Image as Set of Points

Image as Set of Points
Xu Ma1∗ , Yuqian Zhou2∗ ,
Huan Wang1 , Can Qin1 , Bin
Sun1 , Chang Liu1 , Yun
Fu1
1东北大学
2Adobe Inc.
摘要
什么是图像,如何提取潜在的特征?
卷积网络
(ConvNets)将图像视为矩形的有组织的像素,并通过局部区域的卷积操作提取特征;Vision
Transformers(ViTs)视觉变压器(ViTs)将图像视为一系列补丁,并通过注意机制在全局范围内提取特征。在这项工作中,我们引入了一个直接而有前途的视觉表示范式,它称为Context
Clusters。上下文聚类(CoCs,Context
clusters)将图像视为一组无组织的点,并通过简化的聚类算法提取特征。具体地说,每个点都包括原始特征(如颜色)和位置信息(如坐标),并采用简化的聚类算法对深度特征进行分层分组和提取。我们的CoCs是无卷积和无注意的,并且只依赖于聚类算法来进行空间交互。由于简单的设计,我们通过聚类过程的可视化展示了CoCs赋予了令人满意的可解释性。我们的CoCs旨在为图像和视觉表示提供一个新的视角,这可能在不同的领域享有广泛的应用,并表现出深刻的见解。即使我们没有针对SOTA的性能,COCs仍然在几个基准测试上可以取得比ConvNets或ViTs相当甚至更好的结果。
代码可获得:
https://github.com/ma-xu/Context-Cluster。
1介绍
我们提取特征的方式在很大程度上取决于我们如何解释图像。作为一种基本范式,卷积神经网络(ConvNets)近年来主导了计算机视觉领域,并显著提高了各种视觉任务的性能(He
et al., 2016;Xie et al., 2021; Ge et al.,
2021)。从方法论上讲,卷积网络将图片概念化为矩形形式的排列像素的集合,并以滑动窗口的方式使用卷积提取局部特征。受益于一些重要的归纳偏差,如局部性和翻译等价性,卷积网络被证明是高效和有效的。最近,Vision
Transformers(ViTs)显著挑战了卷积神经网络在视觉领域的霸权。Transformers
(Vaswani et al.,
2017)从语言处理中得出,将图像视为一系列补丁,并采用全局范围的自关注操作来自适应地融合补丁中的信息。通过所得到的模型(即ViTs),卷积神经网络中固有的归纳偏差被抛弃,并获得了令人满意的结果(Touvron
et al.,
2021)。
最近的研究表明,视觉社区有了巨大的进步,这些进步主要建立在卷积或注意力的基础上
(e.g., ConvNeXt (Liu et al., 2022), MAE (He et al., 2022), and
CLIP (Radford et al.,
2021))。同时,一些尝试将卷积和注意力结合在一起,如CMT (Guo et al.,
2022a)和CoAtNet (Dai et al.,
2021)。这些方法在网格中扫描图像(卷积),同时探索序列的相互关系(注意力),在不牺牲全局接收(注意力)的情况下享受局部先验(卷积)。虽然它们继承了两者的优点并实现了更好的实证性能,但见解和知识仍然局限于卷积神经网络和ViTs。我们强调,除了卷积和关注之外,一些特征提取器也值得研究,而不是被引诱到追求增量改进的陷阱中。虽然卷积和注意力被认为具有显著的好处,并对视野产生巨大的影响,但它们并不是唯一的选择。基于MLP的架构(Touvron
