Efficient_Video_Integrity_Analysis_Through_Container_Characterization
Efficient Video Integrity Analysis Through Container Characterization
Pengpeng Yang , Student Member, IEEE, Daniele Baracchi , Massimo Iuliani , Dasara Shullani ,Rongrong Ni , Yao Zhao , Senior Member, IEEE, and Alessandro Piva , Fellow, IEEE
摘要
大多数视频取证技术主要通过分析数据流中的痕迹来取证,但在处理高度压缩或低分辨率视频时往往效果欠佳。最新研究表明,有价值的取证线索其实也存在于视频容器结构中,这意味着无需直接查看媒体数据流,就能追溯视频文件的完整生命周期。本文提出一种基于容器的取证方法,不仅能识别视频篡改所用软件,还能在多数情况下确定源设备的操作系统。与现有技术相比,该方法不仅效率更高、效果更佳,还能为决策过程提供直观的解释依据。这是通过将基于决策树的分类器应用于视频容器结构的向量表示来实现的。我们在包含软件处理内容(ffmpeg、Exiftool、Adobe Premiere、Avidemux和Kdenlive)以及通过社交媒体平台(Facebook、抖音、微博和YouTube)交换的视频的7000个视频文件数据集上进行了广泛的验证。该数据集已向研究界开放。所提出的方法在区分原始视频与篡改视频以及分类编辑软件方面实现了97.6%的准确率,即使视频未经重新编码就被剪辑或被缩放至缩略图大小时也是如此。此外,对于大多数篡改视频,该方法还能正确识别源设备的操作系统。
提出的方法
我们可以将视频容器表示为带标签的树结构,其中内部节点和叶子节点分别对应原子和字段值属性。视频容器X可通过符号集合{s1,...sm}进行描述,其中符号si可以是:(i)从根节点到任意字段(不包含值)的路径,也称为字段符号;(ii)从根节点到任意字段值(包含值)的路径,也称为值符号。这种表示法的一个示例可表述为:4
总体而言,我们用Ω表示数字视频容器世界集合X = {X1,...,XN
}中所有唯一符号s1,...,sM的集合。类似地,C =
{C1,...,Cs}表示可能的来源集合(例如华为P9、苹果iPhone 6
s)。给定一个容器X,可以利用其符号集合{s1,...,sm}的不同结构,将视频分配到特定类别Cu中。
为此,我们采用二元决策树[19]构建分层决策结构。在每个内部节点中,系统会将输入数据与特定条件进行比对,根据测试结果选择子节点作为决策流程的下一步。叶节点则代表算法最终做出的决策结论,具体示例可参考图3。需要说明的是,我们的方法采用了基于生长-剪枝的分类回归树(CART)[20]。
考虑到唯一符号的数量|Ω|
=
M,视频容器X会被转换为一个整数向量X→(x₁...x_M),其中xi表示si在X中出现的次数。这种处理方式借鉴了词袋模型[21]的思想,该模型通过将可变长度的文档转换为固定长度的向量表示来实现高效处理。
