Image Copy-Move Forgery Detection via Deep PatchMatch and Pairwise Ranking Learning
Image Copy-Move Forgery Detection via Deep PatchMatch and Pairwise Ranking Learning
Yuanman Li, Senior Member, IEEE, Yingjie He, Student Member, IEEE, Changsheng Chen, Senior Member, IEEE, Li Dong, Bin Li, Senior Member, IEEE, Jiantao Zhou, Senior Member, IEEE, and Xia Li, Member, IEEE
摘要
深度学习算法的最新进展在图像复制-移动伪造检测(CMFD)方面取得了令人印象深刻的进展。然而,这些算法在实际场景中不存在复制区域在训练图像中,或克隆区域是背景的一部分,缺乏通用性。此外,这些算法利用卷积运算来区分源区域和目标区域,当目标区域与背景混合良好时,结果不理想。为了解决这些局限性,本研究提出了一种新的端到端CMFD框架,它集成了传统的和深度学习方法的优势。具体来说,该研究开发了一种深度跨尺度补丁匹配(PM)方法,该方法为CMFD定制,以定位复制移动区域。与现有的深度模型不同,我们的方法利用从高分辨率尺度中提取的特征来寻找源区域和目标区域之间的显式和可靠的点-拓扑匹配。此外,我们提出了一种新的成对秩学习框架来分离源区域和目标区域。通过利用点-点匹配的强先验,该框架可以识别细微的差异,有效地区分源区域和目标区域,即使目标区域与背景很好地融合。我们的框架是完全可微的,可以通过端到训练。全面的实验结果突出了我们的方案在各种复制移动场景中的显著通用性,显著优于现有的方法。
I.介绍
数字图像编辑工具的普及使得图像伪造在我们的日常生活中越来越普遍。这些被操纵的图片可以在网络谣言、保险欺诈、假新闻传播、甚至学术欺诈等活动中被恶意利用,给社会带来重大的安全问题。复制-移动伪造是一种普遍的操作形式,涉及到复制和重新定位图像中的对象,以改变其内容。检测这种伪造品具有挑战性,因为伪造区域和未接触区域之间的统计特征相似,包括噪声分布、亮度和光度性属性。
图像复制-移动伪造检测(CMFD)是多媒体安全领域的一个重要焦点。近年来,它见证了大量的研究努力,产生了各种被提出的方法。传统的CMFD技术利用手工制作的特性来识别复制-移动通信,包括基于块的方法[1]-[4]和基于关键点的方法[5]-[7]。虽然这些算法通过块或关键点匹配明确连接伪造的痕迹,提供了可信的结果,但它们依赖于为通用视觉任务定制的手工制作的特征,限制了它们对复杂的复制移动伪造和对后处理的敏感性的有效性。此外,这些传统的方法只检测对应关系,而不能区分源区域和目标区域。
受深度特征强大的表征能力的推动,近年来,对深度CMFD框架的研究出现了激增。Wu等人[8]引入了具有源/目标分离的开创性的端到端CMFD框架。与传统的方法不同,[8]利用卷积神经网络(CNNs)自适应地从CMFD数据集学习特征,避免了手工设计的需要。这一创新刺激了后续的深度CMFD模型的发展,包括[9]-[11],所有这些模型都利用了来自[8]的见解。有了这些具有代表性的特征,这些深度CMFD方法表现出更高的现实世界有效性和增强的对后处理的弹性。然而,尽管有这些优点,它们仍然表现出某些固有的限制,如下所述:
- 大多数现有的深度复制-移动伪造检测(CMFD)方法通过使用来自深度cnn的高级特征生成注意力地图来识别潜在的复制-移动区域。然而,正如我们将在我们的实验中验证的那样,这些特征经常与训练图像中的物体过度拟合,导致模型的通用性显著下降。因此,在训练数据中缺少复制移动元素的情况下,这些方法的效果较差。此外,当在后台发生复制-移动操作时,它们可能会完全失败。
- 与传统的方法相比,深度CMFD技术很难建立复制-移动对应的显式点对点匹配。因此,其检测结果的可解释性和可靠性受到了损害。
- 它们只是对整个输入图像进行卷积运算来进行源/目标分离,不能有效地利用源和目标区域之间的强点对点关系。因此,当目标区域与背景良好地融合时,它们往往无法分离源/目标区域。
为了应对上述挑战,我们提出了一个新的CMFD端到端CMFD框架,名为Deep PM和成对排名学习(D2PRL)。D2PRL结合了深度模型和传统技术的优势。首先,D2PRL专注于在高分辨率尺度上捕获源区域和目标区域之间的点对点匹配,增强其跨各种类型的复制移动内容的通用性。其次,D2PRL是完全可区分的,它可以通过端到端训练过程来学习特征。最后,D2PRL可以在强大的点匹配先验知识下有效地区分源/目标区域。我们的工作的主要贡献总结如下:
- 我们引入了一个创新的端到端深度CMFD框架,以源/目标分离为特色,利用了传统和现代深度CMFD模型的优势。我们的方法显著优于现有的算法,并展示了对各种复制-移动内容的非常鲁棒的通用性,包括对象和背景。
- 我们设计了一种基于为CMFD定制的深度跨尺度PM的细粒度相似度定位方法。此外,还开发了跨尺度匹配和多尺度密集拟合误差估计等技术,以寻求高分辨率尺度下源区域和目标区域之间可靠的点对点匹配。
- 通过利用点对点匹配的强先验,我们提出将区分源区域和目标区域的原始问题转换为成对排序问题。这种方法迫使网络发现微妙的线索来区分源区域和目标区域,即使目标区域与背景很好地融合。
本文的其余部分的结构如下:第二节提供了相关工作的简要回顾,而第四节则详细阐述了我们的CMFD框架。第五节介绍了广泛的实验结果和消融研究,第六节总结了本文。
II.相关工作
在本节中,我们将简要回顾相关的工作,包括现有的CMFD方法和PM算法。
A.图像复制移动伪造检测
B. 补丁匹配
III.问题公式
给定一个真实的图像,复制-移动伪造涉及到复制图像的一小部分并将其粘贴到同一图像中的不同位置的过程。该技术通常用于隐藏感兴趣的对象或复制图像中的对象。CMFD的目标是识别图像中发生复制移动伪造行为的区域。用于复制的图像的区域称为源区域,被复制区域所覆盖的区域称为目标区域。
根据CMFD是否区分源区域和目标区域,可以分为单通道CMFD和三通道CMFD。单通道CMFD可以看作是一个像素级的二值分类问题,其中每个像素被分类为属于背景或目标/源区域。另一方面,三通道CMFD建立在单通道CMFD的基础上,通过进一步区分源区域和目标区域,确定检测到的像素是来自源区域还是目标区域。根据惯例,我们定义了以下相关的面具
- \(M^{gt}\):地真单通道掩模,其中背景区域用0表示,而源区域和目标区域的像素都被设置为1。
- \(M\):预测的单通道掩码,其中每个值反映了像素属于目标/源区域的概率。
- \(M^{gt}_c\):地面真实三通道掩码,其中背景区域用[0 0 1](蓝色)表示,源区域用[0 1 0]表示(绿色),目标区域用[1 0 0](红色)表示。
- \(M_c\):预测的三通道掩码。
- \(M^{gt}_t\):目标区域的地面真值掩码,其中目标区域中的像素为1,其他像素为0。
- \(M_t\):目标区域的预测掩模。
IV.是我们所提出的算法的框架。
在本节中,我们将讨论我们提出的通过深度PM和成对排序学习的CMFD方法。
A. D2PRL概述
如图1所示,我们的方法的框架有两个主要分支:
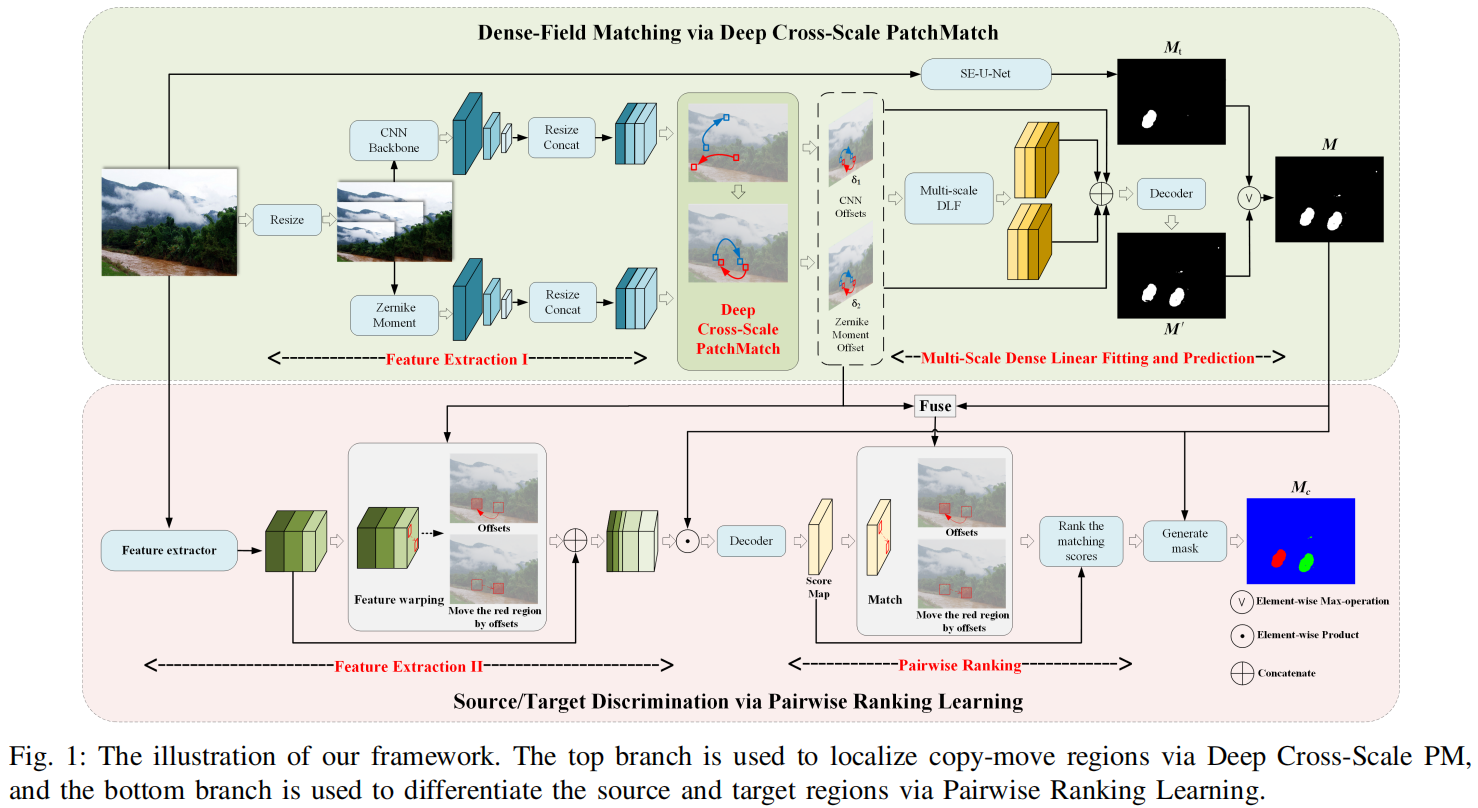
通过深度交叉尺度PM进行的密集场匹配(DFM,Dense-Field Matching via Deep Cross-Scale PM):
该分支的目的是通过密集场匹配来定位复制移动区域。通过采用设计的深度跨尺度PM算法,我们的方法利用高分辨率尺度的特征,寻求源区域和目标区域之间明确和可靠的点对点匹配。与以往的深度CMFD方法相比,我们的检测框架对各种复制移动内容具有很高的通用性,包括对象、不完整对象和背景。
通过成对排名学习而产生的来源/目标歧视(STD,Source/Target Discrimination via Pairwise Ranking Learning):
该分支利用密集场匹配的强先验知识来区分源区域和目标区域。在匹配信息的基础上,将原始识别问题转换成两两排序问题,这使得网络即使目标区域与背景很吻合,网络也能揭示识别源区域和目标区域的细微线索。
B. 通过深度交叉尺度PM进行的密集场匹配(DFM,Dense-Field Matching via Deep Cross-Scale PM)
对点关系是图像复制移动伪造检测和定位的关键线索,在传统的CMFD算法中进行可靠决策方面得到了广泛的研究。然而,由于巨大的样本空间,传统方法的匹配过程要么不可微,要么高度复杂,排除了它们在现代深度学习框架中的使用。因此,大多数现有的深度CMFD算法[8]、[10]、[11]基于特征点之间的成对相关性计算注意力图,以呈现复制移动补丁的可能性,只使用来自非常小的特征图的高级特征。正如我们的实验将证明的那样,这可能使它们容易对训练图像中的物体进行过拟合。
与以往的工作不同,我们的DFM分支通过使用高分辨率特征图的点对点匹配来识别复制移动区域,有效地结合了深度模型和传统模型的优点。如图1的上图所示,DFM分支由三个方块组成,即1)特征提取、2)交叉尺度匹配和3)误差拟合和预测。