)所述。我们通过两层卷积网络从Ffuse生成精细逻辑值。最后,我们应用空间门 在线性混合精细和粗略预测到解码器掩码中:
g门是一个1 × 1卷积层,后接一个Sigmoid函数,输入[Lcoarse,U],在粗略掩码自信(或不确定)的区域降低精细度,防止未编辑区域过度锐化,同时允许在需要时进行细节修正。
Mask解码器
在解码之前,我们将热图提示M和适应性特征{Fes}进行双线性上采样至256×256,以生成更精细的掩模,并将其输入冻结的SAM2掩模解码器以获得256×256的伪造概率 Mˆ 。我们选择256×256是因为它接近我们数据中的最小图像分辨率,这有助于避免最终二进制掩模中出现极端的外推伪影。最后,严格遵循SAM2的方法,我们将 Mˆ 进行双线性上采样至图像分辨率,并通过Sigmoid操作将其转换为概率图: σ(Mˆ)。最终的伪造二进制掩模为B = 1{ σ(Mˆ)>= 1/2 }。
损失函数
训练掩码和特征适配器遵循SAM2的目标(Chen等,2024),结合了焦点损失(Lin等,2018)、Dice损失和IoU损失。Dice损失通过惩罚预测掩码与真实掩码的归一化差异,最大化两者之间的重叠区域。焦点损失进一步解决了信息伪造任务(IFL)中的类别不平衡问题。IoU损失通过伪造掩码的L1损失训练SAM2的IoU预测头。所有损失函数均以真实掩码和模型预测掩码作为输入,预测掩码仅基于篡改后的图像计算得出。正式而言,我们的最终目标是
聚焦参数 γ >= 0 降低了分类良好的样本的权重。平衡因子 α ∈ [0,1] 重新加权正负样本以对抗类别不平衡。我们借鉴了 SAM2 论文(Ravi 等,2024)中的 λfocal = 20,λIoU = 1 并扫描(α ,γ)。
3.3 AUTOEDITFORGE: 由 AI 驱动的自动编辑为Detective SAM 加油
为了应对伪造定位模型中高质量、最新测试和微调数据的严重短缺,我们引入了AutoEditForge,这是一种用于持续改进图像伪造鲁棒性的新型自动化基础设施。这个完全自动化的流程生成具有像素级精确分割掩码的真实图像编辑。与现有的合成数据集不同,这些数据集要么受限于劳动密集型的手动标注而影响规模,要么通过简单的修复技术牺牲真实感(Kwon等,2024),AutoEditForge利用最先进的(SOTA)扩散模型来模拟人类风格编辑的多样性,从而实现持续评估和微调。AutoEditForge采用两阶段架构,将轻量级分析与计算密集型编辑操作分离,从而实现大规模图像批次的高效处理。
第一阶段:分析与决策。
第二阶段:图像分割与图像修复。
Detective SAM 和AutoEditForge
AutoEditForge持续输出基于最新生成式编辑模型的逼真指令引导编辑流。Detective SAM通过适配器微调技术吸收这些编辑流,将冻结的SAM2解码器及其提示与当前编辑技术分布相匹配。由此形成实用的终身学习循环:在新编辑中评估效果、发现错误、微调适配器并重新部署,同时保持主干架构固定,确保在不断演进的编辑器和指令中保持稳健性。
4 实验
训练规范说明
Detective SAM模型基于10k个SIDA样本(Huang等人,2025)和全部8,807个MagicBrush训练样本(Zhang等人,2024)进行训练。我们在CoCoGLIDE、UltraEdit(Zhao等人,2024)、AutoSplice(Jia等人,2023)和NanoBanana(Comanici等人,2025)上进行OOD测试,其中NanoBanana是通过AutoEditForge生成的。所有数据集均经过扩散编辑处理,完整细节参见附录G。Detective SAMSOT A模型在500个FLUX-Bench(Labs等人,2025)和QWEN-Bench(Wu等人,2025)样本(总计1,000个,均通过AutoEditForge生成)上进行微调。因此,CoCoGLIDE、AutoSplice和NanoBanana始终处于完全OOD状态。噪声强度在六个数值范围内进行调整,具体数值取决于噪声类型。其他超参数则按照附录H所述方法进行网格化调参。
