DiRLoc:Disentanglement Representation Learning for Robust Image Forgery Localization
DiRLoc: Disentanglement Representation Learning for Robust Image Forgery Localization
Ziqi Sheng, Zuomin Qu, Wei Lu, Member, IEEE, Xiaochun Cao, Senior Member, IEEE, Jiwu Huang, Fellow, IEEE
中山大学
摘要
深度学习图像伪造定位方法取得了显著的效果,但当伪造图像被JPEG压缩时,无法保持可比的性能,JPEG是一种广泛用于日常信息传输的格式。对JPEG压缩的鲁棒性已成为图像伪造定位实际应用的瓶颈。为了解决这个问题,针对JPEG压缩导致的性能下降,提出了一种鲁棒的图像伪造定位框架。具体而言,提出了一种先进的渐进式解纠缠策略,该策略结合了粗粒度图像解纠缠来减轻通用JPEG压缩的不利影响,同时利用细粒度元素解纠缠的能力来分离多尺度伪影,从而最大限度地减少内容信息的干扰。此外,决策策略经过精心设计,以强化来自篡改区域的微妙信号,包括伪影融合块推理多尺度伪影和双注意力块,以了解更多与伪造相关的特征。大量的可视化和实验表明,我们的方法在一般的JPEG防伪图像定位中可以实现具有竞争力的性能,特别是在泛化实验的性能方面。
I.介绍
近年来,对抗jpeg压缩图像伪造定位的研究越来越多。Kwon等人[10]采用了RGB和DCT域的压缩伪影的法医特征的联合学习。Zhuang等人[11]采用修复策略重建锻造的痕迹。然而,大多数图像伪造定位方法通常将图像伪造定位任务建模为一个分类问题,并对伪造图像的每个像素进行二值分类。这导致人们更倾向于更多地关注内容和语义信息,而不是伪造图像[12]中的人工痕迹。内容偏差的干扰会导致大多数图像伪造定位方法的有限泛化。
在本文中,我们提出了一个原始的框架,引入了鲁棒图像伪造定位(DiRLoc)任务的解纠缠表示学习。抗JPEG的图像伪造定位任务存在两个重要的挑战:
(i)伪造伪在JPEG压缩后会消失,这增加了JPEG压缩[13]的图像伪造定位的难度。(ii)训练数据集中的内容语义和工件相互耦合,从而使检测器更倾向于将伪造定位任务视为分类任务,导致[14]泛化性较差。为了应对这些挑战,我们提出了一种渐进式解纠缠策略,该策略同时包含了粗粒度图像解纠缠和细粒度元素解纠缠。
具体来说,粗粒度图像解纠缠相位将伪造图像与JPEG压缩的轨迹解耦,以消除JPEG压缩对伪造图像的影响。随后,在解耦的伪造图像中,细粒度元素解纠缠阶段将伪元素与内容语义元素解耦,获得与内容无关的伪元素,这对后续的伪造本地化任务有很大的贡献。为了减少内容语义的干扰,我们精心设计了元素独立性损失,以确保内容元素和工件元素保持不同。同时,解耦的伪影元素应该充分代表伪造图像中的被篡改区域,从而设计了图像重建和特征重建损失,以确保伪影元素的完整性。因此,通过设计元件解纠缠阶段的目标损失函数,仔细考虑了解纠缠元件的完整性和独立性。通过解纠缠策略学习相对纯的人工元素,进一步减少了JPEG压缩和内容偏差对伪造线索的影响。总之,这两个阶段是相互关联的,并可以逐步解耦伪造的JPEG图像,以产生语义不可知的伪影。图2直接显示了jpeg处理图像的图像和元素解纠缠的优势。

当不存在分离策略时,模型会被JPEG跟踪和内容偏差所破坏,使其容易错误定位或忽略被篡改的区域。然后,在加入图像解纠缠模型后,进一步提高了被篡改区域的精度。最后,在采用DiRLoc模型的整体解纠缠策略后,该模型能够得到准确的预测结果。这也充分解释了图像解纠缠相位和元素解纠缠相位的意义。
值得注意的是,我们从多层中学习了工件元素,因为较深的特征包含更多的结构信息,而较浅的特征更关注纹理信息。在决策策略中,我们巧妙地设计了伪影融合块(AFB),有效地融合多尺度伪影,并加入双注意块来挖掘伪影特征的通道和位置信息,旨在探索更多与伪造相关的特征。最后,通过决策策略增强了细微的伪造特征,进一步提高了定位性能。通过采用渐进式解纠缠策略,我们确保了DirLoc在一般的抗jpeg图像伪造定位任务和跨数据集泛化实验中优于最先进的方法。例如,在jpeg压缩的事实上的[16]数据集上,DirLoc的F1分数平均优于次优方法IF-OSN[15]5%。同时,DiRLoc在所有跨数据集泛化实验中都取得了良好的性能。这项工作的贡献可以总结如下:
- 本文提出了一种创新的针对JPEG压缩进行鲁棒图像伪造定位的框架DiRLoc,该框架包含了一种渐进式解纠缠策略和一种决策策略。
- 渐进式解纠缠策略以从粗到细的方式将内容不可知的伪影与伪造的JPEG图像解耦,有效地消除了JPEG压缩的影响和内容语义信息的干扰。
- 提出了伪影融合块(AFB)来融合多尺度的伪影,并利用双注意层来学习更多与伪造相关的特征。
- 在公共数据集上进行的大量实验表明,DiRLoc的性能优于最先进的方法,特别是在泛化比较的性能方面。
II.相关工作
A.图像伪造检测
B. 解纠缠表示法学习
解纠缠表示学习的目的是将复杂的高维耦合信息分解为具有高[30]识别能力的简单特征,使语义无关的篡改伪影容易获得。在现实世界中,获取可靠的工件是一项关键但具有挑战性的任务,而在训练数据集中,伪造操作与特定语义意义之间的过拟合可能会显著阻碍这种努力。各种深度学习方法都致力于通过不同的方法来寻找语义上不相关的工件。由于图像在RGB域中具有丰富的语义特征,一些方法试图从语义无关的域中寻找被篡改的图像伪影,如噪声域或频域[14]。例如,Wang等人[31]促进了高频特征,并将其与多模态补丁嵌入中的RGB特征相结合,以检测和定位图像操作。然而,噪声域或频域中的图像信息可以通过后处理轻松改变。然而,噪声域或频域中的图像信息可以通过后处理轻松改变。
为了减少语义信息的干扰,一些方法探索了使用解纠缠表示学习来解耦内容语义。Liang等人[12]提出了一种解纠缠框架来去除人脸伪造检测中的内容信息。Kim等[32]根据相机特征分离身份特征和特征,更加关注身份信息,实现视频人的重新识别。Fu等人[33]引入了一种多层次的特征解纠缠网络,将合成的人脸特征解纠缠为现实特征和伪特征。Liu等人[34]设计了一个对抗性学习框架,将恶搞痕迹分解为模式的分层组合。Li等人[35]提出了一个深度伪检测框架来从深度伪视频中分离伪影。为了确保对语义独立的工件的访问,设计了一种渐进解纠缠策略,包括粗粒度图像解纠缠组件和细粒度元素解纠缠组件。这种新策略消除了伪造图像中内容语义信息的干扰,增强了对JPEG压缩的泛化能力。对渐进式分离策略的详细分析可以在SecIII-B中找到。
III.方法论
A. 概述
如上所述,一种典型的图像伪造定位方法在暴露于特定的后处理操作时,可能难以保持其鲁棒性。JPEG压缩是一种广泛应用于日常信息传递和社交媒体传输中的后处理操作。为了满足实际应用的需要,DiRLoc专注于解决抗jpeg的压缩伪造定位问题。
我们将源伪造图像表示为\(I_0\),\({I}_{0}\in{\mathcal R}^{H\times W\times
C}\)。JPEG压缩过程被表述为JPEG(·)。伪造的JPEG图像记为\(I_j\),其中\(I_j=JPEG(I_0)\),\({I}_{j}\in{\mathcal R}^{H\times W\times
C}\)。\(I_0\)和\(I_j\)的伪造区域像素级标签表示为\(m\in\{0,1\}^{H\times W\times
C}\)(伪造/真实)。H、W和C分别是图像的高度、宽度和通道。对于\(I_0\)和\(I_j\),通道设置为3,而标签m的通道设置为1。最后,对于任意给定的输入\(I_j\),DiRLoc输出像素级预测结果\(\hat
m\)。
DiRLoc的总体框架如图3所示。
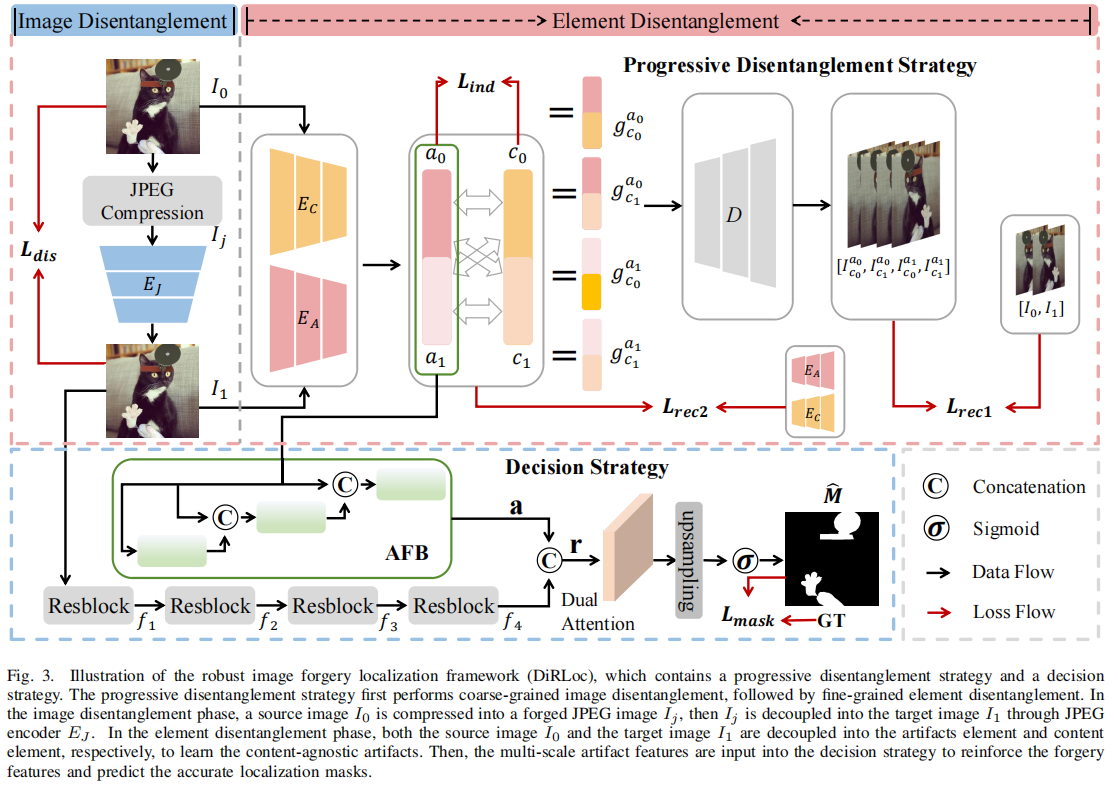
原始的框架包含两个重要的组成部分:渐进式解纠缠策略和决策策略。将粗到细的渐进分离策略分为图像分离阶段和元素分离阶段。在图像解纠缠阶段,对于JPEG压缩的篡改图像IJ,我们将其输入到JPEG编码器EJ中,得到I1,确保I1尽可能接近原始图像I0,以抵消JPEG压缩的影响。在图像解纠缠阶段,I0和I1分别使用伪影编码器EA和内容编码器EC来获取相应的伪影元素和内容元素。通过仔细的设计约束,使解耦的工件能够尽可能地独立于内容语义。在决策策略中,通过对解耦伪影的推理和融合,得到最终的像素级定位性能。接下来,我们将在SecIII-B和SecIII-C中分别介绍渐进式解纠缠策略和决策策略。
B.渐进的分离策略
如图4所示,提出了一种创新的渐进解纠缠策略,以解决针对JPEG压缩的鲁棒图像伪造定位的两个瓶颈。
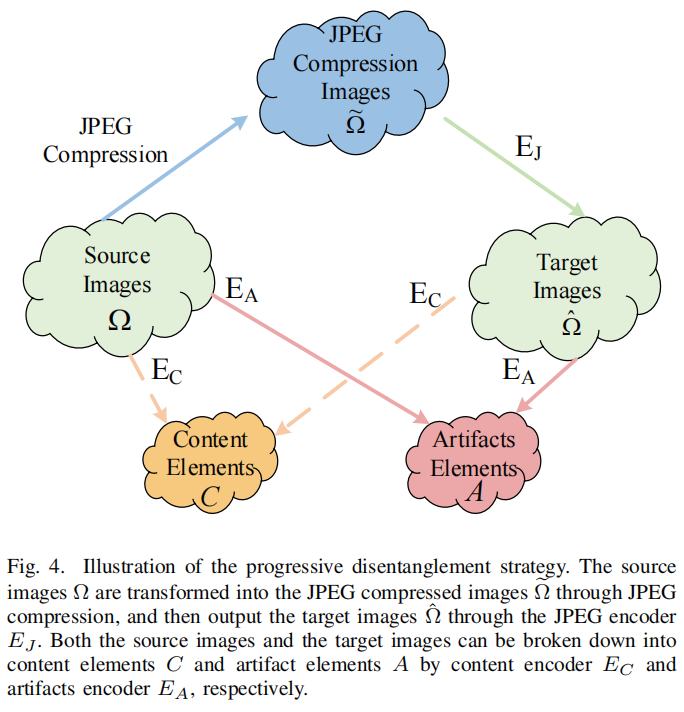
一方面,JPEG压缩引入了复杂的退化痕迹,如阻塞轨迹、振铃效应和模糊效应[7],[8],这可能会干扰图像伪造伪影。因此,伪造的JPEG图像既包含JPEG痕迹,又包含图像伪造伪影,使得伪造区域的准确定位更加困难。另一方面,泛化性差是图像伪造定位方法中普遍存在的问题。在跨数据集实验中,保持良好的性能更加复杂,因为大多数方法都难以消除特定数据集中的内容语义偏差。
为了应对上述挑战,DiRLoc构建了全面的解决方案来解决这些问题。为了解决第一个问题,我们仔细开发了JPEG编码器EJ(·)来执行粗粒度的图像解纠缠和识别JPEG压缩轨迹。JPEG编码器EJ(·)的目标之一是识别并删除JPEG压缩的痕迹。另一个目标是重建伪造伪影A。对于伪造的JPEG图像Ij,图像解纠缠相位可以表示为\(I_{1}=E_{J}(I_{j})\)。直观地说,解耦图像I1中的伪影a1和内容c1是源图像I0中的伪影a0内容c0的一个子集,其中\(I_{0}\in\Omega\)和\(I_{1}\in\tilde{\Omega}\)。为了进一步消除JPEG压缩对伪造图像的负面影响,在细粒度元素解纠缠相位的影响下,应尽可能地减小集合(a1,a0)和(c1,c0)内部的差异。
为了提高模型的泛化性,细粒度元素解纠缠阶段通过减少特定数据集的内容干扰来提高模型的泛化性。该阶段主要由两个独立的编码器\(E_C\)和\(E_A\)组成,分别用于提取内容和人工元素。该编码器可以消除数据集的内容偏差,从而可以更多地关注伪造伪影。在第III-B1中描述了图像解纠缠阶段的技术细节,在第III-B2中详细阐述了元素解纠缠相位。
1)图像解纠缠:
图像质量的下降是JPEG压缩过程中的一个众所周知的影响。当源伪造图像I0被JPEG压缩压缩时,I0中包含的伪造伪影被损坏。图像伪造定位任务在JPEG压缩条件下保持鲁棒性能是一个挑战。受许多先前的JPEG跟踪解纠缠工作[36]-[38]的启发,我们提出了一种JPEG编码器EJ来执行粗粒度的图像解纠缠,这可以消除JPEG压缩的干扰。
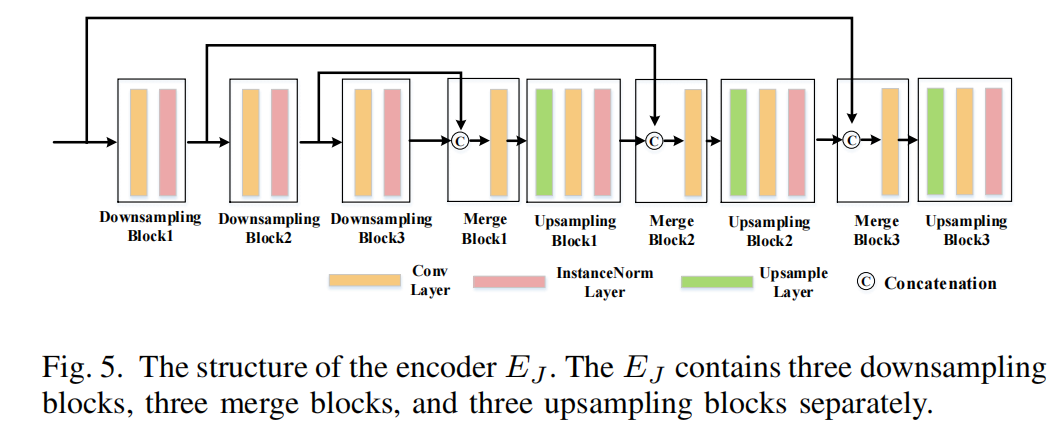
如图5所示,JPEG编码器EJ采用了ADN
[39]提出的编码器结构,专门用于分离CT图像中的伪影。JPEG编码器EJ的目标是解开JPEG压缩轨迹,并尽量减少解耦图像I1与其源图像I0之间的差异。换句话说,通过消除I1中的JPEG痕迹,I1中的伪造伪影被迫与I0中的伪造伪影保持一致。为此,我们引入一个像素损失来测量解耦图像I1和相应的源图像I0之间的距离。图像解纠缠损失Ldis给出如下:
\[{\mathcal{L}}_{d i s}=\frac{1}{H\times
W}||I_{1}-I_{0}||_{1},\]
其中,H×W为i0中的像素数。我们使用L1损失而不是L2损失来鼓励更尖锐的输出。通过强制I1尽可能接近I0,可以尽可能多地重建伪造对象,同时消除在I1时JPEG压缩的影响。
2)元素解纠缠:
我们假设图像的高维潜在表示由内容和伪影元素组成。元素解纠缠网络的主要目的是将复合元素分解为伪影元素和内容元素。然后,将相对纯的伪影元素用于后续的定位任务,而不分散内容语义信息。元素解纠缠阶段主要由两个独立的编码器EC和EA组成,分别用于提取内容和伪影元素,以及一个用于图像重建的解码器D。EA的结构如图6所示。
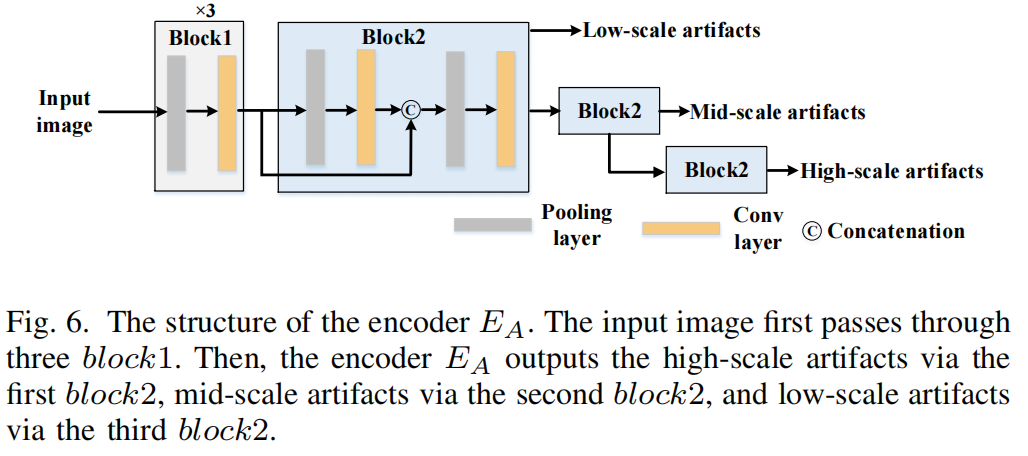
编码器EA输出多尺度伪造伪影:高尺度伪影、中型伪影和低尺度伪影[39]。高尺度的伪影包括尖锐的图案和高频结构。中尺度的伪影指的是图像的纹理和边缘。低尺度的伪影包括像素信息,如构造笔画和镜面高光。内容编码器EC与伪影编码器EA具有相同的结构,但参数不共享,只保留最后一层的输出。如图3所示,将一对输入图像(I0、I1)输入编码器EC和EA,输出(a0、c0)和(a1、c1),分别表示对应的伪影和内容元素。
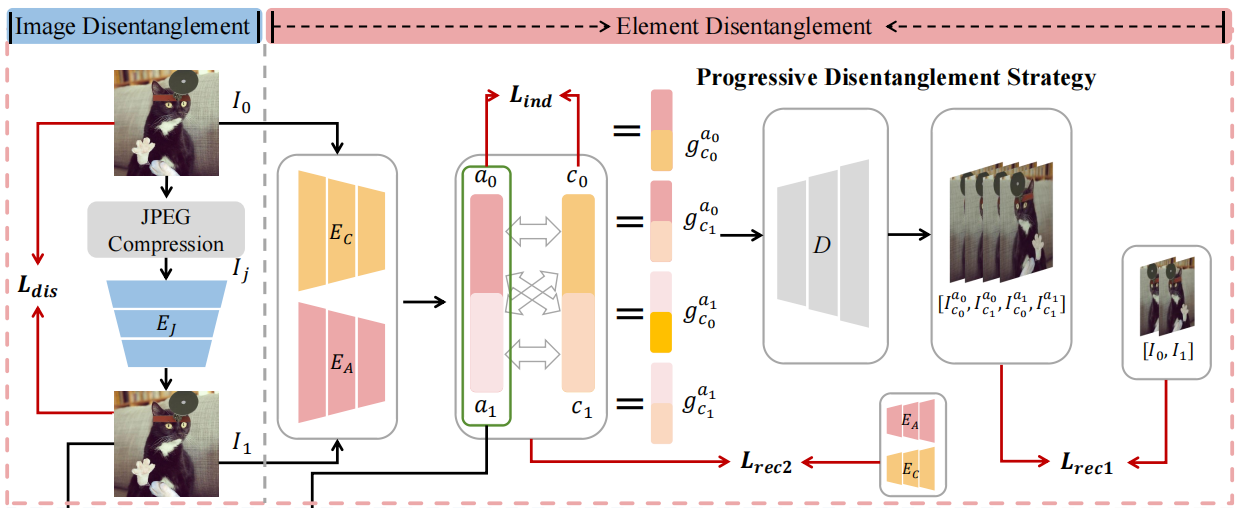
该过程的计算公式如下: \[\begin{array}{l c r}{c_{0}=E_{C}(I_{0}),c_{1}=E_{C}(I_{1}),}\\ {a_{0}=E_{A}(I_{0}),a_{1}=E_{A}(I_{1}).}\end{array}\] 图7显示了直观比较两种不同特征的热力图。

图7中的第三行和第四行分别为伪影元素和内容元素,伪影元素与第二行中显示的groundTruth掩模非常相似。这说明伪影元素更侧重于被篡改的区域,而内容特征更侧重于图像的语义背景。也就是说,元素解纠缠相位可以成功地聚焦于伪造图像的被篡改区域,减少内容偏差信息的影响。因此,DiRLoc比其他伪造图像定位方法具有更大的泛化性,并在SecIV-C中得到了充分的验证。为元素解纠缠相位精心设计了几个关键的损失函数。接下来,我们将详细讨论它们。
a)图像重建损失和特征重建损失:
解耦的伪影元素必须完全表示伪造图像中的被篡改区域。因此,我们设计了图像和特征重建损失,以确保伪影元素的完整性。对于图像重建,首先将元素加法应用于同一图像编码的内容和伪影元素,得到图像的高维潜在表示特征,即\(g_{c_{k}}^{a_{k}}=c_{k}+a_{k}\),其中k =
0,1。然后,将\(g_{c_{k}}^{a_{k}}\)输入到解码器D中,重建相应的原始图像\(I_{c_{k}}^{a_{k}}\)。该过程的计算公式如下:
\[I_{c_{k}}^{a_{k}}=D(g_{c_{k}}^{a_{k}}),\]
其中,k∈{0,1}。图像重建损失保证了重建图像与原始图像在像素水平上的一致性。因此,将图像重建损失定义为:
\[{\mathcal{L}}_{r e
c{1}}=\|I_{c_{0}}^{a_o}-I_{0}\|_{1}+\|I_{c_{1}}^{a_{1}}-I_{1}\|_{1}.\]
对于特征重建,我们首先将来自不同图像的内容元素和伪影元素交叉组合,得到高维的潜在表示特征,即\(g_{c_{k}}^{a_{1-k}}=c_{k}+a_{1-k}\),其中k∈{0,1}。此外,将\(g_{c_{k}}^{a_{1-k}}\)输入到解码器D中,以重建图像\(I_{c_{k}}^{a_{1-k}}\)。该过程的计算公式如下:
\[I_{c_{k}}^{a_{1-k}}=D(g_{c_{k}}^{a_{1-k}}),\]
其中,k∈{0,1}。重建图像的编码元素应与原始元素一致,元素重建损失定义如下:
\[\mathcal{L}_{r e
c2}=\sum_{k=0}^{1}(||E_{C}(I_{c_{k}}^{a_{k}})-c_{k}||_{1}+||E_{A}(I_{c_{k}}^{a_{k}})-a_{k}||_{1}+||E_{C}(I_{c_{k}}^{a_{1-k}})-c_{k}||_{1}+||E_{A}(I_{c_{k}}^{a_{1-k}})-a_{1-k}||_{1}).\]
b)元素独立性损失:
如上所述,伪影元素和内容元素包含在两个独占域中。伪影元素和内容元素可以被视为不同的类,并且类间的距离预计将显著大于工件元素类的类内距离。换句话说,我们期望伪影元素在内部更加聚合,并且离内容元素更远。具体来说,我们将类内伪影元素视为正对,将类间元素视为负对。然后,采用对比学习策略,进一步消除了伪影元素和内容元素可能存在的重叠。受[40]的启发,我们使用内容元素和伪影元素的Gram矩阵作为一个清晰的表示:
\[G_{f}=(f_{i}^{T}f_{i})_{n\times
n}=\begin{bmatrix}f_{1}^{T}f_{1} & \cdots &
f_{1}^{T}f_{n}\\\vdots & \ddots & \vdots\\f_{n}^{T}f_{1} &
\cdots & f_{n}^{T}f_{n}\end{bmatrix}\]
其中,f表示需要计算Gram矩阵的特征,fi表示特征f的列向量,n表示特征f的行数。我们采用余弦距离来测量元素距离,其中较近的元素呈现更大的分数。最后,我们采用InfoNCE
[41]来构建伪影和内容元素之间的元素独立性损失: \[\mathcal{L}_{i n d}=-l o
g[\frac{\mathcal{E}(d(G_{a_{0}},G_{a_{1}}))}{\mathcal{E}(d(G_{a_{0}},G_{a_{1}}))+\sum_{i=0}^{1}\mathcal{E}(d(G_{a_{i}},G_{c_{1-i}}))},\]
其中,Gai和Gci分别表示ai和ci的gram矩阵的平坦向量,E表示exp(·),d(·)表示余弦相似度。
综上所述,伪影解纠缠网络是通过解耦内容偏差信息和学习多尺度伪造伪影来消除伪造图像中内容信息的负面影响。这些多尺度伪影对后续的图像伪造定位任务至关重要。
C. 决策策略
基于学习到的伪造伪影,提出了一种增强jpeg压缩图像中伪造特征的决策策略。该决策策略的体系结构如图3的底部所示。
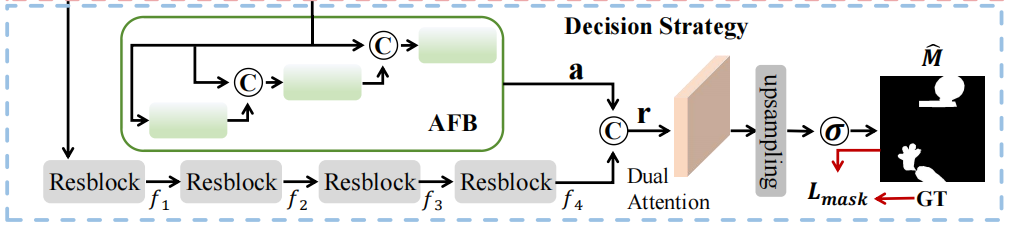
该模块以解耦的图像I1和多尺度伪影作为输入,旨在尽可能准确地预测相应的伪造区域掩模\(\hat m\)。
我们使用4个ResBlocks
[42]作为骨干,从I1中提取基本特征f1、f2、f3和f4,以增强伪造操作造成的伪造特征。此外,我们还引入了伪影融合块(AFB)来融合多尺度伪影,以提高对JPEG压缩的定位精度。伪影融合块的结构如图8所示。
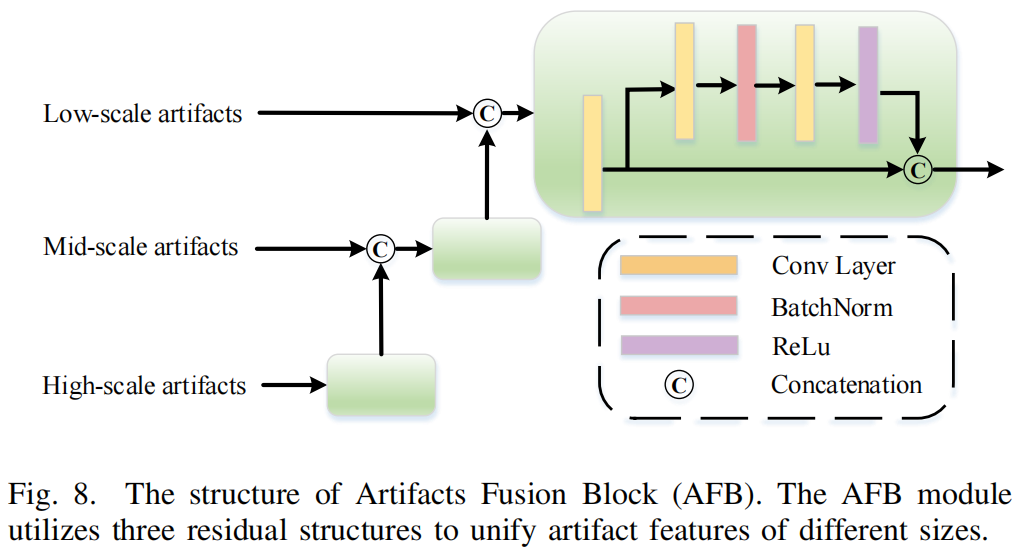
具体地说,在渐进解纠缠策略中,解耦的图像I1被解耦为三个不同尺度的伪影。然后将这些伪影分别输入到AFB中,以产生混合良好的伪影特征a。随后,将基本特征f4和伪影特征a连接并输入双注意块,得到伪造图像的最终预测掩模\(\hat m\),表示如下: \[\hat{m}=S i g m o i d(\mathrm{D}(r)),\]
其中\(r=c o n c a
t(f_{4},a)\),Sigmoid为激活函数,D(·)表示双注意块。
受[43]方法的启发,提出了双注意块来进一步增强脆弱的伪造特征,其中两种注意机制并行工作。
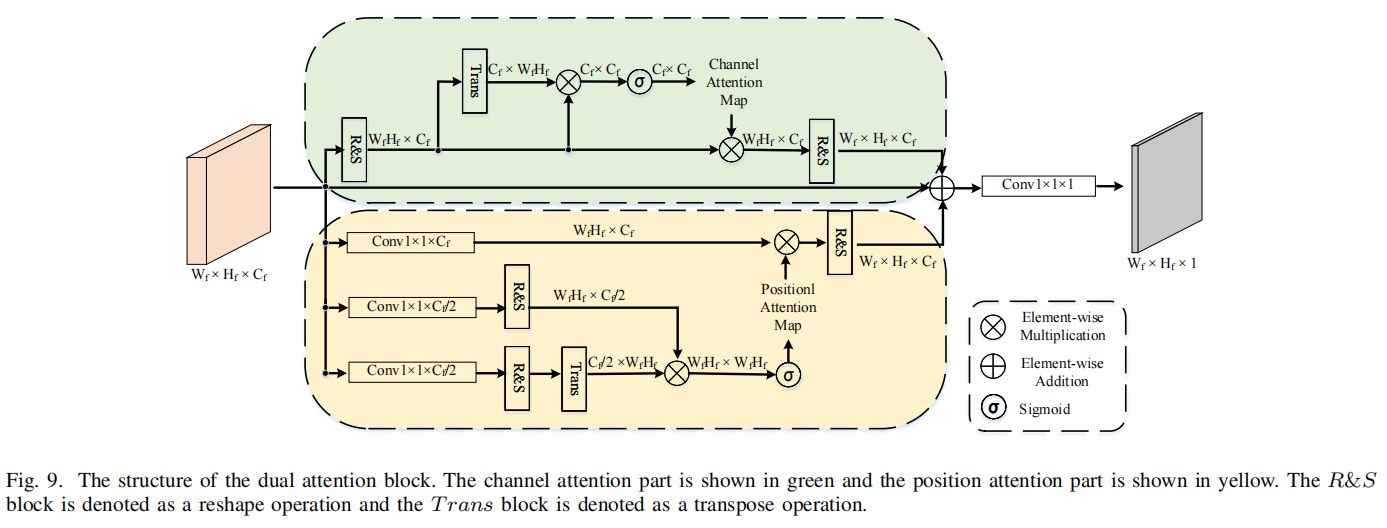
如图9所示,双注意块包括两个主要部分:通道注意部分和位置注意部分。通道注意部分集中于通道内特征的相关性。然后,位置注意部分通过所有位置的特征的加权和有选择地更新每个位置的特征。将这两个注意部分的输出汇总并转换为大小为W×H×1的特征图。
伪造像素的数量远少于被篡改图像中真实像素的数量。我们使用了Dice损失函数,该函数对从极不平衡的数据[44]中学习很有效:
\[\mathcal{L}_{m a s
k}=1-\frac{2\times\sum_{i=1}^{M}\sum_{i=1}^{M}\hat{m}_{i j}m_{i
j}}{\sum_{i=1}^{M}\sum_{i=1}^{H}\hat{m}_{i
j}^{2}+\sum_{i=1}^{M}\sum_{i=1}^{H}m_{i j}^{2}},\]
其中,W和H为伪造图像的空间分辨率。\(m_{ij}\in\{0,1\}\)是一个二进制标签,表示(i,j)像素是否被篡改,而\(\hat m_{i j}\)是预测的掩码\(\hat
m\)的像素值。在本文中,0表示为篡改,1表示为真实。
D. 总损失
本文使用了五种损失的组合,表示用等式(1),等式(4),等式(6),等式(8)和等式(10)。总损失记为: \[L o s s=\lambda_{1}{\cal L}_{d i s}+\lambda_{2}{\cal L}_{i n d}+\lambda_{3}{\cal L}_{r e c1}\] 其中,λ1、λ2、λ3、λ4和λ5均为超参数。
IV.实验
在本节中,我们进行了广泛的实验来评估所提方法的性能。首先,我们在第IV-A中介绍了训练/测试数据集和实验细节。然后,在IV-B,定量和定性实验旨在彻底研究DiRLoc与其他最先进的方法相比的性能。在IV-C,交叉数据集实验评估DiRLoc在Sec的泛化。最后,在IV-D,我们测量了在所提出的模型中涉及的每个组件和损失函数的影响。
A.实验装置
1)数据集:
我们在实验中使用的数据集汇总在表二中。
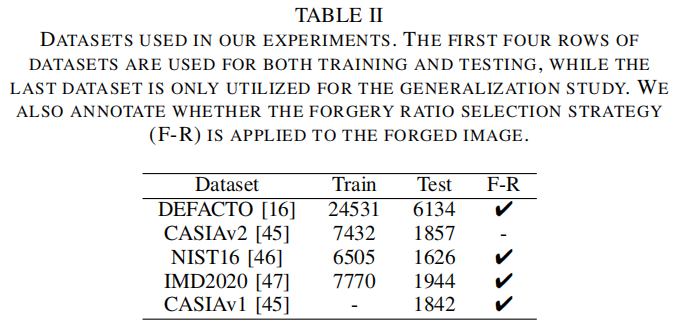
为了与最先进的方法进行合理的比较,我们选择了5个公共数据集:DEFACTO[16]、CASIAv2
[45]、NIST16 [46]、IMD2020 [47]和CASIAv1
[45]。在训练集中,伪造图像中被篡改区域的比例越大,对伪造伪影的学习效果就越好。因此,我们对DEFACTO[16]、NIST16
[46]、IMD2020 [47]和CASIAv1
[45]采用了伪造率选择策略,只剩下伪造率为[0.2,0.8]的图像。DEFACTO[16]是一个具有挑战性的数据集,它包含了所有四种篡改技术(复制-移动、拼接、删除和修改绘画)。CASIAv1
[45]和CASIAv2
[45]不包含地面真实掩码。我们通过对伪造图像和真实图像之间的阈值差异来计算相应的GT掩模。NIST16
[46]主要包含几何伪造图像。IMD2020
[47]包含真实的操纵图像。对于这些不同大小的数据集,我们不使用调整大小操作来统一这些数据集的大小,因为直接减少高分辨率的图像会对图像细节造成重大损害,甚至对伪造痕迹的损失。因此,在预处理阶段,训练和测试数据集中的所有图像都被裁剪到256×256×3。此外,训练和测试数据集是不相交的集。
2)基线网络:
我们选择了几种先进的方法来与DiRLoc进行比较。这些高级方法可以分为两种类型:一种用于伪造的JPEG图像任务,另一种用于常见的伪造图像任务。第一种类型包括IF-OSN
[15]、CAN-DAS [22]、ReLoc [11]和CAT-Net
[10]。他们在训练阶段引入JPEG图像来解决JPEG压缩问题。IF-OSN
[15]研究了在线社交传输对图像伪造定位的整体影响,我们只比较了其对抗JPEG压缩的能力,而该压缩是在线社交传输的重要组成部分。Rao等人[22]提出的比较方法的主要部分是压缩近似网络和域自适应策略(CAN-DAS
[22])。我们在上述公共数据集上使用授权提供的代码来训练CAN-DAS
[22]。对于ReLoc [11]和CAT-Net
[10],我们使用它们的开放源代码。第二种类型,包括MVSS-Net [1]和ManTra-Net
[21],只在训练阶段使用初始伪造图像。为了进行公平的比较,我们在训练阶段直接使用伪造的JPEG图像而不是原始图像来重新训练MVSS-Net
[1]和ManTra-Net
[21]。
3)训练设置:
该方法DiRLoc采用PyTorch框架实现,所有实验均在NVIDIA
GeForce RTX 3090上进行。使用随机QFs(QF =
50、60、70、80、90、100)通过MATLAB
API功能从初始伪造图像I0将伪造的JPEG图像Ij压缩。我们选择QF的范围从50到100,因为来自真实社交媒体的图片通常都在这个范围内,并且这个设置被其他比较方法[22]使用。整个框架使用Adam优化器进行端到端训练,将小批量大小设置为10。我们采用F1分数和MCC作为性能指标。F1得分是精确度和查全率的调和平均值,范围为0~1,1表示完美的精确度和查全率。MCC在处理不平衡样本时特别有用,因为正样本和负样本的数量不相等。初始学习速率设置为10−5,每5个周期减少10%,在训练阶段,权重衰减固定为10−5。等式中的超参数λ1、λ2、λ3、λ4和λ5(11)分别设置为1、0.2、0.01、1和1。
B. 与最先进的方法进行比较
为了全面评估我们的方法的优越性,我们比较了DiRLoc与最先进的方法:
IF-OSN [15],CAN-DAS [22],ReLoc [11],CAT-Net [10],MVSS-Net
[1],和ManTra-Net [21]。比较实验在四个数据集上进行:DEFACTO[16]、CASIAv2
[45]、NIST16 [46]和IMD2020
[47]。我们分别对JPEG压缩图像和未压缩图像进行了充分的实验。
如表三所示,在具有固定阈值(0.5)的f1分数(F1)和在JPEG压缩图像中的Matthews相关系数(MCC)上,我们将我们的方法与各种最先进的方法进行了比较。
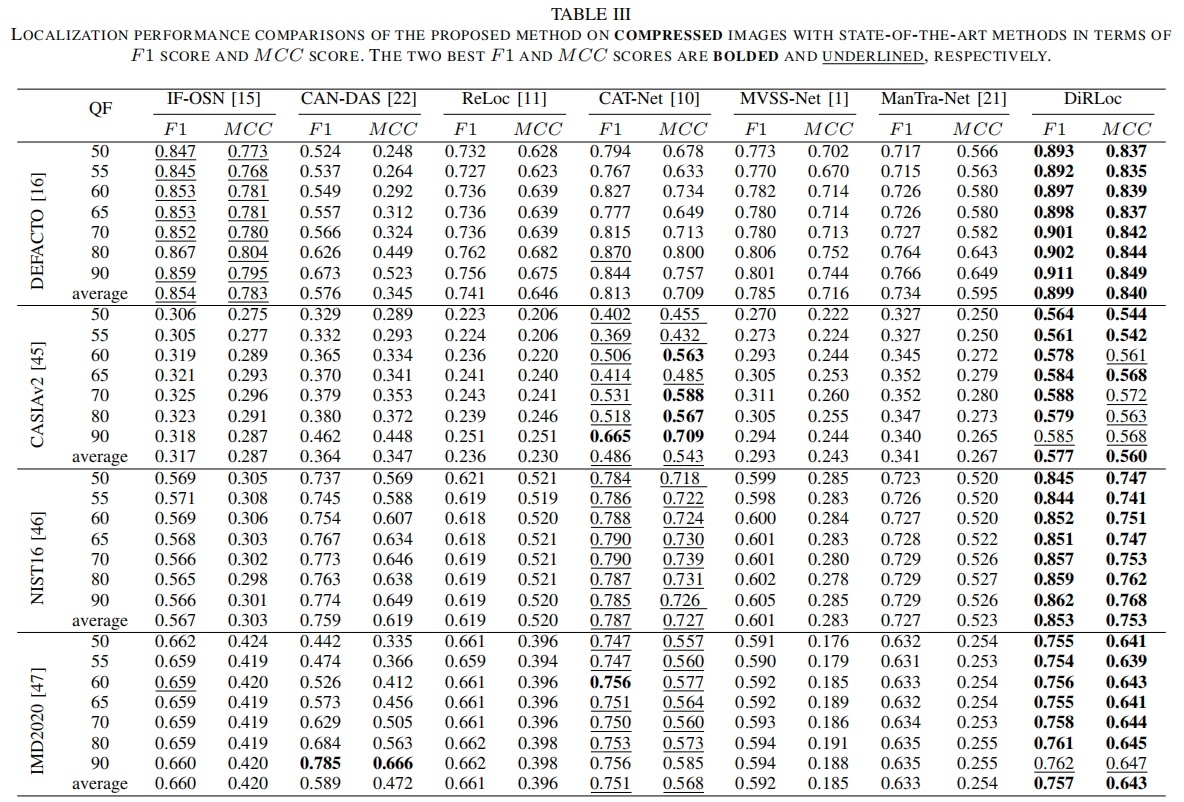
具体来说,为了彻底评价所提方法的鲁棒性,这些方法在QF =
50、55、60、65、70、80、90上进行了测试。每个数据集的最后一行显示了所有QF因素的平均性能。DiRLoc在所有数据集的不同QF因子下达到了前两个性能,特别是在数据集CASIAv2
[45]上,它达到了平均F1 = 0.577,比第二优的方法CAT-Net
[10]高出18%。在其他三个数据集上,即事实上的[16]、NIST16 [46]和IMD2020
[47],我们的方法的平均F1比第二优的方法高出5.2%、8.3%和0.7%。我们还在广泛的QFs上评估了我们的模型,以证明其对JPEG压缩的强鲁棒性。DiRLoc仍然优于其他基线,即使是在极端情况下,如QF
= 50,在那里它的F1分数在事实上的[16]数据集中比第二优的方法IF-OSN
[15]高出5.4%。IF-OSN
[15]在事实上的[16]数据集上表现良好,但在其他三个数据集上的性能有所下降。我们假设,这可能是因为IF-OSN
[15]通过比较压缩数据和未压缩数据之间的差异来建模JPEG压缩过程,在事实上的[16]数据集中有更多的训练样本,从而更容易学习差异。由于渐进式解纠缠策略,DiRLoc在较少的训练样本上取得了良好的性能。为了进一步比较泛化结果,我们用QF
= 55和QF = 65设置了两个测试用例,它们没有出现在训练集中。CAT-Net
[10]在CASIAv2 [45]、NIST16 [46]和IMD2020
[47]数据集上取得了第二好的结果。然而,在QF = 55和QF =
65的情况下,事实上的[16]数据集上的CAT-Net [10]的F1和MCC都低于QF = 50和QF
=
60,而DiRLoc受到非常小的干扰。
虽然我们的问题设置集中在伪造的JPEG图像上,但DiRLoc在非JPEG压缩数据集上也获得了优越的性能。表四展示了DirLoc在非jpeg压缩图像上的定位性能。

JPEG压缩可以被视为对数字图像的强干扰,从而导致阻塞伪影、振铃效应等。这些复杂的压缩轨迹与图像篡改伪影重叠。我们专门设计的DiRLoc经过训练,提取了更多的内在和基本特征,这些特征与篡改痕迹高度相关,从而减轻了复杂JPEG痕迹的干扰。然而,CAT-Net和MVSS-Net的性能在非jpeg压缩图像上表现出明显的下降。这主要是由于在训练数据集中缺少非jpeg压缩图像。因此,这些方法并没有学习到这些非jpeg压缩图像的特征,并且无法处理它们。该方法即使在非jpeg压缩数据集上进行训练,仍能获得良好的结果,很好地反映了其泛化性。
此外,我们观察到,在NIST16
[46]和IMD2020
[47]数据集上,有几种方法在90到50的QFs范围内表现出稳定的性能。导致这种现象有两个原因。首先,在训练数据集和测试数据集中的JPEG压缩范围是一致的。在训练阶段,我们采用了一种数据增强策略,将来自集合{50、60、70、80、90、100}的不同质量因子(QF)值随机应用到训练数据集中的图像上。而在测试阶段,QF的范围与训练集保持一致。这意味着该模型已经被训练成对各种压缩伪影具有鲁棒性,从而在对使用不同QF值压缩的图像进行评估时获得相对稳定的性能。其次,我们假设IMD2020
[47]和NIST16 [46]数据集比事实上的[16]和CASIAv2
[45]数据集包含更少的测试图像。因此,在这些较小的测试集上,不同压缩级别之间的性能差异可能不那么明显,这可能导致测试模型获得更稳定的结果。
最后,我们将定性定位结果与图10中所有测试数据集上的预测结果进行了比较,说明了我们可以更精确地定位伪造区域的情况。

DiRLoc的预测结果显示在最后一列中。与其他最先进的方法相比,DiRLoc的预测结果与实际结果最接近,这也表明了该方法的优势。这些伪造的图像具有复杂的篡改边界、纹理、光和影效果等。这些锻造的区域与周围的场景融合在一起,即使是人眼也无法区分。大多数被比较的方法都失败了,但我们的方法仍然可以找到正确的区域。
C. 泛化研究
D. 消融研究
V.结论
本文从一个全新的角度研究了针对JPEG压缩的伪造图像定位问题。所提出的框架DiRLoc利用渐进式解纠缠策略和决策策略获得了一个稳定、准确的预测。渐进式解纠缠策略包括粗粒度图像解纠缠阶段和细粒度元素解纠缠阶段,分别专注于去除JPEG跟踪和学习内容不可知的伪影。最后,该决策策略对这些多尺度伪影进行了推理,以实现像素级预测。定量和定性实验结果表明,该方法DiRLoc在一般的抗jpeg压缩图像伪造定位任务中优于最先进的方法,特别是在泛化性能方面。本研究的主要局限性是,它主要针对的是JPEG压缩的常见图像处理方法,而没有解决在现实应用中遇到的更广泛的图像操作,如在社交网络中发现的那些。在未来,我们计划将这项工作扩展到处理更复杂和多样化的场景中的图像伪造定位任务,包括那些在社交媒体平台中普遍存在的任务。