需要说明的是,X数据集包含多个无法代表具体类别的符号,这些符号仅反映类别内部的变异性(例如与视频时长、采集日期和时间相关的信息)。这类信息可能在决策过程中引入干扰,因此建议进行过滤处理。为此,我们采用似然比框架对Ω数据进行了预筛选。给定两个类别Cu、Cv、u
= v,以及符号si时,其对数似然比(LLR) \[\log
L_{u,v}(s_{i})=\log{\frac{P(s_{i}|C_{u})}{P(s_{i}|C_{v})}}\]
是通过近似条件概率计算的 \[\begin{array}{r}{P(s_{i}|C_{u})=W_{C_{u}}(s_{i})}\\
{P(s_{i}|C_{v})=W_{C_{v}}(s_{i}),}\end{array}\]
其中WCu(si)和WCv(si)分别表示Cu和Cv中符号si的频率。当且仅当∃u,v,u
= v时,符号si才被保留:log
Lu,v(si)>τ(τ为阈值),否则将其视为无效符号并从Ω中移除。值得注意的是,通过似然比判断,我们可能保留某个字段符号却舍弃其对应值符号,反之亦然。这种机制能自动判断数值或字段对分类是否具有相关性。举个例子,我们考虑两个类别:
Cu:iOS设备,原生视频;
Cv:iOS设备,通过Exiftool修改的日期(详见第V节)。
图2展示了部分已实现的LLR值。在搭载iOS系统的设备上,moov/udta/XMP_/@stuff、moov/udta/XMP_/@ count、wide/@stuff和wide/@count等符号明显与这类操作相关。而像free/@stuff这类符号则可能被过滤掉,因为它们的LLR值接近零。在这种情况下,该操作仅影响少量符号。实际上,决策树只需通过检测moov/udta/XMP_/@stuff的存在等特征,就能在单个步骤中识别此类处理,如图3所示。
实验
在本节中,我们评估我们的方法在视频完整性和源分析上的有效性。
A.实施细节
我们提出的方法基于Pytorch框架实现。实验在NVIDIA
RTX4090显卡上进行,采用Adam优化器以1e-3的学习率训练20个周期。除非特别说明,实验中处理数值叶节点的默认方法是字符串拆分后的编码方式。除非另有说明,所有实验都将整个数据集或其子集按8:2的训练-测试比例进行划分。
我们的研究对比了四种近期基于视频容器的方法[9]
[13] [21]
[24]以及一种基于视频流的方法[20]。其中,Iuliani等人[9]开发了一个用于分析类MP4文件容器的无监督视频取证框架,该框架通过利用文件容器的结构和内容实现视频完整性验证与设备品牌识别。Yang等人[13]提出了一种计算视频文件容器信息中子结构出现概率的方法,采用词袋模型构建固定长度的特征向量进行视频完整性验证。在此基础上,Xiang等人[21]拓展了这一概念,考虑了向量构建过程中离散值与连续值并存的场景。Guera等人[24]提出了一种不依赖视频像素内容、通过分析视频流描述符来识别篡改视频的检测技术,该方法基于流描述符构建特征向量,并采用训练好的支持向量机和随机森林作为分类器。此外,Amerini等人[20]提出了一种独特的多流神经网络架构,专门用于检测社交网络分发视频中的双重压缩痕迹。
B.数据集和后处理操作