测试设置
我们的结果分为三个阶段:
(1) 域内(ID):在训练集的样本外测试集上进行测试。
(2) 域外(OOD):在完全未见过的测试集上进行测试,以公平地与基线方法进行比较。
(3) 微调:在各自数据集的500个样本上对预训练的Detective SAM进行微调,以评估适应效率。
微调
Detective SAM 的微调采用直接重放技术(Zhou 等,2024)。我们通过将20%的原始MagicBrush和SIDA训练数据与新的AutoEditForge样本混合,以缓解灾难性遗忘。损失函数保持不变,验证则在重放数据与微调数据的混合验证集上进行。
评估指标
性能评估采用像素级平均交并比(IoU)和平均F1分数。IoU用于衡量真实伪造掩模与B之间的重叠程度,F1分数则作为像素级精确率与召回率的调和平均值。详见附录E.1。
基准测试
本研究将SAM检测器的伪造检测性能与近期多项基准模型进行对比评估,包括:SAFIRE (Kwon et al., 2024)、Mesorch (Zhu et al., 2024b)、TruFor(Guillaro et al., 2023)、AdaIFL (Li et al., 2025)、PSCC-Net (Liu et al., 2022),以及MLLM定位模型SIDA-7B (Huang et al., 2025)和FakeShield (Xu et al., 2025)。各模型的总参数量和单次推理计算量差异显著:SIDA-7B拥有70亿参数,FakeShield达到230亿,SAFIRE则采用256个并行SAM推理单元处理每个样本。所有推理均在单个NVIDIA H100 GPU上完成,各模型的吞吐量详见附录F.6。为确保公平性,性能评估仅采用OOD分数作为评判标准。
4.1结果
我们将结果分为两部分呈现。首先展示DetectiveSAM与基线模型在 OOD 数据集上的表现;其次展示在更具挑战性的AutoEditForge前沿数据集上的结果,以凸显性能的显著下降及DetectiveSAM的高效微调。
与最先进(SOTA)方法的对比
表1对比了基线模型与Detective SAM的性能表现。
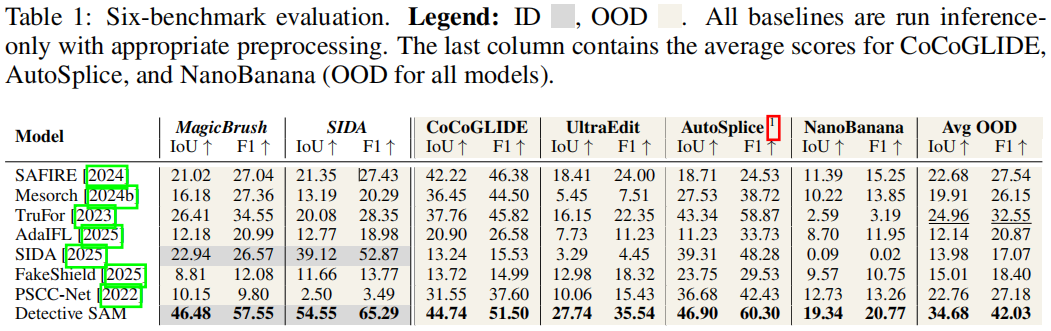
在四个 OOD 数据集(CoCoGLIDE、UltraEdit、AutoSplice、NanoBanana)上,Detective SAM显著优于基线模型。我们注意到多个基线模型在特定数据集上表现突出;例如 SAFIRE 在CoCoGLIDE上的F1分数达到46.38,但在其他所有数据集上的表现均显著下降。因此,我们还展示了四个 OOD 数据集的平均IoU和F1分数。表1显示TruFor是表现最强的平均基线模型。所有模型在我们最新的扩散模型数据集NanoBanana上均出现显著性能下降。表1中仅有两行数据为ID,其余均为 OOD ,这反映了预期操作场景,更能体现实际可靠性。
我们特别强调Detective SAM的泛化性能。尽管大多数模型在不同数据集上的分数不稳定,但Detective SAM在分布内和分布外的分数表现相似,并且具有最高的 OOD 分数(IoU=34.68,F1=42.03)。需注意TruFor和 SAFIRE 报告了另一种F1分数计算方法;有关可比性的更多信息,请参阅附录E.2。
可视化结果
图3展示了各基线模型和DetectiveSAM的掩码预测结果。

