
Image splicing forgery detection:A review
Image splicing forgery detection: A review
Ritesh Kumari1· Hitendra Garg1
摘要
图像拼接伪造是数字图像处理中常见的一种手法,通过将一张或多张图像的不同部分进行拼接,生成看似真实的欺骗性图像。检测图像拼接伪造对于验证图像真实性至关重要。近年来图像拼接伪造检测技术发展迅速,学术界提出了多种检测方法。本文对2014至2023年间现有图像拼接伪造检测方法进行系统综述与分类研究,重点分析了88篇关于图像伪造检测背景下拼接技术的研究论文。文章构建了通用检测框架,梳理了典型检测流程的各个阶段,全面梳理了研究人员提出的手工设计与先进检测方法,并通过基准数据集分析揭示其局限性。本研究旨在为该领域的科研人员和从业者提供清晰透彻的图像拼接伪造检测认知框架,为行业现状分析与未来研究方向提供重要参考依据。
关键词 图像伪造检测 · 图像取证 · 拼接 · 假新闻 · 深度学习 · CNN
1.引言
互联网和社交媒体充斥着海量图像。从脸书、推特到Instagram,数百万张图片在社交平台间流转,其中部分可能传播虚假信息。图像篡改行为出于恶意目的,通过影响个人兴趣和设计风格来在社会中散布假新闻。这类虚假信息在选举等重大事件期间引发公众焦虑,深刻影响民众心理。让我们通过真实案例来了解拼接图像的影响。2011年,印度总理曼莫汉·辛格博士与美国总统巴拉克·奥巴马在东盟峰会上会晤。然而数年后,如图2(g)所示的拼接图像在推特上流传,画面中奥巴马与伊朗总统哈桑·鲁哈尼握手[1]。该拼接图像在2020年美国大选期间被恶意传播至互联网。因此,识别拼接图像并阻止其在线传播至关重要。

图2展示了对原始图像2(a)[1]进行的多种图像伪造方法:(a)原始图像,(b)水印处理,(c)图像修饰,(d)重采样处理,(e)图像压缩,(f)复制粘贴技术,(g)由第一、第二原始图像拼接而成的第三种拼接图像。
然而,目前存在多种图像处理方法。这些方法包括图像修图、图像压缩、复制粘贴、图像拼接、去除水印或数字签名等。其中,图像拼接技术因其可能彻底篡改图像信息或内容而备受关注。因此,图像伪造检测始终是学者们研究的重点领域,尤其是复制粘贴与图像拼接技术。图像拼接是一种伪造手段,通过将一张或多张图像的特定部分进行组合,最终生成新的图像。
以下列举了当前关于图像伪造与检测的若干调查研究及综述文献,可见大多数研究都将图像拼接作为其研究子领域[2,3]。[4]对图像伪造方案进行了详细分类,重点探讨了预处理步骤、相机特性异常、光学与传感器运行机制以及其他统计特征。另一篇综述中,M. A. Qureshi and M. Deriche[5]讨论了基于像素的拼接检测、复制移动伪造、图像采样及修图等检测方法,同时涵盖了中值滤波、锐化处理、对比度优化及噪声检测等后处理技术。其他研究[6-9]则对现有图像伪造检测方法进行了多维度对比分析。文献[7]深入探讨了篡改检测技术的四大主要类别:图像拼接、复制移动伪造、图像重采样及图像修图检测。此外,被动图像伪造检测被细分为两类:基于源相机识别的伪造与基于图像修饰的伪造[8]。Interpol于2020年发布的法医图像与视频分析研究报告[10]主要涵盖2016-2019年间影像与视频伪造领域的学术文献。文献[11]则系统评述了针对拼接与复制移动伪造的多种检测算法,包括基于强度特征、基于特征降维及基于关键特征的算法体系。该研究还为卷积神经网络(CNN)的未来发展方向提供了指导,并强调了现有解决方案方法的局限性。
深度伪造技术是基于人工智能设计的伪造手段。这类技术通过采集人体动作、面部特征乃至语音模式等数据,利用人工智能编码的生成对抗网络(GAN)进行处理,从而生成逼真度极高的虚假视听内容。通常而言,深度伪造技术更侧重于面部替换而非肢体动作或姿态模拟。关于伪造检测的深度学习方法研究进展详见文献[12],其中涵盖卷积神经网络(CNN)、Visual Geometry Group(VGG)、残差网络(ResNet)、生成对抗网络(GAN)、U型编码器-解码器网络(Unet)等网络架构(相关内容将在第3.2节详细讨论)。文献[13]则从伪造类型分类、图像伪造检测方法对比等多个维度展开论述,同时对基于深度学习的伪造检测技术进行了系统性综述与分析。
然而,上述综述论文的研究成果将图像拼接作为图像伪造检测的子主题进行探讨,部分文献亦列于表1。

因此,本研究聚焦图像拼接检测领域的最新进展,并对现有拼接检测解决方案方法进行了层次化分类。过去十年间发表的论文数量充分体现了学者与青年研究者的浓厚兴趣。本研究整合并呈现了近十年来关于拼接检测领域几乎所有现有方法的研究成果。图1展示了过去十年间施普林格、IEEE和爱思唯尔期刊上发表的拼接检测相关论文总数。需要特别说明的是,在检索查询及文献分析中,“伪造”、“篡改”、“操纵”和“假造”等术语具有相似含义。图1中的图表揭示了该领域当前研究的两大特征:其一,该课题正成为学者关注的热点;其二,该领域仍存在巨大的改进空间。统计数据显示,期刊论文与会议论文的发表数量存在显著差距。
1.1 论文贡献与结构
上文已对若干现有综述论文进行讨论,这些文献明确指出存在将拼接过程及其检测方法进行独立研究的潜在空间。因此,本研究对2014年至2023年间关于拼接检测的现有研究进行了全面综述,分析了当前方法及最新进展,旨在解决以下关键问题:
- 本研究首次对图像拼接伪造检测技术进行系统综述(据作者所知)。
- 通过全面梳理88篇研究论文,本研究明确了拼接检测领域的传统方法与前沿技术。
- 同时对现有所有数据集进行了详细统计,列明其特征与局限性。
本文对现有文献进行了全面综述,并深入探讨了在实施拼接检测通用结构过程中所面临的挑战。该研究为对该领域感兴趣的研究人员和实践者提供了宝贵资源,有助于推动拼接检测技术的进一步发展。总体而言,本综述试图解答与图像拼接伪造检测相关的一些重要问题,具体如下:
- 问题1:哪种手工方法对拼接位点定位最具有效性?
- 问题2:哪种深度学习方法对拼接位点定位最具有效性?
- 问题3:哪种分类器对拼接图像分类最具有效性?
- 问题4:哪个数据集适用于拼接分析?
- 问题5:评估指标应选择何种参数?
本文其余部分结构安排如下:第二章通过典型案例介绍图像伪造技术及其分类;第三章阐述图像拼接检测流程,并将检测技术划分为手工设计方法与先进深度学习技术两大类,同时整合了多种基于特征的伪造检测方法;第四章详细说明可用于拼接检测的数据集信息;第五章从基于区块分析、关键特征识别及机器学习方法三大维度,系统梳理当前主流解决方案的分类体系,并分析其在应对高级威胁时存在的局限性;第六章对研究进行总结;第七章则聚焦未来研究方向与新兴挑战。
2.图像伪造:类型与检测技术
本节通过典型案例分析各类图像伪造形式,但重点仅聚焦图像拼接技术,着重解析其与其他伪造形式的区别,并深入探讨其在图像中的定位基础原理。图像伪造是指通过篡改数字图像以欺骗或误导观众的行为,涉及对图像进行未经授权的修改以构建虚假现实表征。其表现形式多样,包括:通过整合不同图像元素生成增强型新图像(即图像修饰)、在同一图像内克隆或复制物体、删除图像中物体或人物、以及从原始图像中移除水印等。图像伪造技术可大致分为主动式与被动式两种方法[2]。图2展示了多种图像伪造技术的应用实例,通过将不同伪造手法应用于同一图像进行对比分析,有助于深入理解其运作机制。
2.1 主动伪造方法
该技术需在图像上线流通前,将其嵌入唯一密钥。这种预置密钥或代码可作为验证图像真实性的手段。但该技术仅对首次在线流通的图像有效。主动伪造行为可进一步分为以下两种方法。
a) 数字水印技术:水印技术是指在数字媒体(包括音频、视频或图像)中嵌入标识符,如图2(b)所示。其核心作用在于确认内容的版权归属。数字水印技术被广泛应用于追踪网络版权侵权行为,以及验证银行系统中纸币的真实性。这类水印可分为可见式与隐蔽式两种类型。
b) 数字签名:数字签名并非简单的数字化证书,而是通过数学技术验证数字文档的真实性和完整性。与包含用户姓名的传统签名不同,数字签名由两组独立密钥(发送方私钥与接收方公钥)或字符序列构成,并采用加密技术对消息或文档内容进行安全保护。
2.2 被动伪造方法
被动伪造技术是指无需预先信息或特定密钥即可完成验证的技术手段。其重要性在于,仅有2%至5%的图像需要通过此类密钥进行主动防护。随着深度伪造技术等数字图像伪造手段的不断进步,识别图像篡改痕迹的难度与日俱增。因此,即便未采取主动防护措施,被动图像伪造技术仍是检测和应对图像篡改的关键手段。
a) 图像修图:指通过增强数字图像质量、修正瑕疵使其呈现更佳视觉效果的技术。该技术广泛应用于摄影、广告、时尚领域,以及Facebook、Instagram等对图像呈现要求较高的社交媒体平台。不过修图通常被视为非专业级图像处理手段,因其包含色彩校正、图像修复、背景增强及皮肤柔化等操作。图2(c)所示为经过修图处理的图像,原始背景中的恒星已被移除。
b)图像重采样:重采样技术通过调整图像像素尺寸实现,如图2(d)所示,可通过增加或减少像素总数来改变图像结构。该技术主要应用于屏幕显示场景,需注意重采样必然导致图像质量下降。需明确区分重采样与图像缩放:后者仅涉及打印尺寸调整,而前者则涉及分辨率改变。
c)图像压缩:压缩技术旨在减小图像文件体积,如图2(e)所示,通常通过剔除冗余数据实现。但过度压缩会导致图像质量显著下降,常见现象包括像素失真、色彩饱和度降低及细节信息丢失。当经过处理的图像多次进行JPEG压缩时,由于压缩伪影的叠加效应[14],检测图像篡改痕迹将变得极具挑战性。
d) 复制粘贴:复制粘贴式图像伪造属于图像篡改手段,其核心是将图像局部内容复制并粘贴至同一图像中。这种操作通常会导致图像内出现重复对象或元素,但需注意复制部分的伪影特征可能与原图存在差异[15,16]。图2(f)所示图像即属此类复制粘贴案例,其中背景区域复制了原始图像中的星形标记。
e) 拼接技术:拼接伪造是指通过复制粘贴单张或多张图像片段来生成全新图像的伪造手法。作为最具破坏性的伪造手段之一,该技术能在保持整体视觉效果的同时隐藏或移除特定对象,其核心原理在于通过剪切粘贴与图像融合技术,创造出看似真实实则属伪造的图像。因此该技术被称为“剪切粘贴式伪造”,其操作过程涉及将图像局部内容复制并粘贴至另一图像上。图2(g)是图像拼接的典型示例,其中将前两张原始图像[1,17]的部分内容粘合在一起,生成了一幅新的但虚假的拼接图像。
2.3 为何图像拼接技术更具挑战性?
