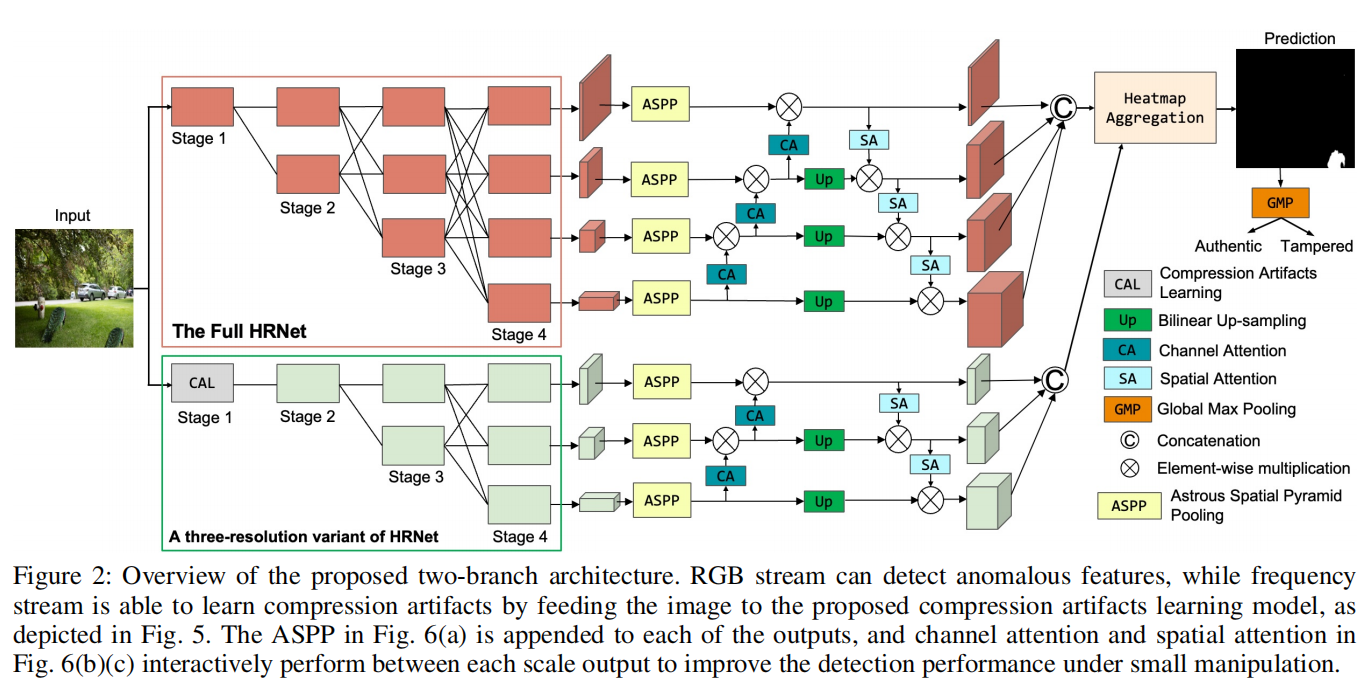
Rethinking Image Editing Detection in the Era of Generative AI Revolution

Rethinking Image Editing Detection in the Era of Generative AI Revolution
Zhihao Sun,Haipeng Fang,Juan Cao,Xinying Zhao,Danding Wang∗
1中国科学院计算技术研究所、中国科学院大学
2中国科学院计算技术研究所
摘要
图像编辑与处理技术对图像内容的真实性、安全性带来严重威胁,因此图像区域篡改检测研究一直是图像处理领域的重要课题。生成式AI的快速发展显著提升了区域生成编辑方法的可行性和有效性,正逐步取代传统图像编辑工具或算法。然而当前研究仍主要聚焦于传统图像篡改领域,目前缺乏包含大量生成式区域编辑方法处理图像的综合性数据集。
我们致力于通过构建GRE数据集来填补这一空白,该数据集是一个大规模生成性区域编辑检测数据集,具有以下优势:
1)整合了逻辑化与模拟化的编辑流程,利用多种模态下的大型模型;
2)包含具有不同特征的各类编辑方法;
3)为相关领域提供最先进方法的全面基准测试与评估;
4)从必要性、合理性及多样性等多个维度对GRE数据集进行分析。
大量实验和深入分析表明,这个更大更全面的数据集将显著提升生成性编辑检测方法的发展水平。相关数据仓库地址为https://github.com/ICTMCG/GRE。
1 引言
尽管图像编辑与处理技术丰富了视觉内容,但同时也对各类媒体中的图像真实性与安全性构成重大威胁。因此,图像区域操控检测研究始终是关键课题。近年来,扩散模型在计算机视觉领域掀起AI生成革命,在可控编辑[29,30,46,47]等任务场景中展现出卓越性能。生成式技术的进步降低了编辑成本并提升了效果,正逐步用生成式编辑方法取代传统工具。然而当前检测研究仍聚焦于传统编辑方式,在新型生成式区域操控检测方面仍存在研究空白。
与全图生成技术需要精准控制的高难度操作不同,局部编辑方法展现出更强的灵活性,能够对原始图像中的特定内容进行修改[29,42,48],从而改变其传达的信息。相较于使用PhotoShop等工具的传统手动处理方式,生成式区域编辑不仅对非专业人士更友好便捷,还能实现高质量的编辑效果。
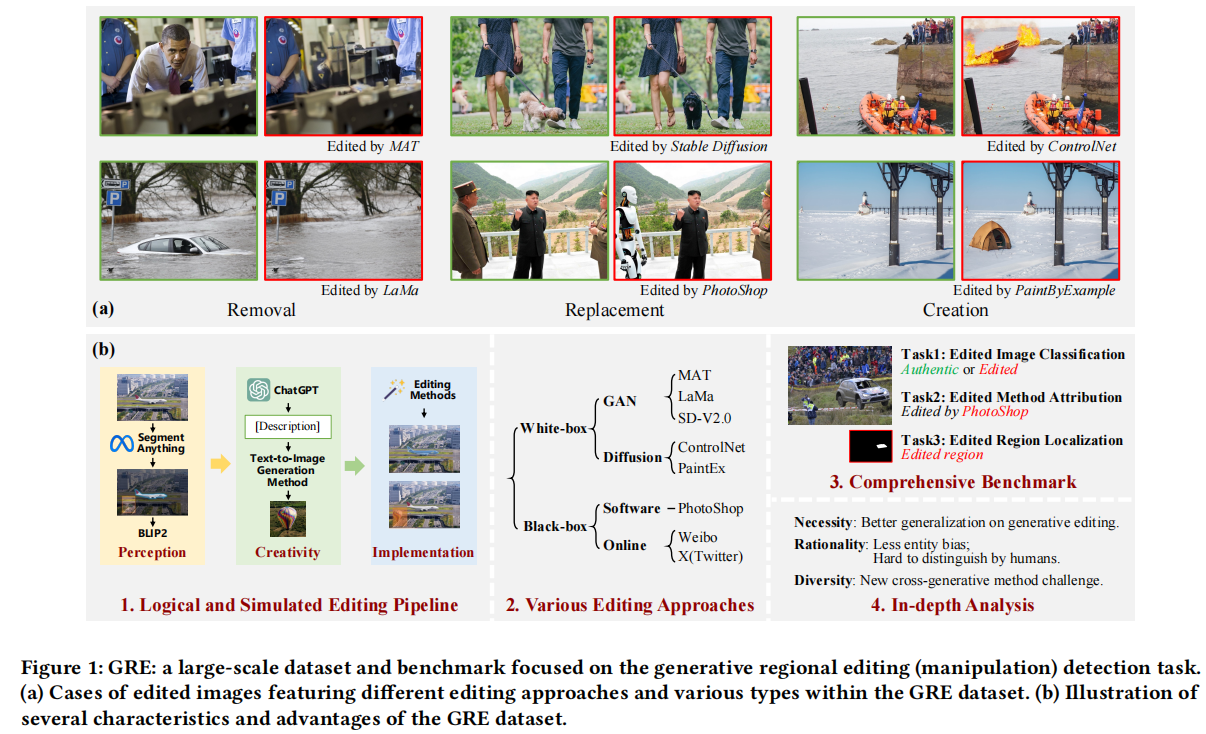
图1
(a)展示了多种代表性生成式区域编辑方法的性能表现,直观呈现了区分真实图像与编辑图像的难度。如今我们确实可以断言“眼见未必为实”。[21]因此,生成式区域编辑的检测能力值得我们重点关注。
本文构建了一个名为生成区域编辑(GRE,Generative
Regional
Editing)的新型大规模数据集,专注于检测生成性区域编辑任务。基于该数据集,我们建立了跨领域评估现有检测方法的基准体系,并从必要性、合理性及多样性等多个维度对数据集进行分析。大量实验和深入研究证明,这个规模更大、内容更全面的数据集将显著推动生成编辑检测方法的发展。具体而言,GRE数据集相较于现有相关数据集具有以下显著优势:
(1)逻辑与模拟编辑流程。过去,小规模区域编辑数据集通过人工操作确保逻辑连贯性(例如避免天空中出现狗的视觉冲突),而大规模数据集则难以通过简单的自动化编辑流程维持逻辑一致性。为确保编辑过程中的逻辑连贯性、增强编辑语义丰富度、适应数据规模扩展及提升系统可扩展性,我们整合了多种超大模型在不同模态下的应用,构建了一个包含感知、创意和实现三大模块的完整图像编辑流程。
(2)多元编辑方法研究。在实际应用场景中,我们无法预知编辑工具或方法的具体形式,因此评估检测模型对不同甚至未知编辑方式的泛化能力至关重要。为此,我们选取了多种代表性编辑方法进行深入探究。这些方法在架构设计上存在差异,包括基于生成对抗网络(GAN)、扩散网络以及黑盒方法等类型,其编辑控制机制也各具特色。
(3)全面基准测试。除了区分处理图像与真实图像的二分类任务外,通过解答图像被编辑的具体位置和方式,我们还致力于提升图像篡改检测任务在现实媒体取证场景中的可解释性。我们在数据集中提供了多层级标注,并提出了三项核心任务:1)编辑图像分类,判断图像是否经过编辑;2)编辑方法归因,识别图像中使用的编辑手段;3)编辑区域定位,精确定位图像中的篡改区域。通过评估前沿方法在这三项任务上的表现,实验表明虽然像素级定位任务更具挑战性,但在视觉效果丰富的编辑图像中发现篡改元素仍具有重要价值。
(4)深入分析。我们通过大量实验对GRE数据集作为基准需要具备的关键特性进行分析,包括其必要性、合理性、多样性等。通过现有数据集的跨数据集实验,我们验证了GRE数据集在解决新型生成性区域编辑检测研究空白方面的必要性。TCAV分析和用户研究证实,该数据集不存在实体偏见,且人工难以区分编辑操作。交叉编辑方法实验突显了生成式编辑方法多样性的价值。这些多维度验证共同表明,GRE是一个高质量的数据集。
2 相关工作
2.1 数据集的生成与处理
图像生成
近年来,生成图像检测领域备受关注,催生了DeepArt
[38]、IEEE VIPCup[36]、DE-FAKE [41]和CiFAKE
[2]等众多基准测试,以及GenImage
[50]提供的百万级数据集。然而这些数据集中的生成图像主要适用于图像级生成检测任务,难以完全满足编辑区域定位任务的需求。专门构建用于生成区域编辑检测的数据集不仅成本高昂,其像素级自动化编辑流程也比图像级生成任务更为复杂。
区域图像编辑
检测图像中被篡改或编辑的区域始终是长期存在的技术难题。表1汇总了现有数据集的规模、图像来源及编辑方法,这些数据集已被广泛使用并获得业界认可。
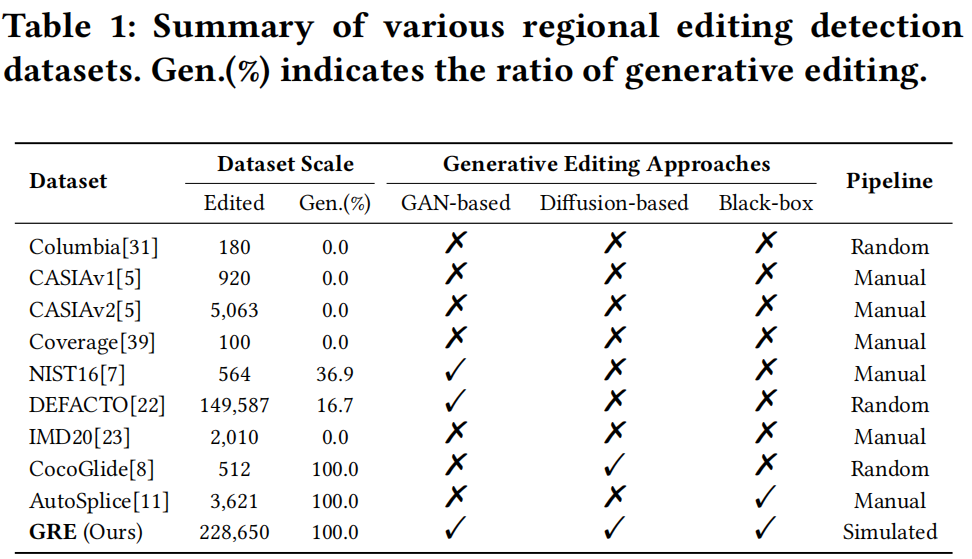
其中,Columbia[31]、CASIA [5]、Coverage [39]、NIST16 [7]和IMD20 [23]主要包含早期非生成式编辑形式(如简单剪切和复制移动)。唯有DEFACTO [22]收录了相对完整的生成式编辑图像数据集。但DEFACTO的自动化编辑流程仍存在明显痕迹。CocoGlide [8]包含512张基于COCO数据集通过GLIDE扩散模型生成的图像。AutoSplice [11]则利用DALL-E2在文本提示引导下进行自动编辑,并辅以人工校验。然而,这些数据集所采用的生成式编辑方法存在局限性,导致其无法为检测模型提供全面分析或泛化能力。
2.2 生成式区域编辑方法
基于扩散的方法
扩散模型的出现真正推动了生成式编辑方法在便捷性和有效性方面超越了依赖人工干预的操作序列。Stable
Diffusion
[29]代表了一种先进的文本到图像扩散模型。在推理过程中引入简单的掩码替换操作,可实现精准的区域编辑。ControlNet
[48]创新性地引入模块化设计,通过调用预训练的大规模扩散模型来适应不同输入条件。PaintbyExample
[42]则采用范例引导式图像编辑技术,突破传统语言引导模式,使编辑过程达到更高精度控制。
基于GAN的方法
然而,我们也必须承认近年来基于生成对抗网络(GAN)的图像编辑方法在性能上取得了显著提升。MAT
[15]通过定制化设计了一个以修复为主的transformer模块,其中注意力模块仅从部分有效的标记中提取非局部信息,动态掩码则对此进行有效调控。该方法在应对大规模图像修复挑战时展现出卓越效果。LaMa
[33]通过在推理过程中最小化多尺度一致性损失,优化了网络的中间特征图。这种策略巧妙解决了高分辨率图像细节缺失的问题,从而显著提升了视觉效果质量。
3 GRE结构
现有大多数图像生成数据集仅包含完整生成样本,未考虑图像内部区域编辑的常见场景。以往多数区域编辑数据集仅包含人工操作样本,缺乏生成模型参与,且创作过程缺乏逻辑合理性与语义多样性的考量。相比之下,我们提出的GRE数据集提供了多种生成式区域编辑方法,并定义了三个核心任务(即编辑图像检测、编辑区域定位及编辑方法溯源),共计包含22.8万张图像。我们设计了一套由多模态大型模型辅助的自动化编辑流程,能够执行逻辑一致的编辑操作。如表1所示,我们将GRE与其他公开区域编辑数据集进行对比。从表中列出的各项指标来看,我们的数据集在规模和多样性方面均优于其他同类数据集。