1)数据集:我们使用以下公开数据集来验证我们的方法的有效性:
- VISION [25]:
- EVA7K [13]:
2)后期处理操作:需要特别说明的是,EVA7K平台的所有视频处理操作均在上传至社交网络平台前完成。该流程包含9项后期处理操作,涉及6种不同软件类型,具体操作步骤如文献[13]所述:
- 剪辑+缩放:每个视频先用ffmpeg剪切,再重新编码;
- 剪辑无编码:使用ffmpeg剪切时,通过复制音视频编码参数来最小化操作痕迹;
- 加速:使用ffmpeg加速视频;
- 减慢:使用ffmpeg减速视频;
- 剪辑+缩放:使用ffmpeg剪切后将分辨率降至320x240;
- 剪辑-键盘:使用Kdenlive(v17.12.3)手动剪切保留5-7秒内容,保存为MP4格式(采用H264/AAC为主格式);
- 剪辑-AV:使用Avidemux(v2.7.4)手动剪切保留5-7秒内容,以MP4 Muxer设置保存副本;
- 剪辑-AP:使用Adobe Premiere Pro CC 2019手动剪切保留5-7秒内容,并以H.264中等比特率保存;
- 数据修改:使用Exiftool(v11.37)手动处理视频元数据以修改日期信息。
为了复现真实场景并模拟用户从社交平台下载视频后可能进行的常见二次处理操作,我们进一步采用ffmpeg工具对VISION和EVA7K数据集应用了若干典型后处理操作。设计的后处理操作如下:
- 使用默认参数进行转码1:仅指定了视频文件的输入和输出路径;
- 使用10种速率处理类型进行转码2:每个视频都采用十种转码速率中的一种进行处理:超快、超快、极快、更快、快、中等、慢、更慢、极慢和安慰剂。最后,ffmpeg会根据视频文件的编码参数和条件自适应地选择合适的参数;
- 15秒随机裁剪3:根据视频有效时长范围内的随机起始点,将每个视频裁剪为15秒片段。若视频时长不足15秒,则从视频起始点到终点提取可用时长;
- 随机水印嵌入4:从十张图片中随机选取一张作为水印嵌入到每个视频中。水印会随机放置在四个区域之一:左上角、左下角、右上角或右下角。水印尺寸设置为50x50像素。
C.完整性分析
1)视频完整性验证:我们通过判断视频是否经过后处理软件处理,进行第一次视频完整性验证实验。与文献[13]的实验设置类似,我们将EVA7K数据集(不含社交网络传播)中的视频按设备类型划分为35个子集,并采用穷尽式留一交叉验证策略——即34个子集用于训练,1个子集用于测试。通过这种方式,每个训练完成的模型都能用于测试由未见过的设备拍摄的视频。

表I汇总了不同方法的对应准确率。可以看出,我们的方法在区分“原始”与“篡改”两类任务中实现了100%的全局准确率,在竞争算法中表现最佳。同时可以发现,近期基于容器的方法[13] [21]也取得了良好效果。但正如后文将要阐述的,这类依赖人工设计容器特征的方法在实际场景中存在明显脆弱性。
我们进一步评估了不同方法在社交网络传输中进行鲁棒完整性验证的有效性。需要注意的是,社交平台会对上传的视频进行各种操作,以优化用户体验、确保平台标准并提升内容交付质量,主要包括自适应画质增强、水印处理和转码。这种操作必然会对上传视频的容器信息造成改变,从而对基于容器的取证方法产生负面影响。