图3:所有模型与数据集的定性结果概览。每行对应一个数据集样本,每列分别对应原始图像、篡改图像、真实掩码及各模型预测的掩码。对于SIDA模型,原始图像与篡改图像的数值相等,因测试集中未提供(原始/篡改)配对数据。
我们观察到不同数据集间结果存在不一致性,多个模型将 SOTA 图像误判为真实图像(黑色掩码),同时正确识别了传统样本(AutoSplice、CoCoGLIDE)。附录F.5中提供了各数据集的若干低IoU(交并比)DetectiveSAM失败案例。
模型崩溃与微调
我们在 SOTA AutoEditForge数据集上评估了Detective SAM的性能,并分析了其轻量级微调策略。表2展示了我们创建的 SOTA 数据集FLUX-Bench、 QWEN -Bench和NanoBanana的评分结果。
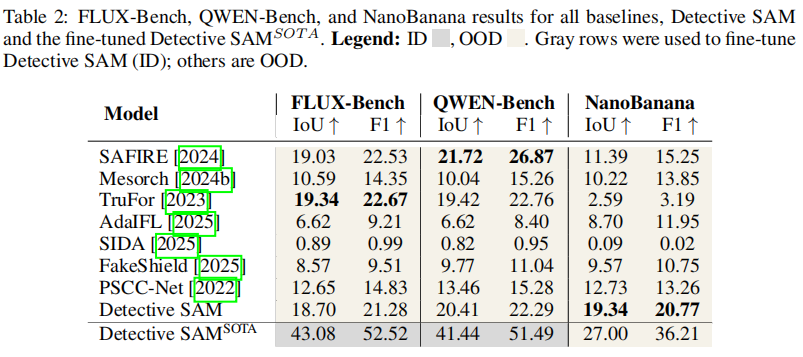
整体来看,所有模型的性能均出现下滑。 SAFIRE 在 QWEN -Bench中表现突出,而Detective SAM在所有 SOTA 数据集2上均保持稳定表现。
尽管在现有基准测试中表现优异常被视为IFL泛化能力的证明,但本研究结果表明,这种优势并未延续到 SOTA 扩散式编辑中,即所有评估的检测器均未有效泛化,且均出现显著性能下降。这凸显了对系统进行周期性适配的必要性,例如随着功能更强大的模型发布,需定期进行微调。
由于SAM2的主干权重被冻结,且我们的适配器轻量级,Detective SAM非常适合高效微调。我们在FLUX-Bench和 QWEN -Bench(非NanoBanana)的500个样本上对Detective SAM进行微调,生成了表2最后一行所示的Detective SAMSOT A。微调后,Detective SAM在FLUX-Bench和 QWEN -Bench数据集上的表现均有所恢复,IoU值分别为43.08和41.44。需注意这些数据集现已成为Detective SAMSOT A的ID,因此无法直接与表2中的基线结果进行比较。Detective SAMSOT A的平均 OOD 性能提升至IoU 35.57和F1 45.62。这归因于接触最新FLUX和 QWEN 数据后,NanoBanana的性能显著提升。完整评分详见附录F.3.1。
最后,我们在不同样本量(含/不含重放)条件下对Detective SAMSOTA进行微调。如附录F.3.4图13a所示,由于样本量有限导致过拟合, OOD 性能出现初期下降。随着样本量增加,ID和 OOD 性能得以保持,同时微调分数持续提升。图13b中ID性能下降及 OOD 分数降低的现象,清晰印证了重放的重要性。
编辑方法的影响
附录F.4展示了不同编辑方法的平均IoU值。其中替换与移除方法的差距最为显著:在 QWEN -Bench测试中,替换方法的IoU值为22.95,而移除方法仅为10.58,差异高达116.92%;在FLUXBench测试中,替换方法的IoU值为17.61,而移除方法仅为9.31,差异达89.15%。这表明 SOTA 数据集需要比单纯图像修复更多样化的编辑方法,否则像移除这类方法在实际场景中将难以被检测到。
外部干扰的影响
附录F.2展示了对图像进行高斯模糊、高斯噪声和JPEG压缩预处理后的影响。通过分析图表可以发现,Detective SAM对高斯模糊和噪声具有较强的鲁棒性。这些正是法医取证中常用的干扰类型。这说明输入数据中添加的外部噪声对两种处理流的影响相似,且两者间的差异仍具有重要参考价值。在JPEG压缩鲁棒性方面,Detective SAM的表现与基准方法基本持平。
4.2 消融研究
所有消融实验均在我们训练集的SIDA和MagicBrush数据集及其验证分割集上进行,且SAM2数据集保持冻结状态,采用相同的训练/调优协议。
