MUN:Image Forgery Localization Based on M3 Encoder and UN Decoder

MUN: Image Forgery Localization Based on M3 Encoder and UN Decoder
Yaqi Liu1, Shuhuan Chen2,3, Haichao Shi2, Xiao-Yu Zhang2†, Song Xiao1, Qiang Cai4
1北京电子科技研究所
2中国科学院信息工程研究所
3中国科学院大学网络安全学院
4北京工商大学食品安全大数据技术重点实验室
摘要
图像伪造技术能够彻底改变图像的语义信息,常被用于不法用途。本文提出了一种名为MUN的新型图像伪造定位网络,该网络由M3编码器和UN解码器组成。首先,M3编码器基于多尺度最大池化查询模块构建,用于提取多线索伪造特征。采用Noiseprint++辅助RGB线索,并讨论了其部署方法。同时提出多尺度最大池化查询(MMQ)模块,实现RGB特征与噪声特征的融合。其次,我们提出了一种创新的UN解码器架构,通过自上而下与自下而上的双向采样提取层次化特征,实现高阶与低阶特征的同步重建。第三,我们构建了基于交并比(IoU)的动态交叉熵损失函数(IoUDCE),该模型能根据IoU值动态调整伪造区域权重,从而实现真实与伪造区域影响的自适应平衡。最后但同样重要的是,我们开发了偏差噪声增强(DNA)数据增强方法,通过获取RGB分布的先验知识来提升模型泛化能力。在公开数据集上的大量实验表明,MUN模型的表现显著优于现有最先进方法。
Code — https://github.com/MrHuan3/MUN
1.引言
在数码相机普及和图像编辑工具高度发达的今天,非专业用户也能轻松制作逼真的伪造图像,这些伪造品可能被用于危害公共安全的恶意行为。针对不同类型的图像伪造(如拼接、复制移动、删除等),存在多种对应的取证解决方案。在拼接检测领域,研究重点在于分析篡改操作在RGB色彩域或光谱域中留下的统计学异常特征(Yang
et al. 2024; Xu et al.
2023)。在复制副本伪造检测中,以手工方式提取和匹配视觉相似特征(Wang et
al. 2023; Li and Zhou 2019)或端到端深度学习方法(Liu et al. 2022b; Weng
et al.
2024)。在图像拼接检测与定位任务中,有些研究尝试通过视觉相似特征来检测拼接痕迹(Liu
et al. 2019; Tan et al.
2023)。在消除图像伪造方面,修复检测技术已得到广泛研究,特别是基于深度学习的修复技术的出现(Li
et al. 2024; Wu and Zhou
2022)。然而,面对疑似伪造的图像时,我们无法确定其被何种类型的伪造手段篡改,且上述方法仅在特定情况下有效。近年来,旨在检测多种类型伪造的图像伪造定位任务已引起越来越多的关注(Liu
et al. 2023; Zhang et al.
2024)。
为提升多类型伪造检测的识别精度与泛化能力,学界已探索了多种特征提取器和架构方案。部分研究聚焦于利用卷积神经网络(CNN)定位伪造区域(Zhuo
et al. 2022; Niloy,Kumar Bhaumik, and Woo
2023)。近期,Transformer模型(Vaswani et al.
2017)在下游计算机视觉任务中展现出优异性能(Jain et al. 2023; Li et
al.2023)。研究者还将其变体应用于伪造检测(Shi, Chen, and Zhang 2023; Wang
et
al.2022)。然而,考虑到性能与复杂度的平衡,究竟哪种架构更适合图像伪造定位,至今仍是悬而未决的难题。
此外,研究人员试图调查多个线索,例如,通过DCT(Bianchi,
De Rosa, and Piva 2011), SRM (Zhou et al. 2018)和高斯的拉普拉斯矩阵(Guo
et al. 2023)以提供附加信息并协助RGB功能。在(Guillaro et al.
2023),研究者提出了另一种视角,通过学习一种名为Noiseprint的“相机模型指纹”来提取低层次伪影。这种指纹记录了相机内部处理步骤的痕迹,并通过孪生网络技术实现获取。Noiseprint++是Noiseprint的升级版本,能够应对更具挑战性的场景。不过在图像伪造定位任务中,当处理不同分辨率的图像时,Noiseprint++的具体部署方式仍是一个未解决的问题。
本文提出了一种新型的图像伪造定位网络——MUN(Image
forgery
LocalizationNetwork),该网络由M3编码器和UN解码器组成,如图1所示。在研究过程中,我们首先需要解决的核心问题是:哪种网络架构更适合图像伪造定位任务。为此,我们选取了三个前沿网络模型进行对比测试,包括基于卷积神经网络的ResNet(He
et al. 2016)、基于卷积神经网络的ConvNeXt V2(Woo et al.
2023),以及基于Transformer架构的Swin网络(Liu et al.
2021)。实验结果表明,在参数量级相近的情况下,ConvNeXt
V2不仅准确率更高,还能有效降低计算成本。基于相同的骨干网络架构(即ConvNeXt
V2),我们探讨了Noiseprint++在三种应用场景下的部署效果:“原始尺寸调整”、“调整尺寸后应用Noiseprint++”以及“先调整尺寸再应用Noiseprint++”。实验结果表明,“先调整尺寸后应用Noiseprint++”方案表现最优。通过充分对比不同骨干网络与Noiseprint++的性能差异,我们构建了双流特征提取器,并提出多尺度最大池化查询模块(MMQ,Multi-scale
Max-pooling
Qurey),该模块能有效增强RGB特征与Noiseprint++特征之间的强关联性。得益于Multiclue多尺度最大池化的特性,我们的特征提取器被命名为\({\mathnormal
M}^3\)编码器。为了获得充足的层次特征,我们从M3编码器中选择层次输出,并将其输入到一个精心设计的双分支解码器中,即UN解码器。在UN解码器中,分层特征图被划分为U分支和N分支。在U分支中,我们通过轻量级的连续卷积层结合残差和拼接操作,从低层级特征图中提取富含空间信息的低阶特征,并将这些特征逐级传递以融合其他高层级特征。类似地,我们通过相同的连续卷积层从高层级特征图中提取高阶特征,并将其传递至下游与其他特征融合。随后,我们将U分支和N分支的特征拼接以重建预测掩膜。此外,我们设计了动态损失函数——即IoU重校准动态交叉熵(IoUDCE)损失,通过批量调整正负样本的类别权重,引导MUN自适应地聚焦难以处理的操控区域。最后,我们提出了一种名为偏差噪声增强(DNA)的新数据增强方法,通过调整训练图像的RGB分布来增强MUN的泛化能力。我们的贡献可总结如下:
- 提出了一种基于M3编码器和UN解码器的新型图像伪造定位网络,即MUN。
- 我们提出了一种M3编码器,该编码器配备了双流ConvNeXt V2特征提取器,用于从RGB和Noiseprint++域中提取特征。同时,我们提出了MMQ模块来整合双域特征。我们验证了Noiseprint++的部署方法。
- 提出了一种从并行的U和N分支中提取低阶和高阶信息的UN解码器,从而能够提取更微妙的伪造特征。
- IoUDCE损失的提出是为了根据预测掩膜的IoU动态平衡权重,并专注于难以处理的伪造区域。
- DNA通过缩小合成训练图像与通用图像之间的差距来增强泛化能力。
- 实验表明,MUN不仅适用于人工篡改的数据集,也适用于人工智能生成的数据集。
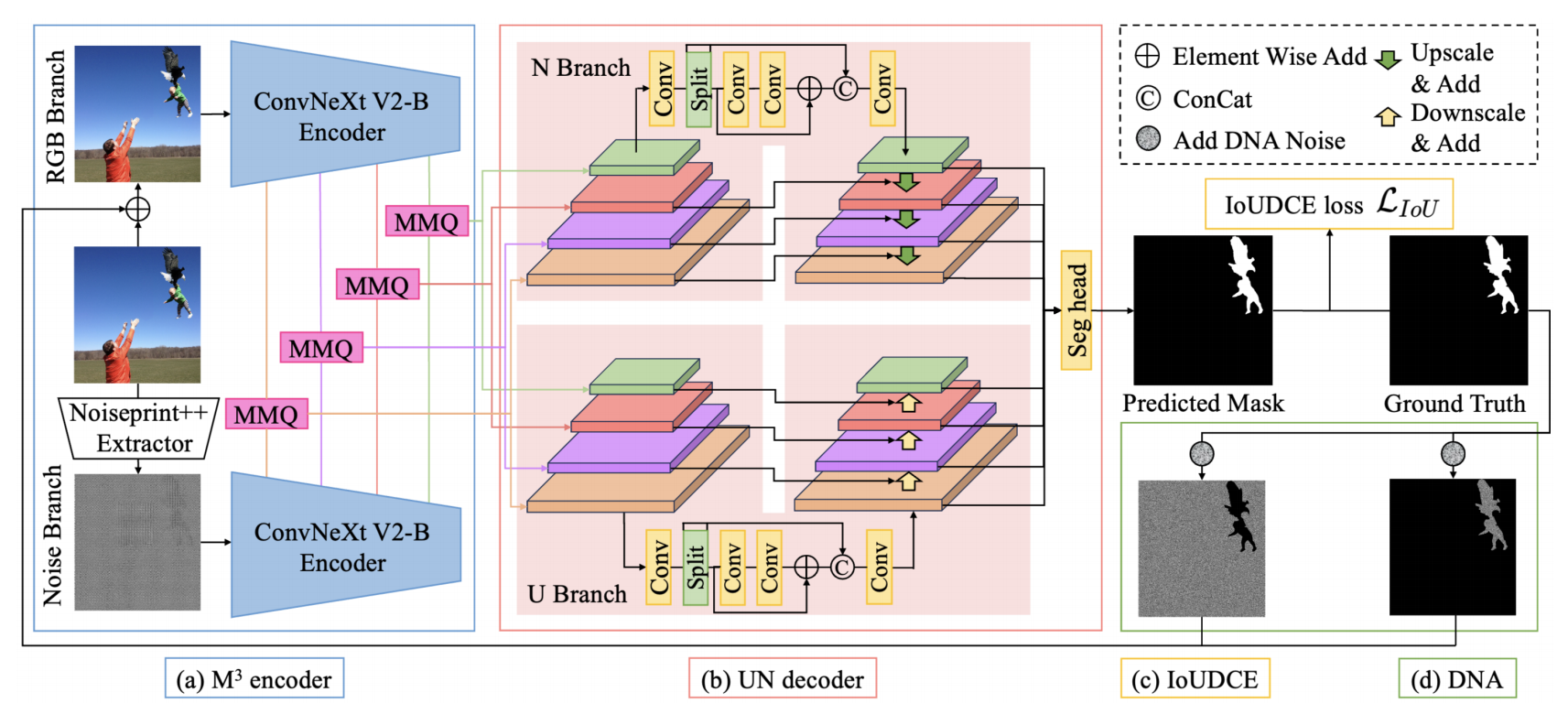
图1:MUN框架。(a) M3编码器包含RGB分支和噪声分支。两个分支的特征图均由ConvNeXt V2提取,多线索特征通过MMQ模块进行整合。(b) UN解码器具有并行的U和N分支,可整合来自MMQ的层级化特征图。整合后的特征图通过拼接重建预测掩膜。(c) IoUDCE损失函数对伪造区域的权重进行动态校准。(d) DNA模块通过将训练图像与通用图像间的RGB均值差异相乘,生成均匀噪声并加以叠加。
2.相关工作
传统的图像伪造定位方法主要分为高级方法和低级方法两大类。在高级方法中,通常会分析高层次语义信息。例如,原始图像与伪造图像可能呈现不同的光影效果(Peng
et al. 2016),透视和几何特性可判断物体是否接触(Peng et al.
2017),而模糊类型的不一致性也可能为伪造定位提供线索(Bahrami et al.
2015)。低级方法则通过人工设计的特征分析像素级统计差异,常见的低级特征包括:PRNU(照片响应非均匀性)反映图像传感器响应电压不均的现象(Korus
and Huang
2017),CFA(彩色滤光阵列)由微小彩色滤光片组成的马赛克结构用于捕捉色彩信息(Popescu和Farid,2005),SRM(空间丰富模型)利用相邻噪声残差样本的统计特征来捕捉依赖关系变化(Zhou等人,2018)。近年来,随着深度学习技术的蓬勃发展,基于深度学习的图像伪造定位已成为主流方法。
研究人员提出了多种基于卷积神经网络(CNN)的图像伪造检测方法。(Liu
et al.
2018)提出基于CNN的多尺度篡改检测器,通过生成一系列互补的篡改可能性图来实现检测。(Niu
et al.
2021)采用主量化矩阵的局部估计技术区分伪造区域,并对图像块进行聚类处理以优化预测结果。(Zhang
et al.
2024))提出的CSR-Net模型则通过参数化方法,从回归分析的角度出发,自适应地拟合目标分割区域,从而有效完成图像伪造定位任务。
Transformer技术持续推动图像伪造定位领域的突破。ObjectFormer通过融合Transformer层的高频特征与RGB特征,有效捕捉图像块层面的一致性特征(Wang
et al.
2022)。TBFormer运用视觉Transformer从RGB域和贝叶斯噪声域双重维度提取篡改痕迹(Liu
et al.
2023)。TANet则采用堆叠式多尺度Transformer分支,在多个层级检测输入图像的结构化异常特征(Shi,
Chen, and Zhang 2023)。
3.方法
我们的MUN系统由M3编码器和UN解码器构成。该系统在DNA数据增强后的合成伪造图像上,采用IoUDCE损失函数进行训练。首先介绍我们提出的MMQ架构作为M3编码器的核心模块,随后详细阐述UN解码器的设计原理。在完整呈现主架构后,我们将重点解析IoUDCE损失函数的特性及其与DNA方法论的关联性。
3.1. \(M^3\)编码器
M3编码器通过RGB域和Noiseprint++(NPP)域获取特征线索。RGB域可提供对比度差异和真实区域与伪造区域之间不自然边界等线索,而Noiseprint++则能获取相机型号、图像编辑历史等底层特征。在我们的机器视觉网络(MUN)中,RGB图像与Noiseprint++地图分别输入到两个并行的ConvNeXt
V2(Woo等人,2023)特征提取器。来自这两个域的中间层级特征由MMQ模块整合,该模块利用RGB域特征对噪声特征进行多尺度最大池化查询。
为探索Noiseprint++的正确使用方法,我们设计了三种操作版本:“调整尺寸”、“调整尺寸后使用Noiseprint++”和“调整尺寸前使用Noiseprint++”。其中“调整尺寸后使用Noiseprint++”表现最佳。具体流程如下:将RGB图像\({\mathbf I}_{RGB}\in{\mathbb R}^{H_o\times
W_o\times 3}\)输入Noiseprint++模块,生成噪声图\({\mathbf I}_{NPP}\in{\mathbb R}^{H_o\times
W_o}\),其中Ho和Wo分别表示图像的原始高度和宽度。接着沿通道维度复制\({\mathbf I}_{NPP}\),得到\({\dot{\mathbf I} }_{NPP}\in{\mathbb R}^{H_o\times
W_o\times 3}\)。随后对\({\mathbf
I}_{RGB}\)和\({\dot{\mathbf I}
}_{NPP}\)进行尺寸调整,最终获得调整后的RGB图像\({\mathbf {\bar I}}_{RGB}\in{\mathbb R}^{H\times
W\times 3}\)和Noiseprint++图\({\mathbf
{\bar I}}_{NPP}\in{\mathbb R}^{H\times W\times
3}\),H和W分别代表输入图像的高度和宽度。
在构建ConvNeXt
V2网络时,我们同时从RGB域和Noiseprint++域获取特征。两个ConvNeXt
V2分支采用相同架构但权重不共享,从而能更专注于各自的特征提取任务。我们分别选取两个分支的第3、6、33和36层输出作为中间特征图。其中C
= {C(0),C(1),C(2),C(3)}表示RGB域的层级特征,N =
{N(0),N(1),N(2),N(3)}表示噪声域的层级特征。
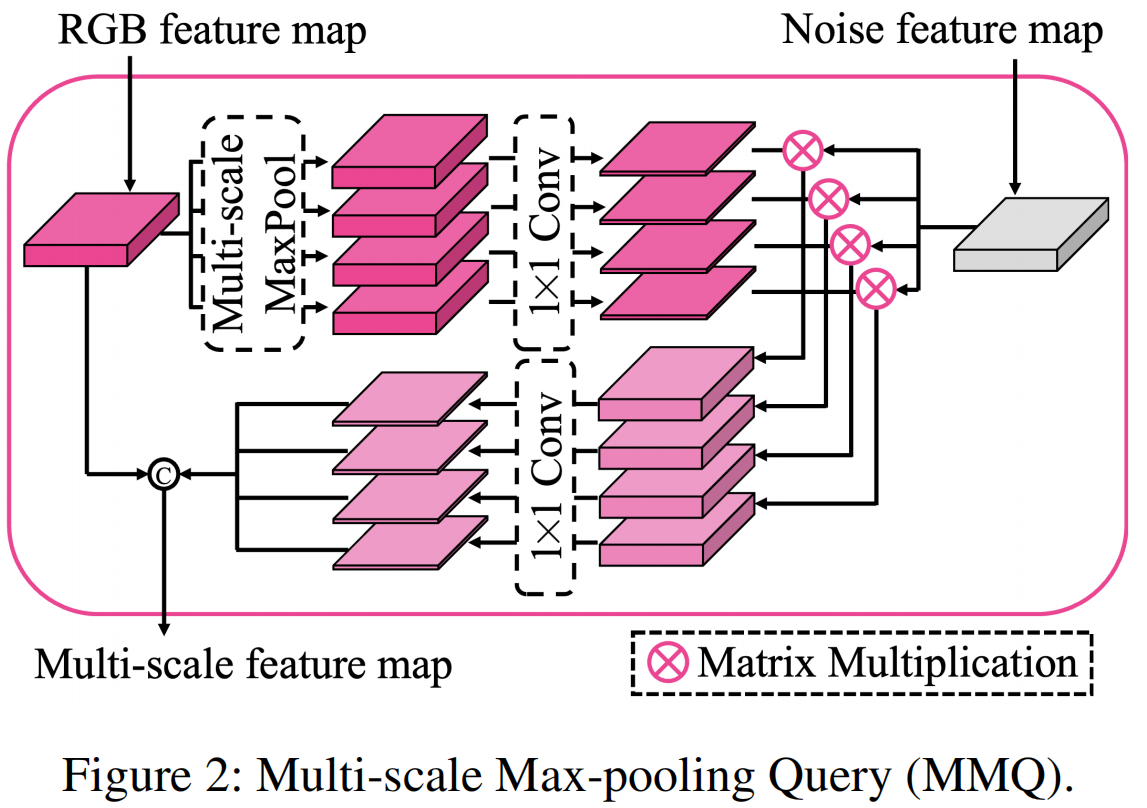
为探究RGB域与噪声域之间的关联性并整合二者特征,我们构建了如图2所示的多尺度最大池化查询(MMQ)模块。以C(0)和N(0)为例,对RGB特征图C(0)执行四个不同核尺寸的最大池化操作后接1×1卷积运算,最终得到Q(0)={Q(0)k×k}。该过程可表述为: \[{\bf Q}_{k\times k}^{(0)}=C o n v_{1\times1}(M a x P o o l i n g_{k\times k}({\bf C}^{(0)}))\] 其中k×k表示最大池化核的尺寸,k∈{1,5,11,15},Conv1×1表示1×1卷积,\(MaxPooling_{k\times k}\)表示使用k×k核的最大池化。\({\bf Q}_{k\times k}^{(0)}\)包含k×k尺度上的最显著局部特征。我们通过计算\({\bf Q}_{k\times k}^{(0)}\)与Noiseprint++特征图N(0)的矩阵乘积来执行多尺度查询操作: \[\dot{\mathbf Q}_{k\times k}^{(0)}={\mathbf Q}_{k\times k}^{(0)}\otimes\mathbf{N}^{(0)}\] 其中⊗表示矩阵乘法。之后,我们构建一个1×1的卷积来降低\(\dot{\mathbf Q}_{k\times k}^{(0)}\)的维度,得到\(\ddot{\mathbf Q}_{k\times k}^{(0)}\)。\(\dot{\mathbf Q}_{k\times k}^{(0)}\)的通道维度是\(\ddot{\mathbf Q}_{k\times k}^{(0)}\)的4倍。最后,我们将\(C^{(0)}\)与四个\(\ddot{\mathbf Q}_{k\times k}^{(0)}\)拼接起来,得到多尺度特征图。 \[\hat{\mathbf Q}_{\mathrm{exp}}^{(0)}=Concat(C^{(0)},\ddot{\mathbf Q}_{1\times 1}^{(0)},\ddot{\mathbf Q}_{5\times 5}^{(0)},\ddot{\mathbf Q}_{11\times 11}^{(0)},\ddot{\mathbf Q}_{15\times 15}^{(0)})\] 其中Concat表示沿通道维度进行拼接。对C(1)、C(2)、C(3)和N(1)、N(2)、N(3)进行相同的MMQ模块处理,从而获得Qˆ(1)、Qˆ(2)、Qˆ(3)。通过多尺度最大池化查询,我们能够构建RGB域与NPP域之间的复杂关系。从M3编码器提取的特征图可表示为Qˆ={Qˆ(0),Qˆ(1),Qˆ(2),Qˆ(3)}。
3.2. UN 解码器
我们设计了一种UN解码器,该解码器从两个相反方向提取层次特征。UN解码器包含U分支和N分支两个子结构,每个分支都拥有特征图的克隆副本Qˆ。我们对这两个分支执行相似但相反的操作:对于U分支,低层通道Qˆ(0)通过轻量级连续卷积层生成BU(0)。具体操作中,首先通过1×1卷积模块将Qˆ(0)的通道维度翻倍,然后将其拆分为通道维度相同的X0和X1张量。这种拆分操作旨在降低计算成本并提升表征能力。接着,我们将X1依次通过两个模块\(f_{3\times3}^{C o n
v}\)处理,最终得到X‘。卷积模块\(f_{3\times3}^{C o n
v}\)由3×3卷积层、批量归一化层和SiLU激活层组成。然后,我们对X0、X1和X′进行积分,得到BU(0):
\[\mathbf{BU}^{(0)}=f_{1\times1}^{c o n v}(C
o n c a t({\bf X}_{0},{\bf X}_{1},f_{3\times3}^{C o n v}(f_{3\times3}^{C
o n v}(\bf X_{1}))+\bf X_{1}))\] 其中\(f_{1\times1}^{c o n
v}\)表示带有批量归一化和SiLU激活函数的1×1卷积模块。接着我们对U分支中的特征进行自底向上更新与融合:
\[\mathbf{BU}^{(i+1)}=\mathbf{\hat
Q}^{(i+1)}+f_{3\times3}^{C o n v\downarrow}(\mathbf{BU}^{(i)})\]
其中i表示第i个特征图,i∈{0,1,2},\(f_{3\times3}^{C o n
v\downarrow}\)表示一个下采样卷积模块,包含批量归一化层和SiLU层。因此,我们得到U分支的特征图BU
=
{BU(0),BU(1),BU(2),BU(3)}。
与U分支的处理流程类似,我们通过提取高层特征Q(3)构建了另一个连续卷积层来获得TD(3)。首先将Q(3)的通道维度翻倍,然后将其拆分为两个通道维度相同的张量Y0和Y1。经过\(f_{3\times3}^{C o n
v}\)卷积模块处理后,从Y1中得到Y‘。将Y’与Y1相加后,再与Y0、Y1进行拼接,并通过1×1卷积模块处理以获得TD(3)。接着我们采用自上而下的方式更新并融合N分支的特征,即\({\bf T D}^{(i-1)}\ =\hat{\bf Q}^{(i-1)}+R e s i z
e({\bf T D}^{(i)}),i\in\{1,2,3\}.\),最终生成TD =
{TD(0),TD(1),TD(2),TD(3)}。在此过程中,我们通过双线性插值操作在Resize阶段扩展了特征尺寸。值得注意的是,U分支和N分支中的两个连续卷积层并不共享相同权重——U分支注重细节特征,而N分支则聚焦全局抽象特征。
在完成所有这些操作后,我们将同一层级的BU和TD进行拼接,以获得联合层级特征UN
= {UN(0),UN(1),UN(2),UN(3)},具体如下: \[\mathbf{UN}^{(i)}=Resize(f_{1\times1}^{c o n
v}(Concat(\mathbf{BU}^{(i)},\mathbf{TD}^{(i)})))\]
当四个UN(i)的尺寸与UN(0)相同,我们将UN拼接后输入一个3×3卷积模块、一个1×1卷积层和一个尺寸调整操作,从而获得预测掩膜M∈R(Ho×Wo):
\[\mathbf{M}=Resize(C o n
v_{1\times1}(f_{3\times3}^{C o n v}(Concat(\mathbf{UN})))\]
3.3. IoUDCE 损失
我们提出一种经过IoU校准的动态交叉熵损失函数(IoUDCE),该函数可在训练过程中动态调整正负样本预测的类别权重。设GT∈R Ho×Wo表示伪造图像的真实标签,其中GT中伪造部分为1,原始部分为0。我们将GT和M进行尺寸调整,分别得到GTb∈R H×W和Mb∈R H×W,并通过将Mb中大于0.5的部分设为1、小于0.5的部分设为0的方式对Mb进行二值化处理。IoUDCE损失函数的计算公式如下: \[\beta_{I o U}=\sum_{i}^{B}\frac{\mathbf{G T}_{b}(i)\cap\mathbf{M}_{b}(i)}{\mathbf{G T}_{b}(i)\cup\mathbf{M}_{b}(i)}\]
\[\mathcal{L}_{I o U}=-\frac{1}{B}\frac{1}{H W}\sum_{i=1}^{B}\sum_{i=1}^{H W}(\alpha_{0}(1-y(i,j))\times\;\log(1-p(i,j))+\alpha_{1}\times\;e^{\lambda(1-\beta_{I o v})}y(i,j)\log p(i,j))\]
其中B表示批量大小,∩和∪分别表示交集和并集,y(i,j)表示批量中第i张图像的第j个真实标签,p(i,j)表示批量中第i张图像在伪造时的第j个预测分数。α0、α1和λ是超参数。
当预测掩膜与真实掩膜差异较大时,1−βIoU值往往会增大,这会导致正类区域的权重增加,并引导MUN模型更加关注这些区域。随着训练过程的进行,预测掩膜与真实掩膜之间的差异逐渐缩小,导致1−βIoU趋近于0,正类权重也趋于α1。当然,当我们遇到βIoU较小的“差批”图像时,可以适当提高正类区域的权重。
3.4. 偏差噪声增强
我们提出偏差噪声增强(Deviation Noise Augmentation,DNA)技术,其核心假设是:模型在数据集分布与训练集更接近时更容易获得更好效果。DNA的核心思想在于缩小通用图像与训练图像之间的分布差异。我们选择RGB通道的均值作为可区分的分布基准。首先计算训练数据集各RGB通道的均值mt = {mt R,mt G,mt B},以及ImageNet(Deng等人,2009)的均值mu = {mu R,mu G,mu B}——因为我们认为ImageNet能够代表现实世界中的通用图像。接着从mu中减去mt,得到差异项d = {dk},其中dk=mu k−mt k,k∈{R,G,B}。我们假设处理图像中的原始部分和伪造部分都遵循通用图像的分布规律,因此生成两个均匀分布的噪声向量Np∈R H×W×3和Nf∈R H×W×3。将GTb沿通道维度复制得到GTˆb∈R H×W×3,并在对应通道上分别用特定的dk值乘以Np和Nf,最终得到Nˆp∈R H×W×3和Nˆf∈R H×W×3: \[\mathbf{\hat{N}}_{p}=C o n c a t(d_{R}{\mathbf N}_{p}(0),d_{G}{\mathbf N}_{p}(1),d_{B}{\mathbf N}_{p}(2))\]
\[\mathbf{\hat{N}}_{f}=C o n c a t(d_{R}{\mathbf N}_{f}(0),d_{G}{\mathbf N}_{f}(1),d_{B}{\mathbf N}_{f}(2))\]
其中Np(i)和Nf (i)分别表示Np和Nf的第i维。然后我们在ˆGTb和ˆNp的原始部分以及GTˆb和Nˆf的伪造部分上执行交集操作,以获得IDNA∈R H×W×3如下所示: \[\mathbf{I}_{D N A}={\bar{\mathbf{I}}}_{R G B}+(\hat{\bf N}_{p}\circ(\hat{\mathbf{G}}\mathbf{T}_{b}=0))+(\hat{\bf N}_{f}\circ(\hat{\mathbf{G}}\mathbf{T}_{b}=1))\] 其中◦表示Hadamard乘积
4.实验
4.1 实施和评估细节
实施细节
MUN基于MMSegmentation构建。我们使用Noiseprint++生成原始尺寸图像的噪声图,随后将图像和噪声图均调整为512×512的块作为输入。优化器采用随机梯度下降(SGD),其学习策略可按以下方式计算:
\[lr_c=\begin{cases}l r_{s}+(l r_{0}-l
r_{s})\times{\frac{i t e r_{c}}{i t e r_{w}}},&i t e r_{c}\lt i t e
r_{w}\\l r_{0}\times(1-\frac{1}{i t e r_{t}-i t e r_{c}+1}),&i t e
r_{c}\gg i t e r_{w}\end{cases}\]
其中lrc表示当前学习率。初始学习率设定为lrs=10−6,初始学习率为lr0 =
0.01,iterc代表当前迭代次数,iterw =
1500表示预热迭代次数,itert则代表总迭代次数。在公式(9)中,参数α0和α1均设为1.0,而λ设为1.5。批量大小为7,训练周期为4。我们的训练和推理实验均在单块NVIDIA
GeForce RTX 4090显卡上完成。
实验数据集
我们在合成数据集(Liu et al.
2023)上训练模型,并采用五个数据集进行评估:NIST16(Guan et al.
2019)、CASIA v1.0(Dong, Wang, and Tan 2013)、IMD2020(Novozamsky,
Mahdian, and Saic 2020)、CocoGlide(Guillaro et al. 2023)和Wild(Huh et
al.2018)。合成数据集基于CASIA v2.0(Wei et al. 2022)和ADE20k(Zhou et
al.2019)构建,包含剪切、复制移动和移除篡改图像。该合成数据集共有156,006张合成图像(训练集140,432张,验证集7,787张,测试集7,787张)。NIST16和IMD2020包含剪切、复制移动和移除图像,CASIA
v1.0仅包含剪切和复制移动图像,而Wild仅包含剪切图像。CocoGlide是基于GLIDE扩散模型(Nichol等人,2022)生成的AI数据集。
实验性指标
我们采用F1分数、交并比(IoU)、准确率和曲线下面积(AUC)作为评估指标,这些指标在图像伪造检测领域具有广泛应用(Guillaro
et al.
2023)。在对预测掩膜进行二值化处理时,我们固定采用0.5作为阈值。
4.2 与最先进方法的比较
我们将MUN与最近的SOTA工作进行比较,包括RGB-N (Zhou et al. 2018), ManTra-Net (Wu, AbdAlmageed, and Natarajan 2019), SPAN (Hu et al. 2020),MVSS-Net (Chen et al. 2021), PSCC-Net (Liu et al. 2022a),ObjectFormer (Wang et al. 2022), TANet (Shi, Chen, and Zhang 2023), TBFormer (Liu et al. 2023), HiFi (Guo et al. 2023), TruFor (Guillaro et al. 2023), CSR-Net (Zhang et al. 2024), NRL-Net (Zhu et al. 2024) and MGQFormer (Zeng et al. 2024)
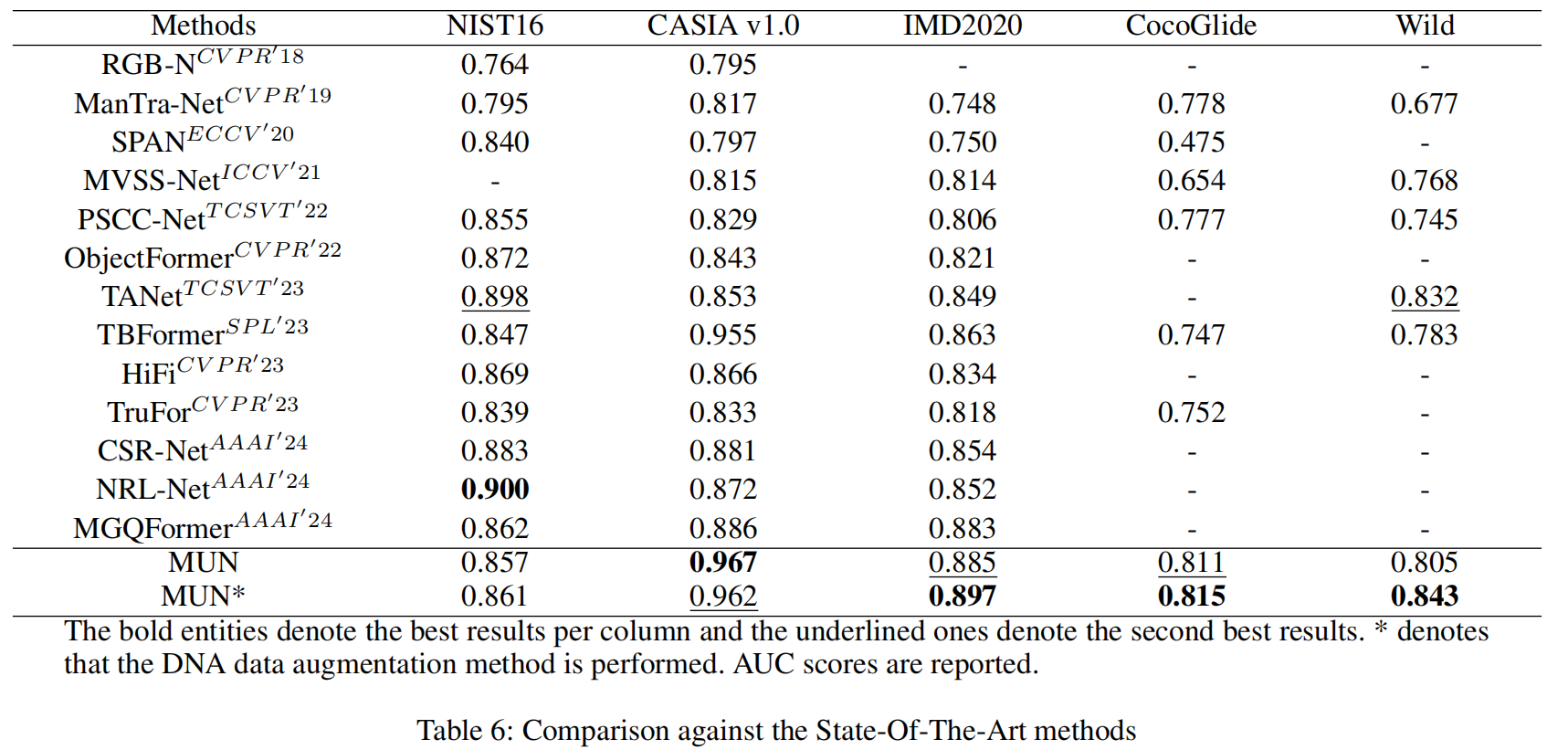
表6展示了上述模型在NIST16、CAISA v1.0、IMD2020、CocoGlide和Wild数据集上的测试结果,评分数据均引自各研究论文。从表6可以看出,MUN模型在多数数据集上表现更优。由于Noiseprint++在处理NIST16超高清图像时需要占用大量GPU内存,我们首先将图像分割为九个区块进行单独处理,这种操作可能导致其在NIST16上的评分有所下降。CocoGlide采用GLIDE扩散模型生成,其优异表现表明MUN模型具备处理AI生成的篡改图像的能力。

图4中展示了视觉比较结果,第一列和第四列中,部分被比较的方法无法检测到被操作的区域,MUN可以准确地定位这些区域。在第2、3列中,比较的方法不能检测到准确的边界或漏掉一些伪造区域,MUN具有更高的定位精度,可以更精确地提取这些篡改区域的边界。
此外,我们还评估了使用DNA数据训练的MUN版本(即MUN*)。如表6底部所示,MUN*在大多数数据集上都能取得更优表现。其在CASIA
v1.0数据集上的性能下降原因在于:该数据集的分布特征与我们的训练数据集高度相似,而DNA技术有效拉大了两者之间的差异。总体而言,DNA技术不仅能提升MUN的性能表现,还能增强其泛化能力,且无需针对每个测试集进行单独微调即可实现。
5.结论
我们提出名为MUN的图像伪造定位网络。在M3编码器中,两个ConvNeXt V2分支作为多线索提取器,从RGB和Noiseprint++两个维度提取伪造痕迹;MMQ模块则构建显著局部RGB特征与噪声域之间的关联。UN解码器能够学习自上而下和自下而上的层次化特征,并重建预测掩膜。IoUDCE损失函数通过交并比动态调整类别权重,引导网络聚焦难以处理的篡改区域。DNA算法缩小了训练图像RGB分布与通用图像之间的差距,显著提升了MUN的泛化能力。实验结果表明,MUN性能优于现有最优方法。未来可通过整合更多线索增强MUN,进一步探索如何识别最能涵盖各类图像分布的噪声类型,并研究其与频域信息的关联性。