et al., 2022; Tolstikhin et al.,
2021)已经证明,纯基于MLP的设计也可以实现类似的性能。
在这项工作中,我们回顾了基本视觉表示的经典算法,聚类方法
(Bishop & Nasrabadi,
2006)。整体地说,我们将图像视为一组数据点,并将所有点分组到集群中。在每个集群中,我们将这些点聚合到一个中心中,然后自适应地将这些中心点分配到所有的点上。我们称之为设计上下文集群。图1说明了这个过程。
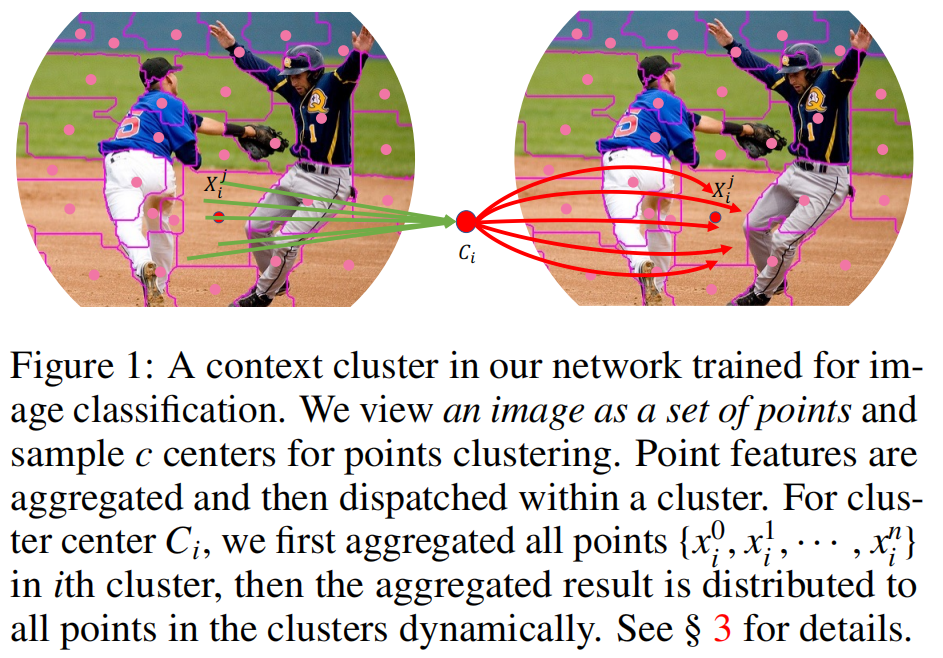
具体来说,我们将每个像素视为一个具有颜色和位置信息的5维数据点。在某种意义上,我们将图像转换为一组点云,并利用点云分析的方法
(Qi et al., 2017b; Ma et
al.,2022)进行图像视觉表示学习。这连接了图像和点云的表示,显示了很强的泛化,并为多模式的简单融合打开了可能性。利用一组点,我们引入了一种简化的聚类方法来将这些点进行聚类。聚类处理与超级像素像素SuperPixel
(Ren &
Malik,2003)有相似的想法,其中相似的像素被分组,但它们在本质上是不同的。据我们所知,我们是第一个引入一般视觉表示的聚类方法并使其工作的人。相反,超级像素及以后版本主要用于图像预处理(Jampanani等人,2018)或语义分割等特定任务(Yang等人,2020;Yu等人,2022b)。
我们基于上下文集群实例化我们的深度网络,并将生成的模型命名为上下文集群(CoCs)。我们的新设计与ConvNets或ViTs有本质上的不同,但我们也从它们那里继承了一些积极的哲学,包括来自ConvNets的层次表示(Liu等人,2022),以及来自ViTs的元代表(Yu等人,2022c)框架。CoCs具有明显的优势。首先,通过将图像作为一组点来考虑,CoCs对点云、RGBD图像等不同的数据域表现出了很强的泛化能力。其次,上下文聚类处理为CoCs提供了令人满意的可解释性。通过可视化每一层的聚类,我们可以明确地理解每一层的学习。尽管我们的方法没有针对SOTA的性能,但在几个基准测试上,它仍然取得了比ConvNets或ViTs相当甚至更好的性能。我们希望我们的上下文聚类将为视觉社区带来新的突破。
2相关工作
2.1图像处理中的聚类
虽然图像处理中的聚类方法(Castleman,1996)在深度学习时代已经失宠,但它们从未从计算机视觉中消失。一个历史悠久的作品是SuperPixel (Ren & Malik, 2003),它通过将一组具有共同特征的像素分组,将图像分割成区域。由于所期望的稀疏性和简单表示,SuperPixel已成为图像预处理的常见做法。在整个图像上简单地应用超级像素穷尽集群(例如,通过K-means算法)像素,使得计算成本沉重。为此,SLIC(Achanta et al.,2012)限制了局部区域的聚类操作,并均匀地初始化K-means中心,以更好更快地收敛。近年来,聚类方法的兴趣激增,并与深度网络紧密相关(Li & Chen,2015年;Jampani等,2018年;秦等,2018年;Yang等,2020年)。为了创建深度网络的超像素,SSN(Jampani et al.,2018)提出了一种可微的SLIC方法,该方法是端到端可训练,具有良好的运行时间。最近,人们尝试将聚类方法应用于网络的特定视觉任务,如分割(Yu et al.,2022b;Xu et al.,2022)和细粒度识别(Huang & Li,2020)。例如,CMT-DeepLab(Yu et al.,2022a)将分割任务中的对象查询解释为集群中心,并将分组的像素分配给每个集群的分割。然而,据我们所知,目前还没有通过聚类进行一般视觉表示的工作。我们的目的是弥补这个空缺,并在数值和视觉上证明其可行性。
