CLIP:Learning Transferable Visual Models From Natural Language Supervision
CLIP: Learning Transferable Visual Models From Natural Language Supervision
Alec Radford * 1, Jong Wook Kim * 1 , Chris Hallacy 1 , Aditya Ramesh 1 , Gabriel Goh 1 , Sandhini Agarwal 1, Girish Sastry 1 , Amanda Askell 1 , Pamela Mishkin 1 , Jack Clark 1 , Gretchen Krueger 1, Ilya Sutskever 1
摘要
当前最先进的计算机视觉系统通常被训练用于预测一组预设的固定物体类别。这种受限的监督方式限制了系统的通用性和实用性,因为要定义其他视觉概念还需要额外的标注数据。而直接从图像的原始文本中学习则是一种有前景的替代方案,它利用了更广泛的数据来源进行监督。我们证明,通过预测图像与对应文字描述的简单预训练任务,能够从互联网收集的4亿张(图像+文本)数据集零基础学习到最先进的图像表征方法,且该方法具有高效性和可扩展性。完成预训练后,自然语言被用来参照已学习的视觉概念(或描述新概念),从而实现模型在下游任务中的零样本迁移。我们通过在30多个现有计算机视觉数据集上进行基准测试,研究了该方法的性能表现。这些数据集涵盖OCR、视频动作识别、地理定位以及多种细粒度物体分类等任务。该模型能够轻松迁移至大多数任务,并且无需任何特定数据集训练,其性能通常可与全监督基线模型相媲美。例如,我们在ImageNet零样本上匹配原始ResNet-50的准确性,而不需要使用它所训练的128万个训练示例中的任何一个。我们在https://github.com/OpenAI/CLIP上发布我们的代码和预训练模型权重。
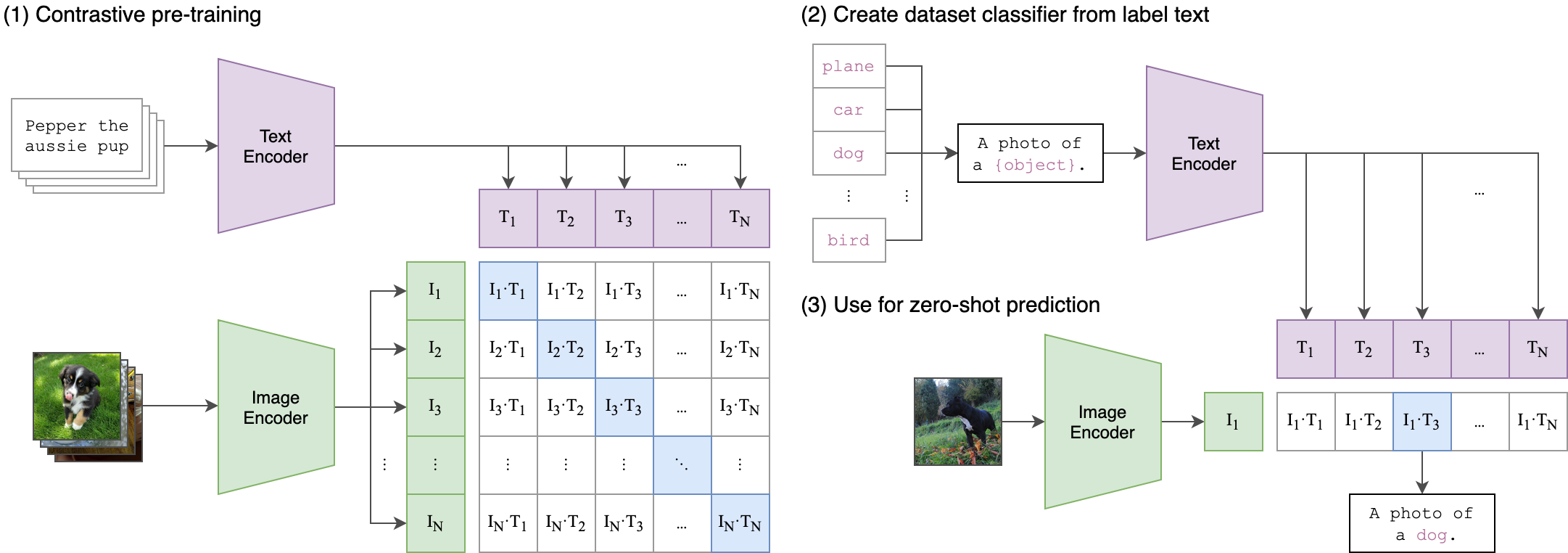
给定一批N(图像,文本)对,CLIP被训练来预测在N×N可能的(图像,文本)配对中实际发生的配对。为此,CLIP通过联合训练图像编码器和文本编码器来学习多模态嵌入空间,以最大化批次中N对真实图像和文本嵌入的余弦相似度,同时最小化N2−N个错误配对的嵌入的余弦相似度。我们对这些相似性分数进行了对称交叉熵损失的优化。图3展示了CLIP算法核心实现的伪代码。据我们所知,这种批量构建技术及其目标函数最初由Sohn(2016)在深度度量学习领域提出,作为多类别N对损失函数;随后被Oord等人(2018)推广应用于对比表示学习领域,命名为InfoNCE损失;最近张等人(2020)则将其改编为医学影像领域的对比(文本/图像)表示学习模型。
