
Text-Guided Channel Perturbation and Pretrained Knowledge Integration for Unified Multi-Modality Image Fusion
Text-Guided Channel Perturbation and Pretrained Knowledge Integration for Unified Multi-Modality Image Fusion
Xilai Li, Xiaosong Li***, Weijun Jiang**
佛山大学物理与光电工程学院
摘要
多模态图像融合通过整合互补信息提升场景感知能力。统一模型旨在跨模态共享参数以实现多模态融合,但显著的模态差异常引发梯度冲突,导致性能受限。部分方法引入模态特异性编码器以增强特征感知并提升融合质量,但该策略会降低跨任务泛化能力。为突破此局限,我们提出基于通道扰动(Perturbation)与预训练知识整合的统一(Unified)多模态图像融合(fusion)框架(UP-Fusion)。为抑制冗余模态信息并突出关键特征,我们设计了语义感知通道剪枝模块(SCPM,Semantic-Aware Channel Pruning Module),该模块利用预训练模型的语义感知能力对多模态特征通道进行过滤与增强。此外,我们提出几何仿射调制模块(GAM,Geometric Affine Modulation Module),通过原始模态特征对初始融合特征进行仿射变换,保持特征编码器的模态区分能力。最后,在解码阶段应用文本引导通道扰动模块(TCPM,Text-Guided Channel Perturbation Module)重塑通道分布,降低对模态特异性通道的依赖。大量实验表明,所提算法在多模态图像融合及下游任务中均优于现有方法。
代码 — https://github.com/ixilai/UP-Fusion
1.引言
多模态图像融合(MMIF,Multi-modality image fusion)旨在整合不同成像模态的互补特征,生成更全面、信息量更大的图像表征(Zhang et al. 2021; Jie et al. 2025)。例如,红外与可见光图像融合(IVIF,infrared and visible image fusion)(Li et al. 2024a; Zhao et al. 2023a; Liu et al. 2024c; Wang et al. 2025b,a)将可见光的精细纹理细节与红外成像的热辐射信息相结合,显著提升了机器视觉在复杂光照条件下的鲁棒性。类似地,医学图像融合(MEIF,medical image fusion)(Xu et al. 2024; James and Dasarathy 2014)通过整合计算机断层扫描(CT)、磁共振成像(MRI)、正电子发射断层扫描(PET)及单光子发射计算机断层扫描(SPECT)等数据,实现了对病理特征的更全面认知。此外, MMIF 在语义分割、目标检测等下游任务中也展现出巨大潜力。
近年来,统一 MMIF 模型备受学界关注。该领域典型的研究路径是采用统一的自编码器(AE)架构(Cheng, Xu, and Wu 2023; Yang et al. 2025; Zhu et al. 2024)。这类方法通常通过通道级拼接或直接求和的方式获取多模态输入的预融合特征,随后将这些特征输入共享的编码器-解码器网络进行优化。另一种方法则是采用共享权重同时提取不同模态的特征。部分研究通过引入持续学习(Xu et al. 2020)和元学习(Liu et al. 2024d)等策略,增强了模型对 MMIF 任务的适应能力。单编码器架构允许模型跨模态共享特征提取器和解码器参数,从而实现强大的跨任务泛化能力。然而,这些方法往往缺乏对模态间交互机制的显式建模,这限制了其融合性能。如图1所示,虽然单AE方法能够处理多项 MMIF 任务,但其融合质量仍不尽如人意。