2.2ConvNets & ViTs
自深度学习时代以来,ConvNets就一直主导着视觉社区(西蒙尼扬和齐瑟曼,2015年;He等人,2016年)。最近,ViTs(多索维茨基等人,2020年)将视觉社区引入了纯基于注意力的变压器(Vaswani等人,2017年),并在各种视觉任务上设置了新的SOTA性能。一个常见而合理的猜想是,这些令人满意的成就被归功于自我注意机制。然而,这个直观的猜想很快就受到了挑战。大量的实验也表明,ResNet(He等人,2016年)可以通过适当的训练配方和最小的修改,达到同等甚至更好的性能(怀特曼等人,2021年;Liu等人,2022年)。我们强调,虽然卷积和注意力可能具有独特的优点(即网络具有归纳偏差(Liu et al.,2022),而vit擅长泛化(Yuan et al.,2021b)),但它们没有显示出显著的性能差距。与卷积和注意不同,在这项工作中,我们从根本上提出了一个新的范式的视觉表示使用聚类算法。通过定量和定性分析,我们表明,我们的方法可以作为一个新的一般主干,并具有令人满意的可解释性。
2.3最近的进展
在ConvNets和ViTs的框架内,视觉任务的表现得到了广泛的努力(Liu等,2021b;丁等,2022b;Wu等,2021)。为了同时利用卷积和注意力,一些工作学习在混合模式下混合这两种设计,如CoAtNet(Dai等人,2021)和移动前者(Chen等人,2022b)。我们还注意到,一些最近的进展探索了更多的视觉表示方法,超出了卷积和注意力。类MLP模型(托尔斯蒂金等人,2021年;Touvron等人,2022年;侯等人,2022年;Chen等人,2022a)直接考虑空间交互作用的MLP层。此外,一些工作采用了转移(Lian等人,2021;Huang等人,2021)或汇集(Yu et al.,2022c)来进行本地交流。与我们将图像视为无序数据集的工作类似,Vision GNN(ViG)(Han et al.,2022)为视觉任务提取图级特征。不同的是,我们直接应用传统图像处理的聚类方法,表现出良好的泛化能力和可解释性。
3方法
上下文聚类放弃了时尚的卷积或注意力,而考虑经典算法聚类,为视觉学习的表示。在本节中,我们首先描述上下文集群管道。然后详细解释了所提出的特征提取的上下文聚类操作(如图二所示)。
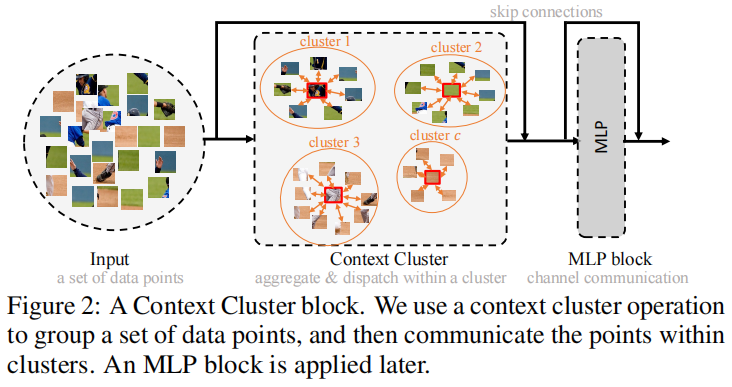
之后,我们建立了上下文集群架构。最后,一些公开的讨论可能会帮助个人理解我们的工作,并根据我们的上下文集群探索更多的方向。
3.1上下文集群管道
3.1.1从图像到点集
给定一个输入图像\({\textbf{I}}\in{\mathbb{R}}^{3\times w\times
h}\),我们首先用每个像素\(\operatorname{I}_{i,j}\)的二维坐标增强图像,其中每个像素的坐标表示为\([{\frac{i}{w}}-0.5,{\frac{j}{h}}-0.5]\)。进一步研究位置增强技术以潜在地提高性能是可行的。这种设计是考虑到其简单性和实用性。然后将增强的图像转换为一个点的集合(即像素)\(\mathbf{P}\in\mathbb{R}^{5 \times
n}\),其中,\(n=w\times
h\)是点的数量,每个点同时包含特征(颜色)和位置(坐标)信息;因此,点集可以是无序和杂乱无章的。