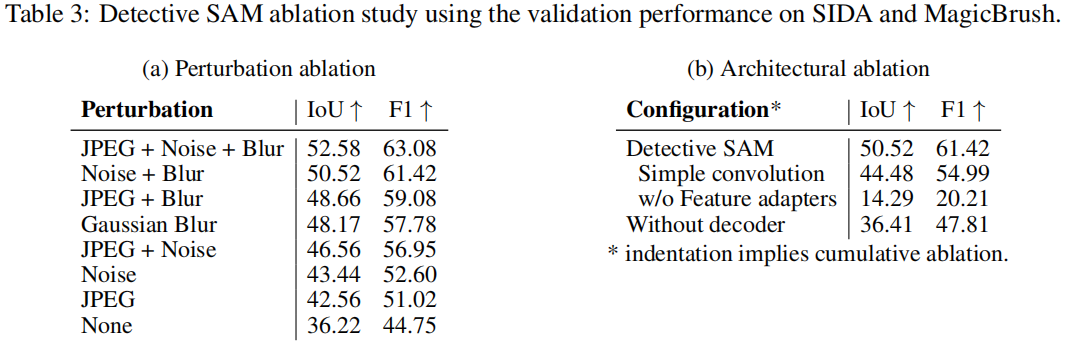
扰动类型的影响
表3a显示扰动类型对定位性能具有显著影响。我们注意到高斯模糊效果良好,而高斯噪声与模糊的组合表现略胜一筹。这与Minder(Tsai 等人,2024b)的研究结论一致,该研究通过结合两种类型来提升图像伪造定位性能。然而,加入JPEG格式进一步提升了性能,这证明了显式扰动信号的实际优势。本文采用高斯模糊与噪声的组合,与先前研究结果保持一致。
掩码适配器设计
分析表3b可见,相较于简单的卷积网络,我们更复杂的架构(降尺度变换器、不确定性机制和空间门控,详见第3.2节)显著提升了验证性能。特征适配器通过使取证嵌入能够利用SAM2解码器的图像先验进行伪造定位,带来了最大性能提升。
掩码解码器的影响
我们直接使用来自掩码适配器的热力图训练Detective SAM进行定位,未使用SAM2解码器。如表3b最后一行所示,未使用掩码解码器时性能显著下降,这表明利用SAM2解码器训练中包含的信息具有重要价值。
噪声强度的影响
扰动的噪声强度选择为在六个数值范围内验证性能最高的值。高斯噪声与模糊组合的最佳性能强度绘制于附录F.1中。
5 结论
Detective SAM在基于扩散的伪造检测领域取得突破性进展,其平均分布外交集(IoU)值达到36.99,较传统分布外基线方法提升33.67%,且在三个测试集上均表现优异。研究证实,当存在强显式扰动法取证信号时,基于扩散的伪造检测系统(IFL)凭借其稳健的分割框架展现出更优性能。此外,持续微调的有效性已被确立为新型扩散编辑器发展的必要前提,而AutoEditForge系统正是这一过程的有力推动者。
局限性
我们依赖扰动驱动的线索,这使得模型性能对特定线索和扰动强度都存在敏感性。后续研究应重点探索自适应扰动技术。传统复制-移动和剪接伪造技术不会产生类似的扩散敏感伪影,因此需要采用不同的信号特征和更广泛的训练数据进行验证。一个可快速部署的模型应当通过在完全合成图像和真实图像上进行训练,以降低误判率。
通过阐明这些关键步骤,我们旨在推动增量式学习(IFL)领域的发展,使其与不断演进的生成式编辑工具保持同步。
可重复性声明
为确保研究结果的可复现性,我们将在匿名存储库https://anonymous.4open.science/r/Detective-SAM-9057/上开源AutoEditForge代码、Detective SAM训练模型及预训练权重。NanoBanana、QWEN-Bench和FLUX-Bench数据集将在通过审核后发布。该模型可在单个NVIDIA H100 GPU上训练。本文涉及的其他数据集(MagicBrush Zhang等人(2024)、SIDA Huang等人(2025)、AutoSplice Jia等人(2023)、CoCoGLIDE)及基线模型(SAFIRE Kwon等人(2024)、Mesorch Zhu等人(2024b)、TruFor Guillaro等人(2023)、AdaIFL Li等人(2025)、FakeShield Xu等人(2025)、PSCC-Net Liu等人(2022))均已公开获取。
伦理声明
SAM检测系统专为法医定位基于扩散的编辑而设计,旨在支持溯源研究与平台完整性验证,其输出结果应视为概率性证据,需接受人工监督。该系统具有双重用途:攻击者可能利用系统故障模式,或误判可能损害利益相关方。因此,我们建议采用AutoEditforge进行模型验证,并配合人工复核。系统在公共数据集和AutoEditForge编辑数据上进行训练与评估;不收集新个人数据,并将严格遵守下架请求。在人工智能应用方面,大型语言模型用于写作辅助和代码补全;所有创意与分析均为自主研发。