ForensicHub:A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization

ForensicHub: A Unified Benchmark & Codebase for All-Domain Fake Image Detection and Localization
Bo Du1†, Xuekang Zhu1,2†, Xiaochen Ma3,4†, Chenfan Qu5, 2†, Kaiwen Feng1†,Zhe Yang1, Chi-Man Pun6, Jian Liu2‡, Jizhe Zhou1‡
1四川大学
2蚂蚁集团
3MBZUAI
4北京大学
5华南理工大学
6澳门大学
摘要
伪造图像检测与定位(FIDL)领域目前仍处于高度碎片化的状态,主要涵盖四大方向:深度伪造检测(Deepfake)、图像篡改检测与定位(IMDL)、人工智能生成图像检测(AIGC)以及文档图像篡改定位(Doc)。尽管部分领域已形成独立的基准测试,但针对FIDL所有领域的统一标准至今仍未建立。由于缺乏统一基准测试标准,各领域形成了明显的数据孤岛现象——不同机构各自为政地构建数据集、模型和评估方案,缺乏跨平台兼容性。这种孤立状态不仅阻碍了跨领域对比研究,更严重制约了FIDL技术的全面发展。为打破这种数据壁垒,我们推出了ForensicHub,这是首个面向全领域伪造图像检测与定位的统一基准测试平台及代码库。考虑到所有领域中数据集、模型和评估配置的剧烈变化,以及开源基准模型的稀缺性和某些领域的缺乏单独的基准,ForensicHub:i)提出了一种模块化和配置驱动的架构,将取证管道分解为跨数据集、转换、模型和评估器的可互换组件,允许在所有领域灵活组合;ii)通过基于适配器的设计,全面实现10个基线模型(其中3个为从头复制),6个主干网络,2个AIGC和文档新基准,并整合了DeepfakeBench和IMDLBenCo两个现有基准;iii)建立图像取证融合协议评估机制,支持不同任务中各类取证模型的统一训练与测试;iv)基于取证中心开展深度分析,针对FIDL模型架构、数据集特征及评估标准提供8项关键可操作性建议。具体来说,ForensicHub包含4个取证任务、23个数据集、42个基准模型、6个骨干网络、11项GPU加速的像素级与图像级评估指标,并实现了16种跨领域评估。该平台在打破FIDL领域壁垒方面实现了重大突破,为未来创新提供了重要启示。相关代码可在以下地址获取:https://github.com/scu-zjz/ForensicHub。
1 概述
"The whole is more than the sum of its parts" - Aristotle
近年来,随着各种数字图像编辑技术的快速发展,假图像变得越来越普遍。篡改图片的检测和定位(FIDL,Fake
Image Detection and
Localization)旨在区分部分篡改和完全生成的图像与真实图像。在FIDL中,术语“检测”指的是图像级别的分类,而“定位”则针对像素级别上更精细的篡改像素分割。
然而,随着时间的推移,FIDL的研究工作逐渐分裂为四个相对独立的研究领域。
1)深度伪造检测(Deepfake)[37,26,25,8,38,4,66,42,28,33,54,71,49,65,67]:检测诸如面部交换、表情编辑或特征替换等操作。
2)图像篡改检测/定位(IMDL)[5,17,29,35,70,53]:检测和定位自然图像中的篡改。
