Imbalance-Aware Discriminative Clustering for Unsupervised Semantic Segmentation

Imbalance-Aware Discriminative Clustering for Unsupervised Semantic Segmentation
Mingyuan Liu1,2 · Jicong Zhang1 · Wei Tang2
摘要
无监督语义分割(USS)旨在通过学习未标注图像集合,将图像划分为具有语义意义的片段。当前方法的有效性受到表征学习与像素聚类协调、不同类别特征分布建模、异常值与噪声处理以及像素类别不平衡问题等挑战的困扰。
本文提出了一种名为“不平衡感知密集判别聚类(IDDC,Imbalance-Aware
Dense Discriminative
Clustering)”的创新方法,为USS提供了一个统一框架来解决上述难题。与现有方法分阶段学习伪掩码生成与更新、嵌入优化与聚类等步骤不同,IDDC通过新颖的目标函数实现了端到端自监督学习——该目标函数将视觉Transformer(ViT)嵌入空间中的像素流形结构迁移至标签空间,同时有效抑制像素亲和度中的噪声干扰。
在推理过程中,训练好的模型会直接输出基于图像条件的每个像素分类概率。
此外,本文提出了一种基于Weibull
function的新正则化方法,用于处理单次训练中的像素类别不平衡和聚类退化问题。实验结果表明,IDDC在COCO-Stuff-27、COCO-Stuff-171和Cityscapes三个真实数据集上的表现显著优于所有先前的USS方法。大量消融研究验证了各设计的有效性。我们的代码可在https://github.com/MY-LIU100101/IDDC
平台获取。
1.引言
USS旨在从未标注图像集合中学习语义分割。该方法无需依赖任何形式的人工标注,不仅大幅降低了标注成本,还能轻松应用于新数据或新应用场景。此外,USS还能发现先验未知的新型视觉模式与结构(Cho et al., 2021),这对分析新兴领域的图像具有重要价值。尽管其重要性不言而喻,但由于缺乏语义监督、类别内差异显著以及严重类别不平衡等问题,USS仍是一个极具挑战性的课题。
现有方法通常采用两阶段学习框架来处理超大规模数据集(USS)。这些方法可分为两大类:
第一类通过K均值算法对预训练模型的像素嵌入进行聚类生成伪标签,随后迭代优化分割结果(Caron et al., 2018; Cho et al., 2021; Gao et al., 2022; Yin et al., 2022)。但这类方法的性能容易受到初始生成伪掩码的影响。此外,如何确定两阶段交替处理的频率也颇具挑战:若频繁更换伪标签会干扰特征学习过程并导致结果不稳定(Zhan et al., 2020),而若更新速度过慢又会使特征学习过度拟合初始标签猜测。
第二类方法以STEGO(Hamilton et al., 2022)为代表,其核心思路是先学习低维且适合聚类的像素嵌入特征,再通过USS(Li et al., 2023; Melas-Kyriazi et al., 2022; Pang et al., 2022; Seong et al., 2023; Van Gansbeke et al., 2021;Zadaianchuk et al., 2022; Ziegler & Asano, 2022)将像素嵌入特征进行聚类分组。但这种方法存在若干局限性。
- 首先,特征学习与像素聚类过程被割裂开来,而非采用端到端的同步训练方式(即所有模块并非同时进行优化)。由于特征学习完全不考虑后续聚类任务的具体目标(包括聚类数量和目标函数),模型优化可能无法达到最佳的聚类效果。
2. 其次,聚类算法(最常用的是K均值算法)具有生成性特征,对聚类形态存在较强假设。相较于判别式聚类方法(Ng和Jordan,2001),它在处理高维特征时表现欠佳且易受异常值干扰。
3. 最后,在超声图像分割(USS)中,严重的像素类别不平衡问题往往被忽视。直接将表征学习与聚类方法结合常导致退化解:部分聚类为空(Caron et al., 2018; Ji et al., 2019)。一种直接的解决方案(Ji et al., 2019; Krause et al., 2010; Van Gansbeke et al., 2020)是强制要求类别标签均匀分布,但这与实际像素高度偏斜的类别分布存在矛盾。