具体而言,我们参照前述实验方法,对上传至社交平台的视频进行分析,验证其在上传前是否经过软件编辑。在此背景下,我们将研究结果与杨等人[13]、向等人[21]及阿梅里尼等人[20]的研究成果进行对比。如表II所示,我们的方法在准确率(ACC)和F1分数指标上均显著优于其他竞争算法。实验表明,当容器被社交平台修改时,人工设计的容器特征缺乏鲁棒性。但通过采用自适应容器特征描述技术,本框架展现出强大的任务特定容器特征学习能力。数据显示,针对社交平台传播场景,我们的方法仍能保持超过96%的准确率。
2)后处理软件识别:在本研究中,我们进一步拓展了对视频原创性的判断范围,旨在辨别视频是否经过Aidemex、Exiftool、ffmpeg、kdenlive或Premiere等软件处理。根据EVA7K数据集显示,存在包括剪辑与重新编码、加速/减速、剪切+缩放等在内的9种后期处理操作。我们使用该数据集进行实验,并将方法所得结果汇总于表III。数据显示我们的方法取得了最佳F1值。但值得注意的是,所有方法在识别Exiftool处理的视频时均存在较高误判率,这表明社交网络对Exiftool容器内嵌的取证信息造成了显著干扰。
D.来源分析
1)品牌识别:本小节将验证不同算法在设备品牌识别中的有效性。实验采用VISION数据集,该数据集包含来自11个不同品牌的35款设备及23种型号。具体品牌型号详见表IV。例如,D09苹果iPhone4与D10苹果iPhone均被归为同一品牌苹果。我们进行了涵盖全部11个品牌的视频测试,包括社交网络传播版本在内的多场景测试。

如表V所示,我们的方法在竞争性方法中表现最佳。在此背景下,我们的模型总体准确率达到94.62%。然而,如表VI所示,我们的方法错误地将小米和联想的17%视频归类为三星产品。根据[9]中的分析,这种现象可归因于小米和联想内部存在某些与三星设备共享相同固件的设备。例如,三星Galaxy S5和小米红米Note 3均采用Android 6.0.1系统。因此,在社交网络传输后,这些设备拍摄的视频中品牌相关信息遭到严重破坏,导致这两个品牌的准确率略有下降。
2)设备型号识别:本研究通过VISION数据集开展实验,旨在确定视频采集所使用的设备型号。需要特别说明的是,该任务是品牌识别的延伸,因为同一品牌但不同设备型号(如iPhone4和iPhone5)的视频会归入不同类别。相较于品牌识别,该任务更具挑战性——同品牌设备往往具有高度相似属性。如表IV所示,35台设备被划分为23个不同型号。
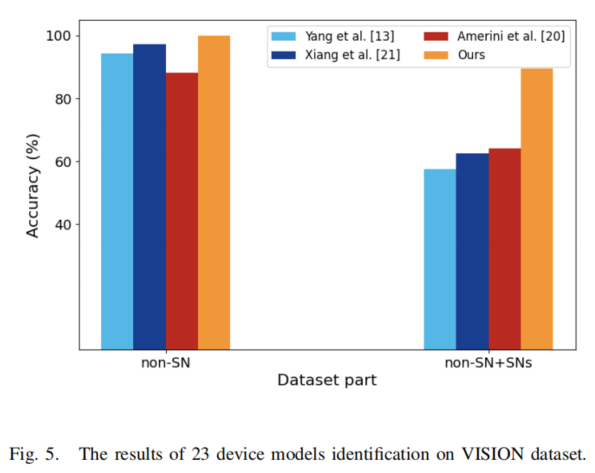
图5展示了视频在社交网络传播前后的识别结果对比。可以看出,我们的方法在无社交传播的视频中实现了完美设备型号识别,这表明即使同一品牌设备内部也存在独特信息。然而对于通过社交网络传播的视频,准确率降至89.47%。考虑到任务复杂性,这一结果仍属可接受范围。
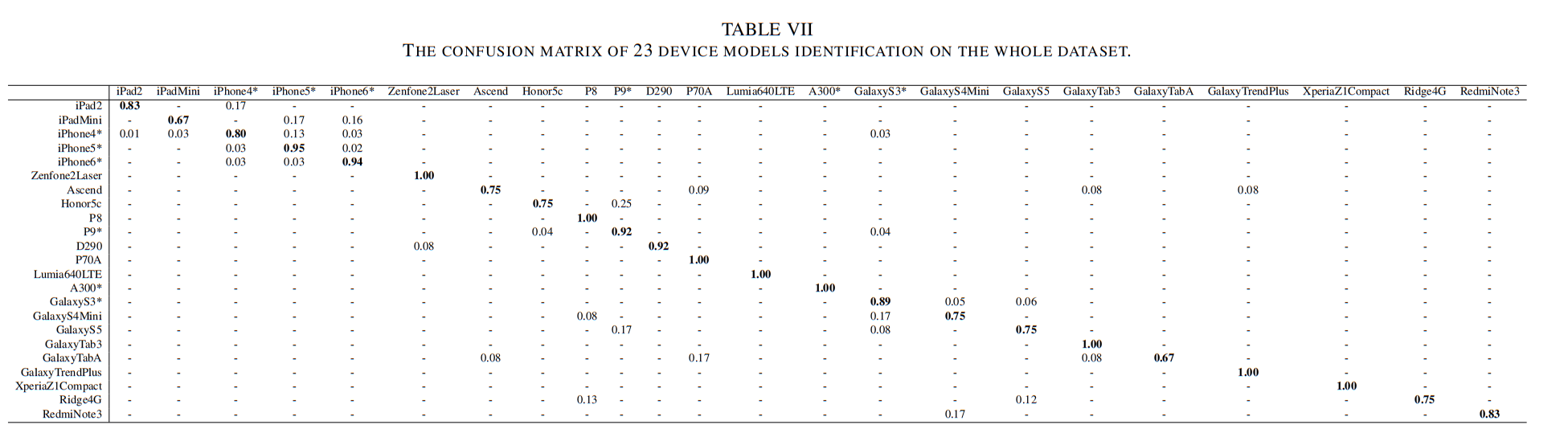
设备型号来源识别的混淆矩阵详见表VII。我们发现,大部分误判的设备型号都属于同一品牌。例如,我们的模型将17%和16%的原版iPad Mini视频错误归类为iPhone5和iPhone6。这凸显了社交平台处理方式可能削弱不同设备型号间细微差异的特征。
