Guard Me If You Know Me:Protecting Specific Face-Identity from Deepfakes
Guard Me If You Know Me: Protecting Specific Face-Identity from Deepfakes
Kaiqing Lin1,3, Zhiyuan Yan2,3, Ke-Yue Zhang3, Li Hao2, Yue
Zhou1, Yuzhen Lin1,Weixiang Li1, Taiping Yao3†, Shouhong Ding3, Bin
Li1†
1
广东省智能信息处理重点实验室、深圳市媒体安全重点实验室和深圳大学 SZU
-AFS人工智能技术联合创新中心
2 北京大学电子与计算机工程学院
3
Tencent Youtu Lab
摘要
在数字时代,保护个人身份免受深度伪造攻击变得越来越重要,特别是对于名人和政治人物,他们的面部信息容易获取且常成为攻击目标。现有的大多数深度伪造检测方法都集中在通用场景上,往往忽略了已知面部身份的宝贵先验知识,例如“VIP人士”的真实面部数据已经公开。本文中,我们提出了一种名为VIPGuard的统一多模态框架,旨在捕捉给定身份的精细且全面的面部特征,将其与潜在的伪造或相似面孔进行比较,并通过推理得出准确且可解释的预测。具体而言,我们的框架包含三个主要阶段。首先,我们微调一个多模态大语言模型(MLLM),以学习详细且结构化的面部属性。其次,我们进行身份级别的判别学习,使模型能够区分高度相似面孔之间的细微差异,包括真实与伪造的变体。最后,我们引入用户特定定制,通过建模目标面部身份的独特特征,并利用
MLLM
进行语义推理,实现个性化且可解释的深度伪造检测。我们的框架比以前的检测工作有明显的优势,传统的检测器主要依赖于低级的视觉线索,而且没有提供人类可以理解的解释,而其他基于
MLLM
的模型往往缺乏对特定人脸身份的详细理解。为了便于评估我们的方法,我们构建了一个全面的身份感知基准测试,称为VIPBench,用于个性化深度伪造检测,涵盖了最新的7种面部替换技术和7种完整面部合成技术。大量实验表明,我们的模型在检测和解释方面均优于现有方法。
代码可在以下网址获取:
https://github.com/KQL11/VIPGuard
1.引言
生成式AI技术的快速发展[51,59,68,75,52,13]导致深度伪造内容的广泛生成与传播——这种合成媒体通常未经同意就操纵或替换个人身份。这些手段严重损害个人声誉与公众信任,尤其对名人、政要及公职人员等公众人物影响更为显著[2]。因此,防范身份信息遭此类操纵已超越单纯的隐私问题范畴,成为亟待解决的社会议题。
尽管深度伪造检测已引起广泛关注,但现有方法大多采用通用设计[50,36,56,76,72,44,88,89,82,83,84]。这些方法旨在对任何人脸图像或视频进行真伪分类,而无需考虑目标人物的身份信息。在现实场景中,许多情况下我们能获取目标身份的先验知识1,例如公众人物或已知个体[16]。这为检测技术开辟了新思路:能否利用已知面部特征来提升个性化深度伪造检测的识别效果和可解释性?与统一处理所有人脸不同,基于身份特征的检测方法[54,19,17,16,81]专注于输入图像与真实身份之间的语义匹配。通过这种方式,它们能提供更具个性化和情境感知的预测结果,从而可能同时提升检测性能和可解释性。
然而,现有的身份识别检测系统[16,81]未能充分利用身份特征的细节信息。这些系统主要依赖全局面部特征,却忽视了眼型、面部轮廓等细微语义细节。如图1所示,最新版GPT-4o模型[48]生成的图像乍看逼真,但局部面部区域仍存在微妙差异——比如明显突出的眼袋。当目标身份已知且所有面部细节都可获取时,利用这些细微差异进行检测就显得尤为重要。
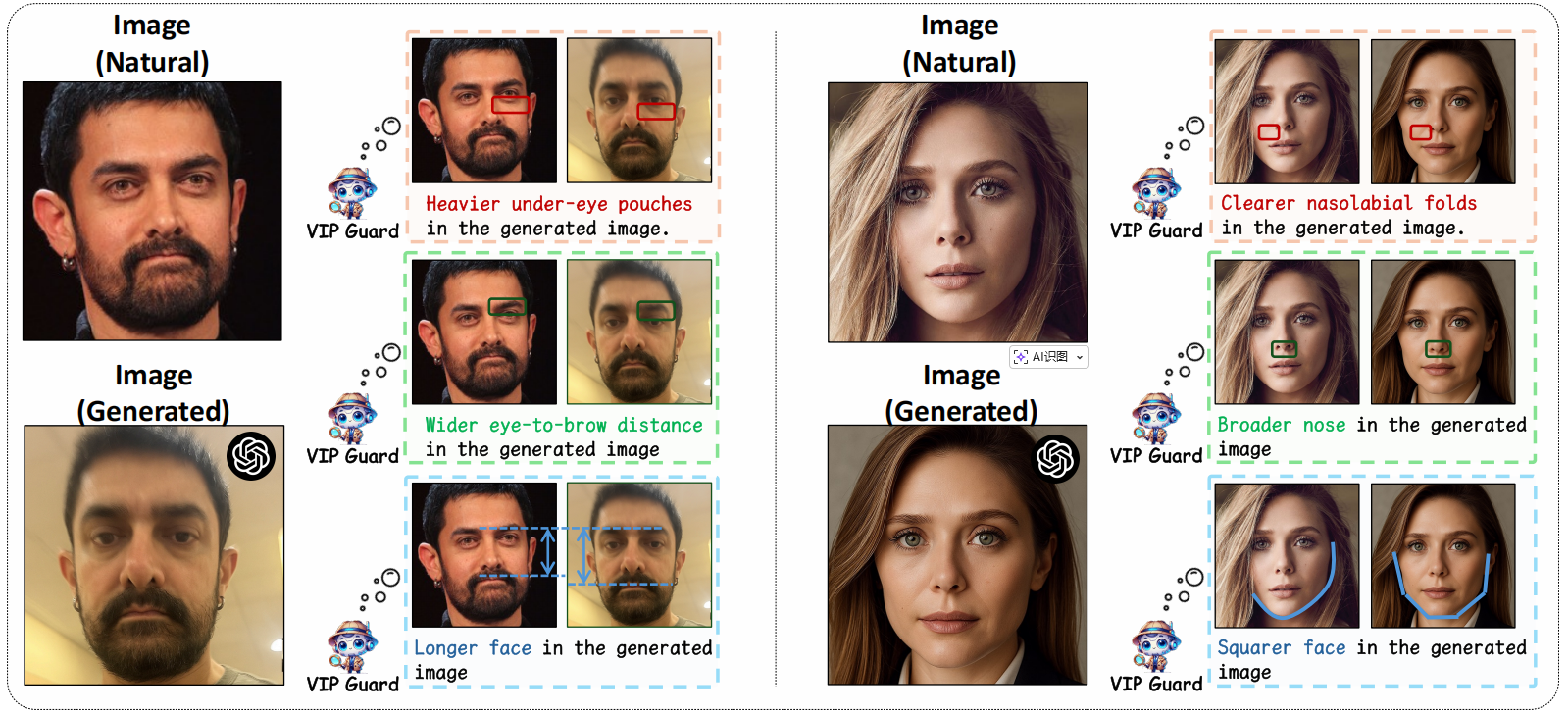
图1:自然图像(来自 LAION -Face [87])与GPT-4o [48]生成图像的示例性比较,显示面部属性(如眼袋和面部形状)的局部不一致性。
为此,本文提出了一种统一的多模态框架VIPGuard,用于检测和解释针对特定用户的深度伪造。VIPGuard通过显式整合已知的面部身份先验信息,包括全局身份信息和来自VIP的详细面部结构特征,解决了身份感知的深度伪造检测问题。为此,本文首次将伪造检测重新定义为针对VIP身份的精细面部识别任务。为了利用全局和局部面部信息,我们使用预训练的面部模型[62,14,11]来提取全局面部先验(面部相似度分数)和局部面部先验(面部特征)。利用这些先验信息,我们旨在使
MLLM
通过跨视觉和文本输入的可疑与真实面部之间的语义比较来执行伪造检测。
我们通过三个阶段训练VIPGuard:
(1)使用多种面部特征数据微调
MLLM
以增强面部理解;
(2)通过推理区分某些任意身份与被操纵或相似的面部;
(3)通过学习一个独特且轻量级的VIP标记来支持个性化检测,该标记代表每个目标身份以进行定制化推理。
为实现个性化深度伪造检测的稳健评估,我们特别推出VIPBench——一个以身份识别为核心的综合性基准测试,其设计与传统深度伪造基准[77,74]存在根本性差异。现有基准通常对人脸进行泛化处理且忽略身份操纵细节,而VIPBench则专门针对目标身份可识别场景展开测试,要求具备目标个体的先验知识。该基准包含22个特定目标身份及总计80,080张图像,涵盖真实样本与伪造样本。这些伪造样本采用14种前沿技术生成,涵盖7种人脸替换(FS)技术和7种全脸合成(EFS)技术,提供多样化操纵类型和真实评估场景。通过以已知身份为中心的评估框架并整合细粒度标注,VIPBench不仅可评估模型的检测准确率,还能考察其利用身份特征的能力。
我们的主要贡献总结如下:
- 我们提出一种针对特定个体的个性化深度伪造检测新方法,将其转化为基于全局身份特征与面部细节特征的精细人脸识别问题。该方法仅需为每位重要人物用户提供少量真实参考图像,使其在现实场景中具有实用价值。
- 我们提出VIPGuard,这是一个用于身份感知深度伪造检测与解释的统一多模态框架。该框架融合了预训练面部先验模型和多模态大语言模型,并采用三阶段流程:提取身份特征、执行视觉-文本推理,以及通过轻量级身份标记实现个性化检测。
- 我们推出VIPBench,这是一个用于评估身份感知深度伪造检测的综合性基准测试。该测试包含22个真实世界目标身份和14种前沿图像处理方法生成的80,080张图像,能够对个性化检测性能进行精细且真实的评估。
2.相关工作
2.1.通用深度伪造检测
常规深度伪造检测
基于多模态大语言模型的深度伪造检测
2.2.个性化深度伪造检测技术在特定身份保护中的应用
在检测伪造人脸的身份不一致时,现有研究[54,19,17,16,10,46]普遍采用参考图像进行个性化深度伪造检测。例如,ICT-Ref[16]通过Transformer模型检测面部内外区域的差异,而DiffID[81]则利用基于重建的身份距离来识别伪造内容。然而,这些方法主要依赖全局身份特征,忽视了更深层的用户特定信息。这种局限性不仅降低了其对数据分布偏移的鲁棒性,还导致无法提供人类可理解的检测解释。
3.VIPBench:个性化深度伪造检测的新基准
为了促进个性化深度伪造检测的训练与评估,我们构建了一个名为VIPBench的全面身份感知基准测试,用于个性化深度伪造检测。VIPBench的训练集逐步微调多语言语言模型(MLLMs),从基础面部属性识别逐步推进到精细的身份不一致检测。此外,我们引入了一个新的身份感知深度伪造检测评估数据集,该设置目前缺乏足够的评估资源,以评估不同方法的有效性。我们从开源数据集获取所有面部图像,包括 LAION -Face [87]、CrossFaceID [64]和FaceID-6M [63],并进行了一些预处理(具体细节见补充材料)。数据集构建流程的主要思想如下所述,完整细节见补充材料。
面部属性描述数据集
解决方案面部图像配以丰富的面部属性描述。该数据集(\({\mathcal D}_{FA}\))从 LAION
-Face收集了约30,000张高分辨率(超过1024 ×
1024)图像,以促进MLLMs中基础面部理解。此外,一个专门从事面部分析的 MLLM
可作为标题生成器,生成描述性面部属性信息。
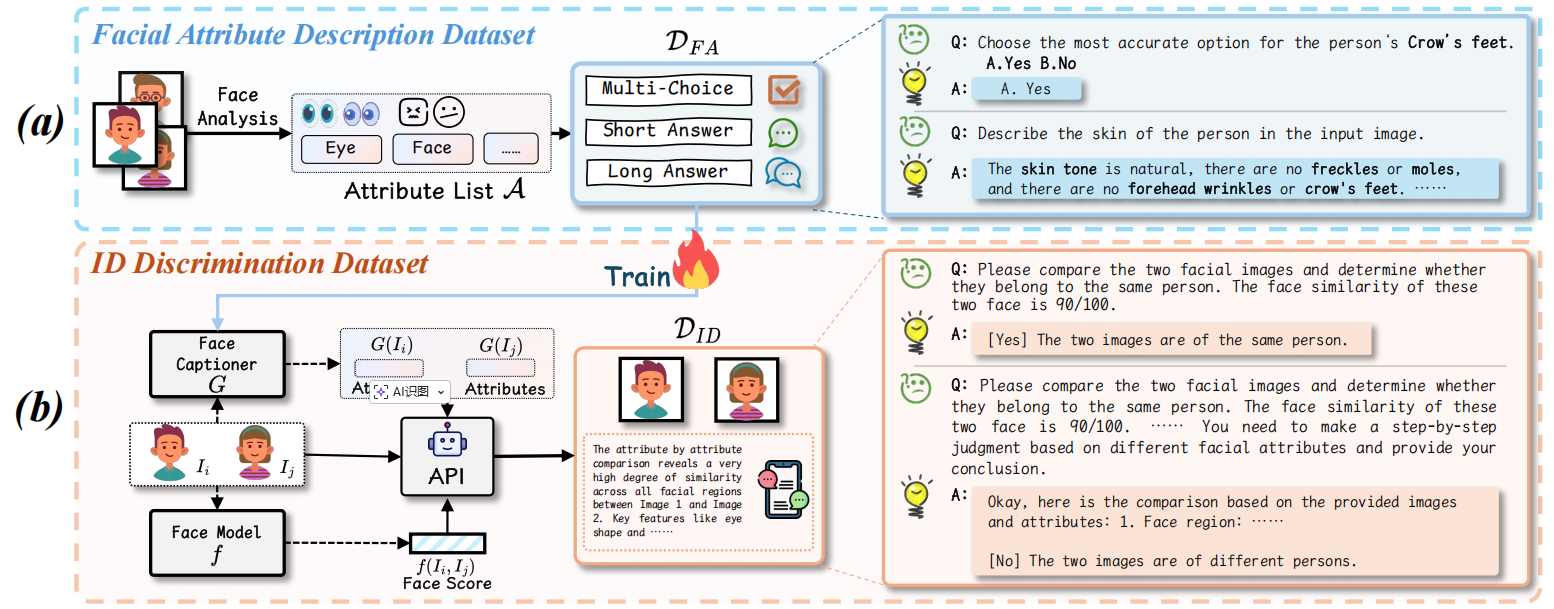
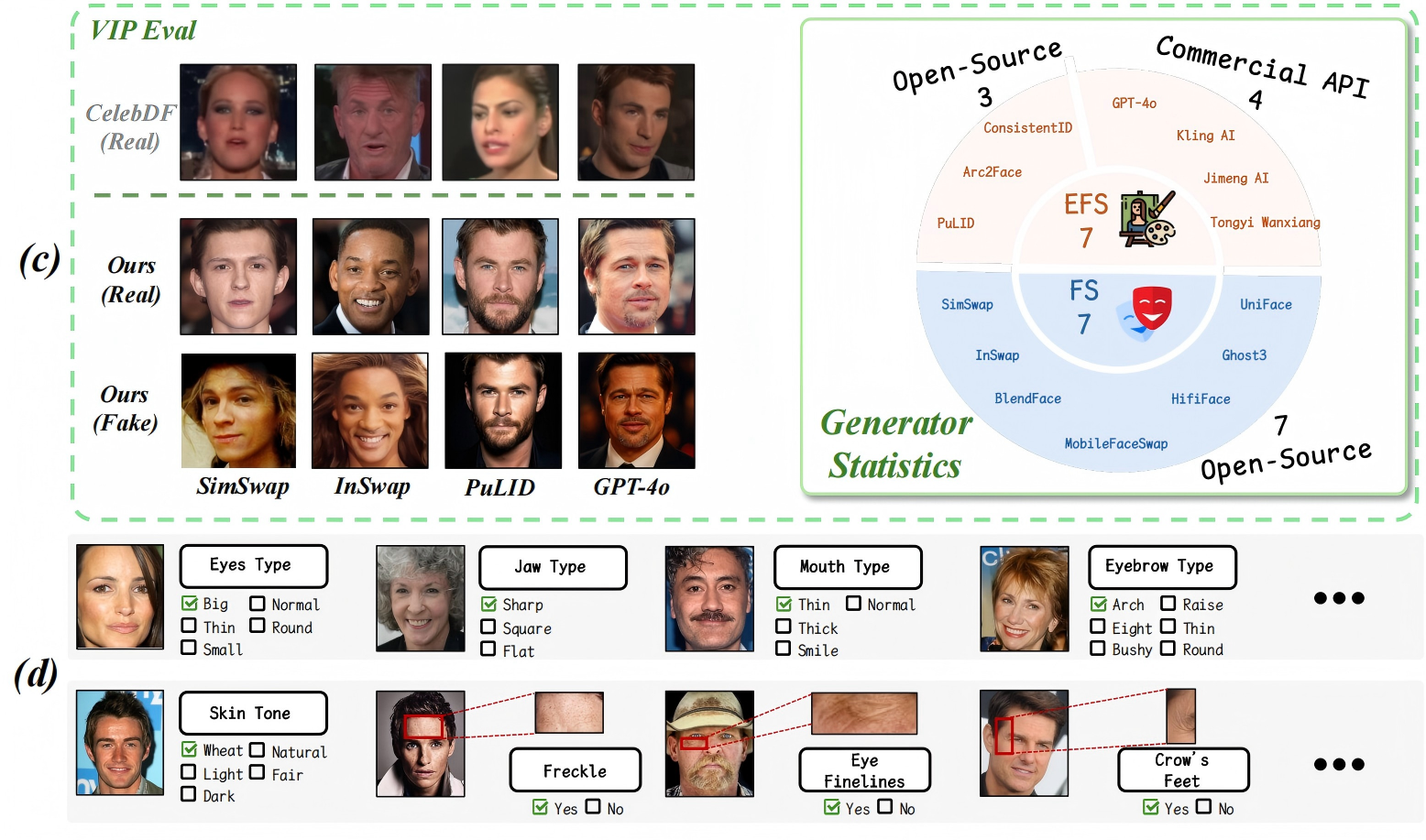
图3:所提出的VIPBench示意图,包括三个个性化数据集,(a) 面部特征描述数据集DF A,(b) 身份识别数据集DID,以及(c) VIPEval DEval。(d) 这里还展示了DF A中使用的一些面部特征示例,完整数据集可在补充材料中获取。(c) 中展示的真实图像来自CelebDF [87] 和VIPBench,而虚假图像则是通过多个模型生成的。(d) 中的所有图像均来自 LAION -Face [87]。
如图3所示,我们通过MegVii官方API2获取了详细属性(如脸型、皮肤状况),随后由人类专家进行精炼。图3(d)提供了这些面部属性的一些示例,随后将其转换为多种 VQA 格式(选择题、简答/长答)。该过程可表述为公式1; \[{\mathcal D}_{F A}=\left\{(I_{i},{\mathrm{VQA}}(a_{i1},a_{i2},\dots,a_{i k})\right\}\left[(a_{i1},\dots,a_{i k})\in{\mathcal A}^{k},\;i=1,\dots,{\mathrm{V}}\right\},\] 其中 A = F (I) 表示提取的面部特征集合,F 是 API,I 是面部图像。数据集 \({\mathcal D}_{FA}\)包含从 A 中抽取的所有 k 元组生成的 VQA 个实例。该数据集为训练 MLLM 理解基本面部特征提供了丰富的监督数据。有关\({\mathcal D}_{FA}\)的其他详细信息,请参见补充材料。
身份判别数据集
我们将个性化深度伪造检测重新定义为目标人脸为中心的精细级人脸识别问题,由此构建了身份判别数据集
\({\mathcal
D}_{ID}\)。该数据集包含\({\mathcal
D}_{ID}^{general}\)集和\({\mathcal
D}_{ID}^{vip}\)集,由面部图像及其对应标注组成,旨在用于精细级身份判别推理。具体而言,\({\mathcal
D}_{ID}\)包含面部图像对:正样本(同一身份,真实-真实)和负样本(其他所有)。如图1‘数据收集’部分所示,\({\mathcal
D}_{ID}^{vip}\)集中的面部对以VIP用户为中心构建,而\({\mathcal
D}_{ID}^{general}\)集中的面部对则采用任意身份构建。鉴于伪造人脸与真实人脸的高度相似性(这对传统人脸识别构成挑战),我们通过SimSwap[5](面部交换)和Arc2Face[49](全脸合成)技术对负样本进行了增强。这些负样本包括不同身份的真实-真实配对和真实-伪造配对,这两类大致以1:1的比例平衡。
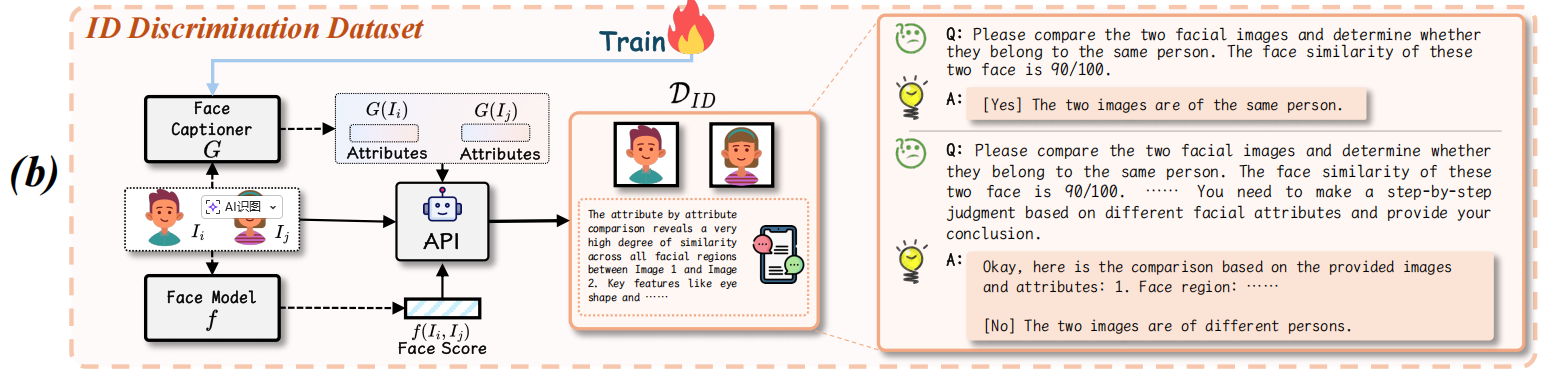
如图3(b)所示,对于每对图像,我们首先使用经过微调的 Qwen2.5VL-7B
模型[1]G生成面部属性列表,该模型在\({\mathcal
D}_{FA}\)上训练。
随后,我们通过预训练的面部识别模型f获取面部相似度评分。最终,我们采用商业模型(本文选用Gemini
2.5
Pro3[21],图3(b)中标注为API)作为训练数据。具体而言,API被严格要求仅基于提供的面部特征G(Ii)和G(Ij)以及相似度评分f(Ii,Ij),对图像对间的身份差异进行推理,确保分析基于真实特征而非受幻觉内容影响。上述过程可表述为
\[\begin{array}{l}{\mathrm{Prompt}=\mathrm{API}\,(Q,f(I_{i},I_{j}),I_{i},I_{j},G(I_{i}),G(I_{j}))}\\
{\cal D}_{I
D}=\{I_{i},I_{j},\mathrm{VQA}\left(I_{i},I_{j},\mathrm{Prompt}\right)\mid
I_{i},I_{j}\in{\mathcal I}\}\end{array}\]
其中Ii和Ij为面部图像,Q为输入至Gemini的提示词,J表示预先构建的图像名称对池(详见补充材料)。
VIPEval(用户特定评估数据集):
我们推出了一套名为VIPEval的用户专属评估数据集,专门用于测试个性化伪造检测性能。传统数据集[39,53]通常缺乏每个个体的高分辨率真实图像,且不同伪造方法间缺乏对应样本,这给个性化检测方法的评估带来挑战。本数据集整合了来自丰富来源的多分辨率图像及多样化生成方式,更能真实反映实际应用场景。为解决这一问题,我们从先前描述的图像名称库J中精心筛选出22个独特身份标识,确保与DID通用数据集中的身份标识无重叠。每个身份标识收集了40-60张真实图像,其中20张用于本基准测试DEval的验证,其余用于构建DID
vip数据集。该基准测试包含预留的真实图像和完整的伪造样本集。针对这22个测试身份,每种方法采用七种不同的面部置换(FS)技术[5,57,30,67,69,65,18]生成420张图像。此外,三种开源全脸合成(EFS)方法[49,28,24]通过随机种子或提示词变化,为每张真实测试图像生成10张图像,共计每个身份200张图像。另有四种基于API的商用EFS方法[48,32,60,34]为每个身份生成20张图像。整个数据集共计包含80,080张图像。
4.VIPGuard:一种用于个性化深度伪造检测的多模态框架
4.1.问题的提出与与已有研究的比较
我们研究一种个性化深度伪造检测场景:检测器可获取目标用户(如名人,下文简称VIP)的多张真实照片,以及来自其他无关个体的真实面部图像。这些真实图像作为先验知识,帮助检测器更精准地识别并保护目标人物身份。其核心目标是通过建模用户特有的面部特征,识别可疑图像,从而防范伪造攻击。针对面部替换等伪造行为,我们设定一个现实约束条件——用于篡改的源身份(标记为\({ID}^{source}\))在训练过程中对检测器不可见。这一假设更贴近现实场景,即攻击者可以使用防御方无法获取的任意人脸。这与身份感知检测方法[16,19,46]形成鲜明对比,后者假设目标身份(\({ID}^{vip}\))和源身份(\({ID}^{source}\))在训练时已知,即所有相关人脸均包含在参考集{\({ID}^{vip}\),\({ID}^{source}\),\({ID}^{others}\)}中。这种封闭世界假设简化了问题,但在实际应用中往往不切实际。在我们的模型中,检测器仅在训练阶段接触{\({ID}^{vip}\),\({ID}^{others}\)},而\({ID}^{source}\)始终未知。这一差异引入了一个更具挑战性但更实用的问题设定,强调了对未见源身份的泛化需求以及与现实部署场景更好对齐的必要性。
4.2.方法概述
为了应对这一挑战,我们提出了一种框架,VIPGuard,它开发了一个 MLLM ,能够识别特定用户的可疑图像,同时基于用户独特的面部特征提供人类可理解的解释。我们将个性化深度伪造检测重新定义为一个以保护目标为中心的精细面部识别问题,通过 MLLM 对全局身份特征和详细面部属性的推理来检测伪造。为了使模型具备这种能力,我们从一个预训练的 MLLM(Qwen-2.5-VL-7B [1])开始,并通过三个阶段的过程逐步微调:面部属性学习、身份判别和用户特定定制。下面我们将详细描述每个阶段。
4.3 .VIPGuard的三阶段训练
阶段一:面部属性学习
首先,增强模型识别和利用精细面部特征的能力至关重要,因为朴素的多层语言模型(MLLMs)本身对人类面部特征缺乏足够的理解,无法有效保护VIP身份。为此,我们在包含大量面部特征识别样本的DF A数据集上对预训练的 MLLM 进行微调(参见第3节)。我们将LoRA[26]模块集成到预训练的 MLLM 中,并使用自回归损失进行监督微调,如公式3中定义: \[L(\theta)=-\sum_{i=1}^{N}\log\left[p_{\theta}(x_{i}\mid x_{\lt i},E_{V}(I))\right],\] 其中 \(\theta\) 表示插入的 LoRA 模块和原始 MLLM 的参数,N 是输出提示的长度,xi 是第 i 个待预测的标记,而 x<i 是之前的标记,EV 表示 MLLM 的视觉编码器,I 是输入图像。经过训练后, MLLM 能够理解和识别面部特征。
阶段二:身份识别学习
如图1所示,尽管假脸乍看逼真,但其面部细节特征仍存在细微差异。因此,我们将个性化深度伪造检测重新定义为一个以受保护目标为中心的精细面部识别问题,通过 MLLM 对全局身份特征和详细面部属性的推理来检测伪造。在此阶段,我们进一步在\({\mathcal D}_{ID}^{general}\)数据集上微调 MLLM ,以实现跨人脸对的精细面部识别——每个对由任意查询人脸\(I_{query}\)和任意输入人脸\(I_{Img}\)组成——从而赋予其推理识别的基础能力。\({\mathcal D}_{ID}^{general}\)数据集包含大量正类(相同身份)和负类(包括不同身份和伪造)人脸对,每对都标注有 VQA 风格的推理问题和答案。这些注释通过推理全局和局部面部先验知识,支持精细的身份判别。在此,我们采用人脸识别模型[62,14,11]提供人脸相似度评分,作为全局面部先验,而局部面部先验——即面部属性知识——已在第一阶段微调的 MLLM 中整合。
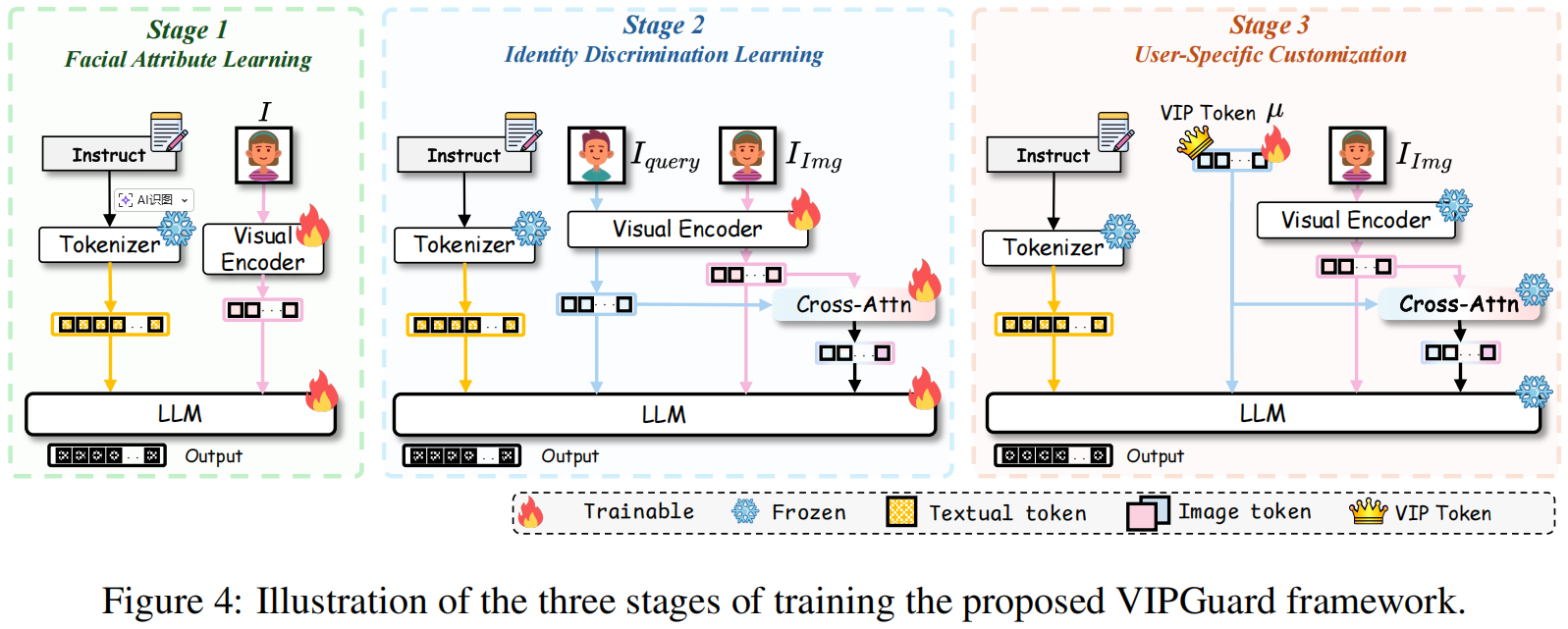
具体而言,如图4所示,查询\(I_{query}\)和输入图像\(I_{Img}\)首先被输入到 MLLM 的视觉编码器EV中,以获得视觉标记序列fquery和fImg。预训练的多语言语言模型(MLLM)通常缺乏针对面部识别任务的特定优化,导致基础视觉特征\(f_{query}\)和\(f_{Img}\)在面部身份判别中表现欠佳。为此,我们引入交叉注意力(Cross-Attn)模块[40],用于捕捉不同面部图像间视觉标记的细微差异,其数学表达式如下 \[g=\mathrm{softmax}\left({\frac{Q K^{\mathsf{T}}}{\sqrt{d_{K}}}}\right)V,\quad{\mathrm{where}}\ Q=f_{\mathrm{quey}},\ K=V=f_{\mathrm{Img}}.\] 我们通过如下所示的自回归损失(等式5)来优化 MLLM : \[L(\theta)=-\sum_{i=1}^{N}\log\left[p_{\theta}(x_{i}\mid x_{\lt i},f_{q u e r y},f_{I m g},g)\right].\] 经过训练后,该模型能够对任意两张人脸进行精细的面部识别,并同时提供其差异的详细解释。
阶段三:用户特定定制
完成阶段二后, MLLM 获得了进行精细面部身份比较和推理的基本能力。在第三阶段,我们进一步引入了用户特定的定制功能,以实现针对特定 VIP 用户的个性化伪造检测。为此,我们构建了一个与 \({\mathcal D}_{ID}^{general}\)结构相同的\({\mathcal D}_{ID}^{vip}\)数据集,该数据集以 VIP 用户的身份为中心,使模型能够基于 VIP 用户的面部先验知识进行推理,从而识别可疑图像。受 Yo‘LLaVA [47] 的启发,为了便于轻量级部署,我们引入了一个在\({\mathcal D}_{ID}^{vip}\)上训练的可学习 VIP 令牌,记为 µ ,它编码了 VIP 用户的身份特定特征。在此阶段,第二阶段的 MLLM 参数被冻结,仅 VIP 令牌在\({\mathcal D}_{ID}^{vip}\)上进行训练,从而精炼模型识别和区分目标 VIP 用户的能力。如图4所示,可学习的VIP标记 µ ,其大小为32×d的向量,用于替代查询图像\(I_{query}\)的视觉特征表示\(f_{query}\)。形式上,预测过程可以描述如下 \[g=\mathrm{softmax}\left(\frac{Q K^{\mathsf{T}}}{\sqrt{d_{K}}}\right)V,\quad\mathrm{where}~Q=\mu,~K=V=f_{\mathrm{Img}}.\]
\[L(\mu)=-\sum_{i=1}^{N}l o g[p_{\theta}(x_{i}|x_{\lt i},\mu,f_{q u e r y},g)].\]
值得注意的是,\({\mathcal D}_{ID}^{vip}\)中的查询图像并未使用;仅将输入图像\(I_{Img}\)及其对应的推理注释输入到 MLLM 中。经过训练后, MLLM 能够通过判断输入图像 \(I_{Img}\)的身份是否属于目标个体,为 VIP 用户提供个性化的伪造检测,并给出以用户为中心的解释。此外,在推理过程中,我们可以为每个用户替换相应的 VIP 令牌 µ ,从而在不重新训练模型的情况下,高效准确地检测恶意面部伪造。这种设计支持轻量级和可扩展的部署。
5.实验
本节通过系列实验验证方法有效性:针对通用深度伪造检测器,采用标准数据集训练的模型;针对身份识别检测器,则基于每位VIP用户20-30张真实图像数据。具体实验参数详见补充材料。
评价指标
在评估环节,我们采用三项标准指标:曲线下面积(AUC)、等错误率(EER)和准确率(ACC)。其中,AUC用于衡量模型在不同阈值下区分正负类别的能力;EER表示误接受率与误拒绝率相等的临界点;ACC则反映正确预测的比例。我们参照文献[74,77]的方法,通过AUC和EER来对比本方法的性能。此外,还采用ACC指标与基于API的商业生成器(如GPT-4o4[48])进行性能对比。
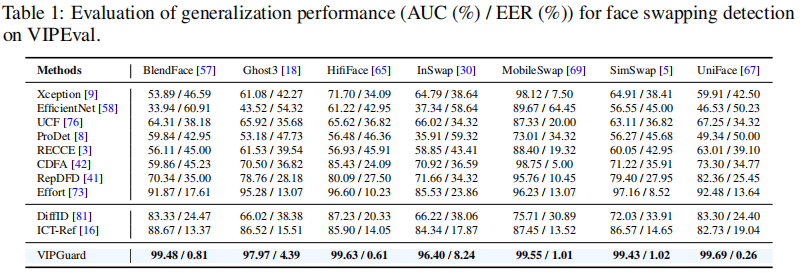
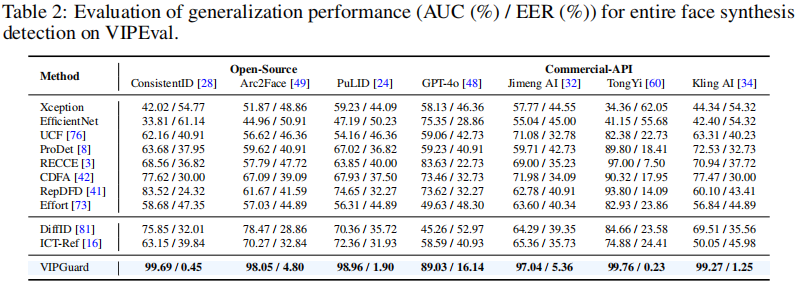
基于VIPEval数据集的Deepfake检测方法对比研究
我们在VIPEval数据集上评估了通用深度伪造检测器、身份识别检测器及我们提出的方法,分别报告了面部替换检测(表1)和完整人脸合成检测(表2)的结果。我们的方法显著提升了所有类型面部伪造的检测效果。通用深度伪造检测器(如Effort[73])在面部替换检测中表现优异,但由于未见过的伪影,无法有效识别商业API生成的更逼真伪造内容。与依赖低级特征的通用检测器不同,身份识别检测器通过利用身份相关的语义一致性,在不同生成技术和数据中实现稳健检测。然而,现有身份识别方法(如DiffID、ICT-Ref)因依赖全局面部特征,在面对完全合成的人脸时表现欠佳,这一局限性随着伪造技术的升级而加剧。相比之下,VIP-Guard通过联合利用全局面部表征与局部属性分析,捕捉身份特定特征,使得仅凭少量真实照片就能在多种伪造手段下有效保护VIP用户。
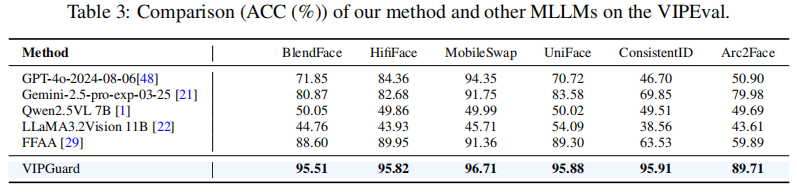
基于LLM的VIPEval方法与其他方法的比较
本实验通过比较多种基于
MLLM 的方法,包括专门用于人脸伪造检测的 MLLM FFAA
[29],以及简单的多模态大语言模型(MLLMs),评估了多模态大语言模型在VIPEval上的检测能力。由于API的输出是二元的(真实/伪造),检测性能使用准确率(ACC)进行衡量。如表3所示,我们的方法在所有伪造图像类型中均表现优于其他方法,证明了身份特定语义检测的有效性。
其他深度伪造检测数据集上的One-shot性能
本实验通过多个权威基准数据集,将我们的方法与现有多种身份识别感知方法进行对比评估。评估特别采用了具有挑战性的CelebDF[39]数据集及其相关子集DF40[74]。由于这些数据集中的真实样本多样性有限,我们采用单次样本设置进行测试,每个用户仅使用一张真实图像。为避免共享视频源导致的相似性问题,参考图像和测试图像均从不同视频中采样。如表4所示,我们的方法仍展现出与其他方法相当的性能优势。值得注意的是,由于真实图像资源有限,这些结果是在第二阶段使用VIP-Guard算法且省略第三阶段的情况下获得的。实验结果也验证了我们方法第二阶段的有效性。
6.结论
本文提出VIPGuard,通过利用已知面部特征实现个性化、精准且可解释的检测,填补了深度伪造检测领域的关键空白。与传统检测器主要依赖低级视觉特征或缺乏身份识别能力的通用多语言模型不同,VIPGuard通过统一的多模态框架整合了细粒度属性学习、身份级判别训练及用户专属定制功能。结合我们新提出的VIPBench测试平台(该平台可对多样化高级伪造类型进行严格评估),我们的方法在检测性能和可解释性方面均展现出显著优势,为保护高风险个体免受身份特征驱动的深度伪造攻击提供了稳健且可扩展的解决方案。