第二类方法采用模态特异性编码器架构(Liu et al. 2024b; Bai et al. 2025; Zhao et al. 2024)。这类方法为不同模态设计独立编码器以提取模态特异性表征,随后将这些表征进行拼接或融合,再由统一解码器处理生成最终融合图像。该策略在编码阶段有效保留了各模态独特的特征表达能力。此外,(Li et al. 2023a)提出的方法通过在编码器间引入模态交互模块实现跨模态特征引导,进一步提升了融合性能。然而,模态特异性编码器存在固有局限:由于各编码器在训练过程中容易过度拟合对应模态的特征分布,当应用于未见过的模态组合或不同分布的数据集时,模型常会出现泛化能力不足的问题。因此,多数 MMIF 方法需要为不同任务分别训练权重参数,而非采用统一参数集。如图1所示,当基于 IVIF 数据训练的多模态自编码器(multi-AE)算法应用于 MEIF 任务时,往往会产生错误的背景细节,而非提取出显著且具有信息量的特征。
为平衡单一注意力增强器(AE)的泛化能力与模态特异性AE的卓越融合质量,我们提出了一种基于文本引导通道扰动与预训练知识整合的统一 MMIF 框架(UP-Fusion)。考虑到多模态数据的高冗余性与弱互补性,以及特征提取可能导致显著的通道扩展,我们设计了语义感知通道剪枝模块(SCPM)。该模块通过挤压激励(SE)模块建模通道响应强度,并整合预训练ConvNeXt模型的全局语义感知,共同指导显著通道的识别。随后,为增强模态特异性特征的表征与融合,我们提出几何仿射调制模块(GAM),该模块通过仿射变换对预融合特征进行结构调制。在解码阶段,我们提出文本引导通道扰动模块(TCPM),该模块利用语义文本指导多模态特征的通道选择与对齐——在使用通道注意力进行进一步过滤后,使特征能够去除模态标记,从而提升模型的泛化能力。我们的主要贡献如下:
- 我们提出了一种基于文本引导通道扰动和预训练知识的统一多模态图像融合框架,该框架能有效减少模态冗余,同时增强跨模态特征的统一建模与泛化能力。
- 我们提出的语义感知通道剪枝模块,将语义感知与通道注意力机制相结合,可过滤冗余通道并强化显著特征。此外,我们还设计了几何仿射调制模块,基于模态特异性特征对融合表征进行仿射变换。
- 大量实验表明,该方法在红外-可见光与医学图像融合任务中均显著优于现有任务特定及统一融合模型,同时在下游应用中也展现出更优的性能表现。
2.提出的方法
2.1 总览
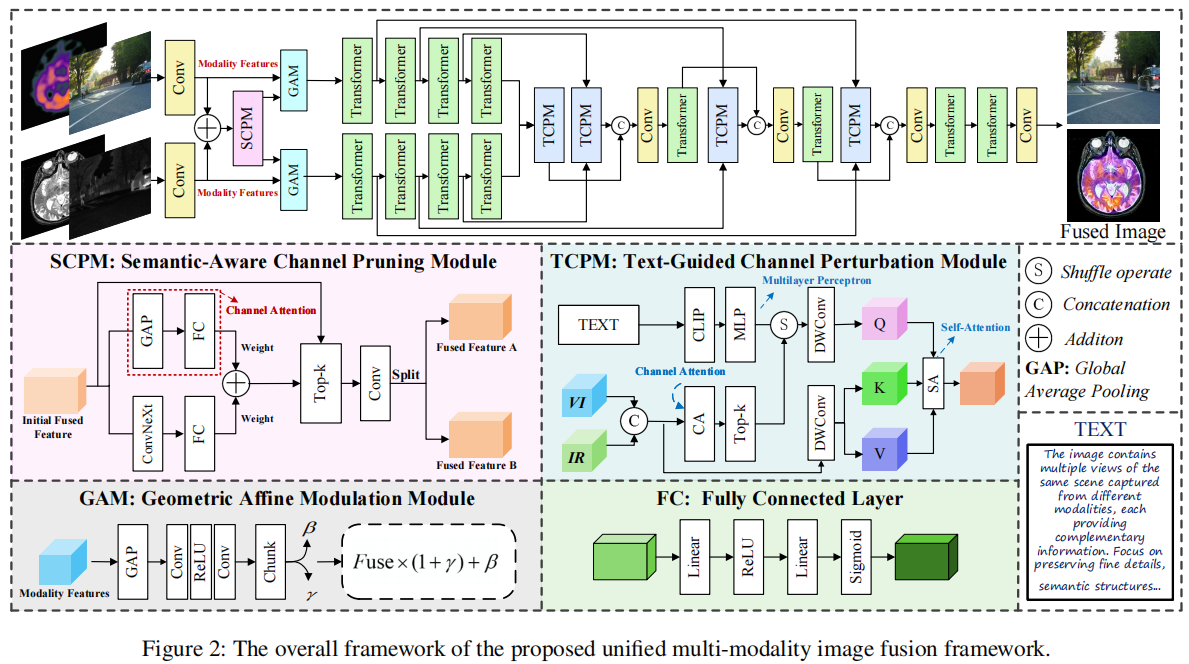
如图2所示,本算法采用基于Transformer模块(Zamir等人,2022)的自编码器架构。网络包含4层编码器和4层解码器,其中编码器中的Transformer模块数量依次递增为[4,6,6,8],对应的注意力头数量也相应提升([1,2,4,8]),从而在保持通道容量的同时逐步降低空间分辨率。在编码阶段,多模态输入I_A和I_B首先通过卷积层处理。随后应用所提出的 SCPM 去除冗余通道并保留关键特征,再通过通道扩展恢复原始维度。为整合模态特异性线索,我们引入GAM模块——该模块在原始模态表示的引导下对融合特征执行仿射变换。双分支编码器独立提取调制后的多模态特征,并在最深层通过所提出的 TCPM 进行通道级交互。解码器由四个Transformer模块组成,逐步重建融合图像。每个阶段中,对应的编码器特征通过 TCPM 进行整合与优化,随后与上采样特征拼接。最终通过卷积实现通道压缩,确保融合图像的逐步重建。