Cross-Image Pixel Contrasting for Semantic Segmentation
Cross-Image Pixel Contrasting for Semantic Segmentation
Tianfei Zhou ,Wenguan Wang
摘要
本研究聚焦图像语义分割问题。现有方法主要通过专门设计的上下文聚合模块(如膨胀卷积、神经注意力机制)或结构感知优化目标(如交并比损失函数)来挖掘单张图像内部像素间的“局部”上下文关联。然而这些方法忽视了训练数据的“全局”上下文,即不同图像间像素间的丰富语义关系。受无监督对比表征学习最新进展的启发,我们提出了一种像素级对比算法——像素对比学习(PiCo),用于全监督学习场景下的语义分割。其核心思想是强制同语义类别的像素嵌入保持更高相似度,而非不同类别的嵌入。该算法通过显式探索标注像素的结构特征,开创了像素级度量学习范式,这一研究方向此前鲜有关注。我们的训练算法与现代分割方案兼容,测试时无需额外开销。实验表明,无论使用知名分割模型(如DeepLabV3、HRNet、OCRNet、SegFormer、Segmenter、MaskFormer)和骨干网络(如MobileNet、ResNet、HRNet、MiT、ViT),我们的算法都能在Cityscapes、ADE20K、PASCALContext、COCO-Stuff、CamVid等多样化数据集上实现持续性能提升。我们预期这项工作将促使学界重新审视语义分割领域当前实际存在的训练范式。
1.引言
近年来无监督表征学习领域的突破性进展[28]
[29],主要得益于对比学习这一深度度量学习[30]核心分支的复兴。其核心理念是“学会对比”:在投影嵌入空间中,给定一个锚点样本,需要从一组差异样本(即负样本)中识别出相似样本(即正样本)。具体到计算机视觉领域,这种对比通常基于图像特征向量进行评估——锚点图像的增强版本被视为正样本,而数据集中的其他图像则作为负样本。
无监督对比学习的巨大成功与我们之前的推测共同促使我们重新思考语义分割领域当前的主流训练范式。本质上,无监督对比学习的强大之处源于结构化对比损失,这种损失函数充分利用了训练数据中的上下文信息。基于这一洞见,我们提出PiCo——一种像素级对比算法,旨在为完全监督场景下的密集表示学习提供更有效的解决方案。具体而言,除了采用像素级交叉熵损失来解决类别判别问题(即属性i),我们还通过探索标注像素样本的结构信息(即属性ii),利用像素级对比损失进一步塑造像素嵌入空间。像素级对比损失的核心思想在于计算像素间的对比度:强制正样本像素的嵌入向量相似,负样本像素的嵌入向量相异。由于训练过程中已提供像素级别的分类信息,正样本是属于同一类别的像素,负样本则是不同类别的像素(图1(d))。通过这种方式,可以捕捉嵌入空间的全局属性特征(图1(e)),从而更准确地反映训练数据的内在结构,实现更精准的像素预测。

图1. 我们的核心思路。
> 在给定训练图像(a)的情况下,当前的分割模型通过学习将像素(b)映射到嵌入空间(c),却忽略了标注数据的内在结构(即同一类别像素间的图像关联,这些关联在(b)中用相同颜色标注)。我们引入像素级对比学习(d)构建新型训练范式,通过明确解决类内紧凑性和类间分散性问题。每个像素(i)的嵌入向量会向同类别像素方向聚集,同时远离其他类别像素。这种机制最终形成结构更优的嵌入空间(e),从而显著提升分割模型的性能表现。
在监督式像素级对比算法中,我们开发了三项创新技术。
首先,针对语义分割的特性,我们提出区域记忆库机制。面对海量高度结构化的像素训练样本,该机制将记忆库存储语义区域的池化特征(即同一图像中具有相同语义标签的像素),而非仅存储像素级嵌入。这种设计形成像素-区域对比策略,作为像素-像素对比策略的补充。通过这种记忆机制,我们能在每次训练中获取更具代表性的数据样本,充分挖掘像素与语义级分割之间的结构关联——即属于同一类别的像素与分割区域在嵌入空间中应保持邻近。
其次,我们提出差异化采样策略以优化信息样本利用,使分割模型能更关注分割困难像素。已有研究证实困难负样本对度量学习至关重要[27]
[30]
[35],本研究进一步揭示了在监督式密集图像预测任务中,挖掘信息性负样本/正样本及锚点的重要性。
第三,除从数据集中提取有效负样本外,我们还提出了一种硬负样本合成机制,用于生成新颖且更具挑战性的负样本。这些负样本用于优化像素表示,从而改进算法性能,最终获得性能更优的算法(即PiCo+)。
简而言之,我们的贡献有三个方面:
- 我们提出一种监督式像素级对比学习方法用于语义分割。该方法将当前的图像级训练策略提升至图像间、像素级的范式。通过充分利用标记像素间的全局语义相似性,本质上学习了一个结构良好的像素语义嵌入空间。
- 我们开发了一个区域记忆机制,以更好地探索大规模视觉数据空间,并支持进一步计算像素到区域的对比度。该方法与像素间对比度计算相结合,利用了像素之间的语义相关性,以及像素与语义区域之间的语义关联。
- 我们证明,与采用随机像素样本进行密集度量学习不同,通过更优的示例采样与合成策略,可实现更强大的分割模型。
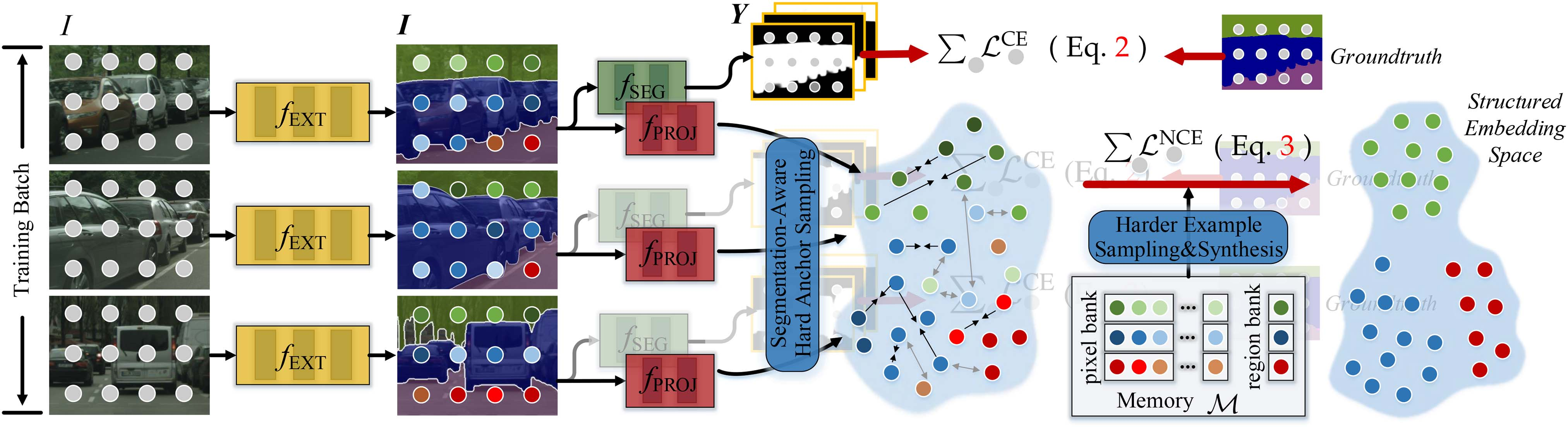
图3. 语义分割学习中PiCo的详细说明。对于小批量中的每个训练图像I,特征提取器\(f_{EXT}\)将其投影到一个密集嵌入I,随后输入到分割头\(f_{SEG}\)中进行掩码预测(即Y),该过程由交叉熵损失(\(L^{CE}\),(2))监督,同时输入到投影头\(f_{PROJ}\)中进行像素对比度($L^{NCE} $,(3))。此外,还维护了一个记忆库M,并设计了硬样本采样和合成策略,以找到更具信息量的样本,从而实现有效的对比学习。
C. 详细网络体系结构
本算法包含五个主要组成部分(参见图3):
- 特征提取器\(f_{EXT}\)将每张输入图像I映射为稠密嵌入向量\(I =f_{EXT}(I) \in R^{H×W×D}\)。实验中采用常见CNN或Transformer骨干网络实现\(f_{EXT}\),测试了五种主流CNN(包括MobileNet V1[39]/V2[49]/V3[50]、ResNet[5]和HRNet[31])以及两种Transformer(MiT[17]和ViT[40])。
- 分割头(\(f_{SEG}\))将输入图像I投影至评分图\(Y = f_{SEG}(I) \in R^{H×W×|C|}\)。我们研究了主流方法中不同的分割头(如DeepLabV3[9]、HRNet[31]、OCRNet[33]、SegFormer[17]、Segmenter[18])。
- 投影头,\(f_{PROJ}\),将每个高维像素嵌入 \(i \in I\) 映射到一个 256 维的 2 归一化特征向量 [28],用于计算对比损失$L^{NCE} $ 。\(f_{PROJ}\) 的实现为两个 1 × 1 卷积层,使用 BN 和 ReLU。请注意,\(f_{PROJ}\)仅在模型训练期间应用,并在推理时移除。因此,它不会对分割网络引入任何变化,也不会在部署时增加额外的计算成本。
- 记忆库(Memory Bank,简称M)由两部分组成,分别用于存储像素嵌入和区域嵌入。针对每个训练图像,我们按类别抽取V=10个像素。每个类别的像素队列大小设为T=10N。对于大规模或高词汇量数据集(如COCO-Stuff和ADE20 K),我们将T设为固定值(即10,000),并在队列满时丢弃最旧样本。训练结束后,记忆库也会被清空。
- 联合损失, LSEG(参见(4)),该方法结合了表征学习(即(2)中的LCE)和度量学习(即(3)中的 LNCE)以实现更独特的分割特征学习。在实际应用中,我们发现我们的方法对系数 λ 不敏感(例如,当 λ ∈ [0.1,1]时),并经验性地将 λ 设置为1。对于(3)中的 LNCE ,我们将温度 τ 设置为0.1。在采样方面,我们发现“半硬样本采样”+“分割感知硬锚点采样”效果最佳,并将采样实例数设置为Kp = 1,024和Kn = 2,048。对于每个小批量,每个类别采样50个锚点(一半随机采样,另一半为分割困难的锚点)。
实验
A.实验设置
数据集:
本实验基于五个数据集:
- Cityscapes数据集[3]包含5,000张精细标注的城市场景图像,其中训练集/验证集/测试集分别包含2,975/500/1,524张图像。我们报告了19个类别的性能表现,例如人物、车辆等。
- ADE20 K[2]是一个包含150个物体/物品类别的大规模场景解析基准数据集,其数据集被划分为20K/2K/3K图像用于训练/验证/测试。
- pascal-Context[36]在训练集和测试集分别包含4,998张和5,105张图像,提供59个语义类别的精确标注。
- COCO-Stuff[37]从COCO数据集中采集了10K图像,划分为9K和1K图像用于训练和测试,提供80个物体类和91个物品类的丰富标注。
- CamVid[38]的训练/验证/测试集分别包含367/101/233张图像,共包含11个语义标签。实验中我们使用了[117]提供的缩放版本。
训练阶段:
在训练过程中,我们遵循惯例[31]、[33]、[34]、[118]来设置超参数。为了公平起见,我们使用在ImageNet-1K[119]上预训练的相应权重初始化所有骨干网络,其余层则随机初始化。对于数据增强,我们使用颜色抖动、水平翻转和随机缩放,缩放因子在[0.5,2.0]之间。对于基于
FCN
的网络,我们使用SGD作为优化器,动量为0.9,权重衰减为0.0005。我们采用多项式退火策略[9]来调度学习率,其乘以\(\bigl(\mathbf{1}\,-\,{\frac{i t e r}{t o t a
l_{-}i t e r}}\bigr)^{p o w e
r}\)的幂次,其中power=0.9。此外,对于Cityscapes数据集,我们采用8的微批量大小,并设置初始学习率为0.01。所有训练图像均通过从1024×2048随机裁剪至512×1024进行增强。对于验证集和测试集的实验,我们遵循[31]的方法,对模型进行80K和100K次迭代训练。请注意,我们没有使用任何额外的训练数据(例如,城市景观粗略数据集[3])。对于ADE20K,我们以16的批量大小和0.02的初始学习率训练模型160K次迭代。对于pascal-Context和COCO-Stuff,我们选择16的小批量大小、0.001的初始学习率和520×520的裁剪尺寸。我们在它们的训练集上进行了60K次迭代训练。对于CamVid,我们以16的批量大小、0.02的学习率和原始图像尺寸训练模型6K次迭代。对于SegFormer[17],我们遵循官方设置,使用AdamW作为优化器,学习率为6e-5,权重衰减为0.01,所有实验均保持相同。此外,在训练过程中,我们遵循[113]的方法,对网络进行5K步的预热,即在前5K次迭代中仅应用LCE((4)中的
λ = 0)。
测试阶段:
作为通用协议[31] [33]
[120],我们采用翻转处理对多尺度分割结果进行平均,即缩放因子为原始图像尺寸的0.75至2.0倍(间隔0.25倍)。需注意的是,在测试过程中,基础分割模型(包括投影头fPROJ和记忆库M)未引入任何变更或额外推理步骤,直接舍弃。
度量:
根据惯例,mIoU被用作主要指标。
可重现性:
我们的模型在PyTorch中实现,并在4个
NVIDIA Tesla V100 GPU上进行训练,每个卡内存为32
GB。在相同机器上进行测试。
C. 与State-of-the-Arts的比较
我们随后在五个数据集上将本方法与最先进的分割模型进行对比。其中,‘PiCo’表示文献[1]中的算法,‘PiCo+’则代表其结合硬负样本合成的扩展版本。
1)Cityscapes中的表现:
表V提供了与Cityscapes
[3] val上的代表性方法在mIoU和训练速度方面的比较结果。
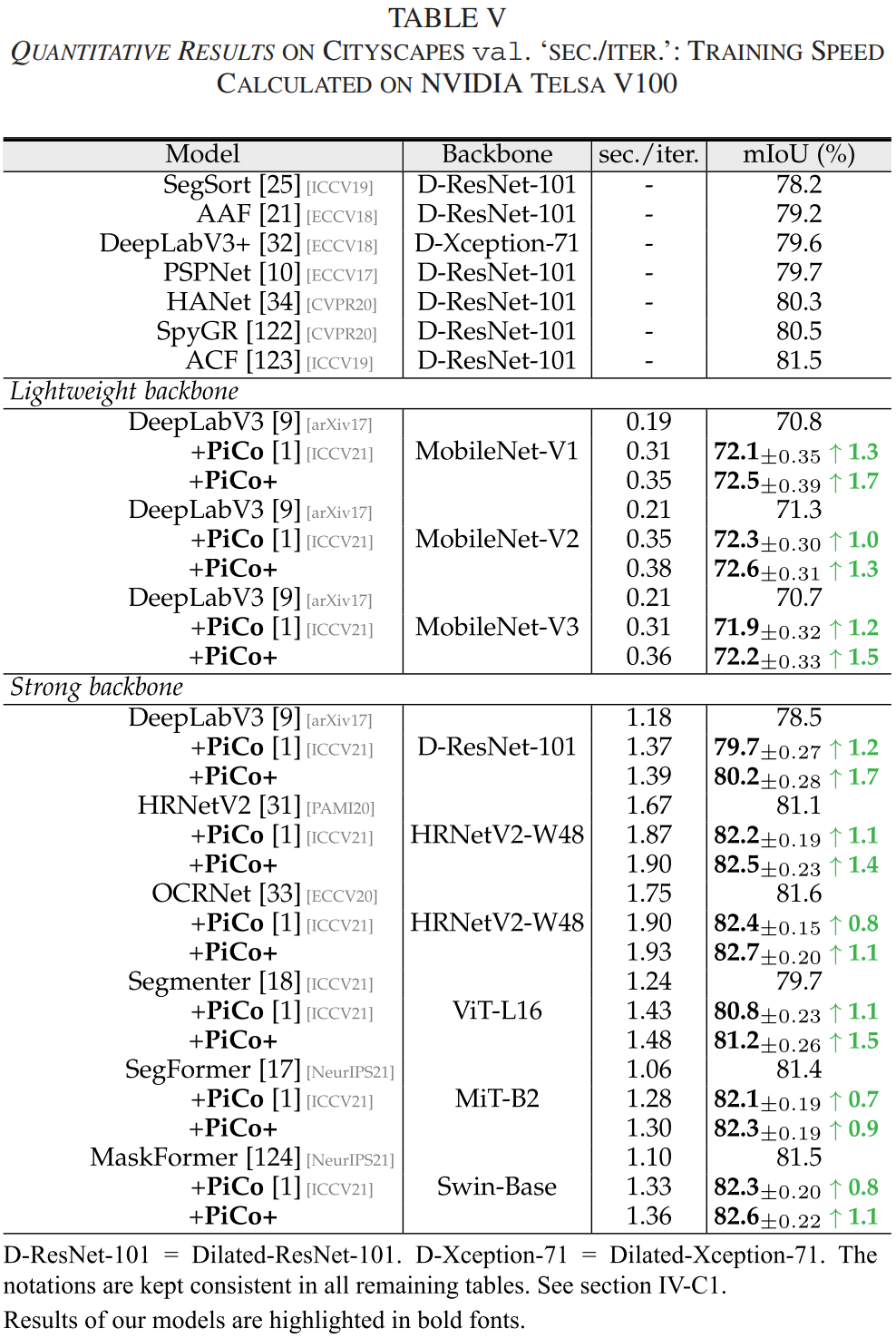
我们使用各种骨干网络(轻量级或强健的,基于CNN或Transformer的)在Cityscapes训练集上进行了80,000次迭代训练,小批量大小为8。从表中可以得出几个观察结果:
i)
通过配备跨图像像素对比度(即PiCo),基于 FCN
的分割模型性能持续提升(分别比DeepLabV3 [9]、HRNetV2 [31]和OCRNet
[33]多出 1.2/1.1/0.8 个点);
ii)
提出的训练协议在更近期的Transformer基分割模型上表现出强大的性能和泛化能力。Segmenter[18]、SegFormer[17]和MaskFormer[124]分别提高了1.1%、0.7%和0.8%;
iii)
PiCo在轻量级骨干网络(1.3/1.0/1.2 用于MobileNet
V1[39]/V2[49]/V3[50])下,与DeepLabV3[9]相比表现稳定提升;iv)
通过硬负样本合成,PiCo+在所有分割模型中相对于PiCo表现稳定提升;v)
对比损失计算导致的训练速度下降微乎其微(即在Cityscapes[3]上约为0.2
sec./iter .)。
表VI列出了不同模型在Cityscapes测试中的得分,该测试采用两种广泛使用的训练设置[31](仅训练集或训练集+验证集)。如表所示,PiCo/PiCo+模型在三种基于CNN的分割模型(即DeepLabV3[9]、HRNetV2[31]和OCRNet[33])以及基于Transformer的模型(即SegFormer[17])上均表现出持续性增益。此外,PiCo+模型的表现始终优于PiCo模型。