Generalizable Synthetic Image Detection via Language-guided Contrastive Learning
Generalizable Synthetic Image Detection via Language-guided Contrastive Learning
Haiwei Wu, Member, IEEE, Jiantao Zhou, Senior Member, IEEE, and Shile Zhang
摘要
人工智能生成图像的逼真度显著提升,这主要得益于生成对抗网络(GAN)和扩散模型(DM)等合成模型的快速发展。然而,合成图像的恶意使用——例如传播假新闻或伪造个人资料——引发了人们对图像真实性的严重担忧。尽管已开发出多种用于检测合成图像的取证算法,但其性能(尤其是泛化能力)仍难以应对日益增多的合成模型。本研究提出了一种基于语言引导对比学习的简单却高效的合成图像检测方法。具体而言,我们通过精心设计的文本标签对训练图像进行增强,从而采用视觉-语言联合对比监督,学习具有更好泛化能力的取证特征空间。实验表明,我们提出的语言引导合成检测(LASTED)模型在未见过的图像生成模型上展现出显著提升的泛化能力,并在四个数据集上展现出远超现有顶尖算法的优异表现。
代码可在以下网址获取:https://github.com/HighwayWu/LASTED
影响声明
合成图像检测技术已成为遏制数字平台视觉内容滥用的关键手段。然而现有检测方法在跨域测试场景中存在明显短板,研究显示高达35%的合成图像仍能逃过现有检测系统。本文提出的创新方法通过将检测准确率大幅提升至95%以上,有效解决了这些痛点。这项突破不仅增强了数字媒体的可信度,更将合成图像检测的应用范围拓展至在线内容审核、数字取证及知识产权保护等领域。此外,该研究成果为教育工作者和政策制定者提供了一项重要工具,助力打击虚假信息并维护数字内容的真实性。
索引术语
人工智能在数字人文中的应用、深度学习、数字图像取证、伪造检测
1.引言
深度学习的迅猛发展催生了众多杰出的生成模型,其中生成对抗网络(GAN)和扩散模型(DM)尤为突出。这些模型生成的图像展现出的逼真度与创意性,正引发各界持续关注。

2022年8月,一幅由扩散模型生成的《Theater d’Opera
Spatial》(见图1(a))在Colorado State Fair’s
digital艺术竞赛中斩获头奖,使生成模型一跃成为焦点。尽管生成模型能为艺术家和设计师提供灵感,或作为娱乐工具,但其被恶意用于制造和传播虚假信息的潜在风险令人担忧(见图1(b))。在此背景下,亟需开发具备普适性的取证算法,以实现合成图像与真实图像的精准鉴别。
为提升合成图像检测器的泛化能力,学界提出了多种算法,包括模型迁移[7]、数据自适应[3]、数据增强[1]
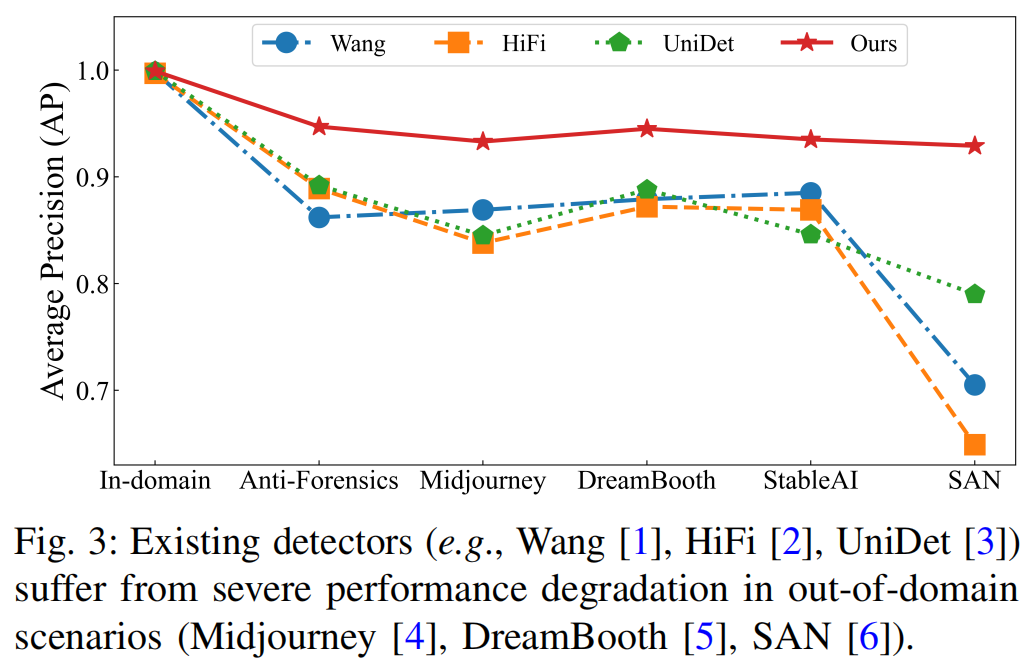
[8]等。尽管这些算法已取得一定成效,但其性能表现——尤其是泛化能力——仍难以满足日益增多的合成模型需求。如图3所示,现有算法Wang[1]、HiFi[2]和UniDet[3]均未能有效泛化以检测未见过的合成方法。
本研究旨在通过重新设计训练范式,提升合成图像检测器的泛化能力。从训练角度而言,大量研究[9]-[12](及其引用文献)表明对比学习能增强神经网络的通用表征能力。其中,OpenAI开发的CLIP模型[10]通过图像与文本的关联学习,实现了对视觉概念的泛化理解。该模型基于语言监督和对比学习,其性能在多项任务中甚至可与监督学习模型相媲美。受此启发,我们提出了一种新型合成图像检测方法:语言引导合成检测(LanguAge-guided SynThEsis Detection,简称LASTED),该方法采用增强型语言监督技术以提升图像域法医特征提取的准确性。我们注意到训练数据(合成图像或真实图像)通常缺乏文本信息,因此建议通过精心设计的文本标签进行增强。首先根据图像来源分配主要标签“真实”或“合成”。考虑到单一主要标签可能无法充分捕捉多样化的图像分布,我们进一步基于图像内容设计了辅助标签。这些辅助标签由预训练的图像描述算法(如ClipCap[13])生成,从而省去了人工标注的需要。在获得图像-文本对后,我们的LASTED模型在对比学习框架下联合训练图像编码器和文本编码器,以预测一批(图像,文本)样本的匹配对。本质上,增强后的文本标签提供了可学习的高维目标,这些目标无需由正交独热向量组成,从而使得语义解耦更易于优化。图2展示了我们LAST模型的对比训练过程。训练完成后,我们利用线性探针提取已学知识,并实现特定的合成检测。
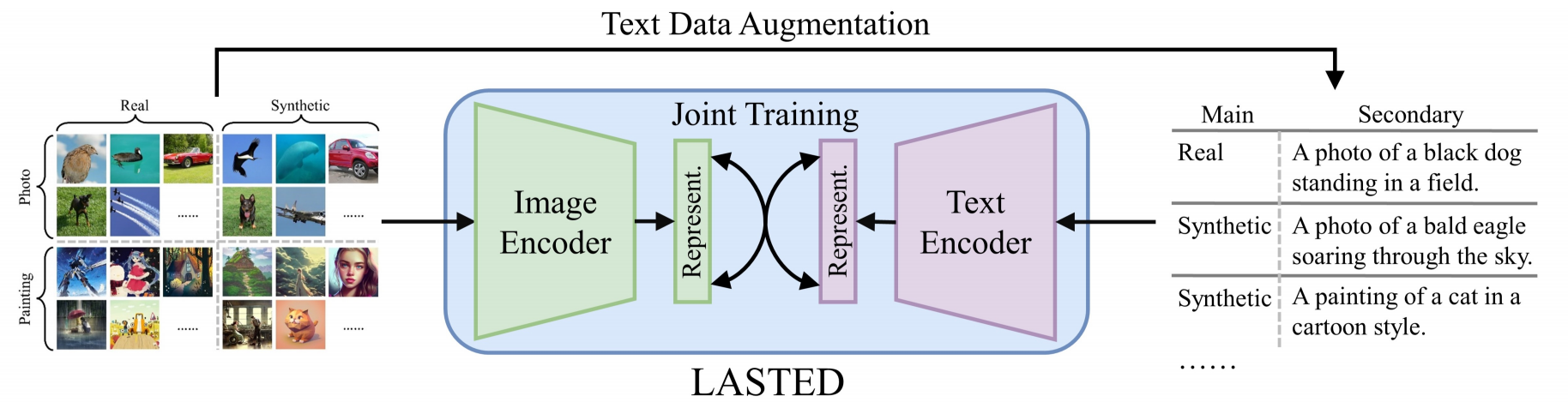
图2:本研究提出的持续训练方法示意图。训练图像首先通过精心设计的文本标签进行增强,随后对图像/文本编码器进行联合训练。
实验结果表明,我们的LASTED模型在未见过的图像生成模型上展现出显著提升的泛化能力(见图3)。具体而言,LASTED在现有ForenSynths[1]和DF3[18]数据集上的表现远超现有最先进模型[1]-[3] [14]-[17],平均精度(AP)分别提升5.5%和3.4%。值得注意的是,现有数据集[1] [18]主要聚焦于照片风格的合成图像,我们为此专门收集了绘画风格的新数据集。绘画作品通常包含奇幻元素且缺乏相机痕迹,这形成了完全不同的法医特征(详见第四章A节和图6)。这些新数据集将为各类检测算法提供更全面的评估依据。本研究的主要贡献可归纳为:
- 通过引入精心设计的文本标签,我们开发出一种基于语言监督的合成图像检测方法,该方法能够在对比学习框架下,从联合视觉语言空间中提取具有高度区分性的法医特征。
- 我们收集了具有绘画风格的合成图像数据集,以更好地模拟现实世界的多样性。
- 实验结果表明,与现有最先进方法[1]–[3]、[14]–[17]相比,所提出的持续时间方法在四个不同数据集上均展现出优越性。
2.有关合成图像检测的研究
近年来,为应对人工智能生成图像可能被恶意利用的问题,学界提出了多种检测算法[1] [14] [16] [23]-[38]。这些算法通常利用图像合成过程中留下的独特痕迹,例如棋盘格纹理[23]、色彩特征[14]和渐变效果[16]。Dzanic等人[27]和Durall等人[28]通过频域分析发现,生成对抗网络(GAN)生成的图像在频谱分布上与真实数据存在显著差异。针对这一现象,部分研究[39]-[43]通过在振幅和相位频谱域引入频率感知注意力特征或可学习噪声模式,成功提取出合成伪影。考虑到检测器难以识别未知类型的图像,其他研究[1] [8]和知识蒸馏[3]提出通过数据增强和知识蒸馏来提升检测器的泛化能力。尽管效果显著,但[42] [44]的研究表明,仅基于GAN图像训练的检测器在识别深度伪造(DM)图像时泛化能力不足。实验结果表明,DM图像具有与GAN图像截然不同的特征伪影。为提升泛化能力,近期研究[45] [46]探索了基于大型预训练视觉语言模型(VLMs)的轻量级微调策略,显著提升了跨领域评估的泛化性能。
3.用于合成图像检测的LASTED算法
我们的目标是设计一种名为LASTED的合成图像检测器,使其能够对未见过的数据进行良好泛化。通过借助语言监督改进训练范式,我们实现了这一目标。下文首先介绍采用增强语言监督的动机,随后详细阐述文本标签的设计方法,最后给出LASTED的具体训练流程。
A.动机
基于对比学习的训练范式已被证实具有强大的泛化能力和零样本迁移能力,这在图像分类领域表现尤为突出[9]-[11] [20]。受此启发,我们尝试将对比学习引入合成图像检测任务。为探索最合适的对比学习范式,我们评估了三种广泛采用的范式——MoCo[11]、MAE[9]和CLIP[10],考察它们提取通用表征的能力,用于区分未见过的真实绘画(Danbooru[21])与合成绘画(Latent Diffusion[22])。通过T-SNE[47]可视化提取的特征如图4所示。
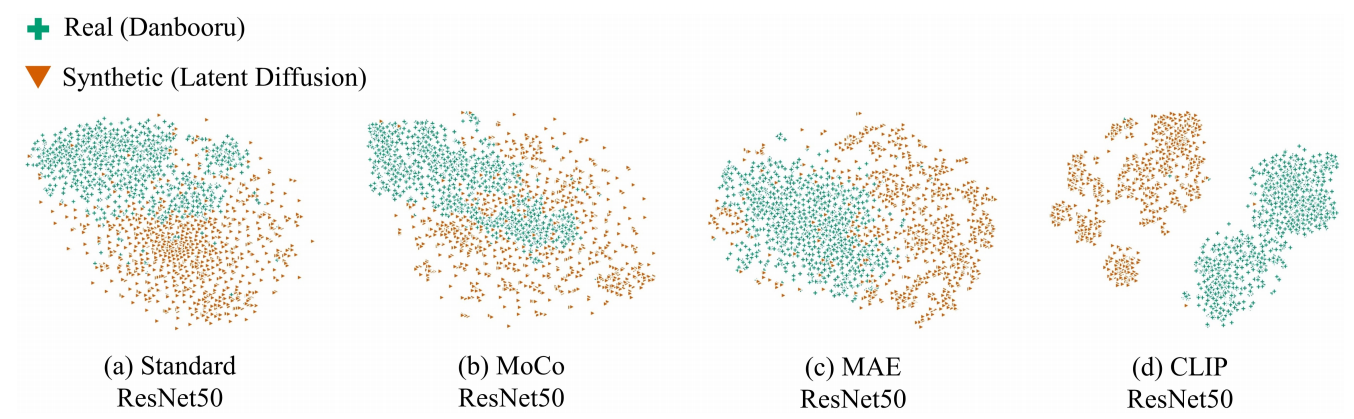
图4:不同训练范式(MoCo [11]、MAE [9]和CLIP [10])导致不同的泛化能力。值得注意的是,所有模型均采用相同的ResNet50 [19]架构,并在自然数据集ImageNet [20]上未经微调进行训练。测试在未见过的真实绘画图像(Danbooru [21])和Latent Diffusion [22]合成的图像上进行。
值得注意的是,实验未进行微调。可以看出,尽管这些模型仅在真实自然照片(如ImageNet[20]——一个广泛用于评估图像分类模型的大型数据集,包含数百万张标注图像及数千个类别)上训练,仍能从未见过的真实/合成绘画图像中提取出高度判别性的表征。特别是CLIP提取的表征,其区分Danbooru和Latent
Diffusion绘画图像的能力更为出色。因此我们推测,尽管深度生成对抗网络(DM)或生成对抗网络(GAN)合成图像具有良好的视觉真实性,但在联合视觉-语言特征空间中仍可被轻易区分。
我们将这种高度区分性的特征空间形成归因于信息的丰富性及多模态表征。具体而言,文本描述提供了超越固定标签的海量信息。这种多样性使检测器能够捕捉不同场景的区分特征,从而提升其辨别相似场景真实与合成的能力。另一方面,多模态目标监督机制不仅引导检测器识别图像的视觉特征,还指导其理解这些特征与文本描述之间的关联。这种监督机制有效塑造了特征空间,使表征实现更优的分离与组织。现在我们已准备好设计合适的文本标签,并基于这些标签开展多模态训练。
B. 文本标签增强
利用视觉-语言联合特征的首个挑战在于,训练图像(真实或合成)本身并不自然地附带文本信息。因 此,设计一种专门适配合成图像检测任务的文本数据增强策略至关重要。一种简单粗暴的方法是,根据图像真实与否,人为地为训练数据集中的每张图像标注“真实”或“合成”(参见表I中的R1)。但实验发现,这种简单的标注方式会导致合成图像检测任务的泛化效果较差。这是因为真实图像(类似合成图像)存在不同类型,例如相机拍摄的图像(如ImageNet[20])和通过Photoshop或数字绘图板绘制的人工图像(如Danbooru[21])。显然,这两类真实图像具有显著不同的特征:真实照片中存在相机痕迹,而绘画图像中则包含虚构元素。因此,不应将它们简单归类为同一类别并统一标注为“真实”。

为解决这一问题,我们可添加“照片”和“绘画”作为二级标签来区分前文提到的两类图像(参见表I中的R2)。除了使用“照片/绘画”标签外,还可通过图像语义进一步优化文本标签。具体而言,R3采用基于ImageNet数据库(包含1000个类别)训练的分类器对给定图像进行分类,并将预测标签作为这些图像的二级标签。类似地,可利用图像描述技术[13]
[48]生成描述图像内容的句子作为R4标签。为更精准地整合“照片/绘画”语义信息,我们采用模板“A照片/绘画的[图像描述]”将R2和R4相结合,最终生成R5标签,该标签将作为训练过程中的文本标签使用。
现在,我们准备介绍使用R5作为文本标签的训练过程。
注:一个自然的想法是直接合并主标签和次标签,将R5转化为R6。然而,这种标注方法会显著干扰我们区分真实图像与合成图像的核心任务,导致学习到泛化语义特征。第四章F节将展示的消融研究显示,与R5相比,R6在检测性能上最多降低24.5%。
C. LASTED训练流程
我们LASTED的训练过程如图5(a)所示,主要涉及两个编码器,即图像编码器 fθ 和文本编码器 gϕ 。
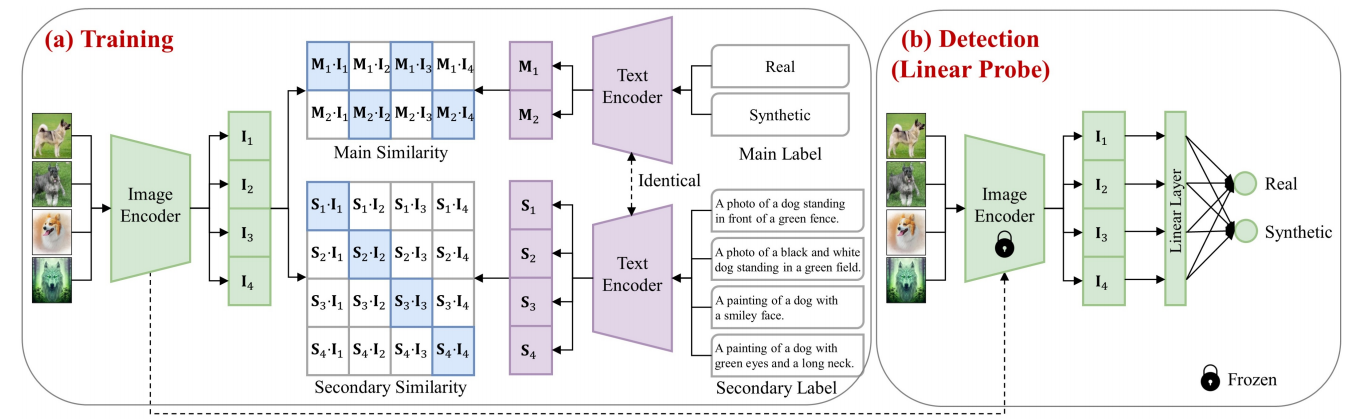
图5:我们提出的LASTED框架在训练过程中引入了语言引导的对比范式,以更好地解耦图像的语义信息,使检测器聚焦于法医信号。训练完成后,通过微调轻量级线性探针即可实现具体的合成/真实检测。
给定一个由N对图像及其增强文本标签\(\{(\mathbf{X}_{i},\mathbf{Y}_{i}^{m},\mathbf{Y}_{i}^{s})\}_{i=1}^{N}\)组成的数据集\(\cal D\),编码器首先提取视觉和文本表示\({\mathbf
I}_{i}=f_{\theta}(\mathbf{X}_{i})\),\({\mathbf
M}_{i}=g_{\phi}(\mathbf{Y}_{i}^m)\),\({\mathbf
S}_{i}=g_{\phi}(\mathbf{Y}_{i}^s)\)。其中,\(\mathbf{Y}_{i}^m\)和\(\mathbf{Y}_{i}^s\)分别是第i个图像\(\mathbf{X}_{i}\)的主要和次要文本标签。通过对视觉和文本表示进行点积运算,我们获得主标签和次标签的相似度矩阵。目标函数旨在最大化匹配视觉和文本配对的余弦相似度(见图5(a)中的蓝色框),同时最小化未匹配配对(白色框)。形式上,沿图像轴的主相似度矩阵损失可表示为:
\[\mathcal{L_{I}^{m}}=\frac{1}{B}\sum_{i=1}^{B}-1{\mathrm{og}}\,\frac{\exp\left(\mathrm{L}_{i}\cdot\mathrm{M}_i/\tau\right)}{\sum_{j\in[1,C]}\exp\left(\mathrm{I}_{i}\cdot\mathrm{M}_j/\tau\right)}.\]
同样地,我们可通过以下方式计算沿文本轴的损失: \[\mathcal{L}_{T}^{m}=\frac{1}{C}\sum_{j=1}^{C}-\log\frac{\sum_{k\in[1,B],\mathrm{M}_{k}=\mathrm{M}_{j}}\exp\left(\mathrm{M}_{k}\cdot\mathrm{I}_{k}/\tau\right)}{\sum_{i\in[1,N]}\exp\left(\mathrm{M}_{j}\cdot\mathrm{I}_{i}/\tau\right)},\]
其中\(\tau\)是一个学习得到的温度参数
[10],C 表示当前批次中具有 B 张图像的不同标签数量。\([i,j]\)表示从 i 到 j
的整数区间。同样地,我们可以计算次级相似性矩阵的图像轴\(\mathcal{L_{I}^{s}}\)和文本轴\(\mathcal{L}_{T}^{s}\)。需要注意的是,由于相似性矩阵可能不总是方形的,对于具有相同文本标签的图像,我们只需取它们的相似度平均值。最终的总体损失函数变为
\[\mathcal{L}=\mathcal{L}_{I}^{m}+\mathcal{L}_{T}^{m}+\lambda(\mathcal{L}_{I}^{s}+\mathcal{L}_{T}^{s}),\]
其中\(\lambda\)是主次损失之间的折衷参数。
关于网络架构,我们分别采用ResNet50x64
[10] 和文本变压器 [49] 作为图像编码器\(f_{\theta}\)和文本编码器\(g_{\phi}\)。还应指出的是,网络的选择是灵活的,只要提取的表示I、M和S共享相同的维度特征空间即可。关于使用不同图像编码器的消融研究将在第IV-F节中给出。
D. LASTED的检测流程
在编码器训练过程中,我们提出通过线性探针(LP)方法实现合成图像检测,如图5(b)所示。LP旨在提炼编码器学到的知识,以便更广泛地检测未见过的合成图像[3],[50]。具体而言,我们在训练良好的图像编码器\(f_{\theta}\)上增加了一个额外的线性层\(l_{\tau}\),并使用二元交叉熵损失对其进行监督:
\[{\mathcal{L}}_{c
e}=-\sum_{i\in{\mathcal{D}}^{S}}\log(l_{\tau}(f_{\theta}({\mathbf{X}}_{i})))-\sum_{j\in{\mathcal{D}}^{R}}\log(1-l_{\tau}(f_{\theta}({\mathbf{X}}_{j}))),\]
其中\(\mathcal{D}^{R}\)和\(\mathcal{D}^{S}\)分别表示数据集 D
的真实子集和合成子集的索引。需要注意的是,图像编码器\(f_{\theta}\)保持冻结状态,无需进一步微调,主要是因为在之前的对比学习中已经监督过其具有良好的判别能力的特征空间。由于线性层\(l_{\tau}\)包含的参数非常少(例如\(\tau\in{\mathbb
R}^{1024}\)),微调过程可以快速完成。
或者,我们也可以通过最近邻(NN)匹配来实现检测过程。具体来说,我们首先分别提取“真实”和“合成”类别的文本表示\(\mathbf{M}_{r}\)和\(\mathbf{M}_{s}\)。给定一个查询图像\(\mathbf{X}_{t}\),我们随后计算其表示\({I}_{t}=f_{\theta}(\mathbf{X}_{t})\)与Mr或Ms之间的余弦相似度。通过SoftMax函数可以推导出Xt属于“合成”类别的概率p:
\[p=\frac{\exp(\mathbf{I}_{t}\cdot\mathbf{M}_{s})}{\exp(\mathbf{I}_{t}\cdot\mathbf{M}_{r})+\exp(\mathbf{I}_{t}\cdot\mathbf{M}_{s})}.\]
如后文所述,我们通过实证研究发现,NN方法的性能逊于LP方法。这可能是由于“真实”与“合成”标签受到次要标签的影响,导致区分能力不足。
4.实验
A.设置
数据集:
我们构建了四个具有挑战性的数据集,以全面评估所提出方法的性能。简要概述见表II。
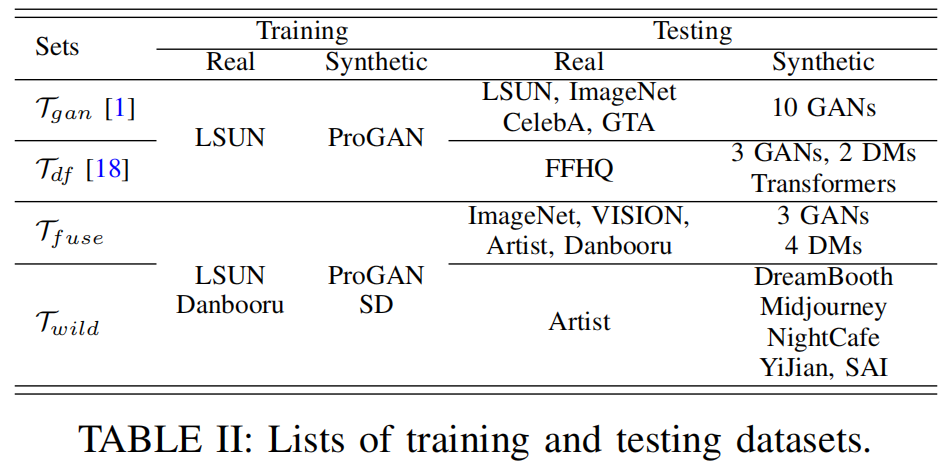
Tgan [1]:
根据 [1]、[3]、[14]–[16] 的研究,我们采用了
ForenSynths [1] 数据集(命名为 Tgan),该数据集由 11 种合成方法生成的 11
个子集组成,包括 ProGAN [51]、StyleGAN [52]、BigGAN [53]、CycleGAN
[54]、StarGAN [55]、GauGAN [56]、 CRN [57]、 IMLE [58]、 SITD [59]、SAN
[6] 和 Deepfake
[60]。为了评估合成图像检测器对未见过图像的泛化能力,仅使用 ProGAN
子集进行训练,而其余 10 个子集用于测试。
Tdf [18]:
Ju 等人 [18] 指出,Tgan
数据集无法反映现实世界的情况,因此他们通过结合 6 个高级生成模型和 5
个反取证操作创建了 Tdf 数据集。具体来说,Tdf 包含 46,400 张由 3
个生成对抗网络(3DGAN [61]、StyleGAN2 [62]、StyleGAN3 [63])、2
个潜在差分模型(LSGM [64]、Latent Diffusion [22])和 1 个 Transformer
[65]
生成的合成图像。为了更好地模拟现实世界情况,应用了五种后处理操作以对抗取证算法,包括常用的后处理(如压缩和模糊)、混合、反取证(如
CW 攻击 [66])、多图像压缩以及上述操作的组合。需要注意的是,Tdf
数据集仅用于测试,而训练则在 Tgan 上进行。
Tfuse:
考虑到Tgan和Tdf中未包含绘画图像,我们通过整合4类数据额外形成了一个融合数据集Tfuse。具体来说,真实和合成照片分别由
LSUN
[67]和ProGAN[51]生成。此外,真实和合成绘画分别来源于Danbooru[21]和稳定扩散(SD)[68]–[70]。此处使用的图像合成模型ProGAN和SD分别在
LSUN
和Danbooru上进行训练,迫使检测器从视觉相似的真实和合成图像中学习更具区分性的表征。每类包含20万张图像,其中1%的图像被划分为验证数据。在测试中,Tfuse采用7个具有代表性的图像合成模型生成跨域合成图像,包括3个GAN(BigGAN[53]、GauGAN[56]和StyleGAN[52])和4个DM(dalle[71]、glide[72]、Guided
Diffusion[73]和Latent
Diffusion[22])。同时,我们从4个真实数据集ImageNet[20]、Vision[74]、Danbooru[21]和Artist[75]
[76]中随机采样图像,采用平衡采样方法。
Twild:
除Tfuse外,我们还通过收集主流分享平台的图像构建了一个更具挑战性的测试数据集Twild。用户在分享平台上传播的真实世界合成图像,其质量远高于使用预训练GAN或DM生成的随机图像。Twild中的图像能更真实地反映现实场景。我们从DreamBooth[5]、Midjourney[4]、NightCafe[77]、StableAI[78]和YiJian[79]等平台共获取4K图像数据。此外,我们还从开源共享平台[75]
[76]获取了63位艺术家创作的2,229幅真实绘画图像。这些图像的预览展示见图6。
比较方法与评估指标:
我们选取了以下前沿合成图像检测器作为对比方法:Wang[1]、CR[14]、Grag[15]、LGrad[16]、DIRE[17]、HiFi[2]和UniDet[3]。特别地,针对不同实现方式的检测器,我们将其归类为不同变体以进行更细致的对比。例如,Wang[1]包含两种自增强策略变体,其自增强概率分别为10%和50%。其官方模型(基于Tgan和Tdf训练)可通过论文链接获取。为确保公平性,除直接使用其公开版本外,我们还使用Tfuse和Twild对所有竞争者进行重新训练。遵循其传统,我们采用平均精度(AP)作为检测性能评估指标。
实施细节:
我们使用PyTorch深度学习框架来实现我们的方法,其中采用默认参数的Adam
[80]作为优化器。学习率初始化为1e-4,如果验证准确率在2个epoch内未能提高,则将学习率减半,直到收敛。图像编码器
fθ 在ImageNet数据集上预训练,而文本编码器 gϕ
则利用CLIP提供的权重。在训练/测试过程中,所有输入图像被随机/中心裁剪为448×448的块。图像域增强,包括压缩、模糊和缩放,以50%的概率应用,这与[1]、[14]中采用的方法类似。权衡参数
λ 经实验设置为0.1。批量大小设为48,并在4个 NVIDIA A100 GPU
40GB上进行训练。
B. 数据集Tgan的评估
表III展示了Tgan的对比结果。
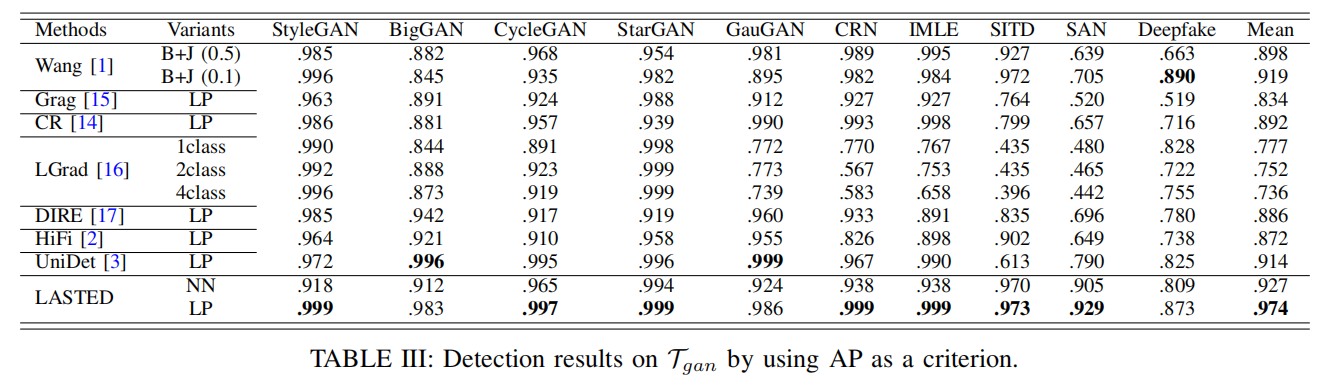
总体而言,所有研究方法[1]、[3]、[14]–[16]在其他生成对抗网络(GAN)生成的图像上均展现出良好的泛化能力,在StyleGAN、CycleGAN、StarGAN和GauGAN等子集上实现了超过0.90的平均精度(AP)。这一现象并不令人意外,因为不同GAN及其类似生成模型往往会产生相似的生成痕迹。然而,现有方法在SAN和Deepfake上的检测性能明显不足,例如UniDet在SAN上的AP仅为0.790,在Deepfake上仅达到0.825,充分暴露了其泛化能力的局限性。如表III最后两行所示,我们的LASTED模型(NN和LP)在全部10个测试案例中均展现出优异的检测性能,尤其在SAN数据集上取得了0.929的高平均精度(AP)。总体而言,我们的LASTED模型以0.974的AP值大幅超越了所有竞品的最佳表现。这充分证明,我们的LASTED模型能够为GAN合成图像检测学习更具普适性的表征特征。
C. 数据集Tdf评估
表IV显示,反取证操作会导致检测性能下降。
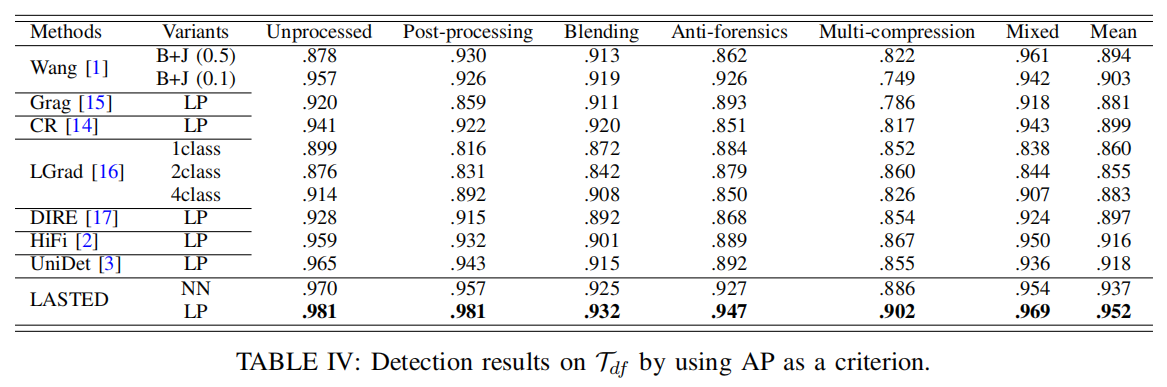
例如,UniDet[3]在反取证和多压缩场景下的性能分别从0.965降至0.892和0.855。我们的模型仍能保持良好的抗干扰性能,平均AP值达0.952,较排名第二的UniDet的0.918提升3.4%。
D. 数据集Tfuse的评估
表V展示了Tfuse与其他竞争方法的检测结果对比。
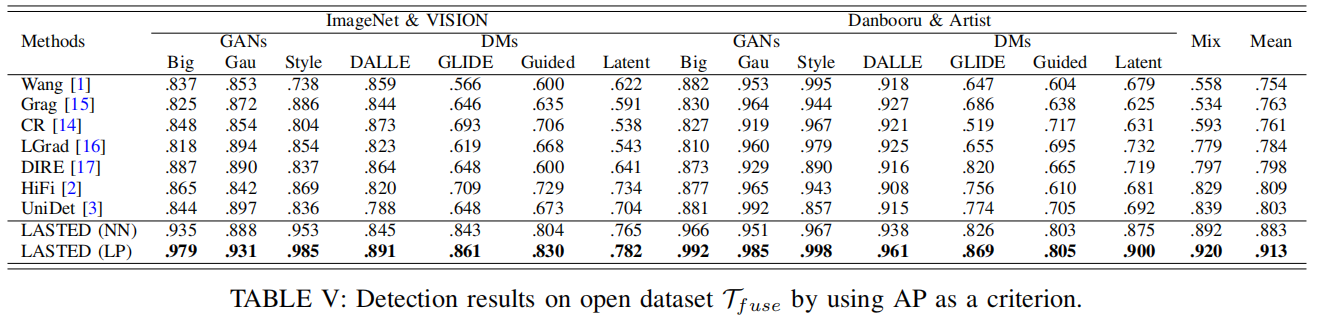
可以看出,Wang[1]、Grag[15]和CR[14]的检测性能相对较低:在真实图像中检测引导式与潜在扩散图像时,其平均AP值仅在0.50-0.70区间,表明这些模型在开放场景下难以提取具有区分度的表征。此外,UniDet[3]在区分真实图像与GAN合成图像时表现优异,这体现在其检测Danbooru和Artist数据集中的GauGAN时AP值高达0.992。但该模型在其他检测场景中仍存在泛化能力不足的问题——例如在ImageNet和视觉场景中区分滑翔图像时AP值仅为0.648,而在Danbooru和Artist数据集中分类引导式扩散图像时AP值为0.705。相比之下,借助语言监督的我们提出的lasted模型在多数测试场景中展现出优异的检测性能。需要说明的是,表V新增了“混合”列,用于展示Tfuse对所有类别的整合与同步推理能力,而此前各列仅进行单类别推理。实验结果表明,LASTED模型具有更强的泛化能力,能够在多个跨域测试数据集上提取高度区分度的表征。总体而言,我们的LASTED模型平均AP值达到0.913,较第二名竞争对手提升10.4个百分点,表现显著更优。
E. 数据集Twild的评估
现在让我们在更实用的数据集Twild上评估合成图像检测性能。
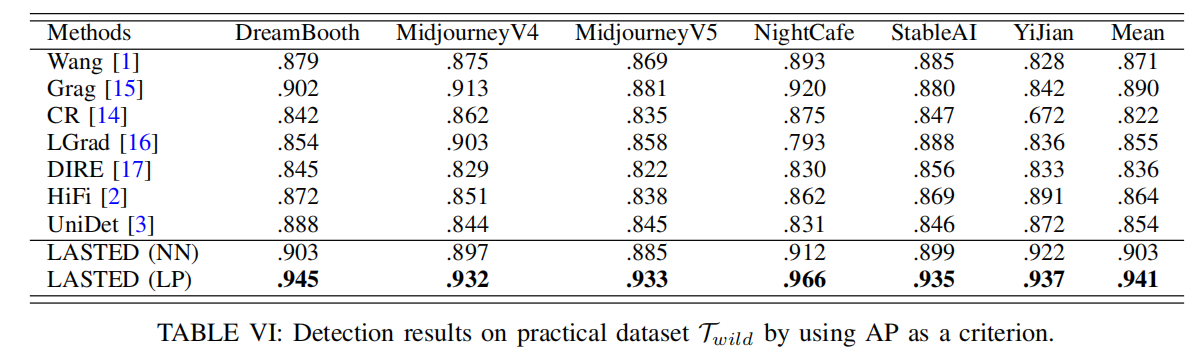
如表VI所示,现有算法普遍表现优异。例如,Grag[15]在DreamBooth和MidjourneyV4上的平均精度(AP)分别达到0.902和0.913。然而,基于分类的训练算法[1]-[3]、[14]-[17]泛化能力较弱,导致检测性能欠佳。相比之下,我们提出的语言引导对比范式使模型能够学习更具泛化性的图像表征,平均AP达到0.941,较第二名提升5.1%。
F.消融研究
本小节通过分析训练范式、语言监督、网络架构及损失参数对最终检测性能的贡献,对LASTED模型进行消融研究。表VII展示了其在Tgan、Tfuse和Twild数据集上的主要对比结果。
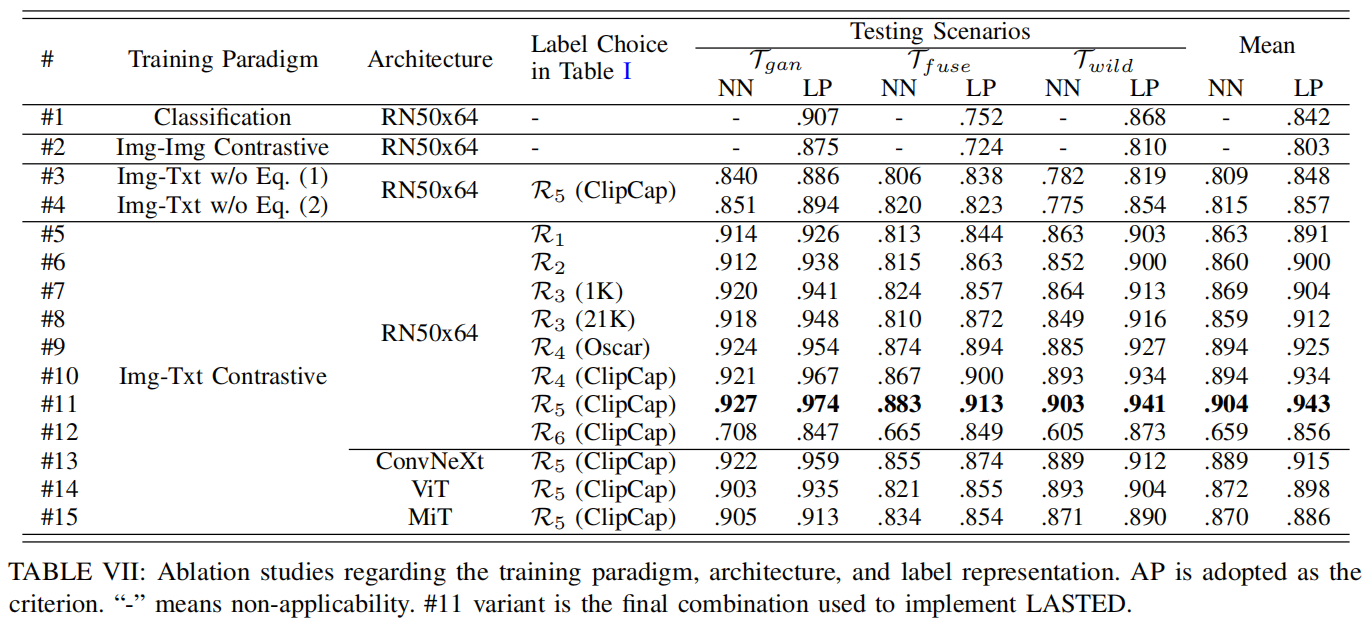
a)训练范式
在表VII中,lasted实验的结果展示在第11行。我们还使用标准分类和图像-图像对比范式训练了相同的网络,结果分别列于第1行和第2行。具体来说,我们采用二元交叉熵损失来监督图像编码器,而在图像-图像对比范式中,我们使用循环损失[12],且未涉及任何文本编码器。显然,分类范式不足以提取具有泛化能力的表征,仅达到0.842的平均精度(AP)。采用图像-图像对比范式训练的网络表现更差,AP值仅为0.803。需要强调的是,图像-图像对比范式的优化目标函数难度更高,容易导致模型陷入局部最优。
与使用单模态对比范式相比,所提出的持久性建立了一种基于公式(1)和(2)的语言引导对比。具体而言,在第3行和第4行中,我们分别消融了等式(1)和等式(2),以评估仅来自文本或视觉视角的约束效果。可见,缺乏图像或文本约束的第3行和第4行分别仅达到0.848和0.857的平均精度(AP),显著低于同时应用两种约束时第11行所达到的0.943
AP。该现象主要源于图像与文本在本任务中不存在一一对应关系。例如,文本“Real”可能对应多个真实图像。因此,图像与文本维度的联合损失使我们提出的模型LASTED能够获得稳健的多模态表征。
除了上述实验外,我们还评估了不同预训练范式在零样本学习能力方面的表现。由于这些预训练范式的目标并非检测合成图像,我们采用特征指标进行评估。具体而言,我们预期两个合成图像(或真实图像)之间的特征相似度会更高,反之则更低。表VIII的结果表明,基于语言监督的CLIP[10]具有更优的表征能力,远超MoCo[11]和MAE[9]范式。这再次验证了我们研究的有效性。需要指出的是,尽管预训练CLIP已具备一定的零样本能力,但其表现仍难以与监督学习方法相媲美。
b)
文本标注
如第三节B部分所述,语言监督涉及多种可能影响检测性能的文本标注策略。在第5至12行中,我们对比了八种标注方案。具体而言,第7行和第8行采用在ImageNet-1K和21K数据集上预训练的ResNet[19]模型作为辅助标签进行目标预测。而第9行和第10行的辅助标签则分别源自图像描述算法Oscar[48]和ClipCap[13]的语义特征。
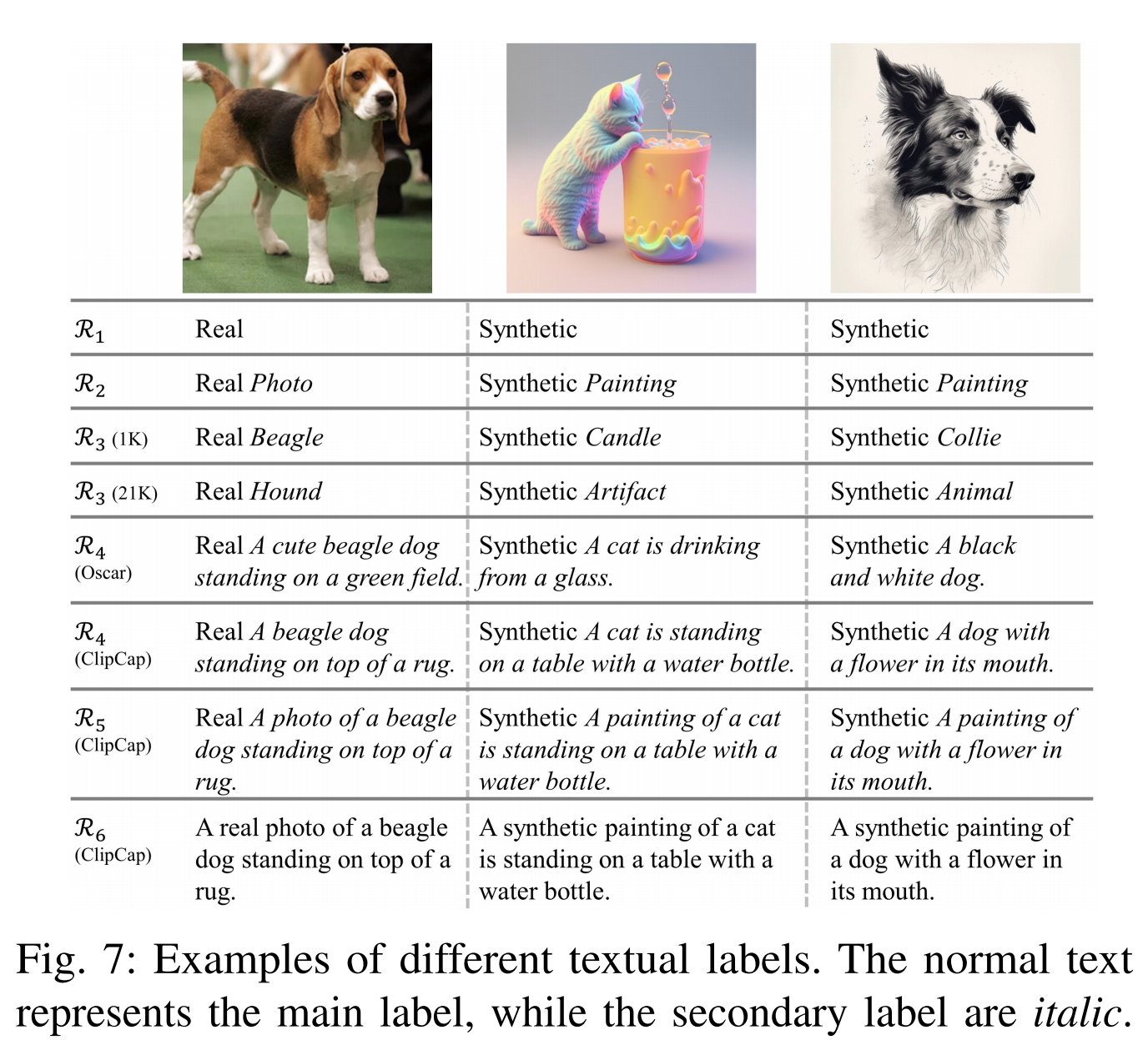
图7展示了文本标注的示例。如图7第四行中间所示,“Artifact”标签无法准确反映图像内容。这表明若能获取更精准的语义描述,通过LASTED范式可实现更显著的性能提升。
可以看出,虽然#5在Tgan数据集上取得了0.926的AP值,但通过扩展文本标签(如#6至#11)仍可进一步提升性能,最高可达到0.974的AP值。相较于只能提供单一类别的分类算法,语义描述算法通过提供更丰富的辅助标签,使得#9和#10的表现普遍优于#7和#8。但需注意的是,这些辅助标签并非完全客观,有时甚至会导致错误标注。此外,#12的实验结果表明,若简单拼接主标签与辅助标签,图像编码器将从合成检测器训练为通用语义特征提取器,这体现在神经网络方法仅获得0.659的AP值上。尽管通过微调(LP方法)可将平均精度(AP)从0.659提升至0.856,但其表现仍不及采用更细粒度划分训练的模型(如AP值达0.943的#11模型)。总体而言,LP方法优于神经网络(NN),主要因其能进一步优化语言编码器的学习成果,并提供更宽泛的决策边界。
c)
网络架构
不同编码器架构在表征能力上存在本质差异。我们评估了使用ResNet50x64[10]、ConvNeXt[81]、ViT[82]和MiT[83]作为图像编码器时的检测性能。具体而言,ResNet50x64、ConvNeXt、ViT和MiT的检测结果分别列于表VII的第11、13、14和15行。值得注意的是,在合成图像检测任务中,基于ResNet的网络比Transformer架构更具优势。因此,我们最终选定ResNet50x64作为图像编码器。对于文本编码器,我们也尝试了DistilBERT[84]和albert[85]等不同架构,但未观察到显著性能差异。因此,我们直接采用Text
Transformer[49]作为文本编码器。
d) λ 的影响
我们研究了损失平衡参数 λ
对最终结果的影响,并在图8中展示了在Twild数据集上的结果。
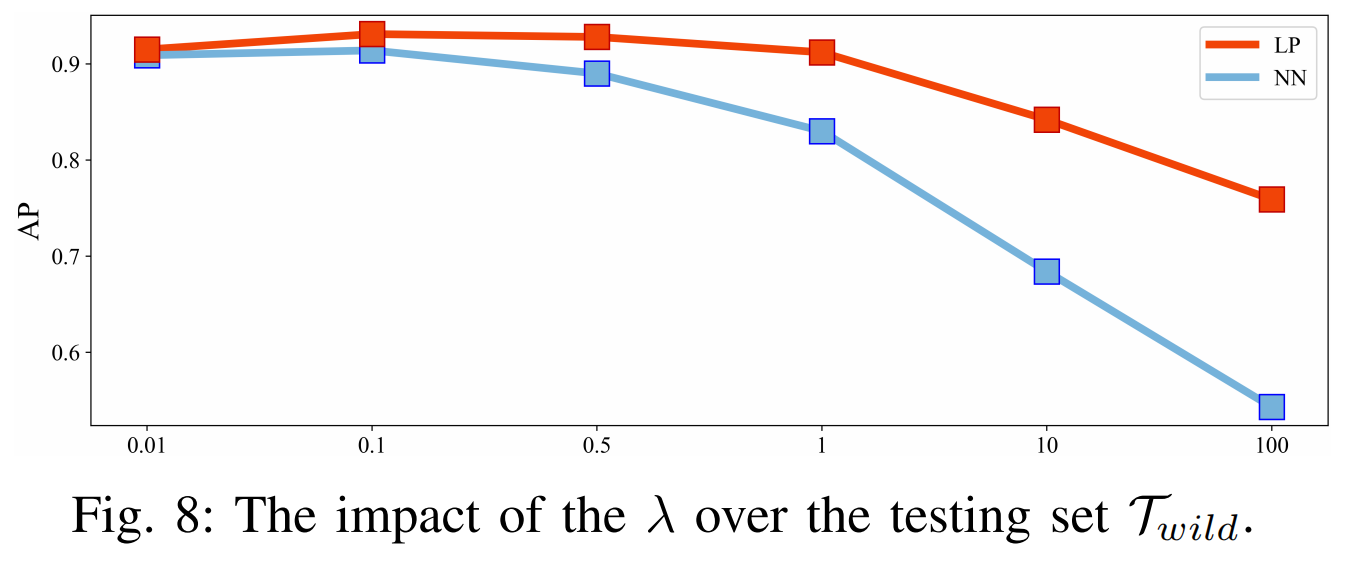
显然,如果 λ 值过大,会导致训练期间的主要标签失去显著性,从而使训练好的编码器变成一个通用的语义提取器。同样,虽然后续的LP可以学习到区分真实与合成的特征,但仍难以达到预期效果。因此,我们最终将 λ 设置为0.1。
e)
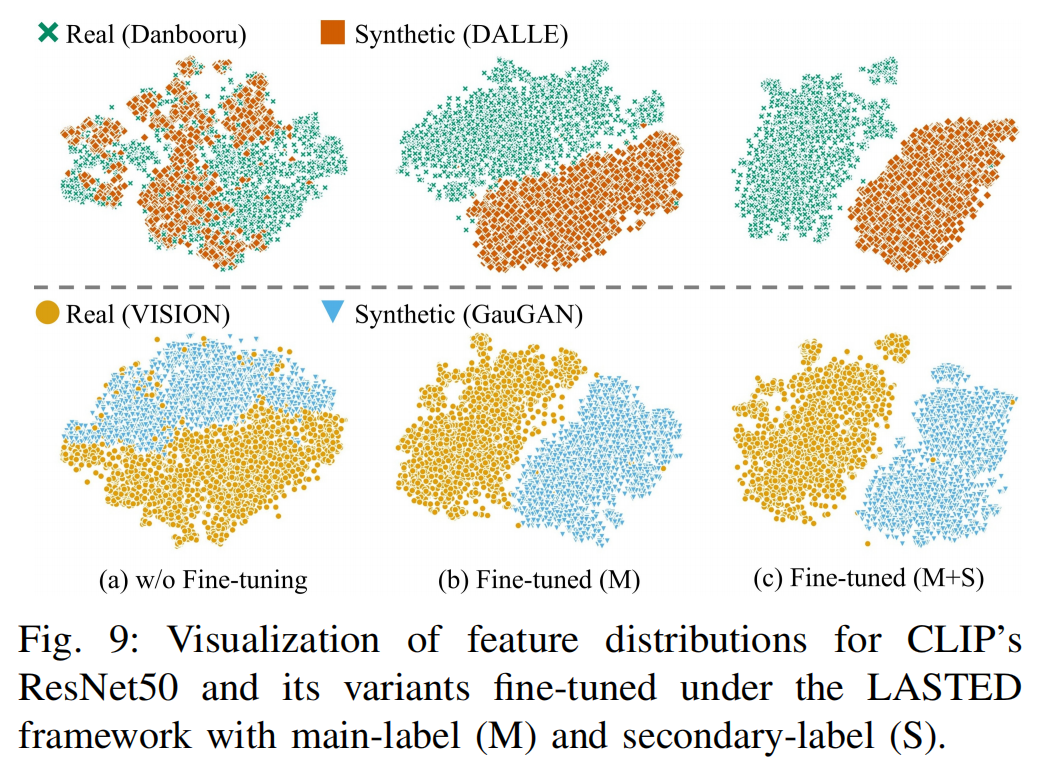
特征分布影响
图9展示了CLIP预训练ResNet50模型及其两种微调变体的特征提取效果,其中一种使用主标签训练,另一种补充了次级标签。预训练模型在处理跨域分布(如Danbooru与dalle)时表现欠佳。虽然主标签微调带来轻微提升,但模型仍缺乏判别能力,这可能源于对训练域(ImageNet与ProGAN)的过拟合。引入次级标签有效缓解了这种过拟合问题,显著增强了跨域特征判别能力。
G.后处理的稳健性
我们还分析了所有竞争性检测器对后处理操作的鲁棒性。这一点至关重要,因为所研究的给定图像可能已经过多种后处理操作。具体而言,这些操作指代初始图像生成流程之后进行的各类用户编辑行为,包括裁剪、缩放或压缩等可能影响最终图像外观与质量的处理。为此,我们选取了四种常用操作:JPEG压缩、高斯模糊、高斯噪声和下采样。随后将这些操作应用于具有挑战性的实际数据集Twild,并在图10中展示结果。
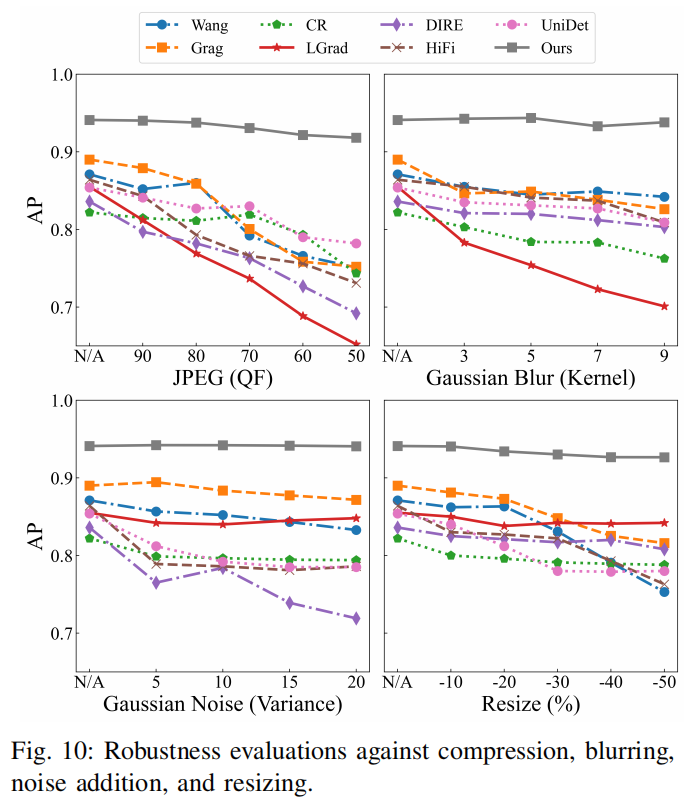
可以看出,CR[14]和Grag[15]对JPEG压缩存在一定敏感性,尤其当质量因子(QFs)较小时。例如当 QF 为50时,性能下降幅度可达10%以上。值得庆幸的是,我们的模型在这些后处理干扰下始终展现出令人满意的鲁棒性。
5.结论
本文针对如何提升合成图像检测器泛化能力这一关键问题展开研究。为此,我们提出了一种基于语言引导的对比学习框架,并创新性地设计了训练范式,以实现合成图像检测的泛化能力提升。通过大量实验验证,我们的LASTED框架展现出强大的泛化性能,其表现远超当前最先进的同类方案。
在后续研究中,我们将重点开发一款性能卓越的合成图像检测系统,以应对恶意篡改提示生成图像可能引发的挑战。具体而言,我们计划构建多模态对抗训练机制,提升检测系统对各类恶意攻击的适应能力——无论攻击源自图像还是文本模态。我们期待这些努力能最终打造出更稳健可靠的合成图像检测系统。