
1-项目的导入以及跑通baseline
我们这这次的任务是完成一个图像篡改定位的任务,我们使用的框架是pytorch,编译器是pycharm,在上一节,我们教了如何安装pytorch等环境,这一节我们将学习如何导入环境和跑通baseline
1.导入项目文件
(1)打开Pycharm软件,打开项目文件夹,选择你下载本地的项目文件: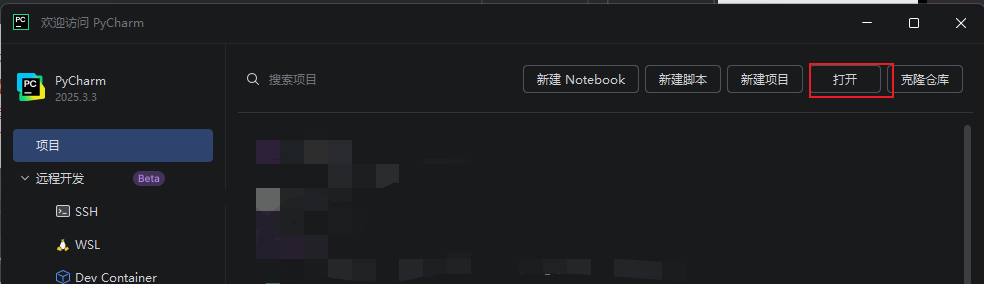
(2)打开Pycharm软件,打开项目文件夹,选择你下载到本地的项目文件:
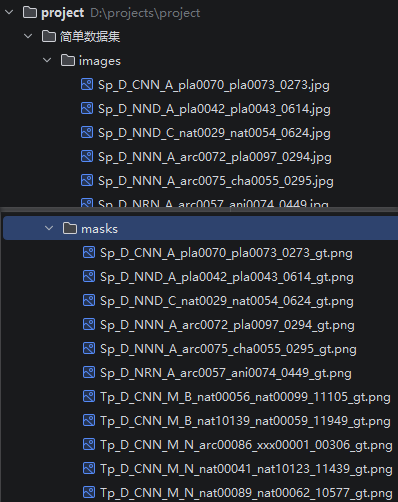
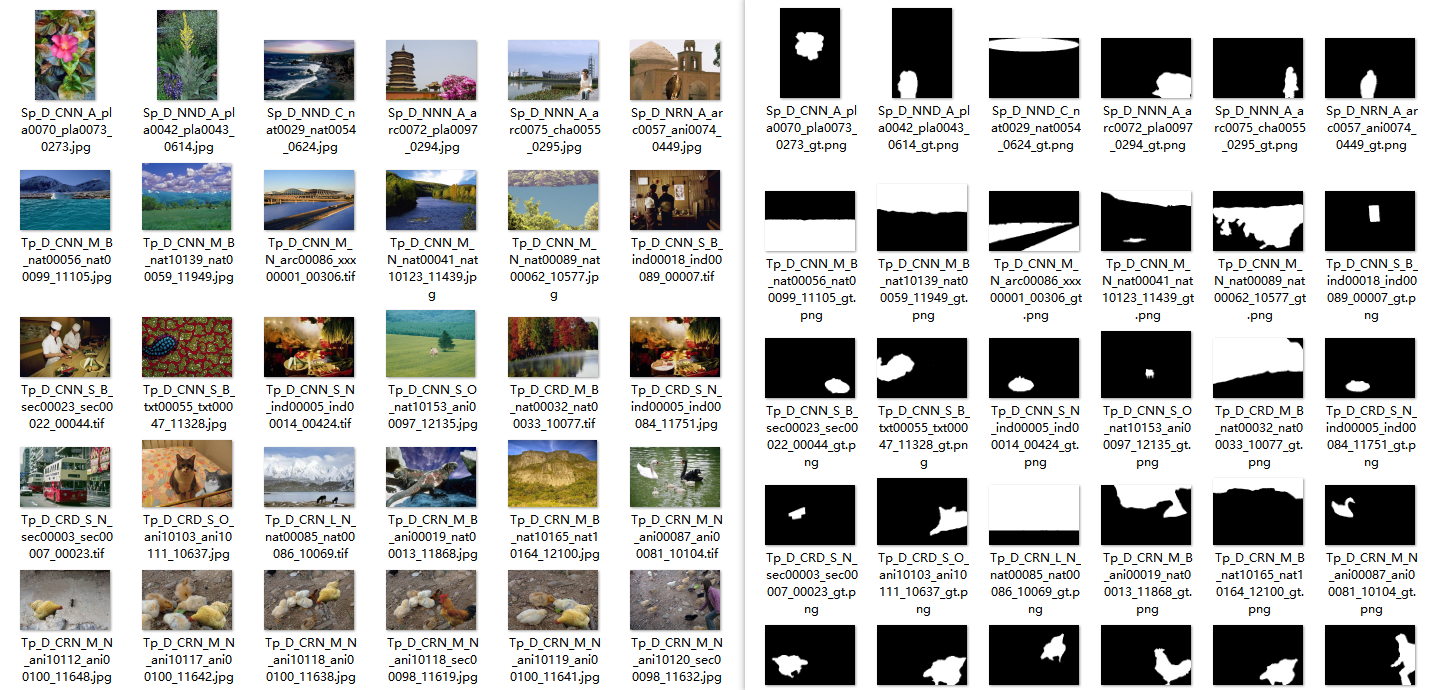
其中数据集是我们的数据,images文件夹中是篡改图像,masks文件夹中是对应的mask:
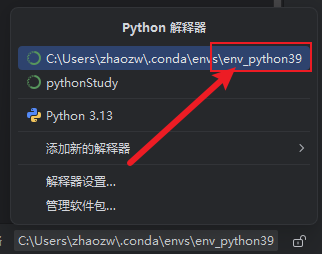
(3)选择已导入的env环境
pip install scikit-learn
2.跑通baseline
0-baseline.py 为老师提供的代码,其模型是一个简单的CNN,具体的构成如下:
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
self.conv1_1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.conv1_2 = nn.Conv2d(32, 32, kernel_size=3, padding=1)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2_1 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.conv2_2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv_out = nn.Conv2d(64, 1, kernel_size=3, padding=1)
def forward(self, x):
x = F.relu(self.conv1_1(x))
x = F.relu(self.conv1_2(x))
x = self.pool1(x)
x = F.relu(self.conv2_1(x))
x = F.relu(self.conv2_2(x))
x = self.pool2(x)
x = F.interpolate(x, size=(256, 256), mode='bilinear', align_corners=False)
logits = self.conv_out(x)
return logits具体而言,其是通过卷积、池化、上采样完成任务的,其尺度-通道数变化如下:
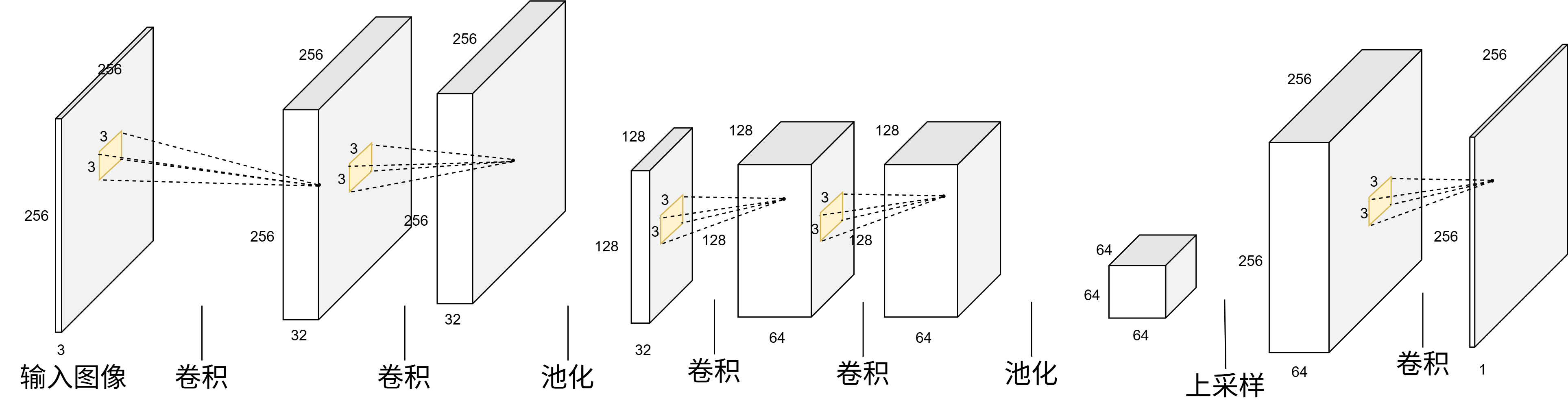
接下来我将具体的解释所有的代码:
首先是数据加载部分:
class TamperDataset(Dataset):
"""图像篡改检测数据集类
Args:
image_dir: 图像目录路径
mask_dir: Mask 目录路径
img_size: 目标图像尺寸
choice: 'train' 或 'val',决定是否应用数据增强
"""
def __init__(self, image_dir, mask_dir, img_size=256, choice='train'):
self.image_dir = Path(image_dir)
self.mask_dir = Path(mask_dir)
self.img_size = img_size
self.choice = choice
self.image_files = sorted(list(self.image_dir.iterdir()))
print(f"找到 {len(self.image_files)} 张图像")
if self.choice == 'train':
self.albu = A.Compose([
A.RandomScale(scale_limit=(-0.5, 0.0), p=0.75),