我们通过提供一个新的图像视角,一组点来获得优秀的泛化能力。一组数据点可以被认为是一种通用的数据表示,因为大多数领域中的数据可以作为特征和位置信息(或两者中的任何一种)的组合给出。这激励我们将一个图像概念化为一组点。
3.1.2使用图像设置点的特征提取
根据ConvNets方法(He等人,2016;Liu等人,2022年),我们使用上下文聚类块(参考见图2,解释见图3.2)分层提取深度特征。图3显示了我们的上下文集群架构。
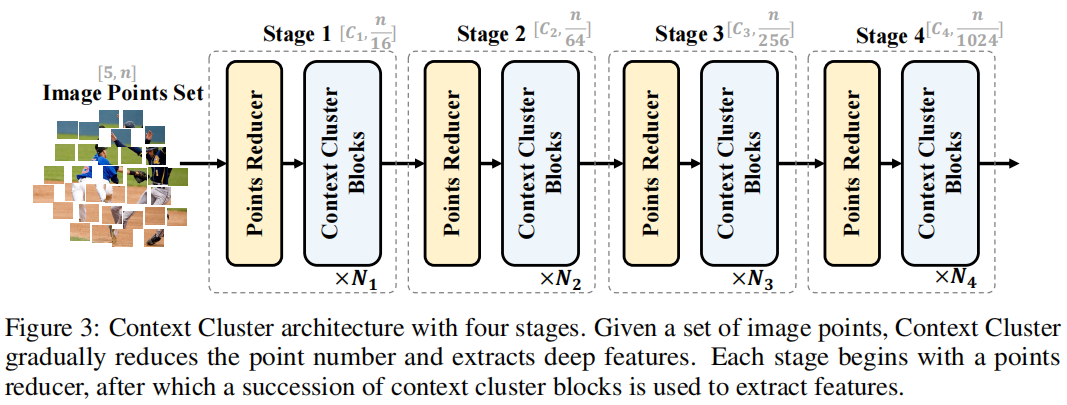
给定一组点\(\mathbf{P}\in\mathbb{R}^{5 \times n}\),我们首先降低点数以提高计算效率,然后应用一系列的上下文聚类块来提取特征。为了减少点数,我们在空间中均匀地选择一些锚点,并将最近的k个点通过线性投影进行连接和融合。请注意,如果所有点按顺序排列,并且k正确设置(即4和9),这种缩减可以通过卷积操作来实现,就像ViT(Dosovitskiy等人,2020)。为了明确前面所述的中心和锚点,我们强烈建议读者查看附录B。
3.1.3任务特定的程序
对于分类,我们对最后一个块输出的所有点进行平均,并使用FC层进行分类。对于下游的检测和分割等密集预测任务,我们需要在每个阶段后按位置重新排列输出点,以满足大多数检测和分割头的需求(如Mask-RCNN(He et al.,2017))。也就是说,上下文集群在分类方面提供了显著的灵活性,但仅限于在密集预测任务的需求和我们的模型配置之间的折衷。我们期望创新的检测和分割头(如DETR(Carion et al.,2020))能够与我们的方法无缝集成。
3.2上下文集群操作
在本小节中,我们将介绍我们工作中的关键贡献——上下文集群操作。整体上,我们首先将特征点分组到聚类中;然后,将每个集群中的特征点进行聚合,然后发回,如图1所示。
3.2.1上下文聚类
给定一组特征点\(\mathbf{P}\in\mathbb{R}^{n \times d}\),我们根据相似性将所有的点分成几个组,每个点被单独分配给一个簇。我们首先将\(\mathbf{P}\)线性投影到\(\mathbf{P}_s\)来进行相似性计算。根据传统的超像素方法SLIC(Achanta et al.,2012),我们均匀地提出了空间中的c个中心,并通过平均其k个最近点来计算中心特征。然后我们计算了在\(\mathbf{P}_s\)和所得到中心点集之间的成对余弦相似度矩阵\(\mathbf{S}\in\mathbb{R}^{c \times n}\)。由于每个点同时包含特征信息和位置信息,因此在计算相似性时,我们隐式地突出了这些点的距离(局部性)和特征相似性。之后,我们将每个点分配到最相似的中心,从而得到c个集群。值得注意的是,每个集群可能有不同数量的点。在极端情况下,一些集群可能有零点,在这种情况下,它们是冗余的。
3.2.2特征聚合
我们根据与中心点的相似性动态地聚合集群中的所有点。假设一个簇包含m个点(P中的一个子集),m个点与中心的相似度为\(s\in\mathbb{R}^{m}\)(S中的一个子集),我们将这些点映射到一个值空间,得到\(P_{\nu}\in\mathbb{R}^{m\times
d^{\prime}}\),其中\(d^{\prime}\)是值维数。我们还提出了一个在价值空间中的中心vc,如聚类中心方案。聚合特征\(g\in\mathbb{R}^{d}\)由: \[g={\frac{1}{C}}\left(\nu_{c}+\sum_{i=1}^{m}\mathrm\,(\alpha
s_{i}+\beta)*\nu_{i}\right),\qquad{\mathrm{s.t.}},\;\;C=1+\sum_{i=1}^{m}\mathrm\,(\alpha
s_{i}+\beta)\,.\]
在这里,α和β是可学习的标量来缩放和移动相似度,而sig(·)是一个s型函数来重新缩放相似度到(0,1)。\(\nu_{i}\)表示\(P_{\nu}\)中的第i个点。根据经验,这种策略将比直接应用原始相似性获得更好的结果,因为没有涉及负值。Softmax不被考虑,因为这些点之间并不相互矛盾。我们在等式1中加入了价值中心vc为数值稳定性\(^1\)以及进一步强调的局部性。为了控制大小,聚合特征归一化为\(C\)。
(1如果没有涉及到vc,也没有任何点被同时分组到集群中,那么C将为零,网络就不能被优化。在我们的研究中,这个难题经常发生。添加一个像1e−5这样的小值并没有帮助,并且会导致梯度消失的问题。)
3.2.3特征处理
然后,聚合的特征g根据相似性自适应地分配到集群中的每个点。通过这样做,这些点可以相互通信,并共享来自集群中所有点的特征,如图1所示。对于每个点pi,我们更新它 \[p_{i}^{\prime}=p_{i}+\mathrm{FC}\left(\mathrm{sig}\left(\alpha S_{i}+\beta\right)*g\right).\] 在这里,我们遵循相同的过程来处理相似性,并应用一个全连接(FC)层来匹配特征维度(从值空间维度\(d^{\prime}\)到原始维度d)。
3.2.3多头计算
我们承认自我注意机制中的多头设计(Vaswani et al.,2017),并使用它来增强我们的上下文集群。为了简单起见,我们考虑h头,并将值空间Pv和相似度空间Ps的维数设为\(d^{\prime}\)。多头操作的输出由一个FC层连接和融合。正如我们通过经验证明的那样,多头体系结构也有助于上下文集群的令人满意的改进。
3.3架构初始化
虽然上下文集群从根本上不同于卷积和关注,但来自ConvNets和vit的设计理念,如层次表示和元变压器架构(Yu
et
al.,2022c),仍然适用于上下文集群。为了与其他网络对齐,并使我们的方法与大多数检测和分割算法兼容,我们在每个阶段逐步减少点数16、4、4和4倍。在第一阶段,我们考虑了选定锚点的16个最近邻,在其余阶段,我们选择了它们的9个最近邻。
一个潜在的问题是计算效率。假设我们有n个d维点和c个聚类,计算特征相似度的时间复杂度为O(ncd),当输入图像分辨率较高时,这是不可接受的(例如,224×224)。为了解决这个问题,我们引入了区域划分,将点分割成几个局部区域,如SwinTransformer(Liu
et
al.,2021b),并计算局部相似度。因此,当局部区域的数量设置为r时,我们显著地将时间复杂度降低了r的因子,从O(ncd)到\(O\left(r{\frac{n}{r}}{\frac{c}{r}}d\right)\)。详细配置见附录A。请注意,如果我们将点集分割到几个局部区域,我们将限制上下文集群的接受域,并且局部区域之间没有可用的通信。
3.4讨论
3.4.1集群的固定中心还是动态中心?
传统的聚类算法和超像素技术都是迭代地更新中心直到收敛。然而,当集群被用作每个构建块中的关键组件时,这将导致过高的计算成本。推理时间将呈指数级增长。在上下文集群中,我们将固定中心视为推理效率的一种替代方案,这可以被认为是准确性和速度之间的一种折衷方案。
3.4.2是重叠的还是不重叠的集群?
我们只将点分配到一个特定的中心,这不同于以前的点云分析设计理念。我们有意地坚持传统的聚类方法(非重叠聚类),因为我们想证明简单和传统的算法可以作为一个通用的主干。尽管重叠聚类可能会产生更高的性能,但重叠聚类对我们的方法并不是必需的,而且可能会导致额外的计算负担。
4实验
我们验证了ImageNet-1K (Deng et al., 2009), ScanObjectNN (Uy et al.,
2019), MS COCO (Lin et al., 2014), 和ADE20k (Zhou et al.,
2017)数据集,用于图像分类、点云分类、目标检测、实例分割和语义分割任务。
即使我们没有追求像ConvNeXt
(Liu et al., 2022) 和DaViT (Ding et al.,
2022a)那样的最先进的性能,上下文集群仍然在所有任务上都显示出有希望的结果。详细的研究证明了我们的上下文集群的可解释性和泛化能力。
4.1在ImageNet-1K上的图像分类
4.2聚类可视化
4.3扫描对象网络上的三维点云分类
4.4MS-COCO上的对象检测和实例分割
4.5ADE20K上的语义分割
5结论
我们引入了上下文集群,一种新的特征提取范式的视觉表示。受点云分析和超像素算法的启发,我们将图像视为一组无组织的点,并采用简化的聚类方法来提取特征。在图像解释和特征提取操作方面,上下文集群与ConvNets和vit有根本上的区别,并且在我们的架构中不涉及卷积或关注。我们展示了我们的上下文集群可以在多个任务和域上获得与ConvNet和ViT基线相当甚至更好的结果,而不是追求SOTA的性能。最值得注意的是,我们的方法显示出了很好的可解释性和泛化特性。我们希望我们的上下文集群除了具有卷积和注意力外,还可以作为一种新的视觉表示方法。
正如结尾的附录3所讨论的,我们的视觉表示的新视角和设计也带来了新的挑战,主要是在准确性和速度之间的妥协。更好的策略值得探索。脱离当前的检测和分割框架,将我们的上下文聚类哲学应用于其他任务,也是一个值得追求的方向。