- 图像修图、重采样、压缩及水印处理等操作通常作用于整幅图像,而拼接与复制粘贴技术则针对局部区域进行处理。
- 拼接技术通过整合多幅图像元素构建新画面,复制粘贴伪造技术则涉及同一图像内区域的复制粘贴操作。
- 拼接技术旨在构建具有欺骗性但真实感的场景表现,而复制粘贴伪造技术往往通过重复或添加冗余元素来实现图像篡改。
当相机拍摄图像时,会经历如图3所示的图像采集流程。
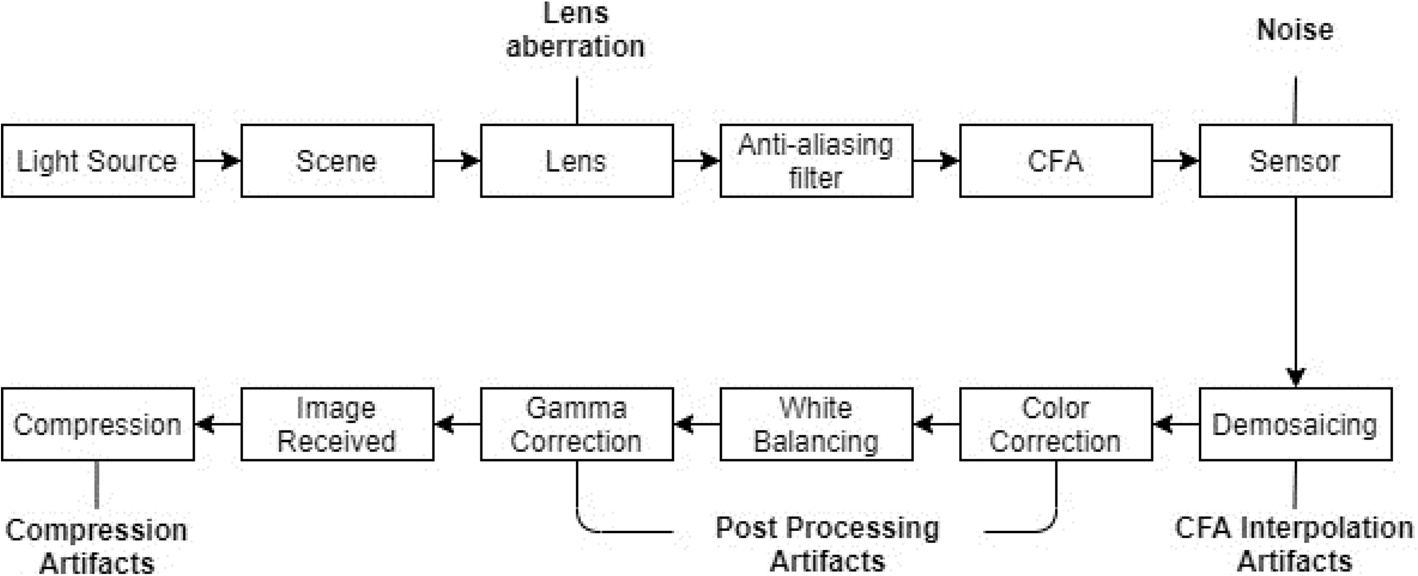
图3 图像生命周期的若干步骤及相应伪影
首先,光源照亮被摄物体,被照亮的物体反射出包含视觉信息的光线。镜头将光线引导至传感器,数码相机则在传感器上方设置彩色滤光片阵列来捕捉RGB色彩信息。传感器通过检测像素的光强来获取颜色数据,通常通过分析不同滤光片覆盖的相邻像素来推断色彩。原始传感器数据需经过去马赛克处理,此时插值算法会填补缺失的色彩细节,生成完整的RGB图像。随后进行色彩校正,调整图像色调以还原原始场景的真实效果。最后通过伽马校正优化亮度参数,使图像在视觉上更加自然协调。
在整个图像处理过程中,图像会保留某些固有特征或伪影(如图3所示),例如由镜头微小缺陷导致的像差、传感器制造误差引发的插值噪声、因校正操作产生的后处理伪影以及有损压缩伪影。这些伪影在真实图像中表现稳定,但在经过处理的图像中则呈现不一致性。通过检测此类特征差异,即可有效识别图像伪造行为。
3.拼接检测方法
本节介绍了基于特征的多种拼接检测技术。拼接检测的核心在于定位图像中的拼接区域,具体可采用基于对象、基于块、基于像素或基于图像的定位方法。实现这种定位需要识别图像中由相机、编辑软件、拍摄光线及背景细节等因素产生的伪影。选定特征后,后续步骤包括选择并实施特征提取与分类方法来检测拼接区域。图4展示了拼接检测的基本流程,包含特征提取和分类这两个核心步骤。需要说明的是,检测方法和算法会因研究方向和方法的不同而有所差异。例如基于关键特征和基于块的不同技术,其处理流程可能略有不同。特征选择与算法的确定需综合考虑具体需求、数据集类型及可用资源。

图4 拼接图像检测的框图
以下是拼接检测所涉及的一般步骤:
- 预处理:对图像进行必要的准备工作以供分析。可能包括将图像转换至合适的色彩空间、调整尺寸、去噪或提升图像质量。
- 特征提取:从图像中提取有助于检测拼接区域的相关特征。常用特征包括 PRNU 噪声模式、色度值、纹理描述符、块状伪影、噪声统计量及直方图属性。
- 区域分割:将图像分割为更小的区域或区块以进行局部分析。此步骤有助于聚焦特定区域并识别不一致或异常现象。
- 单区域分析:利用提取的特征对每个区域进行分析。根据所选检测方法应用适当算法或技术。例如,比较区域间的 PRNU 模式、检查色度不一致性、分析块状伪影、研究噪声特征或评估直方图属性。
- 决策融合:整合各区域分析结果以判定图像中是否存在拼接现象。
- 后处理:应用后处理技术优化检测结果,减少假阳性或假阴性。还包括额外的滤波、平滑或验证步骤以提高检测精度。
- 报告与可视化:以有意义的方式呈现检测结果,例如在图像中突出显示剪接区域或生成报告以指示剪接的存在及位置。
尽管上述流程会因特征提取方法、分类算法及定位类型的不同而持续演变,但本文为简化说明将拼接检测方法划分为两大类:人工设计方法与深度学习方法。传统人工设计方法采用人工筛选的方式进行特征提取与分类处理,而深度学习方法则通过自主学习机制对图像进行分析,无需人工干预即可识别拼接区域。现有文献中部分方法在提升拼接伪造检测的准确性和效率方面展现出巨大潜力。
3.1.手工拼接检测方法
本节将探讨手工设计的方法,并根据其特征划分为九个子类:场景驱动型方法、格式驱动型方法、相机驱动型方法、噪声驱动型方法、像素驱动型方法、几何驱动型方法、纹理驱动型方法、图像质量指标驱动型方法以及光照驱动型方法。
手工处理方法指代以人工特征提取与分析为特征的传统法医取证技术。在这些方法中,法医专家通过分析图像中的特定特征来识别可能发生拼接的区域。这些特征包括噪声、光照条件、相机特性、图像格式、场景环境、几何图案、纹理特征及像素分布[11]。拼接操作会导致图像不同区域间的特征模式出现不一致性。部分方法通过分析噪声的统计特性来识别可能表明拼接的异常特征。每个相机传感器具有独特的噪声特征模式,可作为指纹特征用于分析此类模式噪声以识别异常。基于光照的技术通过分析亮度差异、阴影分布或反射效果等照明不一致性来检测潜在拼接痕迹。场景识别技术则着重分析阴影特征与模糊度变化,这对场景理解及物体识别任务具有关键作用。
颜色属性不一致(如饱和度、色调或色彩分布的差异)可提示拼接痕迹。通过分析不同图像片段融合后产生的非自然边缘或边界特征,同样能有效检测拼接现象。图像压缩过程中可能产生暴露拼接痕迹的伪影。这些人工检测技术需要领域专业知识,并需人工提取相关图像特征。当前人工拼接检测技术的详细分类体系如图5所示。
