Loupe:A Generalizable and Adaptive Framework for Image Forgery Detection

Loupe: A Generalizable and Adaptive Framework for Image Forgery Detection
Yuchu Jiang1,2∗, Jiaming Chu2,3∗, Jian Zhao2,5∗, Xin Zhang2,4,Xu Yang1†, Lei Jin3, Chi Zhang2, Xuelong Li2†
1 东南大学
2 EVOL Lab, TeleAI of China Telecom
3
北京邮电大学
4 兰州大学
5 西北工业大学
摘要
生成模型的迅猛发展引发了人们对视觉内容伪造的严重担忧。现有的深度伪造检测方法主要针对图像级分类或像素级定位。虽然部分方法能达到高精度,但往往存在泛化能力不足的问题,或是依赖复杂的架构设计。本文提出名为Loupe的轻量级框架,该框架能有效实现深度伪造的联合检测与定位。Loupe通过整合补丁感知分类器与带条件查询的分割模块,实现了全局真实性分类与细粒度掩码预测的同步处理。为增强对测试集分布偏移的鲁棒性,该模型创新性地采用伪标签引导的测试时自适应机制,利用补丁级预测结果对分割头进行监督学习。基于DDL数据集的大量实验表明,Loupe模型在IJCAI 2025深度伪造检测与定位挑战赛中以0.846的综合得分稳居榜首。我们的研究结果验证了提出的补丁级融合与条件查询设计方案,在不同伪造模式下均能有效提升分类准确率和空间定位精度。相关代码可在https://github.com/Kamichanw/Loupe获取。
1 引言
生成式人工智能领域的最新突破[Croitoru et al., 2023;Shuai
et al., 2024; Zhan et al.,
2023]显著提升了生成逼真高质量图像的能力,使得创作高度还原现实世界的数字内容成为可能。然而这些技术进步也引发了重大隐忧——特别是针对制造欺骗性内容的恶意应用风险,这类内容往往旨在误导公众或篡改历史叙事。针对这些风险,计算机视觉领域正积极研发先进的深度伪造检测技术。现有方法[Lin
et al., 2024a; Yan et al.,
2023]主要侧重于评估整幅图像的真实性(即真实或伪造),同时也有新兴研究方向专注于定位篡改区域[Guo
et al., 2023;Li et al.,
2024]。
具体而言,早期方法主要依赖视觉网络(如卷积神经网络CNN和视觉变换器ViT)[Pei
et al., 2024; Guo et al., 2023;Li et al.,
2024]或频域分析[Pei et al.,2024; Kwon et al., 2022;
Tan et al.,
2024]来提取生成对抗网络或扩散模型生成图像的特征,以实现伪造检测与定位。然而,这些方法通常架构复杂且领域特定,对不同生成技术产生的图像普遍性较差[Pei
et al., 2024; Lin et al.,
2024b]。另一方面,近期研究采用视觉-语言模型(VLMs)[Huang et
al., 2024; Kang et al.,
2025],这类模型在提供可解释性的同时实现了伪造检测与定位,并展现出优异性能。但VLMs所需的庞大计算资源限制了其实际应用。因此,开发一种计算效率高、结构简洁且能跨多种伪造技术泛化的解决方案至关重要。
本文提出了一种名为Loupe的创新框架,用于图像伪造检测和伪造区域定位,旨在同时进行真实性分类和精确的篡改区域定位。Loupe集成了图像编码器、分类器和分割器,共同建模了真实性验证和伪造区域定位任务。在测试阶段引入监督信号以实现动态自适应,是我们研究的核心目标。需要指出的是,图像级分类通常比像素级分割复杂度更低,这意味着分类网络往往能取得更优性能。值得庆幸的是,随着大规模视觉预训练技术的突破,当前最先进的视觉骨干网络已可直接应用于密集预测任务,无需构建复杂的分割网络架构[Bolya
et al., 2025;Tschannen et al., 2025; Oquab et
al., 2023; Kerssies et
al.,2025]。因此,在我们的分类器中,除了传统的全图像预测外,我们还结合了分块预测,从而得到低分辨率的掩膜预测。这种掩码预测结果在测试时可作为伪标签使用,起到监督信号的作用来指导分割器。此外,将分块级预测结果与传统的全图预测结果相结合,即可得到最终结果。这种融合策略增强了图像级预测的鲁棒性和可靠性。
我们在DDL数据集[Organizers]上评估了Loupe的有效性。在验证集上,分类AUC达到0.946,而分割IoU和F1分数分别达到0.880和0.886。在测试集上,分类AUC达到0.963,分割IoU和F1分数分别为0.756和0.819。值得注意的是,测试集存在轻微的分布偏移,包含训练集中未出现的伪造技术。尽管如此,Loupe仍展现出稳健的性能表现,这证实了所提出的框架本身及测试时自适应方法的有效性。
2 方法
图1展示了Loupe的整体架构,包含三大核心组件:图像编码器、分类器和分割器(由条件像素解码器与掩码解码器构成)。
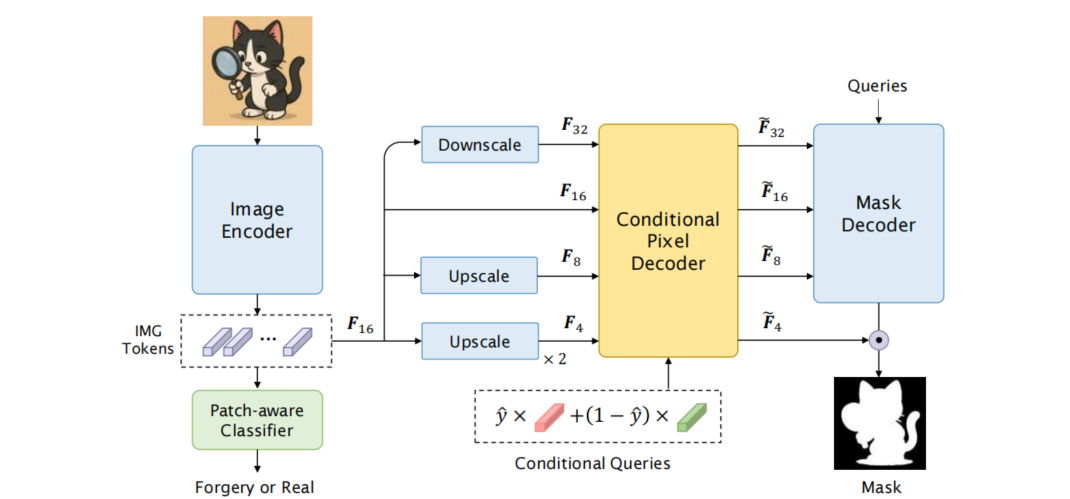
图1:Loupe框架结构示意图。该框架包含三大核心组件:图像编码器、分类器和分割器。图像编码器采用基于ViT架构的视觉主干网络。分类器在传统全图预测基础上,通过添加分块预测功能进行扩展。分割器沿用Mask2Former的元架构设计,但对像素解码器进行了关键性改进。未改动的组件用浅蓝色方块表示。
训练过程分为两个阶段:第一阶段冻结图像编码器,训练分类头;第二阶段则在保持编码器冻结的情况下训练分割头。各阶段的具体方法详见第2.1节和第2.2节。第2.3节将详细说明如何运用Loupe实现测试时的自适应调整。
2.1 第一阶段:分类
在第一阶段,我们训练分类头来判断输入图像是否真实或伪造。给定一张图像\(I\in{\mathbb R}^{3\times H\times W}\)(其中H和W分别表示图像的高度和宽度),首先通过图像编码器处理生成特征表征\(F_{16}\in{\mathbb R}^{H/16\times W/16\times D}\)(其中D表示图像编码器的输出维度,假设其块尺寸为16)。随后将生成的特征图F传递给块感知分类器进行分析。
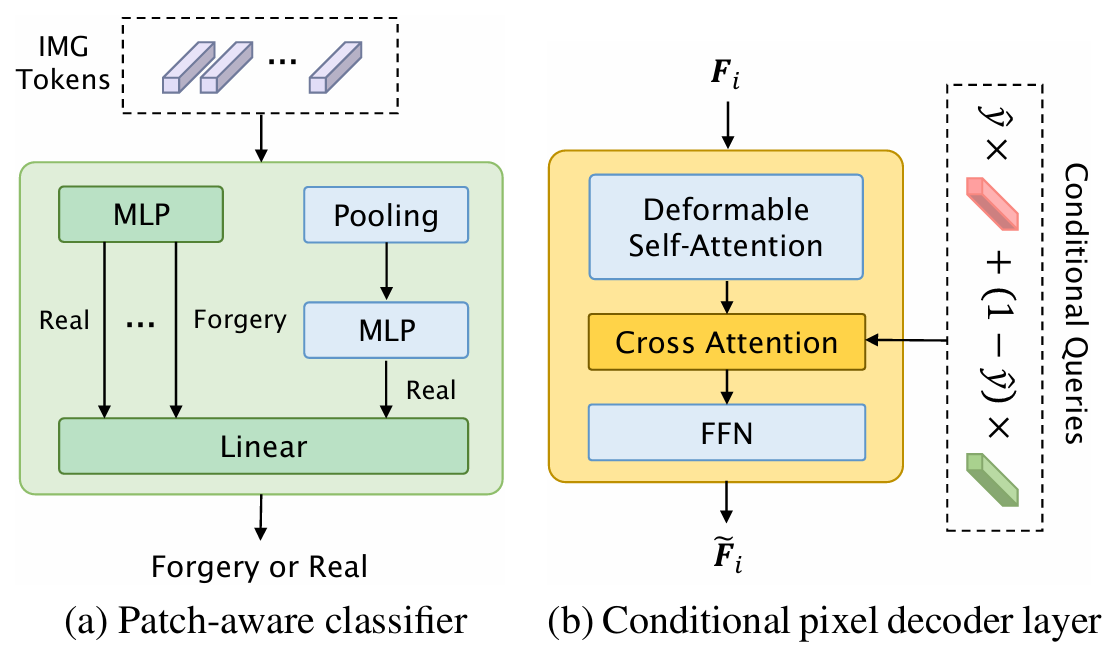
图2:(a)块感知分类器的详细结构。除常规池化后的标记预测外,Loupe还对每个单独补丁的真实性进行预测。(b)条件像素解码层的架构。Loupe在可变形自注意力网络与前馈网络之间引入了交叉注意力层,便于与条件查询进行交互。为简化模型,省略了残差连接和层归一化。
如图2a所示,该补丁感知分类器的架构设计包含三个核心模块:首先通过池化层提取全图像全局特征,随后将这些特征输入多层感知机(MLP)进行全局预测;接着独立运行的MLP模块对每个图像像素进行局部特征分析,生成局部预测结果;最终通过简单的线性层融合全局与局部预测信息,输出最终分类结果\(\hat
y\)。
在图像真实性分类任务中,伪造样本的数量通常远少于真实样本。为缓解类别不平衡问题(即多数类可能主导学习过程),我们采用多焦点损失函数
$ {L}_{patch} $ [Leng et al.,2022]作为样本预测的监督目标:
\[{\mathcal{L}}_{\mathrm{patch}}={\frac{1}{N}}\sum_{i=1}^{N}\left[-\alpha(1-p_{i})^{\gamma}\log(p_{i})+\epsilon(1-p_{i})^{\gamma+1}\right].\]
其中,N = H/16×W/16表示总补丁数量,\(p_i\)代表第i个补丁中伪造类别的预测概率,α和γ是focal损失系数,而ϵ则是多项式项的缩放因子。这种公式设计能促使模型更关注难样本或代表性不足的样本。
此外,全局预测采用标准二元交叉熵损失\({\mathcal{L}}_{\mathrm{global}}\)进行监督。最终分类损失由补丁级损失与全局损失之和构成:
\[{\mathcal{L}}_{\mathrm{cls}}={\mathcal{L}}_{\mathrm{patsh}}+{\mathcal{L}}_{\mathrm{global}}.\]
2.2 第二阶段:分割
在第二阶段,我们训练分割头生成像素级掩码。参照DetVit[Li et
al., 2022]的方法,我们在图像编码器输出的\(F_{16}\)特征图上应用轻量级特征金字塔网络(FPN),提取1/4、1/8、1/16和1/32分辨率的多尺度特征,最终得到{F4,F8,F16,F32}四个层级的特征流\(F_i\in{\mathbb R}^{D\times H_i\times
W_i}\)。在分割预测环节,我们采用Mask2Former[Cheng et
al.,
2022]架构。作为第一步,为增强特征信息,我们引入了改进版的条件像素解码器。在第i层中,特征图\(F_{i}\ \in\
\{F_{4},F_{8},F_{16},F_{32}\}\)通过多尺度可变形注意力机制(MSDA,multi-scale
deformable attention)进行优化,输出处理后的特征流\(\tilde
F_i\)。该过程实现了跨空间分辨率的信息自适应聚合,同时保持计算效率。
为支持第2.3节提出的伪标签引导式测试时自适应机制,MSDA生成的特征通过交叉注意力层进行深度处理。
如图2b所示,这些特征在与条件查询交互的过程中,不仅实现了空间聚合的精准控制,还整合了高层次语义信息,使后续掩码解码器能够生成兼具语义深度与空间精度的掩码。在此过程中,多尺度特征被转化为既保持分辨率一致性又富含语义内涵的表征形式。
掩码解码器的结构和训练流程与Mask2Former保持一致。与第2.1节所述的补丁分类方法类似,我们采用多焦点损失函数替代标准二元交叉熵进行监督分割分类。为有效缓解模型过度预测真实区域(如漏检)的问题,我们引入Tversky损失函数
$ {L}_{tversky} $ [Salehi et al., 2017]作为辅助目标函数: \[{\mathcal{L}}_{\mathrm{twrsky}}=1-{\frac{\mathbf{TP}}{\mathrm{TP}+\alpha\cdot\mathbf{FP}+\beta\cdot\mathbf{FN}}},\]
其中TP、FP和FN分别表示真阳性、假阳性和假阴性的数量。系数α和β用于调节假阳性和假阴性的惩罚值,从而在精确度与召回率之间进行权衡。在实验中,我们设定α
= 0.3和β =
0.7,以优先保证召回率并减少对伪造区域的漏检。
总损失函数的表达式为:
\[\mathcal{L}_{\mathrm{seg}}=\lambda_{1}{\mathcal
L}_{\mathrm{mask}}+\lambda_{2}{\mathcal
L}_{\mathrm{twesky}}+\lambda_{3}{\mathcal L}_{\mathrm{box}},\]
其中,\({\mathcal
L}_{\mathrm{mask}}\)是使用多焦点损失来处理类别不平衡的分类损失函数,该函数会赋予少数类(伪造区域)更高的权重。\({\mathcal
L}_{\mathrm{box}}\)是边界框损失函数,其中使用匈牙利匹配将预测的边界框最优地分配到真实伪造区域,确保预测伪造区域的空间一致性。
2.3 伪标签引导的自适应
如第1节所述,传统伪造检测方法普遍存在泛化能力不足的问题,导致在面对分布外(OOD
,out-of-distribution)数据的真实场景中难以有效应用。因此,在测试阶段如何有效利用已训练模型成为关键挑战。针对这一难题,我们提出了一种创新方案——通过在测试阶段向分割框架注入监督信号,为模型训练提供持续优化的反馈机制。
为实现这一目标,在第二阶段训练过程中,我们定义了两个可学习的嵌入向量来表征“真实”与“伪造”两种语义类别。根据真实标签,系统会选取对应的嵌入向量与条件像素解码器中的图像特征Fi进行交互。测试时,我们将分类器的最终输出作为伪标签,通过在两个语义嵌入向量之间进行插值处理,为像素解码器提供额外约束条件。将补丁级别的预测结果视为低分辨率掩膜,随后将其输入掩膜解码器进行监督学习。
3 实验
3.1 设置
数据集和评估
我们在DDL数据集上对Loupe模型进行了训练和评估,该数据集包含真实/伪造分类和空间定位任务。数据集包含超过150万张图像,涵盖61种操控技术,如单人脸和多人脸篡改场景。在评估中,我们采用ROC曲线下面积(AUC)作为检测指标,F1分数和交并比(IoU)作为空间定位指标(其中IoU仅针对伪造样本计算)。
实施细节
我们采用感知编码器[Bolya等人,2025]作为图像编码器。在分割器部分,像素解码器和掩码解码器的大部分架构参数与Mask2Former
[Cheng等人,2022]保持一致,但将可学习查询数量设置为20。每个训练阶段运行一个周期,使用AdamW优化器进行训练。为调整学习率,我们采用了预热稳定衰减调度器[胡等人,2024],其中前10%的训练步骤用于预热,最后10%用于学习率衰减。更多超参数详见附录A。
3.2 结果
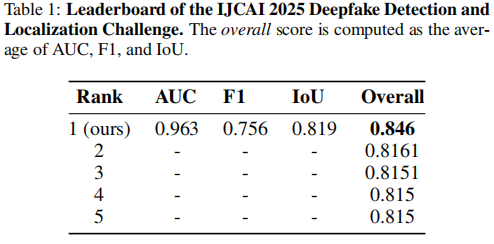
Loupe在IJCAI 2025深度伪造检测与定位挑战赛中勇夺冠军。排行榜前五名的具体数据详见表1。我们的方法总分比亚军高出0.03分,而亚军至季军的分差更是仅有不到0.001分。
在验证集上,Loupe实现了0.947的分类AUC值,以及0.880和0.886的分割IoU和F1分数。尽管测试集与训练集及验证集相比存在轻微的数据分布偏移,但Loupe——尤其是分类AUC指标——基本保持稳定,这表明我们的方法具有较强的鲁棒性。
3.3 消融研究
我们在DDL数据集的验证集上进行了一系列消融研究,以评估我们提出的方法的有效性。
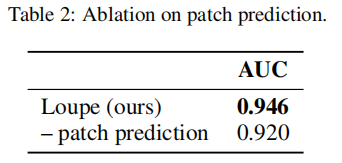
补丁感知分类器
我们通过移除局部预测来验证其重要性。如表2所示,局部预测相比传统的全局方法有显著提升,证明了局部-全局融合策略的有效性。
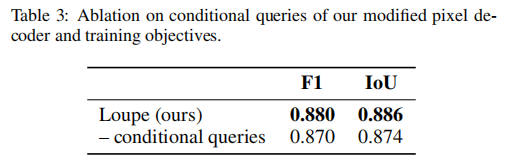
条件像素解码器
表3表明,Loupe模型通过我们提出的条件查询方法获得了显著优势。在将图像特征输入掩码解码器前,先用语义嵌入进行条件化处理,这种方法不仅实现了测试时的自适应调整,还增强了预测掩码与底层伪造类型之间的语义一致性,从而实现更精准且具有上下文感知能力的定位。
4 结论
在本工作中,我们引入了Loupe,这是一个统一和高效的框架,用于深度伪造检测和伪造区域定位。通过将补丁感知分类器与条件像素解码器相结合,Loupe在保持架构复杂度极低的同时,实现了全局与局部预测的鲁棒性。此外,我们提出了一种伪标签引导的测试时自适应机制,有效提升了模型在分布偏移下的泛化能力。在DDL数据集上的大量实验表明,Loupe取得了业界领先的表现,在IJCAI 2025深度伪造检测与定位挑战赛中超越了所有竞争对手。