ForgeLens:Data-Efficient Forgery Focus for Generalizable Forgery Image Detection

ForgeLens: Data-Efficient Forgery Focus for Generalizable Forgery Image Detection
Yingjian Chen, Lei Zhang, Yakun
Niu*
河南大学大数据分析与处理重点实验室
摘要
生成式模型的兴起引发了人们对网络图像真实性的担忧,凸显了对检测器的迫切需求:(1)既要具备高度泛化能力,能应对新型伪造技术,(2)又要实现数据高效利用(用最少训练数据达到最佳效果),从而有效应对新出现的伪造手段。为实现这一目标,我们提出ForgeLens框架,一种数据高效、特征导向的解决方案,通过融合两种轻量级设计,使冻结网络能专注于伪造特征。
首先,我们引入权重共享引导模块(WSGM,Weight Shared Guidance
Module),在训练过程中指导提取伪造特征。
其次,采用伪造感知特征整合器FAFormer,可有效整合多阶段特征中的伪造信息。
ForgeLens突破了传统冻结网络方法的关键局限——从大规模数据中提取的通用特征往往包含大量与伪造无关的冗余信息。因此,该方法不仅具备强大的泛化能力,还能在最小训练数据量下达到最优性能。
实验结果显示,包含生成对抗网络(GAN)和扩散模型在内的19个生成模型,相较于基准模型,平均准确率提升了13.61%,平均精度(AP)提升了8.69%。
值得注意的是,ForgeLens在仅使用1%的训练数据时,其伪造检测性能就超越了现有方法,达到了最先进的水平。我们的代码可在https://
github.com/Yingjian-Chen/ForgeLens 上获取。
1.引言
近期,人工智能生成内容(AIGC)的迅猛发展引发了广泛关注。特别是在图像合成领域,技术的突飞猛进正给社会带来前所未有的挑战。生成对抗网络(GANs)[18]和扩散模型[45]等尖端技术的广泛应用,让制作高度逼真的合成图像变得轻而易举。这种技术突破模糊了真实与合成图像的界限,宣告了“眼见为实”时代的终结。如今仅凭肉眼已难以分辨这些逼真程度令人瞠目的合成图像,对社会安全构成重大威胁。因此,如何有效识别这类合成图像已成为当务之急。
与依赖人工特征提取和算法的传统方法[17,36,37]不同,这些方法常因检测性能有限而受限,当前研究已转向深度学习技术,在合成图像检测领域取得显著成效。现有专用检测方法[14,24,49,54]通过设计深度学习网络,可在合成图像的空间域或频域检测伪影(图1左)。
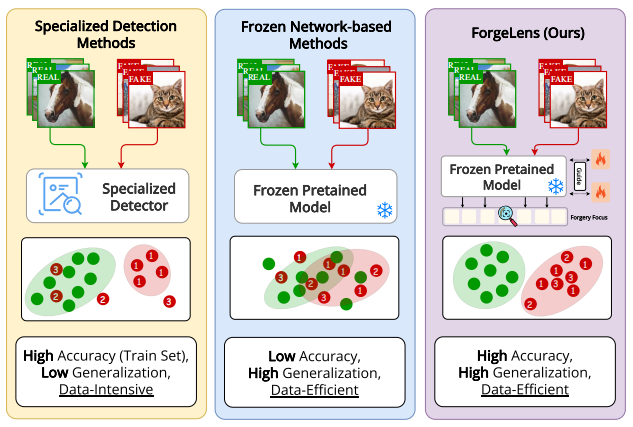
图1。伪造图像检测方法的比较。现有专门检测方法在已知数据集上表现优异,但在未知数据上的效果却大打折扣。基于网络的冻结方法虽然具有较高的泛化能力,但其检测精度却有所欠缺。相比之下,我们的ForgeLens在保持卓越检测精度的同时,实现了高度泛化能力。绿色圆点代表真实图像,红色圆点代表伪造图像,其中1(训练集)、2和3分别展示不同模型生成的伪造图像。
这些方法在检测已见生成模型生成的图像时能实现高精度。然而,由于不同生成模型生成的图像存在独特伪影[11,39],这些从零开始训练的专用检测模型容易对训练集过拟合。因此,当处理未见过的合成图像时,其性能会显著下降,暴露出泛化能力不足的问题。此外,这类方法通常需要大量训练数据才能达到最佳效果。
为解决这一问题,基于冻结网络的方法[29,39]采用预训练网络提取通用图像特征,这些特征适用于多种下游任务。训练过程中网络保持冻结状态,仅对线性分类器进行训练(图1中间部分)。这种设计既能防止过拟合,又能确保模型具有高泛化能力。然而,通用图像特征往往包含大量与伪造无关的冗余信息,导致分类器难以区分真实图像与伪造图像,最终造成检测准确率受限。
为验证前述结论,我们展示了经典ResNet50模型(作为全量训练的专用方法代表)与冻结CLIP-ViT提取的图像特征对比(如图2所示)。
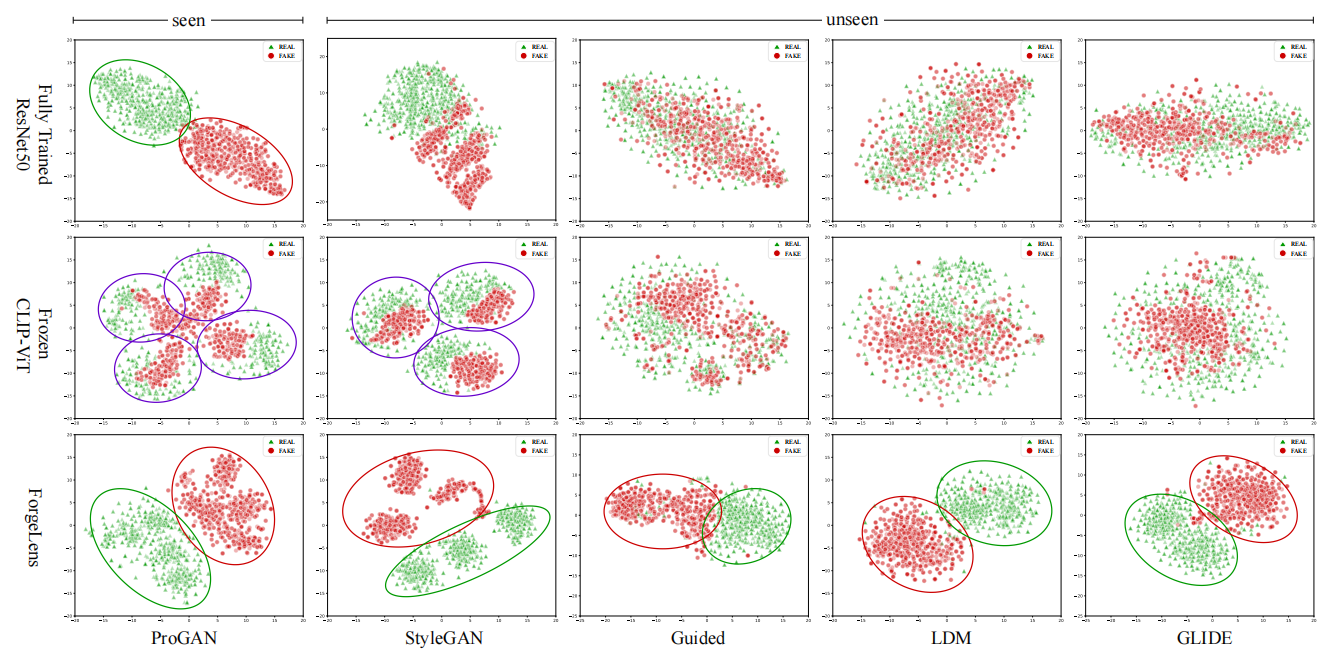
图2。基于t-SNE [52]技术,实现了生成对抗网络(ProGAN [25]、StyleGAN [26])与扩散模型(Guided [15]、 LDM [45]、glide [38])的特征空间可视化。
> 我们对比了三个模型:从零开始训练的经典ResNet50[20]、基础模型CLIP-ViT[43]以及我们的ForgeLens方法,所有模型均基于四分类ProGAN数据集训练。每个数据集包含1000张真实图像和1000张伪造图像的随机样本。紫色圆圈代表对应图像类别的聚类,例如ProGAN中的四个类别(汽车、猫、椅子、马)。
ResNet50提取的特征(第一行)在ProGAN数据集上,真实图像与伪造图像呈现出明显的聚类特征。然而,对于未见过的数据,提取的特征辨别能力会显著下降。如前所述,冻结版CLIP-ViT提取的特征(第二行)属于通用型特征,未针对伪造检测进行优化。这一点在ProGAN和StyleGAN数据的聚类结果中尤为明显——特征是按图像类别而非真实与伪造图像进行分组。这充分说明CLIP-ViT在区分真实图像与伪造图像方面存在明显局限。
基于上述分析,我们致力于为现实场景设计一款伪造图像检测器,该检测器应具备以下功能:
(1)具有强大的泛化能力,能有效识别各类模型生成的图像,包括从未见过的模型生成的图像,同时保持高检测精度;
(2)对训练数据要求极低,能快速适应新型伪造技术。
因此,我们的核心目标是:(1)引导预训练冻结网络聚焦伪造特征,既保证高泛化能力又提升检测精度;(2)尽可能减少可训练参数,使检测器在最少训练数据下即可达到最佳性能。
为实现这一目标,我们提出名为ForgeLens(图1右)的特征引导框架。该框架采用轻量级可训练的权重共享引导模块(WSGM),指导预训练的CLIP-ViT模型聚焦伪造特征。此外,FAFormer作为伪造感知特征集成器,通过整合多阶段特征来优化伪造信息,使模型既能保持大规模预训练权重的高泛化能力,又能有效聚焦伪造检测任务。通过这种方法,我们的方法能够抑制原始CLIP-ViT提取的通用图像特征中与伪造无关的信息,从而获得具有高度区分性的特征表征(图2第三行)。实验表明,仅使用ProGAN生成图像训练的方法,在包含GAN和扩散模型等多种生成模型的UniversalFakeDetect数据集[39]上展现出强大的泛化能力。该方法在该数据集上的平均检测准确率达到94.99%,充分证明其在跨模型伪造检测中的有效性。值得注意的是,即使仅使用1%的训练数据,模型性能波动极小,充分展现了其在少量训练数据下仍能保持竞争力的特性。
综上所述,我们的贡献包括:
- 新型特征引导CLIP-ViT伪造图像检测方法。我们提出ForgeLens,这是一个基于特征引导的CLIP-ViT框架,用于伪造图像检测,确保强泛化能力的同时保持高检测精度。
- 有效的伪造线索。我们提出轻量级的权重共享引导模块(WSGM)和FAFormer,使冻结的预训练CLIPViT在训练时能专注于伪造特征。这有效解决了CLIP-ViT提取的通用图像特征的局限性,这些特征包含过多与伪造无关的信息。
- 高效且数据高效。我们验证了ForgeLens的有效性,其在通用伪造检测数据集上的表现优于 SOTA 方法。值得注意的是,即使在训练数据极其有限的情况下,ForgeLens仍能保持优异性能,充分展现了其强大的数据效率。
2.相关工作和背景
2.1.专业伪造图像检测方法
近期伪造图像检测方法[5,33,35,42,46]采用Xception[10]和ResNet[20]等神经网络,并结合专用模块,通过分析图像的频域和空域特征来识别伪造痕迹。具体而言, GLFF [24]通过双分支网络融合多尺度全局特征与局部细节特征。Tan等人[49]提出的FreqNet将频域学习融入CNN分类器,显著提升了捕捉频率特征的能力。 NAFID [14]则通过专用模块提取图像的非局部特征。虽然这些方法在检测训练过程中看到的生成模型的伪造图像方面很有效,但它们在检测未见过的模型的伪造图像方面很困难,表现出有限的泛化能力。此外,它们需要从零开始训练,并需要大量数据才能表现良好。相比之下,我们的工作即使在训练数据非常有限的情况下,也能对未见过的模型实现高度泛化。
2.2.基于预处理的检测方法
为应对模型泛化到未见过数据的挑战,现有方法主要转向数据增强技术,或通过图像预处理将原始图像转化为新表征。例如CNN-Spot[54]采用多样化数据增强技术来提升对未见测试数据的泛化能力。刘等人[31]发现真实图像中存在一种独特的“学习噪声模式”,其具有更强的区分能力。FreGAN[23]通过整合频率级扰动图谱,有效缓解生成图像中独特伪影导致的过拟合问题,从而在多样化测试场景中提升检测精度。BiHPF[22]则运用双边高通滤波器,放大生成模型合成图像中常见的频率级伪影影响。LGrad [47] 通过变换模型将RGB图像转化为梯度特征,并将这些梯度作为图像特征表示。NPR [50] 则着重突出了伪造图像中上采样留下的痕迹。然而,尽管这些方法在一定程度上提升了泛化能力,但它们不可避免地会丢失原始RGB图像的信息,这可能会影响检测精度。此外,这些方法通常需要额外的处理步骤,使得检测流程更加复杂。相比之下,我们的端到端框架直接以原始图像作为输入,能够更有效地实现更好的泛化能力。
2.3. 基于冻结预训练模型的方法
另一项研究[27,29,39]采用冻结预训练图像编码器(如CLIP-ViT[16,43])提取通用图像特征,再通过线性分类器进行伪造检测。该方法能有效避免模型过度拟合训练集中的特定伪造特征[11,39],同时提升对未见过生成模型生成图像的泛化能力。具体而言,FatFormer[32]提出伪造感知适配器,通过聚合频率特征并借鉴CLIP中图像与文本提示的对比学习策略。C2PCLIP[48]则通过类别通用提示向图像编码器注入类别相关概念,显著提升检测性能。不过由于训练过程中冻结网络权重,图像编码器提取的特征具有通用性,适用于多种下游任务。这些特征包含大量与伪造无关的信息,这限制了检测性能。与现有方法不同,我们的方案采用纯图像编码器架构,使冻结的编码器能专注于伪造特征(如面部轮廓、发丝),同时抑制通用图像特征中无关信息的干扰,从而显著提升泛化能力和检测精度。
3.方法
本节将介绍我们研发的ForgeLens框架,该框架专为实现高效泛化伪造图像检测而设计。其核心机制包含三个关键步骤:
(1)通过权重共享引导模块(WSGM,weight-sharing
guidance
model)引导预训练图像编码器CLIP-ViT在特征提取过程中聚焦伪造特征;
(2)伪造感知特征整合器(FAFormer,forgery
aware feature
integrator)对多层级特征进行伪造相关信息的精炼处理;
(3)将优化后的伪造检测图像表征输入线性分类器完成最终预测。
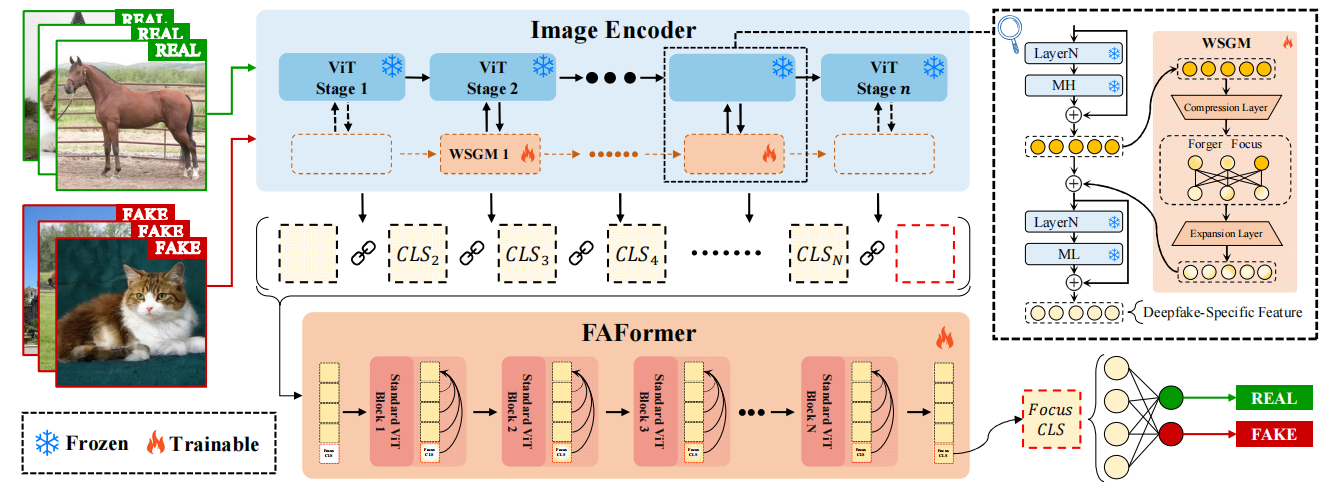
图3。ForgeLens框架的示意图。可训练的 WSGM 模块用于引导冻结的ViT网络聚焦伪造特征;从ViT各阶段提取的 CLS 标记(黄色方框)与聚焦 CLS 标记拼接后,被输入到FAFormer(红色矩形)中。FAFormer由标准ViT模块构成,用于跨多阶段聚焦伪造特征;最终生成的聚焦 CLS 标记作为分类的最终表征。方框“F ocus CLS ”和“CLSi”分别代表附加的聚焦 CLS 标记和冻结ViT第i阶段输出的图像 CLS 标记。
3.1.图像编码器
基于CLIP强大的预训练权重和高效的特征提取能力,我们采用CLIP-ViT[43]作为固定图像编码器,具体策略参照UniFD[39]的框架。对于输入的RGB图像 $ x^{HW} $ ,其补丁嵌入层首先将图像分割为N个互不重叠的补丁,并将每个补丁投影到D维特征空间,形成补丁嵌入序列 $ E_{patch}^{(N+1)D} $ 。随后在序列前添加 CLS 标记,再通过多个视觉变换器模块进行处理,其中自注意力机制对表征进行优化。最终,输出的 CLS 标记作为图像表示(记作( $ f_i^{1R} $ ),在CLIP-ViT模型的第i阶段使用。其中,H和W分别表示输入图像的高度和宽度,\(N=\frac {HW}{P^2}\)为总补丁数,D则代表投影特征的维度。
3.2. 权重共享引导模块
针对预训练CLIP-ViT模型提取通用图像特征时存在过度包含伪造无关信息的问题,我们提出了一种轻量级可训练的权重共享引导模块(WSGM),通过引导编码器聚焦伪造特征,同时最大限度减少额外参数。
在标准视觉变换器(ViT)架构中,多头自注意力(MHSA)模块负责捕捉全局特征,而多层感知器(MLP)模块则对这些特征进行优化和非线性转换。为引导冻结的ViT模型在最小化可训练参数的同时聚焦伪造特征,我们引入了可训练的注意力机制(WSGM)。该机制在多个ViT模块间运作,对
MHSA 输出的特征进行处理后再输入 MLP
。通过优化全局特征并强化伪造相关信息, WSGM 确保 MLP
接收的特征能有效支持伪造检测任务。这使得冻结的编码器能够逐步增强对伪造特征的关注。该过程可表述如下:
\[\begin{array}{l}{z_{l}={\bf M H S A}(L
A(x_{l-1}))+x_{l-1},\quad l=1,\cdot\cdot\cdot,n}\\ {z_{l}^{\prime}={\bf
W S G M}_{k}(z_{l})+z_{l},\quad k=1,\cdot\cdot\cdot,m}\\ {x_{l}={\bf M L
P}(L N(z_{l}^{\prime}))+z_{l}^{\prime}}\end{array}\] 其中\(x_{l-1}\)和\(x_{l}\)分别表示第l个冻结ViT模块的输入和输出特征。WSGMs在多个ViT模块间共享,确保每个
WSGM 模块精确负责\(\frac{n}{m}\)个模块,且\(\frac{n}{m}\)为整数。具体而言,第k个 WSGM
模块会先对其分配的模块组内的 MHSA 输出进行处理,再将其传递给 MLP
模块。
为进一步减少可训练参数数量, WSGM
模块采用了瓶颈结构。该结构包含压缩层、扩展层、ReLU激活函数,以及一个专门引导ViT模块聚焦伪造特征的附加线性层,其数学表达式可表示为:
\[\mathrm{WSGM}(z)=W_{c o
m}\cdot\mathrm{ReLU}(W_{m i d}\cdot\mathrm{ReLU}(W_{e x p}\cdot
z))\] 其中\(W_{c o
m}\in\mathbb{R}^{d\times{\hat{d}}}\)和\(W_{e x
p}\in\mathbb{R}^{\hat{d}\times{d}}\)分别表示压缩与扩展投影矩阵,\(\hat{d}\)为满足\({\hat{d}}\ll d\)的瓶颈中间维度,而\(W_{m i
d}\in\mathbb{R}^{\hat{d}\times{\hat{d}}}\)则代表额外的中间线性层。
WSGM
模块能有效引导冻结的预训练CLIP-ViT模型聚焦伪造特征,从而解决因冻结网络提取的通用特征中存在过多无关伪造信息而导致的准确率下降问题。
3.3. FAFormer
在完成伪造特征提取后,我们进一步探讨了浅层图像特征在伪造检测中的重要性[3,12,29]。为此,我们提出FAFormer——一种伪造感知特征整合器,通过整合多层级特征(包括低级和高级表征),精准捕捉伪造相关特征。
基于经典Transformer[53]利用
CLS
标记捕捉输入序列完整表征的发现,该机制使模型能够将多种特征表征整合为统一的嵌入向量。作为全局表征,
CLS
代币通过自注意力机制整合所有输入代币的信息,从而有效筛选出输入序列中最相关的信息。此外,我们发现冻结的ViT模型在各阶段输出的
CLS 标记\(CLS_i{\in}{\mathbb
R}^D\),其本身已完全满足Transformer的输入要求,因此无需额外的嵌入变换。为此,我们将各阶段的
CLS 标记进行拼接,并引入新的焦点 CLS 标记\(CLS_{focus}{\in}{\mathbb
R}^D\)作为全局表征,用于整合各阶段的信息。该复合表征可表示为:
\[c_{0}=[C L S_{f o c u s};C L S_{1};C L
S_{2};\cdot\cdot\cdot\cdot\cdot-L S_{N}]\]
基于此,FAFormer被设计用于通过多阶段特征(包括低级和高级图像特征)来精炼伪造特定信息。该模块采用标准的视觉变换器(ViT)模块架构[16],其工作流程可表述为:
\[\begin{array}{l c
r}{c_{l}^{'}={\mathrm{MHSA}(LN(c_{l-1}))+c_{l-1}}}\\
{c_{l}={\mathrm{MLP}(LN(c_{l}^{'}))+c_{l}}}\end{array}\]
其中\(c_{l}^{'}\)和\(c_l\)分别表示标准ViT第l个模块中 MHSA 和 MLP
模块的输出特征。
FAFormer通过Transformer的自注意力机制,有效整合了从冻结的CLIP-ViT中提取的多阶段特征,将细粒度的低级细节与抽象的高级语义相结合。低级特征捕捉细微纹理和伪影,而高级特征则编码更丰富的语义和结构信息。通过优化这些多样化特征,FAFormer增强了伪造特征的表征能力,确保细粒度信息与抽象信息共同参与伪造检测。
4.实验设置
4.1.数据集
训练数据集
为确保公平且一致的对比效果,我们沿用现有方法仅使用ProGAN生成的图像进行训练。具体而言,我们采用与先前研究[32,39,48]一致的ForenSynths[54]训练集和验证集。ForenSynths训练集包含20类真实图像(源自
LSUN
数据集[55])及其对应的ProGAN合成假图[25]。参照既往研究,我们选取汽车、猫、椅子、马四个类别作为训练子集。为突出本方法仅需少量训练数据的优势,我们将训练集划分为包含1%、4%、20%、50%和100%数据的子集。更多训练集细节详见附录A.1。
评估数据集
为评估本方法的有效性和泛化能力,我们采用了广泛使用的数据集UniversalFakeDetect[39]。具体而言,该测试集包含19个子集,涵盖多种生成模型,包括ProGAN[25]、StyleGAN[26]、BigGAN[4]、CycleGAN[58]、StarGAN[9]、GauGAN[40]、Deepfake[46]、
CRN [7]、 IMLE [30]、SAN[13]、 SITD [6]、引导扩散模型[15]、 LDM
[45]、Glide[38]和dalle[44]。详细信息请参见附录A.2。
4.2.Baselines
为全面评估本方法,我们将其与各类伪造检测方法进行对比,这些方法可分为专业检测方法、预处理方法和冻结模型方法三大类。
专业检测方法包括Patchfor[5]、F3Net[42]和FreqNet[49]。
在基于预处理的检测方法中,我们纳入了CNN-Spot[54]、LGrad[47]和NPR[50]三种方案。
在基于模型的冻结检测方法中,我们纳入了UniFD[39]、FatFormer[32]、 RINE
[29]和C2PCLIP[48]。
4.3.评估指标
基于先前研究[29,32,39],我们采用准确率(Acc)和平均精度(AP)作为评估方法有效性的主要指标。为全面评估模型在不同生成对抗网络(GAN)和扩散模型子集上的泛化能力,我们报告了平均准确率和平均精度。
4.4.实施细节
我们采用两阶段训练策略以确保训练稳定性。
第一阶段冻结CLIP-ViT主干网络,仅训练
WSGM
网络。
第二阶段保持所有先前网络冻结状态,将FAFormer集成到后端并独立训练。
输入图像随机裁剪至224×224分辨率,训练时仅采用水平翻转增强,不进行其他数据增强。测试阶段仅使用中心裁剪。我们采用Adam优化器[28](β参数设置为(0.9,0.999)),并使用二元交叉熵损失函数。所有实验均在Nvidia
GeForce RTX 3090 GPU上使用PyTorch框架[41]完成,更多细节详见附录D。
5.结果与分析
5.1. 与竞争方法的比较
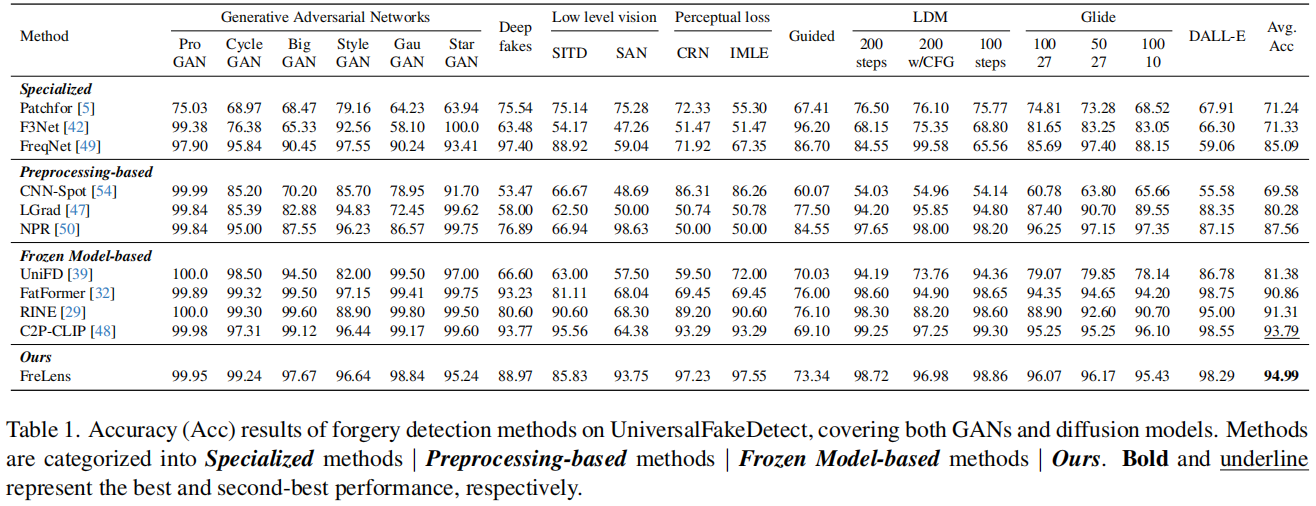
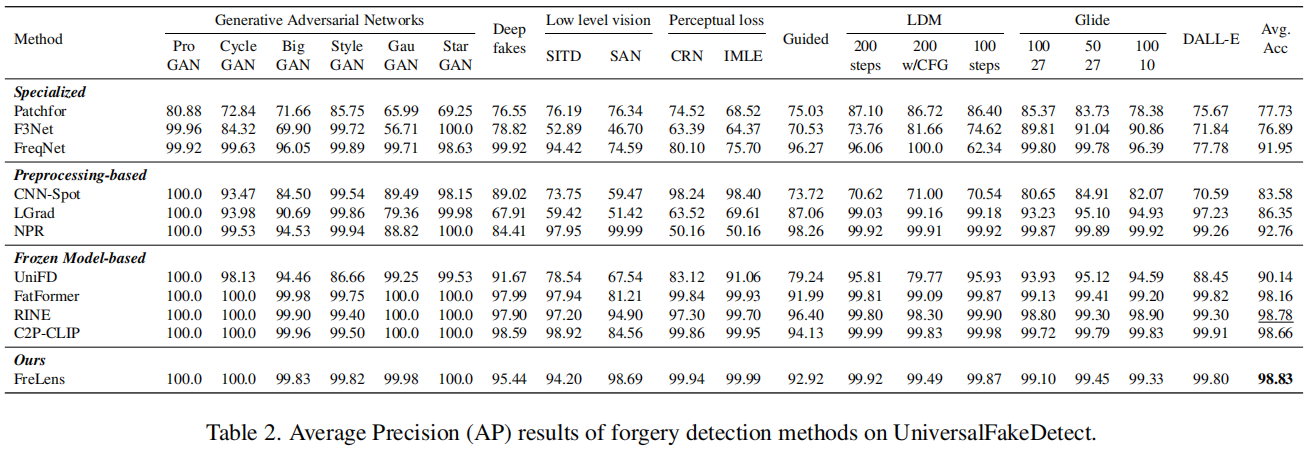
表1和表2展示了我们提出的ForgeLens方法在UniversalFakeDetect[39]数据集上与现有伪造检测方法的准确率(Acc)和平均精度(AP)对比。实验结果表明,ForgeLens方法表现优于现有方法,展现出强大的泛化能力,所有子集的平均准确率达到94.99%,平均精度达到98.83%。
具体而言,在各类专业方法中,最近提出的FreqNet方法在训练集相关的GAN子集上表现最佳,因其是在ProGAN上训练的。然而,当应用于扩散模型子集时,该方法存在局限性。相比之下,我们的方法在所有子集上都表现出较高的泛化能力,相较于FreqNet,平均准确率提升了9.9%,平均AP值提升了6.88%。
在基于预处理的方法中,我们的方法表现更优,平均准确率(Acc)比最佳方法NPR高出7.43%,平均精度(AP)高出6.07%,在多个子集上实现了全面的准确率提升。
对于基于冻结模型的方法,相较于使用原始冻结CLIP-ViT提取图像特征进行分类的基础模型UniFD,我们的方法使平均准确率提升了13.61%,平均精度提高了8.69%。
此外,我们的方法在性能上超越了基于UniFD的先进方法
RINE
。这表明我们的方案有效解决了从冻结预训练编码器中提取的通用图像特征存在的问题——这些特征因包含过多与伪造无关的信息而不适合用于伪造检测。值得注意的是,与同时采用文本和图像编码器的FatFormer及最新前沿方法C2P-CLIP相比(这两种方法通过增加模型复杂度提升了性能),我们的方案以更简洁的架构实现了3.68%和1.2%的平均准确率提升,表现更胜一筹。
5.2.消融研究
5.3.稳健性评估
5.4.类激活图可视化
6.结论
在本研究中,我们推出了名为ForgeLens的数据高效特征引导框架,专为泛化性伪造检测设计。通过整合轻量级权重共享引导模块(WSGM)精准定位伪造焦点,并结合FAFormer多阶段优化伪造特征,ForgeLens有效突破了传统冻结网络方法的局限性——既能精简无关信息,又显著提升特征区分能力。在包含生成对抗网络(GAN)和扩散模型在内的19种生成模型上进行的大量实验表明,ForgeLens仅需极少量训练数据即可达到业界顶尖水平。
局限性与未来工作
需要指出的是,本研究方法存在一个局限性:为确保模型稳定性而采用两阶段训练策略,这会略微增加整体训练复杂度。此外,在第二阶段,FAFormer通过多阶段视觉表征网络(ViT)对伪造特征进行深度优化,导致模型对超参数选择更为敏感,需要进行细致的参数调优。未来,CLIP-ViT框架的开发将聚焦于应对这些挑战,从而提升框架的效率与稳健性。