CoOp:Learning to Prompt for Vision-Language Models
CoOp: Learning to Prompt for Vision-Language Models
Kaiyang Zhou · Jingkang Yang · Chen Change Loy · Ziwei Liu
S-Lab
南洋理工大学
新加坡
摘要
像CLIP这样的大型预训练视觉语言模型,在学习可迁移的表征方面展现出巨大潜力,这些表征能够跨多种下游任务有效迁移。与传统基于离散标签的表征学习不同,视觉语言预训练通过在共同特征空间中对齐图像和文本,使得零样本任务也能通过提示实现迁移——即通过自然语言描述目标类别来合成分类权重。在这项工作中,我们表明在实践中部署此类模型的主要挑战是提示工程,这需要领域专业知识和非常耗时——需要花费大量的时间在词语调优上,因为措辞的轻微变化可能会对性能产生巨大的影响。受自然语言处理(NLP)领域提示学习研究的最新进展启发,我们提出了一种名为“上下文优化”(Context Optimization,简称CoOp)的创新方法。该方案专门针对CLIP类视觉-语言模型在下游图像识别任务中的应用进行了优化设计。具体而言,CoOp通过可学习向量对提示词的上下文词汇进行建模,同时保持所有预训练参数不变。为应对不同图像识别任务,我们为CoOp提供了两种实现方案:统一上下文和类别特定上下文。通过在11个数据集上的大量实验,我们证明CoOp仅需一到两次样本就能以明显优势超越人工设计的提示词,并且在更多样本(如16次)时能显著提升效果——平均增益约15%,最高可达45%以上。尽管采用的是学习型方法,但与使用人工设计提示词的零样本模型相比,CoOp仍展现出卓越的领域泛化能力。
3方法
3.1视觉-语言预训练
我们简要介绍了视觉语言预训练方法,重点聚焦于CLIP模型(Radford等人,2021)。我们的方法适用于更广泛的CLIP类视觉语言模型。
模型
CLIP包含两个编码器,分别用于图像和文本处理。图像编码器旨在将高维图像映射到低维嵌入空间,其架构可采用类似ResNet-50(He
et al., 2016)或ViT (Dosovitskiy et al.,
2021)的卷积神经网络模型。而文本编码器则基于Transformer(Vaswani et al.,
2017)
构建,专门用于从自然语言中生成文本表示。
具体来说,给定一个词序列(标记),例如“一张狗的照片”,CLIP首先将每个标记(包括标点符号)转换为小写字节对编码(BPE)表示(Sennrich等人,2016),本质上是一个唯一的数字ID。CLIP的词汇表大小为49,152。为实现小批量处理,每个文本序列均添加[SOS]和[EOS]标记,并限制在77个字符以内。随后将ID映射到512维词嵌入向量,再输入Transformer模型。最后对[EOS]标记位置的特征进行层归一化处理,并通过线性投影层进一步优化。
训练
CLIP经过专门训练,能够将分别针对图像和文本学习的两个嵌入空间进行对齐。具体而言,其学习目标被定义为对比损失函数:当处理图像-文本配对数据时,CLIP会最大化匹配对的余弦相似度,同时最小化所有未匹配对的余弦相似度。为了学习更具迁移能力的多样化视觉概念,CLIP团队构建了一个包含4亿个图像-文本配对的大型训练数据集。
Zero-Shot推理
CLIP经过预训练,能够预测图像是否与文本描述匹配,因此天然适用于零样本识别任务。该方法通过将图像特征与文本编码器生成的分类权重进行对比实现,其中文本编码器以指定目标类别的文本描述作为输入。严格来说,设f为图像编码器提取的图像x的特征向量,{wi}是文本编码器生成的K个权重向量(i=1)。其中K表示类别数量,每个权重向量wi源自类似“一张[CLASS]的照片”的提示语句。这里的类标记会被替换为具体的类别名称,例如“猫”、“狗”或“汽车”。然后,预测概率计算如下:
\[p(y=i|x)={\frac{\exp(\cos(w_{i},f)/\tau)}{\sum_{j=1}^{K}\exp(\cos(w_{j},f)/\tau)}},\]
其中\(\tau\)是CLIP学习到的温度参数,\(cos(\cdot,\cdot)\)表示余弦相似度。
与传统分类器学习方法通过随机向量学习闭集视觉概念不同,视觉语言预训练允许通过高容量文本编码器探索开放集视觉概念,从而获得更宽泛的语义空间,并使学习到的表征更适用于下游任务。
3.2上下文优化
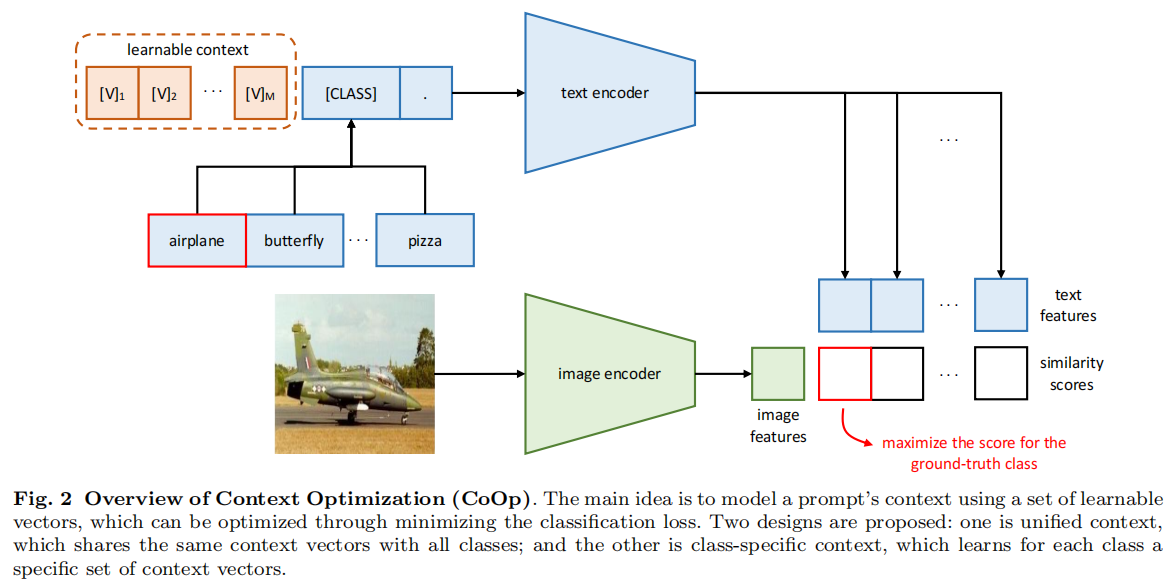
我们提出上下文优化(CoOp)技术,通过端到端学习从数据中提取连续向量来建模上下文词汇,同时冻结大量预训练参数,从而避免手动调整提示词。图2展示了该技术的概览。下文我们将介绍几种不同的实现方式。
统一上下文
我们首先介绍统一上下文方法,该方法与所有类别共享相同的上下文。具体而言,提供给文本编码器g(·)的提示采用以下形式设计:
\[t=[\mathrm{V}]_{1}[\mathrm{V}]_{2}\cdot\cdot\cdot[\mathrm{V}]_{M}[\mathrm{CLASS}],\]
其中每个\(\lbrack\mathbf{V}]_{m}\ \
(m\in\{1,\ldots,M\})\)是一个与词嵌入维度相同的向量(例如CLIP的512维),而M是超参数,用于指定上下文标记的数量。
通过将提示词t传递给文本编码器g(·),我们可以获得一个表示视觉概念的分类权重向量(仍来自[EOS]标记位置)。预测概率的计算方式如下:
\[p(y=i|x\rangle=\frac{\exp({\mathrm{cos}}(g(t_{i}),f)/\tau)}{\sum_{j=1}^{K}\exp({\mathrm{cos}}(g(t_{j}),f)/\tau)},\]
其中,每个提示ti中的类别标记被替换为第i个类别名称对应的词嵌入向量(s)。
除了像公式(2)那样将类标记放在序列的末尾,我们还可以将其放在中间位置。
\[t=[\mathrm{V}]_{1}\ldots[\mathrm{V}]_{\frac{M}{2}}[\mathrm{CLASS}][\mathrm{V}]_{\frac{M}{2}+1}\ldots[\mathrm{V}]_{M},\]
这增加了学习的灵活性——提示可以用来补充描述,也可以通过句号等终止信号提前切断句子。
特定类的上下文
另一种选择是设计类特定上下文(CSC),其中上下文向量与每个类别相互独立,即\([\mathbf{V}]_{1}^{i}[\mathbf{V}]_{2}^{i}\cdot\cdot\cdot[\mathbf{V}]_{M}^{i}\neq[\mathbf{V}]_{1}^{j}[\mathbf{V}]_{2}^{j}\cdot\cdot\cdot[\mathbf{V}]_{M}^{j}\)其中i,j∈{1,...,K}。相较于统一上下文,我们发现CSC在某些细粒度分类任务中具有显著优势。
训练
训练过程旨在通过交叉熵最小化标准分类损失,同时利用参数中编码的丰富知识,使梯度能够反向传播至整个文本编码器g(·)以优化上下文。连续表示的设计还允许在词嵌入空间中进行充分探索,这有助于学习与任务相关的上下文信息。
3.3讨论
我们的方法专门针对近期提出的大型视觉语言模型如CLIP(Radford等人,2021)在适应性训练方面的新挑战。与自然语言处理领域开发的语言模型提示学习方法例如GPT-3(Brown等人,2020)相比,我们的方法存在两个显著差异:首先,CLIP类模型与语言模型的主干架构截然不同——前者同时接收视觉和文本数据作为输入,并生成用于图像识别的对齐分数;后者则专为处理纯文本数据而设计。其次,预训练目标也存在差异:对比学习与自回归学习。这种差异将导致模型行为的不同表现,从而需要采用不同的模块设计。