6代码结构
6.1.总体架构

其中forward_embeddings的作用是将位置信息嵌入,然后进行降维,forward_tokens的作用是聚类,然后基于聚类结果进行特征融合。
6.2.forward_embeddings
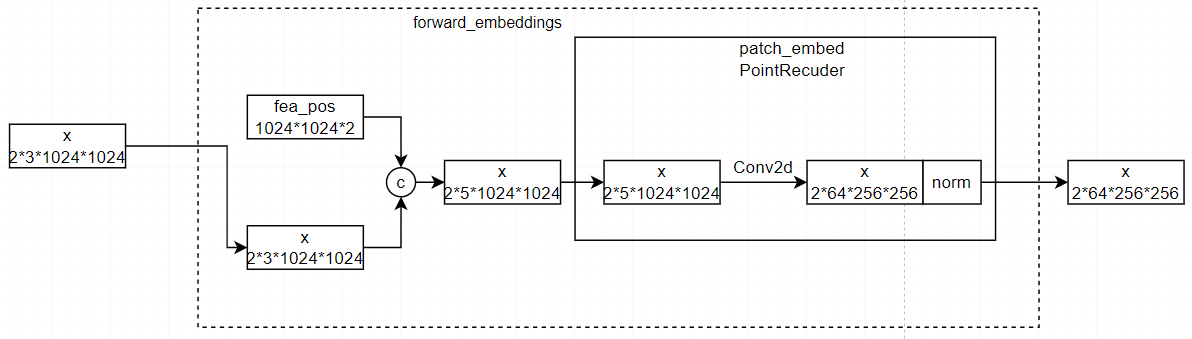
RGB三维加上横向竖向的两维,总共五维,作为输入,然后使用卷积,降低分辨率,即降低要聚类的点:由1024*1024个点降为256*256个点。
6.3.forward_tokens
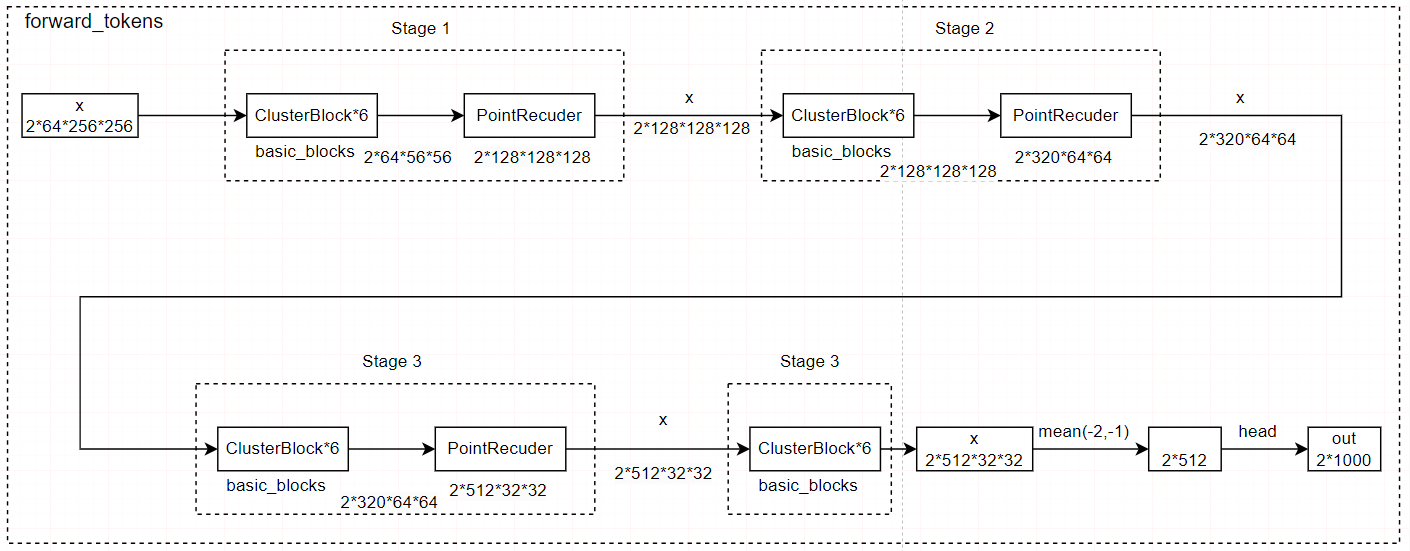
forward_tokens的作用是聚类,然后基于聚类结果进行特征融合,具体而言,其在不同的尺度上进行聚类块的操作,以保证聚类引导结果。其使用PointRecuder降低分辨率。
6.3.1.ClusterBlock
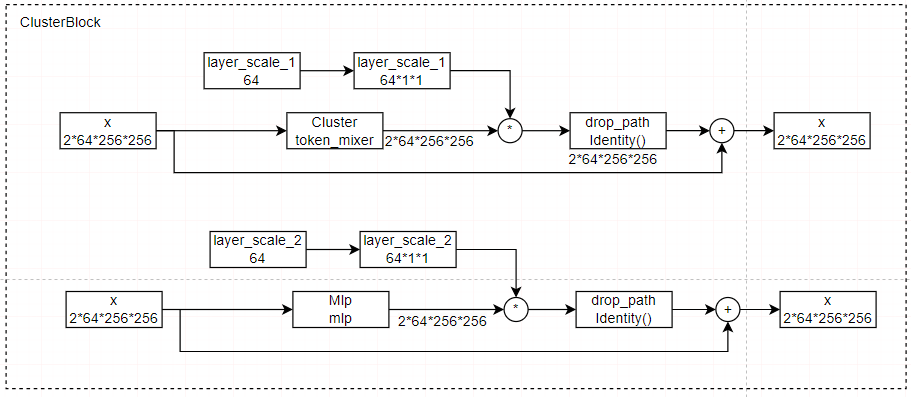
这里只展示第一个stage下的ClusterBlock模块,具体而言,首先使用Cluster模块进行聚类,与可学习的权重相乘再与原来的相加,随后使用MLP层,与可学习的权重相乘再与原来的相加。
6.3.2.ClusterBlock中的Cluster模块
聚类模块是这篇论文的重点,其是将一个空间的聚类结果指导另一个空间的计算,其大致如下:
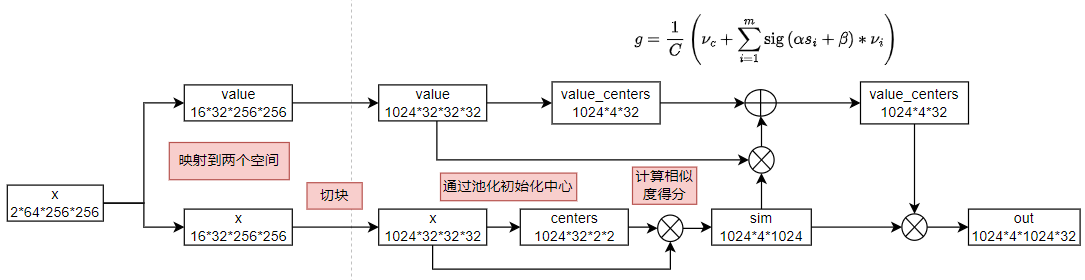
我们首先将这些点映射到一个点空间\(\mathbf{P}_s\)和一个值空间\(\mathbf{P}_{\nu}\),其中\(\mathbf{P}_s\)来进行相似性计算。

然后使用了区域划分,将点分割成64个局部区域,通过池化操作,得到初始化的中心。
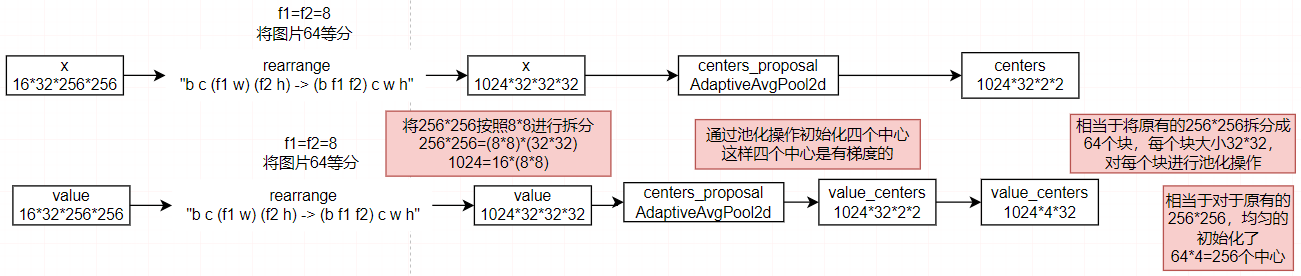