A.PadIfNeeded(min_height=self.img_size, min_width=self.img_size, p=1.0),
A.OneOf([
A.HorizontalFlip(p=1.0),
A.VerticalFlip(p=1.0),
A.RandomRotate90(p=1.0),
A.Transpose(p=1.0),
], p=0.75),
A.ImageCompression(quality_range=(50, 95), compression_type="jpeg", p=0.75),
A.OneOf([
A.OneOf([
A.Blur(blur_limit=3, p=1.0),
A.GaussianBlur(blur_limit=(3, 5), p=1.0),
A.MedianBlur(blur_limit=3, p=1.0),
A.MotionBlur(blur_limit=5, p=1.0),
], p=1.0),
A.OneOf([
A.Downscale(scale_range=(0.5, 0.9), p=1.0),
A.GaussNoise(std_range=(0.02, 0.08), mean_range=(0.0, 0.0), p=1.0),
A.ISONoise(p=1.0),
A.RandomBrightnessContrast(p=1.0),
A.RandomGamma(p=1.0),
A.Sharpen(p=1.0),
], p=1.0),
], p=0.25),
A.Resize(self.img_size, self.img_size)
])
else:
self.albu = A.Compose([
A.Resize(self.img_size, self.img_size)
])
def __len__(self):
return len(self.image_files)
def __getitem__(self, idx):
img_path = self.image_files[idx]
mask_path = self.mask_dir / (img_path.stem + "_gt.png")
if not mask_path.exists():
raise FileNotFoundError(f"未找到对应 mask: {mask_path}")
image = np.array(Image.open(img_path).convert("RGB"))
mask = np.array(Image.open(mask_path).convert("L"))
# train: 75% 概率增强;val: 只做 resize
if self.choice == 'train' and random.random() < 0.75:
aug = self.albu(image=image, mask=mask)
image = aug['image']
mask = aug['mask']
else:
aug = A.Compose([
A.Resize(self.img_size, self.img_size)
])(image=image, mask=mask)
image = aug['image']
mask = aug['mask']
image = image.astype(np.float32) / 255.0
mask = mask.astype(np.float32)
mask = (mask > 127).astype(np.float32)
image = torch.from_numpy(image).permute(2, 0, 1)
mask = torch.from_numpy(mask).unsqueeze(0)
return image, mask接下的方法是载入训练集和测试集,并构建dataset和DataLoader:
加载数据并划分训练集和验证集
- train_loader 是用于训练的 加载器
- val_val_loader 是用于评估测试集的 加载器
- val_train_loader 是用于评估训练集的 加载器
