Robust Watermarking Using Generative Priors Against Image Editing:From Benchmarking to Advances

Robust Watermarking Using Generative Priors Against Image Editing: From Benchmarking to Advances
Shilin Lu1, Zihan Zhou1, Jiayou Lu1, Yuanzhi Zhu2, Adams Wai-Kin Kong
1 南洋理工大学
2 ETH Zurich
摘要
当前的图像水印技术容易受到基于大规模文本转图像模型的高级图像编辑技术的攻击。这些模型在编辑过程中会扭曲嵌入的水印,给版权保护带来重大挑战。在本工作中,我们介绍了W-Bench,这是第一个全面的基准,旨在评估水印方法对广泛的图像编辑技术的鲁棒性,包括图像再生、全局编辑、局部编辑和图像到视频生成。通过对11种代表性水印方法与主流编辑技术的广泛对比测试,我们发现多数方法在遭遇图像编辑后难以有效识别水印。针对这一技术瓶颈,我们创新性地提出VINE水印方案——该方案在保持图像质量优异的同时,显著提升了对各类图像编辑技术的抗干扰能力。我们的方法包含两项核心创新:(1)通过分析图像编辑的频率特征,发现模糊失真具有相似的频率特性,这使我们能够在训练过程中将其作为替代攻击手段来增强水印的鲁棒性;(2)采用大规模预训练扩散模型SDXL-Turbo,并针对水印任务进行适配,从而实现更隐蔽且稳定的水印嵌入。实验结果表明,本方法在多种图像编辑技术下均展现出卓越的水印性能,在图像质量与鲁棒性方面均优于现有方法。代码可在https://github.com/Shilin-LU/VINE上找到。
1引言
图像水印的核心功能在于保护版权或验证真实性。其设计的关键在于确保对各类图像处理具有强大的抗干扰能力。早期基于深度学习的水印技术(Bui
et al., 2023; Tancik et al., 2020; Zhu,
2018)已证明能有效抵御压缩、加噪、缩放和裁剪等常规处理。然而,近年来大规模文本到图像(T2I)模型的突破性进展(Chang
et al., 2023;Ramesh et al., 2022; Rombach et al., 2022; Saharia et al.,
2022)显著提升了图像编辑能力,提供了丰富的用户友好型操作工具(Brooks et
al., 2023;Zhang et al.,
2024b)。这些基于T2I的编辑方法能生成高度逼真的修改效果,使得水印在编辑后的版本中几乎难以察觉。这对版权和知识产权保护构成了挑战,因为恶意用户即使在作品中嵌入了水印,也能轻松篡改艺术家或摄影师的作品,创作出未注明出处的新内容。
在本研究中,我们提出了W-Bench基准测试平台——这是首个整合四种图像编辑技术的综合评估体系,用于检验水印方法的鲁棒性(如图1(a)所示)。该平台共评估了十一种代表性水印技术,涵盖图像再生、全局编辑、局部编辑及图像转视频生成(I2V)四大类。
(1)图像再生技术通过将原始图像扰动为含噪版本后进行重建,可分为随机型(Meng
et al., 2021; Zhao et al., 2023b)和确定型(亦称图像反转)(Mokady et al.,
2022; Song et al.,
2020a)。
(2)在全局编辑方面,我们采用Instruct-Pix2Pix(Brooks等人,2023)和MagicBrush(Zhang等人,2024b)等模型,这些模型以图像和文本提示作为输入来实现图像编辑。
(3)对于局部编辑,我们使用ControlNet-Inpainting(Zhang等人,2023)和UltraEdit(Zhao等人,2024c)等模型,它们允许通过额外的遮罩输入指定需要修改的区域。
(4)此外,我们还利用Stable
Video
Diffusion(SVD)(Blattmann等人,2023)在图像到视频生成的背景下评估水印模型,以确定生成的视频帧中水印是否仍可被检测到。尽管这不是传统图像编辑方法,但我们将其视为一种特殊情况,以便识别生成的视频是否使用了受版权保护的图像。
实验结果(图1(b))表明,大多数先前的水印模型在使用这些方法编辑图像后难以提取水印。StegaStamp(Tancik等人,2020)和MBRS(Jia等人,2021)在某些情况下能够保留水印,但代价是牺牲了图像质量。
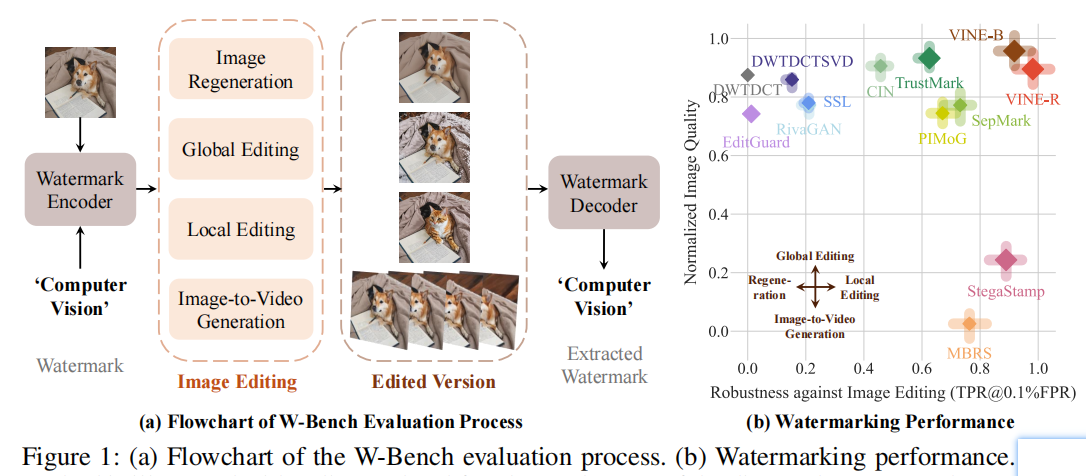
每种方法都用一个方块和四个长条进行可视化呈现。方块的面积代表该方法的编码容量,其中心y轴坐标表示归一化图像质量,通过计算水印图像与原始图像在归一化PSNR、SSIM、LPIPS和FID指标上的平均值得出。x轴坐标反映鲁棒性,以0.1%假阳性率(TPR@0.1%FPR)下的真阳性率作为衡量标准,综合四种图像编辑方法的测试结果,涵盖七种不同模型和算法。四根长条的排列方向对应不同编辑任务:左为图像再生,上为全局编辑,右为局部编辑,下为图像转视频生成。柱体长度反映了各编辑类型后的归一化TPR@0.1%FPR值——柱体越长,说明性能越优。
为此,我们提出VINE,一种专为抵御图像编辑而设计的隐形水印模型。我们的改进重点在于两个关键组件:噪声层和水印编码器。对于噪声层而言,直接将编辑过程纳入训练流程是提升水印模型抗编辑能力的常规方法。然而,这种做法在大规模基于T2I模型的图像编辑场景中几乎不可行,因为需要对整个采样过程进行反向传播,可能导致内存问题(Salman等人,2023)。为此,我们通过频率分析视角研究图像编辑行为,采用替代攻击策略。核心发现在于:图像编辑倾向于消除高频带中的特征模式,而低频带特征则受影响较小。这一特性同样体现在模糊失真(如像素化和散焦模糊)中。实验表明,在噪声层中融入多种模糊失真可显著增强水印对图像编辑的抗干扰能力。
然而,这种鲁棒性是以牺牲水印图像质量为代价的,其质量受限于水印编码器的能力。为解决这一问题,我们采用大规模预训练生成模型(如SDXL-Turbo,Sauer等人,2023年)作为强大的生成先验,并针对水印任务进行专门适配。在此框架下,水印编码器作为条件生成模型运作,以原始图像和水印作为输入,生成具有独特分布特征的水印图像,这些图像能被对应的解码器可靠识别。通过利用这种强大的生成先验,水印得以更有效地嵌入,从而在提升感知图像质量的同时,也增强了系统的鲁棒性。
我们的贡献总结如下:
- 我们提出了W-Bench,这是第一个全面的基准,旨在评估11个代表性的水印模型在各种图像编辑方法中的表现:图像再生、全局编辑、局部编辑和图转视频生成,该评估涵盖了7种广泛使用的编辑模型和算法,并证明了当前的水印模型很容易受到它们的影响。
- 我们发现图像编辑主要针对高频带的水印模式进行消除,而低频带的水印则受影响较小。这种现象在某些类型的模糊失真中同样存在。这类失真可作为替代攻击手段,既能有效应对训练过程中使用T2I模型带来的挑战,又能增强水印的抗干扰能力。
- 我们将水印编码器视为条件生成模型,并引入两项技术将SDXL-Turbo(一种预训练的一步式文本到图像模型)适配于水印任务。这种强大的生成先验不仅提升了水印图像的感知质量,还增强了其对各类图像编辑的鲁棒性。实验结果表明,我们的模型VINE在保持高画质的同时,对多种图像编辑方法表现出色,性能超越现有水印模型。
2相关工作
水印基准
据我们所知,WAVES(An et al.,
2024)目前是评估基于深度学习的水印方法在大规模生成模型驱动图像篡改场景下鲁棒性的唯一综合性基准。然而,该基准仅涵盖主流图像编辑技术中的图像再生(Zhao
et al.,
2023b),未包含其他基于T2I的编辑模型。相比之下,W-Bench不仅包含图像再生,还囊括全局编辑(Brooks
et al., 2023)、局部编辑(Zhang et al.,2023)以及图像转视频生成 (Blattmann
et al.,
2023),从而拓宽了对图像编辑方法的评估范围。此外,WAVES仅评估三种水印方法——StegaStamp(Tancik
et al., 2020)、Stable Signature(Fernandez et al., 2023)和TreeRing(Wen et
al., 2023)。值得注意的是,Stable
Signature和TreeRing仅适用于生成图像,无法应用于真实图像。而W-Bench的设计初衷是评估能适配各类图像的水印模型,从而提升其版权保护效果。
鲁棒水印
图像水印技术长期被用于知识产权追踪与保护等领域(Al-Haj,2007;Cox等,2007;Navas等,2008)。近年来,基于深度学习的方法(Bui等,2023;Chen与Li,2024;Fang等,2022;2023;Jia等,2021;Kishore等,2021;Luo等,2020;2024;Ma等,2022;Tancik等,2020;Wu等,2023;Zhu,2018;Zhang等,2019;2021)展现出对各类图像变换的强健防御能力。然而,这些方法仍难以抵御基于大规模生成模型的图像编辑攻击。近期三项突破性研究——EditGuard(Zhang等,2024d)、RobustWide(Hu等,2024)和JigMark(Pan等,2024)——已开始研发能有效抵御此类图像编辑的水印模型。
3方法
给定原始图像xo和水印w,我们的目标是通过编码器E(·)将水印以不可察觉的方式嵌入图像中,从而获得带水印的图像 $ x_w = E(x_o, w) $ 。即使图像经过编辑\(\epsilon(\cdot)\),对应的解码器D(·)也应能准确提取水印,即\(w^{\prime}=D(x_w)\)。
在第3.1节中,我们研究了各种图像编辑方法的频率特性,并确定了增强水印对它们鲁棒性的替代攻击。在第3.2节中,我们通过采用一步式文本转图像模型作为水印编码器,进一步提升了水印图像的鲁棒性和质量。此外,我们还引入了多种技术手段来促进这种适配过程。第3.3节详细阐述了实验中采用的训练损失函数、策略以及分辨率缩放方法。
3.1图像编辑的频率特性
要开发一种能有效抵御图像编辑的鲁棒水印模型,最直接的方法是在训练过程中将图像编辑模型整合到编码器与解码器之间的噪声层。然而,当前主流的图像编辑方法大多基于扩散模型,这类模型通常需要经过多次采样步骤才能生成编辑后的图像。这可能导致在反向传播去噪过程时出现内存问题。其他替代方案如梯度截断(Hu等人,2024;Yuan等人,2024)效果欠佳,而直流估计器(Bengio等人,2013)在从头训练时甚至无法收敛。因此,我们尝试在训练过程中引入替代攻击机制。
我们首先研究图像编辑方法对图像频谱的影响机制。具体而言,我们设计了三组实验方案,分别在低频、中频和高频频段嵌入对称图案。

图2展示了将图案嵌入低频段的分析流程:首先在原始图像\(x_o\)的RGB通道傅里叶频谱低频区域嵌入一个恒定值环形图案w(即\({\mathcal{F}}(x_{o})+w\)),随后通过逆傅里叶变换得到水印后的图像\(x_w\)。接着应用图像编辑模型\(\epsilon(\cdot)\)对原始图像\(x_o\)和水印图像\(x_w\)进行处理,分别生成编辑后的图像\(\epsilon(x_o)\)和\(\epsilon(x_w)\)。最后通过计算两者的傅里叶频谱差异\(|{\mathcal{F}}(\epsilon(x_{w}))-{\mathcal{F}}(\epsilon(x_{o}))|\),评估图案在编辑过程中的变化情况。具体使用的图像编辑方法详见第4.1节。

实验结果基于1000张图像的平均值。图像编辑方法通常会消除中高频段的频率特征,而低频特征基本不受影响。这种现象在像素化、失焦模糊等模糊失真中同样存在。相比之下,JPEG压缩和饱和度等常见失真方式在频域中不会呈现类似特征。由于SVD会消除所有特征模式,使其对人眼不可见,因此未纳入分析范围。关于SVD的详细讨论可参见第4.3节。
图3显示,图像编辑方法通常会移除中高频段的特征模式,而低频特征则相对不受影响。这表明基于T2I的图像编辑方法往往难以复现复杂的中高频细节特征。我们推测,这是因为T2I模型在训练时优先捕捉图像的整体语义内容和结构(即主要关注低频成分),以匹配文本提示。因此,在生成过程中高频特征会被过度平滑处理。
要开发出能有效抵御图像编辑的水印模型,其核心在于学会将信息嵌入低频带。为识别有效的替代性攻击手段,我们研究了多种图像失真方法(记作\(\cal
T(\cdot)\)),这些方法在某种程度上模拟了图像编辑行为。虽然图像编辑和失真技术都能保持整体布局和大部分内容,但失真处理通常会导致图像感知质量下降。值得注意的是,如图3所示,某些模糊失真(例如像素化和散焦模糊)呈现出与图像编辑相似的特征。相比之下,广泛使用的失真效果(如JPEG压缩和饱和度调整)则不会出现这种现象。由于这些模糊失真具有较高的计算效率,我们在训练过程中将其以不同严重程度融入噪声层。这鼓励模型在低频带中嵌入信息(参见附录B中每种水印方法的频率模式)。因此,如表2的消融研究所示,增强了对图像编辑的鲁棒性。噪声层中应用的完整失真效果包含多种常见失真类型,例如饱和度调整、对比度调节、亮度调整、JPEG压缩、高斯噪声、散粒噪声、脉冲噪声和斑点噪声,这些都能有效抵消透射导致的图像劣化。此外,我们还融入了像素化模糊、虚焦模糊、缩放模糊、高斯模糊和运动模糊等多种模糊效果,以增强图像抗编辑能力。
3.2水印编码的生成式先验
虽然在噪声层中引入图像失真可以增强对图像编辑的鲁棒性,但这种改进是以牺牲水印图像质量为代价的,而图像质量受限于水印编码器的能力。水印编码器可视为一个条件生成模型,其条件包含水印和详细图像,而非深度图、Canny边缘或涂鸦等简单表征。我们推测,强大的生成先验机制既能更隐蔽地嵌入信息,又能提升鲁棒性。因此,我们计划将大规模T2I模型适配为水印编码器。目前存在两种大规模T2I模型:多步骤型和单步骤型。多步骤T2I模型会增加水印提取损失的反向传播复杂度,导致推理速度较慢。为此,我们采用预训练的单步骤文本到图像模型SDXL-Turbo(Sauer等人,2023)。
要将SDXL-Turbo转化为水印编码器,关键在于找到一种能同时整合输入图像与水印信息的有效策略。扩散模型中常见的条件集成方法是引入额外的适配分支(Mou等人,2024;Zhang等人,2023)。但在单步生成模型中,噪声图——即UNet的输入——直接决定了生成图像的最终布局(Sauer等人,2023)。这与多步扩散模型形成鲜明对比,后者在早期采样阶段会逐步构建图像布局。若在单步模型中添加额外条件分支,UNet将接收两组残差特征,每组分别对应不同的结构特征。这使得训练过程更具挑战性,导致性能表现欠佳,如表2的消融实验所示。为此,我们采用条件适配器融合输入图像与水印信息(条件适配器架构详见图11),如图4所示。将融合后的数据输入VAE编码器提取潜在特征后,再通过UNet和VAE解码器生成最终水印图像。我们还尝试通过文本提示输入水印并同步微调文本编码器,但该方案未能收敛。因此在训练过程中,我们直接将文本提示设置为空提示。
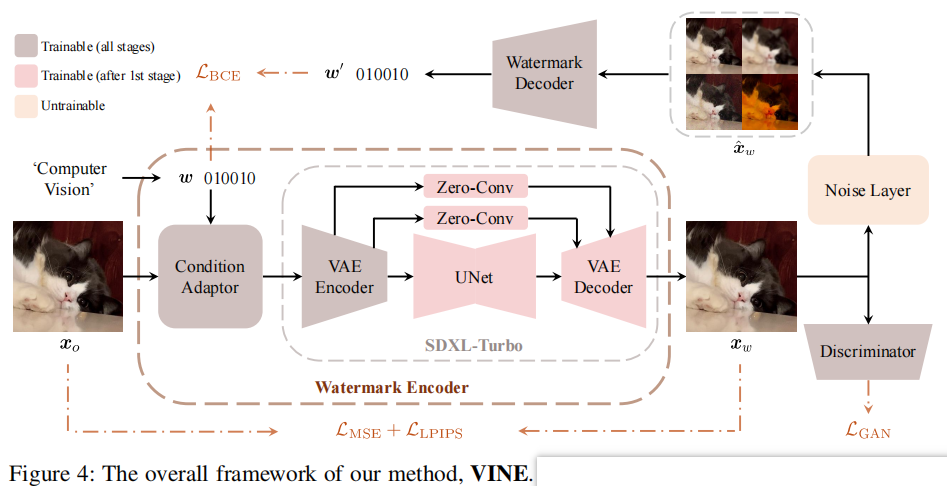
我们采用预训练的一步式文本到图像模型SDXL-Turbo作为水印编码器,并在将信息传递给VAE编码器前,通过条件适配器将水印与图像融合。为增强感知相似性,我们添加了零卷积层(Zhang等人,2023)和跳跃连接。在解码水印时,采用ConvNeXt-B(Liu等人,2022b)作为解码器,并额外增加全连接层输出100比特水印。整个训练过程中,SDXL-Turbo的文本提示始终设置为空提示。图11展示了条件适配器的架构设计。
尽管SDXL-Turbo的变分自编码器(VAE)整体效果良好,但其架构并不完全适合水印任务。该模型旨在平衡重建能力和压缩性能,因此在重建保真度与更平滑的潜在空间及更好的可压缩性之间进行了权衡。然而在水印的背景下,重建能力对于确保带有水印的图像在感知上与输入图像相同是至关重要的。为此,我们通过在编码器与解码器之间引入跳跃连接(图4)来增强变分自编码器(VAE)。具体而言,我们在编码器的每个下采样块后提取四个中间激活值,将其通过零卷积层(Zhang等人,2023年)处理后,输入到解码器对应的上采样块中。如表2所示,这一改进显著提升了水印图像与输入图像之间的感知相似度。为解码水印,我们采用卷积神经网络解码器ConvNeXt-B(Liu等人,2022b),并在其后添加全连接层以输出100比特水印信息。
3.3目标函数和训练策略
目标函数
我们采用标准训练方案,在不同图像处理条件下平衡水印图像质量与水印提取效果,总损失函数如下:
\[{\mathcal L}_{\mathrm{AL}}={\mathcal
L}_{\mathrm{IMG}}\left(x_{o},x_{w}\right)+\alpha{\mathcal
L}_{\mathrm{BCE}}\left(w,w^{\prime}\right),\]
其中α是权衡超参数,\({\mathcal
L}_{\mathrm{BCE}}\)是基于提取的水印与真实值计算的标准二元交叉熵损失函数。图像质量损失\({\mathcal{L}}_{\mathrm{IHG}}\)定义为:
\[{\mathcal{L}}_{\mathrm{IHG}}=\beta_{\mathrm{MSE}}{\mathcal{L}}_{\mathrm{MSE}}\left(\gamma(x_{o}),\gamma(x_{w})\right)+\beta_{\mathrm{LPPS}}{\mathcal{L}}_{\mathrm{LPIPS}}\left(x_{o},x_{w}\right)+\beta_{\mathrm{GAN}}{\mathcal{L}}_{\mathrm{GAN}}\left(x_{o},x_{w}\right),\]
其中\(\beta_{\mathrm{MSE}}\)、\(\beta_{\mathrm{LPIPS}}\)和\(\beta_{\mathrm{GAN}}\)分别代表各损失项的权重。这里,\(\gamma(\cdot)\)是一个可微的非参数映射函数,用于将输入图像从RGB色彩空间转换为感知上更均匀的YUV色彩空间;\({\mathcal{L}}_{\mathrm{LPIPS}}(x_o,x_w)\)是感知损失项,而\({\mathcal{L}}_{\mathrm{GAN}}(x_o,x_w)\)则是来自GAN判别器\({\mathcal
D}_{\mathrm{disc}}\)的标准对抗损失项: \[{\mathcal{L}}_{\mathrm{GAN}}={\mathbb{E}}_{x_{o}}\left[\log
D_{\mathrm{disc}}(x_{o})\right]+{\mathbb{E}}_{x_{o},w}\left[\log\left(1-D_{\mathrm{disc}}(E(x_{o},w))\right)\right].\]
训练策略
在第一阶段训练中,我们优先采用水印提取损失函数,将α设为10,同时将\(\beta_{\mathrm{MSE}}\)、\(\beta_{\mathrm{LPIPS}}\)和\(\beta_{\mathrm{GAN}}\)各设为0.01。为保持生成先验特性,SDXL-Turbo的UNet和VAE解码器以及新增的零卷积层均被冻结。当比特准确率超过0.85时,我们将进入第二阶段训练,解冻所有参数进行后续优化。此时调整损失权重因子为α
= 1.5、βMSE = 2.0、βLPIPS = 1.5、βGAN =
0.5。经过前两个阶段训练后的模型作为基础模型,命名为VINE-B。在第三阶段,我们通过将代表性指令驱动图像编辑模型Instruct-Pix2Pix(Brooks等人,2023)整合到噪声层中,对VINE-B进行微调。梯度通过直流估计器(Bengio等人,2013)进行反向传播。需要注意的是,如果在早期训练阶段直接应用该方法,将无法收敛。经过微调的模型被称为VINE-R。更多实现细节请参见附录F。
分辨率缩放
不同的水印模型通常采用固定输入分辨率进行训练,这限制了它们在测试时只能接受固定分辨率的输入。然而在实际应用中,保持原始分辨率的水印处理对维护图像质量至关重要。Bui等人(2023)提出了一种方法(详见附录D.1),可使任何水印模型适应任意分辨率而不影响水印图像的质量及其固有鲁棒性,如附录D.2和D.3所示。在我们的实验中,我们将这种分辨率缩放方法应用于所有模型,使其能够在统一的512×512分辨率下运行,这与图像编辑模型的兼容性完全一致。
4实验
在W-Bench测试中,我们评估了十一种代表性水印模型对多种图像编辑方法的鲁棒性,包括图像再生、全局编辑、局部编辑以及图像转视频生成。第4.1节和第4.2节分别概述了所采用的图像编辑方法及基准测试设置。第4.3节分析了基准测试结果。第4.4节通过消融实验研究,深入探究了关键组件的影响机制。
4.1图像编辑方法
4.2实验设置
4.3基准测试结果与分析
4.4消融研究
5结论
在本研究中,我们推出了W-Bench,首个整合四大图像编辑功能的综合基准测试平台,通过大规模生成模型评估水印模型的鲁棒性。我们从海量样本中筛选出11种代表性水印方法进行测试,并揭示了图像编辑对傅里叶频谱的普遍影响机制,同时开发出高效的模拟替代方案。自主研发的VINE模型在对抗各类图像编辑技术时展现出卓越性能,在图像质量与鲁棒性方面均超越现有方法。研究结果表明:预训练模型可作为水印技术的通用框架,而强大的生成式先验机制能以更隐蔽且稳健的方式增强信息嵌入效果。
限制
虽然我们的方法在基于生成模型的常见图像编辑任务中表现出色,但在I2V生成方面的效果仍有限。此外,我们的模型比基线模型更大,导致内存需求增加,推理速度略有下降,具体如表7所示。