A Lightweight Clustering Framework for Unsupervised Semantic Segmentation
A Lightweight Clustering Framework for Unsupervised Semantic Segmentation
Yau Shing Jonathan Cheung Xi Chen Lihe Yang Hengshuang Zhao
The
University of Hong Kong
摘要
无监督语义分割的目的是将图像中的每个像素分类为一个相应的类,而不使用带注释的数据。由于获取标记数据集的代价昂贵,这是一个被广泛研究的领域。虽然该领域的工作已经证明了模型精度的逐渐提高,但大多数需要神经网络训练。这使得分割同样昂贵,特别是在处理大规模数据集时。因此,我们提出了一个用于无监督语义分割的轻量级聚类框架。我们发现,自监督视觉Transformer的注意特征表现出很强的前景-背景可微性。因此,聚类可以有效地分离前景和背景图像斑块。在我们的框架中,我们首先跨数据级、类别级和图像级执行多级聚类,并在整个过程中保持一致性。然后,对提取的二进制补丁级伪模进行上采样、细化,最后进行标记。此外,我们提供了自我监督视觉变压器特征的全面分析,并提供了DINO和DINOv2之间的详细比较,以证明我们的主张。我们的框架在无监督语义分割方面显示出了巨大的前景,并在快速的VOC和MS COCO数据集上取得了最先进的结果。
1.介绍
一方面,模型训练仍然需要大量的计算资源,特别是在大型数据集上操作时。另一方面,需要对不同的数据集进行广泛的超参数调优,从而降低了该方法的泛化能力。
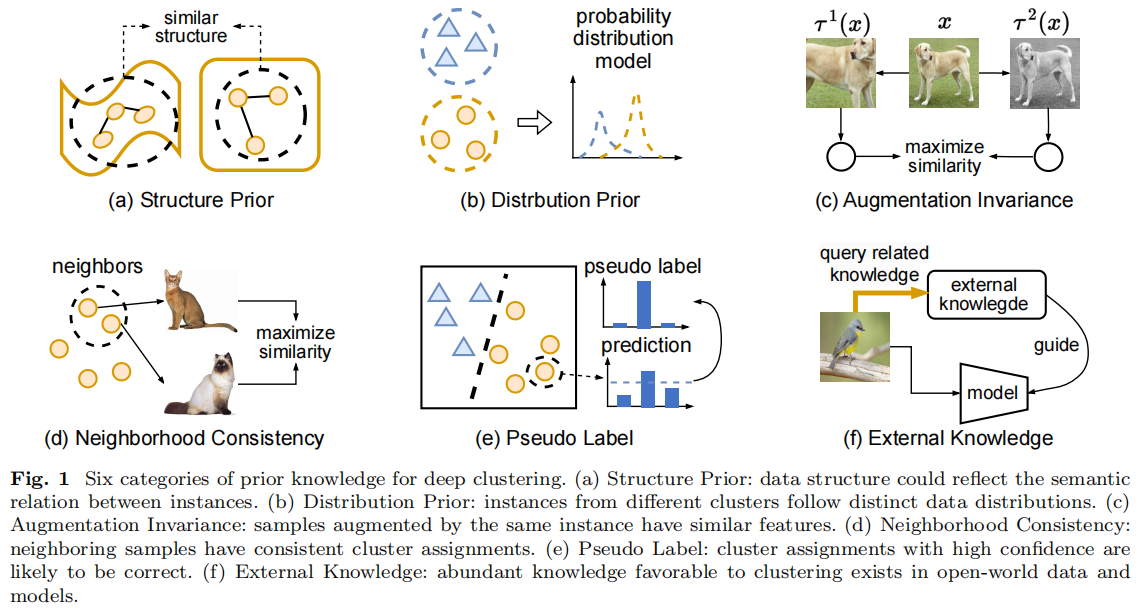
我们提出了一个用于无监督语义分割的轻量级聚类框架。我们发现,自监督视觉Transformer的注意力特征表现出很强的前景-背景可微性。因此,聚类可以用于分离前景和背景图像斑块。我们首先在三个层次上执行聚类:数据集级,通过对同一数据集中的特征进行分组;类别级,通过在同一超类中聚集特征;以及图像级,通过对单个图像中的特征进行分组。数据集级和类别级的结果都提供了高质量的预测。图像级掩模,尽管是最粗糙的,但便于容易的前景-背景检测,并帮助去除噪声区域。因此,我们保持了多级聚类的一致性来提取最终的二进制补丁级伪掩码。图1显示了数据集级、类别级和图像级掩码的可视化结果,以及最终提取的伪掩码。