本文提出了一种名为ImbalanceAware密集判别式聚类(IDDC)的新型方法,用于解决USS问题。该方法在一个统一框架下解决了上述所有限制。
首先,IDDC的独特之处在于其判别式设计,能够直接输出基于输入图像的像素级分类概率。与广泛使用的K均值算法不同,IDDC无需预设聚类的生成分布或形态特征。因此,该方法能更灵活地处理不同类别和数据集的特征分布差异,对异常值更具鲁棒性,并能在高维特征空间中实现更精准的像素分类。
其次,IDDC通过一种创新的目标函数,以端到端和自监督的方式学习像素级特征表示与密集判别聚类。该目标函数将视觉Transformer(ViT)嵌入空间中的像素流形结构迁移至标签空间。IDDC实现了表征学习与像素聚类的无缝衔接,无需经过生成伪标签、更新伪标签或学习降维且适合聚类的嵌入等中间学习目标。
最后但同样重要的是,IDDC引入了一种基于Weibull
函数(Murthy等人,2004年)的新型正则化器,可在单次操作中有效处理像素类别失衡和聚类退化问题。熵值作为深度聚类方法中的常用指标(Barber
& Agakov, 2005; Bridle et al., 1991;Krause et al., 2010; Van
Gansbeke et al.,
2020),通过促进像素均匀分配到各聚类来避免空聚类现象。然而现实世界中物体大小差异显著、出现频率各异,导致像素类别分布呈现严重偏态。我们将证明,这种新型正则化器不仅能精准建模偏态分布,还能有效规避空聚类问题。
我们的贡献总结如下:
- 我们提出了一种名为“不平衡感知密集判别聚类(IDDC)”的创新方法,专门针对图像超尺度聚类(USS)任务。该方法通过直接从图像中预测像素级分类概率,以判别式、端到端且自监督的方式联合学习密集特征表示与像素标签。相较于现有USS方法普遍采用的两阶段学习框架和生成式聚类技术,IDDC有效解决了这些方法在表征学习与像素聚类协同处理、类别分布不平衡建模以及异常值处理等方面的不足。
- 我们设计了一种创新性目标函数,通过将ViT嵌入空间中像素的流形结构迁移至标签空间,有效实现了IDDC模型的学习。针对由不同类别像素在ViT嵌入空间中存在相似性所引发的噪声训练信号问题,我们进行了深入研究。这一技术突破对实现自监督密集表征学习及像素标注具有关键作用。
- 我们提出了一种基于威布尔函数的新型正则化方法。该方法不仅能有效避免聚类退化(即空簇现象),还能解决超声图像分析中的像素类别不平衡问题——这一关键问题在以往研究中往往被忽视。
- 在COCO-Stuff-27、COCO-Stuff-171和Cityscapes三大真实数据集的实验中,IDDC方法以显著优势超越现有最先进算法。该成果为新兴且极具挑战性的超大规模数据集(USS)任务确立了全新基准。我们通过大量消融实验验证了IDDC各设计方案的有效性。
2.相关工作
2.1.无监督语义分割(USS)
USS的目标是无需人工标注即可完成图像中每个像素的自动标注。早期研究将USS建模为补丁级聚类问题,通过最大化互信息将不同像素排列方式的补丁(Ouali等人,2020)、多种增强视角的补丁(Mirsadeghi等人,2021)或空间相邻补丁(Ji等人,2019)进行聚类。然而这些方法容易产生不准确的分割结果,且由于忽视了不同图像间补丁的相关性以及类别分布的不平衡特性,主要应用于分割天空、道路等固定元素。
随后,研究者提出了基于跨图像学习的像素级解决方案。这些方案采用两阶段学习策略:先生成伪掩码再进行优化,或先学习像素级嵌入再进行聚类。前一种方法通过迭代生成并优化伪掩码作为监督信息来实现优化。PiCIE(Cho
et al., 2021)受深度聚类(Caron et al.,
2018)启发,通过对比学习描述性像素嵌入,并迭代更新K均值聚类生成伪掩码。PASS(Gao
et al., 2022)构建自监督模型,在像素注意力图辅助下生成伪掩码。Yin et al.
(2022)采用K均值聚类预训练像素嵌入作为伪标签,并通过自助法进行优化。后续研究中,由Hamilton团队提出的STEGO(Hamilton
et al.,
2022)尝试从预训练模型中提取低维像素特征,并利用下游K均值聚类进行分组优化。Hamilton
et al.
(2022)通过提取预训练网络的密集对应关系,先学习低维像素特征再进行聚类。Pang
et al. (2022)通过提取视频帧的不变性特征,获得更具描述性的特征。Seong et
al. (2023)基于预训练嵌入和局部邻接关系,提取正向像素对进行对比学习。Li
et al.
(2023)将图像分割为多个区域,通过K均值聚类生成区域表征用于无监督语义分割。
IDDC与STEGO
(Hamilton et al.,
2022)在建模、学习和解决类别不平衡问题方面存在显著差异。
(1)建模方面。STEGO首先通过蒸馏方法提取低维特征,随后采用K均值算法进行像素聚类,该算法假设输入特征呈球形分布、各簇方差相等且簇大小均匀。相比之下,IDDC具有判别性特征,能够直接输出基于输入图像条件的每个像素分类概率,且无需满足上述任何假设。因此,IDDC在处理不同类别和数据集间特征分布差异时更具灵活性,对外部异常值的抗干扰能力更强,并能更高效地对高维特征空间中的像素进行分类。
(2)学习机制。STEGO采用分阶段学习策略,分别对蒸馏学习和K均值聚类进行训练。这两个阶段在不同学习目标下进行优化,这种设计存在局限性。例如,蒸馏学习阶段完全不了解聚类目标或聚类数量,因此无法根据聚类阶段的实际需求进行动态调整。相比之下,IDDC可以在统一的学习目标下实现端到端训练。这种设计使得表征学习与像素聚类能够无缝协作,从而提升学习效率。
(3)解决类别不平衡问题。STEGO采用K均值算法提取特征进行聚类,但该方法常生成的均衡聚类结果(Lu
et al., 2019; Xiong et al.,
2006)与类别分布失衡的实际情况存在矛盾。针对这一问题,IDDC创新性地引入基于Weibull函数的正则化项,通过单次训练即可有效解决像素类别不平衡和聚类质量下降的问题。
2.2.无监督对象中心分割
部分研究(Van Gansbeke et al., 2021, 2022; Zadaianchuk et al., 2022;
Melas-Kyriazi et al., 2022; Ziegler &
Asano,2022)聚焦于图像中物体的分割任务。这些研究采用了两阶段自监督学习框架:第一阶段提取前景区域或物体部件,并学习其视觉表征;第二阶段通过K均值聚类将这些区域归类为不同物体类别。具体而言,Van
Gansbeke等人(2021)通过监督显著性检测网络提取前景区域,并利用对比学习技术学习其特征。随后,他们对每个显著物体区域的特征向量进行平均池化处理,再通过K均值聚类确定其类别。COMUS(Zada
ianchuk et al., 2022))和MaskDistill(Van Gansbeke et al.,
2022)则分别采用无监督显著性检测、像素嵌入和注意力机制提取前景区域。这些提取的区域随后被聚类为伪标签,用于训练能够分割多个物体的分割网络。Leopart
(Ziegler & Asano,
2022)通过聚类自监督密集特征提取前景区域,再利用社区检测将其划分为多个物体。DSM
(Melas-Kyriazi et
al.,2022)采用谱分段方法选取前k个特征向量识别物体部件,并对每个部件的特征向量进行平均池化处理后,通过K均值聚类获得语义标签。
这些研究分别独立学习前景区域、特征和聚类,且仅对图像中的物体进行标注。相比之下,IDDC采用端到端的判别式方法学习密集特征和像素聚类,能够对每个像素(包括物体和背景)进行标注。此外,IDDC在自监督学习中明确处理噪声问题,并解决像素类别不平衡问题——这些都是前人研究中未曾涉及的。
2.3.判别式聚类(Discriminative Clustering)
判别式聚类旨在从未标注数据中学习判别分类器,即确定不同聚类之间的分界线。传统方法主要采用互信息优化(Barber与Agakov,2005;Bridle等,1991;Krause等,2010)和最大间隔优化(Xu等,2004;Zhao等,2008)。这些方法通过平衡类别分布或寻找数据中的最大间隔超平面来实现目标。深度学习方法(Van
Gansbeke等,2020;Ji等,2019;Ouali等,2020;Schmarje等,2021;Ghasedi
Dizaji等,2017;Chang等,2017)则基于连通性聚类理念,将视觉相似的图像对归为同一类别。为避免聚类退化,这些方法假设类别标签在数据集中均匀分布。
与之不同,IDDC专注于USS(密集像素标注任务)。Cho等人(2021)的研究表明,直接将图像聚类方法应用于像素层面效果欠佳。此外,处理密集标注带来的计算开销并非易事。我们还深入研究了像素不平衡问题以及由嵌入空间中相似但属于不同类别的像素所引发的噪声训练信号——这些因素在先前研究中常被忽视。
2.4.自监督学习
自监督学习致力于从无标注图像中挖掘具有意义的视觉表征。早期研究通过解决预设任务实现这一目标,例如图像修复、拼图游戏和旋转预测(Alexey等人,2015;Bojanowski与Joulin,2017;Doersch等人,2015;He等人,2020;Komodakis与Gidaris,2018;Noroozi与Favaro,2016)。近年来的研究主要基于对比学习方法(Chen等人,2020;Chen与He,2021;Grill等人,2020;He等人,2020)。这类方法通过提取同一图像的不同视角特征,同时消除不同图像间的相似性。经过训练后,所获得的图像表征可应用于下游任务。
由于全局表征难以满足密集预测需求(何等人,2019;普鲁什瓦卡姆与古普塔,2020),部分研究通过建立跨视角的密集对应关系,将图像级方法扩展到像素级(洪等人,2019;李等人,2021;罗等人,2021;王等人,2021)。另一类方法则利用视觉变换器(ViT)的优势(图沃龙等人,2021),因其能建模长距离特征交互,相比卷积神经网络能更好地保留块级相似性(卡隆等人,2021;汉密尔顿等人,2022;周等人,2021)。我们的方法采用自监督ViT预训练的密集特征作为像素嵌入。
3.方法
3.1.概观
无监督语义分割(USS)旨在从一组未标注的图像中学习语义分割模型。对于新图像,它能够为每个像素分配一个类别标签。
以往的USS方法通常采用两阶段的顺序或迭代学习框架。第一阶段是将图像映射为密集特征的神经网络,第二阶段则是使用传统聚类算法(通常是K均值算法)对特征空间中的像素进行聚类。如第1节所述,该框架存在若干难题:由于表示学习与像素聚类这两个过程被割裂而非端到端衔接,导致二者难以协调;由于K均值算法假设每个聚类呈球形,难以建模物体和背景的多样性并处理异常值;此外,现实世界中像素类别不平衡的问题完全被忽视,难以有效应对。
我们提出了一种名为“不平衡感知密集判别聚类(IDDC)”的创新方法,用于解决超分辨率图像处理中的数据不平衡问题。该方法通过统一框架全面应对上述挑战。
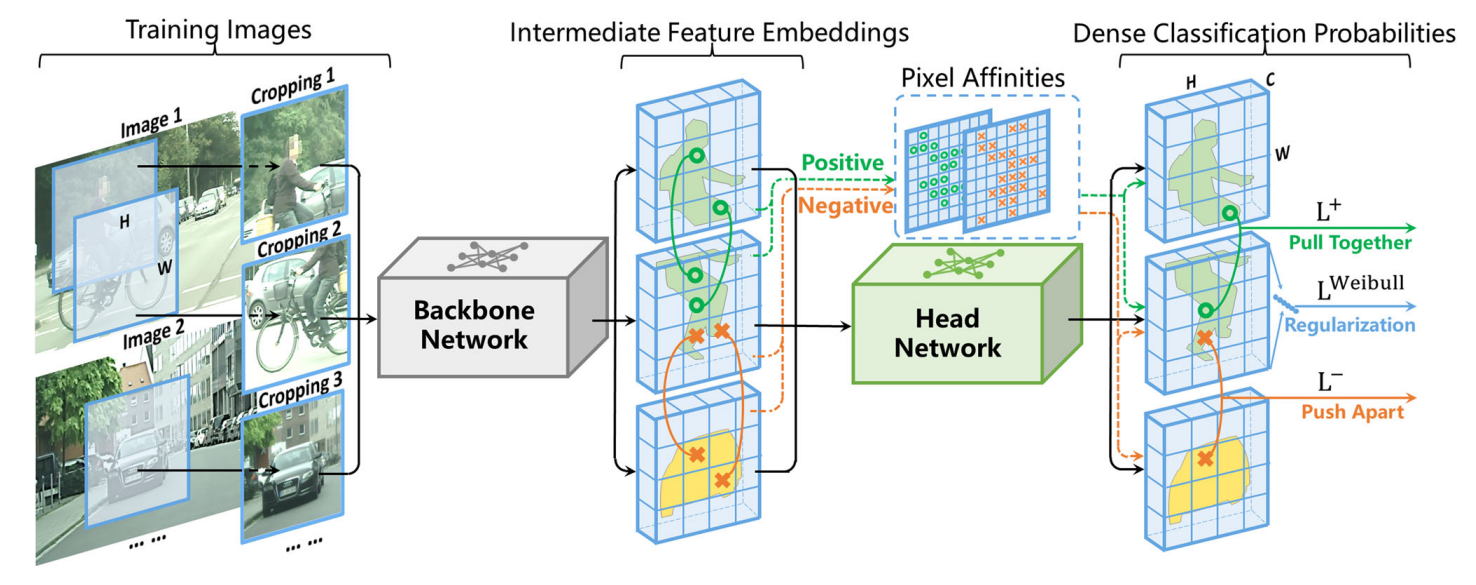
图1不平衡感知密集判别聚类(IDDC)在无监督语义分割(USS)中的应用架构。该方法通过直接建模图像中每个像素的分类概率来实现无监督语义分割。其网络架构包含两个核心组件:主干网络(即基于未标注图像预训练的ViT模型)负责提取图像密集特征,头部网络则负责预测像素级分类概率。这两个组件通过端到端、判别式且自监督的方式进行学习,其核心在于一种创新的目标函数——该函数由三个损失项构成。L+和L−通过将ViT嵌入空间中像素的流形结构迁移至标签空间,并允许像素亲和度存在噪声,为语义分割学习提供了有效的训练信号。\(L^{Weibull}\)是一种基于Weibull函数的新正则化方法,既能避免聚类退化问题,又能有效解决像素类别不平衡的挑战。
图1展示了IDDC的整体架构:IDDC直接基于图像条件建模每个像素的分类概率,无需假设生成分布或聚类形态。其网络架构包含两个核心组件——主干网络(即基于未标注图像预训练的ViT模型)负责提取密集特征,分割头则通过Softmax函数预测像素级分类概率。这两个组件采用端到端、判别式且自监督的学习方式,通过将ViT嵌入空间中的像素流形结构迁移至标签空间,有效缓解像素亲和力噪声的影响,并解决聚类退化与像素类别不平衡问题。具体而言,我们充分利用了自监督ViT模型的最新进展:其图像密集嵌入能良好保留像素间的语义相似性(第3.2节)。基于这种像素流形结构,我们设计了IDDC的监督学习机制(第3.3节)。然而,成对像素亲和力存在显著噪声干扰:在ViT嵌入空间中邻近的像素可能属于不同类别。我们深入研究了噪声处理方法(第3.3节)。最后,我们引入基于Weibull函数的新正则化项,用于建模像素的偏态分布并避免空聚类(第3.4节)。
3.2.密集嵌入作为分割提示
我们证明了自监督视觉Transformer(ViT)学习到的图像密集嵌入具有语义意义。尽管存在噪声,但在ViT嵌入空间中距离更近的两个像素更有可能属于同一类别。
给定输入图像时,基于ViT的主干网络会生成密集特征图。设\(u_i\)表示第i个像素的二维归一化嵌入向量,我们通过计算两个像素i和j的嵌入向量余弦相似度来确定它们之间的亲和力:\(u_i·u_j\)。图2展示了在Cityscapes训练集(Cordts等人,2016)上计算的像素对亲和力分布情况。
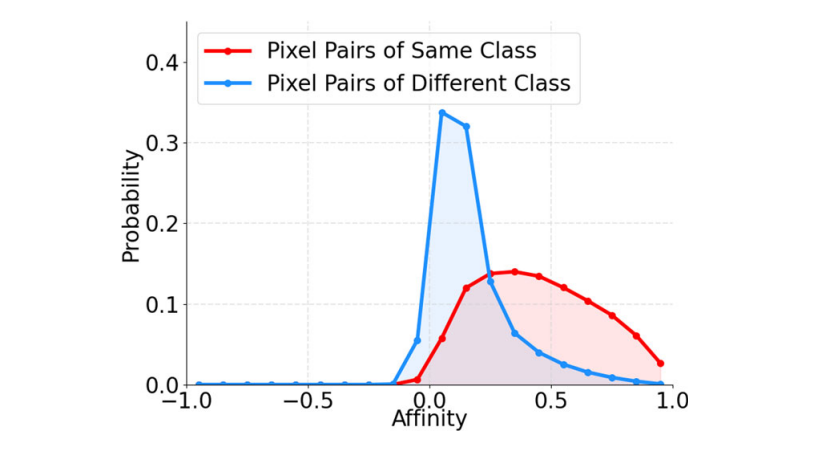
图2展示了同类别(红色)与不同类别(蓝色)像素之间的成对亲和力分布。两个像素间的亲和力通过它们在ViT嵌入空间中的余弦相似度进行计算。
其中红色和蓝色分别对应同类别像素对和不同类别像素对的分布。该主干网络采用ViT小模型架构,补丁尺寸为16,由Zhou等人(2021)基于ImageNet(Deng等人,2009)无标签数据进行预训练。
通过观察图2可以得出两个重要结论。首先,同类像素对的亲和力通常高于异类像素对。当两个像素的亲和力超过0.2(即图2中两条曲线的交叉点)时,它们更可能属于同一类别。这一发现启发我们:在ViT嵌入空间中,通过分析像素间的亲和力关系,可以作为判断标签空间内像素关联性的关键线索,从而为语义分割模型的学习提供有效依据。其次,不同类别的像素仍然可能具有较高的亲和性,这使得前面提到的提示噪声。处理噪声对于有效的自监督学习至关重要。
3.3.像素流形的抗噪学习
我们引入了一个基本的目标函数,通过将ViT嵌入空间中像素的流形结构转移到标签空间(第3.3.1节)以及缓解像素亲和力中的噪声的不利影响(第3.3.2节)来学习USS。
3.3.1像素流形迁移学习
第3.2节计算的像素对亲和度特征,刻画了ViT嵌入空间中像素的流形结构。我们的基础目标函数通过在标签空间中保持这种流形结构来学习USS(Unsupervised
Supervised
Sampling)。具体来说,当两个像素在ViT嵌入空间中距离较近或较远时,它们在标签空间中也应保持相近或相距较远。该目标函数由正项和负项构成:正项使每个正像素对的分类概率向同一方向拉近,而负项则使每个负像素对的分类概率朝相反方向分散。这里,正像素对指亲和度超过阈值t+的像素对,负像素对指亲和度低于阈值t−的像素对。
为了获取正样本对,我们首先在同一图像中选取两个部分重叠的裁剪区域,然后从每个裁剪区域中各选取一个像素形成正样本对。两个裁剪区域之间的重叠部分确保存在同类像素对。通过随机几何变换扰动像素嵌入并扩充数据,这有助于提升学习稳健性并避免过拟合。设\(u_i\)和\(u_j^+\)分别表示两个裁剪区域中像素的l2归一化嵌入向量,其对应的分类概率分别为\(v_i\)和\(v_j^+\)。正样本损失项的公式为: \[L^{+}=\frac{1}{N^{+}}\sum_{\forall
i,j}w^{+}(u_{i}\cdot u_{j}^{+};\,t^{+})h^{+}(v_{i}\cdot
v_{j}^{+})\] 其中\(w^{+}(u_{i}\cdot
u_{j}^{+};\,t^{+})\)通过返回\(u_{i}\cdot u_{j}^{+}\)(当其值大于\(t^+\)时)来筛选正像素对,否则返回零;N+统计正像素对的总数,h+是单调递减函数(因为目标函数需要最小化)。\(v_{i}\cdot
v_{j}^{+}\)可理解为两个像素在独立情况下属于同一类别的概率。除了筛选非正像素对外,\(w^{+}(u_{i}\cdot
u_{j}^{+};\,t^{+})\)还利用ViT嵌入空间中正像素对的亲和力来加权它们在标签空间中的相似度。这解释了亲和力较大的像素对更可能属于同一类别的观察结果。h+的设计对于处理噪声至关重要,将在下一节详细说明。
为了获得负样本对,我们首先分别从两张不同的图像中各采样两个裁剪区域,然后从每个裁剪区域中各采样一个像素点来形成负样本对。负损失项的公式表示为:
\[L^{-}=\frac{1}{N^{-}}\sum_{\forall
i,j}w^{-}(u_{i}\cdot u_{j}^{-};\,t^{-})h^{-}(v_{i}\cdot
v_{j}^{-})\] 其中,\(w^{-}(u_{i}\cdot
u_{j}^{-};\,t^{-})\)通过返回\(1-u_{i}\cdot u_{j}^{-}\)(当\(u_{i}\cdot
u_{j}^{-}\)小于t−时)来筛选负像素对,否则返回零;N−统计负像素对的总数,而h−是一个单调递增函数。最小化\(L^{-}\)会使两个像素在标签空间中进一步分离,前提是它们在ViT嵌入空间中距离更远。
3.3.2抗噪
像素对之间的亲和力存在噪声干扰,因为不同类别的两个像素可能具有较高的亲和性,如图2所示。我们探索了h+(·)和h−(·)的不同表达形式,并分析了它们对噪声的容忍能力。
对数函数广泛应用于概率相关的损失函数中,例如交叉熵损失函数。我们考虑:
\[\begin{array}{l}{h^{+}(v_{i}\cdot
v_{j}^{+})=-\log(v_{i}\cdot v_{j}^{+})}\\ {h^{-}(v_{i}\cdot
v_{j}^{-})=-\log(1-v_{i}\cdot v_{j}^{-})}\end{array}\]
对数函数之所以适用于有良好标注数据的监督学习,是因为它会对错误分类施加渐近无限大的惩罚。但在USS(无监督学习)场景中,噪声是无法避免的。同一类别的像素对可能具有较小的相似度,而不同类别的像素对则可能具有较大的相似度。在这种情况下使用对数函数会导致梯度过大且方向错误。由于惩罚项和梯度值过高,网络将无法有效忽略噪声,从而严重干扰其学习过程。
上述分析促使我们寻找一个定义域为[0,1]且值域有限的函数。满足该条件的最简单函数就是线性函数。我们考虑:
\[\begin{array}{l}{h^{+}(v_{i}\cdot
v_{j}^{+})=1-v_{i}\cdot v_{j}^{+}}\\ {h^{-}(v_{i}\cdot
v_{j}^{-})=v_{i}\cdot v_{j}^{-}}\end{array}\]
线性函数具有恒定的斜率,无论损失值如何变化,其梯度始终保持一致,这意味着两个像素点的亲和力与其类别之间存在不一致性。与鲁棒回归中使用的l1-范数(徐等人,2008年)类似,只要噪声量不过大,线性函数就能容忍噪声的存在。但潜在的问题在于,由于损失函数对所有案例一视同仁,优化简单案例反而更容易,这可能导致学习过程过度关注简单案例而忽视复杂案例,从而阻碍有效学习。
最后,我们考虑一个指数函数:
\[\begin{array}{c}{h^{+}(v_{i}\cdot
v_{j}^{+})=\mathrm{exp}(1-v_{i}\cdot v_{j}^{+})}\\ {h^{-}(v_{i}\cdot
v_{j}^{-})=\mathrm{exp}(v_{i}\cdot v_{j}^{-})}\end{array}\]
与线性函数类似,指数函数在定义域[0,1]内具有有限的输出值范围和梯度。但与线性函数不同的是,指数函数在损失值较大时具有更大的梯度,因此对困难案例会施加更大的压力。
总体而言,线性函数和指数函数相比对数函数都具有更强的噪声容忍度,这得益于它们在输出值范围和[0,1]定义域内的梯度分布特性。相较于线性函数,指数函数更侧重于处理困难案例而非简单案例。在USS算法中,我们无法区分困难案例与噪声干扰。但实验表明,指数函数的表现优于线性函数,两者均以显著优势超越对数函数。究其原因,可能在于噪声容忍度与困难案例处理能力对有效学习都至关重要,而指数函数在这两方面实现了良好的平衡。
3.4.解决集群退化和像素类别不平衡问题
虽然目前提出的模型可以用于学习USS,但仍有两个关键问题亟待解决。首先是聚类退化问题:经常会出现空簇现象。其次是像素类别不平衡问题:现实世界中物体大小和出现频率不同,导致像素类别分布严重失衡。
先前的判别聚类方法(Ji等人,2019;Krause等人,2010;Ouali等人,2020;Van
Gansbeke等人,2020)通过基于熵的正则化器来解决聚类退化问题: \[\begin{array}{c}{L^{\mathrm{enropy}}=\sum_{c}p_{c}\log(p_{c}),}\\
{\mathrm{where}\;p_c=\frac{1}{N}\sum_{\forall
i}v_{i,c}}\end{array}\]
其中,i和c分别表示样本和类别的索引,\(v_{i,c}\)是第i个样本上第c类的预测概率,N是样本总数,pc是训练数据中第c类出现的频率。该方法通过强制类别均匀分布来避免空聚类。
然而现实世界中像素的类别分布往往呈现严重偏斜而非均匀状态。以城市景观数据集为例,道路类像素占比极高,其数量比稀有类别多出上千倍。这种类别失衡问题在USS研究中长期未被重视。
为了解决类别退化和类别分布不均的问题,我们引入了一个正则化项来规范学习过程。这个正则化项有两个作用。首先,它对存在空簇的情况施加了重大惩罚。其次,它容忍了像素类分布的偏斜。
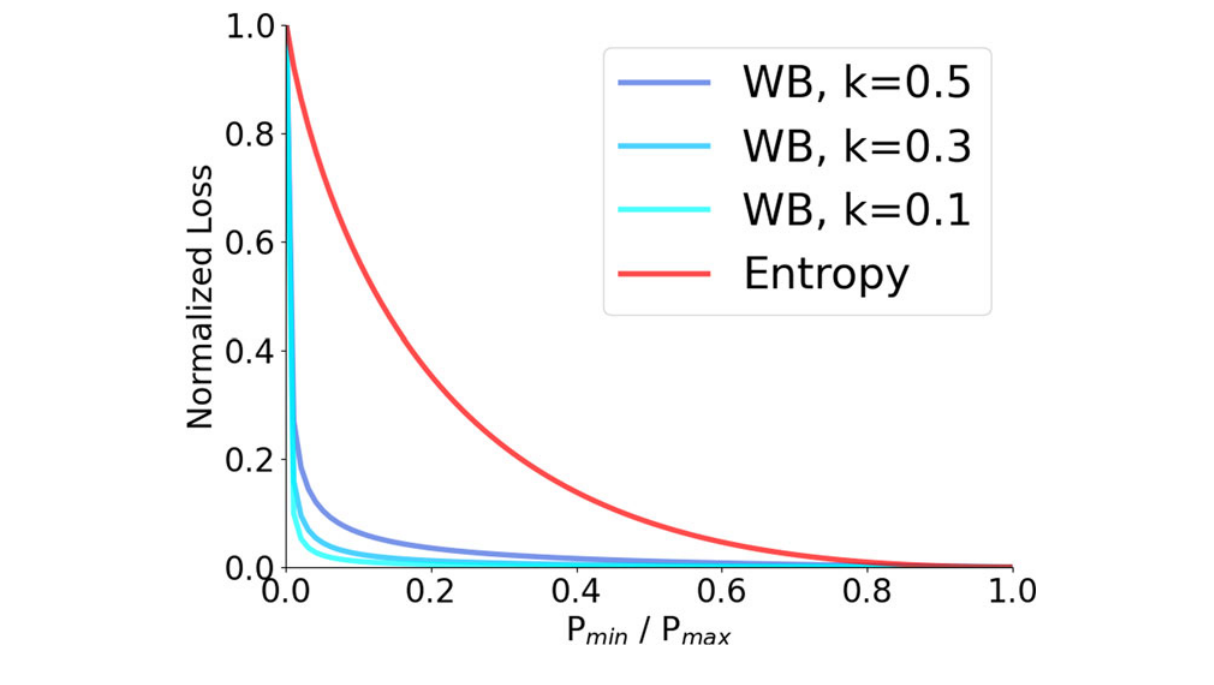
图3展示了基于Weibull函数(WB)和熵两种正则化方法的对比分析。横轴表示罕见类别与常见类别像素数量的比值,该比值范围在0.001到1之间。两种正则化方法均经过归一化处理,确保其上限值均为单位量级。
如图3所示,当x轴表示两类像素的分布比例时,L形函数能完美契合上述双重目标。一方面,“L”的垂直部分会产生较大损失值,有效抑制空簇的出现;另一方面,“L”的水平部分在类别分布不均衡时会产生接近零的损失值,使像素能够根据其在嵌入空间中的距离进行聚类。我们将正则化项建模为韦布尔函数(Murthy等,2004;Weibull,1951),因其形状参数\(k\in(0,1)\)可灵活调整且具有可微性。k值越小,Weibull分布越接近L形曲线。具体而言,本文提出的正则化项可表示为: \[{L}^{\mathrm{Weibull}}=\sum_{c}k p_{c}^{k-1}\exp(-p_{c}^{k})\] 从图3可以观察到,与聚类中广泛使用的熵正则化器(范·甘斯贝克等人,2020年)类似,当出现空簇时(即比例接近零的情况),威布尔正则化器会产生较大的惩罚。但与熵正则化器不同的是,当类别不平衡时(即比例远低于1的情况),Weibull正则化器产生的惩罚会比熵正则化器小得多。
3.5.整体目标函数
IDDC的总体目标函数结合了第3.3节中的基本目标函数和第3.4节中的Weibull正则化项: \[L=L^{+}+\lambda_{1}L^{-}+\lambda_{2}L^{\mathrm{weisull}}\] 其中λ1和λ2是权衡超参数。L+和L−通过将ViT嵌入空间中像素的流形结构迁移至标签空间,并容忍像素亲和力中的噪声,为语义分割学习提供了有效的训练信号。\({L}^{\mathrm{Weibull}}\)方法有效避免了聚类退化问题,并解决了像素类别不平衡的问题。
4.实验
4.1.数据集和评估指标
4.2.实施细节
4.2.1网络结构
所有数据集的骨干网络均采用基于ViT的模型(Touvron等人,2021)。这些模型通过无监督预训练方法进行训练,包括DINO(Caron等人,2021)和iBoT(Zhou等人,2021)在ImageNet数据集上进行无标签预训练(Deng等人,2009)。分割头由两个ReLU激活的卷积层和一个Softmax激活的卷积层组成。
4.2.2训练
我们的方法基于Pytorch框架实现。使用Adam优化器训练模型,批量大小设为64。头网络初始学习率设为5e−4,骨干网络初始学习率设为5e−7。采用多项式学习率策略:初始学习率乘以\((1−iter/max_iter)^{power}\),其中power取值为0.9。针对COCO-Stuff-27、COCO-Stuff-171和Cityscapes数据集的训练轮次分别为5、20和50轮,批量大小保持64。在非端到端训练中,骨干网络固定而头网络可调;在端到端设置中,骨干网络在前2/5和最后1/5训练轮次保持固定。前者避免了随机初始化头网络反向传播对预训练骨干网络的干扰,后者确保监督信号稳定以保证学习过程。输入图像会随机调整尺寸(比例在0.8至1.2之间)、随机翻转,并裁剪为224×224尺寸。遵循先前研究(Van Gansbeke等人,2021;Hamilton等人,2022;Ji等人,2019;Cho等人,2021),我们将聚类数量设为真实类别数。单张NVIDIA V100 GPU卡上的训练耗时不足两小时,因此IDDC算法具有较高的运行效率。
4.2.3超参数
在COCO-Stuff-27数据集的ViT-S/8实验中,目标函数等式(8)中的λ1和λ2参数分别设置为1.4和0.25。用于筛选正负像素对的两个阈值t+和t−则设定为0.2和0.12。ViT-S/16实验中,这三个参数的取值分别为1.4、0.4、0.2和0.12。对于COCO-Stuff-171数据集,对应的参数配置为9.0、0.61、0.15和0.15。在Cityscapes数据集的ViT-B/8版本中,这些参数取值为0.38、0.22、0.2和0.28;而在ViT-S/8版本中则调整为0.25、0.3、0.15和0.25。我们已通过大量消融实验(详见第4.4节)验证了这些超参数的影响。
4.3.与最先进方法的比较
4.4.消融研究
4.5.可视化
5.结论
本文提出了一种名为“不平衡感知密集判别聚类(IDDC)”的创新方法,用于无监督语义分割(USS)。该方法通过端到端自监督学习,直接建模每个像素在图像条件下的分类概率,同时实现像素级特征表示与密集判别聚类的同步优化。我们创新性地提出一个目标函数,通过将ViT嵌入空间中像素的流形结构迁移至标签空间来实现IDDC学习,该方法不仅能容忍像素亲和力中的噪声干扰,还通过引入新型韦布尔正则化器有效解决像素类别不平衡问题。IDDC成功突破了传统方法在表征学习与像素聚类协调、异常值处理、噪声抑制及类别分布偏斜建模等方面的局限。在两个大规模真实数据集上,IDDC的性能显著优于所有现有最优方法。大量消融实验验证了各设计要素的有效性。