train_loader和val_train_loader的区别在于:
- 前者用于训练模型,后者用于评估训练集上的性能,以检测过拟合情况
- 前者进行了数据增强,后者没有进行数据增强
def load_and_split_data(batch_size=8, img_size=256):
# 训练集(用于训练)
train_dataset = TamperDataset(
image_dir="数据集/训练集/images",
mask_dir="数据集/训练集/masks",
img_size=img_size,
choice='train'
)
# 评估测试集
val_val_dataset = TamperDataset(
image_dir="数据集/测试集/images",
mask_dir="数据集/测试集/masks",
img_size=img_size,
choice='val'
)
# 评估训练集
val_train_dataset = TamperDataset(
image_dir="数据集/训练集/images",
mask_dir="数据集/训练集/masks",
img_size=img_size,
choice='val'
)
print(f"\n✓ 训练集:{len(train_dataset)} 张图像")
print(f"✓ 验证集:{len(val_val_dataset)} 张图像")
print(f"✓ 评估训练集:{len(val_train_dataset)} 张图像")
print(f"✓ 实际训练比例:{len(train_dataset) / (len(train_dataset) + len(val_val_dataset)):.2%}")
# 创建数据加载器
train_loader = DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0,
pin_memory=torch.cuda.is_available()
)
val_val_loader = DataLoader(
val_val_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0,
pin_memory=torch.cuda.is_available()
)
val_train_loader = DataLoader(
val_train_dataset,
batch_size=batch_size,
shuffle=False,
num_workers=0,
pin_memory=torch.cuda.is_available()
)
return train_loader, val_val_loader, val_train_loader训练一个epoch的代码如下;
def train_one_epoch(model, train_loader, criterion, optimizer, device):
model.train()
total_loss = 0.0
for images, masks in train_loader:
images = images.to(device)
masks = masks.to(device)
optimizer.zero_grad()
logits = model(images)
loss = criterion(logits, masks)
loss.backward()
optimizer.step()
total_loss += loss.item()
return total_loss / len(train_loader)接下来是训练流程:
# ========= 配置 =========
# 训练轮次
EPOCHS = 20
# 训练批次大小
BATCH_SIZE = 8
# 学习率
LEARNING_RATE = 1e-4
# 输入图像大小
IMG_SIZE = 256
# 模型和数据集名称(用于保存模型和日志)
MODEL_NAME = "SimpleCNN"
DATA_NAME = f"{datetime.datetime.now().strftime('%H_%M_%S')}"