图1.通过简单的注意特征聚类,我们可以得到准确的伪掩模预测。在同一数据集、超类别和图像中,分别通过聚类特征来提取数据集级、类别级和图像级掩模。不同层次的面具都有自己的优缺点。在简单的背景下,所有的掩膜都能提供准确的预测。然而,在复杂的背景下,分割变得更具挑战性。数据集级和类别级掩模都提供了对对象结构的精确估计,而图像级掩模虽然最粗糙,但可以用于1)在数据集级和类别级掩模中识别前景类,2)去除噪声。通过确保多级聚类的一致性,我们可以获得高质量的补丁级二进制伪掩码。
然后,对补丁级伪掩模进行上采样到像素级并进行后处理。为了分配类标签,将根据对象区域对图像进行裁剪,并将相应的CLS标记聚类为各自的类。利用简单的聚类方法,我们的无网络方法不仅计算成本低,而且取得了高质量的分割结果。
我们的主要贡献总结如下:
- 我们提出了一个用于无监督语义分割的轻量级聚类框架。
- 我们确保了跨数据集级、类别级和图像级的多级聚类一致性,以获得高质量的伪掩模。
- 我们的方法在帕斯卡VOC和MS COCO数据集上都取得了最先进的性能。
- 我们提供了对自监督视觉Transformer特性的全面分析,并详细进行了DINO和DINOv2之间的详细比较。
2.相关工作
3.方法
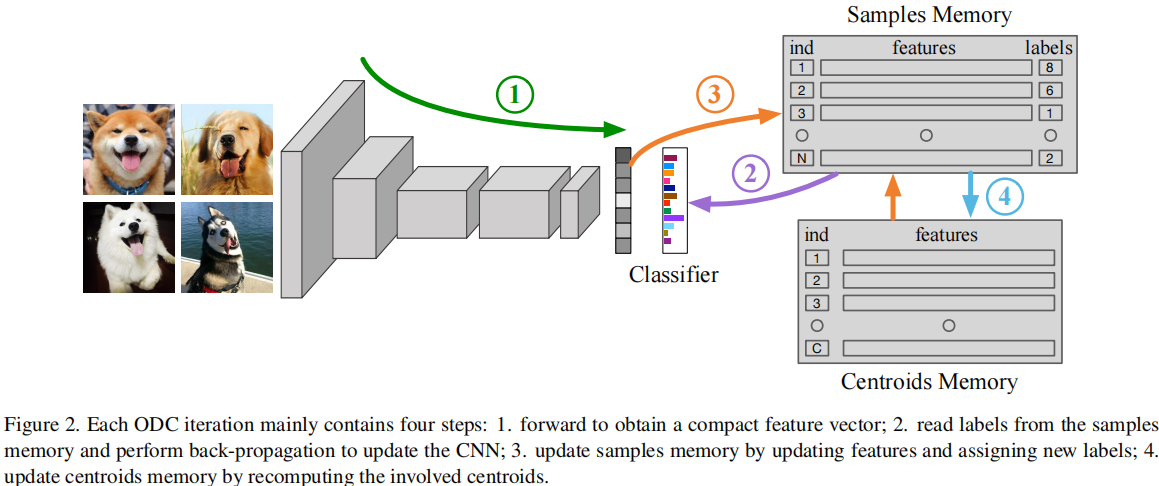
在本节中,我们将提供轻量级集群框架的详细信息。图2说明了我们的方法的总体结构。
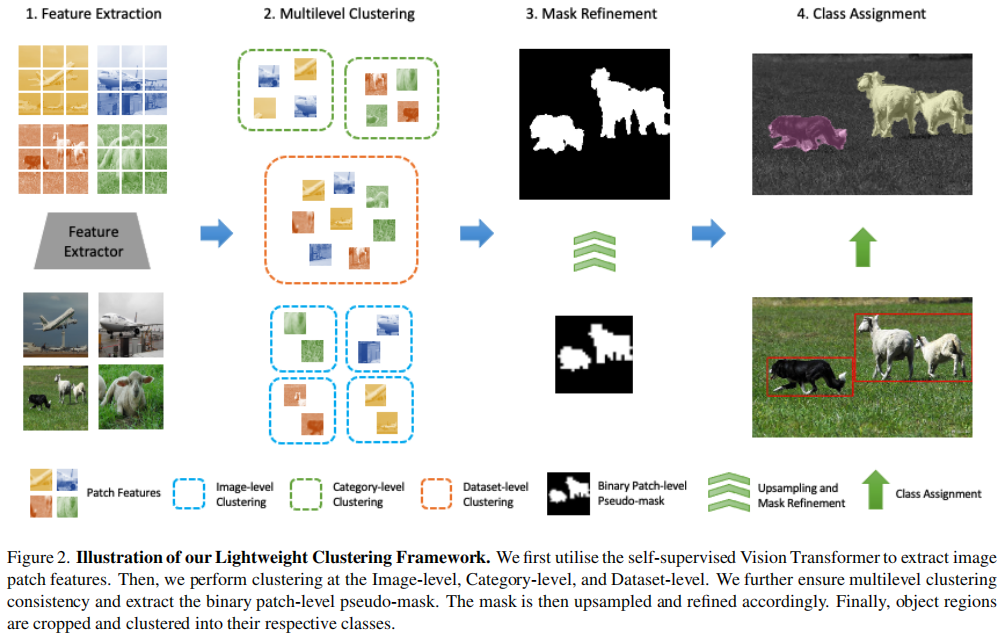
图2我们的轻型聚类框架的说明。我们首先利用自监督的Transformer来提取图像的补丁特征。然后,我们在图像级、类别级和数据集级执行聚类。进一步保证了多级聚类的一致性,并提取了二进制补丁级伪掩码。然后对掩模进行上采样和改进。最后,对象区域被裁剪并聚集到它们各自的类中。
3.1.前期准备工作
查询键值(QKV)注意特征。
Transformers[8,41]中的QKV注意特征是用于自我注意的嵌入式表示。它们使模型能够在计算注意力分数的同时,查询、比较和注意输入序列的不同部分。我们发现,自监督视觉Transformer[3,29]的注意特征具有较强的前景-背景可微性。因此,我们可以通过简单的聚类来提取准确的伪掩模预测。在我们的框架中,我们采用余弦距离聚类,因为它易于实现,并且适合处理大量的样本。
分类(CLS)令牌。
Vision