3)AI生成图像检测(AIGC)[40,18,63,59]:检测由Stable
Diffusion
[46]等深度生成模型完全生成的图像。
4)文档图像处理定位(文档)[48,43,6,12,52]:定位各种形式的文档图像伪造,包括收据、证书和识别材料,特别关注检测打印文本的修改。
尽管这四个领域因应用场景、操作类型和检测方法的差异而逐渐分化,但它们之间仍存在诸多共性与相似之处。作为视觉任务,这些领域普遍采用最先进检测或分割模型作为预训练骨干网络。此外,由于伪造图像制作者通常致力于保留语义合理且逼真的内容,所有领域都高度重视设计低级视觉特征提取器,以捕捉细微的非语义差异实现可靠检测。诸如对比学习等研究方法在这些领域中被广泛采用,用于挖掘判别性特征。我们在表1中总结了各领域中最先进的技术:骨干网络架构、伪影策略、输出类型及贡献度。虽然差异导致四个FIDL领域呈现碎片化特征,但共性要求我们通过统一视角来系统理解其内在联系。
表1:四个法医学领域的代表性方法总结,详细说明模型设计、主干、人工制品策略、输出格式和核心贡献。
| Task | Model | Backbone | Artifact Strategy | Output Type | Contribution |
|---|---|---|---|---|---|
| Deepfake | Capsule-Net [37] (ICASSP19) | VGG [50] | 动态路由 | 标签 | 提出了一种具有动态路由和VGG19主干的胶囊网络 |
| RECCE [4] (CVPR22) | Xception [7] | 重构 | 标签 | 提出了一种基于图的框架,利用重建差异 | |
| SPSL [28] (CVPR21) | Xception [7] | 相位谱 | 标签 | 提出了一种利用Xception进行相位谱融合的面部伪造检测方法 | |
| UCF [66] (ICCV23) | Xception [7] | 多任务解耦 | 标签 | 提出使用Xception进行深度伪造泛化的多任务解耦 | |
| SBI [49] (CVPR22) | EfficientNet [55] | 频率,混合边界 | 标签 | 提出自混合图像以提高深度造假检测的泛化能力 | |
| IMDL | MVSS-Net [62] (ICCV21) | Resnet [19] | BayarConv,Sobel | 标签、掩膜 | 利用多视图学习来检测篡改,以利用噪声和边界伪影 |
| CAT-Net [22] (IJCV22) | HRNet [56] | DCT | 掩膜 | 融合RGB和DCT流,以学习用于剪接定位的压缩伪影 | |
| PSCC-Net [29] (TCSVT22) | HRNet [56] | 多分辨率卷积 | 标签、掩膜 | 通过空间通道相关性逐步细化掩模,以实现高分辨率定位 | |
| Trufor [17] (CVPR23) | Seformer [64] | 高分辨率、多尺度、边缘 | 标签、掩膜 | 融合RGB和学习到的噪声指纹,将篡改检测为异常 | |
| IML-ViT [35] (Arxiv) | ViT [13] | BayarConv,SRM 滤波器 | 掩膜 | 使用高分辨率、多尺度边缘感知设计的ViT进行篡改定位 | |
| Mesorch [70] (AAAI25) | Conv. [31],Segfor. [64] | DCT | 掩膜 | 融合微观和宏观线索,用于介观图像操作定位 | |
| AIGC | Dire [59] (ICCV23) | Resnet [19] | 扩散重建 | 标签 | 利用扩散的重建误差来检测扩散生成的图像 |
| DualNet [63] (APSIPA23) | CNN | SRM,低频 | 标签 | 融合SRM残留和低频内容流用于AIGC检测 | |
| HiFiNet [18] (CVPR23) | HRNet [56] | 多分支特征提取器 | 标签、掩膜 | 学习伪造属性的层次精细表征 | |
| Synthbuster [2] (OJSP23) | None | 傅里叶变换 | 标签 | 利用频域中的频谱伪影进行扩散检测 | |
| UnivFD [40] (CVPR23) | CLIP-ViT [45] | None | 标签 | 使用预训练的视觉语言模型特征进行统一检测 | |
| 文档 | CAFTB [52] (TOMM24) | Resnet [19] | SRM | 掩膜 | 提出具有双分支和交叉注意力的CAFTB-Net |
| TIFDM [12] (TCE24) | Resnet [19] | None | 掩膜 | 提出一个多尺度注意力的鲁棒网络 | |
| DTD [43] (CVPR23) | Conv. [31], Swin.[30] | 频率 | 掩膜 | 提出一种带有频率头和多视图解码器的DTD | |
| FFDN [6] (ECCV24) | ConvNext [31] | 波形,频率 | 掩膜 | 提出了一种结合视觉增强和频率分解的FFDN方法 |
尽管在深度伪造领域存在DeepfakeBench [67]、IMDL领域有IMDLBenCo
[36]等独立基准测试,但FIDL框架下所有领域的统一基准测试仍是一片空白。这种缺乏统一标准的局面导致各领域形成明显的数据孤岛——每个领域都在独立构建自己的数据集、模型和评估协议,彼此之间缺乏互操作性。这种孤立状态不仅造成现有FIDL领域研究的重复与不均衡,更使得建立通用统一的FIDL方法论变得困难重重,严重阻碍了整个FIDL领域的创新发展。
因此,为所有领域建立统一基准至关重要。但该基准面临两大挑战:首先,由于各领域数据集、模型和评估配置存在巨大差异,基准设计必须具备足够的扩展性和灵活性以覆盖所有领域;其次,既要确保与现有基准的兼容性以减少重复研究,又要解决开源基准模型稀缺以及某些领域缺乏独立基准的问题。
为此,我们提出了ForensicHub:
1)提出了一种模块化和配置驱动的架构,将取证管道分解为跨数据集、转换、模型和评估器的可互换组件,允许在所有领域灵活组合;
2)通过适配器设计,完整实现10个基线模型(其中3个为从头复制),6个骨干网络,2个AIGC和文档新基准,并整合了DeepfakeBench和IMDLBenCo两个现有基准。
通过以上工作,ForensicHub成为全领域假图像检测与定位的首个统一基准和代码库。基于ForensicHub平台,我们开发了图像取证融合协议(IFF协议)评估机制,支持跨任务的多样化取证模型统一训练与测试。针对研究者关注但尚未深入探讨的八大核心问题展开深度分析,为FIDL模型架构、数据集特征及评估标准提供全新视角。ForensicHub的推出实现了FIDL各领域的无缝衔接,打破领域壁垒,为未来技术突破注入新动能。
2 相关工作
假图像检测与定位包含四个子任务,详见附录C。尽管取得了快速进展,但目前仍缺乏统一基准——每个任务都使用独立的流程,限制了跨任务比较。
DeepfakeBench
[67]是专为解决数据处理流程不统一问题而设计的深度伪造检测基准测试,该问题会导致检测模型的数据输入存在差异。IMDLBenCo
[36]作为IMDL技术的基准测试平台和代码库,致力于通过统一的训练与评估协议对IMDL模型进行横向对比。AIGCDetectBenchmark
[68]则是一个专门用于测试9种AI生成图像检测方法的实验资源库。
这些基准测试在各自任务中提供了模型、数据集和评估指标,但其底层设计缺乏跨任务考量,导致难以在不同检测场景中实现整合。例如,DeepfakeBench与特定于Deepfake的数据预处理步骤(如面部特征点)存在紧密耦合,而IMDLBenCo要求数据集和模型都输出像素级掩码。AIGCDetectBenchmark在多GPU指标计算方面表现欠佳。此外,它们均未包含完整的图像级和像素级指标体系。这些局限性迫切需要一个全新、统一且灵活的跨任务基准测试。
3 ForensicHub
在本节中,我们提出了我们的ForensicHub,它是一个统一的基准,用于所有域的假图像检测和定位,如图1所示,设计灵活和可扩展。
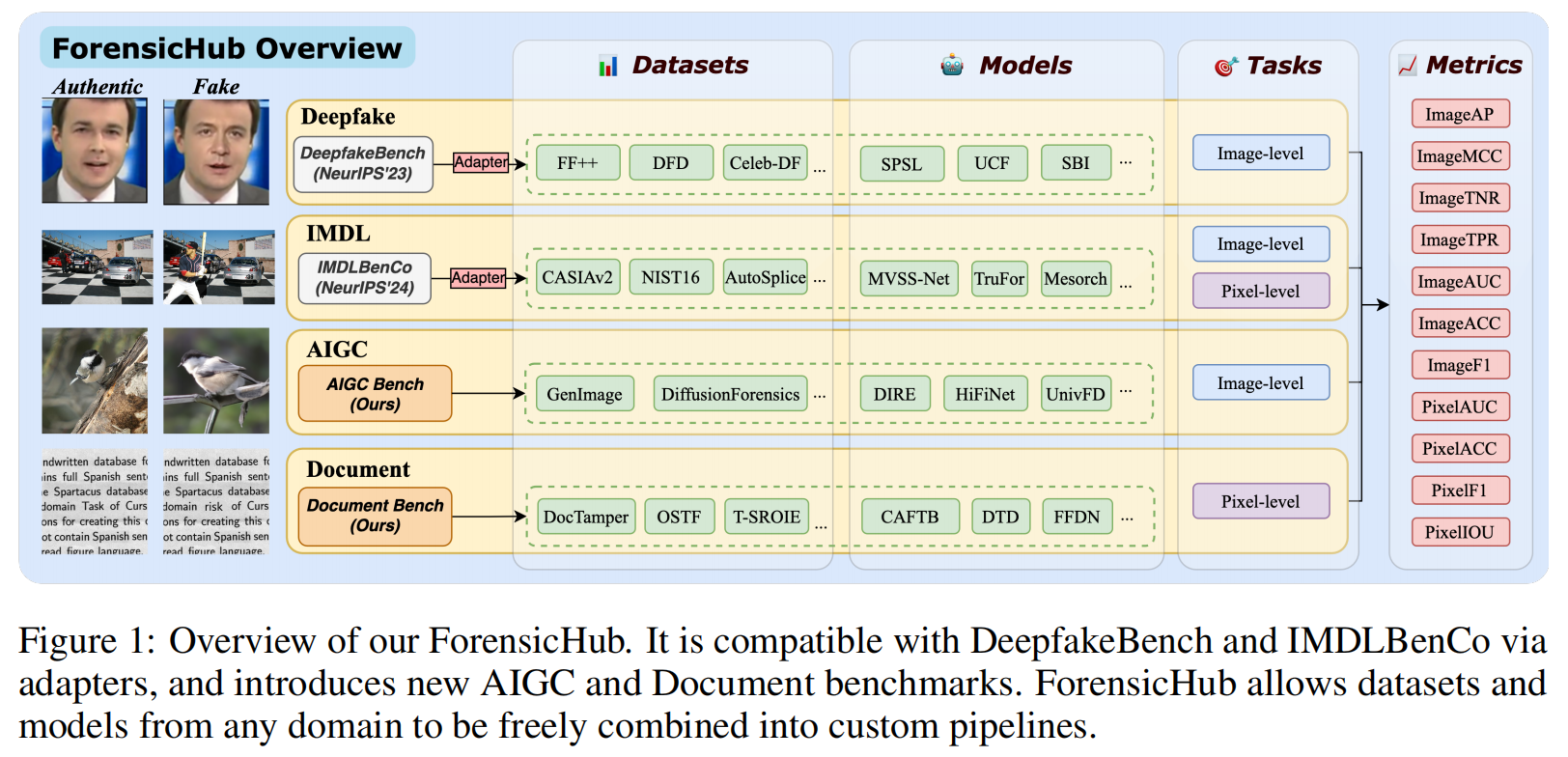
模块结构
为满足不同法证任务需求,ForensicHub采用模块化架构设计,包含四大核心组件:数据集、转换器、模型和评估器。数据集负责数据加载流程,必须返回符合ForensicHub规范的字段。转换器承担数据预处理与增强功能,适配各类任务需求。模型通过与数据集精准匹配并统一输出格式,可集成多种前沿图像取证模型。评估器涵盖了不同任务中常用的图像和像素级指标,并通过GPU加速来提高训练和测试期间的评估效率。
可配置工作流
ForensicHub采用无代码开发模式,用户仅需配置YAML文件即可直接构建训练或测试流程。基于模块化架构设计,用户可灵活选择不同评估器,在任意数据集上对模型进行训练和测试。该平台还提供代码自动生成工具,支持用户通过简单编程实现与基准测试的无缝对接。
ForensicHub的构建
为实现跨平台互操作性并减少重复劳动,ForensicHub采用基于适配器的设计方案[14],确保与深度伪造基准测试平台DeepfakeBench
[67]和IMDL基准库[36]两大主流工具无缝对接。该机制让用户无需大幅修改即可复用现有模型和数据集,同时支持在ForensicHub统一协议框架下定义新模型和基准测试。这种标准化架构简化了跨任务基准测试流程,保障结果可复现性,并实现不同领域评估的一致性。|
具体而言,ForensicHub支持IMDLBenCo提供的全部10个模型进行多领域和跨领域评估。在DeepfakeBench中,34个图像级检测器中有27个兼容,包括5个通用主干网络和9个不适用于跨任务评估的领域专用模型。剩余13个模型支持跨不同法医领域的训练或推理,因此DeepfakeBench共包含22个模型。ForensicHub完整实现了AIGC的5个基准模型和文档的5个基准模型,详见第4节。此外,ForensicHub还包含6个常用主干网络。总体而言,ForensicHub覆盖4项任务、23个数据集、42个模型、6个主干网络,并实现了11种常用的图像级和像素级评估指标。
数据集
本文使用的数据集包括:
用于深度伪造的工具包括:Faceforencs++
[47]、Celeb-DF [27]、DFD [9]、FaceShifter [23]和UADFV
[26];
用于IMDL的工具有:CASIA [11]、COVERAGE
[60]、Columbia[20]、IMD2020 [39]、NIST16 [16]、CocoGlide
[17]和Autosplice [21];
用于AIGC的工具包含:DiffusionForensics
[59]和GenImage [69];
用于文档处理的工具则有:Doctamper
[43]、T-SROIE [58]、OSTF [44]、TPIC-13 [57]和RTM
[32]。
各数据集的简要总结见表2,更多详细信息见附录D.1。
模型
本文使用的模型为:
深度伪造检测的有Capsule-Net
[37]、RECCE [4]、SPSL [28]、UCF [66]和SBI
[49];
图像处理与定位领域的有MVSS-Net [5]、CAT-Net
[22]、PSCC-Net [29]、Trufor [17]、IML-ViT [35]和Mesorch
[70];
生成式人工智能检测领域的有Dire [59]、DualNet
[63]、HiFiNet [18]、Synthbuster [2]和UnivFD
[40];
文档检测方面的有DTD [43]、FFDN [6]、CAFTB [52]和TIFDM
[12]。
这些方法均来自官方资源库及我们的重新实现版本。此外,ForensicHub还精选了视觉任务中常用的6种骨干网络:Resnet
[19]、Xception [7]、EfficientNet [55]、Segformer [64]、Swin Transformer
[30]以及ConvNext [31]。具体模型参数详见附录D.2。
指标
本文使用的指标为:AP、MCC、TNR、TPR、AUC、ACC、F1和IOU等指标,其像素级和图像级实现方式如图1所示。各指标的具体说明详见附录D.3。在评估过程中,所有指标的阈值(若适用)均设为0.5,以确保比较的公平性。
4 基准
除了与现有基准测试DeepfakeBench [67]和IMDLBenCo [36]完全兼容外,ForensicHub还通过引入针对AIGC和文档领域的统一评估协议,进一步推动了标准化进程——这两个领域此前一直缺乏广泛认可的基准测试和代码库。我们为这两个领域提出了两种评估协议,用于衡量模型的泛化能力。
4.1 AI生成图像检测基准
数据集
在AIGC检测领域,数据集构建的难点通常不在于获取足够数量的样本——因为现有模型已能轻松生成这些样本,而在于确保对各类生成模型的全面覆盖。为此,我们仅选取两个常用公开数据集:DiffusionForensics[59]和GenImage[69]。前者仅包含基于扩散生成的图像,后者则涵盖由八种顶尖生成模型构建的百万级数据集。模型在扩散取证数据集上进行训练,并通过基因图像中的不同生成模型进行评估以检验泛化能力,因为检测方法通常已在同源生成模型的样本上取得良好表现[69]。具体数据划分详见表D.1.3。
模型
ForensicHub在AIGC检测中实现了五种最先进方法:Dire
[59]、DualNet [63]、HiFiNet [18]、Synthbuster [2]和UnivFD
[40]。其中Synthbuster没有官方开源代码,我们对其进行了完全重实现。更多关于模型和训练设置的详细信息,请参见附录E.1。
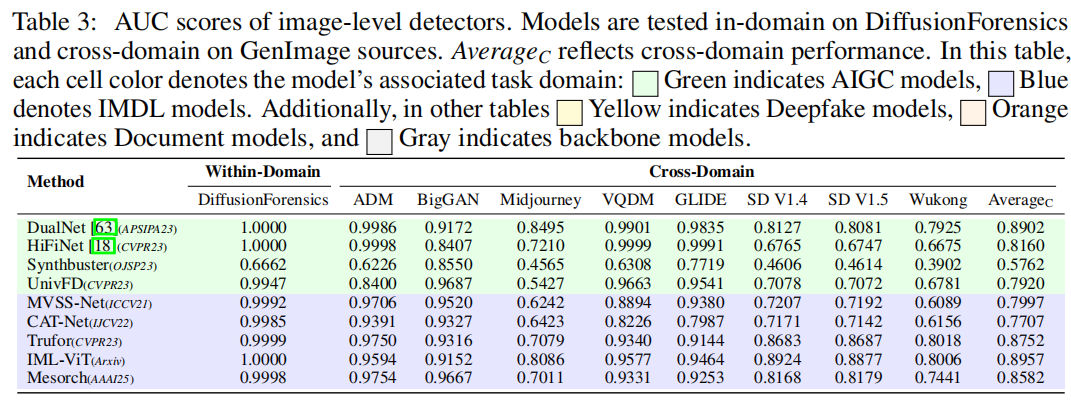
结果
表3中的绿色背景部分展示了AIGC基准测试中图像级分类的AUC分数,具体分为扩散取证[59]测试集的域内结果、不同生成模型的跨域结果以及GenImage
[69]总数据集的结果。结果显示,AIGC的顶尖模型在与训练集同源的扩散取证测试集中表现优异,同时在由基于扩散生成的图像(如ADM、VQDM和GLIDE)构成的数据集上也表现出色。然而,这些模型对Midjourney和Wukong等生成模型的泛化能力相对较弱,这不仅指出了改进方向,也为未来模型开发提供了重要参考。
4.2文档图像处理定位基准
数据集
目前用于文档图像操作定位的现有数据集主要分为两大类:一类是高保真非切片数据集,包括T-SROIE
[58]、OSTF [44]、TPIC-13 [57]和RTM
[32];另一类则是切片数据集,以Doctamper
[43]为代表。两者的根本区别在于是否对图像进行了分块切片预处理。
为确保后续评估的一致性,我们采用了Doctamper的切片策略,并将其应用于四个未切片的数据集,从而形成统一格式。每个数据集均保留原有的训练集与测试集划分。值得注意的是,Doctamper提供了一个训练集和三个不同的测试集——Doctamper-Test、Doctamper-FCD和Doctamper-SCD,分别针对不同操作场景设计。具体数据分布详见表D.1.4。
模型
我们采用了两个开源模型,DTD [43]和FFDN
[6],并复现了两个闭源模型,CATFB [52]和TIFDM
[12]。所有细节见附录D.2.4和E.2。
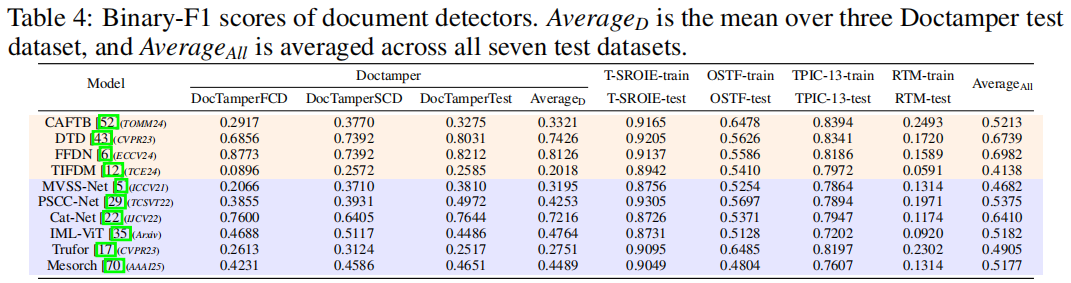
结果
根据原始协议[43,6],每个检测器都在指定的训练集上进行训练,并在对应的测试集上进行评估。如表4所示,有三种模型始终保持着最佳性能:专为文档取证设计的FFDN和DTD,以及基于IMDL架构的Cat-Net模型。值得注意的是,这三种方法都采用了JPEG特有的先验特征,例如离散余弦变换系数和量化表,这凸显了压缩伪影在定位文档图像篡改时的鉴别价值。
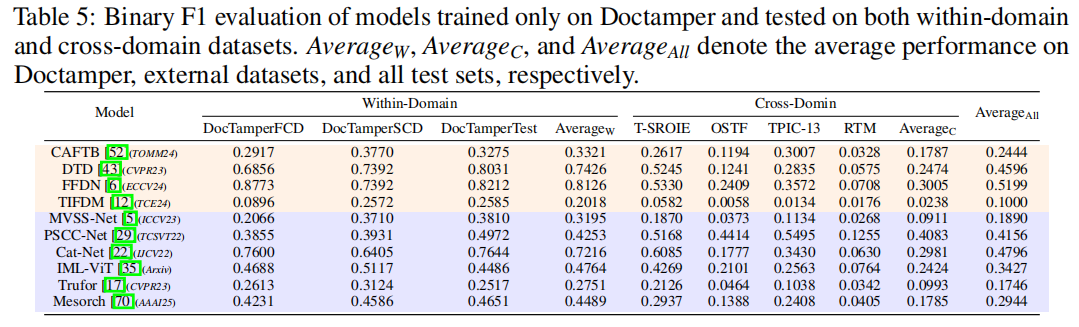
然而,这种评估设置存在一个关键缺陷:所有模型均在相同数据分布下进行训练和测试,这限制了跨域泛化能力的评估。为解决这一问题,我们专门设计了文档协议(Doc Protocol),让模型在Doctamper数据集上训练,并在另外四个文档级测试集上进行评估。如表5所示,PSCC-Net展现出更优的泛化性能,充分证明了渐进式空间建模在文档操作定位中的优势。
5图像取证融合协议
协议
为统一不同模型在法证协议下的性能评估,我们基于CAT-Net的训练数据构建策略,开发了图像取证融合协议(IFF-协议,mage
forensic fusion
protoco)。该协议将训练集定义为Deepfake、IMDL、AIGC和文档数据的组合,每个训练周期从各领域随机抽取等量样本。在训练过程中,我们选择了来自Deepfake任务的FaceForensics++
[47],来自IMDL任务的CASIAv2 [11],来自AIGC任务的GenImage
[69]以及来自文档任务的OSTF
[44]、RealTextManipulation、T-SROIE和Tampered-IC13数据集。我们采用最小数据集CASIAv2(包含12,641个样本),作为每个训练周期的采样量。在测试阶段,我们直接在不同领域的数据集上评估模型性能,无需进行微调。
实施细节
我们将图像尺寸统一调整为256×256(UnivFD、DTD和FFDN模型除外,具体参数详见附录F),仅采用基础数据增强手段:包括图像翻转、亮度与对比度调节、压缩处理以及高斯模糊。所有模型均采用余弦衰减学习率策略进行20轮训练,初始值设为1e−4,训练过程中逐步递减至1e−5。针对输出掩码的模型(IMDL和Doc),我们在最后一层特征图上应用最大池化操作以获取预测标签,并仅基于该标签计算损失函数。
模型效率
我们在表6中测试了各领域模型主干网络和超大规模架构的参数设置与浮点运算量。可以发现,模型效率往往与其应用场景密切相关。例如,深度伪造模型通常采用轻量化设计以支持实时视频检测,而专注于像素级分类的IMDL模型则常采用更复杂且体积更大的架构。这些效率偏好会对IFF协议下的实验结果产生显著影响。

基准结果
表7展示了基于IFF协议下四个领域数据集的主干网络与领域特定SoTA方法的AUC分数,其中DFD代表DeepFakeDetection
[15],DF指DiffusionForensics [59],RTM则对应RealTextManipulation
[32]。详细结果详见附录F。
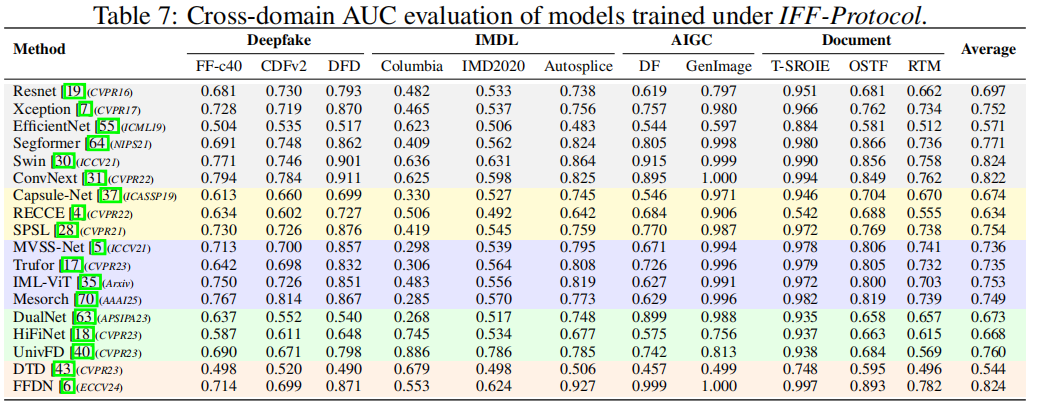
研究结果表明,令人惊讶的是,诸如ConvNeXt [31]和Swin Transformer [30]等视觉主干网络的表现几乎超越了所有领域特定的最先进方法,这说明当在更统一的伪造图像数据上训练时,主干网络展现出更大的潜力。与此同时,领域特定的最先进方法并不总能在其任务中保持优势。例如,基于CLIP微调的AIGC检测模型UnivFD [40],在IMDL提供的IMD2020 [39]数据集上表现出色,揭示了跨任务方法可迁移性的宝贵见解。
从任务层面来看,尽管IMDL的目标分类已从像素级提升至图像级,但由于不同数据集在规模和操作类型上存在显著差异,该任务仍具挑战性。相比之下,AIGC得益于基于多样化生成模型的充足训练数据,从而实现了更高的检测精度。这一现象提醒我们:不仅要确保训练数据涵盖丰富的操作类型,更要着力提升模型的泛化能力。
6实验
基于ForensicHub,我们进行了交叉任务实验,这在以前的研究中很少被探索。不同任务检测方法的异同性引出了以下问题:1)低级特征提取器是否在所有任务中都有效?2)一个任务的检测方法在转移到另一个任务时是否仍然有效?我们通过大量实验回答了上述问题。
6.1低级特征提取器的有效性
鉴于各领域已提出特定特征提取器,为统一评估其在特定领域的有效性,我们在上述IFF协议框架下,采用6种骨干网络与4种不同浅层提取器进行实验。具体包括:用于噪声伪影的BayarConv [3]、处理边缘伪影的Sobel [5]、消除频率伪影的DCT [1]以及滤波伪影的FPH [43]。各提取器的具体参数详见附录G.1。
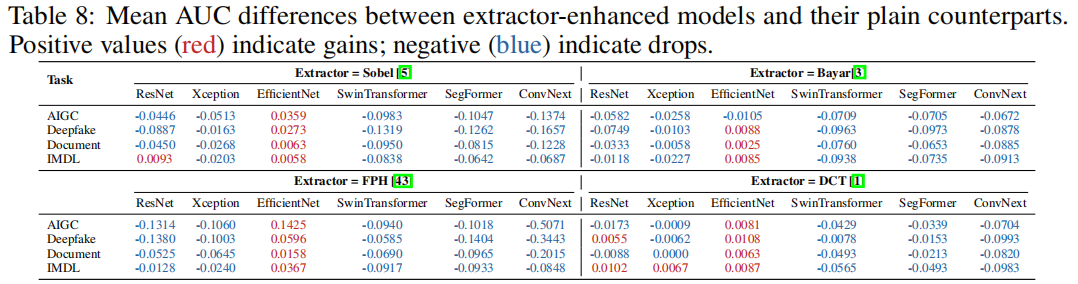
表8展示了各任务测试数据集上,使用四种不同特征提取器与未使用特征提取器的各主干网络版本之间的AUC差异平均值。除EfficientNet [55]外,其他主干网络在使用特征提取器后均出现性能下降,这表明在IFF协议框架下(训练数据包含充足的操控类型和图像数量),模型无需依赖特征提取器提供的额外信息。不过由于EfficientNet本身轻量级的优势,仍能从特征提取器中获益。研究结果表明,特征提取器可能仅对小规模数据集、有限操控类型或轻量级模型的检测任务有益。各领域测试数据集的AUC分数详情可参见附录G.2。
6.2任务专用检测器的可转移性
6.2.1 IMDL与文档基准之间的交叉评估
当前文档级检测器的输入输出格式与图像处理检测定位模型完全兼容。基于这种一致性,我们进行了双向评估:将IMDL检测器应用于文档基准测试,同时将文档检测器用于IMDL基准测试。这种交叉测试不仅扩大了各基准的有效模型库规模,还使我们能够突破检测器原有任务范围,深入探究其通用性。
IMDL→
Document
表4展示了原始文档基准划分下域内评估结果,而表5则呈现了我们新引入的泛化协议在跨域测试中的表现。在这两种场景中,IMDL检测器在文档取证场景中均展现出强劲竞争力。在常规划分中,Cat-Net
[22,43,6]家族以最佳平均F1值脱颖而出,印证了其分层“CatNet”架构的优势。在更具挑战性的跨域评估中,PSCC-Net
[29]展现出显著更强的泛化能力,表明渐进式空间建模能有效捕捉文档篡改定位线索。我们期待未来研究能进一步揭示PSCC-Net背后的潜在机制。
Document →
IMDL
根据MVSS训练协议[36],所有文档导向模型均在CASIAv2数据集[11]上进行训练,并在五个标准IMDL测试集上进行评估。如表9所示,CAFTB
[52]的双分支架构在迁移至IMDL任务时,于文档模型中展现出最佳整体性能——这一结果与当前最先进模型Mesorch
[70]的设计理念相契合,该模型同样强调双分支学习。

6.2.2将IMDL检测器扩展到AIGC和Deepfake基准
IMDL模型旨在生成像素级掩码和图像级标签,其架构大多同时包含分类头和分割分支。这种双输出设计使其能够直接应用于AIGC和Deepfake检测等任务。对于未配备标签头的模型,图像级评分是通过在预测掩码上进行最大池化操作获得的。
IMDL→
AIGC
我们在AIGC基准测试的训练数据集上对代表性IMDL检测器进行微调,并在表3中报告了跨生成器性能。训练设置及其他配置与前述AIGC基准测试设置保持一致。结果显示,IMDL技术中的噪声特征(TruFor)和多尺度分析(IML-ViT)等方法,在AIGC检测中依然有效。
IMDL →
Deepfake
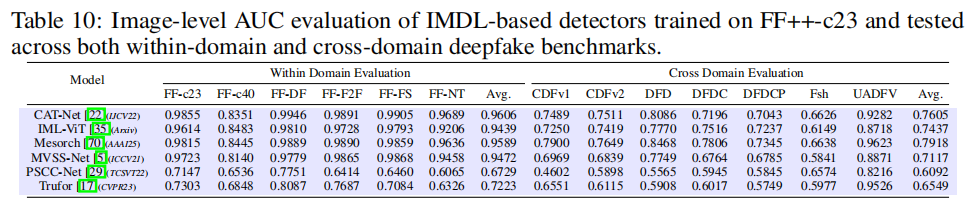
我们在FF++-c23训练集上训练每个IMDL检测器,并在所有剩余的深度伪造测试集上进行评估,具体分数详见表10。与deepfakebench
[67]中的所有基线模型相比,Cat-Net在域内设置中表现最佳,而Mesorch则在跨域评估中取得最高平均准确率,在两个场景下均创下新的最佳成绩。
7.结论
本文提出ForensicHub,这是首个面向全领域假图像检测与定位的统一基准测试平台及代码库。该平台不仅对现有基准测试进行了优化,还拓展至其他领域。通过大量跨领域实验,我们总结出8项对未来研究具有指导意义的关键洞见:
1)在文档领域,PSCC-Net表现出强大的泛化能力,而Cat-Net能有效适应人工合成操作,为文档模型设计提供了有价值的参考。
2)在IMDL中,CAFTB和Mesorch等并行架构模型取得了领先性能,表明多分支建模的有效性。
3)像Cat-Net和Mesorch这样的频率策略模型始终表现良好,突出了频率特征在FIDL中的潜力。
4)在IFF协议下,像ConvNeXt和Swin
Transformer这样的较少被探索的主干网络的表现优于几乎所有领域的SoTA。
5)当数据集较大且包含多种操作类型时,浅层特征提取器的串联往往会降低性能,而像EfficientNet这样的轻量级模型可以从这种做法中受益。
6)当前AIGC和文档评估往往忽视泛化能力,导致性能被高估。我们建议将本文提出的AIGC和文档协议用于后续工作,该协议明确鼓励设计具有泛化意识的模型。
7)现有的AIGC和Deepfake数据集往往过于简单,缺乏多样性,限制了有意义的比较,未来的基准应该以更高的复杂性和真实性为目标。
8)对于全域场景,我们推荐使用我们的IFF协议来实现更全面的评估。
总之,ForensicHub是打破四个领域领域孤岛的重要一步,为FIDL模型架构、数据集特征和评估标准的未来研究提供了新的见解。