ALDEN:Dual-Level Disentanglement with Meta-learning for Generalizable Audio Deepfake Detection
ALDEN: Dual-Level Disentanglement with Meta-learning for Generalizable Audio Deepfake Detection
Yuxiong Xu,Bin Li,Weixiang Li,Sara Mandelli,Viola Negroni,Viola
Negroni
1
广东省智能信息处理重点实验室、深圳大学媒体安全重点实验室
2
Dipartimento di Elettronica, Informazione e Bioingegneria (DEIB),
Politecnico di Milano Milan, Italy
3 Afirstsoft Technology Group
Co., Ltd. Shenzhen, China
摘要
音频深度伪造检测(ADD,audio deepfake detection)面临的一个重大挑战是提升模型对未见过的声码器及其他未知因素的泛化能力,因为现有方法往往容易过度拟合特定声码器模式或合成无关因素。为解决这一难题,我们提出了一种基于元学习的新型双层解耦框架(ALDEN,dual-level disentanglement with meta-learning),通过聚焦声码器无关特征和合成痕迹来实现泛化型ADD。具体而言,我们首先引入基于对抗训练的解耦学习(ADL,adversarial-training-based disentanglement learning)模块,通过显式学习声码器无关特征与声码器特定特征,有效从低级特征层面解耦音频信号。为抑制语义和说话人身份等合成无关信息,我们同时采用基于重构的解耦学习(RDL,reconstruction-based disentanglement learning)模块,该模块在语义高层次上进一步解耦声码器无关特征中的合成相关与无关特征。此外,鉴于低级非语义特征对ADD更为关键,我们提出声码器无关元学习(VAML,vocoder-agnostic meta-learning)模块,通过模拟跨声码器场景来进一步提升泛化性能。大量实验表明,ALDEN在跨声码器场景和真实场景中的表现均优于现有最先进方法。相关代码、模型及补充材料将发布于项目页面: https://beyond0814.github.io/ALDEN/
1 引言
声码器因其快速推理和高保真波形生成能力而被广泛应用,能够将各类声学特征(如梅尔频谱图)转换为音频,在文本转语音(TTS)和语音转换(VC)系统中发挥关键作用[2,6,37]。随着声码器架构的不断进步,其逼真度提升和伪影减少显著增加了合成音频检测的难度。这一日益严峻的挑战,特别是在未见过声码器和真实场景中,凸显了对可泛化音频深度伪造检测(ADD)方法的迫切需求[29,48]。
近期研究提出了基于声码器的自动对齐检测(ADD)数据集[34,44,51],并致力于开发可泛化的检测器[20,24,53]。这些方法通过分析伪影(如混叠和频谱失真)来识别合成音频。传统ADD方法采用两阶段流程:前端特征提取器和后端分类器[49]。像Wav2Vec