Transformer[8]中的分类标记作为输入序列中的第一个标记被添加,并提供了整个图像的汇总表示。由于实例较少,我们利用光谱聚类在整个框架中对CLS标记进行聚类,并且可以有效地捕获非线性关系。
3.2.余弦距离聚类
我们采用具有余弦距离的k-均值聚类作为距离度量。余弦相似度有效地捕获向量之间的相似度,而不偏向于那些较大的向量。注意特征A和注意特征B之间的余弦距离可以表示为 \[1-{\frac{A\cdot B}{\|A\|\ \|B\|}}\] 值得注意的是,具有余弦距离的k均值可以很容易地实现传统的k均值。这是因为当向量被归一化时,余弦距离与欧氏距离成正比。 \[\begin{array}{ll}||X_{1}-X_{2}||_{2}^{2}&=X_{1}^{T}X_{1}+X_{2}^{T}X_{2}-2X_{1}^{T}X_{2}\\ &=2-2X_{1}^{T}X_{2}\\ &=2(1-X_{1}^{T}X_{2})\end{array}\] 首先对注意特征进行l2归一化,然后用k-means聚类对特征向量进行余弦距离聚类。
3.3.多级聚类的一致性
注意特征的聚类是我们的框架的主要焦点。我们发现,聚集在不同层次上的特征具有各自的优缺点,因此有不同的用途。分别为图像级、类别级和数据集级聚类设置2、3和4个集群,可以得到所有数据集的最佳结果。
图像级别。
图像级特征是指单个图像的注意特征。它们被分为两组:一组是前景,另一组是背景。虽然在图像级别上产生的二进制掩模是最粗糙的,但它们可以方便地识别前景和背景区域。这有助于从分别在类别级和数据集级聚类中使用的三个和四个集群中选择前景聚类;更多的细节在第3.4节中提供。此外,图像级别的掩模提供了一个目标区域的粗略近似。这允许我们通过排除图像级别的掩模中不存在的区域来消除最终伪掩模中的随机噪声。
类别级别。
类别级特征是指在同一个超类内的所有样本的注意特征。首先,提取所有图像的CLS标记,并将它们聚集到各自的超类中。例如,PASCAL
VOC包含四个超类:人、动物、车辆和室内。由于同一超类中的对象倾向于共享相似的背景,我们将每个超类中的类别级特征聚为三个簇:一个用于前景,其余两个用于背景。通过正确地选择前景簇,我们可以在类别级获得一个精确的伪掩模。
数据集级别。
数据集级特征指的是数据集中所有样本的注意特征。由于大多数数据集包含不同的背景,我们发现将特征划分为四个集群可以产生最好的结果。一个集群对应于前景,而其余三个集群包含背景图像补丁。通过准确地识别前景聚类,我们可以在数据集级获得高质量的伪掩码预测。
为了确保多级聚类的一致性,我们保留了数据集级和类别级掩模之间的共同前景区域,同时删除了图像级前景掩模中不存在的噪声区域。这可以被表述为: \[(D a t a s e t\cap C a t e g o r y)-(1-I m a g e)\]
3.4.前景集群的选择
图像级掩模用于在数据集级和类别级聚类结果中识别单个前景聚类。这是因为它们只包含两组,并且很容易区分前景和背景。数据集级或类别级聚类中的前景聚类是基于投票系统来确定的。首先提取所有四个预测角的高置信度图像级掩码为前景或背景。然后,执行掩模翻转检查,以确保掩模覆盖前景而不是背景。最后,我们在数据集级或类别级掩码中选择与二进制前景掩码共享最常见像素的集群索引。此步骤在整个数据集/类别中重复进行,接收到最多投票的集群索引被确定为前景集群。文中给出了算法1中的伪代码。

3.5.掩码细化
通过上述聚类过程得到的伪掩模处于补丁级,分辨率较低。因此,掩模首先被上采样到像素级。然后去除小的分量,最后应用条件随机场(CRF,Conditional Random Field)[18]对二进制掩模进行细化。
3.6.类分配
将发现的对象区域裁剪并输入自监督ViT,提取相应的CLS令牌。然后将这些标记被聚集成各自的类。
4.实验
5.消融研究
6.限制
虽然我们的框架在PASCAL VOC和MS COCO数据集上实现了很高的分割性能,但需要注意的是,这两个基准都将背景视为一个类。需要进一步的探索来将背景区域聚集到它们各自的类中。
7.结论
在这项工作中,我们引入了一个轻量级的聚类框架的无监督语义分割。我们发现,自监督视觉Transformer的注意特征具有很强的前景-背景可微性。因此,聚类可以有效地分离前景和背景图像斑块。通过在同一数据集、超类和图像内的聚类特征,分别提取数据集级、类别级和图像级掩模。每个层次的结果都表现出独特的特征,通过确保多层次聚类的一致性,我们可以提取出准确的二进制补丁级伪掩码。然后对掩模进行上采样、细化,最后根据对象区域的CLS标记的聚类进行标记。我们的方法在帕斯卡VOC和MS COCO数据集上都取得了最先进的结果。此外,我们还提供了对自监督ViT特征的全面分析,并详细进行了DINO和DINOv2之间的详细比较。我们希望这项工作将鼓励在无监督学习中的研究人员不仅要优先考虑模型的准确性,而且还要考虑所花费的资源和训练时间。通过这样做,我们可以使分割更加经济有效和高效。