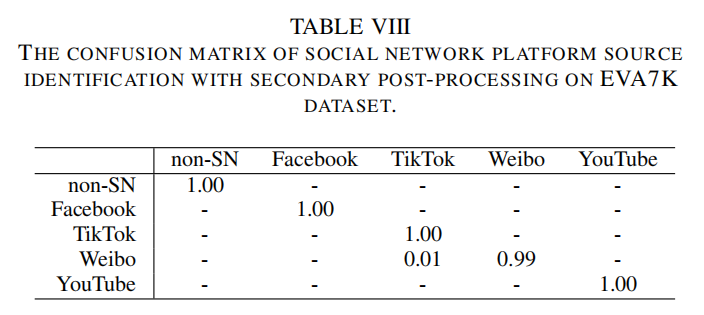
3)社交网络平台来源识别:在此场景中,我们通过实验来确定下载视频的来源社交网络平台。我们同时使用VISION数据集和EVA7K数据集。VISION数据集包含YouTube和WhatsApp,而EVA7K数据集则包含Facebook、抖音、微博和YouTube。为了模拟现实场景——即未经授权用户常在下载后对受版权保护的视频进行二次处理——我们纳入了常见的后期处理操作(具体操作类型详见数据集部分)。实验结果如图6所示。值得注意的是,没有二次处理,我们的方法在两个数据集上都达到了完美的100%准确率。这表明社交平台会在上传视频的容器中嵌入独特标识。即便经过常规二次处理,我们的方法仍能保持卓越精度,在EVA7K数据集上仅出现不足1%的性能损耗。为了清楚,我们在EVA7K数据集上方法的混淆矩阵报告在表VIII中。
这一结果强调了该方法在实际场景中的显著稳健性。
我们还对推理时间进行了全面分析,记录了各方法在Intel
Xeon Silver 4310 CPU上处理单个视频所需的时间。结果如图7所示。
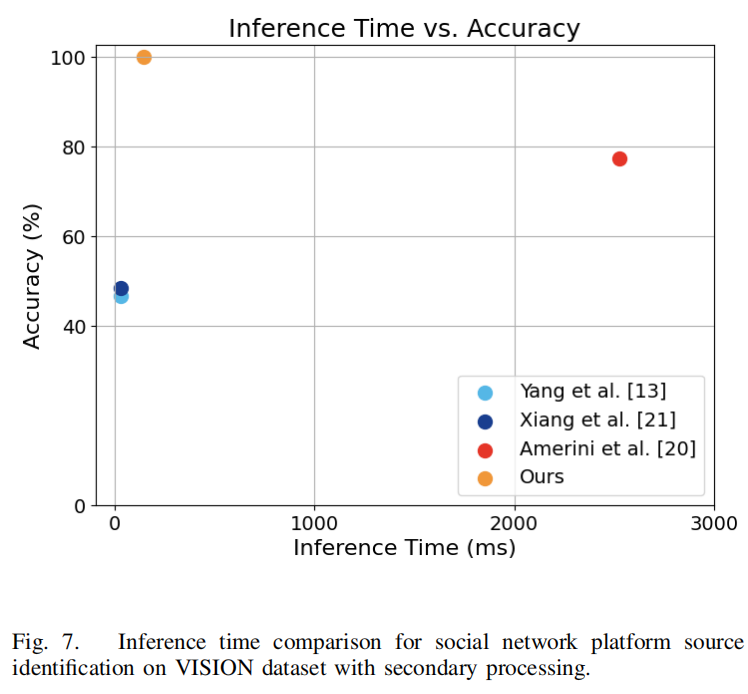
值得注意的是,我们的方法在准确性和计算效率方面表现更优(仅需147毫秒),在这两方面均超越了Amerini等人[20]的研究成果。与Yang等人[13]和Xiang等人[21]的方法相比,虽然处理时间稍长,但其准确率明显优于上述两种方法。
E.消融研究
在本小节中,我们进行了消融研究,以展示我们提出的拆分数量编码策略、层次语言表示和全局上下文标记的有效性。其中,拆分编码策略的重新移除意味着直接将编码数字与单词编码相同,而消除层次语言表示则需要将文本段落视为一个单一的长句子。
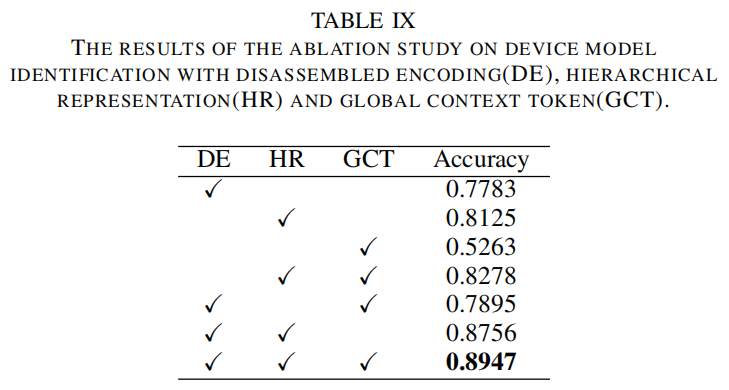
结果如表IX所示。当移除拆分编号编码策略时,可以观察到准确率下降了7%。这种下降可能源于训练过程中对特定数值属性的过度拟合。类似地,排除层级语言表征会导致准确率显著下降10%。将文本段落视为单一句子处理时,容器语义树的结构信息会变得模糊,削弱模型理解段落内部层级关系和上下文的能力。此外,分析还揭示了全局上下文标记的重要性——当排除全局上下文标记时,设备型号识别准确率下降约2%。这表明句子和段落的全局语义信息对于学习更具区分度的取证特征至关重要。这一显著提升凸显了全局上下文标注通过整合更广泛的情境洞察来增强模型性能的关键作用。
结论
本文提出了一种融合自适应容器特征与分层语言模型的视频完整性与源分析框架。视频完整性验证和源分析在多媒体安全领域具有关键作用,本研究通过高效的容器语言映射技术有效应对异构性挑战,无需人工特征标注即可实现整套框架的端到端训练。大量实验结果表明,该方法在社交网络传播场景及多种二次后处理中均展现出卓越性能,充分证明了其稳健性。我们的方法提供了新颖的见解,并对视频取证领域的研究具有重要价值。尽管我们的方法效果显著,但在设备模型识别任务的性能提升方面仍有很大空间。这一问题需要未来更多的共同努力。