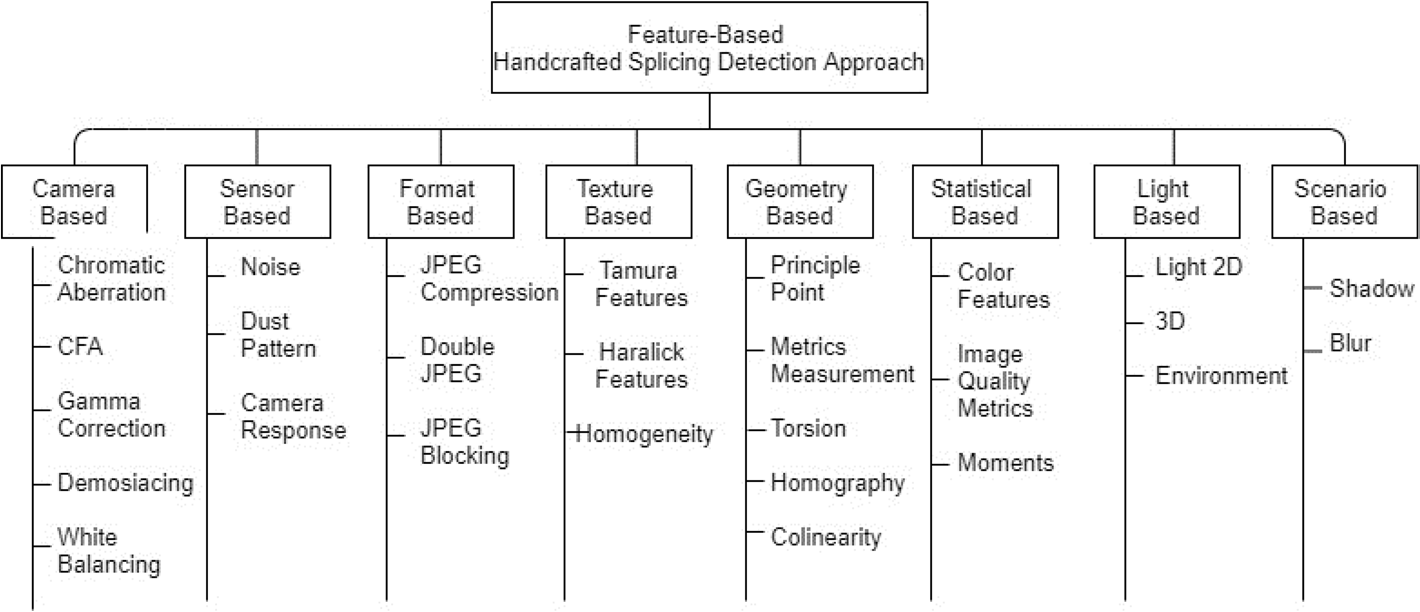
图5 基于特征的手工拼接检测技术分类
3.1.1 基于场景的方法
场景检测技术主要关注图像中的物体、其位置特征及纹理信息,有助于理解图像中的物体分布与光照条件。场景检测技术的两大核心组件如下:
(a) 基于阴影的拼接检测:拼接图像中的阴影不一致性,指的是处理后图像不同区域间阴影模式存在的差异或异常现象。这些不一致性可作为图像篡改的潜在指标。阴影不一致性通过估算遮罩值来表征拼接区域的透明度或不透明度。遮罩值通常介于0到1之间,用于衡量拼接区域在亮度特征上与周边区域的融合程度。
B. Yang等人[18]采用支持向量机(SVM)提取阴影边界,并通过生长率半影宽度(GRPW)计算阴影比例因子,如图6所示。
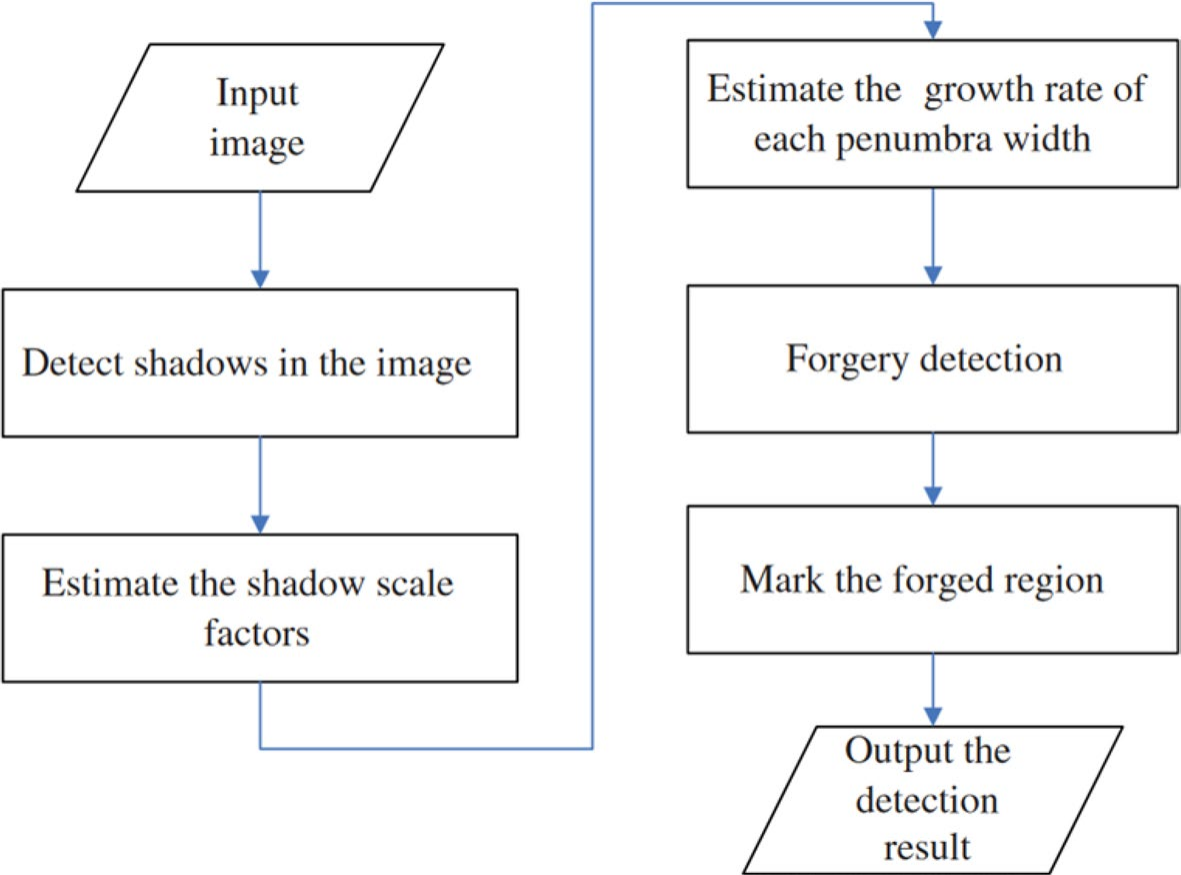
图6 基于阴影的图像拼接目标级定位方法[18]
该模型取得了良好效果(真阳性率88.54%),但主要缺陷在于仅适用于背景光线良好的图像。
(b)基于模糊类型不一致性进行拼接检测:模糊现象由多种原因引起,如相机抖动、长时间曝光或对焦失准,这些都会影响图像整体质量。该方法通过估算图像中不同区域的模糊程度来实现检测。可采用多种模糊度评估技术测量特定区域的模糊量,这些技术包括分析图像频率成分、边缘锐度或梯度特性。若不同区域的模糊度估计值存在显著差异,则可能提示存在拼接痕迹。
模糊可分为两类:(a)运动模糊和(b)离焦模糊。运动模糊由相机移动引起,而离焦模糊则源于镜头焦距设置不当。相较于其他检测技术,模糊检测具有以下优势:(a)对图像缩放具有鲁棒性;(b)无需依赖成像设备信息。K. Bahrami等人[19]提出了一种基于贝叶斯最大后验概率(MAP)的框架,通过局部模糊特征提取结合二元分类器来识别模糊不一致性。M. P. Rao等人[20]采用傅里叶-梅林变换(FMT)进行图像配准,并计算每个模糊核的方位角。相机慢速快门会导致运动模糊,其计算方式是通过平均相机快门时间间隔内像素的强度值。运动模糊[21]不一致性可定位图像中的不连续区域。
3.1.2 基于格式的方法
本节介绍基于格式的拼接检测技术,重点分析图像文件的元数据特征,包括文件格式、压缩方式、色彩空间等参数。JPEG作为相机最常用的图像压缩格式之一,通过JPEG或双JPEG压缩技术可有效识别拼接痕迹[22]。

图7 JPEG图像拼接与尺寸调整示例[23]
图7展示了JPEG拼接图像的基本示例。JPEG压缩过程包含采样、量化和熵编码三个阶段[24,25]:采样阶段将图像分割为多个区块并进行色彩空间转换;量化阶段对各区块进行处理生成量化矩阵;最终通过熵编码对量化结果进行压缩处理。需注意压缩过程中会丢失部分信息,这会影响图像质量及拼接检测效果。
针对此类拼接图像检测,Zhu N.等人[26]提出采用无噪声DCT模型结合直方图的检测框架(如图8所示),通过块级定位技术突出伪造区域。输入图像首先转换至YCbCr色彩空间,随后将Y图分割为互不重叠的区块以降低量化噪声。定位过程通过详细的块级后验概率图进行可视化呈现。
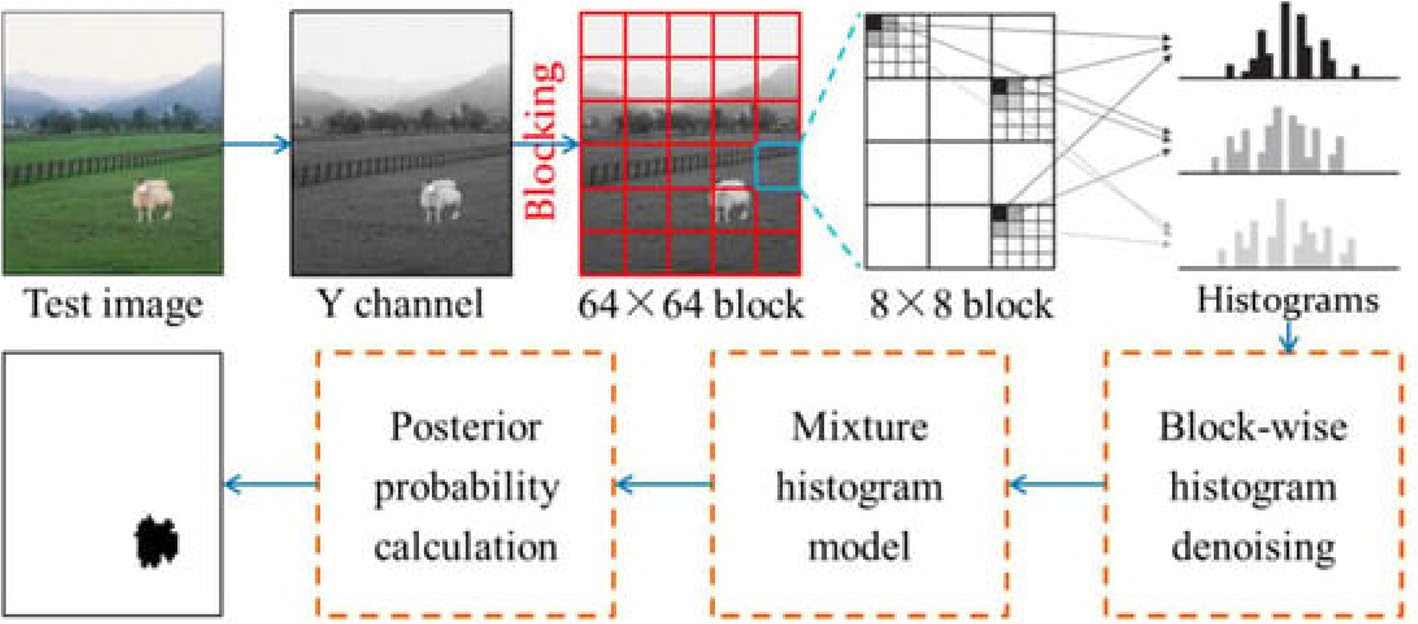
图8 JPEG图像拼接检测框架[26]
3.1.3 基于相机的方法
本节介绍利用相机引入的伪影特征实现图像拼接定位的技术方案。理解相机特性是该方法的核心前提,掌握设备参数有助于确定最佳图像处理方案并提取关键信息。基于相机的检测技术主要通过色彩相关性分析、相机响应特性评估、白平衡校正、滤波阵列处理及传感器噪声分析等维度进行特征提取。
彩色滤光片阵列(CFA)[27]是数字相机及其他成像设备中安装在图像传感器表面的微型滤光片组合体。这些滤光片仅允许特定波长的光线穿透传感器,从而通过检测光线强度与颜色特征生成数字图像。图9展示了一种典型的基于CFA的拼接检测方法,该方法利用所有颜色通道(RGB)进行内核估计。当光线穿过CFA到达传感器时,传感器会记录每个像素中各颜色的亮度值。图像采集完成后,软件算法会对缺失颜色进行插值处理以生成全彩图像。不同相机及成像设备采用的CFA类型各异,其质量对最终图像质量具有显著影响。
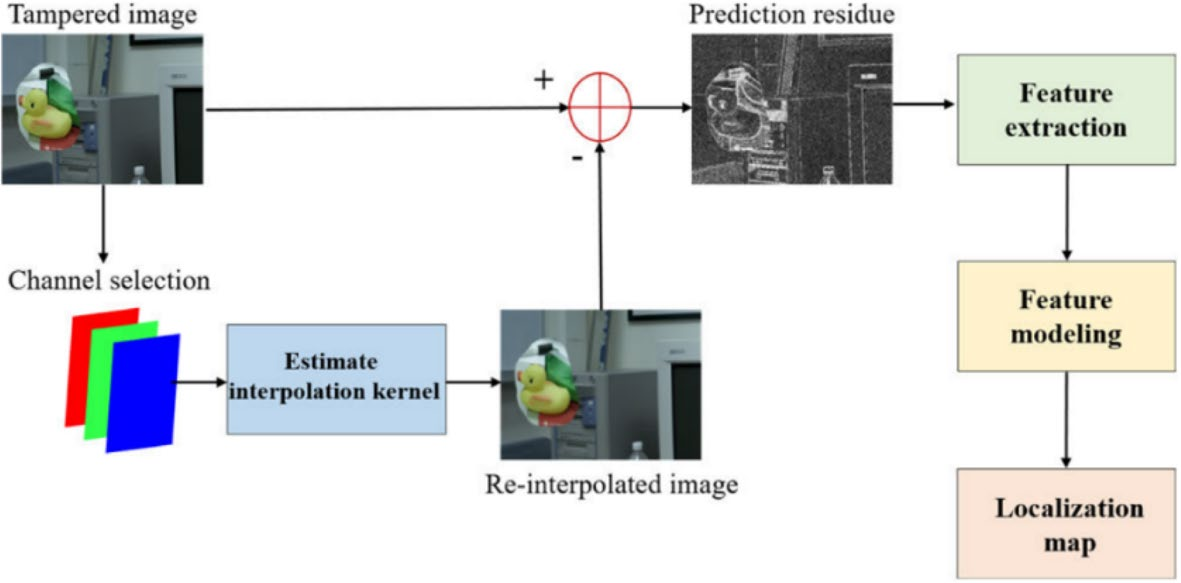
图9 C. W. Park等人[28]提出的基于CFA的伪造定位方法
C.W.Park等人[28]采用奇异值分解(SVD)技术检测图像伪造。该方法旨在通过图像的奇异值重构原始图像,并将重构图像与原始图像进行比对。在伪造图像与真实图像的图像级分类中,W.Wang等人[29]利用彩色空间Croma(YCbCr),结合灰度共生矩阵(GLCM)进行特征提取与 SVM 。
3.1.4 基于噪声的方法
本节探讨利用噪声模式不一致性定位拼接区域的方法。这类方法通常针对具有噪声特征的像素进行检测。基于噪声的检测技术[30]通过计算不同类型的噪声(如固定模式噪声 FPN 、泊松噪声和高斯白噪声)来识别伪造痕迹。泊松噪声是图像传感器固有的噪声类型,其强度与场景光照程度成正比;而高斯白噪声[31]则是人为添加以掩盖伪造痕迹的噪声。但若经过处理的图像仍呈现均匀噪声模式,此类检测技术将失效。 FPN 仅在传感器阵列未受光照区域产生,可通过计算光响应非均匀性(PRNU)进行检测。
基于噪声检测的首要目标是分离噪声信号以计算噪声函数。B. Liu and C. M. Pun[32]提出自适应奇异值分解(SVD)检测技术,通过构建局部多级噪声图谱和邻域噪声描述符来识别图像拼接区域。拼接区域的噪声水平通常高于其他区域,但该方法存在精度不足的问题。另一种方法中,[31]的研究者通过计算多尺度噪声模式差异,利用像素不一致性检测拼接伪造。简单线性迭代聚类(SLIC)用于将图像分割为多尺度,而最优参数组合搜索(OPCS)则用于识别关键特征。该方案对多目标拼接同样具有鲁棒性。
原始图像拼接可通过突出局部噪声不一致性实现。基于此,T. Julliand等人[33]采用块匹配与三维滤波算法计算泊松噪声和高斯噪声水平,并应用主成分分析(PCA)进行特征降维。然而,该方法通常存在较高的误报率,从而降低了效率。
3.1.5 基于像素的检测方法
基于像素的图像检测技术是指按像素逐个处理图像的检测方法。该方法通过分析单个像素的属性(如颜色、亮度和纹理)来识别图像中的目标。常见的基于像素的图像检测技术包括阈值处理、边缘检测、模板匹配和霍夫变换。变换过程通常将相关特征映射为相邻区块间的非相关特征。Z.莫加达西等人[35]提出将奇异值分解与离散余弦变换(DCT)结合核主成分分析的方法。学者们还建议采用离散分数余弦变换(DFrCT)[36]替代DCT,该方法通过评估额外的分数参数来优化检测效果。核主成分分析法通过识别关键特征实现目标检测,因其所有特征在分析过程中均不具有重要性。H.Sheng等人[37]提出四元数离散余弦变换(QDCT),其在四元数域中采用差分矩阵。四元数反向传播神经网络(QBPNN)作为分类器。DCT[38]适用于实值数据处理,并在频域中提供紧凑表示。同时, QDCT 利用四元数表征颜色信息,从而在频域中捕捉色彩变化。
R. Mehta等人[39]对比了三种特征提取方法:离散余弦变换(DCT)、离散小波变换(DWT)[40]以及空间特征提取法。如图10所示,研究采用主成分分析(PCA)进行特征降维,并运用集成分类器完成分类任务。
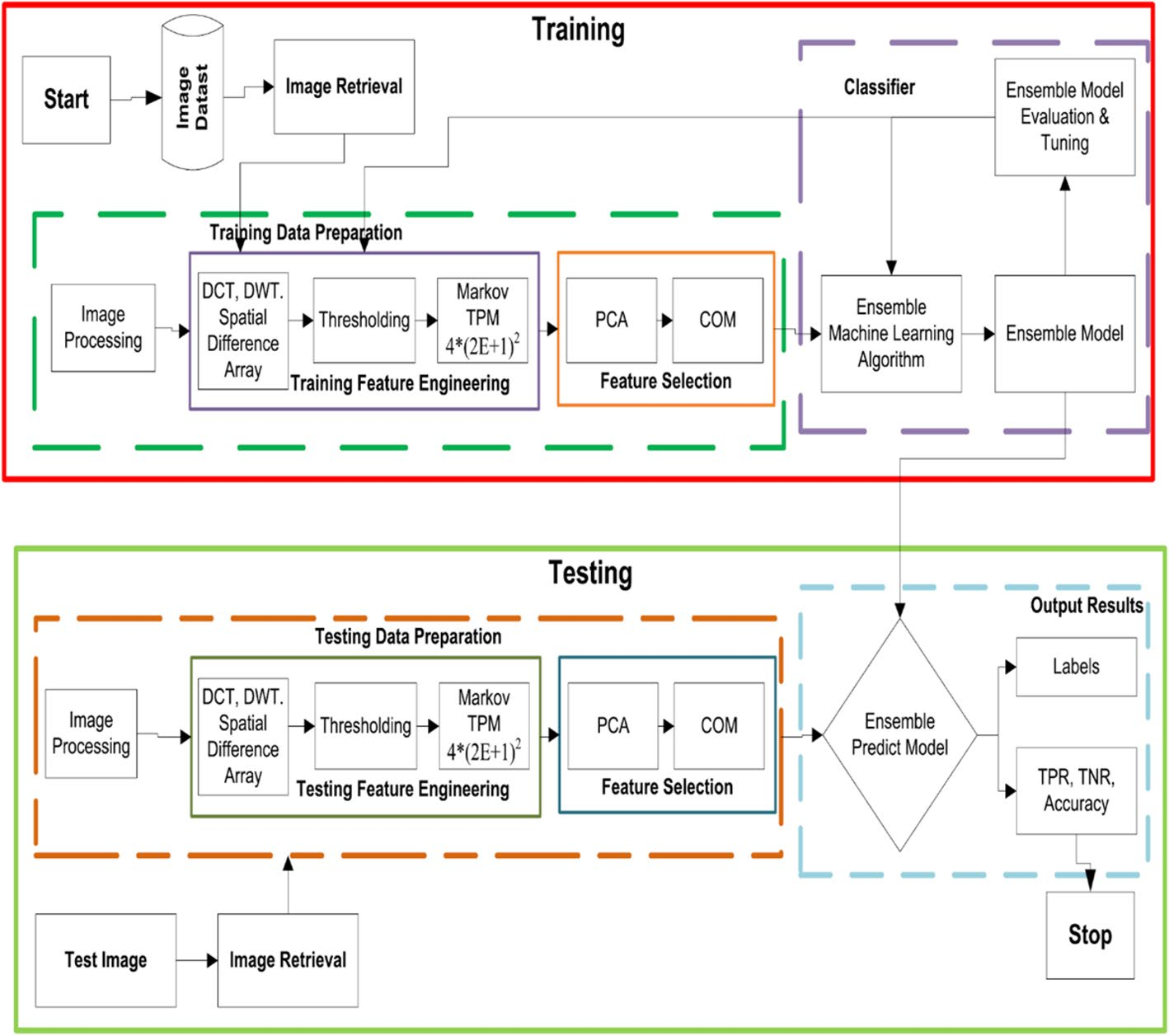
图10 R. Mehta等人[39]提出的基于像素的拼接检测流程图
X. Zhao等人[41]提出了一种基于块DCT、离散Meyer小波变换和 SVM 的二维马尔可夫模型。由于图像属于二维信号,采用二维马尔可夫模型进行泛化处理可显著提升模型精度与鲁棒性。但基础马尔可夫模型运算耗时较长,从而导致计算复杂度增加。
2018年,S.A.Nagtode和S.A.Korde[42]通过多尺度局部二值模式(MS- LBP)解决了图像的角度偏移与尺寸调整问题。MS- LBP 分别应用于A(近似)、V(垂直)、H(水平)和D(对角线)等子带以提取特征。基于DCT的 LBP 在噪声敏感性和像素修改方面效果欠佳。
3.1.6 基于几何的方法
基于几何的检测技术依赖于物体的几何形状特征。当多幅图像进行拼接时,图像中物体的形状、尺寸、对称性及朝向等几何特征极易发生改变。几何变换的基本步骤包括:(a)感兴趣区域提取,(b)按映射函数进行图像变形,(c)插值处理,(d)滤波与平滑处理,(e)采样执行。
典型几何拼接检测技术包括尺度不变特征变换(SIFT)、加速鲁棒特征(SURF)、加速分段测试特征(FAST)以及随机样本一致性(RANSAC)。SIFT基于物体尺度不变特性开发的特征检测与提取技术,通过尺度空间表示法识别对尺度和朝向具有不变性的关键点。 RANSAC 是一种鲁棒估计技术,通过拟合几何模型(如直线或圆)到数据点集来实现目标检测。Chen等人[43]提出通过连续几何变换结合旋转与缩放操作实现拼接检测。Odabas Yıldırım 与G. Ulutas[44]采用稳态小波变换(SWT)与马尔可夫模型相结合的混合方法。与基于二进制缩放和平移的传统小波变换不同, SWT 允许灵活调整尺度和平移参数。
2018年,H. Chen等人[45]提出了SLIC和FAST算法。SLIC是一种简单的线性迭代聚类算法,通过生成超像素来实现图像分割。超像素的大小取决于图像中颜色变化区域的范围。FAST作为广受欢迎的特征检测技术,专门用于识别图像边缘点,其高效快速的边缘检测能力使其特别适用于实时应用场景。K. B. Meena and V. Tyagi [46]提出采用自适应哈尔小波变换(又称四子波变换)替代离散小波变换提取几何特征,通过精准区分伪造区域与自然相似区域显著提升了检测精度。
