ANOMALYCLIP
ANOMALYCLIP: OBJECT-AGNOSTIC PROMPT LEARNING FOR ZERO-SHOT ANOMALY
DETECTION ![]()

Qihang Zhou1∗ , Guansong Pang2∗ , Yu Tian3 , Shibo He1† , Jiming Chen1†
1浙江大学2新加坡管理大学3哈佛大学
论文(arxiv)
# 摘要
零样本异常检测(ZSAD, Zero-shot anomaly detection )需要使用辅助数据进行训练的检测模型,以便在目标数据集中没有任何训练样本的情况下检测异常。这是一个至关重要的任务时,当训练数据无法访问由于各种问题,例如,数据隐私,但它是具有挑战性的,因为模型需要推广异常在不同领域前景对象的外观,异常区域和背景特性,如缺陷/肿瘤在不同的产品/器官,可以显著不同。最近,大型的预先训练的视觉语言模型(VLMs),如CLIP,在包括异常检测在内的各种视觉任务中显示出了很强的零样本识别能力。然而,它们的ZSAD性能较弱,因为vlm更关注于前景对象的类语义建模,而不是图像中的异常/正常性。
在本文中,我们介绍了一种新的方法,即AnomalyCLIP,使CLIP在不同领域的精确ZSAD。AnomalyCLIP的关键见解是学习与对象无关的文本提示,这些提示捕获图像中的一般正常性和异常性,而不管其前景对象如何。这使得我们的模型能够关注异常的图像区域,而不是对象的语义,从而能够对不同类型的对象概括归纳正常和异常识别。在17个真实异常检测数据集上进行的大规模实验表明,AnomalyCLIP在不同缺陷检测和医学成像领域的高度多样性类语义数据集的异常检测和分割方面具有优越的零镜头性能。
引用
本文的主要贡献如下。
1.
我们首次揭示了学习对象不可知的文本提示的正常和异常是一种简单而有效的准确的ZSAD方法。与目前主要为对象语义对齐而设计的文本提示方法
(Jeong et al., 2023; Zhou et al.,
2022b)相比,我们的文本提示嵌入模型语义的一般异常和正常,允许对象无关,广义ZSAD性能。
1.
然后,我们引入了一种新的ZSAD方法,称为AnomalyCLIP,其中我们利用一个对象不可知的提示模板和一个g局部异常损失函数(即全局和局部损失函数的组合)来学习通用异常和正常提示。在此过程中,AnomalyCLIP在很大程度上简化了提示设计,并可以有效地应用于不同的领域,而不需要更改其学习到的两个提示,这与WinCLIP等现有的方法不同,后者的有效性很大程度上依赖于对数百个手动定义提示的广泛工程。
1.
对来自不同工业和医学领域的17个数据集进行的综合实验表明,AnomalyCLIP在检测和分割来自缺陷检查和医学成像领域的高度多样性类语义数据集的异常方面具有优越的ZSAD性能。
方法
与对象无关的提示学习
方法概述
在本文中,我们提出了一种催化CLIP通过对象不可知的提示学习使CLIP适应ZSAD。
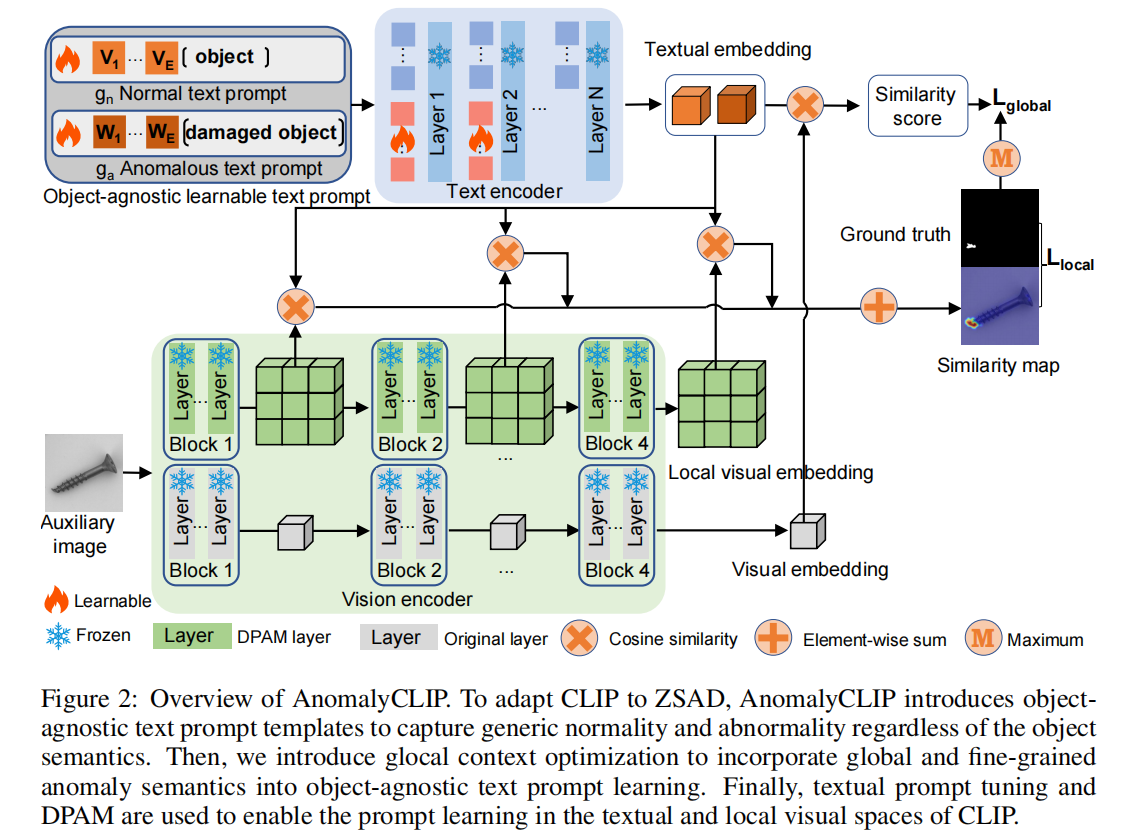
图2:AnomalyCLIP的概述。为了使CLIP适应于ZSAD,AnomalyCLIP引入了与对象无关的文本提示模板来捕获一般的正常性和异常性,而不管对象的语义如何。然后,我们引入了全局上下文优化,将全局和细粒度的异常语义纳入到对象不可知的文本提示学习中。最后,使用文本提示调优和DPAM,在CLIP的文本和局部视觉空间中实现提示学习。
如图2所示,AnomalyCLIP首先引入了对象不可知的文本提示模板,其中我们设计了 $ g_n $ 和 $ g_a $ 的两个通用的对象不可知的文本提示模板,分别学习正态类和异常类的广义嵌入(见Sec. 3.2)。为了学习这种通用的文本提示模板,我们引入了全局和局部上下文优化,将全局和细粒度的异常语义合并到与对象无关的文本嵌入学习中。此外,文本提示调优和DPAM还被用于支持在CLIP的文本和局部视觉空间中的学习。最后,我们整合了多个中间层,以提供更多的局部视觉细节。在训练过程中,所有模块通过全局和局部上下文优化进行联合优化。在推理过程中,我们量化了文本和全局/局部视觉嵌入的错位,以分别获得异常得分和异常得分图(见Sec.3.3)。