EditGuard:Versatile Image Watermarking for Tamper Localization and Copyright Protection

EditGuard: Versatile Image Watermarking for Tamper Localization and Copyright Protection
Xuanyu Zhang\(^{1,2}\), Runyi Li\(^1\) , Jiwen Yu1 , Youmin Xu\(^1\) , Weiqi Li\(^1\) , Jian Zhang\(^{1,2}\)
1 School of Electronic and Computer Engineering, Peking University
2 Peking University Shenzhen Graduate School-Rabbitpre AIGC Joint
Research Laboratory
摘要
在人工智能生成内容(AIGC)的时代,恶意篡改对版权的完整性和信息安全构成了迫在眉睫的威胁。目前的深图像水印,虽然被广泛接受用于保护视觉内容,但只能保护版权和确保可追溯性。它们未能将日益现实的图像篡改本地化,这可能导致信任危机、侵犯隐私和法律纠纷。为了解决这一挑战,我们提出了一个创新的主动取证框架EditGuard,以统一版权保护和篡改不可知的定位,特别是对于基于AIGC的编辑方法。它可以提供一个细致的嵌入难以察觉的水印和精确解码篡改区域和版权信息。利用我们观察到的图像图像隐写的脆弱性和局部性,EditGuard的实现可以转换为一个统一的图像比特隐写问题,从而完全将训练过程与篡改类型解耦。大量的实验验证,我们的编辑guard平衡了篡改定位精度、版权恢复精度和各种基于AIGC的篡改方法的普遍性,特别是对于肉眼难以检测的图像伪造。
1.介绍
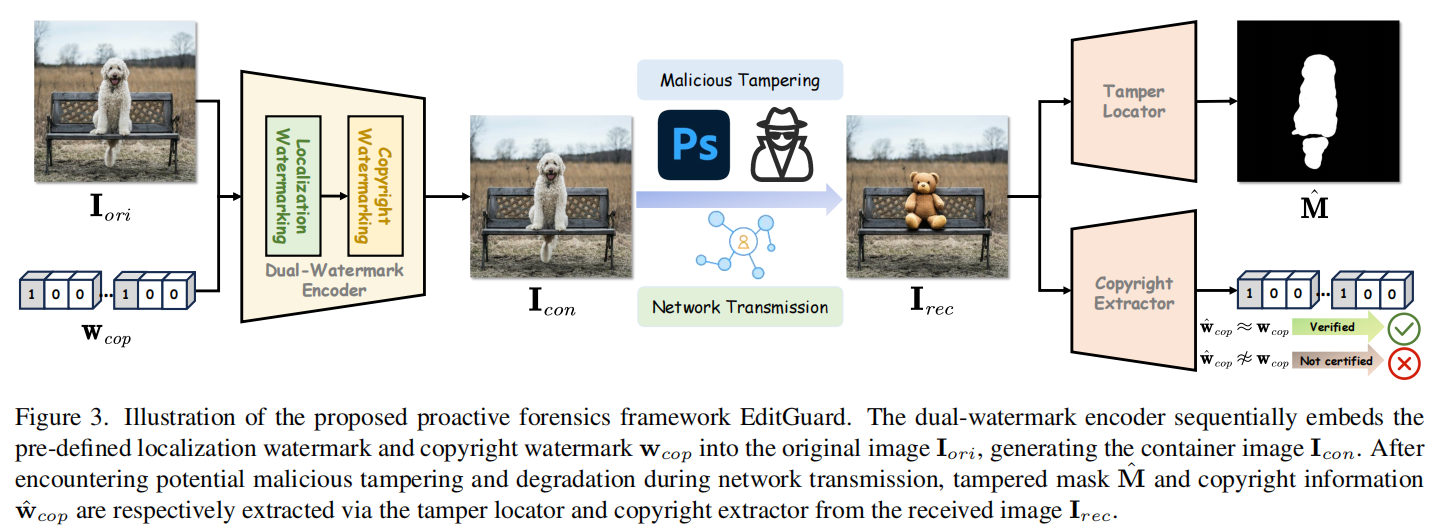
为了明确我们的任务范围,我们再次强调了双重取证任务的定义,如图1所示:

(1)版权保护:“这个图像属于谁?”我们渴望准确地检索一幅图像的原始版权,甚至遭受各种篡改和退化。
(2)篡改定位:“这张照片是在哪里被操纵的?”我们的目标是精确定位被篡改的区域,不受特定篡改类型的限制。
据我们所知,没有现有的方法同时完成这两项任务,同时保持高精度和广泛推广的平衡。
为了满足这一迫切的需求,我们提出了一种新的主动取证框架,称为EditGuard,以保护版权和为基于AIGC的编辑方法本地化篡改区域。具体来说,灵感从我们观察到的图像到图像(I2I)的脆弱性和隐写术固有的鲁棒性,我们可以转换实现的联合图像比特隐写术问题,允许训练编辑完全解耦的篡改类型,从而赋予其特殊的泛化性和以零镜头的方式定位篡改。简而言之,我们的贡献如下:
(1)我们首次尝试设计一个深度通用的主动取证框架EditGuard,用于通用篡改定位和版权保护。它将双隐形水印嵌入到原始图像中,并准确地解码被篡改的区域和版权信息。
(2)我们观察了I2I隐写技术的脆弱性和局部性,创新地将该双取证任务的解决方案转换为训练一个统一的象位隐写网络(IBSN),并利用IBSN的核心组件构建EditGuard。
(3)我们引入了一个基于提示的后验估计模块,以提高该框架的定位精度和退化鲁棒性。
(4)我们的方法的有效性已经在我们构建的数据集和经典的基准测试上得到了验证。与其他竞争方法相比,我们的方法在定位精度、泛化能力和版权精度方面具有显著的优点,而不需要任何标记数据或对特定的篡改类型需要额外的训练。
2.相关工作
2.1.篡改定位
2.2.图像水印
3.EditGuard总体框架
3.1.动机
现有方法的挑战:
(1)如何装备现有的水印方法,仅是为了版权保护,具有定位篡改的能力是编辑保护的关键。我们将通过第3.2节中的框架设计来解决它。
(2)以往大多数篡改定位方法在网络训练中不可避免地引入特定的篡改数据,但在未知篡改类型中往往会引起泛化问题,这将在第3.3节中解决。

我们的观察:
幸运的是,我们观察到图像到图像(I2I)的隐写术表现出明显的脆弱性和定位性,具有解决这些问题的巨大潜力。具体地说,I2I隐写[3,28,42,46,64,69]的目标是将秘密图像\(\mathbf{X}_{sec}\)隐藏到封面图像\(\mathbf{X}_{cov}\)中,以生成容器图像\(\mathbf{X}_{con}\),并以最小失真准则从接收图像\(\mathbf{X}_{con}^{\prime}\)中显示\(\mathbf{\hat X}_{sec}\)和\(\mathbf{\hat X}_{cov}\)。我们发现,当\(\mathbf{X}_{con}^{\prime}\)比\(\mathbf{X}_{con}\)发生显著变化时,\(\mathbf{\hat
X}_{sec}\)也会被损坏并产生伪影(图2的第一行),这被称为脆弱性。此外,我们注意到\(\mathbf{\hat
X}_{sec}\)中的伪影几乎是像素级对应的\(\mathbf{X}_{con}^{\prime}\)相对于\(\mathbf{X}_{con}\)的变化,这被称为定位性。为了证明这一定位性,我们在\(\mathbf{\hat
X}_{sec}\)选择了5个7×7点集,并计算了它们关于\(\mathbf{X}_{con}^{\prime}\)的属性图。如图2的第二行所示,\(\mathbf{\hat X}_{sec}\)只在\(\mathbf{X}_{con}^{\prime}\)的相应位置及其附近表现出强烈的响应,几乎与其他像素无关。这些特性促使我们将\(\mathbf{X}_{sec}\)视为一种特殊的定位水印,并将其嵌入到现有的水印框架中。
3.2.框架设计和取证过程
实现统一篡改定位和版权保护,EditGuard设想嵌入二维定位水印和一维版权可追溯水印以难以察觉的方式到原始图像,这允许解码结束获得图像的版权和二进制掩码反映篡改区域。然而,设计这样一个框架需要解决两种类型的水印的兼容性问题。
(1)局部vs全局:定位水印需要隐藏在原始图像对应的像素位置上,而版权水印需要与空间位置无关,并冗余地嵌入到全局区域中。
(2)半脆弱vs鲁棒:定位水印的期望属性是半脆弱的,这意味着它在网络传输过程中对篡改很脆弱,但对一些常见的退化(如高斯噪声、JPEG压缩和泊松噪声)具有鲁棒性。然而,版权应该几乎无损,无论篡改还是退化。
为了解决这两个关键冲突,EditGuard采用了“顺序编码和并行解码”结构,其中包括双水印编码器、篡改定位器和版权提取器。
如图3所示,双水印编码器将把用户提供的预定义的定位水印和全局版权水印\(\mathbf w_{cop}\)依次添加到原始图像\(\mathbf I_{oir}\)中,形成容器图像\(\mathbf I_{con}\)。我们的实验已经证明并行编码不能有效地添加到图像(在补充材料(S.M.))。相比之下,顺序嵌入通过隐藏这两个水印可以有效地防止交叉干扰。此外,我们对接收(篡改)图像\(\mathbf I_{rec}\)从\(\mathbf I_{con}\)转换为的网络传输过程建模为: \[{\mathbf I}_{r e c}=\mathcal D({\mathbf I}_{c o n}\odot(\bf1-\bf M)+\mathcal T({\bf I}_{c o n}\odot{\bf M})\] 式中,\(\mathcal T (\cdot)\)、\(\mathcal D (\cdot)\)和\(\bf M\)分别表示篡改功能、降级操作和回火掩模。此外,并行解码过程使我们能够在不同的鲁棒性水平下灵活地训练每个分支,并通过篡改定位器获得预测掩码\(\hat M\),通过版权提取器获得可追溯性水印\(\hat{\mathbf w}_{cop}\)。我们可以将EditGuard的双重取证过程分为以下场景。
场景1:如果\(\hat{\bf
w}_{c o p}\not\approx\bf {w}_{c o p}\),那么置信度低的\(\mathbf
I_{rec}\)要么没有在我们的EditGuard中注册,要么经历了极其严重的全局篡改,使其成为不可靠的证据。
场景2:如果\(\hat{\bf w}_{c o p}\approx\bf {w}_{c o
p}\)且\(\hat M \not\approx
0\),那么置信度低的\(\mathbf
I_{rec}\)经历了篡改,取消将其作为有效证据的资格。用户可以根据\(\hat
M\)推断篡改者的意图,并决定是否启用图像的其他部分。
场景3:如果\(\hat{\bf w}_{c o p}\approx\bf {w}_{c o
p}\)且\(\hat M \approx
0\),那么\(\mathbf
I_{rec}\)在EditGuard的盾牌下保持不被篡改且值得信赖。
3.3.将双重取证转化为隐写术
为了实现通用且篡改不可知的定位性能,我们利用了我们观察到的I2I隐写术的局部性和脆弱性。
如第3.1节所述,通过图像的隐写和揭示,可以有效地实现图3中的定位水印和篡改定位性能。同时,结合当前位对图像隐写技术的鲁棒性,通过位加密和恢复,实现了图3中的版权水印和提取器。因此,我们可以将双取证框架EditGuard的实现转换为一个统一的图像比特隐写术网络。
我们的训练目标只是一种自我恢复机制,这意味着它只需要确保隐写术网络的输入和输出在不同的鲁棒性水平下保持高保真度,而不需要引入任何标记数据或篡改样本。
在推理过程中,它可以通过简单的零镜头比较来自然地定位篡改,并准确地提取版权。
4.联合图像比特隐写术网络IBSN
4.1.网络架构
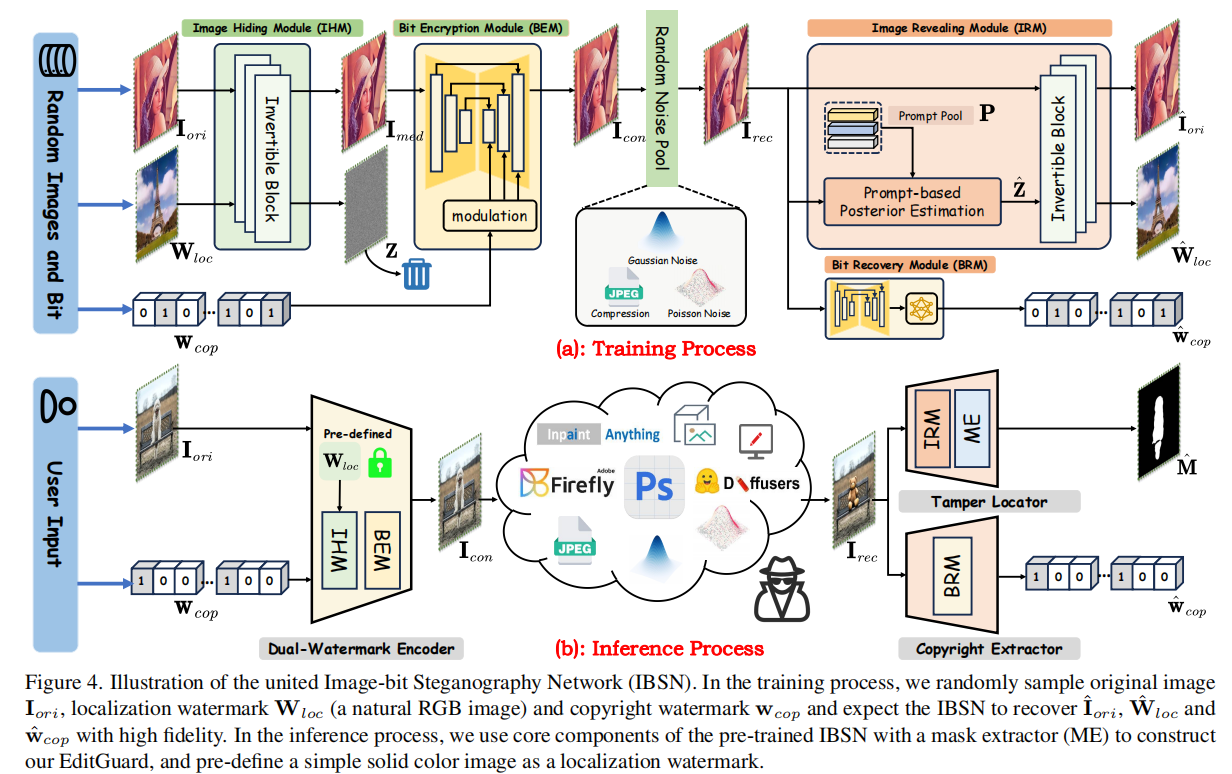
如图4所示,所提出的IBSN(Image-bit Steganography Network)包括图像隐写模块(IHM,image hiding module)、比特加密模块(BEM,bit encryption module)、比特恢复模块(BRM,bit recovery module)和图像显示模块(IRM,image revealing module)。首先,图像隐写模块IHM的目标是将一个定位水印\({\bf W}_{l o c}\in\mathbb{R}^{H\times W\times3}\)隐藏到原始图像\({\bf I}_{ori}\in\mathbb{R}^{H\times W\times3}\)中,从而得到一个中间输出\({\bf I}_{med}\in\mathbb{R}^{H\times W\times3}\)。随后,将\({\bf I}_{med}\)输入到比特加密模块BEM进行特征细化,同时将版权水印\(\mathbf w_{cop}\in\{0,1\}^{L}\)输入到比特加密模块BEM,形成最终的容器图像\({\bf I}_{con}\in\mathbb{R}^{H\times W\times3}\)。在网络传输后,比特恢复模块BRM将从接收到的容器图像\({\bf I}_{rec}\)中如实地重建版权水印\(\hat{\bf w}_{c o p}\)。同时,\({\bf I}_{rec}\)通过基于提示的后验估计对缺失的信息\(\hat Z\)进行预测,并将其作为可逆块的初始化,产生\({\bf \hat I}_{ori}\)和半脆性水印\(\hat{\bf W}_{l o c}\)。
4.2.图像隐写模块IHM和图像显示模块IRM中的可逆块
考虑到基于流的模型具有精确恢复多媒体信息的固有能力,我们利用堆叠的可逆块来构造图像隐藏和揭示模块。原始图像\({\bf I}_{o r i}\in\mathbb{R}^{H\times W\times3}\)和定位水印\({\bf W}_{l o c}\in\mathbb{R}^{H\times W\times3}\)将经过离散小波变换(DWT),得到频率解耦的图像特征。然后,我们使用增强的加性仿射耦合层来投影原始图像及其相应的定位水印分支。这些转换参数将相互生成。增强的仿射耦合层由五层密集卷积块[46]和轻量级特征交互模块(LFIM)[4]组成。LFIM可以增强转换的非线性,并以低计算成本捕获长期依赖性。更多细节见S.M.。最后,通过反DWT将显示的特征转换到图像域。
4.3.基于提示的后验估计
为了提高图像隐藏和揭示模块的保真度和鲁棒性,我们引入了一个基于退化提示的后验估计模块(PPEM, posteriori estimation module)。由于编码网络倾向于将\([{\bf I}_{o r i};{\bf W}_{l o c}]\in\mathbb{R}^{H\times W\times3}\)压缩到容器图像\({\bf I}_{c o n}\in\mathbb{R}^{H\times W\times3}\)中,以前的方法[42,64]通常在解码端使用随机高斯初始化或全零映射来补偿丢失的高频信道。然而,我们的观察表明,被丢弃的信息隐藏在容器图像的边缘和纹理中。因此,部署专用网络被证明是用来预测消失的定位水印信息的后验均值\(\mathbf{\hat Z}=\mathbb{E}[Z|{\bf I}_{rec}]\)的一种更有效的策略。
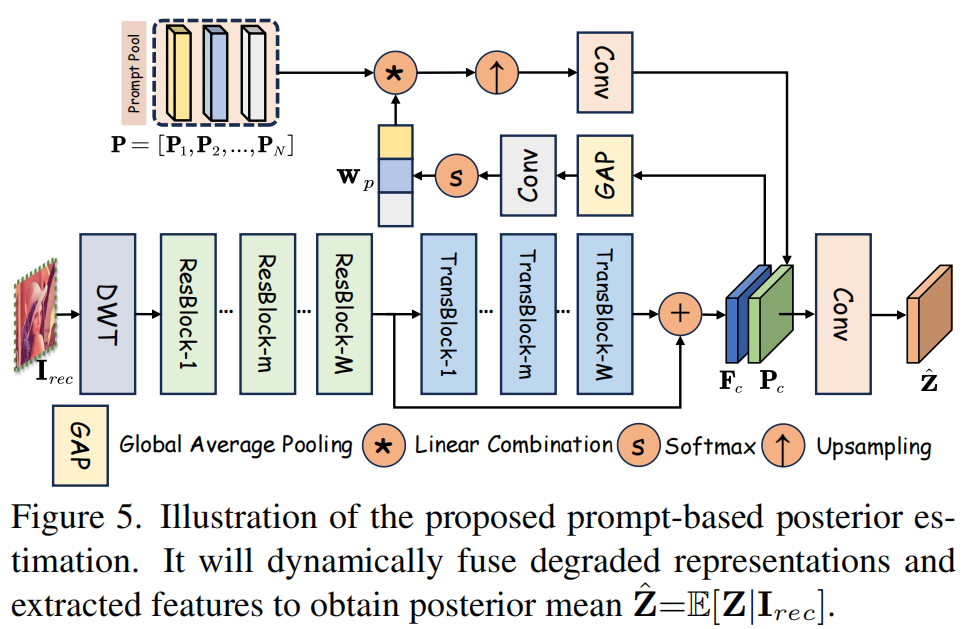
具体来说,如图5所示,我们堆叠M个残差\(\mathrm{Res}(\cdot)\)[19]和M个通道级变压器块\(\mathrm{Trans}(\cdot)\)[70],以提取局部和非局部特征\(\mathbf{F}_c\)。 \[\mathbf{F}_{c}=\mathrm{Trans}(\mathrm{Res}(\mathrm{D}W\mathrm{T}(\mathbf{I}_{r
e c})))+\mathrm{Res}(\mathrm{D}W\mathrm{T}(\mathbf{I}_{r e
c})).\]
考虑到容器图像在网络传输过程中容易发生各种退化,我们将N个可学习的嵌入张量预先定义为退化提示\(\mathbf{P} =
[\mathbf{P}_{1},\mathbf{P}_{2},\cdot\cdot\cdot,\mathbf{P}_{N}]\),其中N表示退化类型的数量,设置为3。这些学习到的提示\(\mathbf{P}\)可以自适应地学习不同范围的退化表示,并与从\({\bf I}_{r e
c}\)中提取的内在特征集成,使所提出的IBSN能够使用一组参数处理多种类型的退化。为了更好地促进输入特征\(\mathbf{F}_{c}\)和退化提示\(\mathbf{P}\)之间的交互作用,将特征\(\mathbf{F}_{c}\)传递到全局平均池化(GAP)层、1×1卷积和softmax算子,以产生一组动态权值系数。每个退化提示符\(\mathbf{P}_{i}\)使用这些动态系数\(\mathbf{W}_{p\circledast
i}\)进行组合,然后通过上采样算子\(\uparrow\)和3×3卷积进行积分,以获得增强的表示\(\mathbf{P}_{c}\)。 \[\mathbf{P}_{c}=\mathrm{Conv_{3x3}}\left(\left(\sum_{i-1}^{N}\mathbf{w}_{p\circledast i}\mathrm{P}_{i}\right)_{\uparrow}\right),\]
其中\({\bf w}_{p}=\mathrm{Softmax}\left({\bf
C o n v}_{1\times1}({\bf C}{\bf A P}\left({\bf
F}_{c}{\bf\rangle}\right)\right)\)。
最后,我们利用3×3卷积来融合基于提取的特征\(\mathbf{F}_{c}\)的学习退化表示,以丰富退化特定的上下文,获得\(\mathbf{\hat Z}\)。此过程可表述为: \[\hat{\mathbf{Z}}=\operatorname{Conv}_{3\times
3}\left([\mathbf{P}_{c};\mathbf{F}_{c}]\right)\in\mathbb{R}^{\frac{H}{2}\times\frac{W}{2}\times12}.\]
4.4.比特加密和恢复模块
如图4所示,为了将版权水印的\({\bf w}_{cop}\)编码到\({\bf I}_{med}\)中,我们首先通过堆叠的MLPs扩\({\bf w}_{cop}\in\{0,1\}^L\),并将其重塑为几个L×L消息特征图。同时,将\({\bf I}_{med}\)馈入u型特征增强网络,提取每个下采样和上采样层的特征。最后,通过融合机制[21,62],将消息特征进行升级,并与多层次图像特征进行集成,实现双定时信息的调制。在解码端,\({\bf I}_{rec}\)被馈入一个u形的子网络,并被降采样到L×L的大小。然后通过MLP提取恢复的版权水印\({\bf \hat w}_{cop}\)。更多细节见S.M.。
4.5.通过IBSN构建EditGuard
为了稳定所提出的IBSN的优化,我们提出了一种双级优化策略。给定任意原始图像图像和水印\({\bf w}_{cop}\),首先通过\(\ell_2\)损失训练比特加密和恢复模块。 \[\ell_{c o p}=\|\mathbf{I}_{c o n}-\mathbf{I}_{m e d}\|_{2}^{2}+\lambda\,\|\hat{\mathbf{w}}_{c o p}-\mathbf{w}_{c o p}\|_{2}^{2}\] 其中,\(\lambda\)被设置为10。此外,我们冻结了比特加密模块BEM和比特恢复模块BRM的权值,并联合训练了图像隐写模块IHM和图像显示模块IRM。给定一个随机的原始图像\({\bf I}_{ori}\)、定位水印\({\bf W}_{loc}\)和版权水印\({\bf w}_{cop}\),其损失函数为: \[\ell_{l o c}=\|{\bf I}_{o r i}-\bf I_{o r i}\|_{1}+\alpha\|\bf I_{c o n}-I_{o r i}\|_{2}^{2}+\beta\|\bf\hat{W}_{l o c}-W_{l o c}\|_{1}\] 其中,\(\alpha\)和\(\beta\)分别设置为100和1。在训练期间,我们只引入降级,没有暴露到任何篡改。在获得预先训练的IBSN后,我们可以通过IBSN的组件构建所提出的EditGuard。如图4所示,EditGuard的双水印编码器由图像隐写模块IHM和图像显示模块BEM组成,分别对应于图3中的定位水印和版权水印。版权提取器严格对应于比特恢复模块BRM。篡改定位器包括图像显示模块IRM和掩模提取器(ME)。注意,我们需要预先定义一个定位水印\({\bf W}_{loc}\),它在编码端和解码端之间共享。\({\bf W}_{loc}\)的选择对于我们的方法来说是非常普遍的。它可以是任何自然图像,甚至是纯色图像。最后,通过比较预定义的水印\({\bf W}_{loc}\)与解码的\(\hat{\bf W}_{loc}\),我们可以得到一个二进制掩码\({\bf M}\in\mathbb{R}^{H\times W}\): \[\hat{\mathrm{M}}[i,j]=\theta_{\tau}(\mathrm{max}(|\hat{\mathrm{W}}_{l o c}[i,j,:]-\mathrm{W}_{l o c}[i,j,:]))\]
5.实验
5.1.实施细节
我们通过COCO [38]的训练集来训练我们的EditGuard,而没有任何被篡改的数据。因此,对于篡改定位,我们的方法实际上是零次学习的。Adam [30]用于用\(\beta_1=0.9\)和\(\beta_2=0.5\)训练250K次迭代。学习速率初始化为1×10−4,每30K迭代减少一半,批处理大小设置为4。我们在原始图像中嵌入一个64位的版权水印和一个简单的定位水印,如纯蓝色图像([R,G,B] = [0,0,255])。随后,跟随[8,17,39],使用F1-score、AUC、IoU和比特精度来评估定位和版权保护性能。由于之前的任何方法都不能同时实现这种双重取证,所以我们对篡改定位和图像水印方法进行了单独的比较。
5.2.与定位方法的比较
为了与篡改定位方法进行公平的比较,我们对四个经典基准[9,16,20,58]进行了广泛的评估,如表一所示。
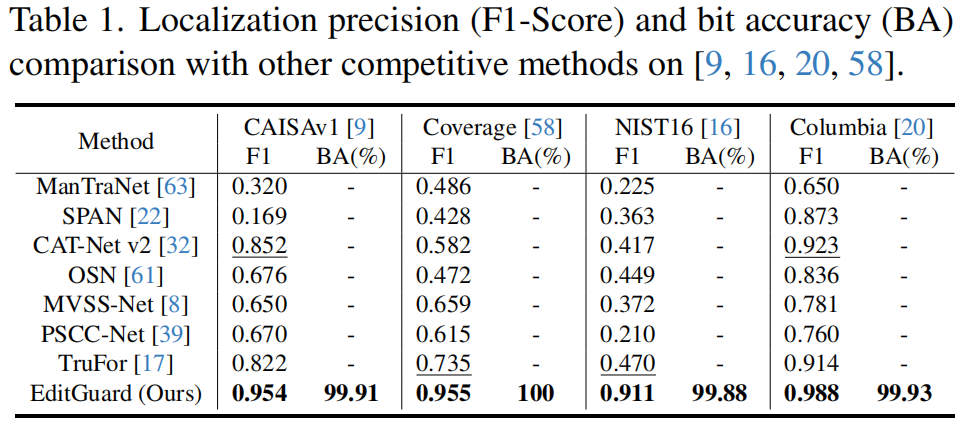
由于EditGuard是一种主动的方法,我们首先将水印嵌入到真实的图像中,然后将被篡改的区域粘贴到容器图像中。值得注意的是,即使是现有方法专门从事的篡改类型,EditGuard的定位精度在四个数据集上始终优于SOTA方法[17],F1分数分别提升为0.102、0.116、0.441和0.065,这验证我们主动定位机制的优越性。

如图6所示,我们的EditGuard可以精确定位像素级的篡改区域,但其他方法只能产生一个粗略的轮廓或仅在某些情况下有效。同时,我们的比特精度保持在99.8%以上,而其他所有方法都无法实现有效的版权保护。
5.3.与水印方法的比较
5.4.扩展到基于AIGC的编辑方法
5.5.鲁棒性分析
5.6.消融研究
6.结论
我们首次尝试设计一种深多功能水印机构EditGuard。它通过嵌入难以察觉的定位和版权水印,解码准确的版权信息和篡改区域,提高图像的可信度,使其成为艺术创作和法律法医分析的可靠工具。在未来,我们将重点提高EditGuard的鲁棒性,不仅努力提供像素级的定位结果,而且努力提供语义级的结果。此外,我们计划进一步扩展EditGuard到更广泛的模式和应用程序,包括视频、音频和3D场景。我们在信息真实性方面的努力不仅服务于AIGC行业,也服务于我们对数字世界的信任,确保每个像素都能说出真相,每个人的权利都得到保障。