3.1.7 基于纹理的方法
图像中的纹理指物体表面的视觉品质与外观特征,它定义了图像中重复且可识别的强度或色彩模式。作为图像的核心特征,纹理提供了场景中物体表面属性的信息。被篡改区域的纹理特性可能与周围区域存在差异,这有助于识别伪造痕迹。相关纹理特征可通过直方图、 LBP [47,48]或 GLCM 提取。
K·H·Rhee[49]采用中值滤波残差法提取纹理特征。真实掩模通过计算灰度级峰值和基于熵的边缘值(EbE)定位篡改区域。最后,立方 SVM 用于拼接区域分类。Jalab H·A等人[50]提出了一种基于离散小波变换(DWT)的近似马查多分数熵(AMFE)新方法,该 AMFE 作为新型分数纹理描述符,而DWT将输入图像分解为多个子图像,每个子图像代表不同频段。相比之下,Z·Moghaddasi等人[51]通过游程长度游程数(RLRN)算法分析纹理特征。核主成分分析(PCA)通过降维去除冗余特征信息以降低复杂度,而 SVM 库(LIBSVM)则采用网格搜索法进行分类。
A. K. Jaiswal 和R. Srivastava[52]将纹理特征与形状特征相结合,开发了一种基于逻辑回归的机器学习工具用于识别图像是否经过拼接处理。但该模型不适用于下采样图像处理。本研究中,RGB图像经灰度化处理后,采用四种特征提取工具——方向梯度直方图(HOG)、局部三元模式(LTP)、离散小波变换(DWT)及 LBP [53]进行处理。离散小波变换能提供信号或图像的多分辨率表征,从而实现高效压缩与分析。相比之下,离散余弦变换[54]因忽略像素间相关性而无法达到高精度。因此,在需要高精度与准确性的场景中,离散小波变换更适用于离散余弦变换。
3.1.8 基于矩量与图像质量指标(IQM)的方法
IQM 通过评估图像对原始场景的还原程度来衡量其质量。这类指标通常将原始图像与处理后的图像进行对比,旨在量化处理图像的失真程度。另一方面,矩量是描述图像强度分布的数学函数。图像被划分为多个区域:若区域数量过少会导致拼接精度下降,而区域过多则会增加计算时间。实际图像中基于矩量的特征通常具有平滑规律性,但伪造图像会破坏这种特性。
Z. Zhang等人[55]通过计算 IQM 进行特征提取,并采用多尺度块DCT技术为每个子带生成直方图。所提出的模型包含240维矩量特征。T. J. Jayan与P. Sajith Sethu[56]提出了一种基于光照图谱的检测方法,结合朴素贝叶斯分类器进行 IQM 。
3.1.9 基于光照的方法
每张图像的背景和光照特性各不相同。在拼接过程中,当将两张或多张图像合成新图像时,图像的语义光照或反射特性会显现出来。这种不一致性被用于伪造检测的评估。照度指场景中光线的强度和方向,通常与低频成分(图像内部)相关;而反射率则反映场景中物体表面的特性,涉及高频成分(裁剪边缘处)。文献[57]提出了一种结合 SVM 与Viola-Jones算法的方法。该算法因其高检测精度、对光照变化和面部表情差异的鲁棒性以及计算效率而被采用。
P. Niyishaka与C. Bhagvati[58]提出了一种基于光照-反射率模型的光照度与色度分量计算方法。该 LBP 用于特征提取,并采用多种分类器 SVM ,包括线性判别分析(LDA)、逻辑回归、K近邻(KNN)、决策树和朴素贝叶斯。F. Hakimi等人[59]开发了基于离散小波变换(DWT)和 SVM 的方案。然而,为提升效果,作者在其另一篇论文[60]中将特征提取的DWT替换为离散余弦变换(DCT),并将 SVM 替换为 KNN 作为分类器。该研究提出了一种基于改进 LBP 和DCT的被动拼接检测方案。该方案将色度分量分割为非重叠块,计算改进 LBP ,并通过二维DCT进行变换,最终采用 KNN 进行分类。
多数其他研究(如[18,32,48,55,61])表明, SVM 是学者在图像拼接中进行二分类或二分类任务时最青睐的技术。朴素贝叶斯通过概率集合对数据进行分类,其中某一特征的概率完全排除另一特征的影响。而 KNN 则通过计算特征向量间的距离来实现分类。但其数据计算过程耗时且成本高昂。
上述大多数技术均基于二维图像,但采用的方法截然不同。B. Peng 等人[62]提出利用三维可变形模型提取静止物体的三维姿态。
表2对比了中国科学院自动化研究所(CASIA)所有人工设计的方法。
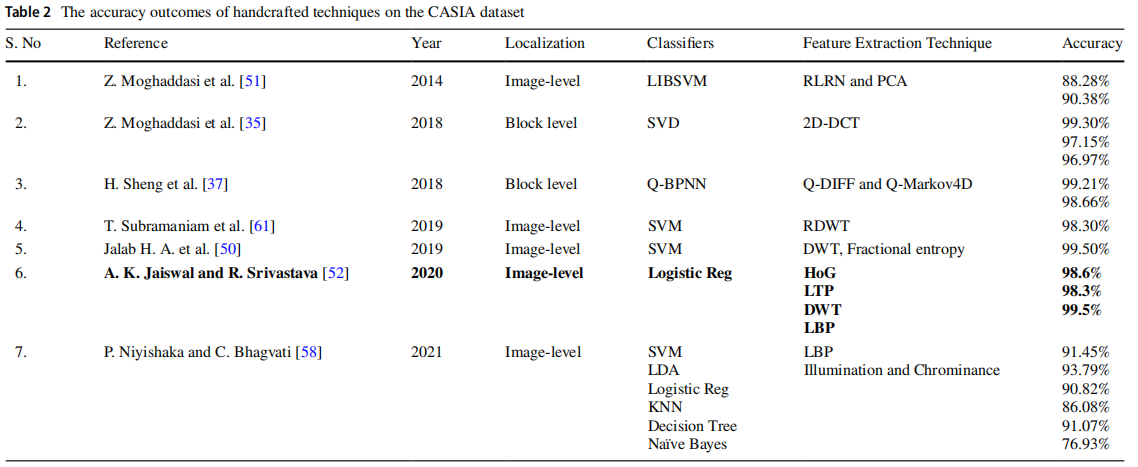
表3汇总了COLUMBIA数据集。
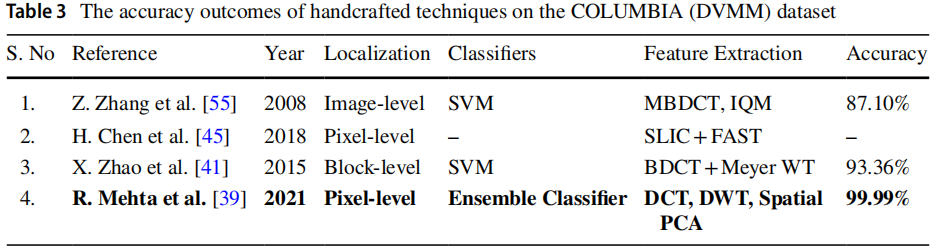
表4列出了其他定制数据集,用于基于准确率评估模型性能。
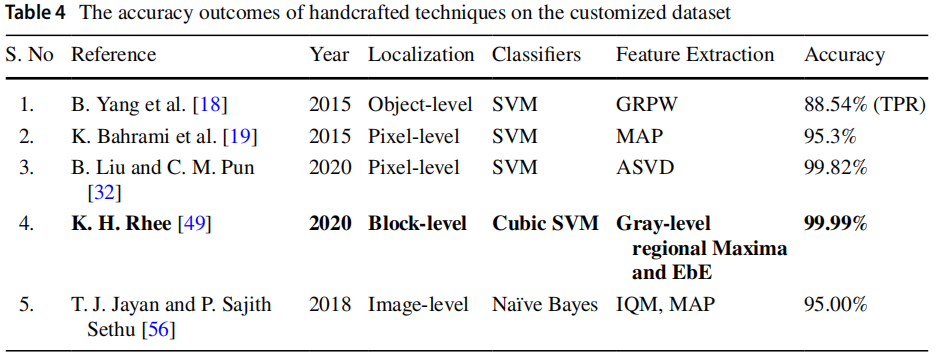
表格中加粗标注的参考文献显示了准确率最高的模型。图像拼接定位结果还按图像层级、区块层级、像素层级及物体层级进行了分类展示。
3.2 基于深度学习的拼接检测方法
本节采用基于深度学习的检测方法,因其在有效识别和定位图像拼接篡改方面展现出显著成效。这类方法凭借高准确率和从海量数据中提取复杂特征的能力,在学界广受青睐。卷积神经网络(CNN)[63-66]是图像分析任务(包括图像拼接检测)中常用的深度学习方法。其核心思路是通过训练神经网络处理拼接图像与真实图像数据集,从而学习区分两者的特征。训练完成后,CNN可对新图像进行拼接或真实分类,实现特征提取与分类的同步处理。该方法通过多层卷积层从输入数据中提取特征,再将特征输入全连接层进行分类。典型CNN架构包括GoogLeNet、MobileNet[67]、DenseNet[68]和VGA16[69]等。基础CNN架构如图11所示,预处理、卷积和池化是其必要步骤。
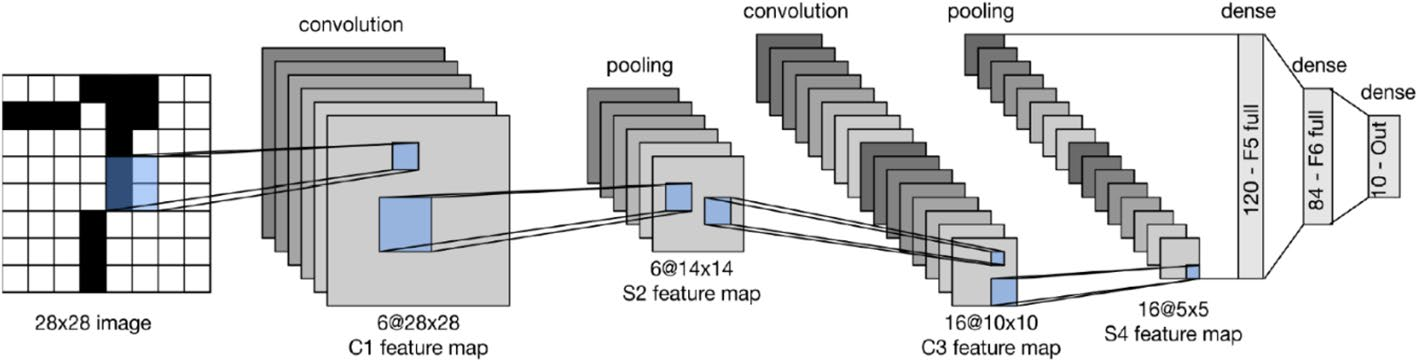
图11 J. M. Czum等人[61]提出的基本CNN架构
D. Kim与H.Y. Lee[63]提出了一种通过高通滤波器增强的卷积神经网络(CNN)模型,用于提取隐藏特征。该模型包含局部响应归一化层、两个最大池化层、全连接层以及高通滤波器。作者[70]提出将CNN、主成分分析(PCA)与离散小波变换(DWT)相结合以检测拼接现象,并将图像拼接分为三大类: LBP 拼接、马尔可夫拼接和深度学习拼接。Abhishek与N. Jindal[71]应用深度CNN与语义分割技术,而Y. Rao等人[72]则采用CNN-128作为局部描述符和 SVM 分类器进行定位。需注意,“CNN-128”特指卷积神经网络最后一层具有128维特征空间。该维度直接影响学习特征的丰富度与复杂性,从而对网络性能产生关键性影响。
L. Almawas等人[73]对比了 SVM 、 KNN 和朴素贝叶斯算法的实验结果,其中 KNN 算法表现最佳,具有更高的准确率和灵敏度。此外,CNN负责特征提取。与此同时,[74]研究者通过整合三个特征的加权和——YCbCr色度空间、光响应不均匀性(PNRU)以及边缘特征,训练CNN模型以实现高精度并减少冗余信息。其中 PRNU 用于解释噪声特征,YCbCr表征色彩特征,边缘特征[75]则处理像素不一致性问题。B. Chen团队[76]提出采用三组 FCN(全卷积网络FCN8、FCN16和 FCN)的模型,并结合长短期记忆(LSTM)与区域提议网络(RPN)进行特征采样。通过移除全连接层,FCN网络能完整保留输入图像的空间信息,从而实现像素级预测。[77]研究中也提出了 LSTM 方法。
其他深度学习架构在拼接检测领域也广受欢迎,例如循环U网络[78]、深度耦合U网络(DCU Net)[79]、粗到精CNN(C2RNet)[80]以及残差神经网络(ResNet)-50[81]。丁浩等人[79]采用 DCU Net通过基于像素的检测技术定位篡改痕迹。该方法首先将双通道编码网络提取的特征进行融合,随后通过膨胀卷积操作提取具有不同细节层次的篡改特征,最终完成二次特征融合。肖斌等人[74]提出了一种采用稀疏自适应聚类的渐进式深度神经网络C2RN。C2RNet通过从粗略表征开始逐步优化输出,经后续层递进增强以提取更精细细节。同时,稀疏自适应聚类技术可根据特征对相似数据点进行自适应分组,从而实现更高效的数据分析。
研究[82]提出了一种基于掩码区域的卷积神经网络(Mask- RCNN),该深度学习模型专为图像中的目标检测与实例分割任务设计。该模型将目标检测与语义分割任务整合为两阶段处理流程。类似地,S·纳思与R·纳斯卡尔[81]将卷积神经网络与人工神经网络分类器相结合,并采用ResNet-50网络从输入图像中提取特征。但该模型未能精确定位目标区域。X·毕等人[83]提出了一种名为环状残差U-Net(RRU -Net)的创新方法,用于优化卷积神经网络的学习过程。该 RRU -Net通过环形连接不同尺度和阶段的特征图,形成环状结构以增强网络性能。
在检测伪造图像与深度伪造图像的场景中,生成对抗网络(GAN)[84,85]是一种有效方法。
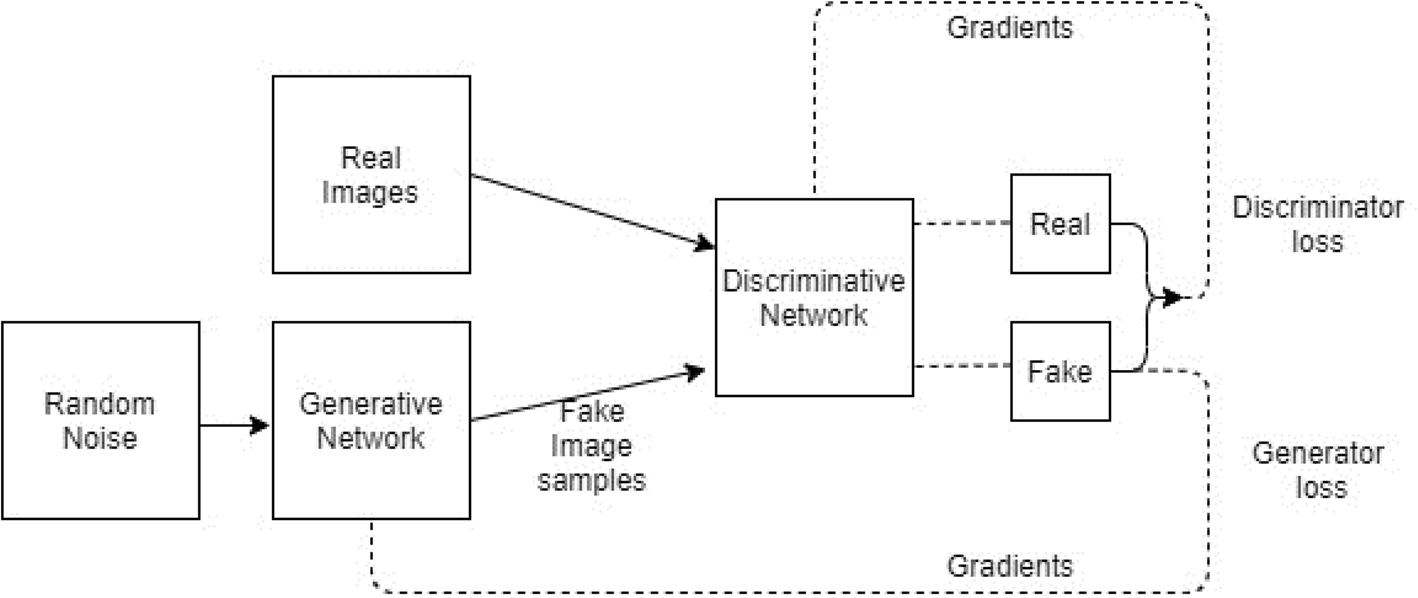
图12 GANs的基本架构
图12展示了GAN的基本架构,该网络由两个人工神经网络构成:生成网络与判别网络。生成网络通过真实数据集进行自我训练,可生成与原始数据集高度相似的图像;判别网络则通过训练实现对真实图像与生成图像的区分能力。
其他类型的GAN包括循环GAN[86]、深度卷积GAN(DCGAN)[87]、最小二乘GAN(LSGAN)[88]、大GAN[89]以及渐进式GAN[90]。GAN与卷积神经网络(CNN)同属深度学习网络,但架构存在显著差异——GAN可采用双CNN结构,专门用于从现有数据集中生成新伪造图像,而CNN则主要用于分类与识别任务。 基于GAN框架,Kniaz V.等人[91]提出了两种生成模型(图像修复与标注)及两种判别模型(二次修复与标注)。其中图像修复模型负责将篡改图像转换至真实图像域,标注模型则通过像素级概率估计来判定图像属于真实图像还是拼接图像类别。该方法论涉及利用深度语义分割生成式标注网络对生成式修图模型进行训练。
文献[92]的作者特别提出了结合变换生成器与定位生成器的现实变换生成对抗网络(GAN)。变换生成器采用可α学习的白化与着色变换(WCT),通过对抗训练,该模块能自动抑制伪造图像中的篡改痕迹。该定位生成器采用多解码器-单任务策略,以准确识别图像中的篡改区域。
约束图像拼接检测与定位(CISDL)[93]基于拼接操作会在伪造图像中引入原始图像不存在的特定统计特征这一原理。在拼接定位领域,Y. Liu等人[93]提出了一种基于生成对抗网络(GAN)的深度匹配网络,该网络采用无孔卷积(DMAC)技术。通过无孔卷积提取的层次化特征被输入到检测器与判别器网络中,这些网络输出的数据随后用于训练 DMAC 以实现两幅图像间的匹配识别。该模型仅适用于固定尺寸图像。因此,为在高分辨率图像中实现像素级拼接定位,研究者[94]通过引入注意力感知编码器-解码器深度匹配网络(Attention DM)对该方法进行扩展。特征提取采用 VGG 网络与残差网络(ResNets)。
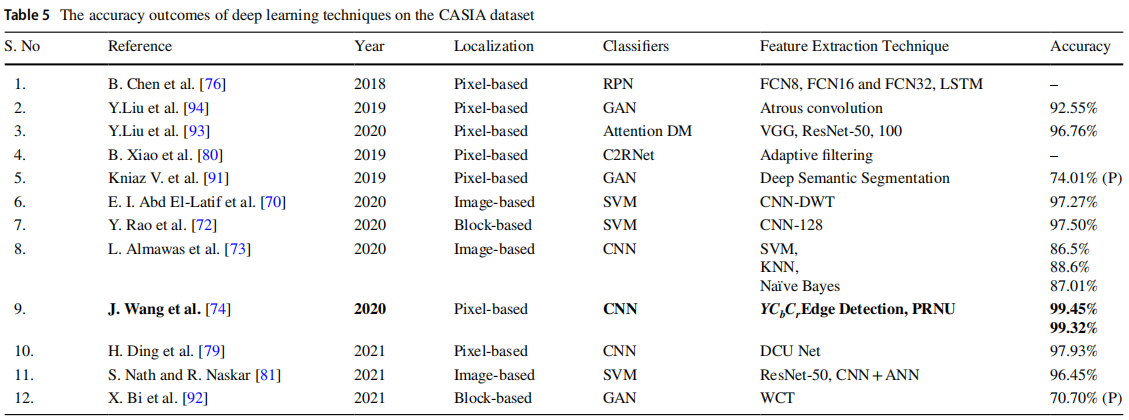
近期学者提出了多种基于深度学习的图像拼接检测方法,现有方法详见表5和表6。实验采用 CASIA v1.0、v2.0及 DVMM 标准数据集进行准确率对比,其中准确率最高的方法以粗体标出。
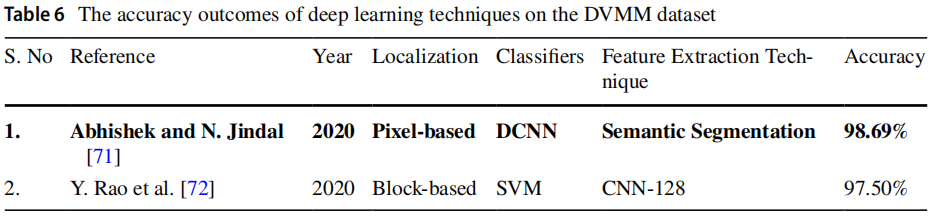
4.数据集
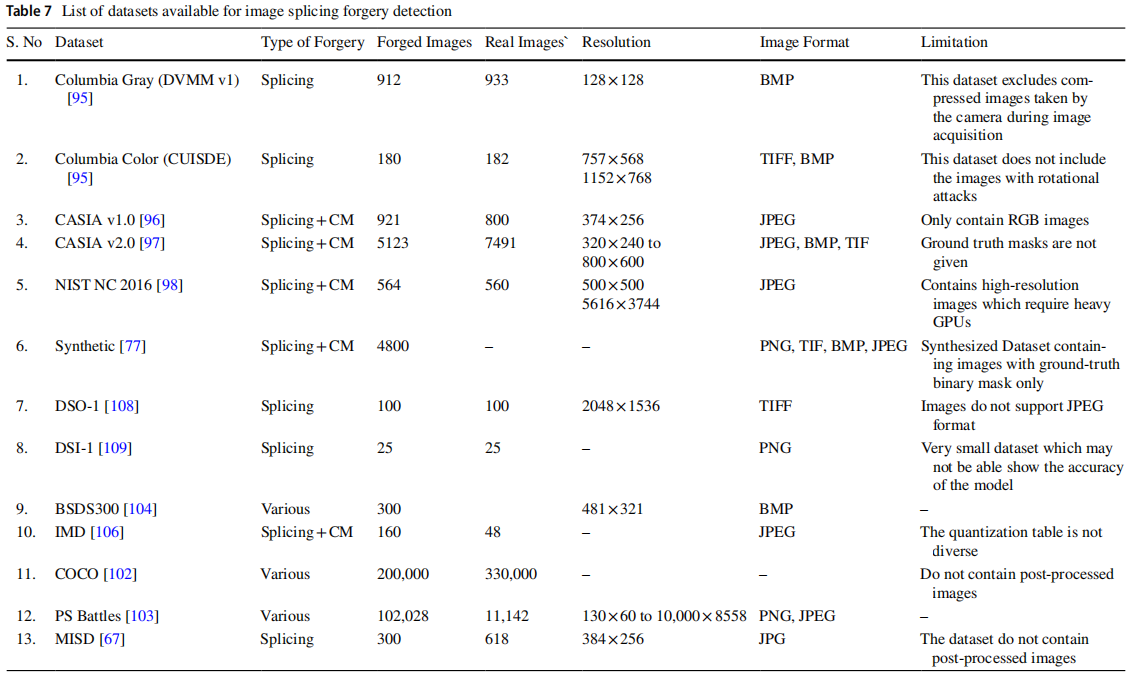
本节将详细探讨多个公开可用的图像拼接检测与定位数据集。但需注意,各数据集各有优缺点,研究人员应根据研究需求选择最合适的数据集。
部分数据集(如 CASIA 1.0、DSO-1、 DSI -1、Columbia数据集等)可在线获取。这些数据集中,拼接图像通过剪切粘贴生成,部分数据集还经过修图处理并采用多种攻击手段进行后期处理。然而多数数据集仅针对一两种伪造场景,且支持的图像格式较少。因此亟需一个通用数据集,需包含所有攻击类型并支持PNG、JPEG、TIFF、 WEBP(谷歌开发的图像文件格式)及 DNG 等多种图像格式。下文将列举若干专为拼接检测设计的数据集。
COLUMBIA大学提供的COLUMBIA未压缩图像拼接检测评估数据集[95]由 DVMM 实验室发布,向公众开放。该数据集提供两个版本:彩色版(CUISDE)分辨率为757×568至1152×768像素,灰度版分辨率为128×128像素。
CASIA v1.0由中国科学院自动化研究所[96]制作,包含800张原始图像和921张经处理的JPEG格式图像,像素尺寸为374×256,均为灰度图像。
CASIA v2.0包含12,323张具有不同Q值的彩色图像,该数据集[97]同时采用复制移动和拼接技术,包含7,491张真实图像和5,123张伪造图像,亦称TIDEv2.0。 NIST NC 2016数据集收录了复制移动、拼接及删除等伪造类型,该数据集于2016年发布但并非全部可用,共包含564张伪造图像和560张真实图像[98]。
Media Forensic Challenge (MFC) 2018数据集[99,100]包含3500万张图像及30万段短视频片段,涵盖多种伪造类型,涉及取证技术、图像处理、成像技术、计算机视觉等领域,包含裁剪、切片、克隆、阴影、反射等特征异常现象。
Synthetic数据集专为拼接任务设计,但未向公众开放。该数据集包含总计65,000张图像,图像尺寸为1024×1024像素。[77]
Common Objects in Context (COCO),大规模数据集Common Objects in Context(COCO)[101,102]包含328,000张图像,其中200,000张为不同伪造手法生成的图像,可通过微软平台获取。
PS Battles 2018年发布的PS Battles数据集[103]包含多种攻击方式的多样化样本,由102,008张伪造图像和11,142张真实图像组成,支持PNG和JPEG格式,像素尺寸范围从130×60到10,000×8558不等。
BSDS300数据集包含300张BMP格式彩色及灰度图像,分辨率为481×321像素。
DSO-1[104]与 DSI -1[79]是面部图像合成数据集,DSO-1包含200张分辨率为2048×1536的图像,其中100张为真实图像,另100张为伪造图像; DSI -1则包含50张图像,其中25张为真实图像,25张经人工篡改。该数据集还整合了图像修图技术。
LibRaw,2008年发布的开源库LibRaw提供原始文件及图像,支持几何变换、CFA滤镜、拜耳滤色片、白平衡调整等多种伪造技术[105]。
Image Manipulation Dataset(IMD)数据集包含160张伪造图像和48张基准图像,可通过其官网获取,涵盖旋转、缩放、复制粘贴等攻击方式。该数据集包含采用JPEG压缩和重采样的图像。[106]
多图像拼接数据集(MISD)[94]专为拼接检测设计,其图像采用 JPG 格式,其中伪造图像300张,原始图像618张。
Dresden数据集包含从18种以上相机型号采集的13,000张图像,所有图像均采用JPEG格式,并符合多种伪造特征[107]。上述数据集的详细信息(包括真实/伪造图像总数、支持的图像格式及伪造类型)已汇总于表7中。
5.图像拼接伪造检测的解决方案
本节重点探讨主流解决方案及其局限性。基于特征分析的解决方案可分为三大类:基于块的分析法、基于关键特征的分析法以及基于学习的分析法,具体分类如图13所示。
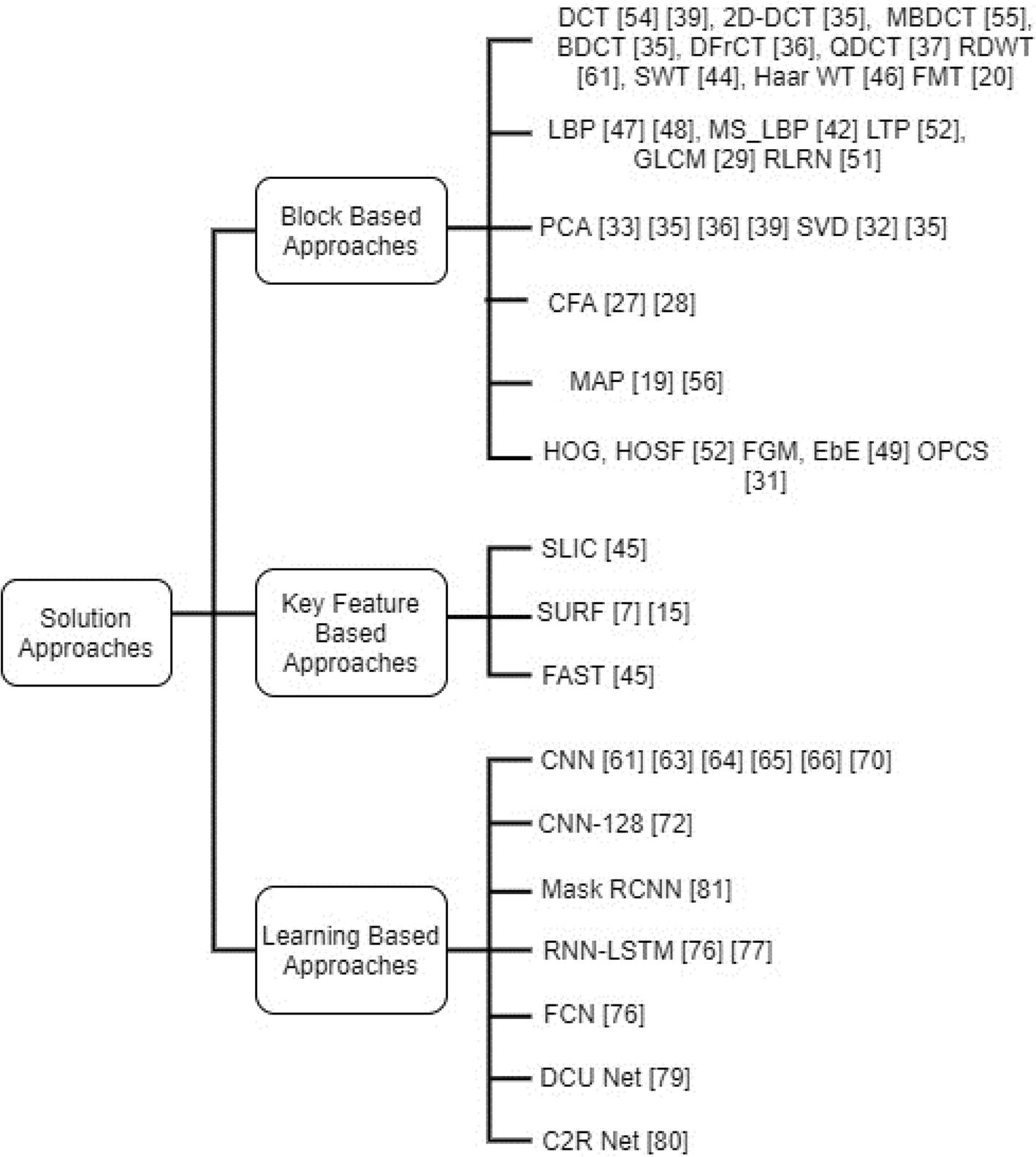
图13 基于特征分析的各种解决方案分类
6.结论
本综述对2014年至2023年间图像拼接伪造检测技术进行了详细研究,重点梳理了该领域具有稳健性的关键技术方案。研究主要分为两大方向:手工设计方法与深度学习方法,二者在特征选择方面存在显著差异。手工设计方法涵盖传统拼接检测实践,依赖人工特征提取与后续分析流程,需对图像中的特定属性进行细致检查以识别潜在篡改区域。检测关键特征包括噪声水平、光照条件、相机参数、图像格式、场景背景、几何图案、纹理特征及单像素特性等维度。相比之下,深度学习技术采用先进的神经网络架构进行拼接检测,代表性模型包括GoogLeNet、MobileNet、DenseNet、VGA16、循环U型网络、深度耦合U型网络、粗到精CNN、残差神经网络-50以及生成对抗网络。基于特征提取的解决方案可分为基于块处理、关键特征识别及学习驱动三大类。图15展示了现有拼接检测研究的占比分布。其中,基于像素的拼接检测方法在众多研究中被广泛采用,而基于纹理和场景的方案则被普遍认可并应用于拼接检测。
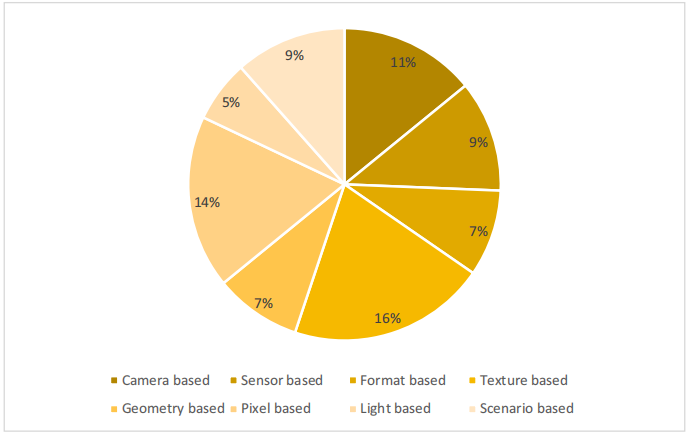
图15 图像拼接检测中所做的工作百分比表示
机器学习方法(尤其是 SVM 和人工神经网络ANN)在伪造品检测领域备受青睐。当前研究还着重强调特征选择与降维技术的应用。
本调查旨在探索当前最先进的方法论,并针对第1节提出的以下研究问题寻求解决方案。
研究问题1:哪种手工制作方法对拼接区域定位最为有效?
在手工技术方面,参考文献[45]所述方法在 CASIA 数据集上展现出最高准确率。该方法结合离散小波变换(DWT)与逻辑回归算法,能精准定位图像中的伪造区域,效果尤为显著。
研究问题2:哪种深度学习方法对拼接区域定位最具优势?
卷积神经网络(CNN)凭借其自动学习能力,在伪造检测领域取得突破性成果。这类模型具备快速、高效且精准的处理能力。深度学习网络领域中,参考文献[69]提出了一种创新方法,通过CNN架构结合光响应非均匀性特征与边缘检测特征,实现了图像伪造区域检测99.99%的准确率,而 DCNN [64]则以98.48%的准确率表现优异。
研究问题3:哪种分类器最适合拼接图像分类?
SVM 在真实图像与拼接图像的图像级分类中应用最广泛,但其特征处理能力有限且运算耗时较长。另一种选择是采用集成分类器[rachana],该模型能够处理高维特征且准确率优于 SVM 。
问题4:哪些数据集适合拼接检测?
本文整合了多种与拼接检测相关的数据集,包括哥伦比亚灰度图像集(DVMM v1)、 CASIA v1.0和v2.0、DSO-1、 DSI -1、COCO、BSDS300以及若干其他数据集。这些数据集通常经过人工整理,可能无法完整涵盖真实场景中可能遇到的各种挑战。文献显示,Casia v2.0是多数研究采用的标准数据集,但仅包含RGB图像。哥伦比亚灰度图像集和DSO-1可作为替代方案,因其专为图像拼接设计,但均仅适用于特定攻击场景。
问题5:评估指标应选用哪些参数?
真阳性率和真阴性率是图像分类中用于判断图像是否被拼接的两个关键参数,后续可据此计算准确率、精确率及F值。
7.未来的工作
自深度神经网络问世以来,拼接检测技术取得了显著进展。然而,研究人员仍需探索诸多潜在方向以提升检测方法的准确性和抗干扰能力。对抗性攻击能够诱使深度神经网络对篡改图像进行错误分类,开发针对此类攻击的强效防御机制将显著增强拼接伪造检测模型的可靠性。通过整合文本、音频等多模态数据与图像信息,可有效提升拼接伪造检测的准确性和可靠性。专门针对拼接检测设计的多样化大规模基准数据集,为不同方法的全面评估提供了有力支撑。通过攻克这些技术挑战,我们有望在检测拼接图像篡改方面取得更精准、更稳健且更具实用性的解决方案。
可以这样吗,输入是特征F、簇中心、软聚类分布
首先是簇-像素注意力: