Reinforced Multi-teacher Knowledge Distillation for Efficient General Image Forgery Detection and Localization
Reinforced Multi-teacher Knowledge Distillation for Efficient General Image Forgery Detection and Localization
Zeqin Yu1 , Jiangqun Ni2,3*, Jian Zhang1 , Haoyi Deng4 , Yuzhen
Lin4
1中山大学计算机科学与工程学院
2中山大学网络科学与技术学院
3鹏程实验室新网络部
4深圳大学广东智能信息处理重点实验室
摘要
图像伪造检测与定位(IFDL)至关重要,因为伪造的图像可能会传播虚假信息,对我们的日常生活构成潜在威胁。然而,以往的方法在处理现实场景中经过多种伪造操作的伪造图像时仍难以有效应对。在本文中,我们提出了一种针对IFDL任务的新型强化多教师知识蒸馏(Re-MTKD)框架,该框架围绕一个编码器-解码器ConvNeXt-UperNet以及边缘感知模块构建,该模块被命名为Cue-Net。首先,分别对三种主要类型的图像伪造进行Cue-Net模型的训练,即复制移动、拼接和修复,然后作为多教师模型,通过自我知识蒸馏,用Cue-Net训练目标学生模型。开发了一种强化动态教师选择(Re-DTS)策略,对涉及的教师模型进行动态分配权重,这有助于特定知识的转移,并使学生模型能够有效地学习不同篡改痕迹的共同和特殊性质。大量实验表明,与其它最先进方法相比,所提出的算法在最近出现的多种图像伪造数据集上具有优越的性能。
1引言
近期在图像编辑和生成模型方面的进展(Karras、Laine和Aila
2019;Rombach等2022)不仅提升了图像处理和合成的质量,还简化了其过程。然而,通过这些技术生成的篡改图像可能被滥用以传播虚假信息,对社会安全构成重大威胁。因此,迫切需要探索有效的图像取证方法,防止篡改图像的滥用。
针对上述问题,图像伪造检测与定位(IFDL)任务旨在识别伪造图像并定位其被篡改区域。通常,图像伪造操作主要包括复制移动、拼接和修复。通常,开发特定的方法用于检测和定位特定的伪造图像,该方法利用了特定类型中图像篡改的伪造痕迹的特性,例如,(Wu,Abd-Almageed,and
Natarajan 2018;Chen et al. 2020)用于复制移动,(Bi et al. 2019;Kwon
et al. 2022)用于拼接和(Li and Huang 2019;Wu and Zhou
2021)用于修复。由于训练数据仅限于特定的伪造行为,这些特定的伪造检测方法可能会过度拟合,导致泛化能力有限。这种局限性通常会导致性能不佳,尤其是在检测跨源数据时,如图4图1第一部分所示,当面对复制移动或拼接伪造时,修复检测器的性能显著下降。
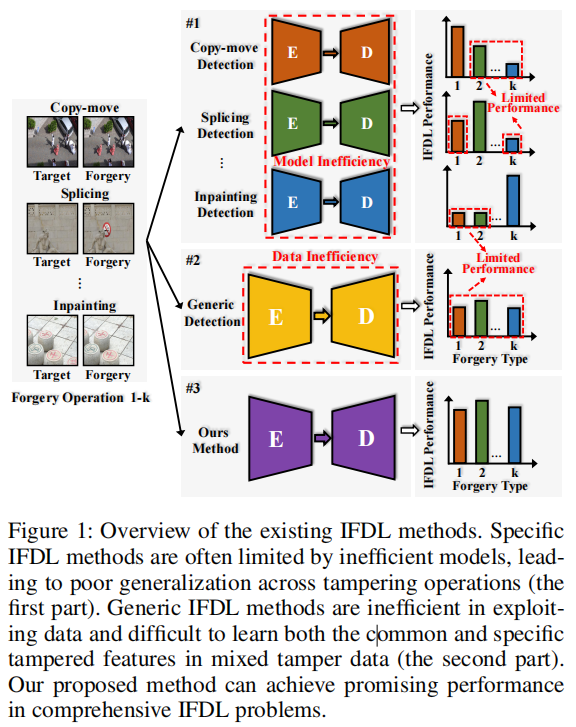
为了解决各种篡改操作,通用的伪造检测方法包括混合数据,其中包括多种类型的篡改。该策略旨在捕获各种伪造中的通用篡改特征,例如,噪声分析(Bappy等人,2019;Zhuo等人,2022;Guillaro等人,2023)、表示学习(Hu等人,2020;Yu等人,2024)、多尺度监督(Dong等人,2022;Ma等人,2023)和多视图特征融合(Liu等人,2022;Guo等人,2023)。然而,同时学习多个任务本身也带来了挑战,如图4图1第二部分所示。仅通过简单的联合训练来学习各种篡改痕迹的共同和特定性质是具有挑战性的,这通常会导致性能下降。此外,这些方法通常会增加复杂性、计算成本和额外参数,使得满足实际应用场景变得困难。因此,促进模型识别不同篡改痕迹的共同特征和具体差异的能力,提高其泛化性能,对于提升图像伪造检测和定位能力至关重要。
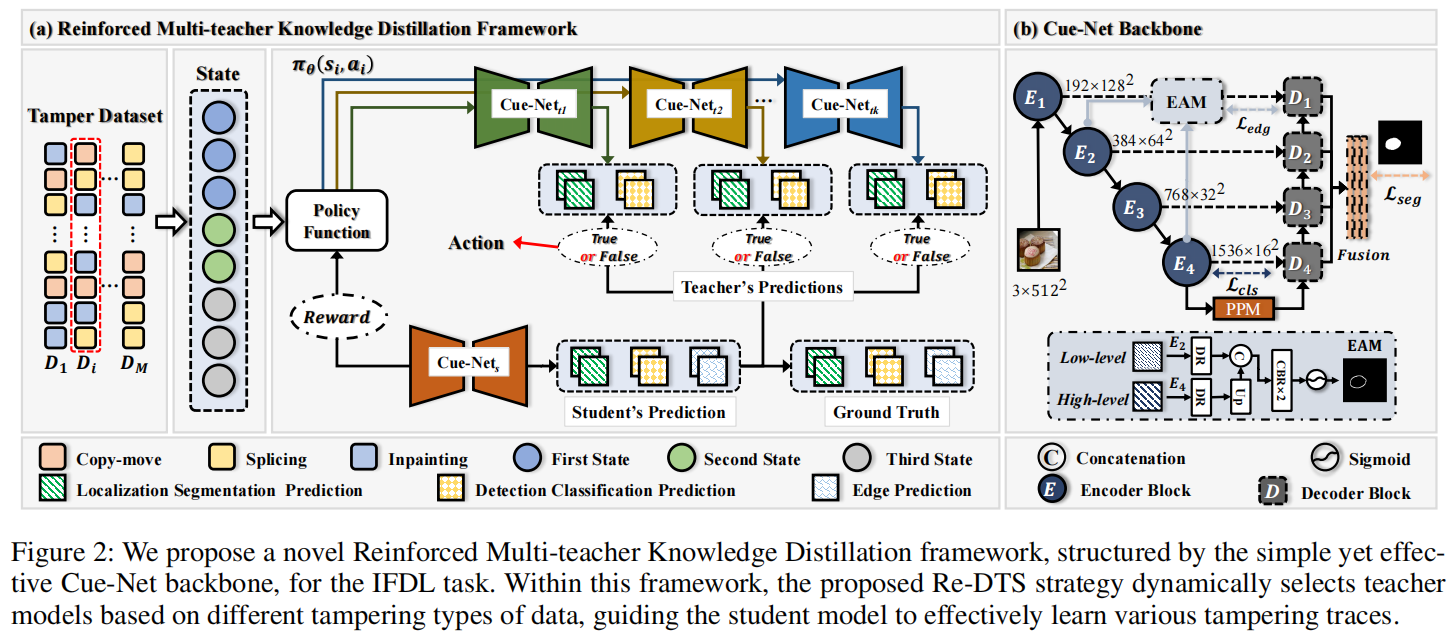
在本文中,我们提出了一种新颖的强化多教师知识蒸馏(Re-MTKD)框架,用于IFDL任务。首先,我们提出了Cue-Net模型,该模型基于ConvNeXt-UperNet结构,并配备了新颖的边缘感知模块(EAM)。EAM的集成通过融合低级和高级特征,促进了伪造伪影检测。为了有效地训练Cue-Net,我们引入了一种新颖的知识蒸馏策略,该策略利用多个教师模型,并通过一种名为强化动态教师选择(Re-DTS)的强化学习策略在训练过程中激活它们。具体来说,我们首先在不同的数据集上训练多个教师模型,每个模型专注于一种特定类型的伪造。通过引入Re-DTS策略,这些训练良好的教师模型会根据篡改数据的类型动态选择,以进行知识蒸馏。这种方法允许将不同伪造类型预训练的教师模型的知识高效地转移到学生模型中,从而降低对任何特定类型伪造痕迹的过拟合风险。我们对此工作的贡献如下:
- 我们提出了一种强化多教师知识蒸馏(Re-MTKD)框架,该框架由ConvNeXt-UPerNet结构和一种新颖的边缘感知模块(EAM)组成,该模块融合了低级和高级特征,显著增强了检测篡改痕迹的能力。
- 我们提出了一种强化动态教师选择(Re-DTS)策略,通过动态选择在特定篡改取证任务中表现出色的教师模型进行专门的知识转移,使学生模型能够学习多个篡改痕迹的共性和细节,从而最大化学生模型的伪造检测和定位能力。
- 综合实验表明,与其它最先进方法相比,该方法在多个近期的多类型篡改数据集上取得了优异的性能。
2相关工作
2.1图像伪造检测与定位
IFDL任务有几种算法,包括针对复制移动、拼接、修复和通用伪造检测策略的特定伪造检测。
2.1.1特定伪造检测
特定的IFDL方法专注于识别特定类型的数据被篡改的具体痕迹。对于复制-移动检测,BusterNet(Wu,Abd-Almageed,和Natarajan 2018)和CMSDSTRD(Chen等2020)分别设计用于并行和串行地定位复制-移动篡改图像中的源/目标区域。对于拼接检测,MFCN(Salloum、Ren和Kuo 2018)侧重于突出篡改的边缘,RRU-Net(Bi等人2019)强调残余伪影,CAT-Net(Kwon等人2022)分析RGB和DCT域中的压缩伪影。对于修复检测,HP-FCN(Li和Huang 2019)使用高通滤波器增强修复痕迹,IID-Net(Wu和Zhou 2021)采用神经架构搜索进行自动特征提取,TLTF-LEFF(Li等2023)引入局部增强变换器架构。虽然这些方法在特定的伪造类型上取得了优异的性能,但它们经常在其他类型的篡改数据上挣扎,导致模型泛化的效率低下。
2.1.2通用伪造检测
随着大数据的增长,近期的通用IFDL方法旨在学习各种篡改任务的共性。H-LSTM (Bappy et al. 2019), SATL-Net (Zhuo et al. 2022), CFL-Net (Niloy, Bhaumik, and Woo 2023)以及 TruFor (Guillaro et al. 2023)将空间域和噪声域整合起来,以检测多种操作。SPAN (Hu et al. 2020)和 DiffForensics (Yu et al. 2024)利用自监督学习来识别细微篡改痕迹。 MVSS-Net (Dong et al. 2022)和IML-Vit (Ma et al. 2023)强调多尺度监督,而PSCC-Net (Liu et al. 2022) 和HiFi-Net (Guo et al.2023)则专注于多视角特征融合。尽管这些方法在各种伪造操作中取得了有希望的结果,但由于任务不兼容,它们在联合训练中经常遭受性能退化,并且通常引入额外的复杂性和计算成本。
2.2知识蒸馏
初始知识蒸馏(KD,knowledge distillation) (Hinton, Vinyals, and Dean 2015)通过教师-学生架构将知识从一个大型教师模型转移到一个较小的学生模型。这一概念被(Zhang等人,2019)扩展到自蒸馏中,其中相同的网络同时作为教师和学生,允许学生从自身学习。对于IFDL任务,(Yu等人,2023)提出了一种固定权重的多教师自蒸馏策略来处理智能手机截图图像中的五种篡改操作,使学生模型能够学习多个篡改痕迹。然而,为每个教师模型分配固定权重可能不是最佳的,因为它阻止了对不同数据批次的动态适应,这些数据批次可能包含不同的篡改类型,从而可能限制学生模型的IFDL性能。
2.3 强化学习
强化学习在自动驾驶(Sinha等人,2020)、智能游戏(Silver等人,2016)和推荐系统(Feng等人,2018;Yuan等人,2021)等领域已经取得了令人鼓舞的结果。它的核心思想是通过使代理能够从与环境的交互中学习,并根据奖励信号调整其行为,从而最大化长期回报。在本文中,我们介绍了一种新颖的Re-MTKD框架,该框架融合了这些原则。该框架的核心是Re-DTS策略,动态选择最合适的教师模型,将专业知识转移到学生模型。这一策略增强了学生模型处理各种篡改痕迹的能力,并提高了IFDL性能。
3拟提出的Re-MTKD框架
3.1Cue-Net主干
流程
图2(b)展示了Cue-Net的架构,这是一个编码器-解码器结构。
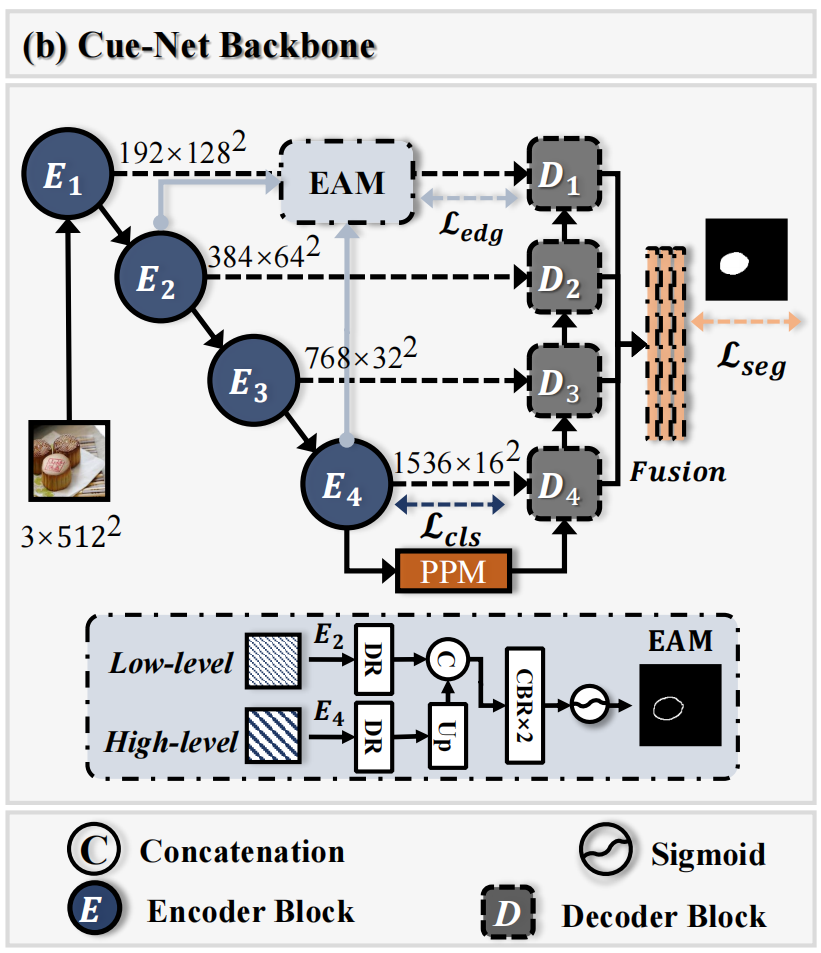
对于编码器,假设输入图像为\(x\in\mathbb{R}^{h\times w\times c}\),首先通过ConvNeXt v2(Woo等人,2023)进行特征提取,并从低到高层次获得特征图\(\{E_{j}\}_{i=1}^{4}\)。此外,\(E_2\)和\(E_4\)用作本文提出的EAM的输入,将在下一小节中介绍。解码器采用UPerNet(Xiao等人,2018),包括两个组件:金字塔池化模块(PPM)(Zhao等人,2017)和特征金字塔网络(FPN)(Lin等人,2017)。FPN输出特征图\(\{D_{j}\}_{i=1}^{4}\),使用双线性插值将其调整为原始尺寸,然后合并以获得应用sigmoid激活函数后的定位分割结果。
边缘感知模块
为了进一步增强细粒度的篡改痕迹提取,我们设计了一个简单而有效的边缘感知模块(EAM),该模块能够准确地提取篡改区域的边缘信息,以便于后续的引导和融合。篡改区域的边缘通常只由几个像素组成,这使得仅使用最低分辨率的高级特征图难以实现精确的边缘监督。相反,仅使用高分辨率的低级特征图很难感知到被篡改的区域。在EAM中,我们在多级特征上执行边缘监督,这是通过在编码器中融合低级特征E2和高级特征E4得到的,如下所示,
\[f^{\epsilon}=\sigma(C B R(C a t(D
R(E_{2}),U p(D R(E_{4})))),\] 其中,\(\sigma(\cdot)\)是sigmoid归一化,CBR模块(卷积+
BN +
ReLU)实现了低级和高级特征的融合,Cat(·)表示拼接操作,DR代表使用CBR模块进行降维,U
p表示上采样。随后,获得的边缘预测图f e和边缘标签y e被用于损失迭代。
损失函数
在以前的IFDL方法(Liu et al. 2022;Dong et al.
2022;Guo et al.
2023)的基础上,我们的方法包括三种类型的监督:定位分割(像素级)监督\(\mathcal{L}_{seg}\)和检测分类(图像级)监督\(\mathcal{L}_{cls}\)作为标准,以及边缘检测监督\(\mathcal{L}_{edg}\)作为特殊设计。
对于本地化分割监督\(\mathcal{L}_{seg}\),根据(Guillaro等人,2023),我们使用加权\(\ell_{w b c e}\)和\(\ell_{d i c
e}\)(Milletari、Navab和Ahmadi,2016)的组合。 \[\mathcal{L}_{s e g}=\lambda_{0}^{s}\ell_{w b c
e}(f^{s},y^{s})+\left(1-\lambda_{0}^{s}\right)\ell_{d i c
e}(f^{s},y^{s}),\] 其中\(\lambda_{0}^{s}\)是分割平衡权重,\(f^{s}\)和\(y^{s}\)分别是定位结果和定位标签。
在ConvNeXt
v2(Woo等人,2023)之后,我们使用标准\(\ell_{b
c e}\)设计了E4上的检测分类损失\(\mathcal{L}_{c l s}\), \[\mathcal{L}_{c l s}=\ell_{b c
e}(f^{c},y^{c}),\] 其中\(f^{c}\)和\(y^c\)分别是检测分类结果和分类标签。
对于边缘监督\(\mathcal{L}_{e d g}\)与EAM,我们使用\(\ell_{d i c e}\)更好地关注微小的边缘区域,
\[\mathcal{L}_{e d g}=\ell_{d i c
e}(f^{e},y^{e}).\] 对于最终的组合损失,也就是“硬”损失\(\mathcal{L}_{h a r
d}\),从三个角度加权,得到我们最近的监督损失函数, \[\mathcal{L}_{\mathrm{hard}}=\alpha\cdot\mathcal{L}_{s
e g}+\beta\cdot(\mathcal{L}_{c l s}+\mathcal{L}_{e d g}),\]
其中α、β、∈、[0,1]。术语“硬”表示每个像素的二进制标签用于监督。
3.2强化动态教师选拔策略
在介绍Re-DTS策略之前,我们将首先构建单教师知识蒸馏KD。为了更好地提升学生模型的定位分割和检测分类性能,我们选择通过“软”损失\(\mathcal{L}_{s o f t}\)进行专门知识的迁移,如下所示, \[\mathcal{L}_{s o f t}=\mathcal{L}_{s e g}(f_{\bf{s}}^{s},f_{\bf{t}}^{s})+\mathcal{L}_{c l s}(f_{\bf{s}}^{c},f_{\bf{t}}^{c}),\] 其中加粗\(\bf{t}\)和\(\bf{s}\)分别表示教师模型和学生模型。
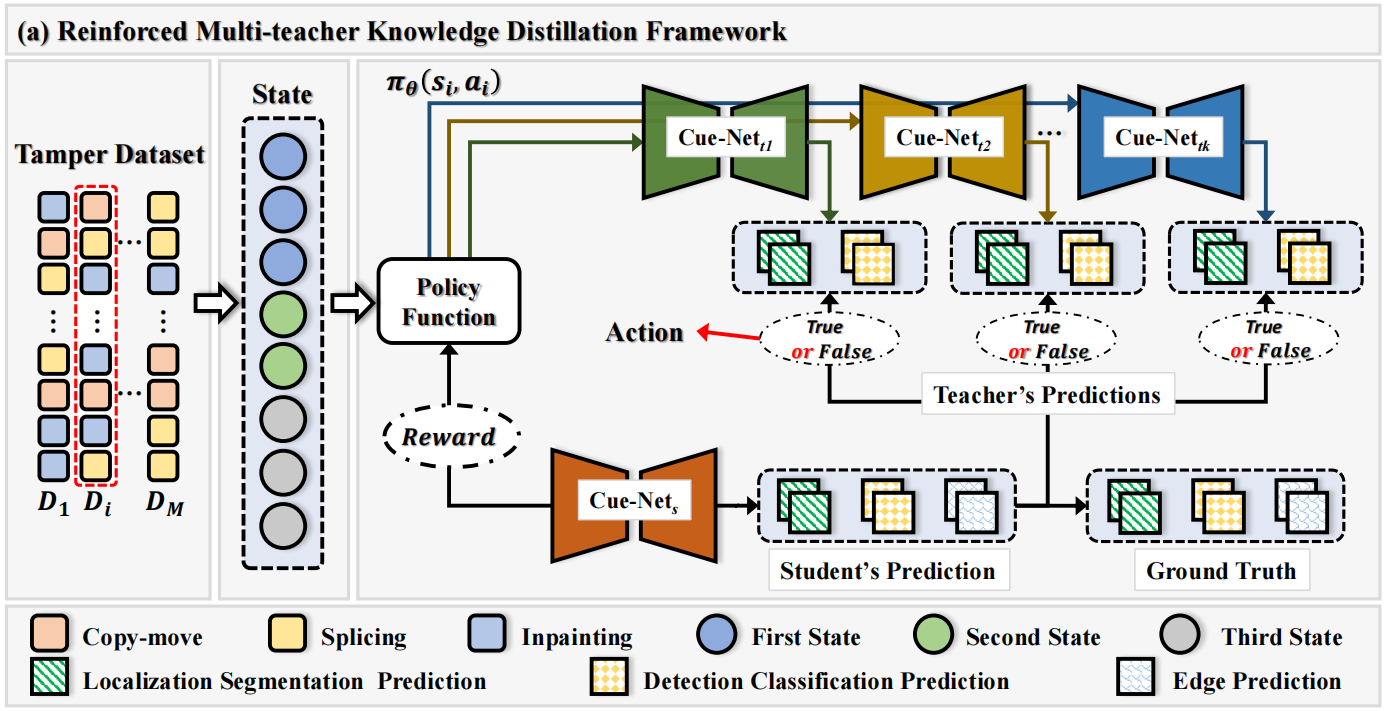
图2(a)展示了我们的Re-DTS策略概览。强化学习中的元素(即状态、动作和奖励)介绍如下。为了明确起见,由于所有教师模型共享相同的训练过程,我们仅介绍其中一个,三个教师模型分别表示为\(\{\Theta_{k}^{t}\}_{k=1}^{3}\)。
状态
我们的Re-DTS策略包含一系列环境状态s1、s2,...,这些状态总结了待检测的篡改图像特征、学生模型特征和候选教师模型特征,以便做出合理的决策。为了构建状态\(s_i\),我们设计了一个状态特征向量\(\mathbf{F}\left(S_{i}\right)\),其中包含了三个特征的组合。
第一个特征是第i个批次图像xi的向量表示\(\mathcal{R}(x_{i})\in\mathbb{R}^{d}\),它可以由任何IFDL表示模型\(\Theta^{r}\)生成。在本文中,我们通过将该批图像xi输入到Cue-Net中,获得解码器D4最后一层的输出作为特征\(\mathcal{R}(x_{i})\),而Cue-Net尚未在任何IFDL任务数据上进行训练。
第二个特征\(\mathcal{S}(x_{i})\in\mathbb{R}^{d}\)的获得方式类似,只是特征向量是从学生模型\(\Theta^{s}\)输出的,该模型在IFDL任务数据上实时训练,旨在有效地表示篡改图像的内容。
第三个特征\(\mathcal{T}_{k}(x_{i})\in\mathbb{R}^{1+1+1}\),分别由教师模型\(\Theta_{k}^{t}\)的定位分割预测结果\(f_{\bf{t}k}^{s}\)、检测分类预测结果\(f_{\bf{t}k}^{c}\)和篡改边缘预测结果\(f_{\bf{t}k}^{e}\)组成,旨在指导策略网络执行更优的动作。
\[{\mathcal T}_{k}(x_{i})=C a t(M a
x(f_{\mathrm{tk}}^{s}),f_{\mathrm{tk}}^{c},M a
x(f_{\mathrm{tk}}^{e})),\]
其中Max(·)是最大池化操作。
因此,状态特征向量\({\bf
F}\left(s_{i}\right)\in{\bf\mathbb{R}}^{2d+3}\)可以表示如下:
\[\mathrm{\bf{F}}(s_{i})=C a
t({\mathcal{R}}(x_{i}),{\mathcal{S}}(x_{i}),{\mathcal
T}_{k}(x_{i})),\] 其中,这种连接确保状态特征向量\(\mathrm{\bf{F}}(s_{i})\)全面反映图像和模型特性,使策略网络能够做出更明智、更有效的决策。
动作
每个教师模型\(\Theta^{t}\)都与一个策略网络相关联,动作\(a_{i}\in\{0,1\}\)定义为指示是否选择策略网络将第k个教师模型\(\Theta_{k}^{t}\)的特殊知识转移到学生模型\(\Theta^{s}\)。我们使用策略函数\(\pi_{\theta}(s_{i},a_{i})\)对\(a_i\)的值进行采样,其中θ是需要学习的参数。在本文中,我们采用以下逻辑函数作为策略函数:
\[\begin{array}{l}\pi_{\theta}(s_{i},a_{i})&=P_{\theta}\
(a_{i}\mid s_{i})\\&=a_{i}\sigma({\bf W} * {\bf
F}(s_{i})+b)+(1-a_{i})(1-\sigma(\mathbf{W}*\mathbf{F}(s_{i})+b))\end{array}\]
其中\(\mathbf{W}\in\mathbb{R}^{2d+3}\),\(b\in\mathbb{R}^{1}\)为可训练参数。
奖励
合理的奖励可以指导教师模型提炼出一个表现优异的学生模型。对于训练数据\(\mathcal D=\{\mathcal D_{1},\mathcal
D_{2},...,\mathcal
D_{M}\}\),其中M是每个周期的批次数,我们为每个教师模型\(\Theta_{k}^{t}\)构建一个特征向量\(s_{i k}\),并根据策略函数\(\pi_{\theta}(s_{i k},a_{i
k})\)为第i个批次的数据\(\mathcal
D_{i}\)选择动作\(a_{i
k}\),以确定该动作是否被选中。对于所有采样的教师模型,我们将所有教师模型的损失\(\mathcal{L}_{s o f t}\)与损失\(\mathcal{L}_{h a r
d}\)集成,以更新学生模型参数\(\Theta^{s}\)。
我们提出了三种奖励计算方法。第一种是“硬”损失\(\mathcal{L}_{h a r
d}\),包括定位分割损失\(\mathcal{L}_{seg}\)、检测分类损失\(\mathcal{L}_{cls}\)和篡改边缘检测损失\(\mathcal{L}_{edg}\)。第二种奖励函数结合了“硬”损失\(\mathcal{L}_{h a r
d}\)以及教师模型的“软”损失\(\mathcal{L}_{s o f
t}\)。最后,为了提高学生模型在IFDL任务上的性能,我们在训练过程中使用学生模型的定位分割F1分数和检测分类准确率作为第三个奖励。总之,我们有
\[\begin{array}{l}r e w a r
d_{1}=&-\mathcal{L}_\mathrm{hard}\\r e w a r
d_{2}=&-(\mathcal{L}_\mathrm{hard}+\mathcal{L}_\mathrm{soft})\\r e w
a r
d_{3}=&-\gamma(\mathcal{L}_{\mathrm{hard}}+\mathcal{L}_{\mathrm{soft}})+(1-\gamma)((F1_{s
e g}+A c c_{c l s})o n D_{i}),\end{array}\] 其中,\(\gamma\)是一个超参数,用于平衡不同的奖励。我们最终选择第三个奖励作为默认选项。值得注意的是,根据强化学习(Williams
1992)的方法,在每一步之后不会立即奖励更新,因此我们将更新推迟到训练了10B批次之后,其中B表示批量大小。
最优化
根据策略梯度定理(Sutton等人,1999)和强化算法(Williams,1992),我们计算梯度以更新当前策略如下:
\[\theta\leftarrow\theta+\xi\sum_{i}r\sum_{k}\nabla_{\theta\pi_{\theta}(s_{i
k},a_{i k})},\] 其中r是等式10中定义的奖励函数,ξ是学习率。
3.3模型的训练过程
算法1概述了ReMTKD框架的训练过程。

在开始联合训练之前,我们对模型进行预训练。教师模型\(\Theta_{k}^{t}\)使用针对相应类型篡改数据\(\mathcal D ^
k\)的专门知识进行预训练。然后,在KD知识蒸馏过程中,通过选择所有教师模型的反馈来初始化策略网络\(\theta_{k}\)。
初始化后,执行Re-DTS策略,根据\(\mathcal{L}\)优化学生模型,如算法2所示。

在这个过程中,我们首先固定策略网络\(\theta_{k}\)来训练学生模型\(\Theta^{s}\)。在预定的迭代次数之后,我们固定\(\Theta^{s}\),计算返回内容,并优化教师选择策略网络\(\theta_{k}\)。重复此过程,直到完成所有训练迭代。
4实验
4.1实验设置
数据集
考虑到可用性和通用性,我们选择了十个具有挑战性的基准数据集来评估我们的方法,涵盖篡改类型:复制移动(Com)、拼接(Spl)、修复(Inp)和多篡改(Multi)。这些数据集的详细信息见附录。
1)对于复制移动,我们使用CASIA
v2(Dong、Wang和Tan 2013)和Tampered
Coco(Liu等2022)进行训练,并使用CASIA v1+(Dong、Wang和Tan
2013)、NIST16(Nimble
2016)和Coverage(Wen等2016)进行测试。
2)对于拼接,我们使用CASIA
v2(Dong,Wang,and Tan 2013)和Fantastic-Reality(Kniaz,Knyaz,and
Remondino 2019)进行训练,并使用CASIA v1+(Dong,Wang,and Tan
2013)、NIST16(Nimble 2016)、Columbia(Hsu and Chang 2006)和DSO-1(De
Carvalho et al. 2013)进行测试。
3)对于修复,我们使用GC
Dresden&Places(Wu和Zhou 2021)进行训练,并使用NIST16(Nimble
2016)、AutoSplicing(Jia等2023)和DiverseInp(Wu和Zhou
2021)进行测试。
4)对于多篡改,我们使用IFC(Challenge
2013)、Korus(De
Carvalho等人,2013)和IMD2020(Novozamsky、Mahdian和Saic,2020)进行测试,因为这些数据涉及上述单一篡改类型的复合操作。
| 篡改类型 | 训练方法及来源 | 测试方法及来源 |
|---|---|---|
| 复制移动 | CASIA v2 (Dong, Wang, and Tan 2013), Tampered Coco (Liu et al. 2022) |
CASIA v1+ (Dong, Wang, and Tan 2013), NIST16 (Nimble 2016), Coverage (Wen et al. 2016) |
| 拼接 | CASIA v2 (Dong, Wang, and Tan 2013), Fantastic-Reality (Kniaz, Knyaz, and Remondino 2019) |
CASIA v1+ (Dong, Wang, and Tan 2013), NIST16 (Nimble 2016), Columbia (Hsu and Chang 2006), DSO-1 (De Carvalho et al. 2013) |
| 修复 | GC Dresden & Places (Wu and Zhou 2021) | NIST16 (Nimble 2016), AutoSplicing (Jia et al. 2023), DiverseInp (Wu and Zhou 2021) |
| 多篡改 | —— | IFC (Challenge 2013), Korus (De Carvalho et al. 2013), IMD2020 (Novozamsky, Mahdian, and Saic 2020) |
对于Cue-Net学生模型\(\Theta^{s}\)和其他SOTA方法,训练是在所有混合的单次篡改数据上进行的。相比之下,在强化多教师知识蒸馏过程中,每个教师模型\(\Theta^{t}\)是在相应类型的篡改数据上进行训练的。
实施细节
我们使用单个Nvidia Tesla A100 GPU
(80
GB内存)在PyTorch深度学习框架上进行实验,强化多教师知识蒸馏KD的参数配置如下:
1)对于单教师模型预训练,我们将输入图像调整为512×512,并应用AdamW优化器。我们通过学习率设为1×10−4,批量大小设为24,训练轮数设为50来设置训练超参数。为了平衡伪造检测和定位的性能,我们将伪造定位Lseg的权重设为α
= 1,λs
0设为0.1。检测分类监督Lcls和边缘监督Ledg的权重β设为0.2。
2)对于强化多教师知识蒸馏KD,我们使用与单教师模型预训练相同的参数设置,包括输入图像大小、优化器、学习率和批量大小,但在此训练阶段使用更多的训练数据和仅25个epoch。对于奖励3中的γ,我们将其设置为0.2。对于L,我们为整体教师损失Lsoft设置约束因子ω
=
0.05,该约束因子乘以选定教师的数量,以平衡教师模型知识迁移和学生模型自主学习的过程。
3)对于策略网络,学习率设置为3×10−4,并使用Adam优化器通过CosineAnnealingLR进行调整。
4.2与最新方法的比较
为了进行公平的比较,我们关注的是在与测试数据集不同的数据集上训练的有可用代码或预训练模型的方法。我们比较针对特定伪造类型和通用伪造检测的方法如下:
DoaGan
(Islam et al. 2020)、
BusterNet (Wu, Abd-Almageed, and Natarajan
2018)
CMSDSTRD (Chen et al.
2020)是为复制移动检测而设计的。
MFCN (Salloum, Ren, and Kuo
2018)、
RRU-Net (Biet al. 2019)
CAT-Net (Kwon et al.
2022)是为剪接检测而设计的。
HP-FCN (Li and Huang 2019),
IIDNet (Wu and Zhou 2021)
TLTF-LEFF (Li et al.
2023)是为修复检测而设计的。
H-LSTM (Bappy et al.2019),
SPAN
(Hu et al. 2020),
MVSS-Net (Dong et al.2022),
SATL-Net
(Zhuo et al. 2022),
PSCC-Net (Liu et al.2022),
HiFi-Net
(Guo et al.2023)
IML-Vit (Ma et
al.2023)是为通用伪造检测而设计的。
4.2.1检测评估
表1展示了伪造检测性能。
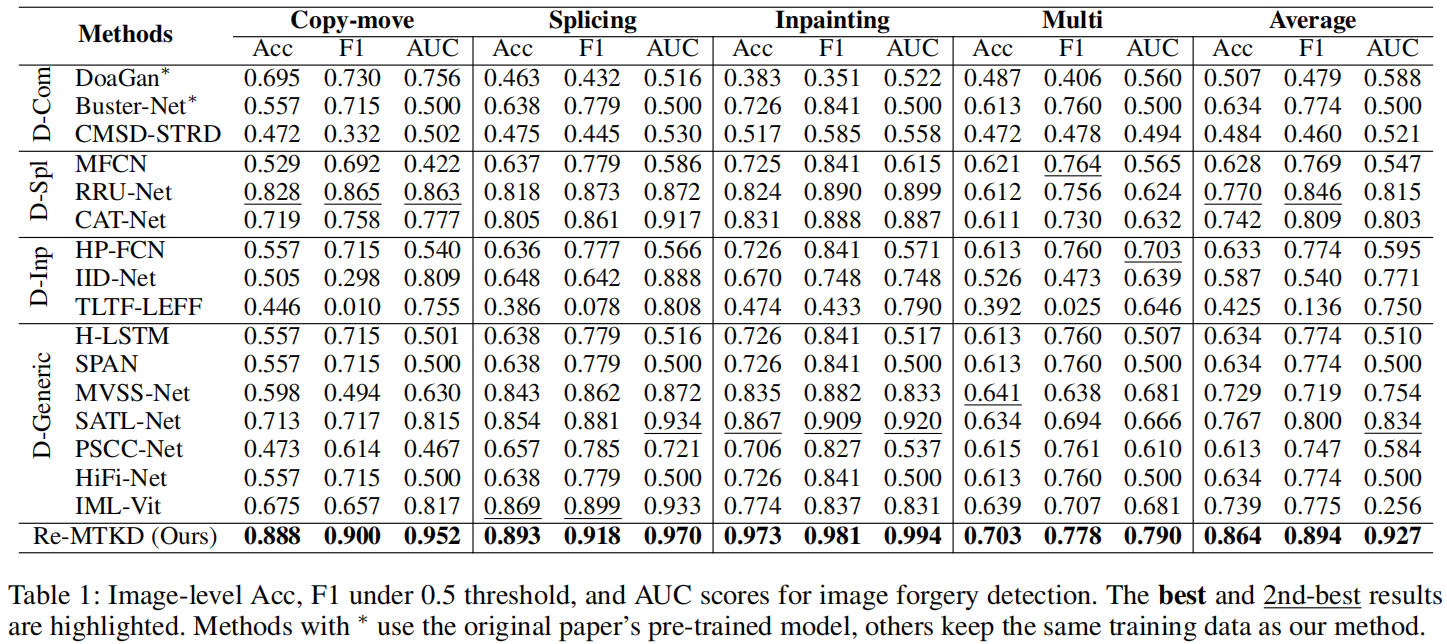
我们观察到许多方法表现非常差,其AUC接近0.5,即接近随机猜测,例如Buster-Net、H-LSTM、SPAN和HiFi-Net。得益于提出的Re-MTKD框架,该框架包括Cue-Net和Re-DTS策略,我们的方法在所有篡改类型的数据集上均达到了SOTA性能。特别是在多篡改数据集上,该数据集包含更复杂的篡改类型,所有比较方法的表现都很差,但我们的方法在AUC得分上比第二名高出8.7%。
4.2.2定位评估
表2展示了伪造定位性能。
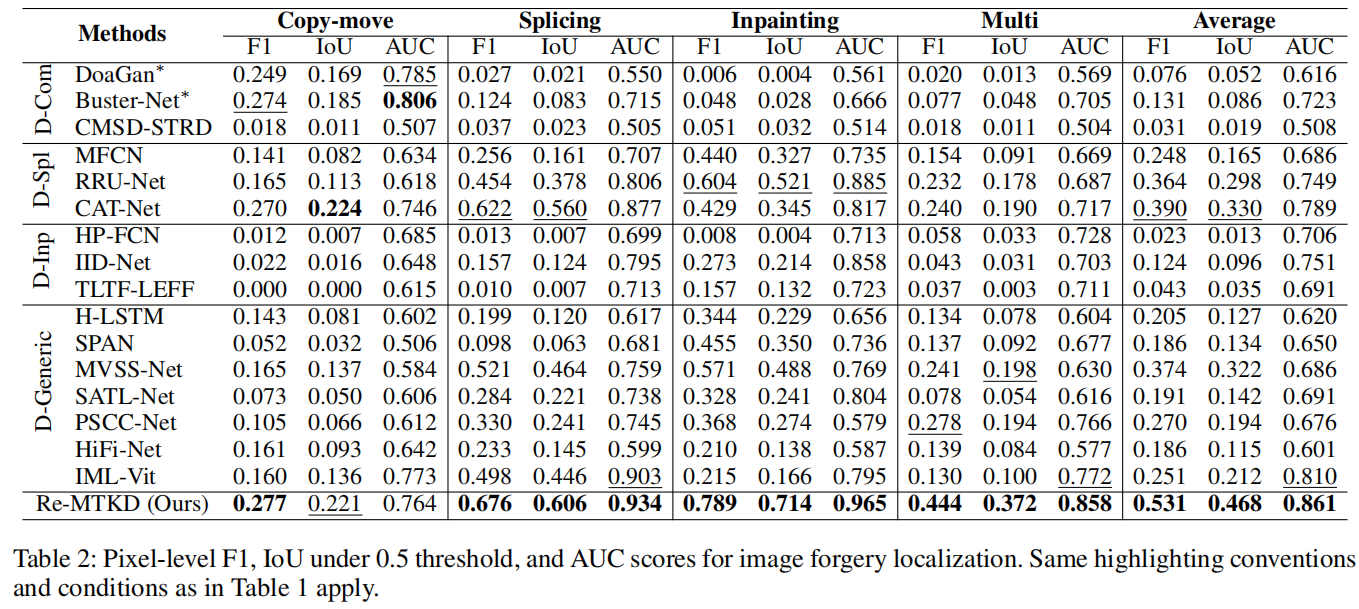
值得注意的是,一些专门针对伪造的检测方法在相应数据上表现出竞争力,例如,Buster-Net在复制移动数据上达到了最佳的AUC分数,CAT-Net在拼接数据上取得了第二好的表现,而IID-Net在修复数据上也获得了具有竞争力的AUC分数。然而,这些方法在应用于其他类型的伪造或多篡改数据时常常表现不佳,导致性能显著下降。有趣的是,很少有通用的伪造检测方法能在特定和多篡改类型中始终表现出强大的效果,这突显了同时学习多个篡改痕迹的挑战。相比之下,我们的方法在所有数据集上都取得了优异的结果,并且平均而言明显优于其他方法,突显了其有效捕捉多种篡改竞赛的共性和特性的能力。
4.2.3更多的评估(补充资料)
定量结果
我们提供了主文中所使用SOTA方法性能的更全面概述。表5展示了使用这些SOTA方法的官方预训练模型获得的IFDL结果。
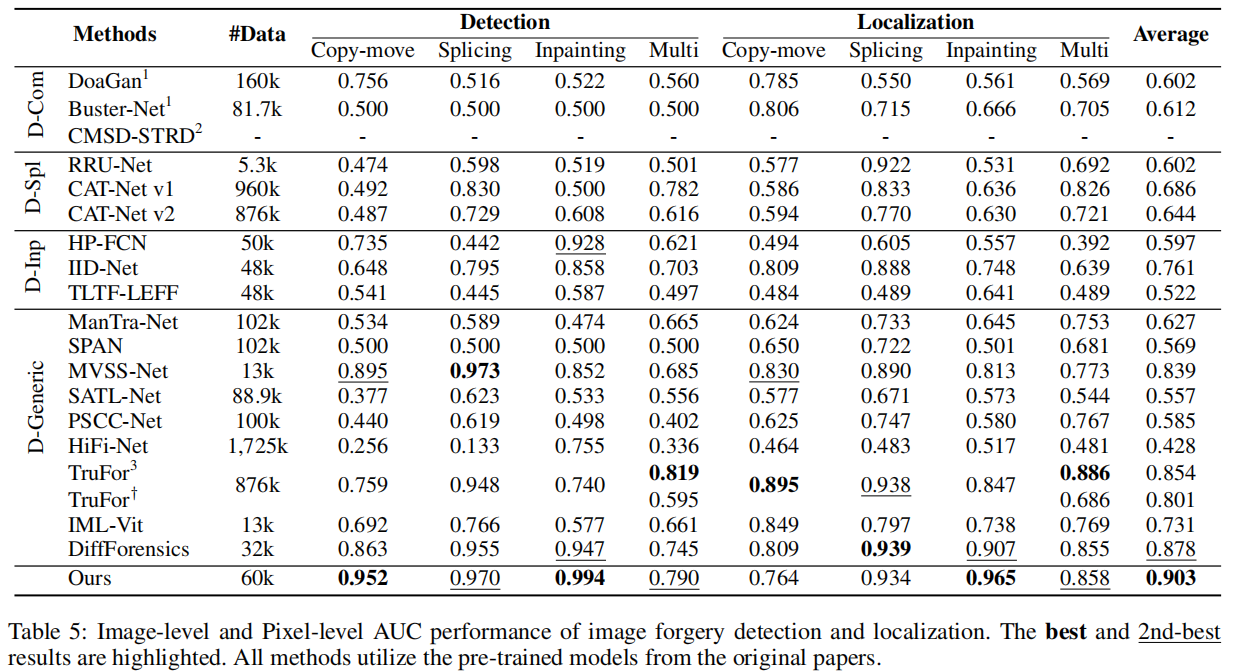
可以观察到,特定的伪造检测方法在相应的篡改类型数据上表现出更好的性能。例如,DoaGan
(Islam等人,2020年)和Buster-Net
(Wu、Abd-Almageed和Natarajan,2018年)在复制移动数据上的定位表现尤为出色,而RRU-Net
(Bi等人,2019年)和CAT-Net v1
(Kwon等人,2021年)在拼接数据上的定位能力更胜一筹。此外,HP-FCN
(Li和Huang,2019年)和TLTF-LEFF
(Li等人,2023年)在修复数据上的检测和定位性能分别非常显著。然而,许多通用的伪造检测方法,如SPAN
(Hu等人,2020年)、SATL-Net (Zhuo等人,2022年)、PSCC-Net
(Liu等人,2022年)和Hi-Fi-Net
(Guo等人,2023年),尽管是在大型数据集上训练的,但在多种篡改类型上的表现却较差。
此外,我们还纳入了竞争比较方法,如ManTra-Net(Wu、AbdAlmageed和Natarajan
2019)和TruFor(Guillaro等人2023),但这些方法未在主文中提及。这是因为这两种方法均未公开发布训练代码,仅提供测试代码。值得注意的是,TruFor是在更大规模的数据集上进行训练的(TruFor使用867k的数据集,而我们的方法使用60k的数据集),并且受到了数据泄露的影响(TruFor使用IMD2020(Novozamsky、Mahdian和Saic
2020)进行训练,本文作为多篡改类型测试数据的一部分)。
特别是在复制-移动和拼接数据上,TruFor展现了卓越的伪造定位性能。然而,其伪造检测性能欠佳,在修复数据上的表现也显著下降,突显了同时处理多种篡改数据类型的挑战。对于多次篡改的数据,我们的方法仍能与TruFor达到相当的性能,尽管TruFor的测试模型存在上述数据泄露问题。当排除IMD2020数据集时,该数据集存在数据泄露问题,我们的方法在平均AUC分数上比TruFor高出10.2%。总体而言,本文提出的Re-MTKD框架有效提升了模型在各种篡改数据类型上的性能,并实现了最优的平均AUC性能。
定性结果
我们展示了特定和通用伪造检测方法在各种类型篡改数据上的定性评估,包括复制移动、拼接、修复和多次篡改数据,以及真实数据,如图8所示。

可以看出,特定的伪造检测方法在相应数据上表现更佳,例如Buster-Net(吴、阿卜杜勒-马吉德和纳塔拉詹2018)在复制移动数据上,RRU-Net(毕等人2019)和CAT-Net(权等人2022)在拼接数据上,以及IID-Net(吴和周2021)在修复数据上。与通用的伪造检测方法相比,我们的方法最终在各种类型的篡改数据中实现了更准确的伪造定位结果。此外,我们提出的方法在应用于真实图像时表现出更低的误报率。
鲁棒性
我们进一步评估了在社交媒体洗牌中面对常见图像扰动时定位结果的鲁棒性,即JPEG压缩、高斯模糊、高斯噪声和中值滤波。如图5所示,一些通用的IFDL方法,例如针对JPEG压缩的PSCCNet(刘等,2022)和针对高斯模糊的SATLNet(卓等,2022),性能显著下降。
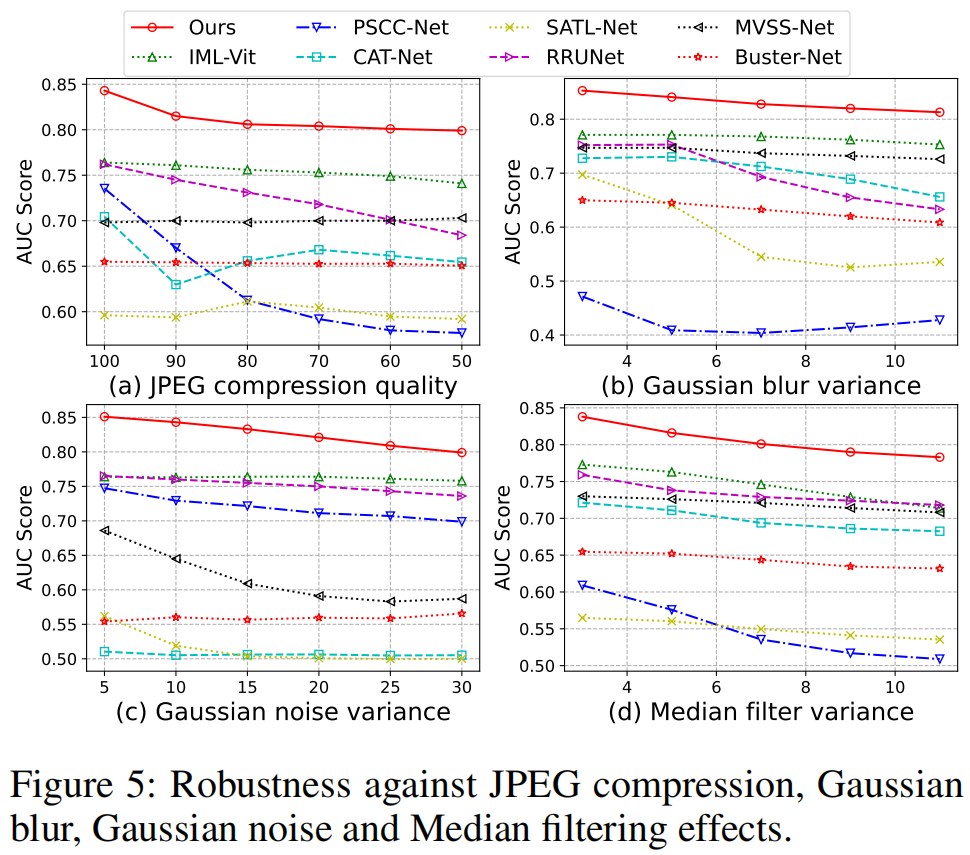
相比之下,我们的方法在整个后处理攻击范围内展示了出色的鲁棒性。
推理效率
如表6所示,我们选择了具有竞争力的SOTA方法在复制移动数据集上进行测试,其中我们的方法在五次运行中平均实现了最快的推理速度和具有竞争力的内存使用。我们的方法展示了卓越的推理效率,推理速度达到38.2毫秒/图像,显著优于其他方法,如MVSS-Net
(129.37毫秒/图像)和TruFor (64.87毫秒/图像)。
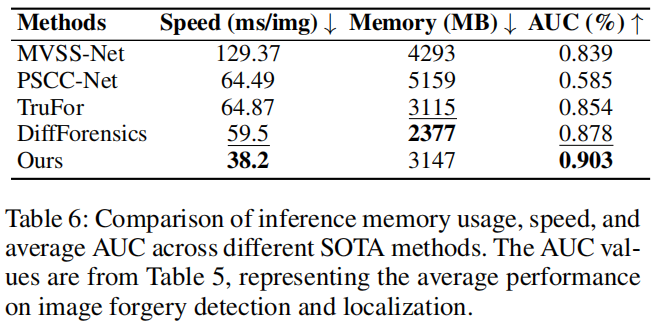
最终,它达到了最高的AUC值0.903,证实了我们的方法在推理效率和性能之间达到了最佳平衡,在检测和定位任务中均表现出色。
4.3消融研究
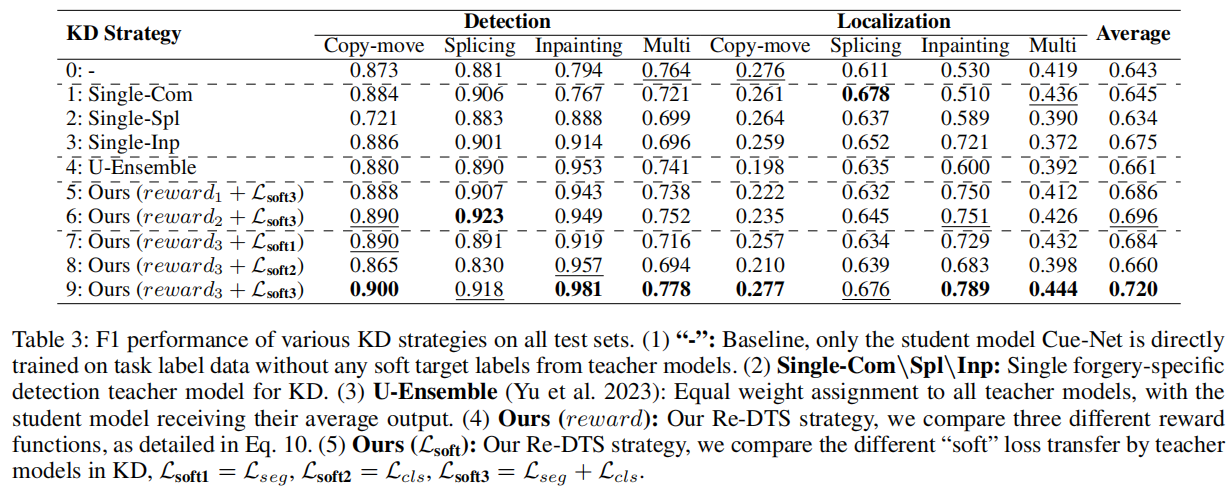
本小节主要分析Re-MTKD框架关键组件的有效性。表3展示了Re-DTS策略的消融结果,以及分配教师权重的其他策略。
关于消融实验的更多细节,请参见附录。
4.3.1知识蒸馏中教师模型的有效性
比较设置#0至设置#3,可以观察到简单的Cue-Net学生模型难以应对广泛的篡改攻击。相比之下,专门针对伪造检测的教师模型能够提高学生模型在相应数据上的性能,例如,在修复数据上,Singe-Inp在伪造检测和伪造定位F1性能方面分别比设置#0提高了14%和19%。
比较设置#0和设置#4,U-Ensemble在IFDL任务中提供了一些性能提升,但在某些操作类型如复制移动和多点篡改时表现下降。这表明,跨多个教师平均权重未能充分捕捉不同篡改操作的独特共性,可能不是最有效的策略。
4.3.2Re-DTS策略的有效性
如最后五个设置所示,我们比较了本文提出的ReDTS中不同奖励和各种教师知识迁移策略Lsoft的效果。
(i)奖励:通过比较设置#5、设置#6和设置#9,可以发现增加奖励作为从教师模型到学生模型的知识迁移监督,能够更好地提升学生模型的性能。对于设置#9,本文采用的最终奖励(奖励3),即教师模型Lsoft的“软”损失和“硬”损失Lhard的总奖励,以及学生模型在伪造定位F1和伪造检测Acc上的性能指标,都有效提升了学生的整体表现。
(ii)Lsoft:通过比较设置#7、设置#8和设置#9可以看出,教师模型转移的专业知识在伪造检测和定位方面的结合,更高效地提高了学生模型的IFDL性能。我们的方法(设置#9)不仅在多个特定的伪造数据上取得了优异的结果,在更具挑战性的多篡改数据上也达到了同等高效的性能。
此外,我们还展示了学习特征的嵌入空间以及不同KD策略的t-SNE(Van
der Maaten和Hinton 2008)可视化图,如图3所示。
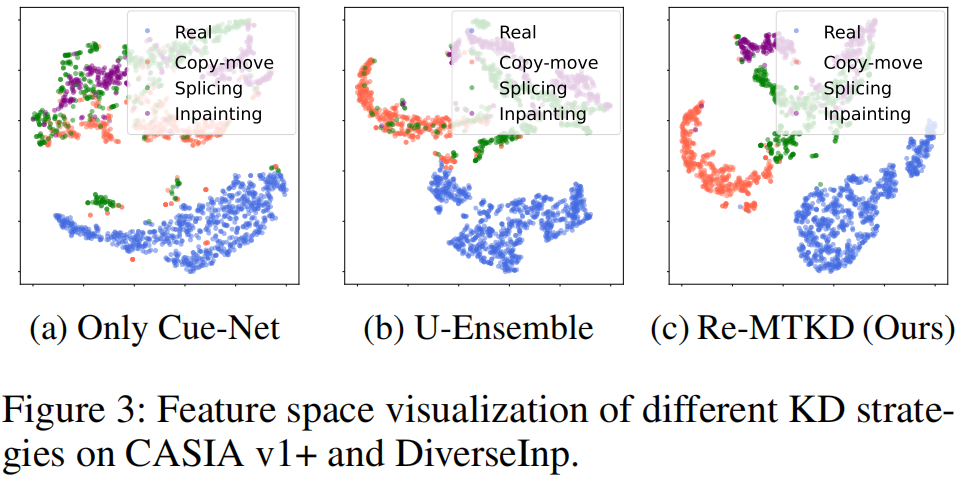
我们观察到,在我们提出的Re-MTKD框架中,Cue-Net在使用Re-DTS策略训练时,能够有效区分真实样本和篡改样本的特征分布,优于其他KD策略。这表明模型能够学习不同篡改类型之间的共同特征,从而能够准确地将所有篡改样本分类为篡改样本,无论具体的篡改技术如何。此外,模型还捕捉到了每种篡改类型的特定特征,使得每个类别的篡改样本分布更加集中且明显。
5结论
在本文中,我们提出了一种新颖的强化多教师知识蒸馏(Re-MTKD)框架,专为图像伪造检测与定位(IFDL)设计。具体而言,我们开发了一种名为Cue-Net的新网络,该网络采用ConvNeXt-UPerNet结构,并配备了一个边缘感知模块,作为IFDL任务的有效骨干。我们进一步引入了一种强化动态教师选择(Re-DTS)策略,该策略根据不同类型的篡改数据动态选择专门的教师模型,引导学生模型有效学习各种篡改痕迹的共性和特异性。广泛的实验结果表明,与现有的最先进方法相比,我们提出的方法在多个IFDL任务中表现出色。
6评价(非作者、主观评价)
1.总体评价:这篇文章发表于AAAI2025,首先将强化学习的方案应用于图像篡改检测任务确实是一个创新的举动,但是其还有些许不足。
2.数据集测试的改动:其没有按照主流方法,以数据集为界,进行测试,而是以篡改方法为界,数据集的篡改有简易有困难,类似于Splicing篡改,Columbia
数据集属于比较容易的数据集,其分数一定程度上会拉升在此篡改任务上的分数,在不分享代码的情况下,使用新颖的数据测试方法,无法让其他研究者与其进行比较。
3.格式性错误:第一段应该是图1,写成了图4