# 设置模型使用的设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备:{device}\n")然后是定义训练的损失函数和优化函数:
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)其训练流程如下:
for epoch in range(EPOCHS):
# 训练一个 epoch,并返回训练损失
train_loss = train_one_epoch(model, train_loader, criterion, optimizer, device)
# 评估训练集的性能
train_eval_loss, train_prec, train_rec, train_f1 = evaluate(
model, val_train_loader, criterion, device
)
# 评估验证集的性能
val_loss, val_prec, val_rec, val_f1 = evaluate(
model, val_val_loader, criterion, device
)
print(f"Epoch {epoch+1}/{EPOCHS}")
print(f" Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f}")
print(f" Train F1: {train_f1:.4f} | Val F1: {val_f1:.4f}")
print(f" Train P/R: {train_prec:.4f}/{train_rec:.4f}")
print(f" Val P/R: {val_prec:.4f}/{val_rec:.4f}")
log += f"Epoch {epoch+1}/{EPOCHS}\n"
log += f" Train Loss: {train_loss:.4f} | Val Loss: {val_loss:.4f}\n"
log += f" Train F1: {train_f1:.4f} | Val F1: {val_f1:.4f}\n"
log += f" Train P/R: {train_prec:.4f}/{train_rec:.4f}\n"
log += f" Val P/R: {val_prec:.4f}/{val_rec:.4f}\n"
if val_f1 > best_val_f1:
best_val_f1 = val_f1
# 保存最佳模型
torch.save(
{
"epoch": epoch + 1,
"model_name": MODEL_NAME,
"model_state_dict": model.state_dict(),
"optimizer_state_dict": optimizer.state_dict(),
"val_f1": val_f1,
},
f"权重/best_model_{MODEL_NAME}.pth"
)
print(f" 已保存最佳模型:权重/best_model_{MODEL_NAME}.pth")
print()
print("=" * 60)
print("训练完成")
print("=" * 60)
print(f"模型:{MODEL_NAME}")
print(f"最佳验证 F1:{best_val_f1:.4f}")
# 添加总结信息到日志
log += "=" * 60 + "\n"
log += "训练完成\n"
log += "=" * 60 + "\n"
log += f"模型:{MODEL_NAME}\n"
log += f"最佳验证 F1: {best_val_f1:.4f}\n"
# 训练结束后,一次性保存到文件
with open(f"日志/train_log_{MODEL_NAME}_{DATA_NAME}.txt", 'w', encoding='utf-8') as f:
f.write(log)
print(f"\n日志已保存到:日志/train_log_{MODEL_NAME}_{DATA_NAME}.txt")其结果最后如下:
...