然后计算局部相似度。
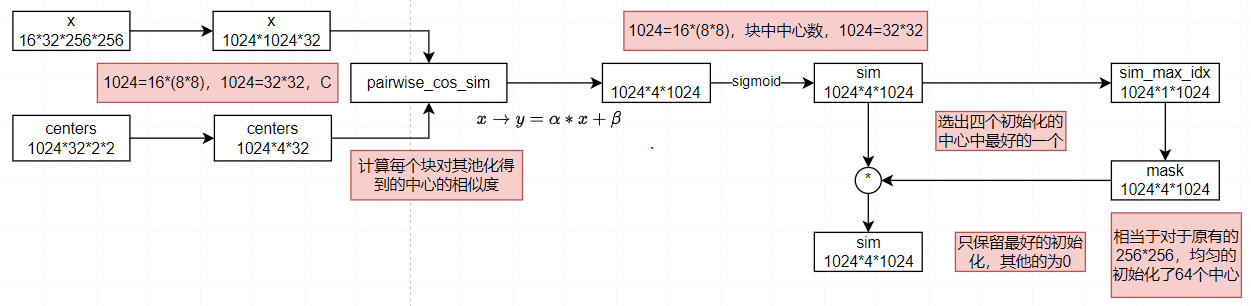
其中创建掩膜并应用是指如下,这样每个点就被分到一个类下。
# we use mask to sololy assign each point to one center |
然后是将特征聚合,按照公式融合特征。
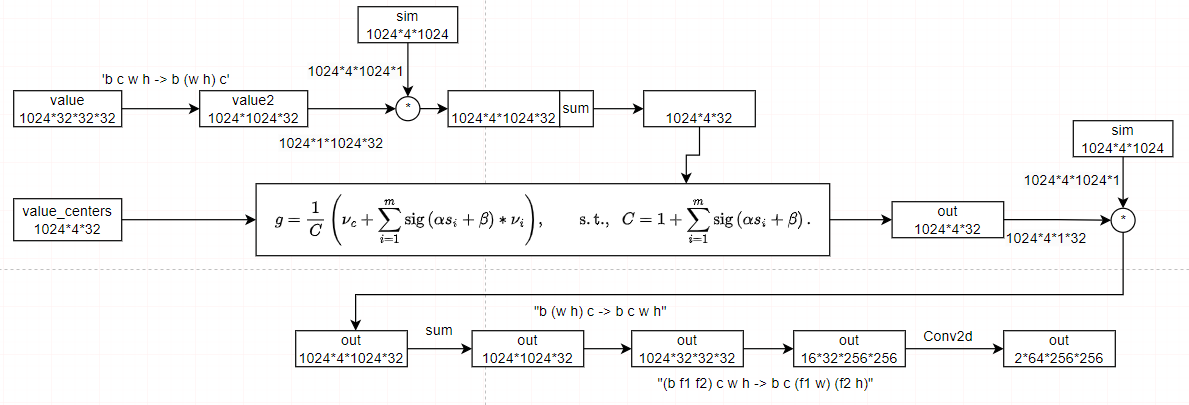
最后得到输出结果。
6.3.3.ClusterBlock中的MLP模块
class Mlp(nn.Module): |
MLP就是线性层、激活函数和dropout层构成。
6.3.4.PointRecuder层
PointRecuder是由卷积层构成,kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)。
6.3.5.各个stage下的设置

7基于此论文的改进论文
7.1 ClusterFomer
发表于A类会议,NeurIPS,2023,其解析为clusterformer,该模型包含两个创新设计:①循环交叉注意力聚类,重新定义了TransFORMER中的交叉注意力机制,通过递归更新聚类中心,促进强大的表示学习;②特征调度,利用更新后的聚类中心,通过基于相似性的度量重新分配图像特征,形成一个透明的处理流程。
代码层面,其改进了ClusterBlock中的Cluster模块。
7.2 FEC
发表于A类会议,CVPR,2024,其解析为Neural Clustering based Visual Representation Learning,FEC算法通过两种交替操作实现:首先将像素分组为独立簇以提取抽象特征,随后利用当前特征向量更新像素的深度特征。这种迭代机制通过多层神经网络实现,最终生成的特征向量可直接应用于下游任务。各层间的聚类分配过程可供人工观察验证,使得FEC的前向计算过程完全透明化,并赋予其出色的自适应可解释性。