2.0[1]和WavLM[7]这样的自监督预训练语音模型,通过大规模预训练来编码潜在声学线索,其性能已超越传统手工特征(如
LFCC [33]、 CQCC
[38])。这些特征通常被输入深度分类器(如卷积神经网络[18]、残差网络[8]或图注意力网络[35]),在基准数据集上表现优异。然而,这些方法往往依赖于全局特征,这些特征会捕获特定于声码器的伪影或无关线索(如语义、说话人身份),从而阻碍其对未见过的声码器及实际场景的泛化能力。
近年来,对抗性数据检测(ADD)领域的研究进展[3,17,28,45]主要聚焦两大方向:一是表征学习技术,用于提取声码器诊断特征;二是训练策略优化,旨在提升对未知欺骗攻击的泛化能力。解耦表征学习(DRL)方法[22,31,53]通过学习能最小化无关信息影响的特征,显著提升了检测性能。与此同时,元学习技术[17,41]通过模拟训练过程中的分布偏移来增强泛化能力。尽管
DRL
和元学习各自取得显著成效,但二者结合应用以构建更稳健的ADD框架,其潜力仍待深入探索。
本文提出了一种基于元学习的双层解耦新框架(alden),旨在实现可泛化的声码器无关性(ADD)。
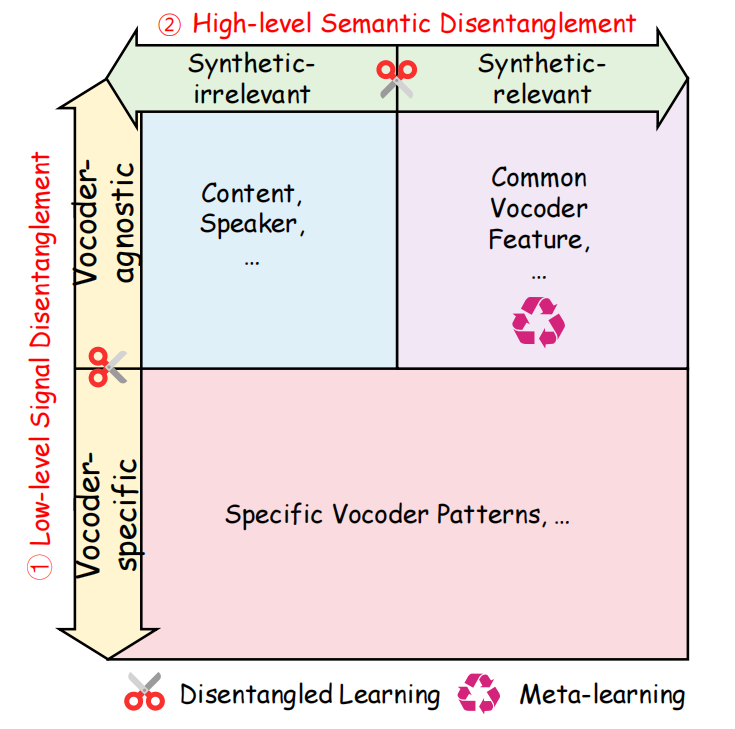
图1:ALDEN模型沿两个维度构建:低级信号(垂直维度)与高级语义(水平维度)的解耦机制。该模型通过双层解耦学习与元学习相结合的方式,专注于可泛化特征的提取,同时抑制无关变异,从而实现跨声码器的泛化能力。
如图1所示,alden通过结合双层解耦学习与元学习,有效分离声码器无关特征与合成相关线索,从而提升跨声码器的泛化能力。该框架包含三个核心模块:基于对抗训练的解耦学习(ADL)、基于重构的解耦学习(RDL)以及声码器无关元学习(VAML)。
其中,ADL模块通过在潜在空间中应用多任务学习,整合双分类器与领域对抗网络,实现声码器特有特征与通用特征的分离。为提升真实性分类性能,我们进一步将Logit归一化(LogitNorm)损失[46]整合至ADL模块,既能有效抑制过度自信的预测,又能在保持训练数据分类准确率的同时提升模型性能。
为抑制与合成语音无关的干扰,
RDL
模块基于声码器无关特征重构音频,整合内容和说话人特征等无关信息,实现高层次语义解耦。
鉴于低级非语义特征的关键作用,
VAML
模块采用元学习模拟声码器分布偏移,进一步提升泛化性能。
本文贡献可归纳如下:
- 我们提出了一种名为ALDEN的新型框架,用于可泛化ADD,该框架能有效解耦并学习声码器诊断特征与合成相关线索。
- 我们提出一个ADL模块,用于分离声码器特有与声码器无关的低级特征。此外,我们设计了一个 RDL 模块,进一步将合成相关与合成无关的特征与声码器无关的特征解耦,实现高层次的语义解耦。最后,我们提出一个 VAML 模块,用于模拟跨声码器场景,从而增强声码器无关特征的提取。
- 大量交叉编码器实验及实际场景测试表明,alden算法不仅效果显著,其性能表现更超越了当前最先进的方法。
2 相关工作
2.1 音频深度伪造检测的泛化能力
面对日益严峻的音频深度伪造挑战,近期研究提出了多种检测方法。sun等人[34]提出了一种基于RawNet2的多任务模型,可同时学习声码器分类与真实性检测。Tak等人[36]通过结合W2V2特征与
AASIST
[14]分类器来提升泛化能力。FC[44]在声码器生成的音频数据上训练了基于W2V2的前馈分类器。Juan等人[26]采用注意力统计池化(ASP)技术对多层W2V2嵌入进行聚合,再通过
MLP 处理。其他架构如 LCNN
[47]和基于Transformer的模型[22]也已被探索。
尽管这些方法效果显著,但它们常会过度拟合全局特征(可能包含特定声码器模式或合成无关因素),从而限制了其对合成音频的判别能力。
2.2 解耦表示学习
解耦表示学习(DRL)通过将潜在变异因素分解为可解释的组件[4,42],已被应用于ADD领域以通过隔离伪影相关线索来降低无关信息的影响。
DSVAE
[50]采用变分自编码器提取解耦的频谱图表示,增强了对ADD中未见过合成器的泛化能力。SafeEar[22]将音频分解为声学与语义成分,利用声学特征进行检测。Ren等人[31]通过语义解耦提取与声码器无关的伪影特征,采用扁平化损失景观优化训练。与仅聚焦单一解耦维度的方法不同,alden联合解耦低级信号与高级语义表征,实现了对未见过声码器的卓越泛化能力。
2.3 元学习
元学习能够在保留已有知识的同时快速适应新任务[15],被广泛应用于提升泛化能力。例如,
MLDG
[19]将源域划分为元训练集和元测试集,通过基于梯度的元学习增强领域泛化能力。在此基础上,Pal等人[28]为ADD引入了原型损失函数与元学习目标,超越了传统分类损失。类似地,Hansen等人[12]采用情节元优化提升欺骗检测效果,Zeng等人[52]则通过可学习权重将元优化与体裁对齐损失相结合以增强泛化能力。
与以往针对语音生成或语音体裁分布偏移的研究不同,alden将声码器引发的分布偏移作为元学习的核心挑战。通过按声码器类型划分域,我们模拟跨声码器偏移以学习声码器无关特征,从而降低过拟合并提升泛化能力。该设计与我们提出的双层解耦表示学习框架实现了无缝整合。
3 提出的方法
本节提出一种双层元学习解耦框架(ALDEN),旨在从声码器生成的音频中提取声码器无关特征和合成相关线索。图2展示了该框架的整体流程。
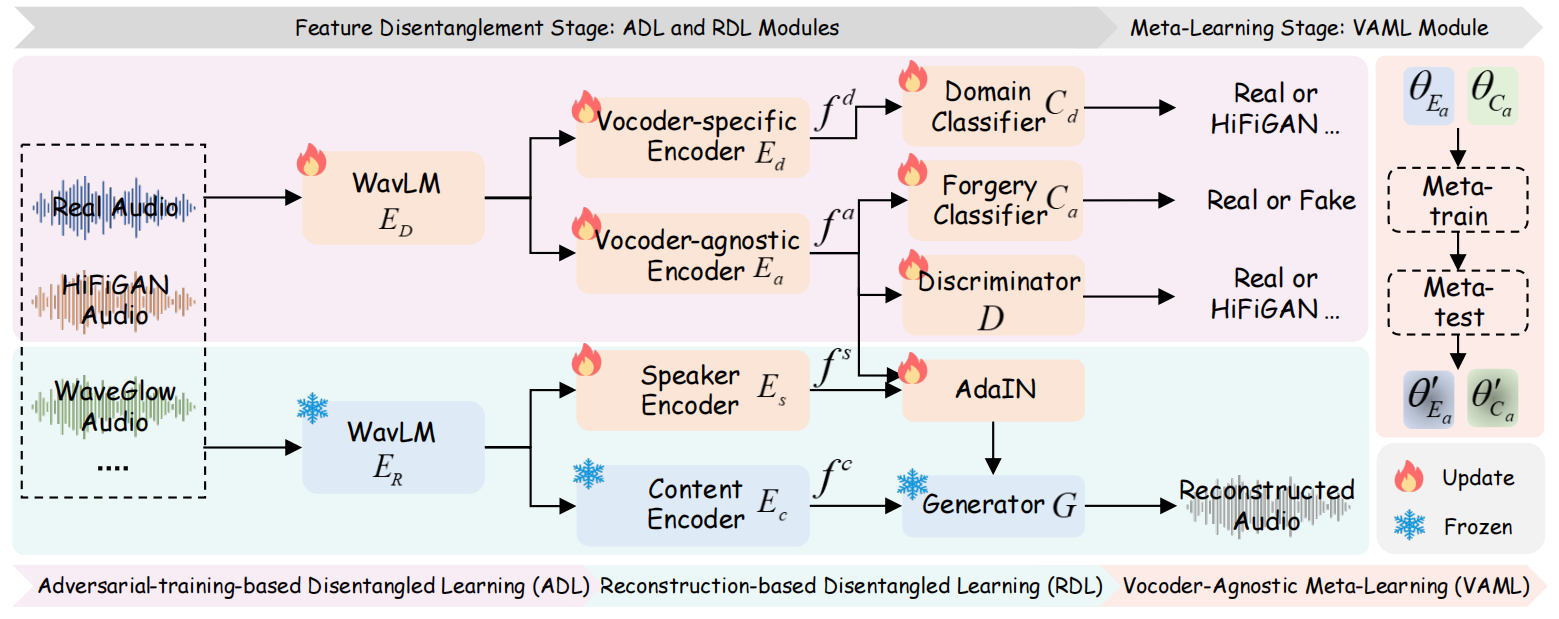
图2:所提算法的整体框架。该算法包含三个核心组件:(a) 基于对抗训练的解耦学习(ADL)模块采用多任务学习策略,将声码器特定特征\(f^d\)与声码器无关特征\(f^a\) 进行解耦。(b) 基于音频重建的解耦学习(RDL)模块通过音频重建技术,将\(f^a\)、内容特征\(f^c\)和说话人特征\(f^s\)进行解耦。(c) 声码器无关的元学习(VAML)模块可缓解对特定声码器的过拟合问题,并有效更新声码器无关的编码器\(E_a\) 和伪造分类器\(C_a\)。
ALDEN包含三个主要模块:(i)基于对抗训练的解耦学习(ADL);(ii)基于重构的解耦学习(RDL);(iii)声码器无关的元学习(VAML)。
完整的训练流程包含两个阶段:特征解耦与元学习。在特征解耦阶段,我们采用ADL和
RDL
模块提取解耦特征,包括声码器特定特征、声码器无关特征、内容特征和说话人特征。在元学习阶段,我们通过
VAML
模块在元训练和元测试阶段模拟跨声码器场景,以优化声码器无关特征。
下文将详细阐述这两个训练阶段,并说明所提出的模块。
3.1 特征解耦阶段
设 𝑋 = {𝑥1,· · · ,𝑥𝑁 } 为 𝑁 音频样本的训练集,每个\(x_i\)为二元元组,包含音频信号及其标签 𝑌 = {𝑦𝑖 } ∈ {0,1} (0表示真实,1表示伪造)。领域标签 \(A=\{a_i\}_{i=1}^k\)指定音频来源,每个 𝐾 领域包含 𝑁/𝐾 样本。例如,在Voc.v4数据集[44]中, 𝐴 ∈{real、HiFiGAN[16]、NSF-HiFiGAN[40]、Hn-NSF[43]和WaveGlow[30]}。
3.1.1 ADL(adversarial-training-based disentanglement learning)模块
声码器伪影对ADD至关重要,但某些伪影存在过度拟合特定声码器的风险。为解决此问题,我们的ADL模块采用多任务学习策略,通过联合执行声码器与伪造分类任务,解耦出声码器无关特征。
我们首先对预训练的WavLM
Large模型1进行微调,作为特征提取\(E_D\)
,获取第 𝑖 个音频样本\(x_i\)的全局表示\(f_i^D=E_D(x_i)\),主要任务是检测真实性(即真实与伪造)。随后将该特征\(f^D\)输入声码器专用编码器 𝐸𝑑
和声码器无关编码器 𝐸𝑎 ,以提取相应特征: \[f_{i}^{d}=E_{d}(f_{i}^{D}),f_{i}^{a}=E_{a}(f_{i}^{D}),\]
其中 𝑓 𝑑 和 𝑓 𝑎 分别代表声码器特定特征和声码器无关特征。 𝐸𝑎 和 𝐸𝑑
两种编码器结构相同但参数不同。伪造分类器 𝐶𝑎 通过 𝑓 𝑎
训练将输入音频分类为真实或伪造,而域分类器 𝐶𝑑 则基于 𝑓 𝑑
预测声码器类别。为增强声码器无关表征并促进解耦,我们引入对抗训练防止编码器
𝐸𝑎 捕获声码器特定信息。配备梯度反转层(GRL)的域分类器 𝐷 ,通过 𝑓 𝑎
预测声码器标签。在反向传播过程中, GRL 会反转梯度,迫使 𝐸𝑎 在 𝑓 𝑎
中抑制声码器特定线索。这种 𝐸𝑎 与 𝐷
之间的对抗性极小极大博弈,使模型能够学习出具有欺骗辨别能力且与声码器无关的特征。
3.1.2 RDL (reconstruction-based disentanglement learning)模块
与语音合成不同,注意力缺陷障碍(ADD)中的合成无关因素(如语音语义和说话人身份[53])会因无关性或对检测的负面影响而阻碍泛化能力。为缓解对这些因素的过度拟合,我们提出
RDL 模块,该模块受解耦语音转换[21,23]启发,可在保留合成伪影的同时抑制 𝑓
𝑎 中的无关信息。该模块由冻结的WavLM-Large特征提取 𝐸𝑅 、内容编码器 𝐸𝑐
、说话人编码器 𝐸𝑠 、AdaIN模块和生成器 𝐺
组成。重建过程保留内容、身份和合成线索,而AdaIN模块通过去除干扰信息,为ADD生成解耦且可泛化的特征。
鉴于WavLM的浅层编码说话人相关信息[7],我们通过聚合
𝐸𝑅 最后24层的隐藏状态来获取说话人特征:
其中 𝐸 𝑗 𝑅 表示 𝐸𝑅 第 𝑗 层的输出。
内容特征通过 𝐸𝑅 和 𝐸𝑐
进行提取
其中 𝐸 𝐿 𝑅 表示 𝐸𝑅
最后一层的输出。
受文献[9]启发,我们采用AdaIN[13]来抑制声码器无关特征
𝑓 𝑎 中的合成无关信息。我们首先通过实例归一化对 𝑓 𝑎
进行归一化处理,然后通过匹配其均值和方差与 𝑓 𝑠
来恢复说话人线索,具体如下: