Rethinking Out-of-distribution (OOD) Detection:Masked Image Modeling is All You Need

Rethinking Out-of-distribution (OOD) Detection:Masked Image Modeling is All You Need
Jingyao Li1 ,Pengguang Chen2 ,Zexin He1 ,Shaozuo Yu1 ,Shu
Liu2,Jiaya Jia1,2
1 香港中文大学
2 SmartMore
摘要
分布外(OOD)检测的核心在于学习分布内(ID)数据的表征特征,使其与 OOD 样本形成有效区分。现有研究多采用基于识别的方法来学习ID特征,但这类方法往往容易陷入学习捷径而非构建全面表征的困境。本研究发现,令人惊讶的是,单纯采用基于重构的方法就能显著提升 OOD 检测性能。通过深入分析 OOD 检测的关键驱动因素,我们发现基于重构的预训练任务具有提供通用且高效的先验知识的潜力,这有助于模型更好地学习ID数据集的内在数据分布。具体而言,我们将掩码图像建模作为 OOD 检测框架(MOOD)的预训练任务。不加任何花哨功能,MOOD在单类 OOD 检测(SOTA)上比前代产品高出5.7%,在多类 OOD 检测上高出3.0%,在近似分布 OOD 检测上高出2.1%。它甚至超越了每类10次样本的异常暴露 OOD 检测,尽管我们并未在检测中使用任何 OOD 样本。相关代码可在 https://github.com/lijingyao20010602/MOOD 获取。
1.引言
一个可靠的视觉识别系统不仅要对已知上下文(即分布内数据)做出准确预测,还需能检测未知的分布外(OOD)样本,并将其拒收(或转移)至人工干预以确保安全处理。这促使人们在将输入数据输入下游网络前应用异常检测器——这正是
OOD 检测的核心任务,该任务也被称为新奇性检测或异常检测。 OOD
检测旨在判断测试样本是否偏离分布内数据(ID)范围。作为医疗诊断[5]、欺诈检测[45]、自动驾驶[14]等安全关键领域的基石技术,该检测能力在众多安全攸关的应用场景中发挥着关键作用。
许多早期的
OOD 检测方法依赖于异常暴露[15,53]来提升检测性能,这使得 OOD
检测变成了一个简单的二元分类问题。我们认为, OOD
检测的核心在于学习有效的ID表示,从而在没有已知异常暴露的情况下发现 OOD
样本。
本文首次揭示了一个令人惊讶的发现:仅采用基于重构的方法,就能显著提升各类
OOD
检测任务的性能。我们在此领域的开创性研究甚至超越了先前的少样本异常检测
OOD 方法,尽管我们并未包含任何 OOD
样本。
现有方法通过对比学习[53,58]或在大规模数据集上进行预训练分类[15]来检测
OOD
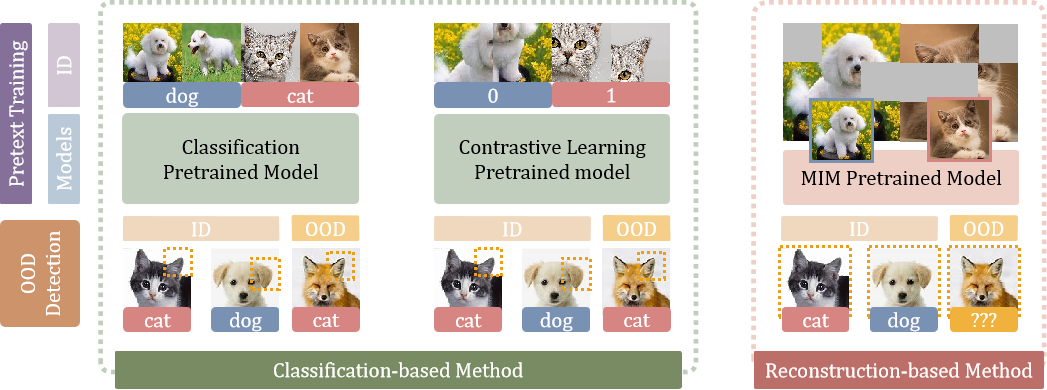
样本。前者根据伪标签对图像进行分类,后者则基于真实标签进行分类,其核心任务都是实现分类目标。然而,针对后门攻击的研究[50,51]表明,当学习过程被表征为数据分类时,网络往往会走捷径进行图像分类。
在典型的后门攻击场景[51]中,攻击者会在原始训练图像上添加带有明显正确标签的秘密触发器。测试过程中,受害模型会将这些带有秘密触发器的图像错误分类。研究表明,网络之所以能识别不同类别的特定可区分模式,是因为这能快速满足分类需求。
然而,单纯学习这些特征模式对
OOD
检测效果有限,因为网络无法理解身份证图像的固有数据分布规律。因此,通过分类身份证数据来学习特征表示进行
OOD 检测可能效果欠佳。例如,当 OOD
样本中出现与某些身份证类别相似的特征模式时,网络很容易将这些 OOD
样本误判为身份证数据,并错误归类到对应的身份证类别中。
为解决这一问题,我们提出了基于重构的预训练任务。与现有
OOD
检测方法[53,58]中的对比学习不同,我们的方法通过强制网络实现图像重构的训练目标,从而使其学习像素级数据分布。
具体而言,我们采用掩码图像建模(MIM,masked
image
modeling)[2,11,20]作为自监督预训练任务。该方法在自然语言处理[11]和计算机视觉[2,20]领域均展现出巨大潜力。在MIM任务中,我们将图像分割为图像块,并随机遮蔽部分图像块后输入视觉变换器进行训练。随后使用离散
VAE
[47]生成的标记作为训练标签。通过这种机制,网络能够从剩余图像块中学习信息,推测被遮蔽区域并还原原始图像标记。这种重建过程使模型能够基于图像固有数据分布进行先验学习,而不仅仅是通过分类过程掌握不同类别间的模式差异。
我们的实验结果表明,掩码图像建模(MOOD)在
OOD 检测的四个任务中均优于当前的 SOTA 方法,包括单类 OOD 检测、多类 OOD
检测、近似分布 OOD 检测,甚至在少样本异常暴露 OOD
检测中也表现更优,如图1所示。

图1 展示了MOOD算法在四项 OOD 检测任务中的性能表现,与当前主流 SOTA 方法(用‘*’标记)对比:(a)单类 OOD 检测;(b)多类检测;(c)近似分布检测;(d)少样本异常暴露 OOD 检测。
具体统计结果如下。
- 在单类 OOD
检测(表6)中,MOOD将当前信道状态信息(CSI)[58]的平均绝对误差(AUROC)提升了5.7%,达到94.9%。
2. 在多类 OOD 检测任务中(表7),MOOD模型的性能比当前SSD+ SOTA 方法[53]提升了3.0个百分点,最终达到97.6%的准确率。
3. 在近似分布的 OOD 检测任务中(表2),MOOD的 AUROC 值达到98.3%,比当前R50+ViT模型的 SOTA 值高出2.1个百分点[15]。
4. 在少样本异常检测 OOD 任务(表9)中,MOOD模型以99.41%的准确率意外超越当前采用R50+ViT架构的 SOTA 模型[15](其准确率为99.29%),该模型每类样本需使用10个 OOD 样本。值得注意的是,MOOD模型本身并未包含任何 OOD 样本。
2.相关工作
2.1.Out-of-distribution 检测
一种直接的分布外(OOD,out-of-distribution)方法是估计分布内(ID,in-distribution)密度[10,63,67,72],并剔除偏离该分布的测试样本。其他方法则基于图像重建[1,17,33]、学习分布内外数据的决策边界[27,37,68]、计算训练与测试特征间的距离[40,53,56,58,59]等。
相比之下,我们的研究聚焦于基于距离的方法,同时将基于重构的方法作为预训练任务纳入考量。这类距离方法的核心思路在于:
OOD
样本在特征空间中应与分布内数据(ID)的中心点保持较远距离[65]。典型方法包括K近邻算法[59]、原型方法[40,56]等。我们将在本文后续部分详细阐述本研究与现有
OOD 检测方法的差异。
2.2.Vision Transformer
Transformer在计算机视觉[2,20]和自然语言处理[11]领域展现出卓越性能。现有
OOD
检测研究[15]采用在ImageNet-21k[49]上进行分类预训练的视觉Transformer(ViT[13])模型。该研究主要探讨不同结构对
OOD 检测任务的影响,而我们的研究则从四个维度深入分析 OOD
检测效果:包括各类预训练任务、架构设计、微调过程以及 OOD
检测指标。
值得注意的是,先前多种方法[15,53]通过使用额外的 OOD
样本来进一步提升检测性能。但我们认为,这种做法违背了 OOD
检测的初衷。实际上,只要预训练任务足够充分,就能取得相当甚至更优的检测效果。因此,本研究重点探索无需使用
OOD 样本的合适预训练任务,以实现 OOD 检测的优化。
2.3.自监督预文本任务
在计算机视觉领域,人们长期采用多种自监督方法对视觉网络进行预训练,包括生成学习[2,11,46,60]、对比学习[6,7,21,29]和对抗学习[18,39,69]。其中代表性生成方法包括自回归[46,60]、基于流的[12,30]、自编码[2,11]以及混合生成方法[55,66]。
在我们的研究框架中,自监督预训练任务采用的是掩码图像建模(Masked
Image
Modeling,MIM)技术。该方法本质上属于自编码生成式方法,最初由自然语言处理领域提出[2]。其语言建模任务通过随机掩码文本中不同比例的标记,并从剩余文本的编码结果中还原被掩码的标记。后续研究[11,20]将自然语言处理领域的相似思路引入计算机视觉领域,通过遮蔽图像块的不同比例来恢复结果。
现有多种方法通过自监督任务指导
OOD
检测的表征学习。最新研究[53,58]提出对比学习模型作为特征提取器。然而,基于对比学习对转换图像进行分类的现有方法存在相似局限——模型容易学习类别特定模式,这种模式虽有利于分类,却无助于理解ID图像的内在数据分布。
文献[15]的研究也提到了这个问题。但根据我们的观察,由于预训练任务仍停留在分类层面,因此引入的大规模预训练Transformer模型[15]可能无法跳出循环。在本研究中,我们通过为
OOD 检测任务执行掩码图像建模任务来解决这一问题。
3.方法
本节首先阐述辅助 OOD
检测的关键要素,最终提出实现该目标的框架方案。
我们首先明确相关符号定义。对于给定数据集
\(X_{\mathrm{ID}}\)
,分布外检测(OOD,out-of-distribution)的目标是构建一个检测器,用于判断输入图像x是否属于
\(X_{\mathrm{ID}}\)(即\(x\in X_{\mathrm{OOD}}\))。现有大多数 OOD
检测方法通过定义 OOD
评分函数s(x)来实现,该函数的异常高或低值表明图像x属于分布外。
3.1.选择预文本任务
本节选择预文本任务,为 OOD 检测任务提供内在先验知识。现有大多数 OOD
方法通过分类[15,23]或对比学习[53,58]在ID样本上学习ID表征,这些方法利用真实标签或伪标签来监督分类网络。
另一方面,文献[50,51]的研究表明,分类网络之所以仅能识别训练类别间的差异模式,是因为这为分类任务提供了捷径。研究表明,该网络实际上并未真正理解ID图像数据的内在分布规律。
相比之下,基于重构的预训练任务要求网络在训练过程中学习ID图像的真实数据分布,而非仅学习分类模式。得益于这些先验知识,网络能学习到ID数据集更具代表性的特征,从而显著扩大
OOD
与ID样本之间的差异。
在本方法中,我们使用掩码图像建模(MIM)预训练数据集[11]对模型进行预训练,并在ID数据集上进行微调。表1对比了MIM与对比学习预训练任务MoCov3[8]的性能表现。结果显示,MIM的性能显著提升13.3%,达到98.66%。

3.2.探索架构
为探索有效架构[15],我们评估了 OOD 检测在BiT(Big Transfer [31])和 MLP -Mixer上的性能,并与ViT进行对比。我们采用 CIFAR -100和 CIFAR -10[32]作为ID- OOD 配对,由于二者语义相似且结构相近,分布相近。结果详见表2。

R50 + ViT [13,22] 是当前在近似分布 OOD 检测任务中表现最佳的 SOTA [15],虽然模型规模和测试时间翻倍,但检测准确率仍达到 96.23%(比 ViT 高出 0.70%)。然而,单个ViT上的MIM显著提升了其 AUROC 值至98.30%(提高了2.07%),且无需任何额外的源假设。这表明,高效的预文本本身足以生成可区分的表征——在此方面,无需使用更大的模型或多个模型的组合。
3.3.关于微调
单类微调
在进行单类 OOD
检测时,我们按照BEiT[2]的建议,先在ImageNet-21k[49]上对MIM模型进行预训练,再进行微调。特别需要注意的是,当在ImageNet-30上执行单类
OOD 检测时,由于训练过程中未包含 OOD
标签,因此仅在ImageNet-21k上进行预训练而无需中间微调。为此,我们采用标签平滑[57]技术,帮助模型从ID数据集上的单类微调任务中学习:
\[y_{c}^{L
S}=y_{c}(1-\alpha)+\alpha/N_{c},\qquad
c=1,2,\cdot\cdot\cdot,N_{c}\] 其中c为类别索引,Nc为类别数量, α
为决定平滑程度的超参数。当 α =0时,得到原始独热编码yc;当 α
=1时,得到均匀分布。
为解决常规微调过程中出现的过拟合和过度自信问题,我们采用了标签平滑技术。但研究发现,该技术同样适用于单类别微调。表3展示了模型在单类别微调前后的性能对比。(其中MIM-pt是指pre-train
the MIM model;inter-ft是指finely tune it on ImageNet-21k)

显然,该模型实际上是从单类微调操作中学习信息的。这可能违反直觉,因为标签是相同的。这是因为标签平滑效应导致损失值大于0,促使模型更新参数,即使准确率已达到1。
多类微调
针对多类别 OOD
检测任务,我们首先对MIM模型进行预训练,随后在ImageNet-21k数据集[49]上进行中间阶段的微调,最后在ID数据集上完成最终微调。通过表5的实验结果验证各阶段的有效性,证明所有阶段都显著提升了
OOD 检测的性能。

3.4. OOD 检测指标很重要
本研究对比了多种常用 OOD 检测指标的性能,包括Softmax[23]、熵[23]、能量[38]、GradNorm[26]和马氏距离[34]。我们采用MIM预训练任务对各指标进行 OOD 检测,结果详见表5。实验表明,Mahalanobis距离是衡量MOOD任务的更优指标。
3.5. MOOD的最终算法
综上所述,本节系统分析了 OOD
检测的多种影响因素,涵盖预训练任务、模型架构、微调策略及评估指标等维度。研究发现,采用Mahalanobis距离优化的微调MOOD模型在视觉Transformer(ViT)架构上表现最佳。该模型的卓越性能表明,仅需一个高效的预训练任务即可生成具有区分性的表征特征,无需依赖更大规模的模型或多模型组合。
在第4节中,我们将证明现有多种
OOD
检测方法[15,53]中采用的少样本异常暴露方法也是不必要的。MOOD算法如附录所示,主要包括以下几个阶段。
- 在ImageNet-21k数据集上对掩码图像建模视觉Transformer(ViT)进行预训练。
2. 在ImageNet-21k数据集上应用ViT的中等微调。
3. 在ID数据集上对预训练的ViT进行微调。
4. 从训练好的视觉Transformer(ViT)中提取特征,并计算Mahalanobis距离指标用于 OOD 检测。
4.试验
本节将掩码图像建模(Masked Image Modeling,MOOD)与当前的 SOTA 方法进行对比,涵盖单类 OOD 检测(第4.1节)、多类 OOD 检测(第4.2节)、近似分布 OOD 检测(第4.3节)以及少样本异常暴露 OOD 检测(第4.4节)。实验结果表明,MOOD在所有四个 OOD 检测任务中均显著优于现有方法。
实验配置
我们采用常用的ROC特征曲线下的面积(AUROC)作为无阈值评估指标,用于检测
OOD 评分。我们在以下数据集上进行实验:(i) CIFAR -10
[32],包含50,000张训练图像和10,000张测试图像,共10个图像类别;(ii)CIFAR
-100 [32]和 CIFAR
-100(超类)[32],分别包含50,000张训练图像和10,000张测试图像,对应100个和20个(超类)图像类别;(iii)ImageNet-30
[49],包含39,000张训练图像和3,000张测试图像,共30个图像类别;(iv)ImageNet-1k
[49],包含约120,000张训练图像和50,000张测试图像,共1,000个图像类别。更多训练设置细节详见附录。