Pixel-Inconsistency Modeling for Image Manipulation Localization

Pixel-Inconsistency Modeling for Image Manipulation Localization
Chenqi Kong , Member, IEEE, Anwei Luo , Shiqi Wang , Senior Member, IEEE, Haoliang Li , Member, IEEE,Anderson Rocha , Fellow, IEEE, and Alex C. Kot , Life Fellow, IEEE
摘要
数字图像取证在图像认证与篡改定位领域发挥着关键作用。尽管深度神经网络技术取得了显著进展,但现有伪造定位方法在处理未知数据集和受干扰图像时仍存在局限性(即缺乏普适性和对实际应用的鲁棒性)。为解决这些问题并保障图像完整性,本文通过分析像素不一致伪影,提出了一种通用且稳健的篡改定位模型。这一理论依据源于一个观察:大多数图像信号处理器(ISP,image signal processors)都会进行去马赛克处理,这会导致原始图像中出现像素相关性。此外,诸如拼接、复制移动和修复等操作会直接影响这种像素规律性。因此,我们首先将输入图像分割成多个区块,并设计了掩码自注意力机制来模拟输入图像中的全局像素依赖关系。与此同时,我们优化了另一条局部像素依赖流,用于挖掘输入伪造图像中的局部操作线索。此外,我们设计了新型学习加权模块(LWM,Learning-to-Weight Modules)来整合两条信息流的特征,从而提升最终的伪造定位性能。为优化训练过程,我们提出了一种创新的像素不一致性数据增强(PIDA,Pixel-Inconsistency Data Augmentation)策略,促使模型专注于捕捉固有的像素级伪影特征,而非单纯挖掘语义层面的伪造痕迹。本研究构建了一个综合性的基准测试框架,整合了12个数据集中的16种代表性检测模型。大量实验表明,我们的方法能够有效提取像素不一致性特征的固有特征,在图像篡改定位任务中展现出最先进的泛化能力和鲁棒性表现。
I.引言
图像伪造技术自摄影诞生之初便已存在[3]。近几十年来,拼接、复制移动和修复等图像处理技术取得重大突破,这三种技术虽普遍却臭名昭著[87](如图1所示)。这些技术能生成高度逼真的伪造内容,模糊真伪图像的界限。其痕迹极其微妙,肉眼几乎难以察觉。随着数字图像在互联网上的广泛传播,恶意攻击者利用现成的强大图像编辑工具(如Photoshop、After
Effects
Pro、GIMP以及最新推出的Firefly)发起伪造攻击变得愈发容易。这些精心制作的内容可用于实施欺诈、制造假新闻及敲诈勒索。图像伪造无疑动摇了公众对媒体内容的信任,而伪造品的泛滥更引发了社会对网络安全的深切担忧。因此,设计有效的图像伪造定位模型以应对这些问题至关重要。
早期图像篡改定位技术主要依赖先验知识进行特征提取,例如镜头畸变[28],[32],[46],[67],[96],[96],色彩滤波阵列(CFA)伪影[10],[25],[29],[38],[76],噪声模式[17],[22],[48],[64],[65],[75],压缩伪影[6],[9],[15],[23],[27],[43],[73].。然而这些传统方法存在精度和泛化能力不足的问题。随着深度学习与人工智能的突破,基于学习的检测器应运而生,在域内图像伪造定位方面展现出优异性能。但数据驱动方法普遍存在过拟合训练数据的缺陷,导致鲁棒性和泛化能力受限——具体表现为对图像扰动异常敏感,且难以应对未知的图像篡改数据集。
提取通用且稳健的图像伪造特征以实现精准定位仍是业界面临的重要挑战。本文重构了传统图像处理流程,提出一种新型伪造检测框架,通过捕捉图像中的像素不一致性实现精准识别。
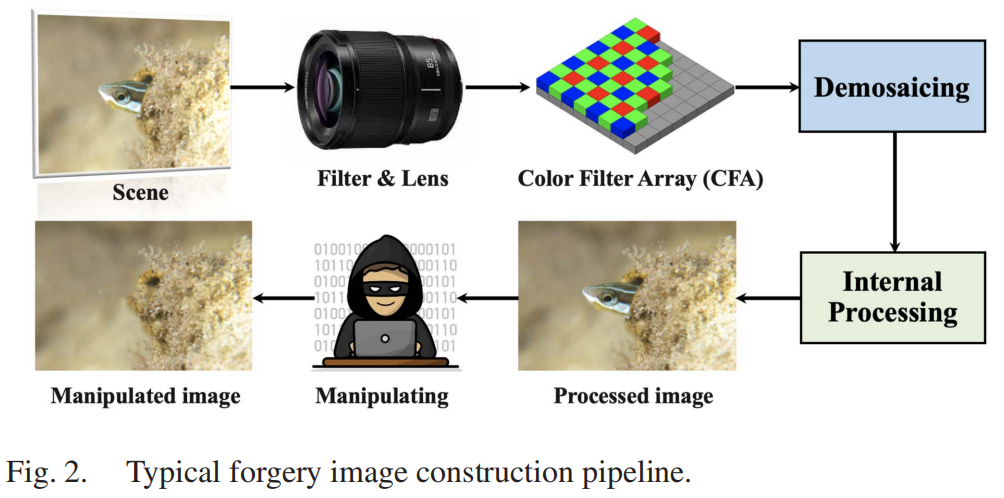
图2展示了典型的伪造图像生成链:滤光片与镜头将非目标光线聚焦至传感器,随后应用色彩滤光阵列(CFA)提取单色分量。在相机内部处理阶段,系统执行去马赛克(即色彩插值)等软件操作,通过周边单色像素重建全彩图像。后续进行色彩校正、降噪和压缩等内部处理步骤,最终生成RGB图像。值得注意的是,恶意攻击者可利用图像编辑工具在后期处理中篡改原始图像,这些操作会破坏去马赛克操作引入的像素相关性(即,扰动周期性图案),从而在取证分析中留下明显的像素不一致性痕迹[10]、[76]、[87]。
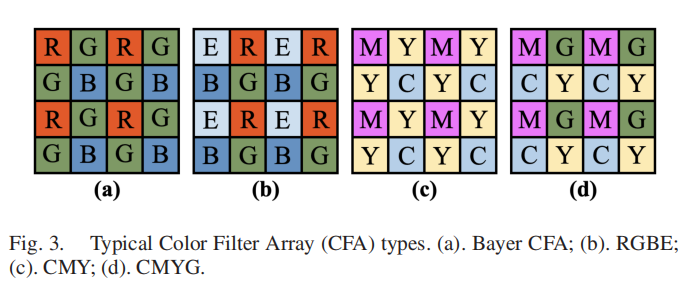
图3展示了四种典型的色彩滤波算法类型:(a)Bayer
CFA、(b)RGBE、(c)CMY、(d)CMYG。色彩滤波技术能够实现每个像素点对特定颜色的精准捕捉。因此,在生成的RAW图像中,每个像素点仅保留单一颜色信息,而去马赛克处理则会重建缺失的颜色样本。现有用于伪造指纹提取的法证分析技术主要聚焦于不同图像规律性的数学建模。例如,Popescu等人[76]量化了CFA插值引入的特定相关性,并描述了如何自动检测这些相关性。Ferrara等人[25]提出了一种新颖特征,通过最小2×2块级测量这些图像规律性的存在与否,从而预测伪造概率图。在[11]和[55]的研究中,则采用线性回归方法对块内指纹进行建模。尽管这些像素相关性建模方法在法证分析中效果显著,但多数仍需将CFA类型作为先验信息。此外,这些方法难以充分捕捉现代AI相机中智能图像信号处理器(ISP)引入的更复杂规律性。
与现有技术不同,我们基于这一洞见提出了一种基于学习的方法,用于捕捉伪造图像中的固有像素不一致性。为此,我们设计了一个双流像素依赖建模框架来实现图像操作定位。受近期自回归模型(如PixelCNN
[85]、[86])在各类计算机视觉任务中取得的成功启发,我们开发了掩码自注意力机制来建模输入图像中的全局像素依赖关系。此外,我们还设计了差异卷积(DC,Difference
Convolution)流以捕捉局部图像区域内的像素不一致性伪影。同时,我们引入了创新的权重学习模块(LWM,Learning-to
Weight
Modules),将这两个流中的全局与局部像素不一致性特征进行融合。
我们设计了三种解码器来预测潜在篡改区域、伪造边界及重建图像。最终引入像素不一致性数据增强(PIDA,Pixel-Inconsistency
Data
Augmentation)策略,用于探索像素级伪造痕迹。PIDA是一种仅依赖真实图像进行数据增强的有效方法,它引导模型专注于捕捉像素不一致性伪影而非语义伪造痕迹。该框架采用端到端训练方式,通过二值掩膜和边界标签的联合监督实现优化。
我们的工作主要贡献是:
- 我们构建了一个全面的基准测试框架,用于评估16种代表性图像伪造定位方法在12个数据集上的泛化能力。该框架进一步扩展至六种未知图像扰动类型(每种包含九个严重程度等级)的鲁棒性评估。此外,我们还针对现代人工智能生成内容(AIGC)技术产生的复杂高级操作,对设计模型进行了性能验证。
- 我们设计了一个双流图像篡改定位框架,包含局部像素依赖编码器、全局像素依赖编码器、四个特征融合模块和三个解码器。该模型能够有效提取像素不一致性伪造特征,从而实现更通用且鲁棒的篡改定位性能。
- 我们提出了一种像素不一致性数据增强策略,该策略完全利用真实图像来生成数据。这种数据增强方法促使模型专注于捕捉固有的像素级伪影,而非语义伪造线索,从而显著提升了伪造定位的性能表现。
- 大量定量和定性实验结果表明,我们提出的方法在泛化能力和鲁棒性评估中始终优于现有最先进方法。全面的消融实验进一步验证了设计组件的有效性。
第二部分概述了图像伪造定位与像素依赖建模领域的前期研究成果。第三部分详细阐述了本文设计的框架体系。第四部分在多种实验场景下展示了全面的评估结果。最后,第五部分对全文进行总结,并探讨了当前存在的局限性及未来可能的研究方向。
II.相关工作
本节将对图像伪造检测与定位领域的现有研究进行综述,包括人工设计方法和基于学习的方法。同时,我们还将回顾像素依赖性建模及其应用的相关研究。
A.使用低等级痕迹的操纵检测和定位方法
图像篡改检测并非新问题。早期方法主要针对相机内部处理痕迹产生的低级伪影进行识别。例如,复杂光学系统缺陷导致的镜头畸变[28],[32],[46],[67],[96],[96],可视为取证领域的独特指纹。色差作为典型镜头畸变特征,已被广泛应用于防伪检测[46],[67],[96].。此外,许多方法[10],[11],[25],[76]通过捕捉滤色阵列(CFA)伪影来检测操作痕迹。这些技术表明,篡改行为会破坏去马赛克处理过程中形成的周期性图案。同时,由于光响应不均匀性(PRNU)具有机型特异性,部分方法[48],[64],[65]通过提取查询图像中的噪声模式来检测数字篡改痕迹。此外,学界已投入大量研究致力于分析JPEG压缩伪影在离散余弦变换(DCT)域[9]、[15]、[23]、[24]、[73]中的残留特征,用于图像伪造检测。尽管这些传统图像篡改检测方法具有可解释性和计算效率优势,但多数仍存在检测精度不足和泛化能力有限的问题。为了实现准确、通用和可解释的图像伪造定位,我们在本文中引入了一个基于学习的框架,旨在捕捉低级像素不一致的伪影。
B.基于学习的操纵检测与定位方法
近年来,图像取证领域取得显著进展。为解决伪造定位难题,各类基于学习的方法层出不穷,有效提升了检测性能。这些方法大多依托丰富的先验知识,例如噪声特征[18],[34],[103],CFA伪影特征[4]、JPEG特征[52],[78],[90]等进行检测。高频(HF)滤波器如隐写分析富模型(SRM)滤波器[94],[103]和拜耳滤波器[19],[94]也被用于捕捉大量高频伪造伪影。此外,通过检测伪造边界线[19],[81],像素级伪造检测效果得到显著提升。更有甚者,部分方法采用多尺度学习技术从不同层级提取伪造特征,从而大幅提升检测精度。与SPAN [40]通过金字塔形局部自注意力模块堆叠来捕捉多尺度图像块或像素间关系不同,我们的方法创新性地采用了三种核心模块:用于捕捉局部像素差异的掩码式自注意力全局像素依赖编码器、模拟长程像素关联的掩码式自注意力编码器,以及整合伪造特征的融合模块。这些组件的设计旨在更精准捕捉伪造图像中固有的像素不一致性伪影。得益于视觉变换器(ViT)的问世,基于ViT的检测器[58]、[89]凭借其长程交互特性与无归纳偏置的优势,在包括取证在内的多种场景中展现出卓越的检测性能。然而,这些数据驱动方法仍存在泛化能力和鲁棒性不足的问题。本文认为,伪造图像中的像素不一致性是各类篡改操作和数据集中普遍存在的一种伪影特征。因此,我们设计了一个新的图像伪造定位框架,通过捕捉像素不一致的伪影来实现更通用和鲁棒的伪造定位性能。
C.像素依赖性建模
自回归(AR)模型[14],[16],[31],[53],[72],[80],[85]在图像生成[31],[49],[85],、补全[14],[44],[72],和分割[71]等各类计算机视觉任务中取得了显著成效。这些AR方法旨在通过以下方式对每个像素的联合概率分布进行建模: \[\hat{a}_{i}\sim p_{\theta}(a_{i}|a_{1},\cdot\cdot\cdot,a_{i-1}).\] 这些模型采用特定的掩码卷积或掩码自注意力策略,使得当前像素的概率分布取决于生成序列中所有先前像素。像PixelCNN [85]和PixelRNN [86]这样的开创性AR模型,在图像生成领域展现了其在模拟自然图像长程像素依赖关系方面的有效性。为了进一步提高图像生成性能,引入了后续变化,例如PixelCNN++ [80]。此外,掩码自注意力机制还能辅助依赖关系建模,例如图像变换器[72]和稀疏变换器[16]。像素螺旋[14]通过将因果卷积与自注意力机制相结合,显著提升了图像生成效果。受像素依赖建模在各类生成任务中取得突破性进展的启发,我们尝试将这一概念拓展至法医分析领域。本文创新性地提出像素差异卷积与掩码自注意力机制,旨在捕捉局部与全局像素不一致性伪影。
III.提出的方法
本节将详细介绍我们提出的图像操作定位方法。首先阐述整体框架架构,接着深入解析各核心模块的设计原理与技术逻辑,包括全局像素依赖建模模块、局部像素依赖建模模块以及学习加权模块。最后重点介绍创新的像素不一致性数据增强策略及其独特优势。
A.总体框架
如图4所示,本文设计了一种双流图像操作定位框架。
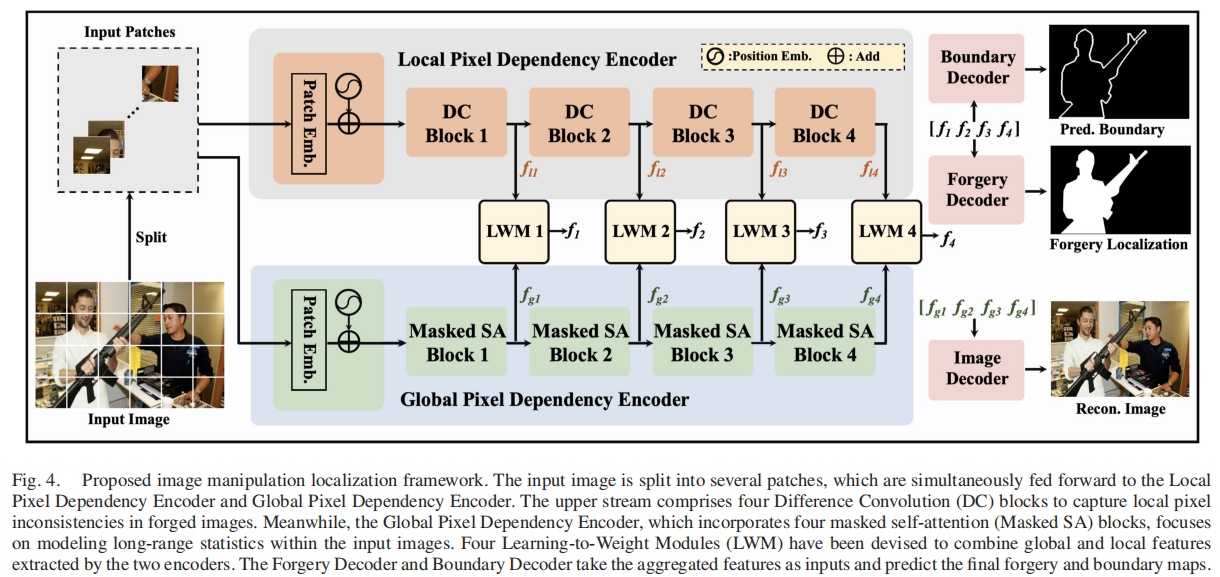
该框架的设计灵感源自一个观察发现:诸如拼接、复制移动和修复等图像处理过程,会不可避免地破坏去马赛克操作引入的像素规律性。该框架通过局部像素依赖编码器和全局像素依赖编码器,共同探索像素不一致性及上下文信息以实现操作定位。具体而言,输入图像首先被分割成多个块,随后由两个编码器进行并行处理。在块嵌入过程中,我们将输入图像分割为4×4像素的块。将每个补丁的原始像素RGB值展平为4×4×3
=
48的维度,然后将每个补丁标记投影到嵌入维度。直观来看,将单个RGB像素值嵌入单一标记有助于建模像素间的依赖关系。但这种方法会显著增加计算成本,因为标记数量将与图像的高度(H)和宽度(W)相等(本研究中H=W=512)。为解决这一问题并实现合理平衡,我们将补丁尺寸放宽至4×4,从而在计算效率与有效捕捉处理图像中的像素不一致性之间取得平衡。相较于单像素,4×4像素标记能提供更具表现力的表征。实验表明,采用这种补丁嵌入策略的方法成功捕捉了处理图像中的全局和局部像素不一致性。此外,我们在设计的transformer模块中引入多层感知机(MLP)层,以增强每个标记内部像素依赖关系的学习效果[56]、[84]。
为探索长程相互作用与无感应偏置特性,我们采用transformer架构作为两条信息流的主干网络。上层局部像素依赖编码器包含四个差分卷积(DC,Difference
Convolution)模块,专门用于捕捉局部区域的像素不一致性。下层全局像素依赖编码器则引入了四个创新的掩码自注意力模块,该机制能建模输入图像中的全局像素依赖关系。此外,我们设计了四个学习加权模块(LWM,Learning-to-Weight
Modules),在多层级结构中协同整合全局特征[fg1,fg2,fg3,fg4]与局部特征[fl1,fl2,fl3,fl4]。整个框架还集成了边界解码器、伪造解码器和图像解码器三大核心组件。
值得注意的是,像素不一致性在边界区域表现最为明显。为此,我们整合了边界辅助监督机制以提升最终伪造检测的定位精度。伪造解码器以组合特征[f1,f2,f3,f4]作为输入,用于预测图像中可能被篡改的区域;而图像解码器则以[fg1,fg2,fg3,fg4]为输入,致力于还原原始图像。最后,我们提出了一种新型的像素不一致性数据增强(PIDA)策略,该策略专注于像素不一致性而非语义伪造痕迹。这一策略进一步增强了模型的泛化能力和鲁棒性。
B.全局像素依赖性建模
本部分的目标是通过光栅扫描顺序对每个标记进行条件化处理,从而建模图像块间的全局像素依赖关系。因此,每个输出标记都会高度依赖所有先前“已观测”的像素。相较于单独处理单个像素,这种设计在计算效率上更具优势。考虑到图像中的空间冗余特性[36],该方法还能有效建模全局像素依赖关系。
受[14]和[72]模型的启发,这些模型通过注意力机制建模长期像素依赖关系,我们在像素全局依赖建模中引入了掩码自注意力(Masked
SA)模块,其设计风格与自注意力机制类似。图4展示了全局像素依赖编码器与图像解码器的组合结构,共同构成自动编码器。
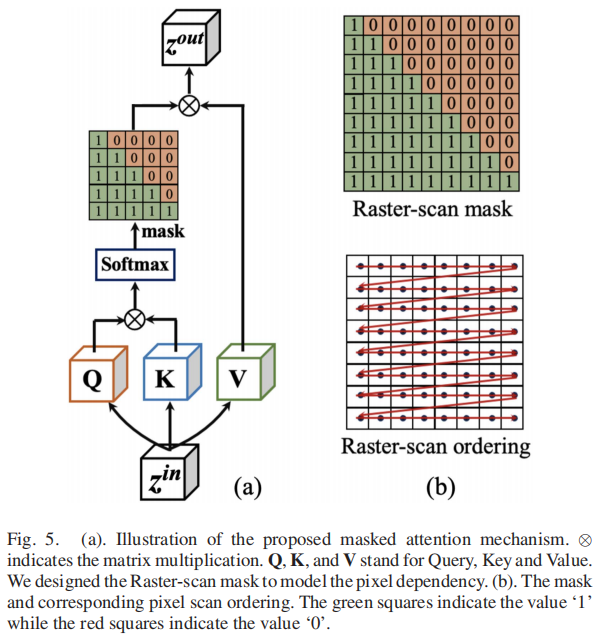
图5(a)详细说明了所提出的掩码自注意力机制及其对应的掩码设计,其中Q、K和V分别表示查询、键和值(为简洁起见,省略了归一化层和MLP层)。\(z^{in}\)和\(z^{out}\)分别表示输入和输出特征,\(\otimes\)表示矩阵乘法运算符。掩码自注意力机制可表述为:
\[z^{out}=\mathrm{Mask}\left[\mathrm{softmax}\left(\frac{y_{q
u e r y}(z^{i n})y_{k e y}(z^{i n})^{\top}}{\sqrt{d i
m}}\right)\right]y_{v a l u e}(z^{i n}),\] 其中\(y_{q u e r y}(\cdot)\)、\(y_{k e y}(\cdot)\)和\(y_{v a l u
e}(\cdot)\)表示可学习参数,而\(y_{q u e
r y}(z^{i n})\)、\(y_{k e y}(z^{i
n})\)和\(y_{v a l u e}(z^{i
n})\)分别对应Q、K和V。如图5(b)所示,我们采用光栅扫描掩码来建模全局像素依赖关系,这与输入图像的光栅扫描采样顺序相对应[71]。若将输入向量\(z^{i n}\in\mathbb{R}^{N\times d i
m}\)定义为\(z^{i n}=[\bar{z}_{1}^{i
n},z_{2}^{i n},...,\ z_{N}^{i n}]^{\top}\),则每一行\(z^{in}\)代表一个输入标记。像[14],对于本文提出的掩码注意力机制输出的\(z^{o u t}\in\mathbb{R}^{N\times d i
m}\),每个输出标记\(z_{m}^{o u
t}\)可表示为: \[z_{m}^{o u
t}=\sum_{n\leq m}\gamma_{m n}y_{v a l u e}(z_{n}^{i n}),\]
其中,行m中的元素\(\gamma_{m
n}\)可表示为: \[\gamma_{m
n}=softmax[y_{k e y}(z_{1}^{i n})^{\top}y_{q u e r y}(z_{m}^{i
n}),\cdot\cdot\cdot,y_{k e y}(z_{m}^{i n})^{\top}y_{q u e r y}(z_{m}^{i
n})],\] 在公式(3)中,我们可以清晰观察到每个输出标记\(z_{m}^{o u t}\)都基于输入\(z_{n}^{i n}\,(n\leq
m)\)中区域的先前标记\(z^{in}\)进行条件化处理,且扫描顺序遵循光栅扫描模式。这种机制还能有效建模现实场景中的复杂像素依赖关系,例如现代AI相机智能图像信号处理器所引入的依赖关系。因此,每个条件句都能通过注意力算子访问其上下文中的任意像素,这由对所有可用上下文的求和运算所体现,记作\(\sum_{n\leq
m}\)。
该设计的模块能够访问远处像素,从而增强长距离统计建模。因此,提取的特征[fg1、fg2、fg3、fg4]可携带丰富的全局像素依赖信息。实验结果表明,真实图像与篡改图像之间的像素相关性特征具有显著差异,这为图像伪造定位提供了有效依据。
C.局部像素依赖性建模
根据去马赛克算法的特性,给定像素的关联规律性主要取决于其邻近像素[10]、[11]。此外,像素规律性可通过线性去马赛克公式[10]、[55]进行建模。然而,这些传统方法在伪造检测性能方面存在局限性。受[59]、[82]、[101]等研究的启发,我们提出通过将传统去马赛克思路整合到卷积运算中,来构建局部像素依赖关系模型。
在局部像素依赖编码器中,我们在每个transformer模块顶部部署差异卷积(DC)头,以学习方式建模局部图像区域的像素依赖关系。我们设计的差异卷积(DC)在标记层面执行,每个标记代表一个非常小的图像块。相较于处理单个像素,4×4图像块能提供更具表现力的表征来执行差异卷积。我们的方法显著降低了计算成本,同时有效捕捉局部图像区域的像素不一致性。此外,我们在每个transformer模块中采用MLP层,进一步增强各模块内部局部像素依赖关系的学习效果。
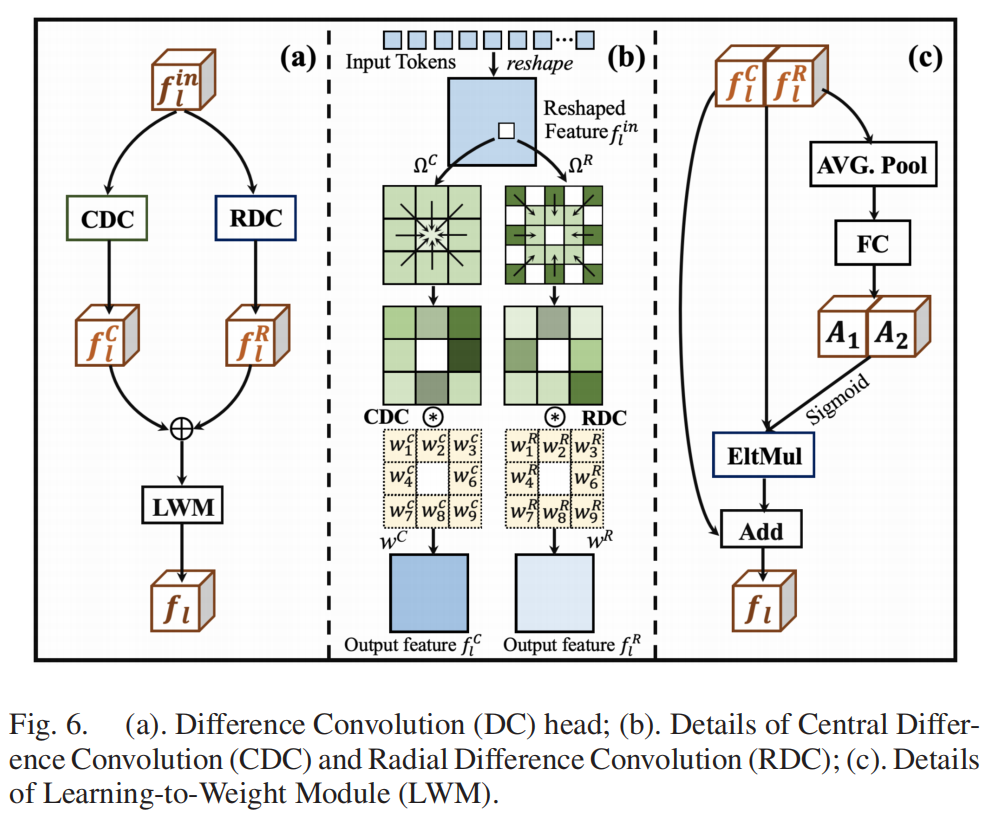
图6(a)展示了设计的差分卷积(DC)头部架构。输入特征fl首先被前馈至两个差分卷积模块:中心差分卷积(CDC)和径向差分卷积(RDC)。通过利用CDC和RDC,可以有效建模局部像素依赖关系,从而提升最终伪造检测性能。图6(b)详细展示了CDC和RDC的工作原理:输入标记(即本地像素依赖编码器中transformer模块的输出)被重塑为二维特征fl。首先计算给定输入特征图在局部特征图区域内的差异,然后分别用对应的卷积权重对两个像素差异特征图进行卷积运算,最终生成CDC和RDC特征图。其中CDC操作可表示为:
\[f_{l}^{C}=\sum_{(x_{i},x_{c})\in\Omega^{C}}w_{i}^{C}(x_{i}-x_{c}).\]
其中,xc表示局部区域ΩC中的中心元素,xi则代表其对应的周边元素。如图6(b)所示,ΩC和ΩR中的每个元素都对应一个标记。wi_C值表示可学习的卷积权重。类似地,RDC操作可表示为:
\[f_{l}^{R}=\sum_{(x_{i},x_{i}^{\prime})\in\Omega^{R}}w_{i}^{R}(x_{i}-x_{i}^{\prime}),\]
其中xi和\(x_{i}^{\prime}\)是区域ΩR中的元素对,如图6(b)所示。
我们通过学习权重模块(LWM)将CDC特征fl
C与RDC特征fl
R进行互补组合,该模块将在第三节D部分详细阐述。本模型旨在提取局部像素依赖特征。相较于传统卷积网络,CDC和RDC通过差异运算的优势,能更充分地揭示像素不一致性伪影,从而显著提升图像伪造定位的最终性能。
D.学习加权模块LWM
如图6(a)所示,由CDC和RDC生成的特征fl C和fl
R被合并后依次输入到学习权重模块(LWM)。设计的LWM通过学习权重融合这两个输入特征,从而实现更有效的特征整合。图6(c)展示了局部CDC特征fl
C与RDC特征fl
R的学习权重过程,其中FC表示全连接层,EltMul代表逐元素乘法。在此过程中,拼接后的特征需先经过一个平均池化层和一个全连接层。随后,学习权重A1⊕A2通过逐元素乘法依次作用于拼接后的特征fl
C⊕fl
R。最终,通过将拼接后的特征与加权特征相加,即可获得融合后的特征fl。
如图4所示,我们进一步采用局部权重混合技术(LWM)融合局部像素依赖特征[fl1,fl2,fl3,fl4]与全局像素依赖特征[fg1,fg2,fg3,fg4]。融合后的特征向量[f1,f2,f3,f4]随后被输入边界与伪造解码器,用于生成边界预测和伪造图谱。
E.像素不一致性数据增强
现有方法[89]主要聚焦于发现伪造图像中的语义层面(或对象层面)不一致。部分方法[19]、[104]还提出通过随机粘贴原始真实图像中的物体来实现数据增强。然而,随着图像处理技术的不断进步,伪造内容的复杂程度也在同步提升。因此,原本用于捕捉语义层面不一致的方法在应对高级操作时难以有效泛化。我们提出了一种像素不一致性数据增强(PIDA)策略,旨在捕捉像素级不一致而非语义伪造痕迹。
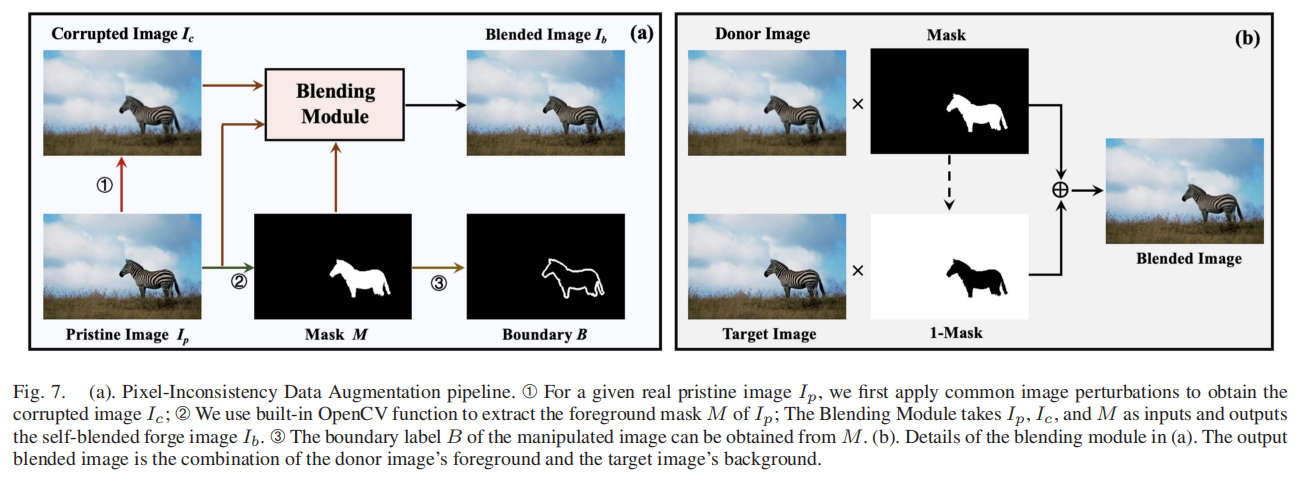
图7(a)展示了我们提出的PIDA流程。➀对于给定的真实原始图像Ip,我们通过施加图像扰动(如压缩、噪声和模糊处理)生成受损图像Ic;➁可以直接调用OpenCV内置函数提取Ip的前景掩膜M。融合模块以Ip、Ic和M为输入参数,生成自融合伪造图像Ib;➂操纵图像的边界标签B可通过M轻松推导得出。图7(b)详细展示了融合模块的工作原理:我们将源图像的前景与目标图像的背景相结合,最终生成自融合伪造样本。
F.目标函数
整个框架采用端到端的方式进行训练,总体目标函数由以下四个部分组成:掩码预测损失LM、边界预测损失LB、紧凑性损失LC和图像重建损失LR:
\[L=L_{M}+\lambda_{B}L_{B}+\lambda_{C}L_{C}+\lambda_{R}L_{R},\]
其中,\(L_{M}\)和\(L_{B}\)分别表示预测结果与对应标签之间的交叉熵损失。边界损失\(L_{B}\)可视为辅助监督机制,有助于提升伪造检测的定位精度。基于观察到大多数篡改区域较为紧凑的特性,我们进一步在预测掩膜上施加了紧凑性约束\(L_{C}\): \[L_{C}={\frac{1}{N_{i m g}}}\sum_{i=1}^{N_{i m
g}}\frac{P e r^{2}}{4\pi S}={\frac{1}{N_{i m g}}}\sum_{i=1}^{N_{i m
g}}\frac{\sum_{j\in\hat{B}}{\hat{B}_{j}}^{2}}{4\pi(\sum_{k\,\in\hat{M}}|\hat{M}_{k}|+\epsilon)}.\]
在该公式中,P P
eri和S分别表示预测伪造区域的周长和面积,Nimg代表图像数量。B̂和M̂则对应预测边界与掩膜。因此,式(8)的分子计算的是预测边界图B̂中像素值平方之和B̂j²,分母则与预测掩膜图M̂中像素绝对值之和M̂k成正比。此处被设定为极小数值。采用LC方法可使预测图像伪造图更加紧凑,并提升操作定位性能。
图像重建损失LR计算重建图像ˆIi与对应输入图像Ii之间的差值的l1−范数:
\[L_{R}=\frac{1}{N}\sum_{i=1}^{N}||I_{i}-\hat{I}_{i}||_{1}.\]
通过使用LR,可以在[fg1、fg2、fg3、fg4]中对全局像素依赖性进行建模,该模型被用于LWMs中的伪造图和边界图预测。
IV.实验与结果
本文首先介绍本研究涉及的数据集、评估指标及基线模型。随后,我们在不同实验场景下评估模型的泛化能力和鲁棒性,并通过可视化伪造定位结果来展示本方法的优势。最后,我们开展消融实验以验证各设计组件的有效性。
A.数据集
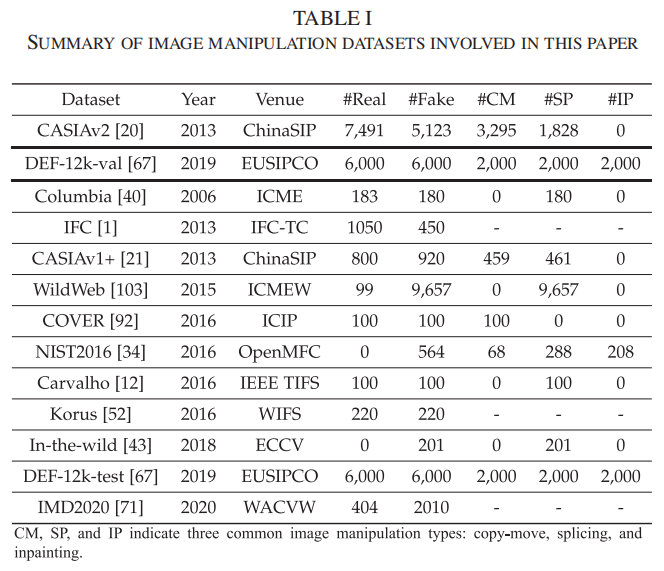
本研究选取了12个具有不同属性、分辨率和质量的图像处理数据集。如表I所示,其中CM(复制-移动)、SP(拼接)和IP(修复)分别代表三种常见的图像处理类型。与[19]、[81]、[103]等先前研究一致,我们选用包含超过12,000张多样化内容图像的CASIAv2 [20]数据集作为训练集。此外,我们采用DEF-12kval [66]作为验证集,该数据集包含6000张具有三种伪造类型的挑战性假图像,以及从MS-COCO [57]数据集中采集的6000张真实图像。在测试阶段,我们选取了11个具有挑战性的数据集进行评估,包括哥伦比亚[39]、IFC [1]、CASIAv1+1 [20]、WildWeb [102]、COVER [91]、NIST2016 [33]、Carvalho [12]、Korus [51]、In-the-wild [42]、DEF-12k-test [66]和IMD2020 [70],并按发布时间排序。所有数据集中,我们都将伪造区域统一标记为‘1’,真实区域标记为‘0’。
B.评估指标
本文使用F1、MCC、IoU和AUC四个指标对最先进的模型的像素级伪造检测性能进行评估。
F1分数
F1分数是二元分类中常用的指标,广泛应用于图像伪造检测和定位领域。该指标通过计算精确率与召回率的调和平均值来实现:
\[F1=2\cdot\frac{P r e c i s i o n\times R e
c a l l}{P r e c i s i o n + R e c a l l}=\frac{2\times T P}{2\times T
P+F P+F N_{.}},\] 其中,T P、T N、F P和F
N分别表示真阳性、真阴性、假阳性和假阴性。
马修斯相关系数(MCC)
马修斯相关系数(MCC)衡量预测值与真实值之间的相关性,MCC的取值范围在-1到1之间,MCC值越大表示性能越好,其计算公式如下:
\[MCC=\frac{T P\times T N-F P\times F
N}{\sqrt{(T P+F P)(T P+F N)(T N+F P)(T N+F N)}}.\]
交并比(IoU)
交并比(IoU)是语义分割领域中广泛应用的评估指标。该指标的分子表示预测区域P与真实区域G的交集面积,而分母则计算两者并集的面积:
\[I o U={\frac{P\cap G}{P\cup G}}.\]
曲线下面积(AUC)
曲线下面积(AUC)衡量接收者操作特征(ROC)曲线下的面积。与其他指标不同,AUC不需要选择阈值。它量化了模型在所有可能阈值下的整体性能。
C.基准模型
本研究整合了来自顶级期刊和会议的16个代表性基准检测器,包含5种数据驱动架构和11种最先进图像伪造检测器。其目标是评估不同网络架构的检测性能并促进直接对比。基准测试包括三种普适性CNN架构(FCN [63]、U-Net [79]和DeepLabv3 [13])以及两个视觉模型:CASIAv1+和训练集CASIAv2共享782张相同的真实图像。为防止数据泄露,CASIAv1+用等量的COREL [88]图像替换了这些真实图像。此外,该基准还纳入了十种最先进的图像伪造检测模型:
MFCN [81]将图像拼接定位问题建模为多任务学习任务,通过采用双分支卷积神经网络VGG-16,实现伪造图与边界图的同步预测。
RRU-Net [8]是一种专为图像拼接检测设计的端到端环形残差U-Net架构。该架构通过残差传播机制有效解决了深度网络中的梯度扰动问题,从而显著增强了伪造线索的学习效果。
MantraNet[94]是一个端到端的图像伪造检测与定位框架,其训练数据集包含385种图像篡改类型。为实现强大的图像篡改检测能力,曼特拉网创新性地引入了一种长短期记忆解决方案,专门用于检测局部异常。
HPFCN [54]通过整合ResNet模块和一个可学习的高通滤波器,实现像素级的修复定位。
H-LSTM [5]是一种融合了CNN编码器和LSTM网络的伪造检测模型。这种组合使模型能够捕捉并分析伪造图像中的空间和频率域伪影。
SPAN [40]是一个构建金字塔注意力网络的框架,用于捕捉图像块在多个尺度上的相互依赖关系。它基于预训练的MantraNet构建,并提供了在特定训练集上微调参数的灵活性。
PSCC [61]是一种渐进式空间通道相关网络,通过密集的交叉连接在多个尺度上提取局部和全局特征。其渐进式学习机制使模型能够以从粗到细的方式预测伪造掩码,从而提升最终检测性能。
MVSS-Net++ [19]设计了一个双流网络,利用多尺度特征捕捉边界和噪声伪影。通过结合两个流,该网络能够有效分析图像的不同方面,从而在像素级别和图像级别检测操作痕迹。
CAT-NET [52]是一种基于卷积神经网络(CNN)的模型,通过利用离散余弦变换(DCT)系数来捕捉图像处理过程中产生的JPEG压缩伪影。
EVP [60]提供了一个统一的低级结构检测框架,适用于图像处理。ViT适配器和视觉提示功能使EVP模型能够实现卓越的伪造定位精度。
TruFor 2 [34]通过基于学习到的噪声敏感指纹的变压器融合架构,同时捕获高级RGB伪影和低级噪声伪造痕迹。
在本研究中,为了进行公平且可重复的比较,我们遵循MVSS-Net++
[19],选择满足以下三个标准之一的基线模型:(1)官方训练代码公开;(2)该模型采用与我们相同的训练协议,即使用CASIAv2作为训练数据集;(3)发布官方预训练模型。
在测试阶段,我们遵循MVSS-Net++
[19]和JPEG-SSDA
[78]的协议规范,对训练完成的模型进行伪造图像检测,并针对所有测试数据集报告图像级检测结果。所选的篡改方法涵盖了多种伪造特征:边界伪影(MFCN[81]、MVSS-Net++[19])、多尺度特征(PSCC
[61]、MVSS-Net++ [19]、TruFor [34])、高频伪影(HPFCN [54]、MVSS-Net++
[19]、MantraNet [94])以及压缩伪影(CATNET [52])。
D.实施细节
我们的模型基于PyTorch [74]框架开发,并在两块Quadro RTX 8000 GPUs上进行训练。输入图像尺寸为512×512像素,采用Adam优化器(参数设置为[47],β1=0.9,β2=0.999)进行训练,批量大小设为28,学习率和权重衰减分别为6×10-5和1×10-5。模型训练周期为20个epoch,每完成1600个全局步骤即进行验证。实验设置参照[19]方法,在CASIAv2 [20]数据集上训练模型,并在DEF-12k-val [66]数据集上进行验证。除提出的像素不一致性数据增强技术外,我们还遵循[19]方法采用翻转、模糊、压缩、噪声、拼贴及修复等常规数据增强手段进行训练。
E.跨数据集评估
像素级检测:
在伪造图像中定位被篡改区域至关重要,因为这能提供已被篡改区域的证据。预测的伪造区域可揭示攻击者的潜在意图[50]。然而,由于训练集和测试集之间的域差距很大,大多数检测器在跨数据集评估中都存在定位性能较差的问题。本研究通过像素级伪造检测(即操作定位)评估不同检测器的泛化能力。遵循[19]跨数据集评估协议,我们在CASIAv2
[20]数据集上训练模型,并在DEF-12kval
[66]数据集上验证模型。为便于全面解读结果,我们在表II和表III中报告了F1和IoU这两个图像伪造定位领域广泛应用的关键指标。附录(在线提供)还提供了AUC和MCC结果。我们用粗体突出最佳定位结果,并用下划线标注次优结果。与[19]中为每个模型和数据集单独确定最优阈值不同,我们统一将F1、MCC和IoU的默认决策阈值设为0.5,主要基于以下两点考虑:(1)在实际应用场景中,不可能为每个测试样本预先设定不同的最优阈值;(2)统一0.5作为决策阈值可确保所有基线模型的公平比较。不同阈值下的像素级评估结果详见附录(在线提供)。
F1分数是该领域[20]、[77]、[78]、[97]中使用最广泛的度量标准。
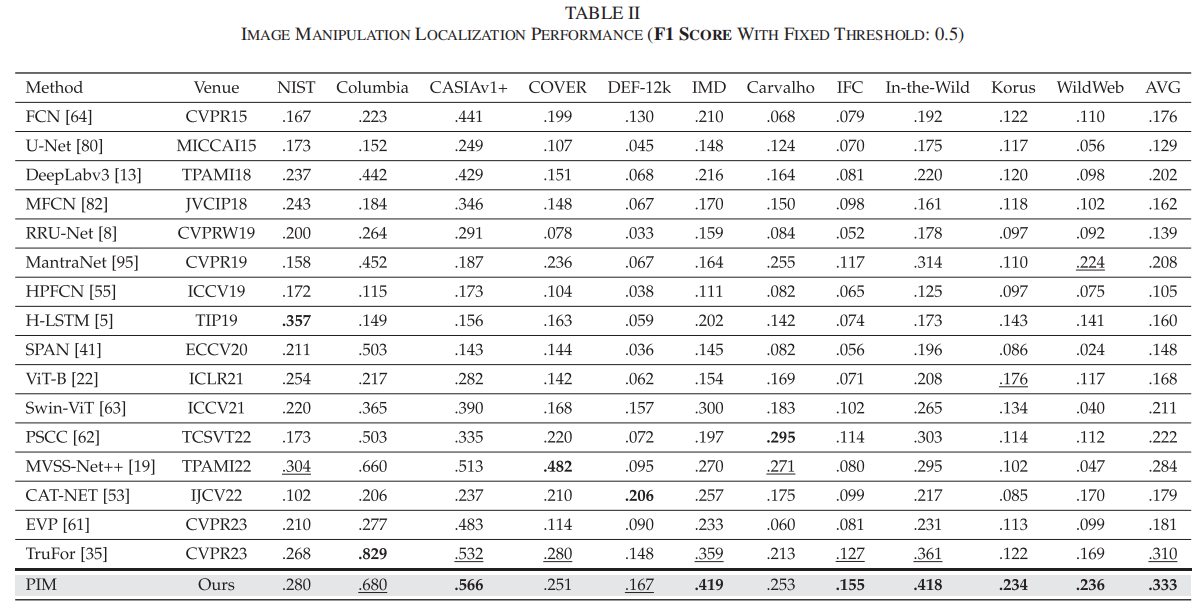
在表II中,我们的方法在六个数据集上取得了最佳检测F1分数,在两个数据集上表现次优。与当前最先进的TruFor [34]方法相比,我们提出的像素不一致性建模(PIM)方法在九个数据集上展现出更优的伪造定位F1分数,平均提升幅度达2.3%,从31.0%提升至33.3%。
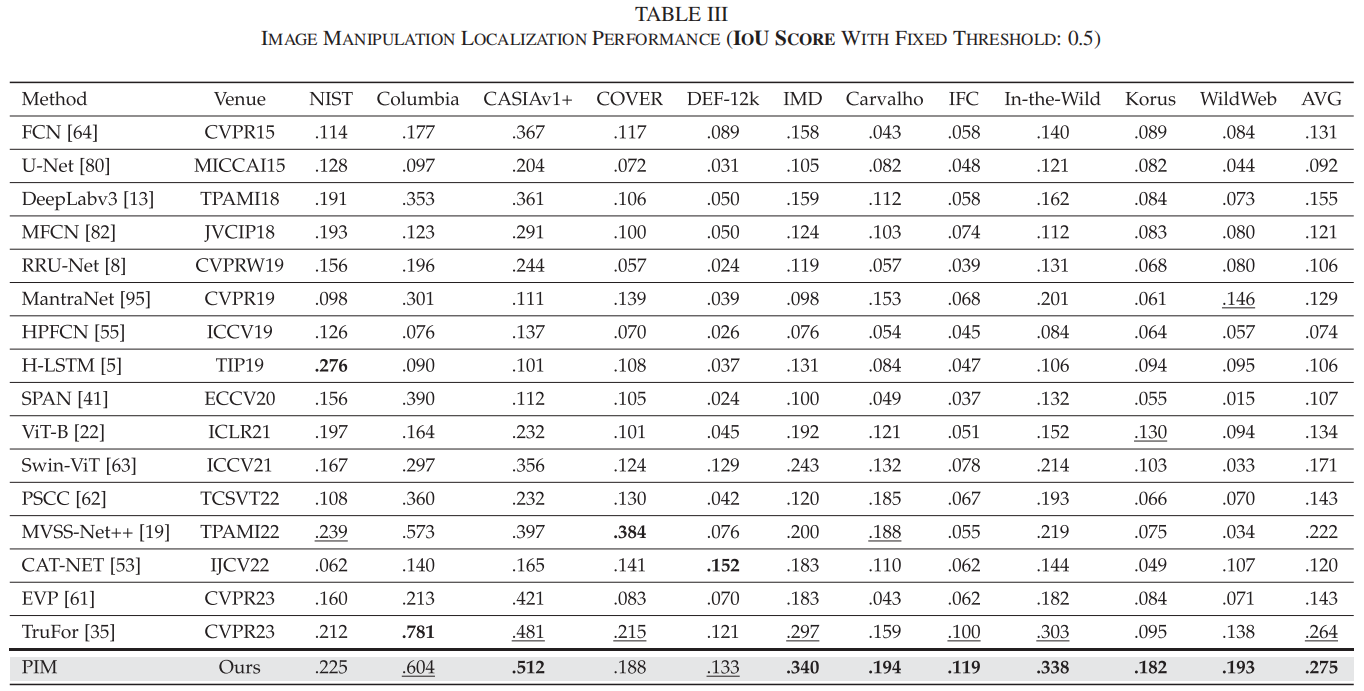
表III显示,我们的像素不一致性建模(PIM)方法在未见过的测试数据集中始终保持着最佳或次优的检测性能。尽管这11个未见过的数据集分布多样,但我们的方法平均交并比得分仍以显著优势超越所有先前方法。所提出方法的优越性可归因于其能够捕捉像素不一致伪影,这在不同的伪造数据集中是一个共同的指纹。
图像级评价:
在本小节中,我们进一步通过跨数据集评估对图像级伪造检测进行验证。理想情况下,原始真实图像的篡改概率图应全部为零。为此,我们在篡改概率图上应用最大池化操作,并将生成的输出分数作为输入图像[78]的整体预测结果。表IV展示了关键指标F1分数,其中最佳结果以粗体标出,次优结果则用下划线标注。
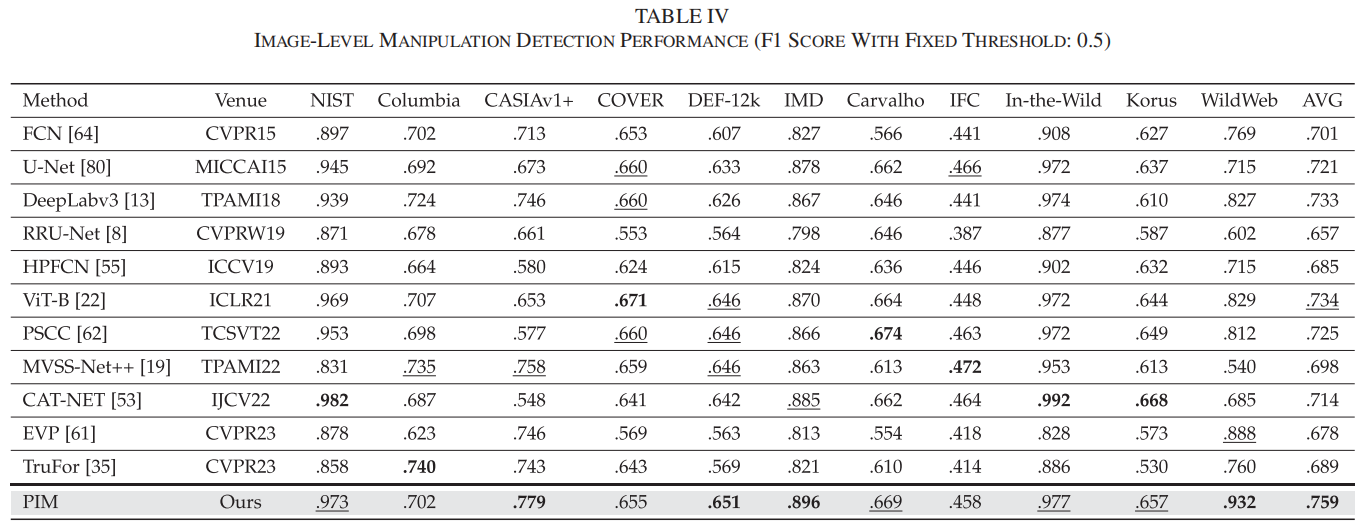
值得注意的是,我们的方法在NIST、CASIAv1+、DEF-12 k、IMD、Carvalho、In-the-Wild、Korus和WildWeb等八个数据集中均取得前两名的图像级检测性能。即使在COVER数据集排名第六、IFC数据集排名第五的情况下,我们的方法仍能逼近最佳检测结果(COVER:我们的方法得分为655分,而最佳方法得分为671分;IFC:我们的方法得分为458分,而最佳方法得分为472分)。该方法展现出卓越的泛化能力,取得了最佳平均性能,充分证明了其出色的伪造检测能力。
F.交叉操作评价
为评估模型对未知修复技术的泛化能力,我们在CASIAv2数据集上训练模型,并在未知修复(IP)技术上进行测试。表V展示了10种修复技术的跨技术F1分数,交并比性能数据详见在线附录。这10个典型且具有挑战性的修复数据集包括CA [98]、EC [68]、GC [99]、LB [93]、LR [35]、NS [7]、PM [37]、RN [100]、SG [41]、SH [95]和TE [83],这些数据集在以往修复检测研究中被广泛采用[92]。
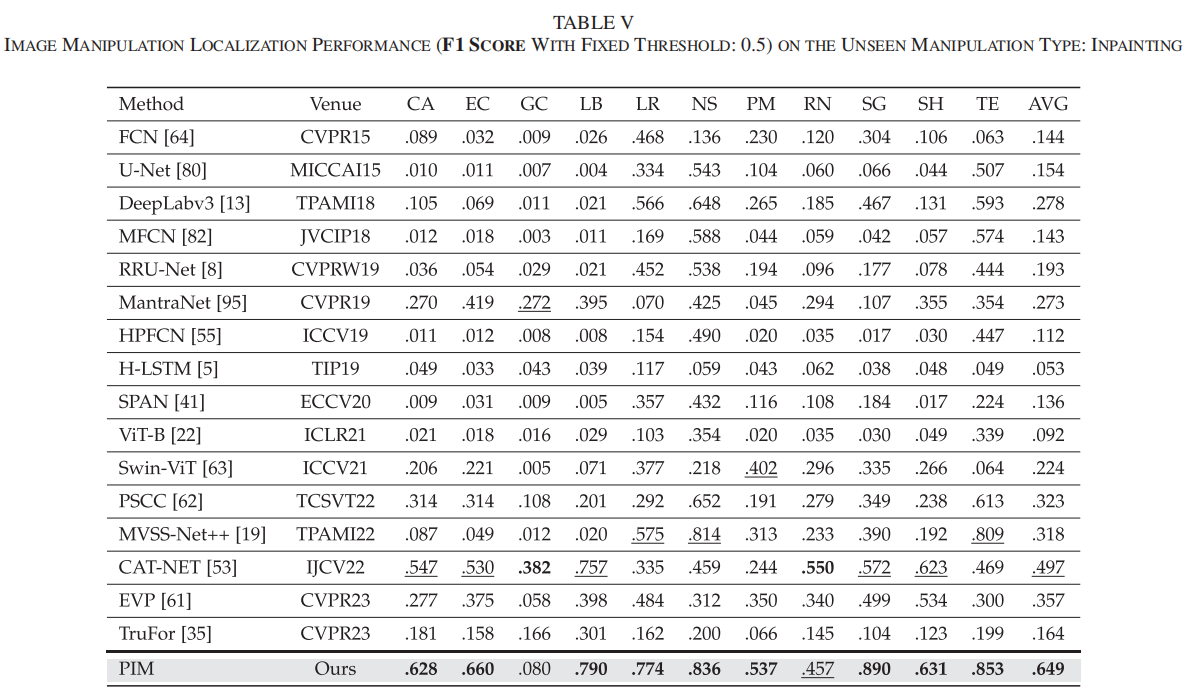
从表V可以看出,CAT-NET和TruFor得益于其海量训练数据和捕捉低级伪造特征的能力,在平均伪造定位性能方面表现亮眼。然而,我们提出的方法PIM在八个修复数据集上取得了最高F1值(平均0.649),以显著优势超越了先前方法。
我们的方法之所以能有效应对不可预见的操控技术,主要得益于两大核心设计:(1)像素不一致性数据增强(PIDA)策略,该方案能让模型捕捉到更普遍且微妙的伪影特征,从而有效缓解训练过程中的过拟合问题;(2)精心设计的网络架构能同时捕捉全局与局部像素不一致性特征,使模型能够揭示更多本质性的像素级伪影,而非仅捕捉语义层面的痕迹。
G.对复杂操作的泛化性
为检验模型在复杂图像合成任务中的泛化能力,我们选取了Dall-E2(DE2)和Stable Diffusion(SD)两个数据集进行测试。DE2包含60张高仿伪造图像,SD则包含328张。这些伪造图像具有高度协调性特征:伪造区域的光照效果一致、尺寸比例合理、语义内容连贯且位置精准。两套数据集的具体生成流程详见在线附录。表VI展示了针对未见过的复杂操控技术的伪造定位性能(F1、IoU、AUC和MCC分数)。
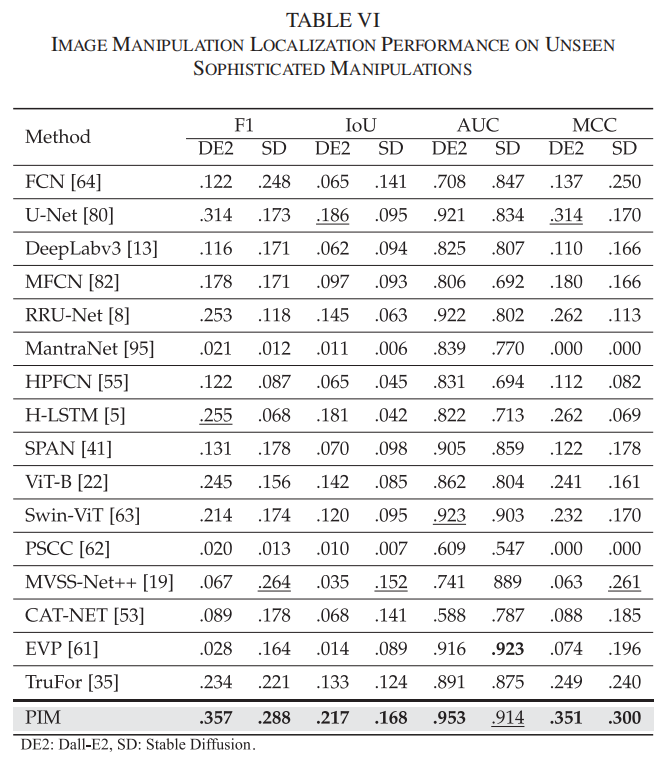
虽然最先进的TruFor在这些指标上表现尚可,但我们的方法——像素不一致性建模(PIM)——在大多数指标上都超越了其他所有方法。在DE2和SD数据集上,PIM均取得了最高的F1值、交并比(IoU)和马修斯相关系数(MCC),这表明其在图像伪造定位中对复杂操作具有更强的泛化能力。PIM在应对先进AI生成内容技术(AIGC)制造的复杂伪造行为时表现出色,这说明该模型能有效适应未知且复杂的操控手段,为实际应用提供了可靠的解决方案。
H.对高级操作的泛化性
随着AI生成图像(AIGC)技术的迅猛发展,伪造图像正变得愈发逼真,使用AIGC工具的门槛也大幅降低。因此,检测这些新兴的高级图像篡改手段至关重要。我们针对两个由先进AIGC方法生成的图像篡改数据集——Autosplice [45]和CocoGlide [69]进行了模型优化。其中,Autosplice [45]是由强大视觉语言模型生成的文本提示图像数据集,包含2,273张真实图像和3,621张经过处理的图像,每张伪造图像均采用三种JPEG压缩质量等级:75、90和100(数值越高表示图像质量越好)。CocoGlide包含512张基于COCO 2017验证集生成的逼真伪造图像,这些图像采用文本引导的GLIDE扩散模型生成。表VII展示了图像伪造定位的AUC和MCC指标。
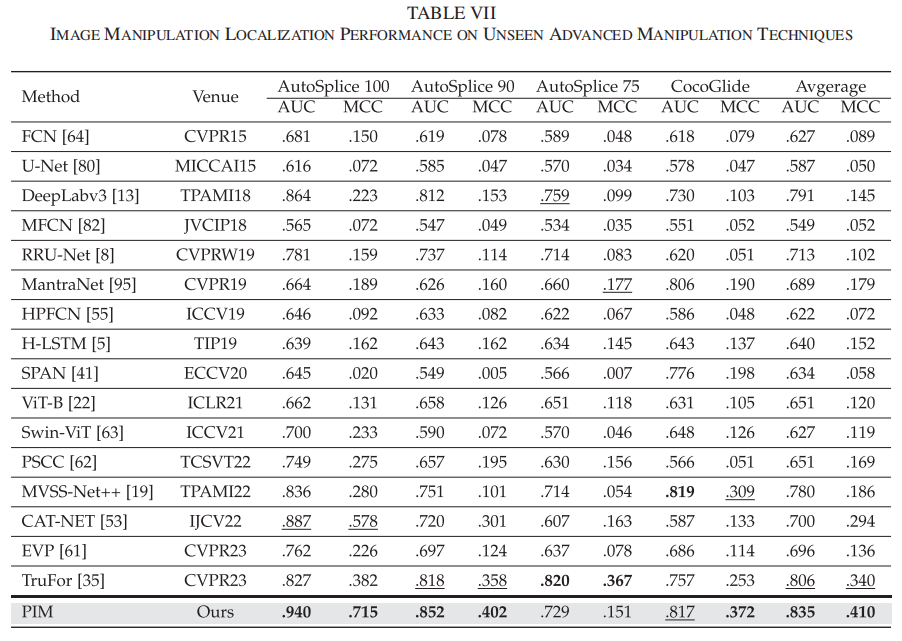
我们的PIM方法在Autosplice 100、Autosplice 90和CocoGlide数据集上持续保持最佳AUC和MCC表现。主流方法TruFor得益于其基于海量额外数据训练的Noiseprint++提取器,在低质量的Autosplice 75数据集上取得最高分。尽管如此,PIM在所有先进AI生成图像数据集上均展现出更优的平均AUC和MCC指标。
I.鲁棒性评价结果
J.定性实验结果
K.打乱图像的可视化结果
L.消融实验
V.结论和今后的工作
本文提出了一种通过捕捉伪造图像中像素不一致性实现的通用型图像篡改定位模型。该方法基于双流像素依赖建模框架构建图像篡改定位系统,创新性地采用掩码自注意力机制有效建模输入图像中的全局像素依赖关系。同时,通过设计中央差分卷积(CDC)和径向差分卷积(RDC)两种定制化卷积模块,能更精准捕捉局部区域内的像素不一致性特征。研究发现,通过建模像素间关联关系可有效挖掘图像篡改的内在线索。为提升整体性能,学习加权模块(LWM)将全局与局部特征互补融合。动态权重方案的应用实现了更优的特征融合效果,从而构建出更具鲁棒性和普适性的图像篡改定位模型。
此外,我们提出了一种新型像素不一致性数据增强(PIDA)技术,该技术专门利用原始图像生成增强伪造样本,将研究重点聚焦于像素级伪影。所提出的PIDA策略为未来取证研究的泛化能力提升提供了重要启示。大量实验结果表明,该框架在图像篡改检测与定位方面展现出最先进水平,在泛化能力和鲁棒性评估中均表现优异。我们设计的模型在未见过的、高级且复杂的篡改图像上也表现出色,充分证明了其在复杂真实场景中的应用潜力。消融实验进一步验证了各组件的有效性。
尽管我们的方法对未见过的图像扰动具有鲁棒性,但仍存在易受重捕获攻击的缺陷。这一漏洞源于该框架的核心目标:识别因处理过程中破坏CFA规律性而产生的像素不一致伪影。重捕获操作会重新引入去马赛克化过程中建立的像素依赖关系,掩盖了这些伪影,导致伪造检测失败。未来研究中,开发有效的重捕获检测模块将成为关键方向,以确保更安全的篡改检测。
(以下仅代表个人观点:首先作为发表在IEEE Transactions on Pattern Analysis and Machine Intelligence(TPAMI) 2025的文章,只与2023的方法对比,其次比较论文实验的结果和原本论文在相同数据集相同指标下的结果相差太多,对实验结果持怀疑态度,对此文的阅读暂且搁置)