Contrastive_learning_semantic_segmentation
总结对比学习在语义分割任务上的最新sota
一、语义分割对比的数据集和评价标准
1.数据集
五个公共数据集进行实验:Cityscapes、ADE20K、PASCAL-C 、COCO-Stuff 和CamVid 数据集。
2.评价指标
使用类并联合(mIoU)的平均值作为评价度量。
一个实例级的交叉过联合度量(iIoU),其定义如下:
\[\mathrm{i}\mathrm{Io}\mathrm{U}=\frac{\mathrm{i}\mathrm{TP}}{\mathrm{(iTP+FP+iFN)}}\]
其中,iTP、FP、iFN分别表示真阳性、假阳性和假阴性像素的数量。请注意,iTP和iFN是根据每个类的平均实例大小与相应的地面真实实例大小的比值,用加权像素贡献来计算的。
特征级分析,我们采用以下三个指标:
类内对齐评估类内特征紧密聚集,
类间一致性(U)评估多远的质来自不同类的特征分离嵌入空间
类间社区均匀性(Ul)测量l的分离,这表明如何清楚l最近的质心之间的决策边界的区别
二、sota方法的对比
1.Contextrast
Contextrast:Contextual Contrastive Learning for Semantic Segmentation(CVPR2024)
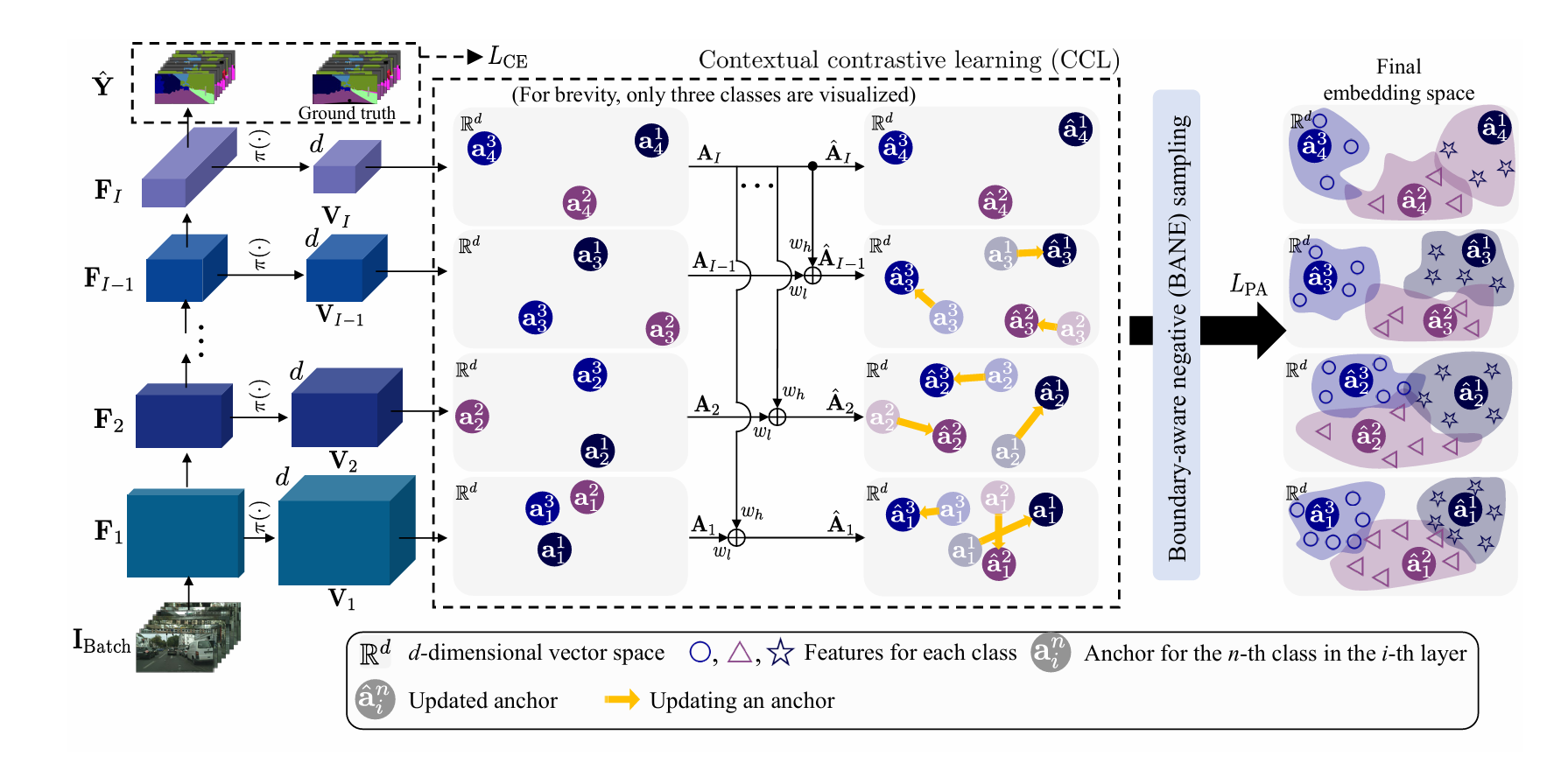
其提出了上下文对比学习,即是使用InfoNCE对比学习在多个尺度上让同一实例对齐;
提出了边界感知负值采样,即首先得到每个类的二进制误差映射\(\mathbf{B^n_i}\)(错误预测的像素为1),然后计算在每个像素点和边缘像素点最近的距离,作为每个像素点的类向距离映射\({\mathbf D_{i}^{n}}\),最后,在\({\bf
B}_{i}^{n}\)中值为1的区域中,我们选择对应于\({\bf
D}_{i}^{n}\)中最小距离较低的前百分之K的嵌入向量作为损失函数中第n个代表锚点的负样本。
2.PRCL
PRCL:Probabilistic Representation Contrastive Learning for Semi-Supervised Semantic Segmentation(IJCV 2024)
基于像素级对比学习的半监督语义分割任务的gt中,难免出现噪声,这会影响到无监督的训练部分,为解决这一问题,提出了一种基于概率表示对比学习(PRCL)框架的鲁棒性增强方案,显著提升了无监督训练的稳健性。通过多元高斯分布将像素级表征建模为概率表示(PR),并动态调节模糊表征的贡献度,有效规避了对比学习中引导信息失准的风险。
由于伪标签的不准确性和类内方差导致表征差异,这种做法容易引发相邻迭代中的原型偏移现象。我们认为原型一致性对于建立表征聚合的稳定方向至关重要。负样本表征来自当前小批量数据,而小批量数据规模有限,导致负样本表征的分布呈现碎片化特征。为突破这些局限,我们从全局视角重新构思像素级对比学习方法,基于概率化表征构建全局分布原型。
面对半监督的语义分割任务,存在Nl对有着像素级标签的标注数据集Dl和Nu张未标注图像的未标注数据集,基础分割模型包含编码器f(·)和分割头g(·),我们采用教师-学生框架,并将像素级对比学习融入框架设计。
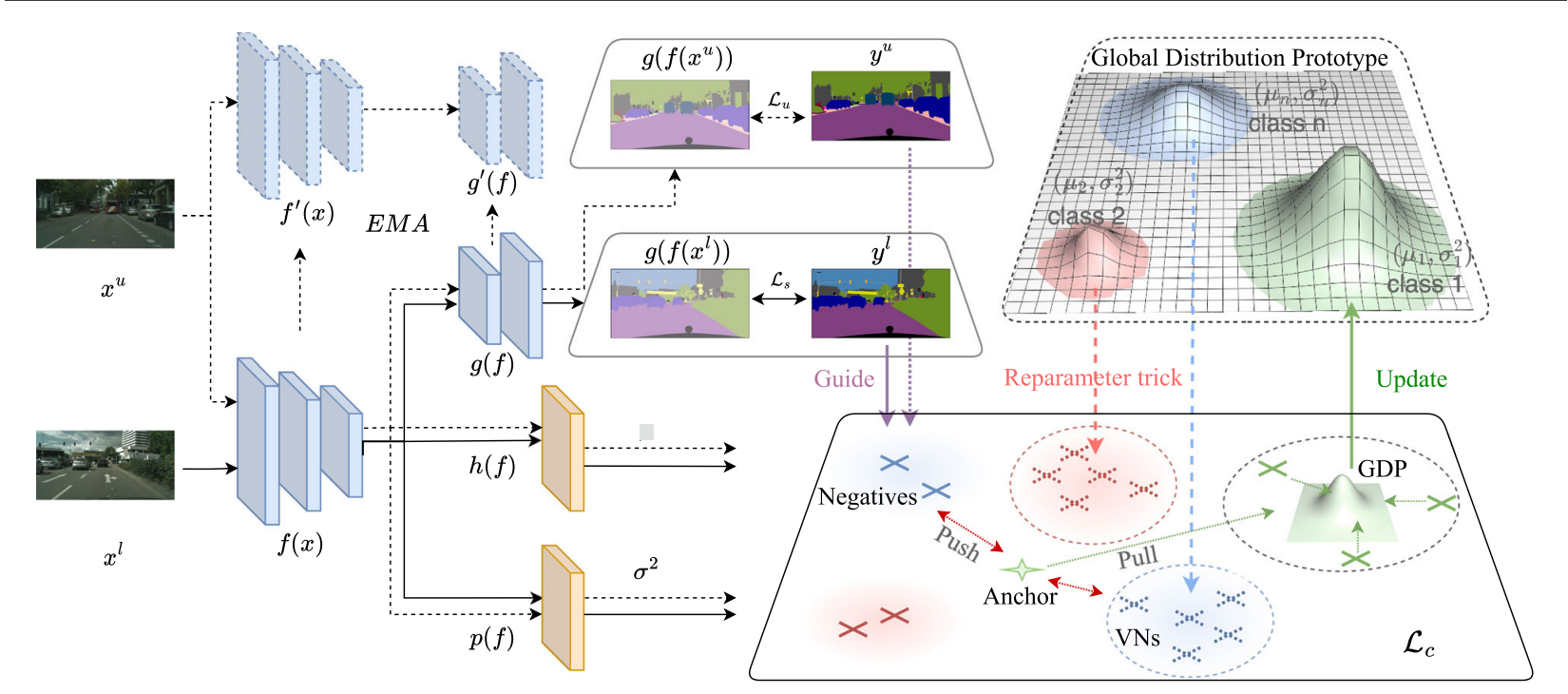
带标签图像(黑色箭头)和未标注图像(黑色虚线箭头),Ls通过标准交叉熵(CE)损失函数ce构建,Lu通过加权CE损失构建
在传统对比学习中,表征之间的相似性通常通过l2距离或余弦相似度进行衡量,但这种方法无法量化两个分布之间的相似性。为解决这一问题,我们采用互似度评分(Mutual likelihood Score,简称MLS)作为衡量两个分布zi和zj之间相似性的指标,具体计算公式如下: \[\begin{aligned}M L S(z_{i},z_{j})&=\log(p(z_{i}=z_{j}))\\&=-\,\frac{1}{2}\sum_{l=1}^{D}\left(\frac{(\mu_{i}^{(l)}-\mu_{j}^{(l)})^{2}}{\sigma_{i}^{2(l)}+\sigma_{j}^{2(l)}}+\log(\sigma_{i}^{2(I)}+\sigma_{j}^{2(I)})\right)-\frac{D}{2}l o g2\pi,\end{aligned}\] 为解决原型漂移问题,提出了一种从全局视角跨迭代序列化聚合表征的有效策略。具体而言,我们将当前迭代中计算出的原型定义为局部原型,并将其扩展为全局分布原型(GDP)。给定Zl(t)则表示第t次迭代中相同类别表示的集合,即\({\mathcal{Z}}_{g}(t)=\mathcal{Z}_{l}(0)\cup\mathcal{Z}_{l}(1)\dots\cup\mathcal{Z}_{l}(t)\)。
具体来说,GDP可按如下方式更新: \[\begin{aligned}&\rho_{g}(t)\sim{\mathcal N}({\hat{\mu}}_{g}(t),{\hat{\sigma}}_{g}^{2}(t){\cal I}),\\&\frac{1}{\hat{\sigma}_{g}^{2}(t)}=\frac{1}{\hat{\sigma}_{g}^{2}(t-1)}+\frac{1}{\hat{\sigma}_{l}^{2}(t)},\\&\hat{\mu}_{g}(t)=\hat{\sigma}_{g}^{2}(t)\biggl(\frac{\hat{\mu}_{g}(t-1)}{\hat{\sigma}_{g}^{2}(t-1)}+\frac{\hat{\mu}_{l}(t)}{\hat{\sigma}_{l}^{2}(t)}\biggr).\end{aligned}\] 也就是说,最新迭代轮次计算的分布不会因为当前的原型偏移,出现较大变化。
为解决负样本分布零散的问题,提出了一种高效策略来替代传统的记忆库方法,该策略巧妙利用了GDP的分布特性。具体而言,我们通过改进的参数重配置技术(Kingmaand & Welling 2013),从对应类别c的GDP \(\rho_{(c)g}(t)\sim\mathcal{N}(\tilde{\mu}_{(c)g}(t),\,\hat{\sigma}_{(c)g}^{2}(t)I)\)中生成虚拟负样本(VN): \[{Z_{c}^{V N}=\hat{\mu}_{(c)g}(t)+\beta\epsilon^{\top}I\hat{\sigma}_{(c)g}^{2}(t),}\]
3.RankMatch
RankMatch: Exploring the Better Consistency Regularization for Semi-supervised Semantic Segmentation(CVPR 2024)
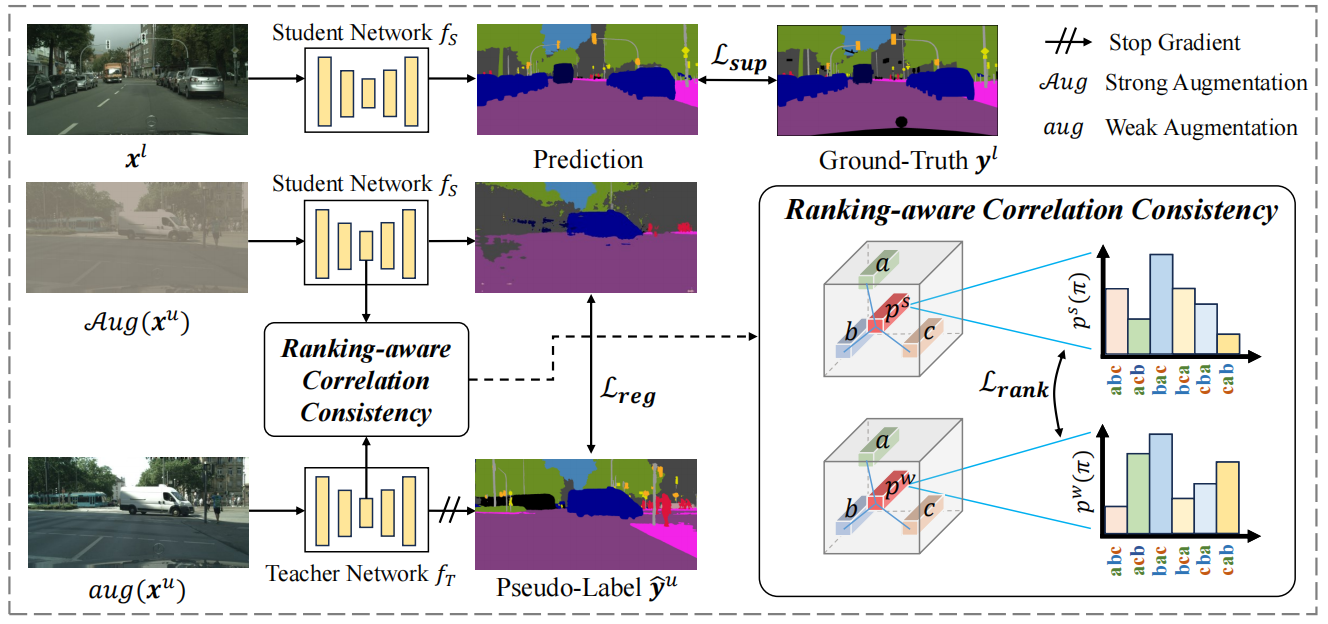
面对半监督语义分割任务,先使用交叉熵Lsup来约束学生网络,然后使用使用代理来代表每一种语义信息,rank则是每种最大可能性排列的概率,然后使用KL散度约束师生模型的不同。