Epoch 8/10
Train Loss: 0.4205 | Val Loss: 0.4359
Train F1: 0.5127 | Val F1: 0.4719
Train P/R: 0.7463/0.3904
Val P/R: 0.7862/0.3371
提示:训练/验证较接近
Epoch 9/10
Train Loss: 0.4036 | Val Loss: 0.4273
Train F1: 0.5755 | Val F1: 0.5711
Train P/R: 0.7148/0.4817
Val P/R: 0.7652/0.4556
提示:训练/验证较接近
Epoch 10/10
Train Loss: 0.4077 | Val Loss: 0.4140
Train F1: 0.5932 | Val F1: 0.6232
Train P/R: 0.6063/0.5806
Val P/R: 0.6744/0.5792
提示:训练/验证较接近
============================================================
训练完成
============================================================
模型:baseline
最佳验证 F1:0.6233可视化结果:
simpleCNN:
好的样本:


中等的样本:

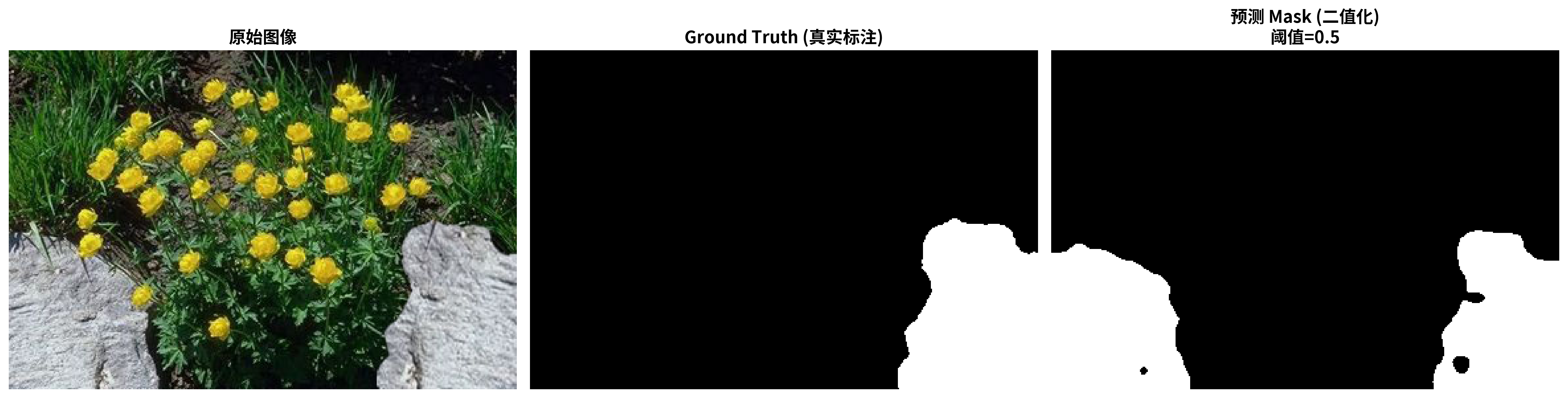

差的样本:


