Poster:Query-efficient Black-box Attack for Image Forgery Localization via Reinforcement Learning
Poster: Query-efficient Black-box Attack for Image Forgery Localization via Reinforcement Learning
Xianbo Mo
广东省智能信息处理重点实验室,深圳市媒体安全重点实验室,深圳大学
Shunquan
Tan∗
广东省智能信息处理重点实验室,深圳市媒体安全重点实验室,深圳大学
Bin
Li
广东省智能信息处理重点实验室,深圳市媒体安全重点实验室,深圳大学
Jiwu
Huang
广东省智能信息处理重点实验室,深圳市媒体安全重点实验室,深圳大学
摘要
近年来,深度学习技术在取证工具中得到广泛应用,用于检测和定位伪造图像。然而,其易受对抗性攻击的特性凸显了反取证研究的必要性。为此,我们提出了一种创新且高效的黑盒反取证框架,专门针对对抗性伪造图像的生成。该框架采用强化学习范式下的马尔可夫决策过程模型,模拟在线取证服务的查询动态。我们进一步引入了一种新型奖励函数,通过评估查询结果与攻击目标之间的逻辑非关系来衡量攻击效果。为提升攻击的查询效率,采用actor-critic算法实现累积奖励最大化。实证研究验证了该方法的有效性:不仅对多种主流图像伪造检测器产生显著对抗效果,同时确保反取证图像在视觉上几乎无法察觉失真。
ccs概念:•安全与隐私→领域特定的安全和隐私架构;•计算方法→机器学习;•应用计算→计算机取证
关键词:反取证;强化学习;黑盒攻击
1.引言
伪造或篡改图像的泛滥在多个领域引发日益严峻的安全威胁。这包括移除版权水印、替换内容、抹除细节以及添加误导性元素等行为。由于数字图像在刑事调查、新闻报道和知识产权保护等领域被广泛用作证据和可靠记录,准确识别图像中的伪造区域变得至关重要。为确保数字图像的真实性,研究人员开发了多种取证技术,例如CAT-Net
[1]和OSN
[2]。这些技术不仅能够检测并精确定位伪造图像片段,甚至能有效抵御社交网络平台中因数据压缩操作导致的图像失真问题。
然而,现有的强大防伪检测系统尚未充分考虑对抗性攻击的影响。众所周知,当前最先进的防伪检测技术主要依赖深度学习算法,容易遭受对抗性攻击的威胁。这类攻击在防伪定位领域尤为棘手,因此必须重视并提升防伪定位系统的抗干扰能力。尽管对抗样本[3]和生成对抗网络(GAN)[4]等现有技术策略为构建对抗攻击提供了方法论,但我们认为这些方法在安全关键的防伪定位领域适用性存疑。对抗样本的白盒攻击方式受限于不同检测系统的可迁移性;而黑盒方法依赖查询式操作,由于需要大量查询数据导致效率低下[5]。因此,服务提供者能够通过检测重复且高度相似的查询来轻松识别查询密集型攻击。至于GAN模型,其同样受到可迁移性问题的限制,因为判别器在白盒攻击中扮演着与目标模型类似的角色。
本文聚焦于通过强化学习(RL)技术突破上述局限。我们的创新贡献包括:
(1)提出一种新型反取证框架用于图像伪造定位,其核心特征在于高效的黑盒特性。该框架不仅摆脱了特定目标网络的限制,还能有效减少重复查询次数。通过构建有效攻击图像,我们仅需五次左右的查询迭代即可完成攻击。
(2)实验结果表明,多种伪造检测器的F1分数指标均显著下降,这凸显了当前鲁棒性检测器设计亟需改进以有效应对对抗性攻击。值得注意的是,本方法在保持低误报率的同时实现攻击效果,进一步验证了攻击策略的隐蔽性。
2.提出的方法
首先,我们面临三大核心挑战:(1)黑盒特性:由于版权保护和安全考量,此类检测器的详细信息无法公开,用户只能通过查询系统获取取证结果。因此,我们需要基于查询结果开发一套黑盒框架。(2)查询效率:有效的基于查询的攻击需要最小化总查询次数。这要求构建一个既能保持最佳攻击效果,又能减少查询次数的高效框架。(3)随机策略:强化学习策略在攻击噪声调制中的随机初始化会导致初始阶段反馈不一致。这种复杂性给强化学习代理的训练带来了挑战。
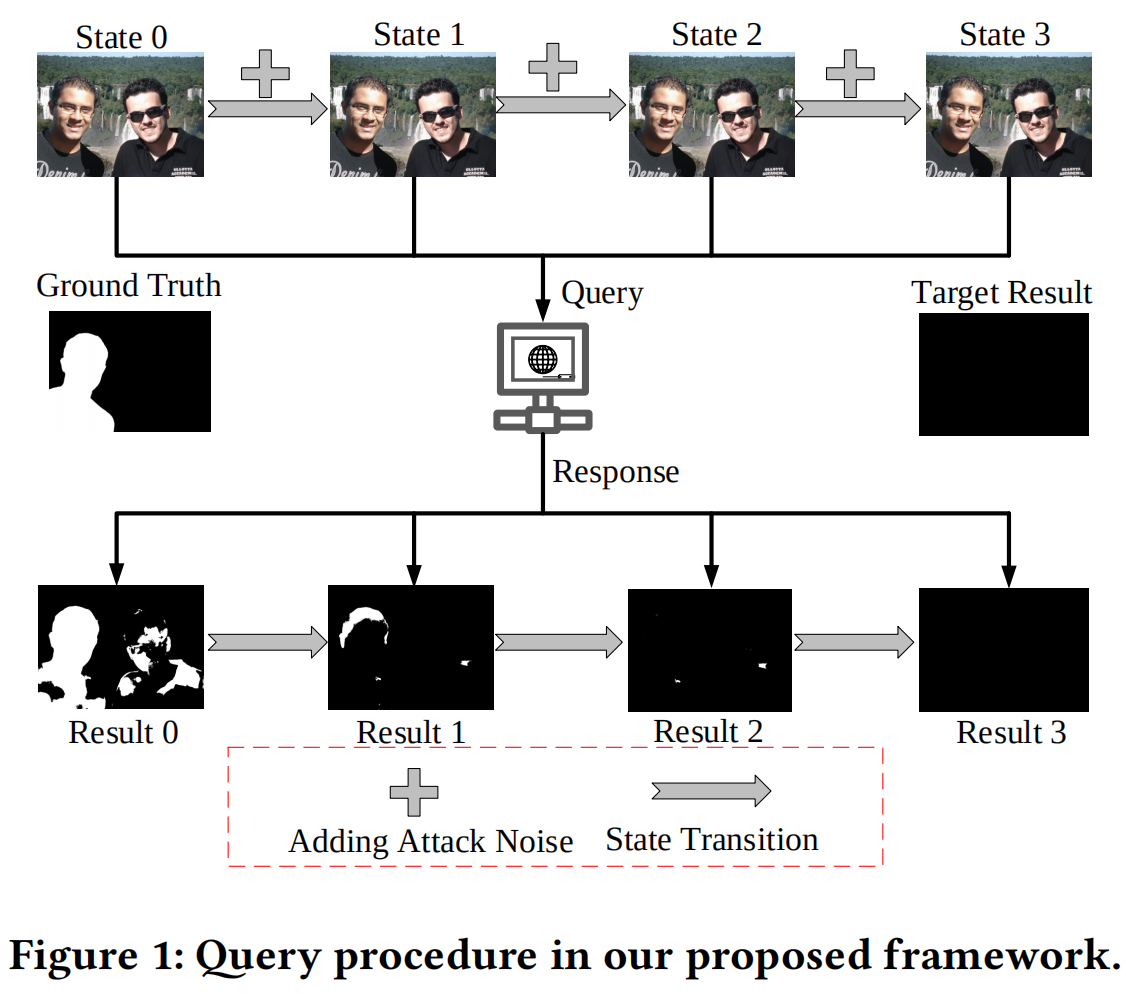
为解决第一个挑战,我们将查询过程建模为马尔可夫决策过程(MDP)(图1)。在任意时间步\(0\lt t\leq n\),给定当前伪造图像\(x_t\)及其噪声\(\xi_{t-1}\),根据转移概率\(\pi\),它们之间的关系可表示为 \[\pi(X_{t}|X_{0;t-1},\ \xi_{0;t-1})=\pi(X_{t}|X_{t-1},\xi_{t-1})\] 该方法将查询过程建模为马尔可夫决策过程(MDP),使强化学习智能体能够通过迭代交互构建有效攻击策略。针对第二个挑战,我们采用基于卷积神经网络的策略,并通过异步优势演员-评论家(A3C)算法[6]进行优化以提升查询效率。A3C的并行处理能力有助于高效利用数据资源。通过调整奖励折扣因子𝜆,使系统在最小化状态转移的同时获得最大奖励,从而进一步提高累积奖励效率。为应对最后一个挑战,我们设计了渐进式降噪训练策略:随着迭代次数增加逐步降低噪声强度。这种策略既便于早期训练,又能在保持攻击性能的前提下,通过降低噪声干扰促进策略的有效开发。
2.1.元素的定义
环境模型:伪造检测器,即OSN[2]。
行为主体:每个像素被视为独立的行为主体。
状态:将伪造图像\(X=x_{i,j,k}^{w\times h\times
c},x_{i,j,k}\in\{0,1,2,...,255\}\)视为状态,其中(𝑤×ℎ×𝑐)是其形状。
状态转移:
给定当前状态\({S_t}\),从\({S_t}\)到\(S_{t+1}\)的转移,记作\(T(S_{t+1}|S_t,A_t)\),可表述为 \[\begin{aligned}T(S_{t+1}|S_{t},A_{t}):X_{t+1}&=X_{t}\ast
A_{t}\ast\zeta^{t}\\(x_{i,j,k}^{t+1})^{w*h*c}&=(x_{i,j,k}^{t}*a_{i,j,k}^{t})^{w\times
h\times c}*\zeta^{t}\end{aligned}\] 其中\(X_{t}\)和\(X_{t+1}\)是\({S_t}\)和\(S_{t+1}\)。\(A_{t}\)是智能体在\({S_t}\)时采取的动作映射,\(\zeta= 0.95\)是噪声折扣因子。
奖励函数:
其数学表达式如下: \[\begin{aligned}&R(T(S_{t+1}|S_{t},A_{t}),M)=(r_{i,j})^{w\times
h\times
c}\\&=[(M_{t}-M)\circledast(M_{t}-M)]-[(M_{t+1}-M)\circledast(M_{t+1}-M)]\\&=\{(m_{i,j}^{t}-m_{i,j})^{2}-(m_{i,i}^{t+1}-m_{i,j})^{2}|i\in\{1,2,...,w\},j\in\{1,2,...,h\}\}\}\end{aligned}\]
其中\(M_{t+1}\)和\(M_{t}\)是环境模型输出的掩膜。\(M=0^{(w\times
h)}\)是目标结果,其中0表示伪造定位中未被改变的像素。\(\circledast\)是哈德曼积符号。
A3C:
编码器由ImageNet预训练的EfficientNet
B0[7]初始化,Actor和critic是UNet[8]的上采样模块。
2.2.训练和测试程序
我们的训练流程在每次迭代中包含5次策略转换,初始噪声强度𝜎= 0.1。当最后50次迭代中F1分数持续低于0.35时,系统会将𝜎降低至𝜎=𝜎∗0.9。基于优势的A3C损失函数通过优化编码器、行为器和评论器模块,在攻击图像上实现最大奖励。若连续200次迭代未见𝜎下降,则终止训练。随后使用最优训练模型和最终𝜎值进行测试,该过程包含5次策略转换,并以最低F1分数作为最终攻击样本。
3.实验
3.1.数据集
针对需要研究的伪造定位模型(如CAT-Net[1]和OSN[2]),我们严格遵循其论文中公开的数据集设置,通过访问其GitHub仓库获取预训练模型。在黑盒攻击场景下,数据集的具体配置信息对攻击者是保密的。因此,我们的反取证方法采用了CASIA数据集[9],训练集、验证集和测试集的比例为4:1:5。此外还使用了DSO数据集[10]进行测试。根据相关论文记载,CASIA [9]和DSO [10]并未用于CAT-Net [1]和OSN [2]的训练与验证过程。
3.2.攻击影响
如图2所示,攻击效果通过视觉方式直观呈现。

第一、二行图像来自CASIA[9],第三行则来自DSO[10]。显然,我们提出的方法成功规避了OSN[2]的检测定位。为进一步验证有效性,我们计算了伪造图像在攻击前后对OSN[2]和CAT-Net[1]的平均F1值、交并比(IOU)及曲线下面积(AUC)得分,具体数据汇总于表1。
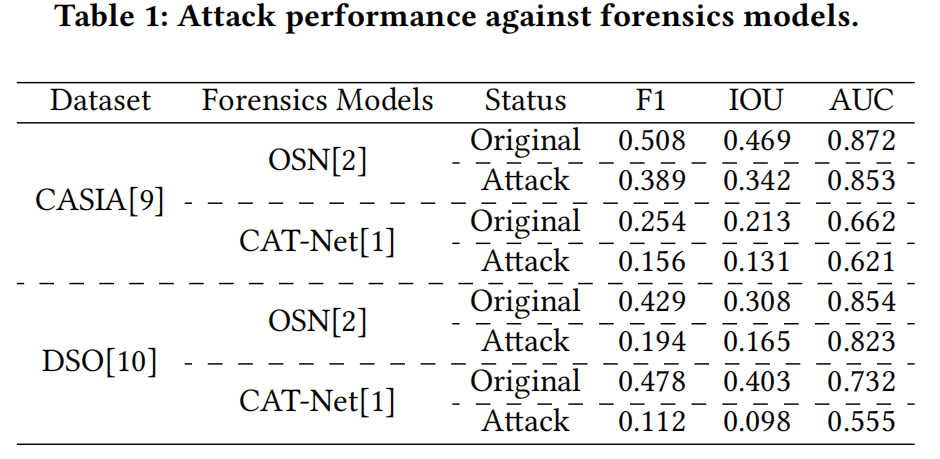
这些结果再次印证了本攻击方法卓越的定位规避能力及其在不同伪造检测器间的良好迁移性。此外,我们通过峰值信噪比(PSNR)和结构相似性指数(SSIM)评估攻击噪声造成的失真程度:针对CASIA图像,PSNR为33.43,SSIM为0.912;针对DSO图像,PSNR为32.56,SSIM为0.818。这些结果表明,本攻击产生的可感知失真水平极低。
4.结论
我们提出了一种基于强化学习的黑盒技术,构建了新型反图像伪造检测框架。该框架在保持高攻击效能的同时,实现了图像失真度的最小化。后续研究将重点优化攻击效果与失真控制,同时完善论文结构,形成完整的学术成果以供深入探讨。