Contextrast:Contextual Contrastive Learning for Semantic Segmentation

Contextrast: Contextual Contrastive Learning for Semantic Segmentation

摘要
尽管在语义分割方面有了很大的改进,但由于缺乏局部/全局上下文以及它们之间的关系,挑战仍然存在。在本文中,我们提出了上下文分析法,一种基于对比学习的语义分割方法,它允许捕获局部/全局上下文并理解它们之间的关系。我们提出的方法包括两部分:a)上下文对比学习(CCL)和b)边界感知负值(BANE,boundary-aware negative)抽样。上下文对比学习从多尺度特征聚合和特征间/内部关系中获得局部/全局上下文信息,从而获得更好的识别能力。同时,BANE采样选择沿错误预测区域边界的嵌入特征,作为对比学习的硬负样本,利用细粒度细节解决沿边界区域的分割问题。我们证明了我们的上下文结构大大提高了语义分割网络的性能,在不同的公共数据集上优于最先进的对比学习方法,如Cityscapes、CamVid、PASCALC、COCO-Stuff和ADE20K,而不增加推理过程中的计算成本。
1.介绍
语义分割是一种广泛应用的基本技术,包括自动驾驶、医学成像和机器人[12,13,18,32,37,40]。最近的实证研究在语义分割方面取得了显著的进展,显著地得益于广泛的数据集[1,2,9,10,29,55]的可用性。为了提高分割性能,研究人员提出了更大的深度神经网络(DNN)架构(4-8、11、14、16、19、21、24、25、27、34、35、39、42-44、46-49、51-54、56]和新的损失函数[36,38,50]。
尽管取得了这些成就,但语义分割有时会产生不准确的分割,如图1(b)所示。
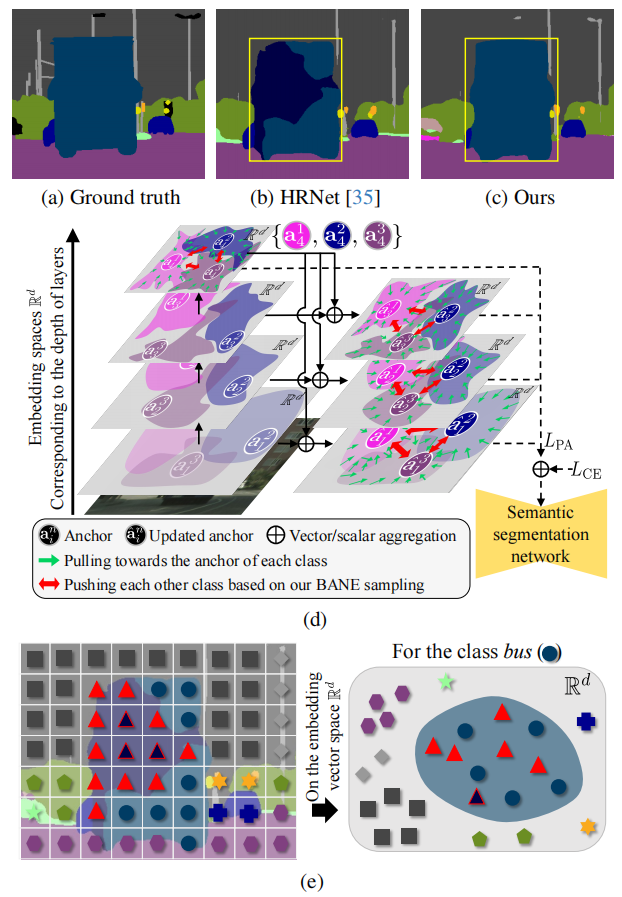
图1.(a)Ground truth,(b)HRNet [35]的输出,和(c)我们的输出。(d)我们的上下文对比学习(CCL,contextual contrastive learning)概述:最后一层的代表性锚,来自较高的嵌入空间级别,被聚合到较低层的代表性锚,以封装局部和全局上下文。通过这样做,在第i层\(\mathbf{a}_{i}^{n}\)上的第n类锚被更新为\(\mathbf{\hat a}_{i}^{n}\)(在右边,它的位置被移动),增强了每个类锚之间的区别性。(e)视觉描述我们的边界感知负值(BANE)采样(具有红色和红色边界的三角形)。我们的抽样优先选择在边缘(红色三角形)上的错误预测的特征,而不是在区域内(带有红色边框的三角形)作为负样本。每个形状都代表一个从各自的类派生出来的嵌入向量(最好用颜色来看)。
它可以通过增加网络[25,27,34,42,43]的复杂性来解决;然而,这些方法需要更多的内存,并可能会降低推理速度。因此,有必要在不增加任何神经网络模块的情况下提高性能。
由于这些原因,另一种值得注意的方法,对比学习,已经成为一个有价值的解决方案[17,41],因为对比学习的目的是使网络在训练过程中更好地理解语义上下文。这是通过在训练阶段附加细化模块并将它们在推理上分离来实现的,以便网络模型在不增加架构复杂性的情况下保持推理速度。
然而,以往的研究[17,41]忽略了多尺度特征的重要性,包括全局和局部背景。为了缓解这一问题,Pissas等人[31]提出了一种从多个编码器层中提取多尺度嵌入特征的方法。然而,由于多尺度和跨尺度的对比学习是独立考虑的,因此该方法并不能一致地理解不同尺度特征之间的关系。因此,它很难理解本地和全球环境之间的关系。
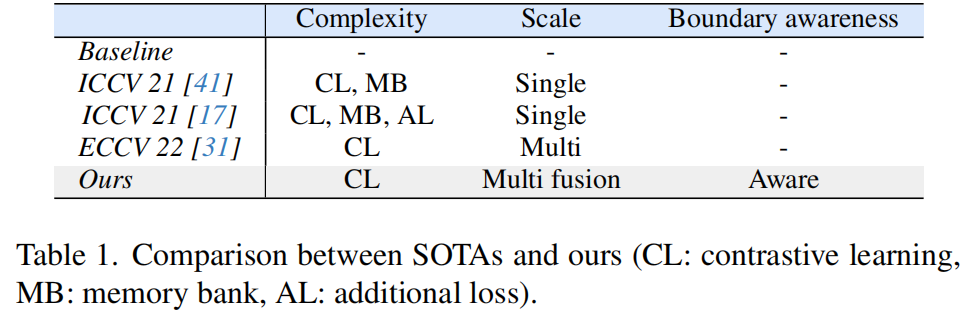
为了解决上述问题,我们提出了一个有监督的对比学习框架,其中结合了两种新的语义分割方法,称为上下文统计法。首先,提出了上下文对比学习(CCL),从代表局部和全局上下文的多个编码器层中获取嵌入式特征。基于嵌入的特征,我们在每一层中定义具有代表性的锚点,它们作为每个类的语义质心。最后一层的锚比下层的锚代表更多的全局上下文。最后一层的锚点用于更新每层的锚点(图1(d)中的绿色箭头)。因此,较下层的锚点可以同时具有全局和局部上下文。因此,它使用更新的代表性锚点,即共享相同的全局上下文,一致地理解本地和全局上下文之间的关系。其次,受关注边界区域的[50]和[38]的启发,提出了边界感知负样本(BANE)采样,以沿着错误预测区域的边界对负样本进行采样(图1(e))。它利用了采样更难的负样本和捕获细粒度细节的优点,因此所提出的方法在[20,41]训练过程中获得了更多的信息梯度。我们总结了最先进的方法和我们的方法的几个关键特性,如表1所示。
综上所述,本文的贡献如下:
- 我们的Contextrast使分割模型能够从多尺度特征中捕获全局/局部上下文信息,并通过具有代表性的锚点一致地理解它们之间的关系。
- 我们的BANE采样能够获取信息负样本的对比学习和细粒度细节。它指导模型在训练过程中逐步关注混淆区域。
- 为了证明我们的上下文在语义分割中的适用性,我们验证了在各种强大的CNN模型[6,35,49]和公共数据集上的语义分割的先进性能:Cityscapes[9],CamVid [1],PASCAL-C [29],COCO-Stuff [2]和ADE20K [55],它们是在不同领域获得的。
2.相关工作
2.1.语义分割
语义分割是计算机视觉中的一项基本任务,它需要对图像进行像素级的对象分类。近年来,深度学习的显著进步推动了语义分割领域达到了前所未有的准确性和效率水平。首先,全连接网络(FCNs)[28]通过引入端到端密集特征学习,在语义分割方面取得了重大进展。然而,由于局部接受域狭窄,FCNs的空间和背景信息有限。
因此,以下研究人员专注于在语义分割中捕获更好的空间和上下文信息。空间空间金字塔池(ASPP)[6]捕获不同范围的上下文信息。HRNet
[35]在整个网络中维护高分辨率的表示,确保了细粒度细节的保存。为了进一步改进,引入了OCRNet
[49]架构,该架构集成了对象-上下文表示,允许网络考虑场景中对象之间的关系。由于这些先进的方法利用个体图像中的上下文信息来学习辨别能力,因此全局特征辨别能力存在局限性。
2.2.语义分割的对比学习
对比学习是一种特征学习准则,其目的是最小化类内特征之间的距离,同时最大化类间特征之间的距离。语义分割[17,22,31,41]对比学习的最新进展显示了令人印象深刻的性能。
Hu等人[17]和Wang等人[41]提出了一种完全监督设置下的语义分割方法,该方法探索全局像素关系,从多个图像中提取特征,全局正则分割嵌入空间。Wang等人[41]引入了记忆库和分割感知的负采样方法,存储大量数据来训练独特的表示,并在训练过程中获得更多的梯度贡献。Hu等人[17]引入了由正样本生成的类加权区域中心,作为对比学习的锚点。然而,仅关注正样本进行加权可能会降低模型的识别能力。此外,[17,41]除了忽略了最后一层的特征外,还忽略了多个尺度的特征,因此它们只捕获有限的局部/全局上下文以及局部和全局上下文之间的关系。
最后,Pissas等人[31]提出了一种利用多尺度特征进行监督对比学习的方法。也就是说,研究者将对比学习应用于多尺度和跨尺度的特征。通过这样做,[31]方法从多尺度特征中获取全局/局部上下文信息,并从跨尺度特征中获取局部和全局上下文之间的关系。然而,由于多尺度和跨尺度的对比学习是分开操作的,因此它不能一致地掌握跨特征尺度的关系。在某些情况下,特征在多尺度和跨尺度对比学习中可以有不同的排列。例如,在跨尺度对比学习中,通过多尺度对比学习改变的特征可能会发生不同的变化。
3.Contextrast:使用BANE抽样的上下文对比学习
3.1.总体框架
如图2所示,我们提出了一个包含两种新的语义分割方法的监督对比学习框架。
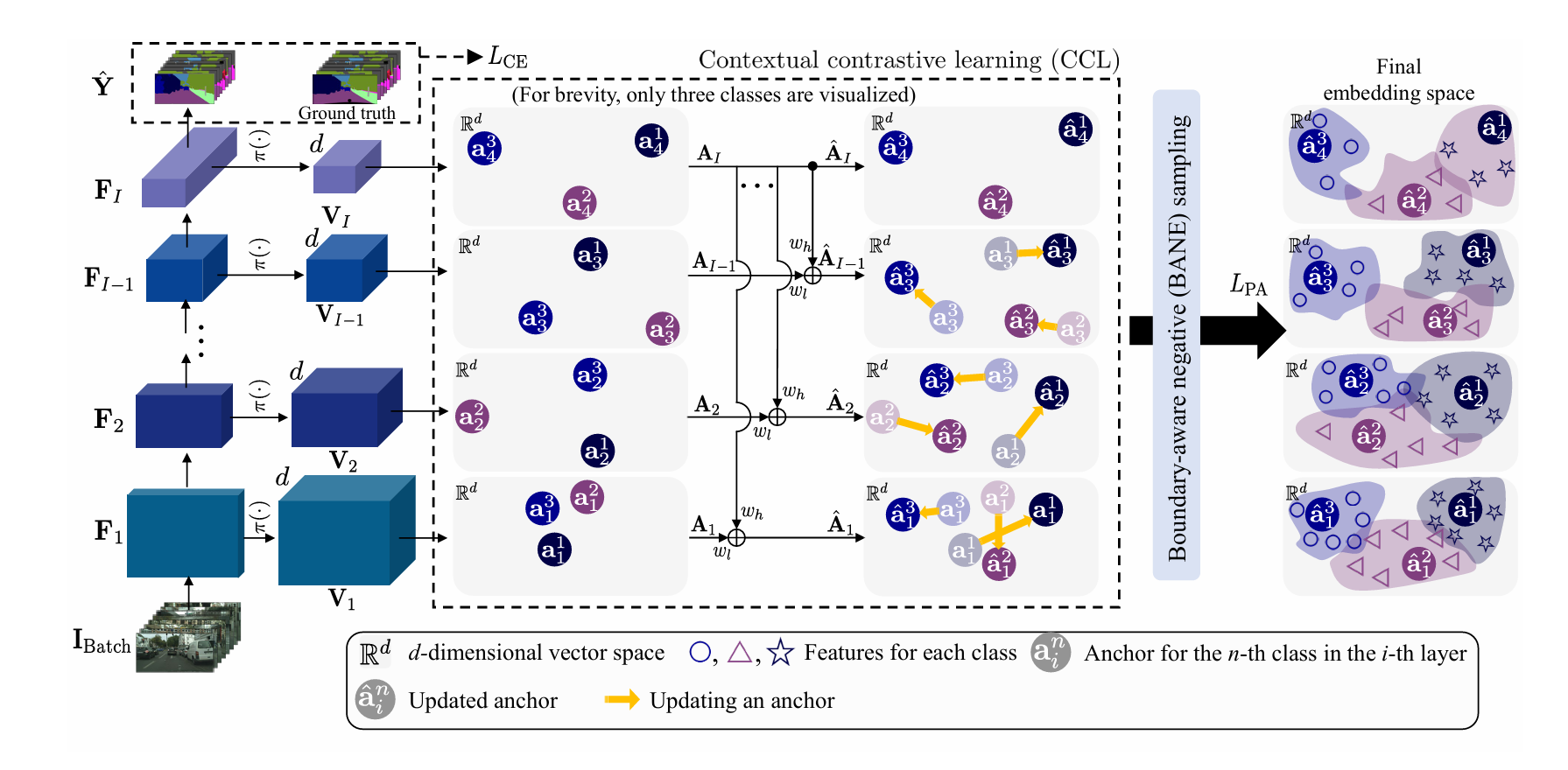
图2.Contextrast框架整体架构。该框架采用由语义丰富的代表性锚点向量集AI更新的代表性锚点,整合局部与全局上下文及其关联关系。BAE采样算法通过在预测误差区域边界处采样样本,获取更具信息量的负样本并捕捉对比学习所需的细粒度特征细节。IBatch表示批量图像数据,Yˆ为模型预测结果,Fi是第i层编码器的特征图,Vi是编码函数π(·)生成的第i组嵌入特征向量,Ai代表第i个嵌入特征向量的代表性锚点。更新后的代表性锚点Aˆ_i由低层级与高层级锚点叠加生成,权重参数wh和wl用于优化代表性锚点。LPA是提出的像素-锚点损失函数,LCE为交叉熵损失函数。各语义类别的特征以不同形状和颜色呈现(最佳效果需彩色查看)。
首先,我们提出了一个代表性锚点的概念,它是多尺度感知的显著特征,通过利用层次设计隐式地表示类,如章节3.2所述。其次,我们故意对被错误预测为负样本的区域内边界对应的特征进行采样,如章节3.3所述。
3.2.上下文对比学习(CCL)
我们假设编码器由\(I\)层组成。然后,我们首先将第i个编码器层对应的代表性锚点表示为\(A_i\),其中i∈{1,···,I}。\(A_i\)由N个类级别代表性锚组成。第n类的每个锚用\(\mathbf{a}_{i}^{n}\in\mathbb{R}^{d}.\)表示,定义为批图像中
ground-truth语义类嵌入特征向量的平均值如下: \[\mathbf{a}_i^n=\frac{\sum_{\mathbf{v}\in\mathbf{V}_i}\mathbf{v}\mathbb{1}[g(\mathbf{v})=n]}{\sum_{\mathbf{v}\in\mathbf{V}_i}\mathbb{1}[g(\mathbf{v})=n]},n=1,2,...,N,\]
其中\(\mathbf{V}_i\)是基于第i个编码器层\({\textbf{f}}\in{\textbf{F}}_{i}\)特征映射特征的嵌入特征向量集,如图2所示,即\(\mathbf{v}=\pi(\mathbf{f})\);\(g(\cdot)\)表示一个函数,返回每个嵌入特征向量的ground-
truth语义标签;\(\mathbb{1}[\cdot]\)是艾弗森括号,如果条件满足则输出一个,则为零。通过使用等式(1),\(A_i\)表示为\(\mathbf{A}_{i}=\{\mathbf{a}_{i}^{1},\mathbf{a}_{i}^{2},...,\mathbf{a}_{i}^{N}\}\)。为了方便起见,我们以矩阵形式来表示\(A_i\),即\(\mathbf{A}_{i}=[\mathbf{a}_{i}^{1}\,\mathbf{a}_{i}^{2}\,\dots\,\mathbf{a}_{i}^{N}]\in\mathbb{R}^{d\times
N}\)。
然后,用最后一层\(A_I\)的代表性锚点更新低级锚点\(A_i\),以封装高级和低级上下文,从而考虑多尺度。因此,更新后的代表性锚点\(\hat A_i\)被定义为\(\hat{\bf A}_{i}=w_{l}{\bf A}_{i}+w_{h}{\bf
A}_{I}=\{\hat{\bf a}_{i}^{1},\hat{\bf a}_{i}^{2},\ldots,\hat{\bf
a}_{i}^{N}\}\),其中,wl和wh是锚点更新的权重超参数(见图2)。通过更新低级锚,\(\hat
A_i\)可以作为捕获不同尺度的关系的标准。当\(i=I\)时,\(A_I\)被定义为\(\hat A_I=A_I\)。 \[L_{\mathrm{NCE}}=\frac{-1}{|{\bf
V}_{+}|}\sum_{\bf v_+\in\bf V_+}\log\frac{\exp({\bf v}\cdot{\bf
v}_+/\tau)}{\exp({\bf v}\cdot\bf v_+/\tau)+\sum_{\bf v_-}\exp({\bf
v}\cdot\bf v_-/\tau)},\] 接下来,我们在等式(2)中将\(\hat A_i\)加入InfoNCE
[15,30]损失,其称为像素锚点(PA,pixel-anchor)损失,如下: \[L_{\mathrm{PA}}=\sum_{i=1}^{I}\lambda_{i}\biggl[{\frac{1}{N}}\sum_{\hat{\bf{a}}_{i}^{n}\in\hat{\bf{A}}_{i}}\frac{-1}{|{\bf
V}_{+}|}\sum_{\bf v_+\in\bf V_+}L_a\biggr]\]
\[L_a=\log\frac{\exp(\hat{\mathbf{a}}_i^n\cdot\mathbf{v}_+/\tau)}{\exp(\hat{\mathbf{a}}_i^n\cdot\mathbf{v}_+/\tau)+\sum_{\mathbf{v}_-\in\mathbf{V}_-}\exp(\hat{\mathbf{a}}_i^n\cdot\mathbf{v}_-/\tau)}\]
其中,v+/−分别表示正样本和负样本,λi表示第i个编码器层像素锚对比损失的权重超参数。而等式(2)中的锚点是个体特征的集,等式(4)中的锚点是代表性锚点的集合\(\hat
A_i\)。像素锚损失的目的是通过最小化类内特征与其对应的代表性锚之间的距离来优化嵌入特征,同时最大限度地提高类间特征与其对应的代表性锚之间的分离。因此,该网络以具有代表性的锚点为标准,从多尺度特征及其连接中获取全局背景和复杂的细节。
此外,像素-锚定损失与传统的像素级交叉熵损失LCE
[35]相结合,提供了一种提高分割性能的补充方法。这种协同作用是有目的的:像素级交叉熵损失的目的是预测每个样本的正确标签,而像素级锚定损失的目的是通过考虑不同样本之间的关系来学习良好的数据表示。
因此,整个框架的主要目标是优化以下损失:
\[L=L_{\mathrm{CE}}+\alpha
L_{\mathrm{PA}},\] 其中,α表示像素锚定损失的权重。
3.3.边界感知负值(BANE)采样
在增强损失函数的同时,我们还提出了一种有效的负值抽样方法,即考虑预测误差的边界,以提高等式(4)中v−的质量。为此,我们采用了一种简单而有效的从\(\hat Y\)提取中边界的方法。该方法主要包括三个步骤,如图3所示:
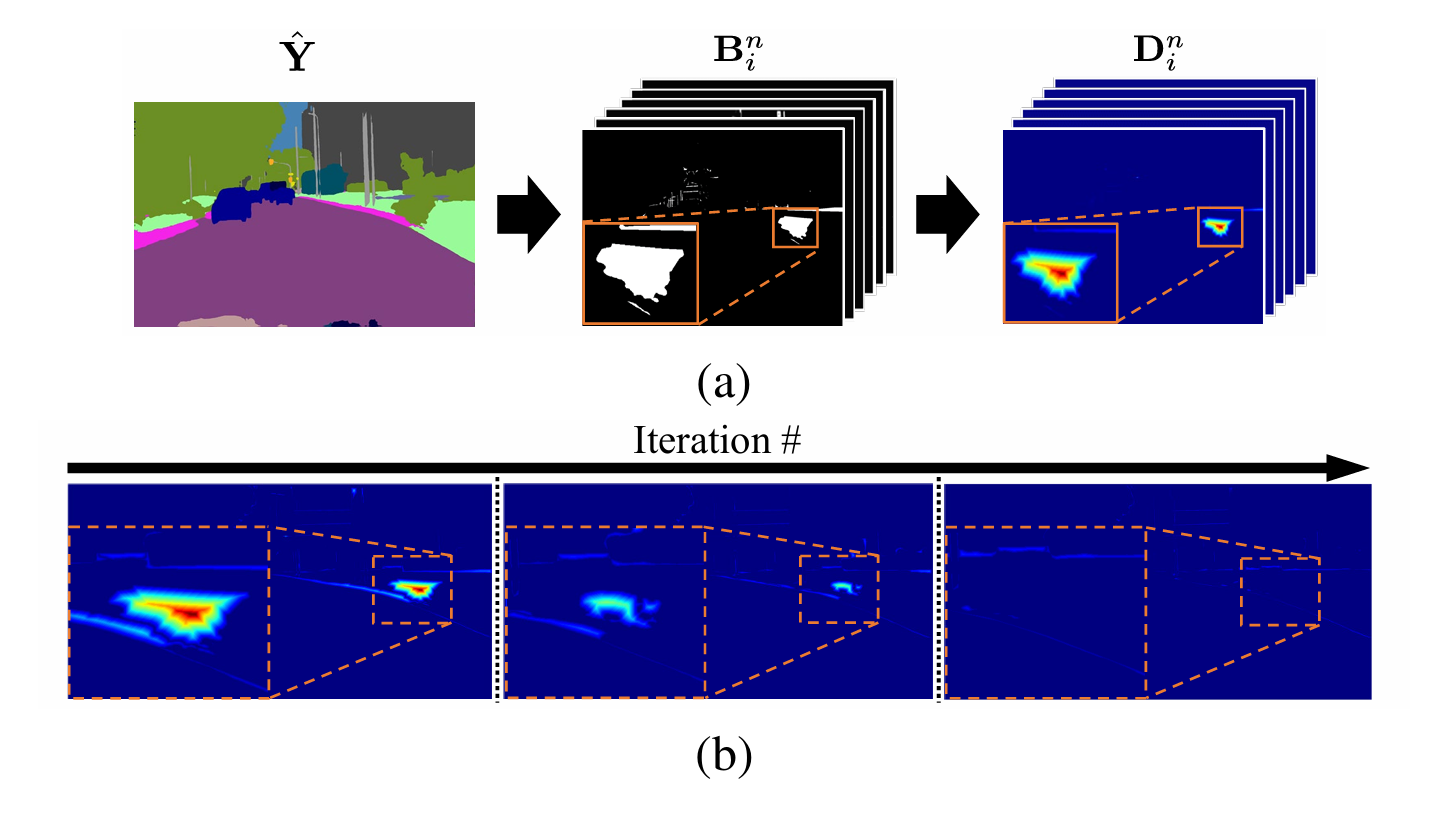
图3.边界感知负采样技术的可视化说明及训练过程中如何解决欠分割/过分割问题。(a)预测结果\(\hat Y\)被分解为类别二值化图\(B^n_i\)。随后通过距离变换算法[23]生成类别间距离图\(D^n_i\)。(b)距离图在迭代过程中的演变轨迹。训练过程中错误预测区域逐渐缩小(彩色视图中效果最佳)。
1)将预测输出分解为类级二值误差图,2)基于类级误差图进行距离变换,3)选择负样本。
为了提取负样本,每个像素(u,v)的类二进制误差映射\(\mathbf{B^n_i}\)定义为: \[{\bf B}_{\
i}^{n}(u,v)=\mathbb{1}[(\hat{y}_{i}\neq{n})\wedge(g(\hat{y}_{i})={n})],\]
其中,\(\hat{y}_{i}\)表示从最后一层的预测类降采样的第i层的预测类。g(·)表示与3.2节中相同的标记函数。对于错误预测的像素,\({\bf
B}_{i}^{n}\)的值为1,即为负样本,否则为零,如图3(a)所示。
接下来,通过距离变换[23]将\({\bf B}_{i}^{n}\)的转换为类向距离映射\({\bf D}_{i}^{n}\)的。\({\bf
D}_{i}^{n}\)的像素值是像素(u,v)与边缘像素\({\bf
E}_{i}^{n}\)之间的最小距离,来自对应的类误差映射,定义如下:
\[{\bf
D}_{i}^{n}(u,v)=\operatorname*{min}_{(x,y)\in{\bf
E}_{i}^{n}}\sqrt{(u-x)^{2}+(v-y)^{2}}.\]
这意味着在错误预测的区域内,\({\bf
B}_{i}^{n}\)的像素值为1(图3(a)中的白色区域),值越低表示像素在边界上的概率越高。
最后,在\({\bf
B}_{i}^{n}\)中值为1的区域中,我们选择对应于\({\bf
D}_{i}^{n}\)中最小距离较低的前百分之K的嵌入向量作为等式
(4)中第n个代表锚点的负样本。通过将这些向量纳入到等式(3)中,Contextrast允许这些向量接近真实类别的锚点,而远离在训练过程中被错误预测类别的特征。因此,这些具有边界感知能力的负样本有助于网络更好地学习分割类之间的空间间关系。
4.实验
4.1. 实验设置
数据集
我们使用五个公共数据集进行实验:Cityscapes[9]、ADE20K
[55]、PASCAL-C [29]、COCO-Stuff [2]和CamVid
[1]数据集。为了进行公平的比较,我们遵循数据集现有的训练和验证设置(细节在补充材料中解释)。其中,由于城市景观数据集通过使用测试数据另外提供了公共基准测试,因此我们使用后缀测试来区分验证集和测试集,即Cityscapes测试。
训练设置。
为了证明我们提出的方法的有效性,我们采用了三种网络:
a) DeepLabV3 [6],b) HRNet [35],和c) OCRNet
[49]。DeepLabV3中使用了D-ResNet-101主干网络。HRNet和OCRNet网络采用HRNetV2-W48主干网络。我们使用相同的超参数,并在ImageNet
[10]上使用预先训练的权值初始化网络,而其余的层被随机初始化。我们使用颜色抖动、水平翻转和随机缩放来增强数据。采用随机梯度下降(SGD)作为CNN骨干的优化器,动量为0.9。此外,采用多项式退火策略[6]来调度学习速率,它乘以\(\left(1-\frac{Iteration }{Total\
iterations}\right)^{0.9}\)。\(\lambda_{4\rightarrow1}\)被设置为1.0、0.7、0.4和0.1。α被设置为0.1。在Cityscapes数据集上,我们为40K次迭代设置了8的批处理大小,并从1024×2048裁剪到512×1024。该模型在CamVid数据集上训练,批大小为16,进行6K迭代。在ADE20K上,模型被训练的作物大小为512×512,批处理大小为12,80K迭代。在COCO-Stuff和PASCAL-C上,模型以512×512和16的批处理大小进行训练。请注意,我们不使用任何额外的训练数据。
测试设置。
我们遵循一般设置[6,35,49],对CamVid、COCO-Stuff、ADE20K和PASCAL-C数据集在多个尺度上平均分割结果。缩放因子从0.75设置到2.0,间隔为0.25。我们采用单尺度的城市景观评价来遵循多/跨尺度对比学习[31]的实验设置。
评价指标。
在实验中,我们定量分析了a)语义分割结果和b)特征特征的性能。
为了评价语义分割的性能,使用类并联合(mIoU)[17,41]的平均值作为评价度量。对于城市景观测试,一个实例级的交叉过联合度量(iIoU)[9]也被用来评估单个实例如何被很好地分割。这是因为mIoU可能会偏向于覆盖街景中较大图像区域的对象实例。iIoU的定义如下:
\[\mathrm{i}\mathrm{Io}\mathrm{U}=\frac{\mathrm{i}\mathrm{TP}}{\mathrm{(iTP+FP+iFN)}}\]
其中,iTP、FP、iFN分别表示真阳性、假阳性和假阴性像素的数量。请注意,iTP和iFN是根据每个类的平均实例大小与相应的地面真实实例大小的比值,用加权像素贡献来计算的。接下来,特征级分析,我们采用以下三个指标:类内对齐(A)评估类内特征紧密聚集,类间一致性(U)评估多远的质来自不同类的特征分离嵌入空间,和类间社区均匀性(Ul)测量l的分离,这表明如何清楚l最近的质心之间的决策边界的区别。更多的细节可以在[26]中找到(见第4.3节)。
4.2.语义分割性能
4.3.特征级别的深入分析
4.4.消融研究
4.5.结论
在本文中,我们提出了一种新的边界感知对比学习的语义分割,称为Contextrast。通过利用多尺度的上下文对比学习,我们使网络能够捕获局部/全局上下文信息,并始终理解它们之间的关系。特别是,我们证明了我们的BANE抽样通过在对比学习阶段提供更困难的BANE负样本,显著增加了mIoU。因此,与在公共数据集上的其他对比学习方法相比,我们的方法取得了很好的结果。
5.补充材料
5.1.详细说明实验设置和实验数据集
实验设置的详细情况见表1。这些数据集的细节描述如下。
- Cityscapes[3]包括来自德国50个城市的图像,包括农村和城市环境。它包含5000张具有2975张训练图像的图像,500张验证图像和1525张具有19个语义类的测试图像。
- ADE20K [10]有描绘各种场景的图像,包括室内和室外环境。与专注于自动驾驶等特定领域的数据集不同,ADE20K包含了不同的场景,如卧室、办公室、公园等。它包括20,210个训练图像和2,000个验证图像,其中包含150个语义类。
- PASCAL-C [5]包含4998个训练图像和5105个测试图像,包含59个语义类。它还包括室内和室外的环境。
- COCO-Stuff [2]拥有9000张火车和1000张测试图像。它提供了80个对象类和91个东西类。
- CamVid [1]包含367个训练图像、101个验证图像和233个包含11个语义类的测试图像。
5.2.特征级别分析指标的详细说明
我们采用了来自[4]的评价指标,表示为对齐、均匀性和邻域均匀性。类内对齐,记为A,表示类内特征的收敛程度,定义如下:
\[\mathrm{A}={\frac{1}{N}}\sum_{i=1}^{N}{\frac{1}{|V_{i}|^{2}}}\sum_{v_{j},v_{k}\in
V_{i}}||v_{j}-v_{k}||_{2},\]
其中,N、i、Vi分别表示语义类的数量、第i个语义类和第i个语义类的特征集。通过这样做,等式(1)表示类内特征在到达分割头之前聚集的紧密程度。类内特征的有效聚类意味着提高了识别能力。
类间均匀性,记为U,表示类间特征中心在特征空间中的分离程度,定义如下:
\[\mathrm{U}=\frac{1}{N(N-1)}\sum_{i=1}^{N}\sum_{j=1,j\neq
i}^{N}||\mu_{i}-\mu_{j}||_{2},\]
其中,N和μi分别表示语义类的数量和第i个语义类的中心。
最后,邻域均匀性记为Ul,测量类间特征的l个最近中心的分离。邻域一致性的定义如下:
\[U_{l}=\frac{1}{N
l}\sum_{i=1}^{N}\operatorname*{min}_{j_{1},\cdots,j_{l}}\left(\sum_{j=1,j\not=i}^{l}||\mu_{i}-\mu_{j}||_{2}\right).\]
