GIM:A Million-scale Benchmark for Generative Image Manipulation Detection and Localization

GIM: A Million-scale Benchmark for Generative Image Manipulation Detection and Localization
Yirui Chen1,3,, Xudong Huang3,,Quan Zhang 2,3,*, Wei
Li3,Mingjian Zhu3,Qiangyu an3
,Simiao Li 3, Hanting Chen3,
Hailin Hu3,Jie Yang1, Wei Liu1,†,Jie Hu3,
1 上海交通大学
2 清华大学
3 Huawei Noah’s Ark Lab
摘要
生成模型的非凡能力正成为图像编辑与生成逼真图像领域的新趋势,这对多媒体数据的可信度构成严峻挑战,并推动了图像操作检测与定位(IMDL)研究的发展。然而,由于缺乏大规模数据基础,IMDL任务难以实现。本文构建了一个整合了结构化注意力模型(SAM)、语言模型(LLM)和生成模型强大功能的定位篡改数据生成流程。在此基础上,我们提出了GIM数据集,该数据集具有以下优势:
1)大规模,GIM包含超过100万对人工智能操作的图像和真实图像。
2)丰富的图像内容,GIM包含广泛的图像类别。
3)多种生成式操作,这些图像是使用最先进的生成器和各种操作任务进行处理的图像。
上述优势使得IMDL方法的评估更加全面,拓展了其在各类图像中的应用范围。我们通过两种设置构建了GIM基准测试平台来评估现有IMDL方法,并提出了一种名为GIMFormer的创新IMDL框架,该框架包含影子追踪器、频域空间模块(FSB)和多窗口异常建模(MWAM)模块。大量实验表明,GIMFormer在两个不同基准测试中均超越了先前的最先进方法。
1. 引言
2. 相关工作
3. 数据集和基准构建
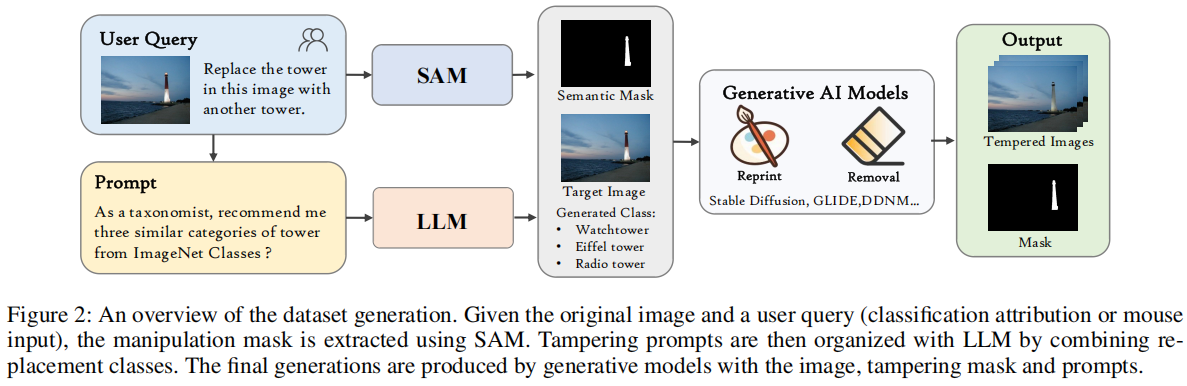
在本节中,我们提出了一种从未标注数据生成处理图像的自动化流程。通过这一流程,我们构建了一个全面的大规模GIM数据集。为构建合理的基准测试体系,我们重点围绕数据规模与图像退化两大核心维度开展前期实验。首先,通过分析训练数据规模对模型性能的影响,确定GIM基准测试的合适规模参数。其次,为还原真实场景特征,对处理过和原始图像分别进行三种随机退化处理。最终,GIM基准测试包含超过32万张经过处理的图像及其真实对应图像,用于算法训练与评估。示例图像及其原始版本与篡改掩码如图1所示。最后,我们详细阐述了IMDL方法评估所采用的评判标准与参数设置方案。
4. 方法
为应对生成式操控的挑战,我们提出采用双编码器与解码器架构的GIMFormer模型。该框架包含多个组件:ShadowTracer、频域空间块(Frequency-Spatial Block,简称FSB)以及多窗口异常建模模块(Multi Windowed Anomalous Modeling,MWAM)。图3展示了该框架的整体架构。
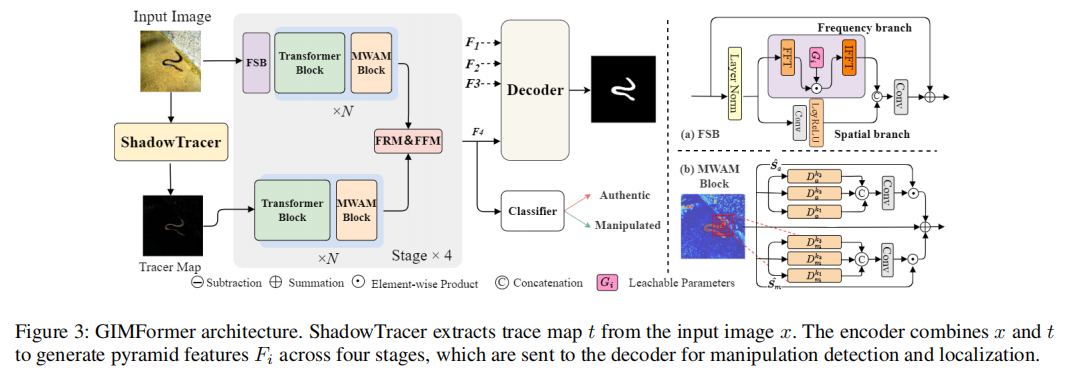
对于输入的RGB图像x,我们首先提取其学习得到的轨迹图t。随后,x和t被输入到一个双分支网络中,通过四阶段结构提取金字塔特征Fi(i∈[1,4])。
RGB分支由FSB、Transformer
Block(谢等人,2021)和WMAM组成;
ShadowTracer分支则包含Transformer
Block和WMAM。
在融合步骤中,采用特征整流模块(FRM)和特征融合模块(FFM)(张等人,2023)进行特征融合。经过四阶段融合的特征被传递至解码器,最终完成检测yˆ和定位Mˆ。
4.1 ShadowTracer
传统图像篡改检测方法主要针对“廉价伪造”,依赖可见痕迹。这类痕迹包括因图像结构被篡改而产生的失真和突变现象。然而生成式篡改会对内容进行深度修改,且不会产生明显的频率变化或结构异常。如图4所示,这些细微痕迹会呈现独特的内在规律,而可见痕迹则具有不规则的边缘特征。

ShadowTracer致力于捕捉生成模型的内在特征与细微痕迹。针对经过处理的图像,我们的目标是学习一个映射\({\mathcal{g}}_{\phi}\),将篡改后的图像映射到其潜在扰动像素值,其中\({\mathcal{g}}_{\phi}\)代表具有可训练参数ϕ的神经网络。我们发现生成模型在数据分布中引入的差异具有内在规律,深度神经网络能够尝试重构这些变化。在训练阶段,我们会生成图像xi与篡改后的图像\(G(x_i)\)这对样本,通过\(t_i = G(x_i)−x_i\)计算出操作痕迹。训练\({\mathcal{g}}_{\phi}\)的目标函数可表述为: \[\operatorname*{min}_{\phi}\{\mathcal{L}_{r}(g_{\phi}(G({\mathbf x}_{i})),t_{i})\}\] 其中\(\mathcal{L}_{r}(x,y)=\|x-y\|_2\)。此外,映射网络需要能够检测细微篡改痕迹,并对现实世界中的各种图像退化具有鲁棒性。为此,我们通过混合原始图像与篡改图像,并在训练阶段引入多样化的退化操作来生成图像对。具体而言,给定输入图像I后,我们首先分割出目标区域并进行生成式处理以获得Im。采用混淆(Zhang等人,2017)策略对原始与篡改图像进行处理,以掩盖明显的篡改痕迹。随后,我们将图像置于上述退化处理中以生成最终的篡改图像。网络在从数据集中随机抽取的64×64像素块上进行训练,并采用等式1损失函数。
4.2 频率-空间块FSB
在进行退化处理时,被篡改图像中的伪影往往难以察觉。为提升图像局部特征的表达能力并提取判别线索,我们设计了频域-空间块(FSB)算法,通过在频率和空间维度同步提取伪造特征。
受近期研究(Rao等人,2021;Lee-Thorp等人,2021;Zhang等人,2022)启发,FSB系统包含两个分支:频率分支和空间分支,如图3所示。
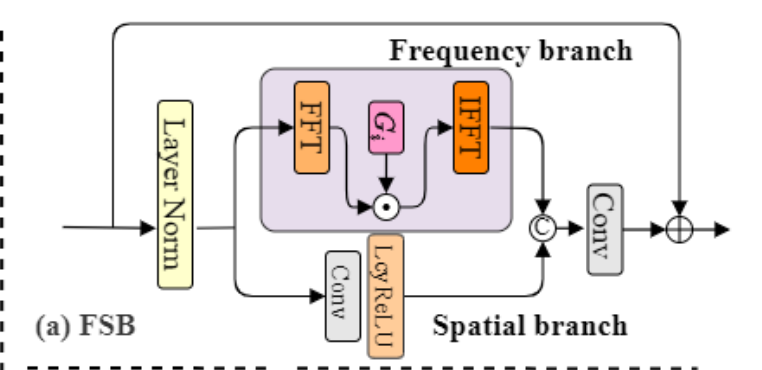
在频率分支中,输入信号X通过二维快速傅里叶变换(FFT)转换为频域傅里叶变换(FT)信号X。可学习滤波器Gi与信号相乘以调制频谱并捕捉频率信息,随后通过逆快速傅里叶变换将特征还原至空间域,从而提取出频率感知特征Xf。在空间分支中,输入信号X经过卷积层和LeakyReLU函数处理以增强特征表达能力,获得精细的空间特征Xs。接着将Xf与Xs拼接后,通过卷积层和LeakyReLU函数进一步增强信息量,并通过逐元素求和的方式与原始输入X结合。整个处理流程可表示为 \[\begin{array}{l}{X_{\mathrm{f}}=\widehat{\mathcal F}_{T}(\mathcal{F}_{T}(X)\odot G_{\mathrm{i}})}\\ {X_{\mathrm{s}}=\mathrm{Conv_{L}}(\mathrm{Conv}(X))}\\ {X_{o u t}=\mathrm{Conv_{L}}([X_{\mathrm{f}},X_{\mathrm{s}}])+X,}\end{array}\] 其中\(\odot\)表示Hadamard积,ConvL表示使用LeakyReLU的卷积,[·]表示拼接。
4.3 多窗口异常建模模块MWAM
图像处理会导致像素层面的差异。真实像素应与邻近像素保持一致性,而经过处理的像素可能出现偏差并呈现异常现象。受先前研究(Wu,AbdAlmageed, and Natarajan 2019; Kong et al. 2023)探索局部不一致性的启发,我们引入多窗口异常建模(MWAM)模块,通过在多个尺度上对这些差异进行建模,从而捕捉处理区域与真实区域之间的像素级差异,实现细粒度特征的精准刻画。
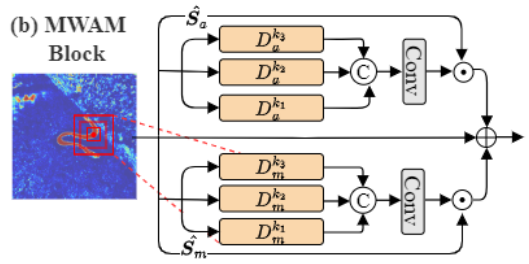
如图3所示,对于输入特征F∈H×W×C,我们通过等式3在两个分支中计算像素与其局部窗口内周围区域的差异。 \[\begin{array}{l c r}{D_{u}^{k}[i,j]=(F[i,j]-F_{u}^{k}[i,j])/\sigma^{*},}\\ {\sigma^{*}=\operatorname*{maximum}(\sigma(F),1e^{-5}+w_{\sigma})}\end{array}\] 其中,\(u\in\left\{a,m\right\}\)表示平均值或最大值分支,σ(F)是F的标准差,wσ是一个与σ长度相同的可学习非负权重向量。\(F_a^k\)和\(F_m^k\)分别通过计算每个像素处k_×_k窗口的平均值和最大值得出。通过选择不同尺寸的k来建模不同尺度的不一致性特征。随后,将获得的N = 3个不同尺度的\(D_a^k\)和\(D_m^k\)拼接后输入卷积网络,生成与原始输入相同尺寸的异常图Ma和Mm。此外,特征的异常评分掩码也\(\hat S_{u}\in H\times W\)是通过该方法计算得出。 \[\begin{array}{l}{\hat{f}_{u}=\mathrm{DConv}\left(f\right),}\\ {\hat{S}_{u}=\mathrm{Sigmoid}\left(\mathrm{Conv}(C,1)\left(\hat{f}_{u}\right)\right).}\end{array}\] 其中DConv表示一个3×3的深度向量卷积层。通过将异常分数\(\hat S_{u}\)与异常图Mu进行逐元素相乘,可以捕捉异常信息。随后,我们计算生成的异常感知图与输入特征图X之间的逐元素求和,从而获得异常敏感特征图。整个过程可描述为: \[\hat{X}=X+\hat{S}_{a}\times M_{a}+\hat{S}_{m}\times M_{m}\]
4.4 损失函数
在检测任务中,我们采用(Wang et al. 2020)提出的轻量级主干网络,并基于第四阶段特征进行二分类预测yˆ。定位任务则使用多层感知机解码器(Xie et al.2021)作为分割头,生成预测掩膜ˆM。给定真实标签y和掩膜M,我们通过以下目标函数训练GIMFormer模型: \[{\mathcal{L}}={\mathcal{L}}_{c l s}(y,{\hat{y}})+{\mathcal{L}}_{s e g}(M,{\hat{M}}),\] 其中Lcls和Lseg均为二元交叉熵损失函数。
4.5 实施细节
我们的方法包含两个独立的训练步骤。首先,我们使用ImageNet生成的数据集训练ShadowTracer模型。该训练过程采用了与前一章所述类似的数据生成方法。接着,根据GIM框架中描述的两种配置方案(如前一节所述),我们对模型的编码器和解码器进行训练。模型在8个V100 GPU上运行,初始学习率设为6e−5,采用幂策略(功率0.9)进行20轮周期的调度。优化器选用AdamW(Loshchilov和Hutter 2017),参数设置为epsilon 1e−8、权重衰减1e−2,每个GPU的批量大小为4。
5. 结论
我们针对生成式操控检测与定位的挑战,为人工智能生成内容(AIGC)安全领域构建了可靠的GIM数据库。该数据集通过整合多个生成器提供多样化操控数据,并基于此设计了IMDL方法的基准测试框架,包含两种实验场景。同时创新性地提出基于Transformer的GIMFormer框架。大量实验数据表明,该框架实现了当前最先进的性能表现。