均匀性和邻域均匀性都暗示了该模型定义类间特征之间的决策边界。因此,对齐A、均匀性U和邻域均匀性Ul代表了模型区分类内和类间特征的能力。
5.3.损失函数的梯度
在本节中,我们证明对比学习中的硬负样本在训练过程中带来更多的梯度贡献。提出的损失函数如下: \[\begin{align*}L_i = \frac{1}{N} \sum_{\hat{a}_i^n \in \hat{A}_i} \left| \frac{1}{V_+} \right| \sum_{v_+ \in V_+} L_{\hat{a}},\end{align*}\]
\[\begin{align*}L_{\mathbf{a}} = -\log \frac{\exp \left( \hat{\mathbf{a}}_i^n \cdot \mathbf{v}_+ /{\tau} \right)}{\exp \left( \hat{\mathbf{a}}_i^n \cdot \mathbf{v}_+ /{\tau} \right) + \sum_{\mathbf{v}_- \in \mathbf{V}_-} \exp \left( \hat{\mathbf{a}}_i^n \cdot \mathbf{v}_- /{\tau} \right)}\end{align*}\]
然后,得到了\(L_{i}\)对锚点\(\hat{\bf{a}}_{i}^{n}\)的导数如下: \[\begin{align*}\frac{\partial L_i}{\partial \dot{a}_i^n} = \frac{-1}{\tau N | V_+|} \sum_{\dot{a}_i^n \in \dot{A}_i} \sum_{v_+ \in V_+} \left((1-p_+) \cdot v_+ - \sum_{v_- \in V_-} p_- v_- \right),\end{align*}\] 其中,\(p_{+/-}=\frac{\exp{\hat{\bf{a}}_{i}^{n}\cdot v_{+/-}/\tau}}{\sum_{v\in V}\hat{\bf{a}}_{i}^{n}\cdot v/\tau}\)表示锚点与样本之间的匹配概率。因此,一旦我们通过BANE抽样对较硬的负样本进行采样,锚点\({\bf{a}}_{i}^{n}\)和负样本v−之间的点积接近于1。因此,负p−的匹配概率增加了。因此,当负样本较硬时,损失函数的梯度增大。
5.4.其他定量结果
5.5.其他定性结果
5.6.特征级分析的定性比较
5.7.额外的消融研究
5.8.限制性分析
本文提出了在层次结构中利用代表性锚点的上下文变换法。因此,它允许在每个层中共享高级特性的全局上下文。它在公共数据集上主要取得了最先进的性能,但COCO-Stuff [2]和PASCAL-C [5]的改进没有CamVid [1]、Cityscapes[3]和ADE20K [10]那么大。我们认为,在最后一层有广义的代表性锚点是有限制的,因为一些数据集在场景中有这么多不同的类;上下文法对每个类只有有限的特性,训练批处理大小有限。在未来,我们计划进一步研究如何在不增加训练批规模的情况下,在许多数据集中推广代表性锚点。